
Schemat Google Cloud Search to struktura JSON, która definiuje obiekty, właściwości i opcje używane do indeksowania i przesyłania zapytań do danych. Oprogramowanie sprzęgające treści odczytuje dane z Twojego repozytorium i na ich podstawie uporządkuje je oraz utworzy ich indeks na podstawie zarejestrowanego schematu.
Aby utworzyć schemat, prześlij do interfejsu API obiekt schematu w formacie JSON, a potem go zarejestruj. Zanim zaczniesz indeksować dane, musisz zarejestrować obiekt schematu dla każdego repozytorium.
Ten dokument zawiera podstawowe informacje o tworzeniu schematów. Informacje o dostrajaniu schematu w celu poprawy wyników wyszukiwania znajdziesz w artykule Poprawianie jakości wyszukiwania.
Tworzenie schematu
Oto lista czynności, które należy wykonać, aby utworzyć schemat Cloud Search:
- Określanie oczekiwanego zachowania użytkowników
- Inicjowanie źródła danych
- Tworzenie schematu
- Pełny przykładowy schemat
- Rejestrowanie schematu
- Indeksowanie danych
- Testowanie schematu
- Dostosowywanie schematu
Określanie oczekiwanego zachowania użytkowników
Przewidywanie typów zapytań użytkowników pomaga określić strategię tworzenia schematu.
Na przykład podczas wysyłania zapytań do bazy danych filmów możesz przewidzieć, że użytkownik wyśle zapytanie takie jak „Pokaż wszystkie filmy z Robertem Redfordem”. Dlatego schemat musi obsługiwać wyniki zapytań oparte na „wszystkich filmach z występem określonego aktora”.
Aby zdefiniować schemat, który odzwierciedla wzorce zachowań użytkowników, wykonaj te czynności:
- Oceniać różne zestawy zapytań pochodzące od różnych użytkowników.
- Określ obiekty, które mogą być używane w zapytaniach. Obiekty to logiczne zbiory powiązanych danych, np. film w bazie danych filmów.
- Określ właściwości i wartości, z których składa się obiekt i które mogą być używane w zapytaniach. Właściwości to indeksowalne atrybuty obiektu. Mogą one zawierać wartości prymitywne lub inne obiekty. Na przykład obiekt filmu może mieć właściwości takie jak tytuł filmu i data premiery jako wartości proste. Obiekt filmu może też zawierać inne obiekty, takie jak członkowie obsady, które mają własne właściwości, takie jak imię i nazwisko lub rola.
- Przykładowe prawidłowe wartości właściwości. Wartości to rzeczywiste dane posortowane według właściwości. Na przykład tytuł jednego z filmów w Twojej bazie danych może brzmieć „Poszukiwacze zaginionej arki”.
- Określ opcje sortowania i rankingu, których oczekują użytkownicy. Na przykład podczas wyszukiwania filmów użytkownicy mogą chcieć je sortować według chronologii i oceny przez widzów, a nie alfabetycznie według tytułu.
- (Opcjonalnie) Zastanów się, czy jedna z Twoich usług reprezentuje bardziej szczegółowy kontekst, w którym mogą być wykonywane wyszukiwania, np. stanowisko lub dział użytkownika, aby sugestie autouzupełniania mogły być wyświetlane na podstawie tego kontekstu. Na przykład w przypadku osób szukających w bazie danych filmów użytkownicy mogą być zainteresowani tylko określonym gatunkiem filmów. Użytkownicy mogliby definiować, jakiego gatunku mają być wyniki wyszukiwania, prawdopodobnie w ramach swojego profilu. Gdy użytkownik zacznie wpisywać zapytanie dotyczące filmów, w ramach sugestii autouzupełniania zostaną wyświetlone tylko filmy z jego ulubionego gatunku, np. „filmy akcji”.
