
Google অ্যাসিস্ট্যান্টকে একটি প্রতিক্রিয়া ফেরত দেওয়ার সময়, আপনি আপনার প্রতিক্রিয়াগুলিতে স্পিচ সিন্থেসিস মার্কআপ ল্যাঙ্গুয়েজ ( SSML ) এর একটি উপসেট ব্যবহার করতে পারেন। SSML ব্যবহার করে, আপনি আপনার কথোপকথনের প্রতিক্রিয়াগুলিকে স্বাভাবিক বক্তৃতার মতো মনে করতে পারেন। নিম্নলিখিত উদাহরণটি SSML মার্কআপ এবং Google সহকারী থেকে সংশ্লিষ্ট অডিও দেখায়:
Node.js
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.add(ssml); }
JSON
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
অডিও
SSML-এ URL
শুধুমাত্র একটি URL অন্তর্ভুক্ত করে এমন একটি SSML প্রতিক্রিয়া সংজ্ঞায়িত করার সময়, সেই URL-এর অ্যাম্পারস্যান্ডগুলি XML ফর্ম্যাটিংয়ের কারণে সমস্যা সৃষ্টি করতে পারে। URLটি সঠিকভাবে উল্লেখ করা হয়েছে তা নিশ্চিত করতে, & এর সাথে & .
এমনকি আপনার SSML প্রতিক্রিয়াতে শুধুমাত্র একটি URL অন্তর্ভুক্ত থাকলেও, অ্যাকশন অন Google-এর প্রতিক্রিয়ার জন্য প্রদর্শনের পাঠ্য প্রয়োজন। যেহেতু <audio> ট্যাগের ভিতরের টেক্সট অ্যাসিস্ট্যান্ট দ্বারা বলা হবে না, তাই এই প্রয়োজনীয়তা পূরণ করতে আপনি আপনার <audio> ট্যাগে ফিলার টেক্সট বা একটি ছোট বিবরণ যোগ করতে পারেন। <audio> ট্যাগের ভিতরের টেক্সট অডিও চালানোর পর অ্যাসিস্ট্যান্টের দ্বারা কথা বলা হবে না এবং আপনার SSML-এর ডিসপ্লে টেক্সট ভার্সনের জন্য Google-এর প্রয়োজনীয়তা পূরণ করে।
এখানে একটি সমস্যাযুক্ত SSML প্রতিক্রিয়ার একটি উদাহরণ:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
উপরের উদাহরণটি সঠিক XML বিন্যাসের জন্য & এড়াতে পারে না।
একই SSML প্রতিক্রিয়ার একটি স্থির সংস্করণ এইরকম দেখায়:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
SSML উপাদানগুলির জন্য সমর্থন
নিম্নলিখিত বিভাগগুলি আপনার অ্যাকশনগুলিতে ব্যবহার করা যেতে পারে এমন SSML উপাদান এবং বিকল্পগুলি বর্ণনা করে৷
<speak>
SSML প্রতিক্রিয়ার মূল উপাদান।
speak উপাদান সম্পর্কে আরও জানতে, W3 স্পেসিফিকেশন দেখুন।
উদাহরণ
<speak> my SSML content </speak>
<break>
একটি খালি উপাদান যা শব্দের মধ্যে বিরতি বা অন্যান্য প্রসোডিক সীমানা নিয়ন্ত্রণ করে। যেকোনো জোড়া টোকেনের মধ্যে <break> ব্যবহার করা ঐচ্ছিক। যদি এই উপাদানটি শব্দগুলির মধ্যে উপস্থিত না থাকে, তবে বিরতিটি ভাষাগত প্রেক্ষাপটের উপর ভিত্তি করে স্বয়ংক্রিয়ভাবে নির্ধারিত হয়।
break উপাদান সম্পর্কে আরও জানতে, W3 স্পেসিফিকেশন দেখুন।
গুণাবলী
| বৈশিষ্ট্য | বর্ণনা |
|---|---|
time | বিরতির দৈর্ঘ্য সেকেন্ড বা মিলিসেকেন্ড দ্বারা সেট করে (যেমন "3s" বা "250ms")। |
