
Dans Google Cloud Search, les accès sont contrôlés en fonction du compte Google des utilisateurs. Lors de l'indexation du contenu, toutes les listes de contrôle d'accès (LCA) des éléments doivent être associées à des ID d'utilisateurs ou de groupes Google valides (adresses e-mail).
Souvent, les dépôts ne reconnaissent pas directement les comptes Google, car les utilisateurs passent par un compte local ou une connexion fédérée avec un fournisseur d'identité et un ID, plutôt que par leur adresse e-mail. Cet ID est appelé ID externe.
Afin de remédier à ces différences entre les systèmes d'identité, vous pouvez créer des sources d'identité dans la Console d'administration. Pour ce faire:
- Définissez un champ d'utilisateur personnalisé pour stocker les ID externes. Ce champ est utilisé pour associer les ID externes à un compte Google.
- Définissez un espace de noms pour les groupes de sécurité gérés par un dépôt ou un fournisseur d'identité.
Utilisez des sources d'identité si vous êtes dans l'un des cas suivants:
- Le dépôt ne connaît pas l'adresse e-mail principale de l'utilisateur dans Google Workspace ou Google Cloud Directory.
- Le dépôt définit des groupes de contrôle d'accès qui ne correspondent pas aux groupes de messagerie dans Google Workspace.
Les sources d'identité améliorent l'efficacité de l'indexation en dissociant l'indexation et le mappage d'identité. Grâce à cette dissociation, vous n'êtes plus contraint de rechercher l'utilisateur au moment de créer des LCA et d'indexer des éléments.
Exemple de déploiement
Dans le déploiement illustré dans la figure 1, l'entreprise utilise des dépôts sur site et dans le cloud. Chaque dépôt utilise un type d'ID externe différent pour identifier les utilisateurs.
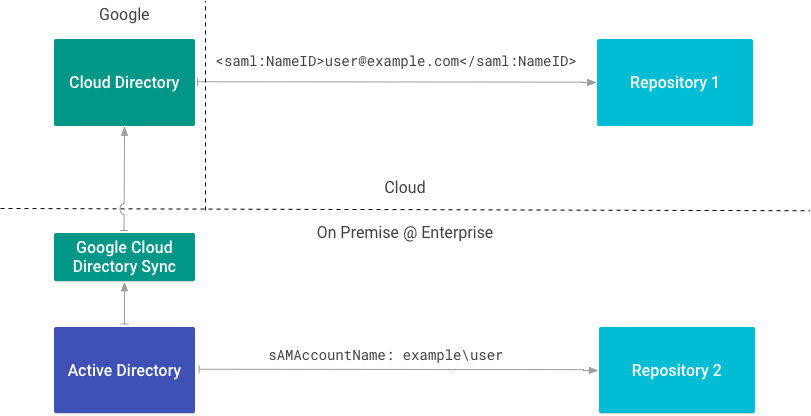
Le dépôt 1 identifie l'utilisateur avec l'adresse e-mail déclarée à l'aide du protocole SAML. Comme le dépôt 1 connaît l'adresse e-mail principale de l'utilisateur dans Google Workspace ou Cloud Directory, il est inutile d'utiliser une source d'identité.
Le dépôt 2 est directement intégré à un dépôt sur site et identifie l'utilisateur par son attribut sAMAccountName. Comme le dépôt 2 utilise un attribut sAMAccountName en tant qu'ID externe, il est nécessaire d'utiliser une source d'identité.
Créer une source d'identité
Si vous avez besoin d'une source d'identité, consultez l'article Associer des identités d'utilisateur dans Cloud Search.
Vous devez créer une source d'identité avant de créer un connecteur de contenu, car vous aurez besoin de l'ID de la source d'identité pour créer des LCA et indexer les données. Rappelons que la création d'une source d'identité entraîne l'ajout d'une propriété utilisateur personnalisée dans l'annuaire cloud. Utilisez cette propriété pour enregistrer l'ID externe de chaque utilisateur de votre dépôt. Le nom de la propriété suit la convention IDENTITY_SOURCE_ID_identity.
Le tableau suivant contient deux sources d'identité : une qui traite les noms de compte SAM (sAMAccountName) comme ID externes et l'autre qui traite les ID utilisateur (uid) en tant qu'ID externes.
| Source d'identité | propriété utilisateur | ID externe |
|---|---|---|
| id1 | id1_identity | sAMAccountName |
| id2 | id2_identity | uid |
Créez une source d'identité pour chaque ID externe associé à un utilisateur de votre entreprise.
Le tableau suivant montre comment un utilisateur disposant d'un compte Google et de deux ID externes (id1_identity et id2_identity) et leurs valeurs apparaissent dans Cloud Directory:
| utilisateur | id1_identity | id2_identity | |
|---|---|---|---|
| Anne | ann@example.com | exemple\anne | 1001 |
Lors de l'établissement de LCA pour l'indexation, vous pouvez utiliser ces trois ID (adresse e-mail Google, sAMAccountName et uid) pour identifier un même utilisateur.