- Utwórz listę tych obiektów, właściwości i przykładowych wartości, które można stosować w wyszukiwaniach. (szczegółowe informacje o sposobie używania tej listy znajdziesz w sekcji Definiowanie opcji operatora).
Inicjowanie źródła danych
Źródło danych reprezentuje dane z repozytorium, które zostały zindeksowane i zapisane w Google Cloud. Instrukcje inicjowania źródła danych znajdziesz w artykule Zarządzanie zewnętrznymi źródłami danych.
Wyniki wyszukiwania użytkownika są zwracane ze źródła danych. Gdy użytkownik kliknie wynik wyszukiwania, Cloud Search przekieruje go do rzeczywistego produktu za pomocą adresu URL podanego w żądaniu indeksowania.
Definiowanie obiektów
Podstawową jednostką danych w schemacie jest obiekt, zwany też „obiektem schematu”. Jest to logiczna struktura danych. W bazie danych filmów jedna z logicznych struktur danych to „film”. Innym obiektem może być „osoba”, która reprezentuje obsadę i ekipę filmową.
Każdy obiekt w schemacie ma serię właściwości lub atrybutów, które opisują obiekt, takich jak tytuł i czas trwania filmu lub imię i data urodzenia osoby. Właściwości obiektu mogą zawierać wartości prymitywne lub inne obiekty.
Rysunek 1 przedstawia obiekty film i osoba oraz powiązane z nimi właściwości.
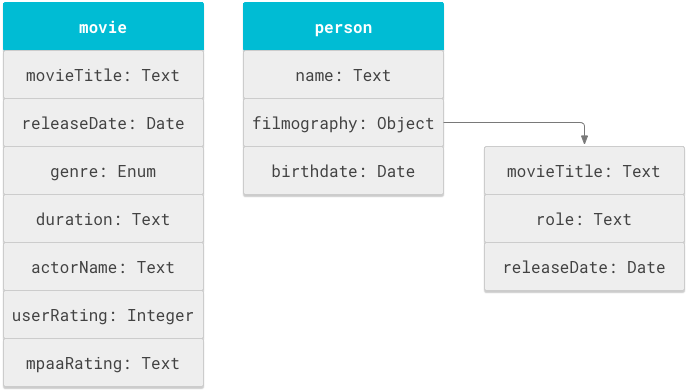
Schemat Cloud Search to w podstawie lista definicji obiektów zdefiniowanych w tagu objectDefinitions. Ten fragment schematu pokazuje instrukcje objectDefinitions dotyczące obiektów schematu filmu i osoby.
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
Podczas definiowania obiektu schematu podajesz dla niego name, który musi być unikalny wśród wszystkich innych obiektów w schemacie. Zwykle używasz wartości name, która opisuje obiekt, np. movie dla obiektu filmu. Schemat usługi używa pola name jako klucza identyfikatora obiektów możliwych do zindeksowania. Więcej informacji o polu name znajdziesz w definicji obiektu.
Definiowanie właściwości obiektu
Zgodnie z informacjami podanymi w dokumentacji dotyczącej ObjectDefinition nazwa obiektu jest poprzedzona zestawem options i listą propertyDefinitions.
options może się składać z freshnessOptionsi displayOptions.
freshnessOptions
służą do dostosowywania rankingu wyszukiwania na podstawie aktualności produktu. Parametry displayOptions służą do określania, czy w wynikach wyszukiwania obiektu mają się wyświetlać określone etykiety i właściwości.
W sekcji
propertyDefinitions
określasz właściwości obiektu, takie jak tytuł filmu i data premiery.
Ten fragment kodu przedstawia obiekt movie z 2 właściwościami: movieTitle i releaseDate.
