
Google 어시스턴트에 응답을 반환할 때 응답의 음성 합성 마크업 언어 (SSML) 작성자: SSML을 사용하면 대화의 응답을 보다 자연스럽게 할 수 있습니다. 있습니다. 다음 예는 SSML 마크업 및 Google 어시스턴트:
Node.js
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.add(ssml); }
JSON
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
오디오
SSML의 URL
URL만 포함하는 SSML 응답을 정의할 때는 해당 URL의 앰퍼샌드가
XML 형식으로 인해 문제가 발생할 수 있습니다. URL이 제대로
&의 인스턴스를 &로 바꿉니다.
SSML 응답에 URL만 포함되어 있더라도 Actions on Google에
응답의 표시 텍스트를 지정합니다. <audio> 태그 내의 텍스트는
음성 안내가 포함된 경우
<audio> 태그가 있어야 이 요구사항을 충족할 수 있습니다. <audio> 태그 안의 텍스트는
Google의 Action on Google과 상호작용하여
을 준수해야 합니다.
다음은 문제가 있는 SSML 응답의 예입니다.
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
위의 예에서는 적절한 XML 형식 지정을 위해 &를 이스케이프 처리하지 않습니다.
동일한 SSML 응답의 수정된 버전은 다음과 같습니다.
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
SSML 요소 지원
다음 섹션에서는 작업에 사용할 수 있는 SSML 요소와 옵션을 설명합니다.
<speak>
SSML 응답의 루트 요소.
speak 요소에 대한 자세한 내용은 W3 사양을 참조하세요.
예
<speak> my SSML content </speak>
<break>
단어 사이의 끊어 읽기 또는 기타 운율적 경계를 제어하는 빈 요소. 토큰 쌍 간에 <break> 사용은 선택사항입니다. 이 요소가 단어 사이에 없으면 음성 중지는 언어적 맥락에 따라 자동으로 결정됩니다.
break 요소에 대한 자세한 내용은 W3 사양을 참조하세요.
속성
| 속성 | 설명 |
|---|---|
time |
초나 밀리초 단위로 음성 중지의 길이를 설정합니다(예: '3s' 또는 '250ms'). |
strength |
출력 음성의 운율적 중지의 강도를 상대적 용어로 설정합니다. 유효한 값은 'x-weak', 'weak', 'medium', 'strong', 'x-strong'입니다. 'none' 값은 운율적 중지 경계가 출력되어서는 안 됨을 나타내며, 설정된 값이 없을 경우 프로세서가 생성하는 운율적 중지를 방지하는 데 사용할 수 있습니다. 다른 값은 토큰 사이의 점증적인(단조 비감소) 중지 강도를 나타냅니다. 일반적으로 중지 경계가 뚜렷하면 끊어 읽기가 됩니다. |
예
다음 예시는 <break> 요소를 사용하여 단계간에 일시 중지하는 방법을 보여줍니다.
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
이 요소를 사용하면 요소 내에 포함 된 텍스트 구문 유형에 대한 정보를 나타낼 수 있습니다. 또한 포함된 텍스트 렌더링의 세부 수준을 지정하는 데도 도움이 됩니다.
<say‑as> 요소에는 값을 말하는 형식을 결정하는 필수 속성인 interpret-as가 있습니다. 특정 interpret-as 값에 따라 선택적 속성 인 format 및 detail을 사용할 수 있습니다.
예시
interpret-as 속성은 다음 값을 지원합니다.
-
currency다음 예시는 'forty two dollars and one cent'라고 말합니다. 언어 속성이 누락된 경우 현재 언어가 사용됩니다.
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> -
telephoneW3C SSML 1.0 say-as attribute values WG 메모에서
interpret-as='telephone'설명을 참조하세요.다음 예시는 '18002021212'로 말합니다. 'google:style' 속성이 생략된 경우 문자 O가 0으로 표시됩니다.
'google:style='zero-as-zero' 속성은 현재 EN 언어로만 작동합니다.
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak> -
verbatim또는spell-out다음 예는 한 글자씩 철자를 말합니다.