Écrire des LCA utilisateur
Utilisez les méthodes getUserPrincpal() ou getGroupPrincipal() pour créer des principaux à partir d'un ID externe fourni.
L'exemple ci-dessous indique comment obtenir les données relatives aux autorisations des fichiers. Ces autorisations contiennent le nom de chaque utilisateur pouvant accéder aux fichiers.
L'extrait de code suivant montre comment créer des comptes principaux qui sont propriétaires des fichiers en utilisant l'ID externe (externalUserName) enregistré dans les attributs.
Enfin, l'extrait de code suivant indique comment créer des comptes principaux qui sont autorisés à lire les fichiers.
Une fois que vous avez identifié les lecteurs et propriétaires des fichiers, vous pouvez créer la liste de contrôle d'accès:
Pour créer les ID des comptes principaux, l'API REST sous-jacente utilise le format identitysources/IDENTITY_SOURCE_ID/users/EXTERNAL_ID. Si vous créez une LCA avec l'id1_identity (SAMAccountName) d'Anne, vous obtiendrez l'ID suivant:
identitysources/id1_identity/users/example/ann
Pris dans son ensemble, cet ID utilisateur est qualifié d'ID intermédiaire, car il crée un lien entre l'ID externe et les ID Google enregistrés dans Cloud Directory.
Pour obtenir plus d'informations sur les différents modèles de listes de contrôle d'accès utilisées dans un dépôt, consultez l'article LCA.
Mapper les groupes
Les sources d'identité servent également d'espaces de noms pour les groupes utilisés dans les listes de contrôle d'accès. Cette fonctionnalité d'espace de noms permet de créer et de mapper des groupes utilisés uniquement à des fins de sécurité ou des groupes locaux d'un dépôt.
Utilisez l'API Cloud Identity Groups pour créer un groupe et en gérer les membres. Pour associer le groupe à une source d'identité, utilisez le nom de la ressource de la source d'identité comme espace de noms du groupe.
L'extrait de code suivant montre comment créer un groupe avec l'API Cloud Identity Groups:
Créer une LCA de groupe
Pour créer une LCA de groupe, commencez par créer un compte principal de groupe à partir de l'ID externe fourni, en utilisant la méthode getGroupPrincipal(). Créez ensuite la LCA à l'aide de la classe Acl.Builder comme suit:
Connecteurs d'identité
Bien qu'il soit possible d'utiliser des ID externes, aucunement liés à Google, pour créer des listes de contrôle d'accès et indexer des éléments, les utilisateurs ne peuvent pas voir les éléments d'une recherche tant que leurs ID externes ne sont pas associés à un ID Google dans Cloud Directory. Il existe trois façons de s'assurer que Cloud Directory reconnaît à la fois l'ID Google et les ID externes d'un utilisateur:
- Mettre à jour manuellement chaque profil utilisateur depuis la Console d'administration. Cette méthode est réservée aux tests et prototypages impliquant peu de profils utilisateur.
- Mapper des ID externes avec des ID Google en utilisant l'API Directory. Cette méthode est recommandée quand le SDK Identity Connector ne peut pas être utilisé.
- Créez un connecteur d'identité à l'aide du SDK Identity Connector. Ce SDK simplifie l'utilisation de l'API Directory pour mapper des ID.
Les connecteurs d'identité sont des programmes utilisés pour mapper des ID externes entre les identités d'entreprise (utilisateurs et groupes) et les identités Google internes utilisées par Google Cloud Search. Vous ne pouvez créer de source d'identité sans créer de connecteur d'identité.
Google Cloud Directory Sync (GCDS), par exemple, est un connecteur d'identité. Ce dernier fait correspondre les informations concernant les utilisateurs et les groupes enregistrées dans Microsoft Active Directory avec celles de l'annuaire cloud, ainsi que les attributs de l'utilisateur qui peuvent être employés par d'autres systèmes pour l'identifier.
Synchroniser des identités à l'aide de l'API REST
Utilisez la méthode update pour synchroniser les identités à l'aide de l'API REST.
Remapper des identités
Après avoir remappé l'identité d'un élément sur une autre identité, vous devez réindexer les éléments pour que la nouvelle identité prenne effet. Par exemple,
- Si vous essayez de supprimer une mise en correspondance d'un utilisateur ou de la remapper sur un autre utilisateur, la mise en correspondance d'origine est toujours conservée jusqu'à ce que vous réindexiez.
- Si vous supprimez un groupe mappé présent dans une LCA d'élément, puis créez un nouveau groupe avec le même
groupKey, le nouveau groupe n'offre pas d'accès à l'élément tant qu'il n'a pas été réindexé.