
Funkcja interpretacji zapytań w Cloud Search automatycznie interpretuje operatory i filtry w zapytaniu użytkownika, a następnie przekształca je w ustrukturyzowane zapytanie oparte na operatorach. Interpretacja zapytania korzysta z operatorów zdefiniowanych w schemacie oraz z indeksowanych dokumentów, aby ustalić znaczenie zapytania użytkownika. Ta funkcja umożliwia użytkownikom wyszukiwanie przy użyciu minimalnej liczby słów kluczowych, a jednak z dokładnymi wynikami.
Rzeczywiste wyniki wyświetlane użytkownikowi zależą od pewności interpretacji zapytania. Pewność zależy od kilku czynników,
w tym od tego, gdzie w zaindeksowanych dokumentach występują ciągi znaków zapytań. Ciąg znaków, np. imię i nazwisko aktora „Tom Hanks”, który pojawia się konsekwentnie w polu schema o nazwie actors, powoduje większą ufność. Ten sam ciąg znaków („Tom Hanks”) występujący w akapicie, a nie w polu schema, może spowodować spadek ufności. W przypadku wysokiego poziomu pewności wyświetlane są tylko wyniki interpretacji zapytania. W przypadku niższych wartości pewności wyniki interpretacji zapytania są łączone ze zwykłymi wynikami wyszukiwania słów kluczowych.
Interpretacja przykładowego zapytania
Załóżmy, że masz źródło danych, np. bazę danych, zawierające informacje o filmach. Rysunek 1 przedstawia przykładowe zapytanie i interpretację.
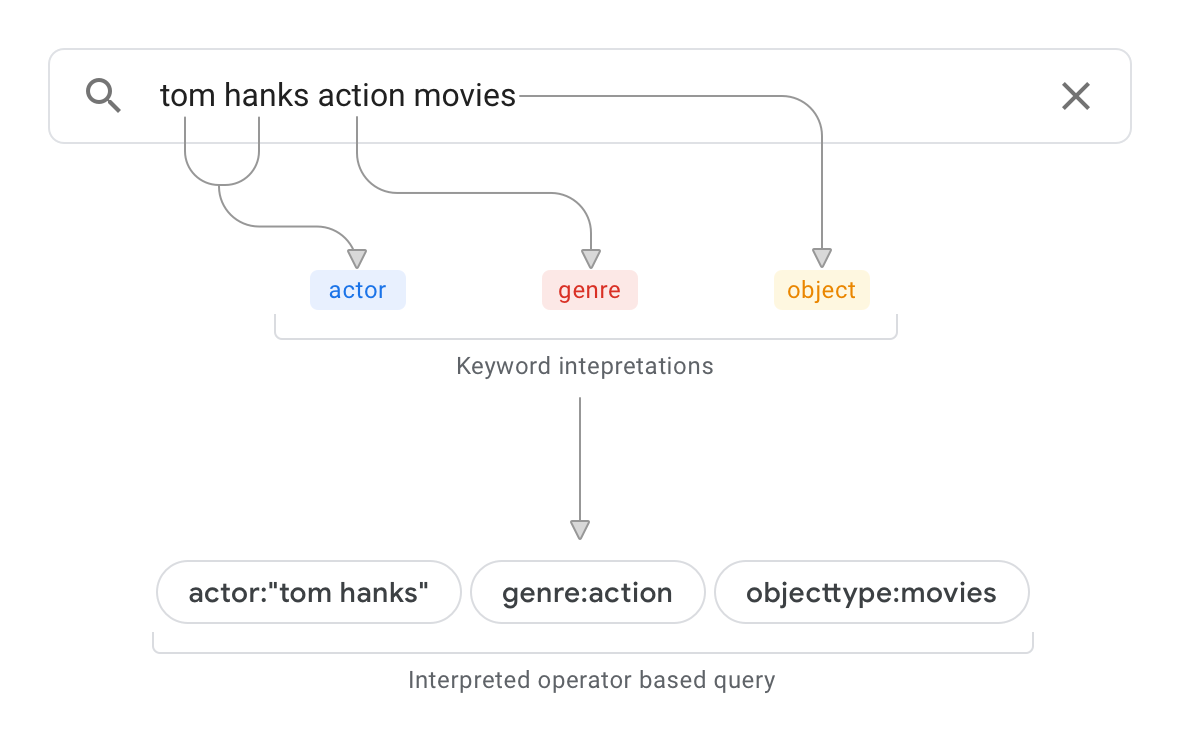
W przypadku tego przykładowego zapytania interpretacja zapytania wykonuje te czynności:
Przeanalizuj schemat i sprawdź, czy obiekty najwyższego poziomu w źródle danych są sklasyfikowane jako
objecttype:movies. Interpretacja zapytania wie teraz, że „filmy” w zapytaniu to typ obiektu.Skanuje dokumenty w źródle danych w połączeniu ze schematem, aby określić, gdzie występuje ciąg „działanie”. Jeśli ciąg występuje głównie w konkretnym polu źródła danych „genre”, interpretacja zapytania ma pewność, że „action” jest wartością właściwości dla właściwości „genre” zgodnie z definicją w schemie. Jeśli ciąg występuje głównie w kontekście akapitów treści, poziom ufności interpretacji zapytania maleje.