strength | আপেক্ষিক পদ দ্বারা আউটপুটের প্রসোডিক বিরতির শক্তি সেট করে। বৈধ মানগুলি হল: "x-দুর্বল", দুর্বল", "মাঝারি", "শক্তিশালী", এবং "x-শক্তিশালী"। মান "কিছুই নয়" নির্দেশ করে যে কোনো প্রসোডিক বিরতি সীমানা আউটপুট করা উচিত নয়, যা একটি প্রতিরোধ করতে ব্যবহার করা যেতে পারে। প্রসোডিক ব্রেক যা অন্যথায় প্রসেসর তৈরি করবে তা একঘেয়েভাবে হ্রাস না হওয়া (ধারণাগতভাবে বৃদ্ধি) টোকেনগুলির মধ্যে শক্তিশালী সীমানাগুলি সাধারণত বিরতির সাথে থাকে। |
উদাহরণ
নিম্নলিখিত উদাহরণটি দেখায় কিভাবে ধাপগুলির মধ্যে বিরতি দেওয়ার জন্য <break> উপাদানটি ব্যবহার করতে হয়:
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
এই উপাদানটি আপনাকে উপাদানের মধ্যে থাকা পাঠ্য নির্মাণের ধরণ সম্পর্কে তথ্য নির্দেশ করতে দেয়। এটি অন্তর্ভুক্ত পাঠ্য রেন্ডার করার জন্য বিশদ স্তর নির্দিষ্ট করতে সহায়তা করে।
<say‑as> উপাদানটির প্রয়োজনীয় বৈশিষ্ট্য রয়েছে, interpret-as , যা নির্ধারণ করে যে মানটি কীভাবে উচ্চারিত হয়। ঐচ্ছিক গুণাবলী format এবং detail ব্যবহার করা যেতে পারে বিশেষ interpret-as মূল্যের উপর নির্ভর করে।
উদাহরণ
interpret-as বৈশিষ্ট্য নিম্নলিখিত মানগুলিকে সমর্থন করে:
-
currencyনিচের উদাহরণটিকে "দুয়াল্লিশ ডলার এবং এক সেন্ট" হিসাবে বলা হয়। ভাষা বৈশিষ্ট্য বাদ দেওয়া হলে, এটি বর্তমান লোকেল ব্যবহার করে।
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> telephoneW3C SSML 1.0 বলে-এ অ্যাট্রিবিউট মান WG নোটে
interpret-as='telephone'বিবরণ দেখুন।নিম্নলিখিত উদাহরণটি "এক আট শূন্য শূন্য দুই শূন্য দুই এক দুই এক দুই" হিসাবে বলা হয়েছে। যদি "google:style" অ্যাট্রিবিউটটি বাদ দেওয়া হয়, তাহলে এটি অক্ষর O হিসাবে শূন্য বলে।
"google:style='zero-as-zero'" বৈশিষ্ট্যটি বর্তমানে শুধুমাত্র EN লোকেলে কাজ করে।
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak>verbatimorspell-outনিম্নলিখিত উদাহরণটি অক্ষরে অক্ষরে বানান করা হয়েছে:
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak>-
dateformatবৈশিষ্ট্য হল তারিখ ক্ষেত্রের অক্ষর কোডগুলির একটি ক্রম।formatসমর্থিত ক্ষেত্রের অক্ষর কোডগুলি যথাক্রমে বছর, মাস এবং দিনের (মাসের) জন্য {y,m,d}। যদি ফিল্ড কোডটি বছর, মাস বা দিনের জন্য একবার প্রদর্শিত হয় তবে প্রত্যাশিত সংখ্যার সংখ্যা যথাক্রমে 4, 2 এবং 2। যদি ফিল্ড কোডটি পুনরাবৃত্তি করা হয় তবে প্রত্যাশিত সংখ্যার সংখ্যাটি কোডটি পুনরাবৃত্তি করার সংখ্যা। তারিখ পাঠ্যের ক্ষেত্রগুলি বিরাম চিহ্ন এবং/অথবা স্পেস দ্বারা পৃথক করা যেতে পারে।detailবৈশিষ্ট্য তারিখের কথ্য ফর্ম নিয়ন্ত্রণ করে।detail='1'শুধুমাত্র দিনের ক্ষেত্র এবং মাস বা বছরের একটি ক্ষেত্র প্রয়োজন, যদিও উভয়ই সরবরাহ করা যেতে পারে। এটি ডিফল্ট যখন তিনটি ক্ষেত্রের কম দেওয়া হয়। কথ্য ফর্ম হল "{মাস}, {বছর} এর {অর্ডিনাল দিন}"।নিম্নলিখিত উদাহরণটি "সেপ্টেম্বরের দশম, উনিশ ষাট" হিসাবে বলা হয়েছে:
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>নিম্নলিখিত উদাহরণটি "সেপ্টেম্বরের দশম" হিসাবে বলা হয়েছে:
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>detail='2'দিন, মাস এবং বছরের ক্ষেত্র প্রয়োজন এবং এটিই ডিফল্ট যখন তিনটি ক্ষেত্র সরবরাহ করা হয়। কথ্য ফর্ম হল "{মাস} {সাধারণ দিন}, {বছর}"।নিম্নলিখিত উদাহরণটি "সেপ্টেম্বর দশম, উনিশ ষাট" হিসাবে বলা হয়েছে:
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
charactersনিম্নলিখিত উদাহরণটি "CAN" হিসাবে বলা হয়:
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalনিম্নোক্ত উদাহরণটি "বারো হাজার তিনশত পঁয়তাল্লিশ" (ইউএস ইংরেজির জন্য) বা "বারো হাজার তিনশত পঁয়তাল্লিশ (ইউকে ইংরেজির জন্য)" হিসেবে বলা হয়:
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinalনিম্নলিখিত উদাহরণটিকে "প্রথম" হিসাবে বলা হয়:
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fractionনিম্নলিখিত উদাহরণটিকে "সাড়ে পাঁচ" হিসাবে বলা হয়:
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletiveবাbleepনিম্নলিখিত উদাহরণটি একটি বীপ হিসাবে বেরিয়ে আসে, যেন এটি সেন্সর করা হয়েছে:
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unitসংখ্যার উপর নির্ভর করে একককে একবচন বা বহুবচনে রূপান্তরিত করে। নিম্নলিখিত উদাহরণটি "10 ফুট" হিসাবে বলা হয়:
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
timeনিম্নলিখিত উদাহরণটি "টু থার্টি পিএম" হিসাবে বলা হয়েছে:
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>formatবৈশিষ্ট্য হল সময় ক্ষেত্রের অক্ষর কোডগুলির একটি ক্রম।formatসমর্থিত ফিল্ড ক্যারেক্টার কোডগুলি হল {h,m,s,Z,12,24} ঘন্টার জন্য, মিনিট (ঘন্টার), সেকেন্ড (মিনিটের), সময় অঞ্চল, 12-ঘন্টা সময় এবং 24-ঘন্টা সময় যথাক্রমে যদি ফিল্ড কোডটি ঘন্টা, মিনিট বা সেকেন্ডের জন্য একবার প্রদর্শিত হয় তবে প্রত্যাশিত সংখ্যার সংখ্যা যথাক্রমে 1, 2 এবং 2। যদি ফিল্ড কোডটি পুনরাবৃত্তি করা হয় তবে প্রত্যাশিত সংখ্যার সংখ্যাটি কোডটি পুনরাবৃত্তি করার সংখ্যা। সময়ের পাঠ্যের ক্ষেত্রগুলি বিরাম চিহ্ন এবং/অথবা স্পেস দ্বারা পৃথক করা যেতে পারে। যদি ঘন্টা, মিনিট বা সেকেন্ড বিন্যাসে নির্দিষ্ট করা না থাকে বা কোন মিলিত সংখ্যা না থাকে তাহলে ক্ষেত্রটিকে একটি শূন্য মান হিসাবে গণ্য করা হয়। ডিফল্টformatহল "hms12"।detailবৈশিষ্ট্য নিয়ন্ত্রণ করে যে সময়ের কথ্য ফর্মটি 12-ঘন্টা সময় বা 24-ঘন্টা সময়। কথ্য ফর্ম হল 24-ঘন্টা সময় যদিdetail='1'অথবা যদিdetailবাদ দেওয়া হয় এবং সময়ের বিন্যাস হয় 24-ঘন্টা সময়। কথ্য ফর্ম হল 12-ঘন্টা সময় যদিdetail='2'অথবা যদিdetailবাদ দেওয়া হয় এবং সময়ের বিন্যাস হল 12-ঘন্টা সময়।
