
Khi trả lời câu trả lời cho Trợ lý Google, bạn có thể sử dụng một số thuộc tính Ngôn ngữ đánh dấu tổng hợp giọng nói (SSML) trong câu trả lời của bạn. Theo bằng SSML, bạn có thể làm cho câu trả lời của cuộc trò chuyện có vẻ tự nhiên hơn CANNOT TRANSLATE Ví dụ sau đây cho thấy mã đánh dấu SSML và âm thanh tương ứng từ Trợ lý Google:
Node.js
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.add(ssml); }
JSON
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
Âm thanh
URL trong SSML
Khi xác định phản hồi SSML chỉ bao gồm URL, ký hiệu "&" trong URL đó
có thể gây ra vấn đề do định dạng XML. Để đảm bảo URL được nhập đúng cách
được tham chiếu, hãy thay thế các bản sao của & bằng &.
Ngay cả khi phản hồi SSML của bạn chỉ bao gồm URL, Actions on Google vẫn yêu cầu
hiển thị văn bản cho câu trả lời. Vì văn bản bên trong thẻ <audio> sẽ không được
do Trợ lý nói, bạn có thể chèn văn bản bộ nạp hoặc một đoạn mô tả ngắn vào
Thẻ <audio> để đáp ứng yêu cầu này. Văn bản bên trong thẻ <audio> sẽ không được
được Trợ lý nói sau khi phát âm thanh và đáp ứng tính năng Hành động trên
phiên bản văn bản hiển thị của SSML.
Dưới đây là ví dụ về phản hồi SSML có vấn đề:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
Ví dụ trên không thoát & để định dạng XML thích hợp.
Phiên bản sửa lỗi của cùng một phản hồi SSML sẽ có dạng như sau:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
Hỗ trợ các phần tử SSML
Các phần sau đây mô tả các phần tử và tuỳ chọn SSML có thể dùng trong Hành động của bạn.
<speak>
Phần tử gốc của phản hồi SSML.
Để tìm hiểu thêm về phần tử speak, hãy xem thông số kỹ thuật của W3.
Ví dụ:
<speak> my SSML content </speak>
<break>
Một phần tử trống kiểm soát việc tạm dừng hoặc những ranh giới tạm thời khác giữa các từ. Bạn không bắt buộc phải sử dụng <break> giữa các cặp mã thông báo bất kỳ. Nếu không có yếu tố này giữa các từ, dấu ngắt sẽ được tự động xác định dựa trên ngữ cảnh ngôn ngữ.
Để tìm hiểu thêm về phần tử break, hãy xem thông số kỹ thuật của W3.
Thuộc tính
| Thuộc tính | Mô tả |
|---|---|
time |
Đặt thời lượng của điểm chèn theo giây hoặc mili giây (ví dụ: "3 giây" hoặc "250 mili giây"). |
strength |
Đặt độ mạnh của điểm chèn giả tạo của đầu ra theo các điều kiện tương đối. Các giá trị hợp lệ là: "x-yếu", "yếu", "trung bình", "mạnh" và "x-strong". Giá trị "không có" chỉ ra rằng không nên đưa ra ranh giới phá vỡ hữu hình. Giới hạn này có thể được dùng để ngăn chặn sự phá vỡ hữu hình mà bộ xử lý sẽ tạo ra. Các giá trị khác cho biết độ mạnh giữa các mã thông báo không giảm (tăng theo khái niệm). Những ranh giới mạnh mẽ hơn thường đi kèm với những khoảng lặng. |
Ví dụ:
Ví dụ sau đây cho thấy cách sử dụng phần tử <break> để tạm dừng giữa các bước:
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
Phần tử này cho phép bạn cho biết thông tin về kiểu cấu trúc văn bản có trong phần tử. Lớp này cũng giúp chỉ định mức độ chi tiết để hiển thị văn bản bên trong.
Phần tử <say‑as> có thuộc tính bắt buộc là interpret-as. Thuộc tính này sẽ xác định cách đọc giá trị. Bạn có thể sử dụng các thuộc tính không bắt buộc format và detail tuỳ thuộc vào giá trị interpret-as cụ thể.
Ví dụ
Thuộc tính interpret-as hỗ trợ các giá trị sau:
-
currencyVí dụ sau được đọc là "bốn mươi hai đô la và một xu". Nếu thuộc tính ngôn ngữ bị bỏ qua, thuộc tính này sẽ sử dụng ngôn ngữ hiện tại.
