
借助 Connector SDK 和 Google Cloud Search API,您可以创建 Cloud Search 索引队列,以用来执行以下任务:
维护每个文档的多方面状况(状态、哈希值等),以便用于确保索引与存储区保持同步。
维护在遍历过程中发现的一系列项以将其编入索引。
根据项的状态确定该项在队列中的优先级。
维护其他状态信息(如检查点、更改标记等),以确保高效集成。
队列是分配给编入索引的项的标签,例如默认队列的“default”或队列 B 的“B”。
状态和优先级
文档在队列中的优先级取决于其 ItemStatus 代码。下面按优先级顺序(即从第一个处理到最后一个处理的顺序)列出了可用的 ItemStatus 代码:
ERROR- 将项编入索引期间发生了异步错误,并且需要重新编入索引。MODIFIED- 已编入索引的项自上次编入索引后在存储区中发生了修改。NEW_ITEM- 未编入索引的项。ACCEPTED- 已编入索引的文档自上次编入索引后在存储区中未发生更改。
如果队列中的两个项具有相同状态,则在队列中停留时间最长的项将被赋予更高优先级。
简要介绍如何使用索引编制队列将新项或已更改的项编入索引
图 1 显示了使用索引队列为新项或更改后的项编入索引的步骤。以下步骤显示了 REST API 调用。如需了解等效的 SDK 调用,请参阅队列操作 (Connector SDK)。
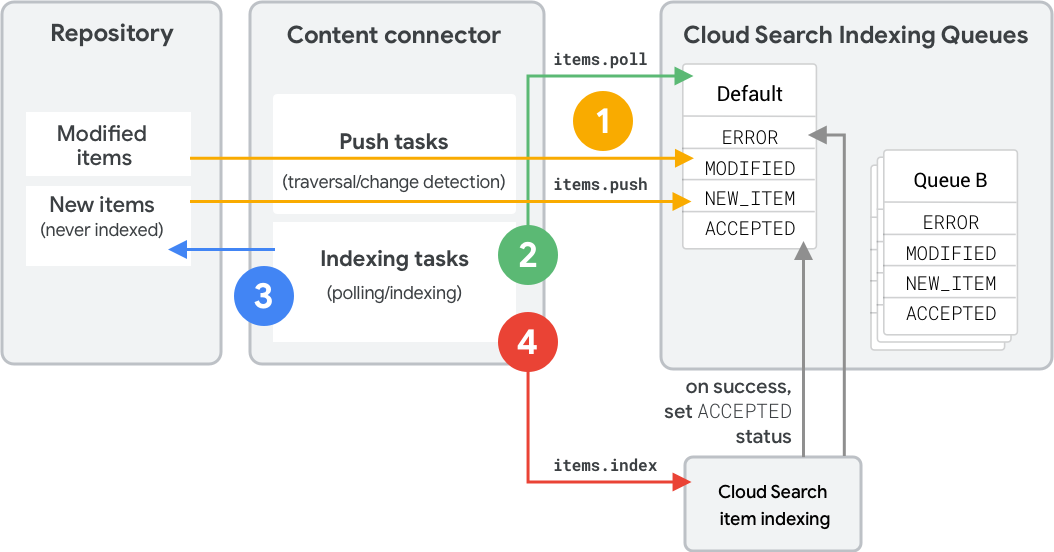
内容连接器使用
items.push将项(元数据和哈希)推送到索引队列中,以建立项的状态(MODIFIED、NEW_ITEM、DELETED)。具体而言:- 推送时,连接器会明确包含推送
type或contentHash。 - 如果连接器不包含
type,则 Cloud Search 会自动使用contentHash来确定项目的状态。 - 如果商品未知,则商品状态会设置为
NEW_ITEM。 - 如果相应项存在且哈希值匹配,则状态保持为
ACCEPTED。 - 如果相应内容存在且哈希值不同,则状态变为
MODIFIED。
如需详细了解如何确定商品状态,请参阅 Cloud Search 使用入门教程中的遍历 GitHub 代码库示例代码。
通常,推送与连接器中的内容遍历和/或更改检测进程相关联。
- 推送时,连接器会明确包含推送
内容连接器使用
items.poll轮询队列,以确定要编入索引的项。Cloud Search 会告知连接器哪些项最需要编入索引,并按状态代码和队列中等待时间对这些项进行排序。连接器从代码库中检索这些项,并构建索引 API 请求。
连接器使用
items.index为项编入索引。只有在 Cloud Search 成功处理完内容后,内容才会进入ACCEPTED状态。