say-as এলিমেন্ট সম্পর্কে আরও জানতে, W3 স্পেসিফিকেশন দেখুন।
<audio>
রেকর্ড করা অডিও ফাইলের সন্নিবেশ এবং সংশ্লেষিত বক্তৃতা আউটপুটের সাথে অন্যান্য অডিও বিন্যাস সন্নিবেশ সমর্থন করে।
গুণাবলী
| বৈশিষ্ট্য | প্রয়োজন | ডিফল্ট | মূল্যবোধ |
|---|---|---|---|
src | হ্যাঁ | n/a | একটি URI অডিও মিডিয়া উৎস উল্লেখ করে। সমর্থিত প্রোটোকল হল https । |
clipBegin | না | 0 | একটি TimeDesignation যা অডিও উৎস থেকে প্লেব্যাক শুরু থেকে অফসেট। যদি এই মানটি অডিও উৎসের প্রকৃত সময়কালের চেয়ে বেশি বা সমান হয়, তাহলে কোনো অডিও ঢোকানো হবে না। |
clipEnd | না | অনন্ত | একটি টাইমডিজাইনেশন যা অডিও উৎসের শুরু থেকে প্লেব্যাক শেষ পর্যন্ত অফসেট। যদি অডিও উৎসের প্রকৃত সময়কাল এই মানের থেকে কম হয়, তাহলে সেই সময়ে প্লেব্যাক শেষ হয়ে যায়। যদি clipBegin clipEnd এর থেকে বড় বা সমান হয়, তাহলে কোনো অডিও ঢোকানো হবে না। |
speed | না | 100% | একটি শতাংশ হিসাবে প্রকাশ করা স্বাভাবিক ইনপুট হারের তুলনায় অনুপাত আউটপুট প্লেব্যাক হার। বিন্যাসটি একটি ধনাত্মক বাস্তব সংখ্যা যার পরে %। বর্তমানে সমর্থিত পরিসর হল [50% (ধীর - অর্ধ গতি), 200% (দ্রুত - দ্বিগুণ গতি)]। সেই সীমার বাইরের মানগুলি এর মধ্যে থাকার জন্য সামঞ্জস্য করা যেতে পারে (বা নাও হতে পারে)৷ |
repeatCount | না | 1, অথবা 10 যদি repeatDur সেট করা থাকে | কতবার অডিও ঢোকাতে হবে তা নির্দিষ্ট করে একটি বাস্তব সংখ্যা (ক্লিপ করার পরে, যদি থাকে, clipBegin এবং/অথবা clipEnd দ্বারা)। ভগ্নাংশের পুনরাবৃত্তি সমর্থিত নয়, তাই মানটি নিকটতম পূর্ণসংখ্যায় বৃত্তাকার করা হবে। শূন্য একটি বৈধ মান নয় এবং তাই অনির্দিষ্ট হিসাবে বিবেচিত হয় এবং সেই ক্ষেত্রে ডিফল্ট মান রয়েছে। |
repeatDur | না | অনন্ত | একটি টাইমডিজাইনেশন যা clipBegin , clipEnd , repeatCount , এবং speed বৈশিষ্ট্যগুলির জন্য (বরং সাধারণ প্লেব্যাকের সময়কাল) জন্য উত্স প্রক্রিয়া করার পরে সন্নিবেশিত অডিওর সময়কালের একটি সীমা। যদি প্রক্রিয়াকৃত অডিওর সময়কাল এই মানের থেকে কম হয়, তাহলে সেই সময়ে প্লেব্যাক শেষ হয়ে যায়। |
soundLevel | না | +0dB | soundLevel ডেসিবেল দ্বারা অডিওর সাউন্ড লেভেল সামঞ্জস্য করুন। সর্বাধিক পরিসর হল +/-40dB কিন্তু প্রকৃত পরিসর কার্যকরভাবে কম হতে পারে এবং আউটপুট গুণমান সমগ্র পরিসরে ভাল ফলাফল নাও দিতে পারে। |