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> -
telephoneXem
interpret-as='telephone'phần mô tả trong ghi chú W3C SSML 1.0 nói-as thuộc tính WG.Ví dụ sau đây được nói là "một tám không không hai không hai một hai một hai". Nếu "google:style" bị bỏ qua, vì thuộc tính này viết bằng 0 giống như chữ O.
"google:style='zero-as-zero'" hiện chỉ hoạt động bằng ngôn ngữ tiếng Anh.
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak> -
verbatimhoặcspell-outVí dụ sau đây được viết theo từng chữ cái:
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak> -
dateThuộc tính
formatlà một chuỗi mã ký tự của trường ngày. Mã ký tự trường được hỗ trợ trongformatlần lượt là {y,m,d} cho năm, tháng và ngày (trong tháng). Nếu mã trường xuất hiện một lần cho năm, tháng hoặc ngày thì số chữ số cần có lần lượt là 4, 2 và 2. Nếu mã trường bị lặp lại thì số chữ số cần thiết là số lần mã lặp lại. Các trường trong văn bản ngày có thể được phân tách bằng dấu chấm câu và/hoặc dấu cách.Thuộc tính
detailkiểm soát cách nói của ngày đó. Đối vớidetail='1', bạn chỉ phải cung cấp trường ngày và một trường tháng hoặc năm, mặc dù bạn có thể cung cấp cả hai trường. Đây là chế độ mặc định khi có ít hơn cả 3 trường. Biểu mẫu được nói là "Ngày {ordinal day}/{month}, {year}".Ví dụ sau đây được đọc là "Ngày 10 tháng 9 năm 1960":
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>Ví dụ sau đây được đọc là "Ngày 10 tháng 9":
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>Đối với
detail='2', các trường ngày, tháng và năm là bắt buộc. Đây là trường mặc định khi cả 3 trường đều được cung cấp. Biểu mẫu được nói là "{month} {ordinal day}, {year}".Ví dụ sau đây được đọc là "ngày 10 tháng 9, ngày 1960":
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
charactersVí dụ sau đây được đọc là "C A N":
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalVí dụ sau đây được đọc là "Mười hai nghìn ba trăm bốn mươi năm" (đối với tiếng Anh (Mỹ)) hoặc "Mười hai nghìn ba trăm bốn mươi năm (đối với tiếng Anh Anh)":
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinalVí dụ sau được đọc là "Đầu tiên":
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fractionVí dụ sau được đọc là "năm và 5":
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletivehoặcbleepVí dụ sau xuất hiện dưới dạng tiếng bíp, như thể nó đã được che đi:
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unitChuyển đổi đơn vị thành số ít hoặc số nhiều tuỳ thuộc vào số. Ví dụ sau được đọc là "10 feet":
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
timeVí dụ sau được đọc là "Hai ba mươi P.M.":
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>Thuộc tính
formatlà một chuỗi mã ký tự trường thời gian. Mã ký tự trường được hỗ trợ trongformatlần lượt là {h,m,s,Z,12,24} cho giờ, phút (trong giờ), giây (trong số phút), múi giờ, thời gian 12 giờ và 24 giờ. Nếu mã trường xuất hiện một lần cho giờ, phút hoặc giây thì số chữ số cần có lần lượt là 1, 2 và 2. Nếu mã trường bị lặp lại thì số chữ số cần thiết là số lần mã lặp lại. Các trường trong văn bản thời gian có thể được phân tách bằng dấu chấm câu và/hoặc dấu cách. Nếu giờ, phút hoặc giây không được chỉ định ở định dạng hoặc không có chữ số nào khớp, thì trường này được xem là giá trị bằng 0.formatmặc định là "hms12".Thuộc tính
detailkiểm soát việc dạng đọc của thời gian là thời gian 12 giờ hay 24 giờ. Biểu mẫu được nói sẽ có thời gian 24 giờ nếudetail='1'hoặc nếudetailbị bỏ qua và định dạng thời gian là thời gian 24 giờ. Biểu mẫu được nói sẽ có thời gian 12 giờ nếudetail='2'hoặc nếudetailbị bỏ qua và định dạng thời gian là thời gian 12 giờ.
Để tìm hiểu thêm về phần tử say-as, hãy xem thông số kỹ thuật của W3.
