
Zwracając odpowiedź do Asystenta Google, możesz użyć podzbioru Speech Synthesis Markup Language (SSML) w Twoich odpowiedziach. Według przy użyciu SSML, możesz sprawić, że odpowiedzi w rozmowie będą wyglądały bardziej naturalnie. mowa. W tym przykładzie widać znaczniki SSML i odpowiadającą im ścieżkę audio z Asystent Google:
Node.js
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.add(ssml); }
JSON
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
Dźwięk
Adresy URL w SSML
Gdy definiujesz odpowiedź SSML, która zawiera tylko adres URL, w tym adresie URL znajduje się znak „&”
może powodować problemy z powodu formatowania XML. Aby upewnić się, że adres URL jest prawidłowy
, zastąp wystąpienia & elementem &.
Nawet jeśli odpowiedź SSML zawiera tylko adres URL, działania w Actions on Google wymagają
Wyświetlać tekst odpowiedzi. Tekst w tagu <audio> nie będzie
mówionych przez Asystenta, możesz wstawić tekst uzupełniający lub krótki opis
<audio> tag, aby spełnić to wymaganie. Tekst w tagu <audio> nie będzie
odczytywane przez Asystenta po odtworzeniu dźwięku i wykorzystywane do działania funkcji Action
wymagany dla wersji SSML do wyświetlania w formacie tekstowym.
Oto przykład problematycznej odpowiedzi SSML:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
W powyższym przykładzie nie ma znaczenia & dla prawidłowego formatowania XML.
Poprawiona wersja tej samej odpowiedzi SSML wygląda tak:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
Obsługa elementów SSML
W sekcjach poniżej opisujemy elementy i opcje SSML, których można używać w działaniach.
<speak>
Element główny odpowiedzi SSML.
Więcej informacji o elemencie speak znajdziesz w specyfikacji W3.
Przykład
<speak> my SSML content </speak>
<break>
Pusty element, który kontroluje wstrzymywanie lub tworzenie innych granic między słowami. Używanie elementu <break> między dowolną parą tokenów jest opcjonalne. Jeśli ten element nie występuje między słowami, przerwa jest określana automatycznie na podstawie kontekstu językowego.
Więcej informacji o elemencie break znajdziesz w specyfikacji W3.
Atrybuty
| Atrybut | Opis |
|---|---|
time |
Ustawia długość przerwy w sekundach lub milisekundach (np. „3 s” lub „250 ms”). |
strength |
Określa siłę przerw w działaniu danych wyjściowych według haseł względnych. Prawidłowe wartości to: „x-weak”, „słabe”, „medium”, „strong” i „x-strong”. Wartość „none” (brak). wskazuje, że nie powinna zostać wysłana granica przerwania prosodii, co może pomóc w zapobieżeniu przerwa w działaniu, którą w innym przypadku mógłby uzyskać procesor. Pozostałe wartości wskazują monotonicznie niezmniejszającą się (koncepcyjnie zwiększającą się) siłę pęknięć między tokenami. Silniejszym granicom zwykle towarzyszą pauzy. |
Przykład
Ten przykład pokazuje, jak używać elementu <break> do wstrzymywania między krokami:
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
Ten element umożliwia wskazanie informacji o typie tekstu, który jest w nim zawarty. Pomaga także określić poziom szczegółowości renderowania zawartego tekstu.
Element <say‑as> ma wymagany atrybut interpret-as, który określa sposób odczytywania wartości. W zależności od konkretnej wartości interpret-as mogą być używane opcjonalne atrybuty format i detail.
Przykłady
Atrybut interpret-as obsługuje te wartości:
-
currencyW następującym przykładzie mówi się „czterdzieści dwa dolary i jeden grosz”. Jeśli pominiesz atrybut język, używany będzie bieżący język.