নিম্নলিখিতগুলি বর্তমানে অডিওর জন্য সমর্থিত সেটিংস:
- বিন্যাস: MP3 (MPEG v2)
- প্রতি সেকেন্ডে 24K নমুনা
- প্রতি সেকেন্ডে 24K ~ 96K বিট, নির্দিষ্ট হার
- বিন্যাস: Ogg মধ্যে Opus
- প্রতি সেকেন্ডে 24K নমুনা (সুপার-ওয়াইডব্যান্ড)
- 24K - 96K বিট প্রতি সেকেন্ড, নির্দিষ্ট হার
- বিন্যাস (অপ্রচলিত): WAV (RIFF)
- PCM 16-বিট স্বাক্ষরিত, সামান্য endian
- প্রতি সেকেন্ডে 24K নমুনা
- সব ফরম্যাটের জন্য:
- একক চ্যানেল পছন্দ, কিন্তু স্টেরিও গ্রহণযোগ্য।
- সর্বোচ্চ সময়কাল 240 সেকেন্ড। আপনি যদি দীর্ঘ সময়ের সাথে অডিও চালাতে চান তবে একটি মিডিয়া প্রতিক্রিয়া প্রয়োগ করার কথা বিবেচনা করুন৷
- 5 মেগাবাইট ফাইল সাইজ সীমা।
- উৎস URL অবশ্যই HTTPS প্রোটোকল ব্যবহার করবে।
- অডিও আনার সময় আমাদের UserAgent হল "Google-Speech-Actions"।
<audio> উপাদানের বিষয়বস্তু ঐচ্ছিক এবং অডিও ফাইল চালানো না গেলে বা আউটপুট ডিভাইস অডিও সমর্থন না করলে ব্যবহার করা হয়। বিষয়বস্তুতে একটি <desc> উপাদান থাকতে পারে যে ক্ষেত্রে সেই উপাদানটির পাঠ্য বিষয়বস্তু প্রদর্শনের জন্য ব্যবহার করা হয়। আরও তথ্যের জন্য, প্রতিক্রিয়া চেকলিস্টে রেকর্ড করা অডিও বিভাগটি দেখুন।
src URL অবশ্যই একটি https URL হতে হবে ( Google ক্লাউড স্টোরেজ একটি https URL-এ আপনার অডিও ফাইলগুলি হোস্ট করতে পারে)৷
মিডিয়া প্রতিক্রিয়া সম্পর্কে আরও জানতে, প্রতিক্রিয়া নির্দেশিকাতে মিডিয়া প্রতিক্রিয়া বিভাগটি দেখুন।
audio উপাদান সম্পর্কে আরও জানতে, W3 স্পেসিফিকেশন দেখুন।
উদাহরণ
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
বাক্য এবং অনুচ্ছেদের উপাদান।
p এবং s উপাদান সম্পর্কে আরও জানতে, W3 স্পেসিফিকেশন দেখুন।
উদাহরণ
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
সর্বোত্তম অনুশীলন
- সম্পূর্ণ বাক্যগুলি মোড়ানোর জন্য <s>...</s> ট্যাগগুলি ব্যবহার করুন, বিশেষ করে যদি সেগুলিতে SSML উপাদান থাকে যা প্রসোডি পরিবর্তন করে (অর্থাৎ, <audio>, <break>, <emphasis>, <par>, <prosody>, <say-as>, <seq>, এবং <sub>)।
- যদি বক্তৃতার বিরতি যথেষ্ট দীর্ঘ হয় যাতে আপনি এটি শুনতে পারেন, <s>...</s> ট্যাগগুলি ব্যবহার করুন এবং বাক্যগুলির মধ্যে সেই বিরতিটি রাখুন৷
<sub>
নির্দেশ করুন যে উপনাম অ্যাট্রিবিউট মানের পাঠ্যটি উচ্চারণের জন্য অন্তর্ভুক্ত পাঠ্যটিকে প্রতিস্থাপন করে।
আপনি একটি কঠিন-পঠন শব্দের সরলীকৃত উচ্চারণ প্রদান করতে sub উপাদানটিও ব্যবহার করতে পারেন। নীচের শেষ উদাহরণটি জাপানি ভাষায় এই ব্যবহারের ক্ষেত্রে দেখায়।
sub এলিমেন্ট সম্পর্কে আরও জানতে, W3 স্পেসিফিকেশন দেখুন।