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
Element PropertyDefinition składa się z tych elementów:
- ciąg tekstowy
name. - Lista opcji niezależnych od typu, takich jak
isReturnablew poprzednim fragmencie kodu. - typ i powiązane z nim opcje, takie jak
textPropertyOptionsiretrievalImportancew poprzednim fragmencie kodu. operatorOptionsopisujący sposób użycia tej właściwości jako operatora wyszukiwania.- Co najmniej 1 element
displayOptions, np.displayLabelw poprzednim fragmencie kodu.
name usługi musi być unikalny w ramach obiektu zawierającego,
ale ta sama nazwa może być używana w innych obiektach i podobiektach.
Na rysunku 1 tytuł i data premiery filmu zostały zdefiniowane dwukrotnie: raz w obiekcie movie i ponownie w podrzędnym obiekcie filmography obiektu person. Ten schemat ponownie używa pola movieTitle, aby obsługiwać dwa typy zachowań wyszukiwania:
- wyświetlać wyniki wyszukiwania filmów, gdy użytkownicy wyszukują tytuł filmu;
- wyświetlać wyniki dotyczące osób, gdy użytkownicy wyszukują tytuł filmu, w którym zagrał dany aktor.
Podobnie schemat ponownie używa pola releaseDate, ponieważ ma ono to samo znaczenie w przypadku obu pól movieTitle.
Podczas tworzenia własnego schematu zastanów się, czy Twój repozytorium może zawierać powiązane pola, które zawierają dane, które chcesz zadeklarować więcej niż raz w schemacie.
Dodawanie opcji niezależnych od typu
Element PropertyDefinition zawiera listę ogólnych opcji funkcji wyszukiwania wspólnych dla wszystkich usług niezależnie od typu danych.
isReturnable– wskazuje, czy usługa identyfikuje dane, które powinny być zwracane w wynikach wyszukiwania za pomocą Query API. Wszystkie przykładowe właściwości filmów można zwrócić. Właściwości, których nie można zwracać, mogą być używane do wyszukiwania lub rankingowania wyników bez zwracania ich użytkownikowi.isRepeatable– wskazuje, czy w przypadku właściwości dozwolone są liczne wartości. Na przykład film ma tylko jedną datę premiery, ale może mieć wielu aktorów.isSortable– wskazuje, że właściwość może być używana do sortowania. Nie można tego zrobić w przypadku właściwości, które są powtarzalne. Na przykład wyniki dotyczące filmów mogą być sortowane według daty premiery lub oceny widzów.isFacetable– wskazuje, że właściwość może być używana do generowania aspektów. Aspekt służy do doprecyzowania wyników wyszukiwania. Użytkownik widzi początkowe wyniki, a potem dodaje kryteria (czyli aspekty), aby jeszcze bardziej zawęzić wyniki. Ta opcja nie może być ustawiona na „prawda” w przypadku właściwości, których typ to obiekt, a aby ustawić tę opcję, musi być ustawiona wartość „prawda” w poluisReturnable. Ta opcja jest obsługiwana tylko w przypadku właściwości typu enum, boolean i text. Na przykład w naszym przykładowym schemacie możemy utworzyć kolumnygenre,actorName,userRatingimpaaRating, aby można było ich używać do interaktywnego doprecyzowania wyników wyszukiwania.isWildcardSearchableoznacza, że użytkownicy mogą wyszukiwać w tej usłudze za pomocą symboli zastępczych. Ta opcja jest dostępna tylko w przypadku właściwości tekstowych. Sposób działania wyszukiwania z użyciem symboli wieloznacznych w polu tekstowym zależy od wartości ustawionej w polu exactMatchWithOperator. Jeśli parametrexactMatchWithOperatorma wartośćtrue, wartość tekstowa jest dzielona na tokeny jako jedna wartość atomowa, a następnie przeprowadzane jest wyszukiwanie z użyciem symboli wieloznacznych. Jeśli np. wartość tekstowa toscience-fiction, zapytanie z symbolem wieloznaczeniowymscience-*będzie do niego pasować. Jeśli parametrexactMatchWithOperatorma wartośćfalse, wartość tekstowa jest dzielona na tokeny, a w przypadku każdego z nich jest wykonywane wyszukiwanie z użyciem symboli wieloznacznych. Jeśli np. wartość tekstowa to „science-fiction”, zapytania z symbolami wieloznacznymisci*lubfi*pasują do elementu, alescience-*do niego nie pasuje.