<audio>
Hỗ trợ chèn các tệp âm thanh đã ghi và chèn các định dạng âm thanh khác cùng với đầu ra giọng nói tổng hợp.
Thuộc tính
| Thuộc tính | Bắt buộc | Mặc định | Giá trị |
|---|---|---|---|
src |
có | không áp dụng | URI tham chiếu đến nguồn nội dung nghe nhìn dạng âm thanh. Giao thức được hỗ trợ là https. |
clipBegin |
không | 0 | TimeDesignation (Thiết kế thời gian) là giá trị bù trừ từ thời điểm nguồn âm thanh bắt đầu phát. Nếu giá trị này lớn hơn hoặc bằng thời lượng thực tế của nguồn âm thanh, thì sẽ không có âm thanh nào được chèn. |
clipEnd |
không | vô hạn | TimeDesignation (Thiết kế thời gian) là giá trị bù trừ từ thời điểm bắt đầu phát đến lúc kết thúc của nguồn âm thanh. Nếu thời lượng thực tế của nguồn âm thanh nhỏ hơn giá trị này thì quá trình phát sẽ kết thúc tại thời điểm đó. Nếu clipBegin lớn hơn hoặc bằng clipEnd thì sẽ không có âm thanh nào được chèn. |
speed |
không | 100% | Tỷ lệ tốc độ phát đầu ra so với tốc độ đầu vào bình thường, biểu thị dưới dạng phần trăm. Định dạng là Số thực dương, theo sau là %. Phạm vi hiện được hỗ trợ là [50% (chậm - một nửa tốc độ), 200% (nhanh - gấp đôi)]. Các giá trị nằm ngoài phạm vi đó có thể (hoặc có thể không) được điều chỉnh để nằm trong phạm vi đó. |
repeatCount |
không | 1 hoặc 10 nếu bạn đặt repeatDur |
Số thực xác định số lần chèn âm thanh vào (sau khi cắt, nếu có, bằng clipBegin và/hoặc clipEnd). Không hỗ trợ lặp lại phân số, vì vậy, giá trị sẽ được làm tròn thành số nguyên gần nhất. 0 không phải là một giá trị hợp lệ và do đó được coi là không được chỉ định và có giá trị mặc định trong trường hợp đó. |
repeatDur |
không | vô hạn | TimeDesignation (Thiết kế thời gian) là giới hạn về thời lượng của âm thanh được chèn sau khi nguồn được xử lý cho các thuộc tính clipBegin, clipEnd, repeatCount và speed (thay vì thời lượng phát thông thường). Nếu thời lượng của âm thanh được xử lý nhỏ hơn giá trị này thì quá trình phát sẽ kết thúc tại thời điểm đó. |
soundLevel |
không | 0 dB | Điều chỉnh mức âm thanh bằng soundLeveldecibel. Phạm vi tối đa là +/-40 dB nhưng phạm vi thực tế có thể kém hiệu quả hơn và chất lượng đầu ra có thể không mang lại kết quả tốt trên toàn bộ phạm vi. |
Sau đây là các chế độ cài đặt hiện được hỗ trợ cho âm thanh:
- Định dạng: MP3 (MPEG v2)
- 24 nghìn mẫu mỗi giây
- 24K ~ 96K bit/giây, tốc độ cố định
- Định dạng: Opus in Ogg
- 24 nghìn mẫu mỗi giây (băng tần siêu rộng)
- 24K – 96K bit/giây, tốc độ cố định
- Định dạng (không dùng nữa): WAV (RIFF)
- PCM 16-bit đã ký, endian nhỏ
- 24 nghìn mẫu mỗi giây
- Đối với mọi định dạng:
- Bạn nên ưu tiên một kênh nhưng âm thanh nổi cũng được chấp nhận.
- Thời lượng tối đa 240 giây. Nếu bạn muốn phát âm thanh có thời lượng dài hơn, hãy cân nhắc triển khai tính năng phản hồi nội dung nghe nhìn.
- Giới hạn kích thước tệp 5 megabyte.
- URL nguồn phải sử dụng giao thức HTTPS.
- Tác nhân người dùng của chúng tôi khi tìm nạp âm thanh là "Google-speech-Actions".