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak> -
dateformat속성은 일련의 날짜 필드 문자 코드입니다.format에서 지원되는 필드 문자 코드는 각각 연도, 월, 일에 해당하는 {y,m,d}입니다. 연도, 월, 일에 필드 코드가 한 번씩 표시될 경우 예상 자릿수는 각각 4자리, 2자리, 2자리입니다. 필드 코드가 반복될 경우 예상 자릿수는 코드의 반복 횟수입니다. 날짜 텍스트의 필드는 구두점 또는 공백으로 구분될 수 있습니다.detail속성은 날짜를 읽는 방식을 제어합니다.detail='1'의 경우 월이나 연도 필드 중 하나와 일 필드가 필수 항목이지만 월과 연도 필드 둘 다 입력해도 됩니다. 이는 3개 미만의 필드가 지정될 경우 기본값입니다. 말하는 형식은 '{몇 월}의 {며칠째 날}, {몇 년도}'(영어 기준)입니다.다음 예는 '9월의 열째 날, 1960년' 형식으로 말합니다.
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>다음 예는 '9월의 열째 날' 형식으로 말합니다.
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>detail='2'의 경우 일, 월, 연도 필드가 필요하며, 세 필드가 모두 입력된 경우 기본값에 해당합니다. 말하는 형식은 '{몇 월} {며칠째 날}, {몇 년도}'(영어 기준)입니다.다음 예는 '9월 열째 날, 1960년' 형식으로 말합니다.
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
characters다음 예는 한 글자씩 말합니다.
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinal다음 예시는 숫자를 기수 형식으로 말합니다.
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinal다음 예는 숫자를 서수 형식으로 말합니다.
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fraction다음 예는 숫자를 분수 형식으로 말합니다.
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletive또는bleep다음 예시는 텍스트가 검열된 것처럼 삐 소리가 납니다.
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unit숫자에 따라 단위를 단수 또는 복수로 변환합니다. 다음 예는 단수형 단위를 복수형으로 말합니다.
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
time다음 예는 '2시 30분 P.M.' 형식으로 말합니다.
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>format속성은 일련의 시간 필드 문자 코드입니다.format에서 지원되는 필드 문자 코드는 각각 시간, 분, 초, 시간대, 12시간제, 24시간제에 해당하는 {h,m,s,Z,12,24}입니다. 시간, 분, 초에 필드 코드가 한 번씩 표시될 경우 예상 자릿수는 각각 1자리, 2자리, 2자리입니다. 필드 코드가 반복될 경우 예상 자릿수는 코드의 반복 횟수입니다. 시간 텍스트의 필드는 구두점 또는 공백으로 구분될 수 있습니다. 시간, 분, 초가 이 형식으로 지정되지 않거나 일치하는 자릿수가 없을 경우 필드 값이 0으로 취급됩니다. 기본format은 'hms12'입니다.detail속성은 시간을 말하는 형식을 12시간제 또는 24시간제로 지정합니다.detail='1'또는detail이 누락되어 있고 시간 형식이 24시간인 경우 말하는 형식은 24시간제입니다.detail='2'또는detail이 누락되어 있고 시간 형식이 12시간인 경우 말하는 형식은 12시간제입니다.
say-as 요소에 대한 자세한 내용은 W3 사양을 참조하세요.
<audio>
합성된 음성 출력과 함께 녹음된 오디오 파일의 삽입과 기타 오디오 형식의 삽입을 지원합니다.
속성
| 속성 | 필수 | 기본값 | 값 |
|---|---|---|---|
src |
예 | 해당사항 없음 | 오디오 미디어 소스를 참조하는 URI. 지원되는 프로토콜은 https입니다. |
clipBegin |
아니요 | 0 | 재생 시작 지점을 결정하며, 오디오 소스의 시작 부분에 삽입되는 오프셋 값인 시간 지정. 이 값이 오디오 소스의 실제 지속 시간보다 크거나 같을 경우 오디오가 삽입되지 않습니다. |
clipEnd |
아니요 | 무한대 | 재생 종료 지점을 결정하며, 오디오 소스의 시작 부분에 삽입되는 오프셋 값인 시간 지정. 오디오 소스의 실제 지속 시간이 이 값보다 작으면 지정된 시간에 재생이 종료됩니다. clipBegin이 clipEnd보다 크거나 같으면 오디오가 삽입되지 않습니다. |
speed |
아니요 | 100% | 정상 입력 속도 대비 출력 재생 속도의 비율을 백분율로 표현한 값. 양의 실수 다음에 %가 오는 형식입니다. 현재 지원되는 범위는 [50%(저속 - 0.5배속), 200%(고속 - 2배속)]입니다. 이 범위를 벗어나는 값은 이 범위에 맞게 조정되거나 조정되지 않을 수 있습니다. |
repeatCount |
아니요 | repeatDur이 설정된 경우 1 또는 10 |
clipBegin 또는 clipEnd로 잘라낸 후 오디오를 삽입할 횟수를 지정하는 실수. 소수 반복은 지원되지 않으므로 가장 가까운 정수로 값이 반올림됩니다. 0은 유효한 값이 아니므로 지정되지 않은 것으로 취급되며 이 경우 기본값이 설정됩니다. |
repeatDur |
아니요 | 무한대 | 소스의 clipBegin, clipEnd, repeatCount, speed 속성이 처리된 후 삽입되는 오디오의 지속 시간(일반적인 재생 시간과 다름)을 제한하는 TimeDesignation. 처리된 오디오의 지속 시간이 이 값보다 작으면 지정된 시간에 재생이 종료됩니다. |
soundLevel |
아니요 | +0dB | soundLevel 데시벨을 사용하여 오디오의 사운드 레벨을 조정합니다. 최대 범위는 +/-40dB이지만 실제 범위는 실질적으로 더 작으며, 전체 범위에서 출력 품질이 좋지 않을 수 있습니다. |
다음은 현재 오디오에 지원되는 설정입니다.