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> -
telephoneZapoznaj się z opisem atrybutu
interpret-as='telephone'w notatce WG W3C SSML 1.0 poświęconej wartościom atrybutów.Poniższy przykład jest odczytywany jako „jeden osiem zero zero dwa zero dwa jeden dwa jeden dwa”. Jeśli w tagu „google:style” jest pomijany, ma postać 0 jako litery O.
Opcja „google:style='zero-as-zero'” obecnie działa tylko w języku angielskim.
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak> -
verbatimlubspell-outW tym przykładzie pisze się litera po literze:
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak> -
dateAtrybut
formatjest sekwencją kodów znaków pól daty. Obsługiwane kody znaków pól w poluformatto {y,m,d} odpowiednio dla roku, miesiąca i dnia (dnia miesiąca). Jeśli kod pola pojawia się raz dla roku, miesiąca lub dnia, oczekiwana liczba cyfr to odpowiednio 4, 2 i 2. Jeśli kod pola się powtarza, oczekiwana liczba cyfr to liczba powtórzeń kodu. Pola w tekście daty mogą być rozdzielone spacjami lub znakami interpunkcyjnymi.Atrybut
detailokreśla mówioną formę daty. W przypadku elementudetail='1'wymagane są tylko pola dnia oraz jedno pole miesiąca lub roku, choć można podać oba te pola. Jest to ustawienie domyślne, jeśli podano mniej niż wszystkie 3 pola. Używana forma wypowiedzi to „{dzień} {miesiąc}, {rok}.Poniższy przykład jest używany jako „Dziesiąty września dziewiętnaście sześćdziesiątego”:
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>Poniższy przykład jest używany jako „Dziesiąty września”:
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>W przypadku
detail='2'pola dnia, miesiąca i roku są wymagane. Jest to wartość domyślna, gdy wypełnione są wszystkie 3 pola. Postać mówiona to „{month} {ordinal Day}, {year}”.Poniższy przykład jest używany jako „Dziesiąty września 1960”:
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
charactersNastępujący przykład jest odczytywany jako „C A N”:
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalPoniższy przykład jest wypowiadany jako „Dwanaście tysięcy trzysta czterdzieści pięć” (dla języka angielskiego – USA) lub „Dwanaście tysięcy trzysta czterdzieści pięć (dla języka angielskiego – Wielka Brytania)”:
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinalPoniższy przykład jest odczytywany jako „Pierwszy”:
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fractionNastępujący przykład jest wypowiadany jako „pięć i pół”:
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletivelubbleepNastępujący przykład jest zasygnalizowany sygnałem dźwiękowym, jakby został ocenzurowany:
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unitKonwertuje jednostkę na liczbę pojedynczą lub mnogą w zależności od liczby. Następujący przykład jest odczytywany jako „10 stóp”:
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
timePoniższy przykład jest odczytywany jako „Dwadzieścia trzydzieści”:
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>Atrybut
formatjest sekwencją kodów znaków pól czasu. Obsługiwane kody znaków w poluformatto odpowiednio {h,m,s,Z,12,24} oznaczające godzinę, minutę (godziny), sekundy (minutę), strefę czasową, 12-godzinny i 24-godzinny format czasu. Jeśli kod pola pojawia się raz na godzinę, minutę lub sekundę, oczekiwana liczba cyfr to odpowiednio 1, 2 i 2. Jeśli kod pola się powtarza, oczekiwana liczba cyfr to liczba powtórzeń kodu. Pola w tekście godziny mogą być rozdzielone spacjami lub znakami interpunkcyjnymi. Jeśli w formacie nie określono godziny, minuty lub sekundy albo nie ma pasujących cyfr, pole jest traktowane jako wartość zerowa. Wartość domyślna polaformatto „hms12”.Atrybut
detailokreśla, czy godzina ma być w formacie 12-godzinnym czy 24-godzinnym. Format mówiony to 24-godzinny, jeśli wartośćdetail='1'lubdetailpominięto, a format godziny to 24-godzinny. Format mówiony to 12-godzinny, jeśli właściwośćdetail='2'lubdetailpominięto, a format godziny to 12-godzinny.