如果某个项已不再存在于代码库中,连接器还可以将其删除;如果该项未经修改或存在源代码库错误,则可以再次推送该项。如需了解如何删除商品,请参阅下一部分。
简要介绍如何使用索引编制队列删除项
完全遍历策略使用双队列进程来将项编入索引并检测删除操作。图 2 显示了使用两个索引队列删除项的步骤。具体而言,图 2 显示了使用完整遍历策略执行的第二次遍历。这些步骤使用 REST API 调用。如需了解等效的 SDK 调用,请参阅队列操作 (Connector SDK)。
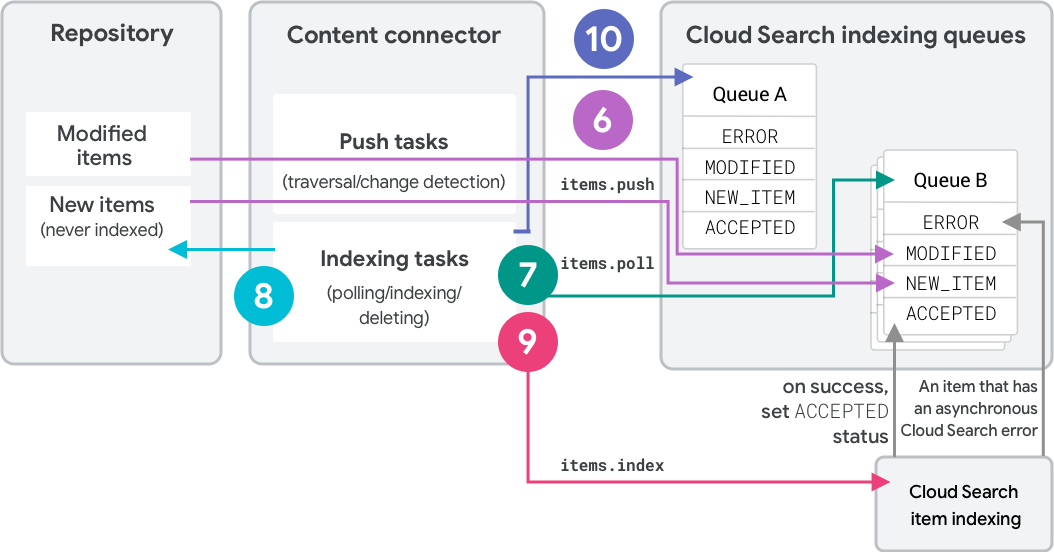
在初始遍历时,内容连接器使用
items.push将项(元数据和哈希)推送到索引队列“队列 A”,并将其标记为NEW_ITEM,因为它不存在于队列中。每个项都分配了“队列 A”的标签“A”。系统会将内容编入 Cloud Search 的索引。内容连接器使用
items.poll轮询队列 A,以确定要编入索引的项。Cloud Search 会告知连接器哪些项最需要编入索引,并按状态代码和队列中等待时间对这些项进行排序。连接器会从代码库中检索这些项,并构建索引 API 请求。
连接器使用
items.index将项编入索引。只有在 Cloud Search 成功处理完内容后,内容才会进入ACCEPTED状态。系统会对“队列 B”调用
deleteQueueItems方法。但是,没有任何内容已推送到队列 B,因此无法删除任何内容。在第二次完整遍历时,内容连接器使用
items.push将项(元数据和哈希)推送到队列 B:- 推送时,连接器会明确包含推送
type或contentHash。 - 如果连接器不包含
type,则 Cloud Search 会自动使用contentHash来确定项目的状态。 - 如果项目未知,则项目状态会设为
NEW_ITEM,并且队列标签会更改为“B”。 - 如果相应项存在且哈希值匹配,则状态保持为
ACCEPTED,队列标签会更改为“B”。 - 如果相应内容存在且哈希值不同,状态会变为
MODIFIED,队列标签会更改为“B”。
- 推送时,连接器会明确包含推送
内容连接器使用
items.poll轮询队列,以确定要编入索引的项。Cloud Search 会告知连接器哪些项最需要编入索引,并按状态代码和队列中等待时间对项进行排序。连接器会从代码库中检索这些项,并构建索引 API 请求。
连接器使用
items.index将项编入索引。只有在 Cloud Search 成功处理完内容后,内容才会进入ACCEPTED状态。最后,系统会对队列 A 调用
deleteQueueItems,以删除之前已编入索引但仍然具有队列“A”标签的所有 CCloud Search 项。在后续的完整遍历中,用于编制索引的队列和用于删除的队列会互换。