- 형식: MP3(MPEG v2)
- 초당 24K 샘플
- 초당 24K~96K 비트, 고정 속도
- 형식: Ogg의 Opus
- 초당 24K 샘플(초광대역)
- 초당 24K~96K 비트, 고정 속도
- 형식(지원 중단됨): WAV(RIFF)
- PCM 16비트 부호 Little Endian
- 초당 24K 샘플
- 모든 형식에 해당:
- 단일 채널이 권장되지만 스테레오가 허용됩니다.
- 최대 지속 시간: 240초. 이보다 오랜 시간 동안 오디오를 재생하려면 미디어 응답을 구현하는 것이 좋습니다.
- 파일 크기 제한: 5MB
- 소스 URL은 HTTPS 프로토콜을 사용해야 합니다.
- 오디오를 가져올 때 UserAgent는 'Google-Speech-Actions'입니다.
<audio> 요소의 콘텐츠는 선택사항이며 오디오 파일을 재생할 수 없거나 출력 기기가 오디오를 지원하지 않는 경우에 사용됩니다. 내용에는 <desc> 요소가 포함될 수 있으며, 이 경우 해당 요소의 텍스트 내용이 화면에 표시됩니다. 자세한 내용은 응답 체크리스트의 녹음된 오디오 섹션을 참조하세요.
또한 src URL은 https URL이어야 합니다(Google Cloud Storage는 https URL의 오디오 파일을 호스팅할 수 있음).
미디어 응답을 자세히 알아보려면 응답 가이드의 미디어 응답 섹션을 참조하세요.
audio 요소에 대한 자세한 내용은 W3 사양을 참조하세요.
예
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
문장과 단락 요소입니다.
p 및 s 요소에 대한 자세한 내용은 W3 사양을 참조하세요.
예
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
권장사항
- 특히 prosody를 변경하는 SSML 요소가 포함된 경우 전체 문장을 래핑하려면 <s> ... </s> 태그를 사용합니다(예: <audio>, <break>, <emphasis>, <par>, <prosody>, <say-as>, <seq>, <sub>).
- 음성 내 구분을 들을 수 있도록 충분하게 길게 하려면 <s> ... </s> 태그를 사용하여 문장 사이에 줄 바꿈을 삽입합니다.
<sub>
alias 속성 값의 텍스트는 포함된 텍스트의 발음을 대체한다는 것을 나타냅니다.
sub 요소를 사용하여 읽기 어려운 단어의 쉬운 발음을 제공할 수도 있습니다. 마지막 예시는 이 사용 사례를 일본어 버전으로 설명합니다.
sub 요소에 대한 자세한 내용은 W3 사양을 참조하세요.
예시
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
텍스트 또는 태그 시퀀스에 마커를 배치하는 빈 요소입니다. 시퀀스의 특정 위치를 참조하거나 비동기 알림에 사용되는 출력 스트림에 마커를 삽입하는 데 사용할 수 있습니다.
mark 요소에 대한 자세한 내용은 W3 사양을 참조하세요.
예
<speak> Go from <mark name="here"/> here, to <mark name="there"/> there! </speak>
<prosody>
요소에 포함된 텍스트의 높낮이, 말하기 속도, 볼륨을 맞춤설정하는 데 사용됩니다. 현재 rate, pitch, volume 속성이 지원됩니다.