উদাহরণ
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
একটি খালি উপাদান যা পাঠ্য বা ট্যাগ অনুক্রমের মধ্যে একটি মার্কার রাখে। এটি ক্রমানুসারে একটি নির্দিষ্ট অবস্থান উল্লেখ করতে বা অ্যাসিঙ্ক্রোনাস বিজ্ঞপ্তির জন্য একটি আউটপুট স্ট্রীমে একটি মার্কার সন্নিবেশ করতে ব্যবহার করা যেতে পারে।
| বৈশিষ্ট্য | বর্ণনা | ||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
name | প্রতিটি চিহ্নের জন্য স্ট্রিং আইডি। | ||||||||||||||||||||||||||||||||||||||||||
| অপশন | বর্ণনা |
|---|---|
| আপেক্ষিক | একটি আপেক্ষিক মান নির্দিষ্ট করুন (যেমন "নিম্ন", "মাঝারি", "উচ্চ", ইত্যাদি) যেখানে "মাঝারি" ডিফল্ট পিচ। |
| সেমিটোনস | যথাক্রমে "+ N st" বা "- N st" ব্যবহার করে " N " সেমিটোন দ্বারা পিচ বাড়ান বা হ্রাস করুন৷ মনে রাখবেন যে "+/-" এবং "st" প্রয়োজন। |
| শতাংশ | যথাক্রমে "+ N %" বা "- N %" ব্যবহার করে " N " শতাংশ দ্বারা পিচ বাড়ান বা হ্রাস করুন৷ মনে রাখবেন যে "%" প্রয়োজন কিন্তু "+/-" ঐচ্ছিক। |
prosody উপাদান সম্পর্কে আরও জানতে, W3 স্পেসিফিকেশন দেখুন।
উদাহরণ
নিচের উদাহরণে <prosody> উপাদানটি স্বাভাবিকের চেয়ে কম 2 সেমিটোনে ধীরে ধীরে কথা বলার জন্য ব্যবহার করে:
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
উপাদানের মধ্যে থাকা পাঠ্য থেকে জোর যোগ করতে বা অপসারণ করতে ব্যবহৃত হয়। <emphasis> উপাদানটি <prosody> এর মতই বক্তৃতা পরিবর্তন করে, কিন্তু পৃথক বক্তৃতা বৈশিষ্ট্য সেট করার প্রয়োজন ছাড়াই।
এই উপাদানটি নিম্নলিখিত বৈধ মানগুলির সাথে একটি ঐচ্ছিক "স্তর" বৈশিষ্ট্য সমর্থন করে:
-
strong -
moderate -
none -
reduced
emphasis উপাদান সম্পর্কে আরও জানতে, W3 স্পেসিফিকেশন দেখুন।
উদাহরণ
নিম্নলিখিত উদাহরণ একটি ঘোষণা করতে <emphasis> উপাদান ব্যবহার করে:
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
একটি সমান্তরাল মিডিয়া ধারক যা আপনাকে একসাথে একাধিক মিডিয়া উপাদানগুলি চালানোর অনুমতি দেয়। শুধুমাত্র অনুমোদিত সামগ্রী হল এক বা একাধিক <par> , <seq> , এবং <media> উপাদানগুলির একটি সেট৷ <media> উপাদানগুলির ক্রম উল্লেখযোগ্য নয়।
যতক্ষণ না একটি চাইল্ড এলিমেন্ট একটি ভিন্ন শুরুর সময় নির্দিষ্ট করে না, ততক্ষণ এলিমেন্টের অন্তর্নিহিত শুরুর সময় <par> কন্টেইনারের মতোই। যদি একটি চাইল্ড এলিমেন্টের শুরু বা শেষ অ্যাট্রিবিউটের জন্য অফসেট মান সেট করা থাকে, তাহলে এলিমেন্টের অফসেট <par> কন্টেইনারের শুরুর সময়ের সাথে আপেক্ষিক হবে। রুট <par> এলিমেন্টের জন্য, start এট্রিবিউট উপেক্ষা করা হয় এবং শুরুর সময় হল যখন SSML স্পিচ সিন্থেসিস প্রক্রিয়া রুট <par> এলিমেন্টের জন্য আউটপুট তৈরি করা শুরু করে (অর্থাৎ কার্যকরভাবে সময় "শূন্য")।