Więcej informacji o elemencie say-as znajdziesz w specyfikacji W3.
<audio>
Obsługuje wstawianie nagranych plików audio oraz innych formatów audio w połączeniu z syntezatorem mowy.
Atrybuty
| Atrybut | Wymagane | Domyślny | Wartości |
|---|---|---|---|
src |
tak | nie dotyczy | Identyfikator URI odnoszący się do źródła multimediów audio. Obsługiwany protokół to https. |
clipBegin |
nie | 0 | TimeDesignation, czyli przesunięcie od początku odtwarzania źródła dźwięku. Jeśli ta wartość jest większa lub równa rzeczywistemu czasowi trwania źródła dźwięku, dźwięk nie zostanie wstawiony. |
clipEnd |
nie | nieskończoność | Wartość TimeDesignation określa przesunięcie od momentu rozpoczęcia do zakończenia odtwarzania źródła dźwięku. Jeśli rzeczywisty czas trwania źródła dźwięku jest krótszy od tej wartości, odtwarzanie kończy się o tej godzinie. Jeśli clipBegin ma wartość większą lub równą clipEnd, dźwięk nie zostanie wstawiony. |
speed |
nie | 100% | Współczynnik wyjściowej szybkości odtwarzania w stosunku do normalnej szybkości wejściowej wyrażonej w procentach. Format to dodatni liczba rzeczywista, po której następuje znak %. Obecnie obsługiwany zakres to [50% (wolna - połowa prędkości), 200% (szybka – podwójna prędkość)]. Wartości spoza tego zakresu mogą (lub nie) zostać dostosowane, aby mieściły się w nim. |
repeatCount |
nie | 1 lub 10, jeśli ustawiono repeatDur |
Liczba rzeczywista określająca, ile razy dźwięk ma zostać wstawiony (po przycięciu, jeśli występuje, przez clipBegin lub clipEnd). Ułamkowe powtórzenia nie są obsługiwane, więc wartość zostanie zaokrąglona do najbliższej liczby całkowitej. 0 nie jest prawidłową wartością i dlatego jest traktowane jako nieokreślone i ma w tym przypadku wartość domyślną. |
repeatDur |
nie | nieskończoność | TimeDesignation, który określa limit czasu trwania wstawionego dźwięku po przetworzeniu źródła dla atrybutów clipBegin, clipEnd, repeatCount i speed (zamiast normalnego czasu odtwarzania). Jeśli czas trwania przetworzonego dźwięku jest krótszy od tej wartości, odtwarzanie się zakończy. |
soundLevel |
nie | +0dB | Dostosuj poziom dźwięku dźwięku soundLevelw decybelach. Maksymalny zakres to +/-40 dB, ale rzeczywisty zakres może być mniejszy, a jakość wyjścia może nie dawać dobrych wyników w całym zakresie. |
Oto aktualnie obsługiwane ustawienia dźwięku:
- Format: MP3 (MPEG v2)
- 24 tys. próbek na sekundę
- 24 KB ~ 96 tys. bitów na sekundę, stała szybkość
- Format: opus w formacie Ogg
- 24 tys. próbek na sekundę (superszerokopasmowe)
- 24 tys.–96 tys. bitów na sekundę, stała szybkość
- Format (wycofany): WAV (RIFF)
- PCM 16-bitowy ze znakiem, little endian
- 24 tys. próbek na sekundę
- Wszystkie formaty:
- Preferowane są kanały jednokanałowe, ale dźwięk stereo jest dozwolony.
- Maksymalny czas trwania to 240 sekund. Jeśli chcesz odtwarzać dźwięk przez dłuższy czas, rozważ wdrożenie reakcji na multimedia.
- Limit rozmiaru pliku to 5 megabajtów.
