
Google アシスタントにレスポンスを返すときは、 SSML(音声合成マークアップ言語)をレスポンスに挿入します。方法 SSML を使用すると、会話のレスポンスをより自然なものにできます。 生成します。次の例は、SSML マークアップと、 Google アシスタント:
Node.js
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.add(ssml); }
JSON
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
音声
SSML の URL
URL のみを含む SSML レスポンスを定義する場合は、その URL にアンパサンドが含まれる
XML 形式が原因で問題が発生することがあります。URL が正しく
& のインスタンスを & に置き換えます。
SSML レスポンスに URL のみが含まれている場合でも、Actions on Google では
表示するテキストを指定します。<audio> タグ内のテキストは
音声のみのテキストや簡単な説明を
この要件を満たすには <audio> タグを使用します。<audio> タグ内のテキストは
音声再生後にアシスタントが応答し、Google のアクション
SSML の表示テキスト バージョンの要件です。
以下に、問題のある SSML レスポンスの例を示します。
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
上記の例では、適切な XML 形式の & がエスケープされていません。
同じ SSML レスポンスの修正済みバージョンは次のようになります。
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
SSML 要素のサポート
次のセクションでは、アクションで使用できる SSML 要素とオプションについて説明します。
<speak>
SSML レスポンスのルート要素。
speak 要素の詳細については、W3 仕様をご覧ください。
例
<speak> my SSML content </speak>
<break>
休止、または韻律のその他の単語間の境界を制御する空の要素。トークンのペアの間で <break> を使用するかどうかは任意です。この要素が単語間に存在しない場合、言語的コンテキストに基づいて自動的にブレークが決定されます。
break 要素の詳細については、W3 仕様をご覧ください。
属性
| 属性 | 説明 |
|---|---|
time |
ブレークの長さを秒またはミリ秒単位で設定します(「3 秒」、「250 ミリ秒」など)。 |
strength |
出力の韻律ブレークの強さを相対的な強さで設定します。有効な値は、「x-weak」、「weak」、「medium」、「strong」、「x-strong」です。値「none」は、韻律ブレーク境界が出力されるべきでないことを示し、プロセッサによる韻律ブレークの生成を防止するために使用できます。その他の値は、単調に減少しない(概念的に増加する)トークン間のブレークの強度を示します。一般的に、強い境界は休止を伴います。 |
例
次の例は、<break> 要素を使用してステップ間で休止する方法を示します。
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
この要素を使用すると、要素内に含まれているテキスト構造体の種類に関する情報を指定できます。また、含まれているテキストのレンダリングの詳細レベルを指定することもできます。
<say‑as> 要素には、値の発音方法を指定する必須属性、interpret-as があります。オプションの属性 format と detail は、interpret-as が特定の値の場合に使用できます。
例
interpret-as 属性は次の値をサポートしています。
-
currency次の例は「forty two dollars and one cent」と発音されます。language 属性を省略すると、現在の言語 / 地域が使用されます。
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> -
telephoneW3C SSML 1.0 の say-as attribute values に関する WG メモの
interpret-as='telephone'についての説明をご覧ください。次の例は「one eight zero zero two zero two one two one two」と発音されます。google:style 属性を省略すると、ゼロがアルファベットの O(オー)として発音されます。
google:style='zero-as-zero' 属性は、現在英語を使用する言語 / 地域でのみ機能します。
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak> verbatimまたはspell-out次の例は、文字ごとにスペルアウトされています。
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak>-
dateformat属性は、日付のフィールド文字コードの連続を表します。formatでサポートされているフィールド文字コードは {y,m,d} で、それぞれ年、月、日を表します。年、月、または日のフィールド コードを 1 回使用する場合、それぞれを 4、2、2 桁で指定する必要があります。同じフィールド コードを繰り返す場合、そのコードの数が桁数を意味します。日付テキスト内のフィールドは、句読点やスペースで区切ることが可能です。detail属性は、日付の発音形式を制御します。detail='1'の場合、日フィールドに加え、月フィールドまたは年フィールドのどちらかが必須ですが、両方指定することも可能です。これは、3 つのフィールドが 1 つでも欠けている場合のデフォルトです。発音形式は「The {ordinal day} of {month}, {year}」です。次の例では、「The tenth of September, nineteen sixty」と発音されます。