উদাহরণ
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak> <seq>
একটি ক্রমিক মিডিয়া ধারক যা আপনাকে মিডিয়া উপাদানগুলিকে একের পর এক চালাতে দেয়৷ শুধুমাত্র অনুমোদিত সামগ্রী হল এক বা একাধিক <seq> , <par> , এবং <media> উপাদানগুলির একটি সেট৷ মিডিয়া উপাদানগুলির ক্রম হল সেগুলি যে ক্রমে রেন্ডার করা হয়।
চাইল্ড উপাদানগুলির শুরু এবং শেষ বৈশিষ্ট্যগুলি অফসেট মানগুলিতে সেট করা যেতে পারে (নীচের সময় নির্দিষ্টকরণ দেখুন)। সেই শিশু উপাদানগুলির অফসেট মানগুলি অনুক্রমের পূর্ববর্তী উপাদানটির শেষের সাথে আপেক্ষিক হবে বা, অনুক্রমের প্রথম উপাদানের ক্ষেত্রে, এটির <seq> ধারকটির শুরুর সাথে আপেক্ষিক হবে৷
উদাহরণ
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak> <media>
একটি <par> বা <seq> উপাদানের মধ্যে একটি মিডিয়া স্তর প্রতিনিধিত্ব করে। একটি <media> উপাদানের অনুমোদিত সামগ্রী হল একটি SSML <speak> বা <audio> উপাদান। নিচের সারণীটি <media> উপাদানের বৈধ বৈশিষ্ট্য বর্ণনা করে।
গুণাবলী
| বৈশিষ্ট্য | প্রয়োজন | ডিফল্ট | মূল্যবোধ |
|---|---|---|---|
| xml:id | না | কোন মূল্য নেই | এই উপাদানটির জন্য একটি অনন্য XML শনাক্তকারী৷ এনকোড করা সত্তা সমর্থিত নয়। অনুমোদিত শনাক্তকারী মানগুলি রেগুলার এক্সপ্রেশনের সাথে মেলে "([-_#]|\p{L}|\p{D})+" আরও তথ্যের জন্য XML-ID দেখুন। |
| শুরু | না | 0 | এই মিডিয়া ধারক জন্য শুরু সময়. যদি এটি রুট মিডিয়া কন্টেইনার উপাদান হয় ("0" এর ডিফল্ট হিসাবে একই আচরণ করা হয়) উপেক্ষা করা হয়। বৈধ স্ট্রিং মানগুলির জন্য নীচের সময় স্পেসিফিকেশন বিভাগটি দেখুন। |
| শেষ | না | কোন মূল্য নেই | এই মিডিয়া কন্টেইনারের শেষ সময়ের জন্য একটি স্পেসিফিকেশন। বৈধ স্ট্রিং মানগুলির জন্য নীচের সময় স্পেসিফিকেশন বিভাগটি দেখুন। |
| পুনরাবৃত্তি গণনা | না | 1 | কতবার মিডিয়া ঢোকাতে হবে তা নির্দিষ্ট করে একটি বাস্তব সংখ্যা । ভগ্নাংশের পুনরাবৃত্তি সমর্থিত নয়, তাই মানটি নিকটতম পূর্ণসংখ্যায় বৃত্তাকার করা হবে। শূন্য একটি বৈধ মান নয় এবং তাই অনির্দিষ্ট হিসাবে বিবেচিত হয় এবং সেই ক্ষেত্রে ডিফল্ট মান রয়েছে। |
| পুনরাবৃত্তি | না | কোন মূল্য নেই | একটি টাইমডিজাইনেশন যা সন্নিবেশিত মিডিয়ার সময়কালের একটি সীমা। যদি মিডিয়ার সময়কাল এই মানের থেকে কম হয়, তাহলে সেই সময়ে প্লেব্যাক শেষ হয়। |
| সাউন্ড লেভেল | না | +0dB | soundLevel ডেসিবেল দ্বারা অডিওর সাউন্ড লেভেল সামঞ্জস্য করুন। সর্বাধিক পরিসর হল +/-40dB কিন্তু প্রকৃত পরিসর কার্যকরভাবে কম হতে পারে এবং আউটপুট গুণমান সমগ্র পরিসরে ভাল ফলাফল নাও দিতে পারে। |