Interpretacja zapytania:
actor:“tom hanks” genre:action objecttype:movies
Interpretacja zapytań jest automatycznie włączana dla wszystkich klientów Cloud Search bez konieczności wykonywania dodatkowych czynności. Jednak aby zapewnić optymalną interpretację zapytań, musisz ustrukturyzować schemat zgodnie z instrukcjami podanymi w tym dokumencie.
Uporządkuj schemat, aby ułatwić interpretację zapytań
Schemat powinien być sformatowany w taki sposób, aby można było korzystać z interpretacji zapytań.
Włącz interpretację wyświetlanej nazwy
Interpretacja zapytań w Cloud Search wykorzystuje elementy objectDefinitions i propertyDefinitions w schemacie, aby interpretować zapytania użytkownika i dostosowywać wyniki. Aby w maksymalny sposób wykorzystać te elementy schematu, utwórz intuicyjne wyświetlane nazwy, używając symbolu displayLabel w przypadku nazw właściwości, objectDisplayLabel w przypadku nazw obiektów i operatorName w przypadku operatorów.
Poniższy schemat przedstawia intuicyjne nazwy wyświetlane obiektu filmu:
{
"objectDefinitions": [
{
"name": "movie",
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
...
},
"propertyDefinitions": [
{
"name": "genre",
"isReturnable": true,
"isRepeatable": true,
"isFacetable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "genre"
}
},
"displayOptions": {
"displayLabel": "Category"
}
},
...
]
}
]
}
W poprzednim przykładzie:
Definicja obiektu filmu ma element „Film”
objectDisplayLabel.Definicja własności gatunku zawiera „gatunek”
operatorNamei „kategorię”displayLabel.
Te wyświetlane nazwy umożliwiają Cloud Search wykonywanie tych interpretacji zapytań:
- „filmy akcji”, „filmy akcji typu gatunek” lub „filmy typu gatunek akcji” są interpretowane jako
genre:action object:movies. - „filmy z gatunku akcji lub thriller” są interpretowane jako
objecttype:movies genre:(action OR thriller). - „film akcji” lub „filmy akcji” jest interpretowane jako
genre:action objecttype:movies. - „filmy z kategorii komedia” jest interpretowane jako
genre:comedy objecttype:movies.
Włącz interpretację dat, liczb i sortowania.
W przypadku wszystkich właściwości daty i liczbowych należy zdefiniować typy lessThanOperatorName i greaterThanOperatorName, które są określone w IntegerOperatorOptions. Te ustawienia umożliwiają automatyczne interpretowanie dat i liczb. Aby umożliwić interpretację sortowania, ustaw opcję isSortable w przypadku właściwości daty i liczb. Schemat poniżej pokazuje, jak włączyć te opcje.
{
"objectDefinitions": [
{
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
},
"propertyDefinitions": [
{
"name": "runtime",
"isReturnable": true,
"isSortable": true,
"integerPropertyOptions": {
"orderedRanking": "DESCENDING",
"minimumValue": {
"value": 10
},
"maximumValue": {
"value": 500
},
"operatorOptions": {
"operatorName": "runtime",
"lessThanOperatorName": "runtimelessthan",
"greaterThanOperatorName": "runtimegreaterthan"
}
},
"displayOptions": {
"displayLabel": "Length"
}
},
{
"name": "releasedate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "releasedate",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}
]
}
W poprzednim przykładzie:
- Właściwość liczbowa
runtimeodnosi się do długości filmu. Właściwośćruntimelessthaniruntimegreaterthanjest ustawiona dla tej usługi. - Właściwość data
releaseDateodnosi się do daty premiery filmu w kinach. Właściwościreleasedbeforeireleasedaftersą ustawione dla tej usługi.