- Źródłowy adres URL musi używać protokołu HTTPS.
- Nasz klient użytkownika podczas pobierania danych dźwiękowych to „Google-Speech-Actions”.
Zawartość elementu <audio> jest opcjonalna i używana, jeśli nie można odtworzyć pliku audio lub gdy urządzenie wyjściowe nie obsługuje dźwięku. Treść może zawierać element <desc>. Oznacza to, że do wyświetlenia jest wykorzystywana zawartość tekstowa tego elementu. Więcej informacji znajdziesz w sekcji „Nagrany dźwięk” na liście kontrolnej odpowiedzi.
Adres URL src musi też być adresem https (Twoje pliki audio mogą być przechowywane w Google Cloud Storage pod adresem URL https).
Więcej informacji o odpowiedziach w mediach znajdziesz w sekcji dotyczącej odpowiedzi w mediach w przewodniku dotyczącym odpowiedzi.
Więcej informacji o elemencie audio znajdziesz w specyfikacji W3.
Przykład
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
Elementy zdania i akapitu.
Więcej informacji o elementach p i s znajdziesz w specyfikacji W3.
Przykład
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
Sprawdzone metody
- Użyj tagu <s>...</s> zawijaj całe zdania, zwłaszcza jeśli zawierają elementy SSML, które zmieniają prozodię (czyli <audio>, <break>, <emphasis>, <par>, <prosody>, <say-as>, <seq> i <sub>).
- Jeśli przerwa w mowie ma być wystarczająco długa, żeby można było ją usłyszeć, użyj funkcji <s>...</s> i umieścić ten podział między zdania.
<sub>
Wskaż, że tekst w wartości atrybutu alias zastępuje zawarty w niej tekst wymowy.
Możesz też użyć elementu sub, aby uprościć wymowę trudnych do odczytania słów. Ostatni przykład poniżej przedstawia ten przypadek użycia w języku japońskim.
Więcej informacji o elemencie sub znajdziesz w specyfikacji W3.
Przykłady
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
Pusty element, który umieszcza znacznik w tekście lub sekwencji tagów. Może służyć jako odwołanie do określona lokalizacja w sekwencji lub wstawienie znacznika do strumienia wyjściowego, dla powiadomienia asynchronicznego.
. .Więcej informacji o elemencie mark znajdziesz w specyfikacji W3.
Przykład
<speak> Go from <mark name="here"/> here, to <mark name="there"/> there! </speak>
.
<prosody>
Służy do dostosowania wysokości, tempa wypowiedzi i objętości tekstu zawartego w elemencie. Obecnie obsługiwane są atrybuty rate, pitch oraz volume.
Atrybuty rate i volume można ustawić zgodnie ze specyfikacją W3. Wartość atrybutu pitch możesz ustawić na 3 sposoby:
| Atrybut | Opis |
|---|---|
name |
Identyfikator ciągu znaków dla każdego znaku. |
| Opcja | Opis |
|---|---|
| Krewny | Podaj wartość względną (np. „niska”, „średnia”, „wysoka” itp.), gdzie „średnia” to domyślny ton. |
| Półtony | Zwiększ lub zmniejsz tonację o „N” półton z użyciem „+Nst” lub „-Nst” . Zapis „+/-” i „st” są wymagane. |
| Procent | Zwiększ lub zmniejsz tonację o „N” procent, stosując „+N%” lub „-N%” . Pamiętaj, że „%” jest wymagany, ale „+/-” jest opcjonalna. |
Więcej informacji o elemencie prosody znajdziesz w specyfikacji W3.
Przykład
W tym przykładzie użyto elementu <prosody>, aby mówić wolniej w 2 półtonach niższych niż zwykle:
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
Służy do dodawania lub usuwania podkreślenia tekstu w elemencie. Element <emphasis> modyfikuje mowę podobnie jak <prosody>, ale nie ma potrzeby ustawiania poszczególnych atrybutów mowy.