| fadeInDur | না | 0 সে | একটি টাইম ডিজাইনেশন যার উপর মিডিয়া নীরব থেকে ঐচ্ছিকভাবে-নির্দিষ্ট soundLevel বিবর্ণ হয়ে যাবে। মিডিয়ার সময়কাল এই মানের থেকে কম হলে, প্লেব্যাকের শেষে ফেড ইন বন্ধ হয়ে যাবে এবং শব্দের স্তর নির্দিষ্ট শব্দ স্তরে পৌঁছাবে না। |
| fadeOutDur | না | 0 সে | একটি টাইম ডিজাইনেশন যার উপর মিডিয়া ঐচ্ছিকভাবে-নির্দিষ্ট soundLevel থেকে নিঃশব্দ না হওয়া পর্যন্ত বিবর্ণ হয়ে যাবে। যদি মিডিয়ার সময়কাল এই মানের থেকে কম হয়, তবে প্লেব্যাকের শেষে নীরবতা পৌঁছেছে তা নিশ্চিত করতে শব্দ স্তরটি একটি নিম্ন মান সেট করা হয়। |
সময়ের স্পেসিফিকেশন
একটি সময়ের স্পেসিফিকেশন, <media> উপাদান এবং মিডিয়া কন্টেইনারগুলির ( <par> এবং <seq> উপাদান) এর `begin` এবং `end` বৈশিষ্ট্যের মানের জন্য ব্যবহৃত হয়, হয় একটি অফসেট মান (উদাহরণস্বরূপ, +2.5s ) অথবা একটি সিঙ্কবেস মান (উদাহরণস্বরূপ, foo_id.end-250ms )।
- অফসেট মান - সময়ের অফসেট মান হল একটি SMIL টাইমকাউন্ট-মান যা রেগুলার এক্সপ্রেশনের সাথে মেলে এমন মানগুলিকে অনুমতি দেয়:
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"প্রথম অঙ্কের স্ট্রিংটি দশমিক সংখ্যার পুরো অংশ এবং দ্বিতীয় অঙ্কের স্ট্রিংটি দশমিক ভগ্নাংশের অংশ। ডিফল্ট চিহ্ন (যেমন "(+|-)?") হল "+"। ইউনিটের মান যথাক্রমে ঘন্টা, মিনিট, সেকেন্ড এবং মিলিসেকেন্ডের সাথে মিলে যায়। ইউনিটের জন্য ডিফল্ট হল "s" (সেকেন্ড)।
- সিঙ্কবেস মান - একটি সিঙ্কবেস মান হল একটি SMIL সিঙ্কবেস-মান যা রেগুলার এক্সপ্রেশনের সাথে মেলে এমন মানগুলিকে অনুমতি দেয়:
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"অঙ্ক এবং ইউনিটগুলি অফসেট মান হিসাবে একইভাবে ব্যাখ্যা করা হয়।
টিটিএস সিমুলেটর
অ্যাকশন কনসোলে একটি TTS সিমুলেটর রয়েছে যা আপনি উপরের যে কোনো উপাদানের সাথে SSML পরীক্ষা করতে ব্যবহার করতে পারেন। আপনি সিমুলেটর > অডিওর অধীনে কনসোলে TTS সিমুলেটরটি খুঁজে পেতে পারেন। সিমুলেটরে আপনার টেক্সট এবং SSML টাইপ করুন এবং TTS আউটপুট শুনতে Update and Listen-এ ক্লিক করুন।
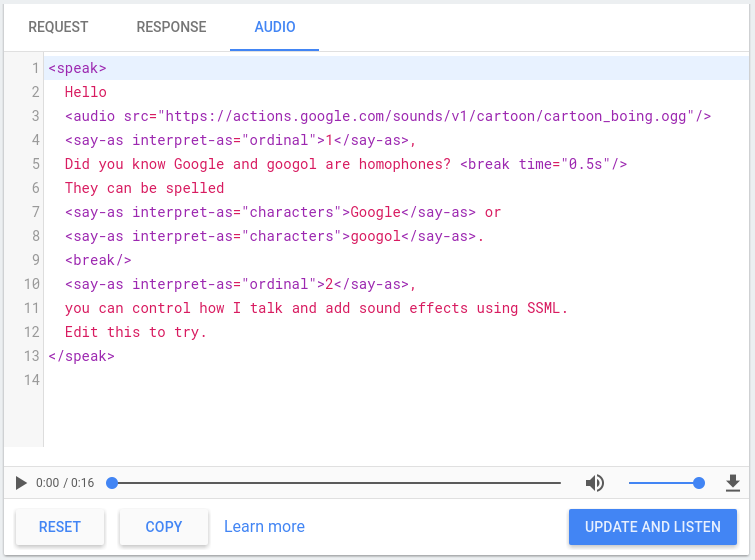
আপনি আপনার TTS আউটপুটের একটি .mp3 ফাইল সংরক্ষণ করতে ডাউনলোড বোতামে ক্লিক করতে পারেন।
অন্য কিছু উল্লেখ না করা থাকলে, এই পৃষ্ঠার কন্টেন্ট Creative Commons Attribution 4.0 License-এর অধীনে এবং কোডের নমুনাগুলি Apache 2.0 License-এর অধীনে লাইসেন্স প্রাপ্ত। আরও জানতে, Google Developers সাইট নীতি দেখুন। Java হল Oracle এবং/অথবা তার অ্যাফিলিয়েট সংস্থার রেজিস্টার্ড ট্রেডমার্ক।
2025-07-25 UTC-তে শেষবার আপডেট করা হয়েছে।