Nội dung của phần tử <audio> là không bắt buộc và được sử dụng nếu không thể phát tệp âm thanh hoặc nếu thiết bị đầu ra không hỗ trợ âm thanh. Nội dung có thể bao gồm phần tử <desc>. Trong trường hợp đó, nội dung văn bản của phần tử đó sẽ được dùng để hiển thị. Để biết thêm thông tin, hãy xem phần Âm thanh đã ghi trong Danh sách kiểm tra cho câu trả lời.
URL src cũng phải là một URL https (Google Cloud Storage có thể lưu trữ các tệp âm thanh của bạn trên một URL https).
Để tìm hiểu thêm về phản hồi của nội dung nghe nhìn, hãy xem phần phản hồi của nội dung nghe nhìn trong hướng dẫn về Nội dung phản hồi.
Để tìm hiểu thêm về phần tử audio, hãy xem thông số kỹ thuật của W3.
Ví dụ:
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
Thành phần câu và đoạn.
Để tìm hiểu thêm về các phần tử p và s, hãy xem thông số kỹ thuật của W3.
Ví dụ:
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
Các phương pháp hay nhất
- Sử dụng <s>...</s> các thẻ để gói câu đầy đủ, đặc biệt nếu chúng chứa các phần tử SSML thay đổi âm thanh (ví dụ: <audio>, <break>, <emphasis>, <par>, <prosody>, <say-as>, <seq> và <sub>).
- Nếu bạn dự định ngắt đoạn giọng nói đủ dài để bạn có thể nghe được, hãy sử dụng <s>...</s> thẻ và đặt điểm ngắt giữa các câu.
<sub>
Cho biết rằng văn bản trong giá trị thuộc tính bí danh sẽ thay thế văn bản chứa trong cách phát âm.
Bạn cũng có thể sử dụng phần tử sub để cung cấp cách phát âm đơn giản của một từ khó đọc. Ví dụ cuối cùng bên dưới minh hoạ trường hợp sử dụng này bằng tiếng Nhật.
Để tìm hiểu thêm về phần tử sub, hãy xem thông số kỹ thuật của W3.
Ví dụ
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
Phần tử trống đặt điểm đánh dấu vào trình tự văn bản hoặc thẻ. Bạn có thể dùng hàm này để tham chiếu vị trí cụ thể trong trình tự hoặc để chèn điểm đánh dấu vào luồng đầu ra đối với thông báo không đồng bộ.
Để tìm hiểu thêm về phần tử mark, hãy xem thông số kỹ thuật của W3.
Ví dụ:
<speak> Go from <mark name="here"/> here, to <mark name="there"/> there! </speak>
<prosody>
Dùng để tuỳ chỉnh cao độ, tốc độ nói và âm lượng của văn bản có trong phần tử. Hiện tại, các thuộc tính rate, pitch và volume được hỗ trợ.
Bạn có thể thiết lập thuộc tính rate và volume theo thông số kỹ thuật W3. Có 3 cách để thiết lập giá trị của thuộc tính pitch:
| Thuộc tính | Mô tả |
|---|---|
name |
Mã nhận dạng chuỗi của từng nhãn. |
| Phương thức | Mô tả |
|---|---|
| Họ hàng | Chỉ định giá trị tương đối (ví dụ: "thấp", "trung bình", "cao", v.v.) trong đó "trung bình" là cao độ mặc định. |
| Nửa cung | Tăng hoặc giảm độ cao theo "N" nửa cung sử dụng "+N" hoặc "-N" . Lưu ý rằng "+/-" và "st" là trường bắt buộc. |
| Phần trăm | Tăng hoặc giảm độ cao theo "N" phần trăm bằng cách sử dụng "+N%" hoặc "-N%" . Lưu ý rằng "%" là bắt buộc nhưng "+/-" là tuỳ chọn. |
Để tìm hiểu thêm về phần tử prosody, hãy xem thông số kỹ thuật của W3.
Ví dụ:
Ví dụ sau đây sử dụng phần tử <prosody> để nói chậm ở 2 nửa cung thấp hơn bình thường:
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
Dùng để thêm hoặc xoá điểm nổi bật khỏi văn bản có trong phần tử. Phần tử <emphasis> sửa đổi lời nói tương tự như <prosody>, nhưng không cần phải đặt từng thuộc tính lời nói.