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>次の例は「The tenth of September」と発音されます。
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>detail='2'の場合、日、月、年の 3 つのフィールドが必要で、3 つのフィールドがすべて指定されている場合はこれがデフォルトになります。発声形式は「{month} {ordinal day}, {year}」です。次の例では、「September tenth, nineteen sixty」と発音されます。
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
characters次の例は、「C A N」と発音されます。
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalたとえば次の値は、アメリカ英語では「Twelve thousand three hundred forty five」、イギリス英語では「Twelve thousand three hundred and forty five」と発音されます。
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinal次の例は、「First」と発音されます。
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fraction次の例は、「five and a half」と発音されます。
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> expletiveまたはbleep次の例は、放送禁止用語に使われるビープ音として出力されます。
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak>-
unit数に応じて、単位を単数形または複数形に変換します。次の例は、「10 feet」と発音されます。
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
time次の例は、「Two thirty P.M」と発音されます。
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>format属性は、時刻のフィールド文字コードの連続を表します。formatでサポートされているフィールドの文字コードは {h,m,s,Z,12,24} で、それぞれ、時、分、秒、タイムゾーン、12 時間制の時間、24 時間制の時間を表します。時、分、秒のフィールド コードを 1 回使用する場合、それぞれを 1、2、2 桁で指定する必要があります。同じフィールド コードを繰り返す場合、そのコードの数が桁数を意味します。時間テキスト内のフィールドは、句読点やスペースで区切ることが可能です。時、分、秒がこの形式で指定されていないか、一致する数字がない場合、フィールドは値 0 として扱われます。デフォルトのformatは "hms12" です。detail属性は、時刻を 12 時間制と 24 時間制のどちらで発音するかを制御します。detail='1'の場合、またはdetailが省略され、時刻の形式が 24 時間制の場合、発音形式は 24 時間制です。detail='2'の場合、またはdetailが省略され、時刻の形式が 12 時間制の場合、発音形式は 12 時間制です。
say-as 要素の詳細については、W3 仕様をご覧ください。
<audio>
合成された音声出力に関連して、録音された音声ファイルの挿入、他のオーディオ形式の挿入をサポートする要素です。
属性
| 属性 | 必須 | デフォルト | 値 |
|---|---|---|---|
src |
○ | なし | 音声メディアソースを参照する URI。サポートされているプロトコルは https です。 |
clipBegin |
× | 0 | 再生する音源の先頭からのオフセットを示す TimeDesignation。この値が音源の実際の時間以上である場合、音声は挿入されません。 |
clipEnd |
× | 無限大 | 音源の再生開始から再生終了までのオフセットを示す TimeDesignation。音源の実際の時間がこの値より短い場合、その時点で再生が終了します。clipBegin が clipEnd 以上の場合、音声は挿入されません。 |
speed |
× | 100% | 通常の入力レートに対する出力再生レートの比。パーセント値で表されます。形式は正の実数で、後に % が続きます。現在サポートされている範囲は [50%(低速 - 半分の速度)、200%(高速 - 2 倍の速度)] です。この範囲外の値を指定した場合、範囲内に収まるように調整されることもありますが、確実ではありません。 |
repeatCount |
× | 1、または repeatDur が設定されている場合は 10 |
音声を挿入する回数を指定する実数(clipBegin や clipEnd によってクリッピングが発生した場合はその後に挿入される数)。小数の繰り返しはサポートされていないため、値は最も近い整数に丸められます。0 は有効な値ではないため、指定されていないものとして扱われ、その場合はデフォルト値になります。 |
repeatDur |
× | 無限大 | 入力音源に clipBegin、clipEnd、repeatCount、speed の属性が適用され処理された後に、挿入される音声の時間制限を示す TimeDesignation(通常の再生時間ではない)。処理された音声の時間がこの値より短い場合、その時点で再生が終了します。 |