Ten element obsługuje opcjonalny „poziom” o następujących prawidłowych wartościach:
strongmoderatenonereduced
Więcej informacji o elemencie emphasis znajdziesz w specyfikacji W3.
Przykład
Ten przykładowy kod pozwala opublikować ogłoszenie za pomocą elementu <emphasis>:
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
Równoległy kontener multimediów, który umożliwia odtwarzanie wielu elementów multimedialnych jednocześnie. Jedyną dozwoloną treścią jest zestaw co najmniej 1 elementu <par>, <seq> i <media>. Kolejność elementów <media> nie jest istotna.
O ile element podrzędny nie określa innego czasu rozpoczęcia, niejawny czas rozpoczęcia elementu jest taki sam jak w kontenerze <par>. Jeśli element podrzędny ma wartość przesunięcia dla atrybutu begin lub end, przesunięcie elementu będzie określone względem czasu rozpoczęcia kontenera <par>. W przypadku głównego elementu <par> atrybut początkowy jest ignorowany, a godziną rozpoczęcia jest moment, w którym proces syntezy mowy SSML rozpoczyna generowanie danych wyjściowych dla głównego elementu <par> (czyli w efekcie otrzymuje wartość „zero”).
Przykład
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak><seq>
Sekwencyjny kontener multimediów, który umożliwia odtwarzanie elementów multimedialnych jeden po drugim. Jedyną dozwoloną treścią jest zestaw co najmniej 1 elementu <seq>, <par> i <media>. Kolejność elementów multimedialnych to kolejność ich renderowania.
W atrybutach begin i end elementów podrzędnych można ustawić wartości przesunięcia (patrz Specyfikacja czasu poniżej). Te elementy podrzędne wartości przesunięcia będą określone względem końca poprzedniego elementu w sekwencji lub, w przypadku pierwszego elementu w sekwencji, względem początku jego kontenera <seq>.
Przykład
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media>
Reprezentuje warstwę multimediów w elemencie <par> lub <seq>. Dozwolona zawartość elementu <media> to element SSML <speak> lub <audio>. W tabeli poniżej znajdziesz opisy prawidłowych atrybutów elementu <media>.
Atrybuty
| Atrybut | Wymagane | Domyślny | Wartości |
|---|---|---|---|
| xml:id | nie | brak wartości | Unikalny identyfikator XML tego elementu. Encje zakodowane nie są obsługiwane. Dozwolone wartości identyfikatorów pasują do wyrażenia regularnego "([-_#]|\p{L}|\p{D})+". Więcej informacji znajdziesz w sekcji XML-ID. |
| początek | nie | 0 | Czas rozpoczęcia tego kontenera multimediów. Ignorowana, jeśli jest to główny element kontenera multimediów (traktowany tak samo jak wartość domyślną, czyli „0”). Prawidłowe wartości ciągów znaków znajdziesz w sekcji Specyfikacja czasu poniżej. |
| end | nie | brak wartości | Specyfikacja czasu zakończenia tego kontenera multimediów. Prawidłowe wartości ciągów znaków znajdziesz w sekcji Specyfikacja czasu poniżej. |