W3 사양에 따라 rate 및 volume 속성을 설정할 수 있습니다. pitch 속성 값을 설정하는 데 세 가지 옵션이 있습니다.
| 속성 | 설명 |
|---|---|
name |
각 표시의 문자열 ID입니다. |
| 옵션 | 설명 |
|---|---|
| 친척 | 상대 값(예: 'low', 'medium', 'high' 등)을 지정합니다. 여기서 'medium'은 기본 높낮이입니다. |
| 반음 | '+Nst' 또는 '-Nst'를 각각 사용하여 'N' 반음씩 높낮이를 올리거나 내립니다. '+/-' 및 'st'는 필수입니다. |
| 비율 | '+N%' 또는 '-N%'를 각각 사용하여 'N' 퍼센트씩 높낮이를 올리거나 내립니다. '%'는 필수이지만 '+/-'는 선택사항입니다. |
prosody 요소에 대한 자세한 내용은 W3 사양을 참조하세요.
예
다음 예시에서는 <prosody> 요소를 사용하여 정상보다 2반음 낮추어 느리게 말합니다.
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
요소에 포함된 텍스트에서 강세를 추가하거나 제거하는 데 사용됩니다. <emphasis> 요소는 <prosody>와 유사하게 음성을 수정하지만 개별 음성 속성을 설정할 필요가 없습니다.
이 요소는 다음의 유효한 값을 사용하여 선택적 'level' 속성을 지원합니다.
strongmoderatenonereduced
emphasis 요소에 대한 자세한 내용은 W3 사양을 참조하세요.
예
다음 예시에서는 <emphasis> 요소를 사용하여 공지합니다.
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
여러 미디어 요소를 한 번에 재생할 수 있게 해주는 병렬 미디어 컨테이너입니다. 유일하게 허용되는 콘텐츠는 <par>, <seq>, <media> 요소 한 개 이상으로 구성된 세트입니다. <media> 요소의 순서는 중요하지 않습니다.
하위 요소가 다른 시작 시간을 지정하지 않으면 요소의 암묵적 시작 시간은 <par> 컨테이너의 시작 시간과 동일합니다. 하위 요소의 begin 또는 end 속성에 설정된 오프셋 값이 있으면 요소의 오프셋은 <par> 컨테이너의 시작 시간을 기준으로 합니다. 루트 <par> 요소의 경우 begin 속성이 무시되며, 시작 시간은 SSML 음성 합성 프로세스에서 루트 <par> 요소(즉, 사실상 '0' 시간)의 출력 생성을 시작하는 시간입니다.
예
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak><seq>
미디어 요소를 하나씩 재생할 수 있게 해주는 순차적 미디어 컨테이너입니다. 유일하게 허용되는 콘텐츠는 <seq>, <par>, <media> 요소 한 개 이상으로 구성된 세트입니다. 미디어 요소의 순서는 렌더링되는 순서와 같습니다.
하위 요소의 begin 및 end 속성은 오프셋 값으로 설정될 수 있습니다(아래의 시간 사양 참조). 이러한 하위 요소의 오프셋 값은 시퀀스에서 이전 요소의 끝 지점을 기준으로 합니다. 시퀀스의 첫 번째 요소의 경우 <seq> 컨테이너의 시작 지점을 기준으로 합니다.
예
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media>
<par> 또는 <seq> 요소 내 미디어 레이어를 나타냅니다. <media> 요소에서 허용되는 콘텐츠는 SSML <speak> 또는 <audio> 요소입니다. 다음 표에서는 <media> 요소의 유효한 속성을 설명합니다.