Te ustawienia umożliwiają Cloud Search wykonywanie tych interpretacji zapytań:
- Zakładając, że mamy rok 2019, „filmy wydane w tym roku” będą interpretowane jako
objecttype: movies releasedafter:2019-1-1 releasedbefore:2019-12-31. - Zakładając, że jest to trzeci tydzień marca, „filmy wydane w zeszłym tygodniu” należy interpretować jako
objecttype: movies releasedafter:2019-3-10 releasedbefore:2019-3-16 - „Filmy o czasie trwania krótszym niż 90” są interpretowane jako
objjecttype: movies runtimelessthan:90. - Zakładając, że mamy rok 2019, „filmy wydane w tym roku o długości ponad 120” są interpretowane jako
releasedafter:2019-1-1 releasedbefore:2019-12-31 objecttype:movies runtimegreaterthan:120. - „sortuj filmy według daty premiery” spowoduje zastosowanie filtra „objecttype: movies”, a wyniki zostaną posortowane według daty premiery w kolejności rosnącej.
Włącz interpretację rezerwacji operatora
Aby ulepszyć interpretację zapytania, możesz też użyć wbudowanych operatorów type, before, after i objecttype. Podczas indeksowania dokumentu:
Wypełnij pole
updateTimewItemMetadata, aby używać operatorówbeforeiafter. Te ustawienia umożliwiają Cloud Search wykonywanie tych interpretacji zapytań:- „filmy z ostatniego tygodnia” zawierałyby wszystkie filmy, które zostały zaktualizowane w indeksie w poprzednim tygodniu.
- „movies before jan 2019” (filmy sprzed stycznia 2019 r.) wyświetli wszystkie filmy, które zostały zindeksowane przed styczniem 2019 r.
Aby korzystać z automatycznego wykrywania typu, wypełnij pole
mimeTypew elementachItemMetadata. Zapytanie „filmy akcji” wyświetli wszystkie dokumenty filmów akcji o typie mimeapplication/mp4,application/mpeg4,application/x-shockwave-flash,video/iapplication/vnd.google-apps.video.
Ograniczenia interpretacji zapytań
Funkcja interpretacji zapytań ma te ograniczenia:
- Interpretacja zapytań działa tylko w przypadku tych list kontroli dostępu źródeł danych:
- Wszystkie dokumenty są publiczne w domenie (każdy w domenie ma do nich dostęp).
- Wszystkie dokumenty są publiczne (mogą je zobaczyć wszyscy, którzy mają dostęp do źródła danych).
- Większość dokumentów w źródle danych ma tę samą listę kontroli dostępu (wszystkie dokumenty dziedziczą listę kontroli dostępu z tego samego elementu kontenera) bez zdefiniowanych dodatkowych czytników.
- Jeśli kilka operatorów schematu ma tę samą wartość, interpretacja tej wartości jako intencji operatora w zapytaniu zależy od ogólnego współczynnika pewności zwróconego przez system interpretacji zapytań. Załóżmy na przykład, że masz właściwości
priorityiseverityz tymi samymi nazwami operatorów zdefiniowanymi w schemacie. Załóżmy, że oba operatory mogą mieć wartości 0, 1, 2 lub 3. W tym przykładzie wartość „0” w zapytaniu może odnosić się do wartości operatoraprioritylubseverity. Te wartości są niejednoznaczne, a poziom ufności jest niższy. - Domyślnie podczas interpretacji zapytania Cloud Search ignoruje wielkość liter w wartościach pól, z wyjątkiem operatorów tekstowych zdefiniowanych za pomocą opcji
exactMatchWithOperator. - Operator
sourcenie jest obsługiwany w zapytaniach. - Zapytania, które łączą terminy oparte na operatorach i terminy w formie dowolnego tekstu, nie są interpretowane. Na przykład zapytanie „p0 priorytetowe przypadki:poważny:s0” nie będzie obsługiwane, ponieważ „p0 priorytetowe przypadki” to termin z tekstem dowolnym, a „poważny:s0” to termin z operatorem.
- Strategia interpretacji zapytań zawsze łączy interpretowane wyniki z zwykłymi (nieinterpretowanymi, uporządkowanymi według trafności) wynikami. Nie powoduje pełnego zastąpienia wyników.