Phần tử này hỗ trợ "cấp" tuỳ chọn bằng các giá trị hợp lệ sau đây:
strongmoderatenonereduced
Để tìm hiểu thêm về phần tử emphasis, hãy xem thông số kỹ thuật của W3.
Ví dụ:
Ví dụ sau đây sử dụng phần tử <emphasis> để tạo thông báo:
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
Một vùng chứa nội dung nghe nhìn song song cho phép bạn phát nhiều phần tử nội dung nghe nhìn cùng một lúc. Nội dung duy nhất được phép là một tập hợp gồm một hoặc nhiều phần tử <par>, <seq> và <media>. Thứ tự của các phần tử <media> là không đáng kể.
Trừ phi phần tử con chỉ định thời gian bắt đầu khác, thời gian bắt đầu ngầm định của phần tử đó sẽ giống với thời gian bắt đầu của vùng chứa <par>. Nếu một phần tử con có giá trị chênh lệch được đặt cho thuộc tính begin (bắt đầu) hoặc end (kết thúc), thì độ lệch của phần tử con này sẽ tương ứng với thời điểm bắt đầu của vùng chứa <par>. Đối với phần tử <par> gốc, thuộc tính bắt đầu sẽ bị bỏ qua và thời điểm bắt đầu là khi quá trình tổng hợp giọng nói SSML bắt đầu tạo đầu ra cho phần tử <par> gốc (tức là thời gian thực tế là "không").
Ví dụ:
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak><seq>
Một vùng chứa nội dung nghe nhìn tuần tự cho phép bạn phát lần lượt các phần tử nội dung nghe nhìn. Nội dung duy nhất được phép là một tập hợp gồm một hoặc nhiều phần tử <seq>, <par> và <media>. Thứ tự của các phần tử nội dung đa phương tiện là thứ tự hiển thị của các phần tử đó.
Bạn có thể đặt thuộc tính begin và end của các phần tử con để bù trừ giá trị (xem phần Thông số kỹ thuật thời gian ở bên dưới). Các phần tử con đó các giá trị chênh lệch sẽ tương ứng với điểm kết thúc của phần tử trước đó trong trình tự hoặc so với điểm bắt đầu vùng chứa <seq> của phần tử đầu tiên trong trình tự.
Ví dụ:
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media>
Đại diện cho một lớp nội dung nghe nhìn trong phần tử <par> hoặc <seq>. Nội dung được phép của phần tử <media> là phần tử SSML <speak> hoặc <audio>. Bảng sau đây mô tả các thuộc tính hợp lệ cho một phần tử <media>.
Thuộc tính
| Thuộc tính | Bắt buộc | Mặc định | Giá trị |
|---|---|---|---|
| xml:id | không | không có giá trị | Giá trị nhận dạng XML duy nhất cho phần tử này. Không hỗ trợ thực thể đã mã hoá. Các giá trị nhận dạng được phép khớp với biểu thức chính quy "([-_#]|\p{L}|\p{D})+". Xem phần XML-ID để biết thêm thông tin. |
| bắt đầu | không | 0 | Thời gian bắt đầu của vùng chứa nội dung nghe nhìn này. Bỏ qua nếu đây là phần tử vùng chứa phương tiện gốc (được xử lý giống như giá trị mặc định là "0"). Xem phần Đặc tả thời gian bên dưới để biết các giá trị chuỗi hợp lệ. |
| kết thúc | không | không có giá trị | Thông số kỹ thuật về thời gian kết thúc cho vùng chứa nội dung nghe nhìn này. Xem phần Đặc tả thời gian bên dưới để biết các giá trị chuỗi hợp lệ. |
