
התכונה פירוש שאילתות ב-Cloud Search מפרשת באופן אוטומטי את האופרטורים והמסננים בשאילתה של משתמש, וממירה את הרכיבים האלה לשאילתה מובנית שמבוססת על אופרטור. לצורך פענוח השאילתות נעשה שימוש באופרטורים שמוגדרים בסכימה, יחד עם המסמכים שנוספו לאינדקס, כדי להסיק מה המשמעות של השאילתה של המשתמש. תכונה זו מאפשרת למשתמש לחפש עם מספר מינימלי של מילות מפתח, ועדיין לקבל תוצאות מדויקות.
התוצאות שמוצגות למשתמש בפועל תלויות בביטחון של פרשנות השאילתה. המהימנות מבוססת על כמה גורמים, כולל המיקום שבו מחרוזות השאילתה מופיעות במסמכים שנוספו לאינדקס. מחרוזת, כמו השם של השחקן טום הנקס, שמופיעה באופן עקבי בשדה בסכימה שנקרא actors, משפרת את רמת הסמך. אותה מחרוזת ("Tom Hanks") שמופיעה בפסקה, במקום בשדה הסכימה, עלולה להוביל לרמת סמך נמוכה יותר. במקרה של רמת מהימנות גבוהה, רק תוצאות מפרשנות השאילתה מוצגות למשתמש. במקרה של רמת מהימנות נמוכה יותר, התוצאות מפרשנות השאילתה ימוזגו עם תוצאות חיפוש רגילות של מילות מפתח.
דוגמה לפרשנות שאילתה
נניח שיש לכם מקור נתונים, כמו מסד נתונים, שמכיל מידע על סרטים. איור 1 מציג שאילתת חיפוש לדוגמה ואת הפרשנות שהתקבלה.
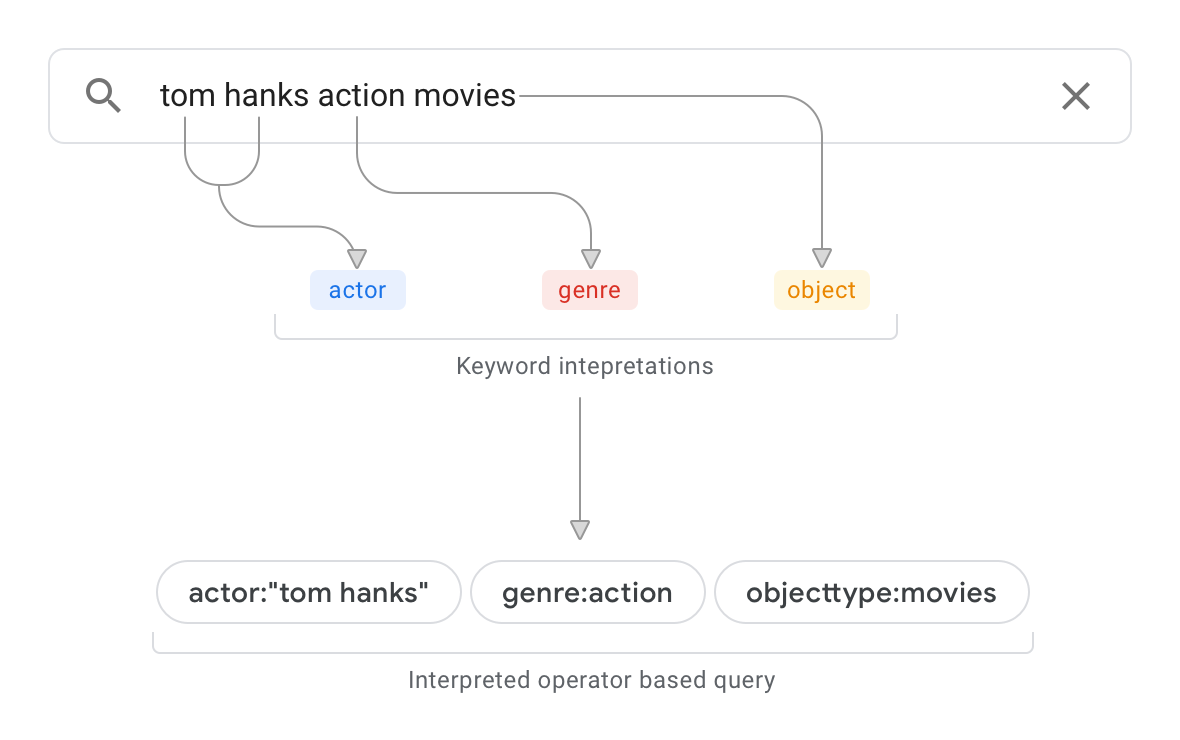
על סמך השאילתה לדוגמה הזו, פרשנות השאילתות מתבצעת:
מנתח את הסכימה וקובע שהאובייקטים ברמה העליונה במקור הנתונים מסווגים כ-
objecttype:movies. כיום, פרשנות השאילתות נדע ש"סרטים" בשאילתה הם סוג אובייקט.הפונקציה סורקת מסמכים במקור הנתונים, בשילוב עם הסכימה, כדי לקבוע איפה תופיע המחרוזת "action". אם המחרוזת מופיעה בעיקר בשדה ספציפי של מקור נתונים 'ז'אנר', לפי פירוש השאילתה, ברור ש-'action' הוא ערך המאפיין של המאפיין 'ז'אנר' כמוגדר בסכימה. אם המחרוזת מופיעה בעיקר בהקשר של פסקאות תוכן, רמת הסמך של פרשנות השאילתות יורדת.