Te parametry funkcji ogólnych wyszukiwania mają wartości logiczne. Wszystkie mają wartość domyślną false i aby mogły być używane, muszą mieć wartość true.
W tabeli poniżej przedstawiono parametry logiczne ustawione na wartość true dla wszystkich właściwości obiektu movie:
| Właściwość | isReturnable |
isRepeatable |
isSortable |
isFacetable |
isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle |
prawda | prawda | |||
releaseDate |
prawda | prawda | |||
genre |
prawda | prawda | prawda | ||
duration |
prawda | ||||
actorName |
prawda | prawda | prawda | prawda | |
userRating |
prawda | prawda | |||
mpaaRating |
prawda | prawda |
W przypadku genre i actorName wartość isRepeatable to true, ponieważ film może należeć do więcej niż jednego gatunku i zazwyczaj ma więcej niż jednego aktora. Właściwości nie można sortować, jeśli jest ona powtarzalna lub zawarta w powtarzalnym podobiekcie.
Zdefiniuj typ
W sekcji referencyjnej PropertyDefinition wymieniono kilka wartości xxPropertyOptions, gdzie xx to konkretny typ, np. boolean. Aby ustawić typ danych właściwości, musisz zdefiniować odpowiedni obiekt typu danych. Zdefiniowanie obiektu typu danych dla właściwości ustala typ danych tej właściwości. Na przykład zdefiniowanie wartości textPropertyOptions dla właściwości movieTitle wskazuje, że tytuł filmu jest typu text. Poniższy fragment kodu pokazuje właściwość movieTitle z ustawieniem textPropertyOptions typu danych.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
Z usługą może być powiązany tylko 1 typ danych. Na przykład w schemacie filmu releaseDate może być tylko datą (np. 2016-01-13) lub ciąg znaków (np. January 13, 2016), ale nie obie.
Oto obiekty typu danych, które służą do określania typów danych właściwości w przykładzie schematu filmu:
| Właściwość | Obiekt typu danych |
|---|---|
movieTitle |
textPropertyOptions |
releaseDate |
datePropertyOptions |
genre |
enumPropertyOptions |
duration |
textPropertyOptions |
actorName |
textPropertyOptions |
userRating |
integerPropertyOptions |
mpaaRating |
textPropertyOptions |
Wybór typu danych dla usługi zależy od przewidywanych przypadków użycia.
W wyobrażonym scenariuszu tego schematu filmu użytkownicy chcą sortować wyniki według czasu, więc releaseDate jest obiektem daty.
Jeśli na przykład przewidywany jest przypadek użycia polegający na porównywaniu wydań z grudnia w poszczególnych latach z wydaniami z stycznia, przydatny może być format ciągu znaków.