| repeatCount | không | 1 | Số thực xác định số lần chèn nội dung nghe nhìn. Không hỗ trợ lặp lại phân số, vì vậy, giá trị sẽ được làm tròn thành số nguyên gần nhất. 0 không phải là một giá trị hợp lệ và do đó được coi là không được chỉ định và có giá trị mặc định trong trường hợp đó. |
| repeatDur | không | không có giá trị | TimeDesignation (Thiết kế thời gian) cho biết thời lượng của nội dung nghe nhìn được chèn. Nếu thời lượng của nội dung nghe nhìn nhỏ hơn giá trị này thì quá trình phát sẽ kết thúc tại thời điểm đó. |
| soundLevel | không | 0 dB | Điều chỉnh mức âm thanh của âm thanh theo soundLevel đexiben. Phạm vi tối đa là +/-40 dB nhưng phạm vi thực tế có thể kém hiệu quả hơn và chất lượng đầu ra có thể không mang lại kết quả tốt trên toàn bộ phạm vi. |
| fadeInDur | không | 0 giây | Một TimeDesignation (Thiết kế thời gian) mà theo đó nội dung nghe nhìn sẽ mờ dần từ im lặng sang soundLevel được chỉ định tuỳ ý. Nếu thời lượng của nội dung nghe nhìn nhỏ hơn giá trị này, thì hiệu ứng rõ dần sẽ dừng khi kết thúc quá trình phát và mức âm thanh sẽ không đạt được mức âm thanh đã chỉ định. |
| fadeOutDur | không | 0 giây | TimeDesignation (Thiết kế thời gian) mà theo đó nội dung đa phương tiện sẽ mờ dần từ soundLevel được chỉ định tuỳ ý cho đến khi không có tiếng. Nếu thời lượng của nội dung nghe nhìn nhỏ hơn giá trị này, thì mức âm thanh được đặt thành giá trị thấp hơn để đảm bảo đạt được khoảng lặng khi kết thúc quá trình phát. |
Thông số thời gian
Thông số thời gian, dùng cho giá trị của thuộc tính "begin" (bắt đầu) và "end" (kết thúc) của các phần tử <media> và vùng chứa nội dung đa phương tiện (phần tử <par> và <seq>), có thể là giá trị bù trừ (ví dụ: +2.5s) hoặc giá trị Syncbase (ví dụ: foo_id.end-250ms).
- Giá trị chênh lệch – Giá trị bù thời gian là một giá trị đếm thời gian SMIL cho phép các giá trị khớp với biểu thức chính quy:
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Chuỗi chữ số đầu tiên là phần nguyên của số thập phân và chuỗi chữ số thứ hai là phần thập phân. Dấu mặc định (tức là "(+|-)?") là "+". Giá trị đơn vị tương ứng với giờ, phút, giây và mili giây tương ứng. Giá trị mặc định cho đơn vị là "s" (giây).
- Giá trị cơ sở dữ liệu đồng bộ – Giá trị cơ sở đồng bộ là một giá trị cơ sở đồng bộ SMIL cho phép các giá trị khớp với biểu thức chính quy:
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Các chữ số và đơn vị được diễn giải theo cách tương tự như giá trị bù trừ.
Trình mô phỏng TTS
Bảng điều khiển Actions có một trình mô phỏng TTS mà bạn có thể dùng để kiểm thử SSML với bất kỳ yếu tố nào ở trên. Bạn có thể tìm thấy trình mô phỏng TTS trong bảng điều khiển trong Trình mô phỏng > Âm thanh. Nhập văn bản và SSML vào trình mô phỏng rồi nhấp vào Cập nhật và nghe để nghe kết quả TTS.
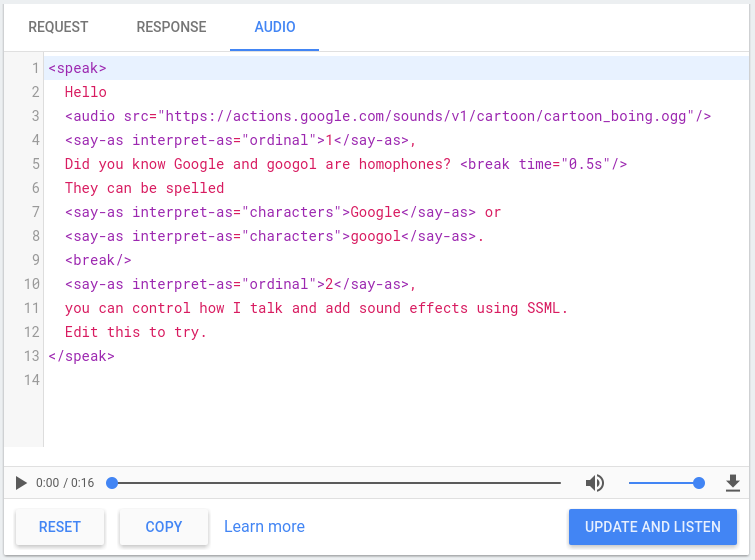
Bạn cũng có thể nhấp vào nút tải xuống để lưu tệp .mp3 của TTS
đầu ra.