队列操作 (Connector SDK)
借助 Content Connector SDK,您可以将项推送到队列中,以及从队列中拉取项。
如需打包某个项并将其推送到队列中,请使用 pushItems 构建器类。
要从队列中拉取项以进行处理,您无需执行任何特定操作。而是会使用 Repository 类的 getDoc 方法按优先级顺序从队列中拉取项。
队列操作 (REST API)
通过 REST API,您可以分别使用以下两个方法将项推送到队列中以及从队列中拉取项:
- 如需将项推送到队列中,请使用
Items.push。 - 如需轮询队列中的项,请使用
Items.poll。
您还可以使用 Items.index 在索引编制期间将项推送到队列中。在编入索引期间推送到队列的项不需要 type,并且会自动分配 ACCEPTED 状态。
Items.push
Items.push 方法可将 ID 添加到队列中。此方法可使用特定 type 值调用,该值决定了推送操作的结果。如需查看 type 值的列表,请参阅 Items.push 方法中的 item.type 字段。
推送新 ID 会添加一个包含 NEW_ITEM
ItemStatus 代码的新条目。
可选载荷始终会作为不透明值进行存储,并通过 Items.poll 返回。
轮询某个项时,系统会预留该项,这意味着您无法通过再次调用 Items.poll 返回该项。将 Items.push 与 type 作为 NOT_MODIFIED、REPOSITORY_ERROR 或 REQUEUE 搭配使用时,会取消预留轮询条目。如需详细了解预留条目和未预留条目,请参阅 Items.poll 部分。
Items.push(采用哈希值)
Google Cloud Search API 支持在 Items.index 请求中指定元数据和内容哈希值。可以通过推送请求指定元数据和/或内容哈希值,而不指定 type。Cloud Search 索引队列会将提供的哈希值与数据源中该项对应的存储值进行比较。如果不匹配,则该条目将被标记为 MODIFIED。如果索引中不存在相应项,则状态为 NEW_ITEM。
Items.poll
Items.poll 方法用于从队列中检索具有最高优先级的条目。请求的状态值和返回的状态值分别指示所请求优先级队列的状态和所返回 ID 的状态。
默认情况下,系统可以根据优先级返回任意队列部分中的条目。除非出现以下任一情况,否则返回的每个条目都会被预留,并且无法通过对 Items.poll 进行其他调用返回:
- 预留超时。
Items.index将该条目再次加入队列。- 使用
type值NOT_MODIFIED、REPOSITORY_ERROR或REQUEUE调用Items.push。