Konfigurowanie opcji związanych z typem
W sekcji PropertyDefinition znajdziesz linki do opcji dotyczących poszczególnych typów. Większość opcji związanych z typem jest opcjonalna, z wyjątkiem listy possibleValues w sekcji enumPropertyOptions. Dodatkowo opcja orderedRanking umożliwia sklasyfikowanie wartości względem siebie. Poniższy fragment kodu pokazuje właściwość movieTitle z ustawieniem textPropertyOptions typu danych i opcją retrievalImportance dla danego typu.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
Oto dodatkowe opcje związane z typem użyte w przykładowym schemacie:
| Właściwość | Typ | Opcje dotyczące typu |
|---|---|---|
movieTitle |
textPropertyOptions |
retrievalImportance |
releaseDate |
datePropertyOptions |
|
genre |
enumPropertyOptions |
|
duration |
textPropertyOptions |
|
actorName |
textPropertyOptions |
|
userRating |
integerPropertyOptions |
orderedRanking, maximumValue |
mpaaRating |
textPropertyOptions |
Definiowanie opcji operatora
Oprócz opcji związanych z typem każdy typ zawiera też zestaw opcjonalnych opcji operatorOptions. Opcje te opisują sposób użycia właściwości jako operatora wyszukiwania. Poniższy fragment kodu pokazuje właściwość movieTitle z ustawieniem textPropertyOptions typu danych oraz opcjami retrievalImportance i operatorOptions.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
Każdy element operatorOptions ma element operatorName, np. title dla movieTitle. Nazwa operatora to operator wyszukiwania usługi. Operator wyszukiwania to parametr, którego użytkownicy mają używać podczas zawężania wyszukiwania. Aby na przykład wyszukać filmy na podstawie ich tytułu, użytkownik wpisze title:movieName, gdzie movieName to nazwa filmu.
Nazwy operatorów nie muszą być takie same jak nazwa usługi. Zamiast tego używaj nazw operatorów, które odzwierciedlają najczęściej używane przez użytkowników w organizacji słowa. Jeśli na przykład użytkownicy wolą, aby nazwa filmu była określana jako „nazwa” zamiast „tytuł”, nazwę operatora należy ustawić na „nazwa”.
Możesz używać tej samej nazwy operatora w przypadku wielu usług, o ile wszystkie usługi mają ten sam typ. Gdy w zapytaniu używasz nazwy operatora, który jest używany wspólnie, pobierane są wszystkie usługi, które używają tej nazwy. Załóżmy na przykład, że obiekt filmu ma właściwości plotSummary i plotSynopsis, a każda z tych właściwości ma wartość operatorName plot. Jeśli obie te właściwości są tekstowe (textPropertyOptions), można je odnaleźć za pomocą pojedynczego zapytania z operatorem wyszukiwania plot.
Oprócz właściwości operatorName właściwości, które można sortować, mogą zawierać pola lessThanOperatorName i greaterThanOperatorName w usługi operatorOptions.
Użytkownicy mogą używać tych opcji do tworzenia zapytań na podstawie porównań z podawaną wartością.
W zasobach operatorOptions tabela textOperatorOptions zawiera pole exactMatchWithOperator. Jeśli ustawisz parametr exactMatchWithOperator na true, ciąg zapytania musi pasować do całej wartości właściwości, a nie tylko występować w tekście.
Wartość tekstowa jest traktowana jako jedna wartość atomowa w wyszukiwaniach z operatorami i dopasowaniach na podstawie atrybutów.
Możesz na przykład zindeksować obiekty Book lub Movie za pomocą właściwości genre.
Gatunki mogą obejmować „Fantastyka naukowa”, „Nauka” i „Fabuła”. Jeśli parametr exactMatchWithOperator ma wartość false lub jest pominięty, wyszukiwanie gatunku albo wybranie filtra „Nauka” lub „Fikcyjny” spowoduje również wyświetlenie wyników dla „Nauka-Fikcyjny”, ponieważ tekst jest dzielony na tokeny, a tokeny „Nauka” i „Fikcyjny” występują w grupie „Nauka-Fikcyjny”.
Gdy exactMatchWithOperator to true, tekst jest traktowany jako pojedynczy element, więc ani „Science”, ani „Fiction” nie pasuje do „Science-Fiction”.
(Opcjonalnie) Dodaj sekcję displayOptions
Na końcu każdej sekcji propertyDefinition znajduje się opcjonalna sekcja displayOptions. Ta sekcja zawiera 1 ciąg displayLabel.
displayLabel to zalecana, przyjazna dla użytkownika etykieta tekstowa usługi. Jeśli właściwość jest wyświetlana za pomocą ObjectDisplayOptions, ta etykieta jest wyświetlana przed właściwością. Jeśli właściwość jest skonfigurowana do wyświetlania, a wartość displayLabel nie jest zdefiniowana, wyświetlana jest tylko wartość właściwości.