soundLevel |
× | +0dB | soundLevel デシベル単位で音声のサウンドレベルを調整します。最大範囲は +/-40dB ですが、実際の範囲は狭くなることがあり、全範囲にわたって出力品質が良好にならない可能性があります。 |
現在サポートされている音声の設定は次のとおりです。
- 形式: MP3(MPEG v2)
- 24K サンプル/秒
- 24K~96K ビット/秒、固定レート
- 形式: Ogg に格納された Opus
- 24K サンプル/秒(超広帯域)
- 24K~96K ビット/秒、固定レート
- 形式(非推奨): WAV(RIFF)
- PCM 16 ビット符号付きリトル エンディアン
- 24K サンプル/秒
- すべての形式:
- 単一チャンネルが推奨されていますが、ステレオも使用できます。
- 最大時間は 240 秒。長時間の音声を再生したい場合は、メディア レスポンスの実装を検討してください。
- 5 メガバイトのファイルサイズ上限。
- ソース URL には HTTPS プロトコルを使用する必要があります。
- 音声をフェッチするときの UserAgent は「Google-Speech-Actions」です。
<audio> 要素のコンテンツはオプションであり、音声ファイルを再生できない場合や出力デバイスで音声がサポートされていない場合に使用されます。コンテンツに <desc> 要素を含めることができ、その場合はその要素のテキスト コンテンツが表示に使用されます。詳細については、レスポンス チェックリストの「録音された音声」セクションをご覧ください。
src URL は https URL にする必要があります(Google Cloud Storage は https URL で音声ファイルをホストできます)。
メディア レスポンスの詳細については、レスポンス ガイドのメディア レスポンス セクションをご覧ください。
audio 要素の詳細については、W3 仕様をご覧ください。
例
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
文と段落の要素。
p 要素と s 要素の詳細については、W3 仕様をご覧ください。
例
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
ベスト プラクティス
- 特に、韻律を変更する SSML 要素(<audio>、<break>、<emphasis>、<par>、<prosody>、<say-as>、<seq>、<sub>)が含まれる場合は、<s>...</s> タグを使用して文全体を囲みます。
- 聞いて認識できる長さの区切りを音声に含めたい場合は、<s> ...</s>タグを使用して文と文の間に区切りを入れます。
<sub>
発音の際、タグ内のテキストが alias 属性値のテキストによって置き換えられることを示します。
sub 要素を使用して、読みにくい単語の簡略化された発音を提供することもできます。下の最後の例は、日本語でのこのユースケースを示しています。
sub 要素の詳細については、W3 仕様をご覧ください。
例
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
テキスト シーケンスやタグのシーケンスにマーカーを挿入する空の要素。シーケンス内の特定の場所を参照する場合や、非同期通知のマーカーを出力ストリームに挿入する場合に使用できます。
mark 要素の詳細については、W3 仕様をご覧ください。
例
<speak> Go from <mark name="here"/> here, to <mark name="there"/> there! </speak>
<prosody>
要素によって含まれるテキストのピッチ、発話速度、音量をカスタマイズするために使用されます。現在、rate、pitch、volume の属性がサポートされています。
rate 属性と volume 属性は、W3 仕様に従って設定できます。pitch 属性値の設定は、次の 3 通りの方法で行えます。
| 属性 | 説明 |
|---|---|
name |
各マークの文字列 ID。 |
| オプション | 説明 |
|---|---|
| 相対 | 相対値を指定します(例: 「low」、「medium」、「high」など)。「medium」がデフォルトのピッチです。 |
| 半音 | 「+Nst」または「-Nst」を使用して、ピッチを半音で「N」個ずつ増減します。なお、「+/-」と「st」は必須になります。 |
| 割合 | 「+N%」または「-N%」を使用して、ピッチを「N」パーセントずつ増減します。「%」は必須ですが、「+/-」は任意です。 |
prosody 要素の詳細については、W3 仕様をご覧ください。
例
次の例では、通常より半音 2 つ分低く、ゆっくりと話すように <prosody> 要素を使用しています。
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
要素によって含まれるテキストに強調を追加するか、削除するために使用されます。<emphasis> 要素は <prosody> と同様に音声を変更しますが、個々の音声属性を設定する必要はありません。
この要素は、次の有効な値を持つオプションの属性「level」をサポートします。
strongmoderatenonereduced
emphasis 要素の詳細については、W3 仕様をご覧ください。
例
次の例では、<emphasis> 要素を使用してアナウンスを行います。
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