속성
| 속성 | 필수 | 기본값 | 값 |
|---|---|---|---|
| xml:id | 아니요 | 값 없음 | 이 요소의 고유한 XML 식별자. 인코딩된 항목은 지원되지 않습니다. 허용되는 식별자 값은 정규 표현식 "([-_#]|\p{L}|\p{D})+"와 일치합니다. 자세한 내용은 XML-ID를 참조하세요. |
| begin | 아니요 | 0 | 이 미디어 컨테이너의 시작 시간. 루트 미디어 컨테이너 요소(기본값 '0'과 동일하게 취급됨)이면 무시됩니다. 유효한 문자열 값은 아래의 시간 사양 섹션을 참조하세요. |
| end | 아니요 | 값 없음 | 이 미디어 컨테이너의 종료 시간에 대한 사양. 유효한 문자열 값은 아래의 시간 사양 섹션을 참조하세요. |
| repeatCount | 아니요 | 1 | 미디어 삽입 횟수를 지정하는 실수. 소수 반복은 지원되지 않으므로 가장 가까운 정수로 값이 반올림됩니다. 0은 유효한 값이 아니므로 지정되지 않은 것으로 취급되며 이 경우 기본값이 설정됩니다. |
| repeatDur | 아니요 | 값 없음 | 삽입된 미디어의 지속 시간을 제한하는 시간 지정. 미디어의 지속 시간이 이 값보다 작으면 지정된 시간에 재생이 종료됩니다. |
| soundLevel | 아니요 | +0dB | soundLevel 데시벨을 사용하여 오디오의 사운드 레벨을 조정합니다. 최대 범위는 +/-40dB이지만 실제 범위는 실질적으로 더 작으며, 전체 범위에서 출력 품질이 좋지 않을 수 있습니다. |
| fadeInDur | 아니요 | 0초 | 미디어가 무음에서 시작해 선택적으로 지정된 soundLevel로 페이드 인하는 시간 지정. 미디어의 지속 시간이 이 값보다 작으면 재생 종료 시 페이드 인이 중지되고 사운드 레벨이 지정된 사운드 레벨에 도달하지 않습니다. |
| fadeOutDur | 아니요 | 0초 | 미디어가 선택적으로 지정된 soundLevel에서 시작해 무음이 될 때까지 페이드 아웃하는 시간 지정. 미디어의 지속 시간이 이 값보다 작으면 재생 종료 시 무음에 도달할 수 있도록 사운드 레벨이 더 낮은 값으로 설정됩니다. |
시간 사양
<media> 요소와 미디어 컨테이너(<par> 및 <seq> 요소)의 `begin`과 `end` 속성 값에 사용되는 시간 사양은 오프셋 값(예: +2.5s) 또는 syncbase 값(예: foo_id.end-250ms)입니다.
- 오프셋 값 - 시간 오프셋 값은 정규 표현식
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"와 일치하는 값을 허용하는 SMIL Timecount 값입니다.첫 번째 숫자 문자열은 십진수의 전체 부분이고 두 번째 숫자 문자열은 십진수의 소수 부분입니다. 기본 기호(예: '(+|-)?')는 '+'입니다. 단위 값은 각각 시, 분, 초, 밀리초에 해당합니다. 단위의 기본값은 's'(초)입니다.
- Syncbase 값 - syncbase 값은 정규 표현식
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"와 일치하는 값을 허용하는 SMIL syncbase 값입니다.숫자와 단위는 오프셋 값과 같은 방식으로 해석됩니다.
TTS 시뮬레이터
Actions 콘솔에는 SSML을 테스트하는 데 사용할 수 있는 TTS 시뮬레이터가 포함되어 있습니다. 위 요소 중 하나로 사용할 수 있습니다. 콘솔에서 TTS 시뮬레이터를 찾을 수 있습니다. 시뮬레이터 > 오디오를 선택합니다. 시뮬레이터에 텍스트와 SSML을 입력하고 업데이트 및 듣기: TTS 출력을 듣습니다.
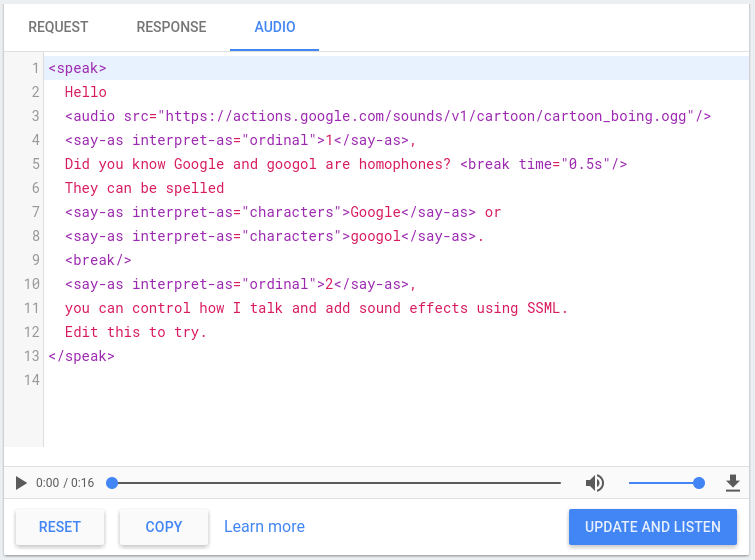
다운로드 버튼을 클릭하여 TTS의 .mp3 파일을 저장할 수도 있습니다.
출력됩니다.