Ten fragment kodu pokazuje, że właściwości movieTitle z wartością displayLabel ma wartość „Title” (Tytuł).
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
Oto wartości displayLabel dla wszystkich właściwości obiektu movie w schemacie przykładowym:
| Właściwość | displayLabel |
|---|---|
movieTitle |
Title |
releaseDate |
Release date |
genre |
Genre |
duration |
Run length |
actorName |
Actor |
userRating |
Audience score |
mpaaRating |
MPAA rating |
(Opcjonalnie) Dodaj sekcję suggestionFilteringOperators[]
Na końcu każdej sekcji propertyDefinition znajduje się opcjonalna sekcja suggestionFilteringOperators[]. W tej sekcji zdefiniuj właściwość używaną do filtrowania sugestii autouzupełniania. Możesz na przykład zdefiniować operator genre, aby filtrować sugestie na podstawie ulubionego gatunku filmowego użytkownika. Gdy użytkownik wpisze zapytanie, w ramach sugestii autouzupełniania wyświetlą się tylko filmy pasujące do wybranego przez niego gatunku.
Rejestrowanie schematu
Aby z zapytań Cloud Search były zwracane dane strukturalne, musisz zarejestrować schemat w usłudze schematu Cloud Search. Rejestrowanie schematu wymaga identyfikatora źródła danych uzyskanego w kroku Inicjowanie źródła danych.
Użyj identyfikatora źródła danych, aby wysłać żądanie UpdateSchema i zarejestrować schemat.
Aby zarejestrować schemat, wyślij żądanie HTTP opisane na stronie referencyjnej UpdateSchema:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
Treść żądania powinna zawierać te informacje:
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
Aby przetestować poprawność schematu bez rejestrowania go, użyj opcji validateOnly.
Indeksowanie danych
Po zarejestrowaniu schematu wypełnij źródło danych za pomocą wywołań Index. Indeksowanie jest zwykle wykonywane w połączeniu treści.
Korzystając ze schematu filmu, żądanie indeksowania interfejsu API REST dla pojedynczego filmu będzie wyglądać tak:
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
Zwróć uwagę, że wartość movie w polu objectType jest zgodna z nazwą definicji obiektu w schemacie. Dzięki dopasowaniu tych dwóch wartości Cloud Search wie, którego obiektu schematu użyć podczas indeksowania.
Zwróć też uwagę, że indeksowanie właściwości schema releaseDate używa podwłaściwości year, month i day, które dziedziczy, ponieważ jest zdefiniowana jako typ danych date za pomocą właściwości datePropertyOptions.
Jednak ponieważ year, month i day nie są zdefiniowane w schemacie, nie możesz wysyłać zapytań dotyczących jednej z tych właściwości (np. year) indywidualnie.
Zwróć też uwagę, jak właściwość powtarzalna actorName jest indeksowana za pomocą listy wartości.
Identyfikowanie potencjalnych problemów z indeksowaniem
Oto 2 najczęstsze problemy związane ze schemami i indeksowaniem:
Twoje żądanie indeksowania zawiera nazwę obiektu lub właściwości schematu, która nie została zarejestrowana w usłudze schematu. Z tego powodu właściwość lub obiekt są ignorowane.
Żądanie indeksowania zawiera właściwość o wartości typu innej niż typ zarejestrowany w schemacie. Ten problem powoduje, że Cloud Search zwraca błąd podczas indeksowania.