פרשנות השאילתה שתתקבל היא:
actor:“tom hanks” genre:action objecttype:movies
פרשנות השאילתות מופעלת באופן אוטומטי לכל לקוחות Cloud Search, ללא צורך בפעולות נוספות. עם זאת, כדי לפרש את השאילתות בצורה אופטימלית, כדאי לבנות את הסכימה בהתאם להוראות במסמך הזה.
בניית הסכימה לתמיכה בפרשנות שאילתות
כדאי לבנות את הסכימה כך שתוכלו להפיק תועלת מפירוש השאילתות.
הפעלת פירושים של שמות מוצגים
הפרשנות של השאילתות ב-Cloud Search משתמשת בסכימה objectDefinitions ו-propertyDefinitions כדי לפרש את שאילתת המשתמש ולכוונן את התוצאות. כדי להפיק את המרב מהרכיבים האלה, כדאי ליצור שמות תצוגה אינטואיטיביים באמצעות displayLabel לשמות נכסים, objectDisplayLabel לשמות אובייקטים ו-operatorName לאופרטורים.
הסכימה הבאה מציגה שמות מוצגים אינטואיטיביים לאובייקט של סרט:
{
"objectDefinitions": [
{
"name": "movie",
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
...
},
"propertyDefinitions": [
{
"name": "genre",
"isReturnable": true,
"isRepeatable": true,
"isFacetable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "genre"
}
},
"displayOptions": {
"displayLabel": "Category"
}
},
...
]
}
]
}
בדוגמה הקודמת:
בהגדרת אובייקט הסרט יש
objectDisplayLabel'סרט'.למאפיין הז'אנר יש 'ז'אנר'
operatorNameו'קטגוריה'displayLabel.
השמות לתצוגה האלה מאפשרים ל-Cloud Search ליצור את פרשנויות השאילתות הבאות:
- המונח 'סרטי פעולה', 'סרטי פעולה בז'אנר' או 'פעולה בז'אנר של סרטים' יתפרש כ-
genre:action object:movies. - "סרטים עם ז'אנר או מותחן" מפוענחים בתור
objecttype:movies genre:(action OR thriller). - המונח "סרט פעולה" או "סרטי פעולה" יתפרש בתור
genre:action objecttype:movies. - המונח 'סרטים בקטגוריית קומדיה' מפוענח כ-
genre:comedy objecttype:movies.
הפעלה של פירושי תאריך, מספרי ומיון
צריך להגדיר את lessThanOperatorName ואת greaterThanOperatorName שצוינו בשדה IntegerOperatorOptions לכל מאפייני התאריך והמאפיינים המספריים. ההגדרות האלה מאפשרות הצגה אוטומטית של תאריך ופרשנויות מספריות. בנוסף, כדי להפעיל פירושי מיון, צריך להגדיר את האפשרות isSortable למאפיינים של תאריך ומספרים. בסכימה הבאה מוסבר איך להפעיל את האפשרויות האלה.
{
"objectDefinitions": [
{
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
},
"propertyDefinitions": [
{
"name": "runtime",
"isReturnable": true,
"isSortable": true,
"integerPropertyOptions": {
"orderedRanking": "DESCENDING",
"minimumValue": {
"value": 10
},
"maximumValue": {
"value": 500
},
"operatorOptions": {
"operatorName": "runtime",
"lessThanOperatorName": "runtimelessthan",
"greaterThanOperatorName": "runtimegreaterthan"
}
},
"displayOptions": {
"displayLabel": "Length"
}
},
{
"name": "releasedate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "releasedate",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}
]
}
בדוגמה הקודמת:
- המאפיין המספרי
runtimeמתייחס לאורך של סרט. הערכיםruntimelessthanוגםruntimegreaterthanמוגדרים לנכס הזה. - מאפיין התאריך
releaseDateמתייחס למועד שבו סרט מופץ בבתי הקולנוע. ההגדרותreleasedbeforeוגםreleasedafterהוגדרו לנכס הזה.