| repeatCount | nie | 1 | Liczba rzeczywista, która określa, ile razy trzeba wstawić multimedia. Ułamkowe powtórzenia nie są obsługiwane, więc wartość zostanie zaokrąglona do najbliższej liczby całkowitej. 0 nie jest prawidłową wartością i dlatego jest traktowane jako nieokreślone i ma w tym przypadku wartość domyślną. |
| repeatDur | nie | brak wartości | TimeDesignation, który określa limit czasu trwania wstawionych multimediów. Jeśli czas trwania multimediów jest krótszy od tej wartości, odtwarzanie kończy się w tym momencie. |
| soundLevel | nie | +0dB | Dostosuj poziom dźwięku dźwięku o soundLevel decybele. Maksymalny zakres to +/-40 dB, ale rzeczywisty zakres może być mniejszy, a jakość wyjścia może nie dawać dobrych wyników w całym zakresie. |
| fadeInDur | nie | 0 s | Ustawienie TimeDesignation, po którym multimedia zmieniają się z wyciszenia do opcjonalnie określonego soundLevel. Jeśli czas trwania multimediów będzie krótszy niż ta wartość, po zakończeniu odtwarzania wyciszanie zostanie zatrzymane, a poziom dźwięku nie osiągnie określonego poziomu. |
| fadeOutDur | nie | 0 s | Pole TimeDesignation, w którym multimedia mają zanikać z określonego opcjonalnie soundLevel, aż do momentu wyciszenia. Jeśli czas trwania multimediów jest krótszy niż ta wartość, poziom dźwięku jest ustawiany na niższą, tak aby na końcu odtwarzania została osiągnięta cisza. |
Określenie czasu
Specyfikacja czasu używana dla wartości atrybutów „begin” i „end” elementów <media> i kontenerów multimediów (elementów <par> i <seq>) jest wartością przesunięcia (np. +2.5s) lub wartością synchronizacji bazy danych (np. foo_id.end-250ms).
- Wartość przesunięcia – wartość przesunięcia czasu to wartość czasu SMIL, która dopuszcza wartości pasujące do wyrażenia regularnego:
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Pierwszy ciąg cyfr to część liczby dziesiętnej, a drugi to ułamek dziesiętny. Domyślny znak (np. „(+|-)?”) to „+”. Wartości jednostek odpowiadają godzinom, minutom, sekundom i milisekundom. Wartość domyślna jednostek to „s”. (sekundy).
- Syncbase value – wartość syncbase to wartość parametru syncbase SMIL, która zezwala na wartości pasujące do wyrażenia regularnego:
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Cyfry i jednostki są interpretowane w taki sam sposób jak wartość przesunięcia.
Symulator zamiany tekstu na mowę
Konsola Actions zawiera symulator zamiany tekstu na mowę, którego możesz używać do testowania SSML. z dowolnymi z powyższych elementów. Symulator zamiany tekstu na mowę znajdziesz w konsoli w sekcji Simulator > Audio. Wpisz tekst i SSML w symulatorze, a następnie kliknij Zaktualizuj i słuchaj, aby usłyszeć sygnał zamiany tekstu na mowę.
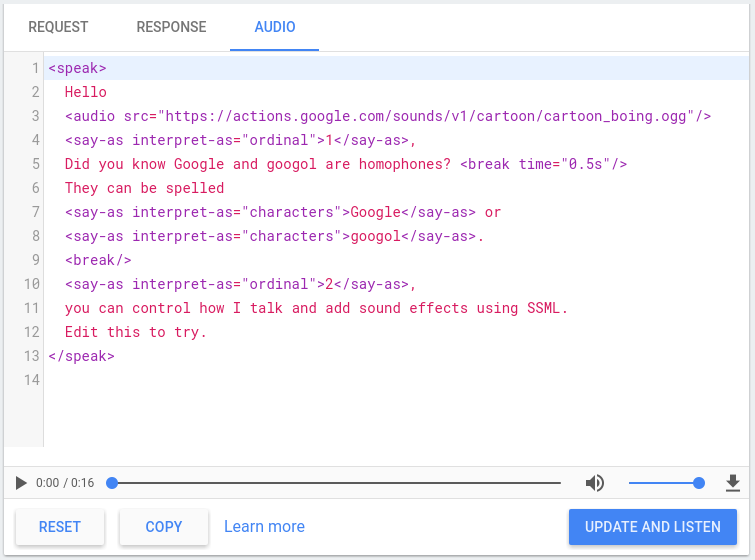
Możesz też kliknąć przycisk pobierania, aby zapisać plik .mp3 TTS.
dane wyjściowe.