一度に複数のメディア要素を再生できるパラレル メディア コンテナです。使用を許可されているコンテンツは、1 つまたは複数の <par>、<seq>、<media> 要素のセットに限られています。<media> 要素の順序は重要ではありません。
子要素で異なる開始時刻が指定されていない限り、要素の暗黙の開始時刻は <par> コンテナの開始時刻と同じです。子要素の begin 属性または end 属性にオフセット値が設定されている場合、要素のオフセットは <par> コンテナの開始時刻に対する相対値になります。ルートの <par> 要素については、begin 属性は無視され、代わりに SSML 音声合成プロセスがルートの <par> 要素の出力生成を開始する時刻が開始時刻になります(つまり、時刻を「0」と指定した場合と同じです)。
例
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak><seq>
メディア要素を次々と順番に再生できるシーケンシャル メディア コンテナ。使用を許可されているコンテンツは、1 つまたは複数の <seq>、<par>、<media> 要素のセットに限られています。メディア要素の順序がレンダリングされる順序になります。
子要素の begin 属性と end 属性はオフセット値に設定できます(下の時間指定を参照)。こうした子要素のオフセット値は、シーケンス内の直前の要素の最後からの相対値で、シーケンス内の最初の要素についてはその <seq> コンテナ先頭からの相対値になります。
例
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media>
<par> または <seq> 要素内のメディアレイヤを表します。使用を許可されている <media> 要素のコンテンツは、SSML の <speak> 要素または <audio> 要素です。次の表に、<media> 要素の有効な属性を示します。
属性
| 属性 | 必須 | デフォルト | 値 |
|---|---|---|---|
| xml:id | × | 値なし | この要素の一意の XML 識別子。エンコードされたエンティティはサポートされません。この識別子は正規表現パターン "([-_#]|\p{L}|\p{D})+" と一致する値です。詳細については、XML-ID をご覧ください。 |
| begin | × | 0 | このメディア コンテナの開始時刻。これがルートのメディア コンテナ要素である場合は無視されます(デフォルトの「0」と同じように扱われます)。有効な文字列値については、以下の時間指定セクションをご覧ください。 |
| end | × | 値なし | このメディア コンテナの終了時刻の指定。有効な文字列値については、以下の時間指定セクションをご覧ください。 |
| repeatCount | × | 1 | メディアを挿入する回数を指定する実数。小数の繰り返しはサポートされていないため、値は最も近い整数に丸められます。0 は有効な値ではないため、指定されていないものとして扱われ、その場合はデフォルト値になります。 |
| repeatDur | × | 値なし | 挿入されたメディアの時間の制限を示す TimeDesignation。メディアの時間がこの値より短い場合、その時点で再生が終了します。 |
| soundLevel | × | +0dB | soundLevel デシベル単位で音声のサウンドレベルを調整します。最大範囲は +/-40dB ですが、実際の範囲は狭くなることがあり、全範囲にわたって出力品質が良好にならない可能性があります。 |
| fadeInDur | × | 0 秒 | メディアが無音からオプション指定の soundLevel までフェードインする時間を示す TimeDesignation。メディアの時間がこの値より短い場合、フェードインは再生が終了すると停止し、サウンドレベルは指定したレベルに達しません。 |
| fadeOutDur | × | 0 秒 | メディアがオプション指定の soundLevel から無音になるまでフェードアウトする時間を示す TimeDesignation。メディアの時間がこの値より短い場合、再生終了時に無音に到達するようにサウンドレベルを低い値に設定します。 |
時間指定
<media> 要素とメディア コンテナ(<par> および <seq> 要素)の「begin」または「end」属性値に使われる時間指定は、オフセット値(例: +2.5s)または同期ベース値(例: foo_id.end-250ms)になります。
- オフセット値 - 時間オフセット値は SMIL Timecount 値で、正規表現パターン
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"と一致する値を使用できます。最初の数字列は 10 進数の整数部、2 番目の数字列は小数部分です。符号(「(」、「+」、「|」、「-」、「)」、「?」など)のデフォルトは「+」です。単位値はそれぞれ、時、分、秒、ミリ秒に相当します。単位のデフォルトは「s」(秒)です。
- 同期ベース値 - 同期ベース値は SMIL 同期ベース値で、正規表現パターン
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"と一致する値を使用できます数字と単位は、オフセット値と同様に解釈されます。
TTS シミュレータ
Actions Console には、SSML のテストに使用できる TTS シミュレータが含まれています。 必要があります。TTS シミュレータはコンソールにあります。 [シミュレータ]>オーディオ。シミュレータにテキストと SSML を入力して、 TTS 出力を聞くには、[Update and Listen] をクリックします。
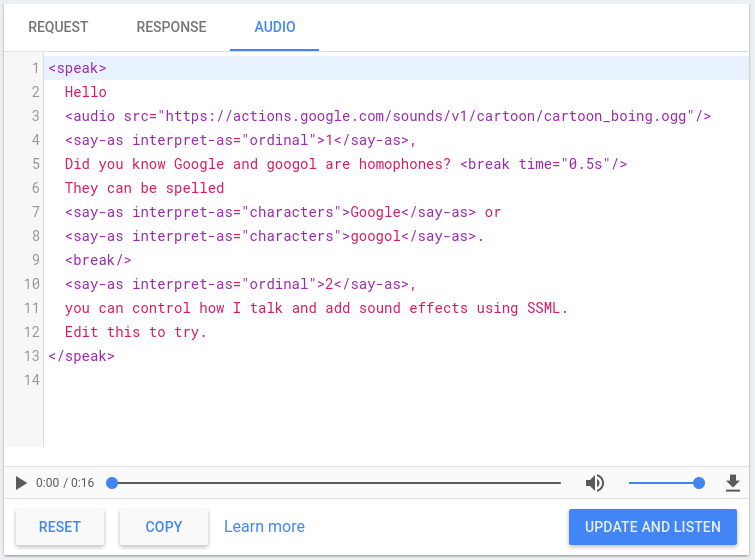
ダウンロード ボタンをクリックして、TTS の .mp3 ファイルを保存することもできます。
出力です。