ההגדרות האלה מאפשרות ל-Cloud Search ליצור את פרשנויות השאילתות הבאות:
- בהנחה שהשנה היא 2019, הערך "סרטים שיצאו השנה" יפורש בתור
objecttype: movies releasedafter:2019-1-1 releasedbefore:2019-12-31. - בהנחה שהשבוע הוא השבוע השלישי בחודש מרץ, הפירוש של "סרטים שפורסמו בשבוע שעבר" הוא
objecttype: movies releasedafter:2019-3-10 releasedbefore:2019-3-16 - "סרטים עם זמן ריצה קטן מ-90" יפורשו כ-
objjecttype: movies runtimelessthan:90. - בהנחה שהשנה היא 2019, הערך "סרטים שיצאו השנה והאורך שלהם עולה על 120" יפורש כ-
releasedafter:2019-1-1 releasedbefore:2019-12-31 objecttype:movies runtimegreaterthan:120. - "מיון סרטים לפי תאריך הפצה" יסנן לפי "objecttype: Movies", והתוצאות שיוצגו ימוינו לפי תאריך הפרסום, וסדר המיון שהוגדר כברירת מחדל יהיה בסדר עולה.
הפעלה של פירוש אופרטור שמור
אפשר גם להשתמש באופרטורים המובנים השמורים ל-type, before, after, objecttype כדי לשפר את פרשנות השאילתות. כשמוסיפים מסמך לאינדקס:
כדי להשתמש באופרטורים
beforeו-after, צריך לאכלס את השדהupdateTimeב-ItemMetadata. ההגדרות האלה מאפשרות ל-Cloud Search ליצור את פירושי השאילתות הבאות:- בקטע 'סרטים מהשבוע שעבר' יוצגו כל הסרטים שעודכנו באינדקס בשבוע הקודם.
- ברשימה "סרטים לפני ינואר 2019" יופיעו כל הסרטים שנוספו לאינדקס לפני ינואר 2019.
מאכלסים את השדה
mimeTypeב-ItemMetadataכדי להשתמש בזיהוי אוטומטי של סוג. בשאילתה 'סרטוני פעולה' יופיעו כל המסמכים של סרטי פעולה עם סוג MIME שלapplication/mp4,application/mpeg4,application/x-shockwave-flash,video/ו-application/vnd.google-apps.video.
מגבלות על פרשנות שאילתות
לתכונת פרשנות השאילתות יש את המגבלות הבאות.
- פירוש השאילתות פועל רק ברשימות ה-ACL הבאות של מקור הנתונים:
- כל המסמכים מוגדרים כציבוריים בדומיין (לכל מי שבדומיין יש גישה).
- כל המסמכים הם מקור נתונים ציבוריים (כל מי שיש לו גישה ל-ACL של מקור הנתונים).
- לרוב המסמכים במקור הנתונים יש אותה רשימת ACL (כל המסמכים יורשים ACL מאותו פריט מאגר), ללא הגדרה של קוראים נוספים.
- אם למספר אופרטורים של סכימה יש ערך זהה, הפרשנות של הערך הזה ל-Intent של אופרטור בשאילתה תלויה בגורם המהימנות הכולל שהוחזר על ידי המערכת מפרשת השאילתות. לדוגמה, נניח שיש לכם את המאפיינים
priorityו-severityעם אותם שמות אופרטורים שמוגדרים בסכימה. נניח ששני האופרטורים יכולים לקבל את הערכים 0, 1, 2 או 3. בדוגמה הזו, "0" בשאילתה יכול להתייחס לערך האופרטור שלpriorityאוseverity. הערכים האלה לא ברורים ורמת הסמך נמוכה יותר. - כברירת מחדל, הפרשנות של שאילתות ב-Cloud Search מפחיתה את גודל האותיות
של ערכי השדות כשמפרשים את השאילתה, חוץ מהאופרטורים של טקסט שמוגדרים עם האפשרויות של
exactMatchWithOperator. - האופרטור
sourceלא נתמך בשאילתות. - שאילתות שמשלבות מונחים המבוססים על אופרטורים ומונחים של טקסט חופשי לא מתפרשות. לדוגמה, לא תהיה תמיכה בשאילתה 'p0 שהיא מקרי עדיפות של רמת חומרה:s0' כי 'מקרים בעדיפות p0' היא מונח שמבוסס על טקסט חופשי, ואילו 'מידת חוּמרה:s0' היא מונח שמבוסס על אופרטורים.
- האסטרטגיה של פרשנות השאילתות משלבת תמיד את התוצאות המפוענחות עם תוצאות רגילות (שאינן מתפרשות, לפי דירוג רלוונטיות). לא ניתן להחליף את התוצאות בדף מלא.