Testowanie schematu za pomocą różnych typów zapytań
Zanim zarejestrujesz schemat dla dużego repozytorium danych produkcyjnych, przetestuj go na mniejszym repozytorium danych testowych. Testowanie za pomocą mniejszego repozytorium testowego pozwala szybko wprowadzać zmiany w schemacie i usuwać zindeksowane dane bez wpływu na większy indeks lub istniejący indeks produkcyjny. W przypadku testowego repozytorium danych utwórz regułę ACL, która upoważnia tylko testowego użytkownika, aby inni użytkownicy nie widzieli tych danych w wynikach wyszukiwania.
Aby utworzyć interfejs wyszukiwania służący do sprawdzania zapytań, zapoznaj się z artykułem Interfejs wyszukiwania.
Ta sekcja zawiera kilka przykładowych zapytań, których możesz użyć do przetestowania schematu filmu.
Testowanie za pomocą ogólnego zapytania
Zapytanie ogólne zwraca wszystkie elementy w źródle danych zawierające określoną ciąg znaków. Korzystając z interfejsu wyszukiwania, możesz przesłać ogólne zapytanie do źródła danych o filmach, wpisując słowo "titanic" i naciskając Return. W wynikach wyszukiwania powinny się pojawić wszystkie filmy zawierające słowo „titanic”.
Testowanie z użyciem operatora
Dodanie operatora do zapytania ogranicza wyniki do elementów pasujących do wartości operatora. Możesz na przykład użyć operatora actor, aby znaleźć wszystkie filmy z udziałem konkretnego aktora. Za pomocą interfejsu wyszukiwania możesz wykonać to zapytanie operatora, wpisując parę operator=wartość, np. „actor:Zane”, i naciskając Enter. W wynikach wyszukiwania powinny się pojawić wszystkie filmy z udziałem Zane’a.
Dostosowywanie schematu
Po użyciu schematu i danych nadal sprawdzaj, co działa, a co nie działa w przypadku użytkowników. Warto dostosować schemat w tych sytuacjach:
- indeksowanie pola, które nie było wcześniej indeksowane; Użytkownicy mogą na przykład wielokrotnie wyszukiwać filmy na podstawie nazwy reżysera, dlatego możesz dostosować schemat, aby obsługiwał nazwę reżysera jako operator.
- Zmiana nazw operatorów wyszukiwania na podstawie opinii użytkowników. Nazwy operatorów powinny być przyjazne dla użytkowników. Jeśli użytkownicy regularnie „zapamiętują” nieprawidłową nazwę operatora, rozważ zmianę tej nazwy.
Ponowne indeksowanie po zmianie schematu
Zmiana dowolnej z tych wartości w schemacie nie wymaga ponownego indeksowania danych. Wystarczy przesłać nowe żądanie UpdateSchema, a indeks będzie nadal działać:
- nazw operatorów;
- Minimalne i maksymalne wartości liczb całkowitych.
- Porządkowanie według liczb całkowitych i wartości wyliczonych.
- Opcje dotyczące aktualności.
- Opcje wyświetlania.
W przypadku tych zmian dane wcześniej zindeksowane będą nadal działać zgodnie z wcześniej zarejestrowanym schematem. Aby jednak zobaczyć zmiany oparte na zaktualizowanym schemacie, musisz ponownie zindeksować istniejące wpisy, jeśli zawiera on te zmiany:
- Dodawanie lub usuwanie nowej usługi lub obiektu
- Zmiana wartości
isReturnable,isFacetablelubisSortablezfalsenatrue.
Warto ustawić wartość isFacetable lub isSortable na true tylko, jeśli masz jasny przypadek użycia i potrzebę.
Gdy zaktualizujesz schemat, oznaczając usługę isSuggestable, musisz ponownie zindeksować dane, co powoduje opóźnienie w używaniu funkcji autouzupełniania w tej usłudze.
Niedozwolone zmiany właściwości
Niektóre zmiany schematu nie są dozwolone, nawet jeśli ponownie zindeksujesz dane, ponieważ mogą one spowodować uszkodzenie indeksu lub przynieść słabe lub niespójne wyniki wyszukiwania. Obejmują one zmiany w:
- Typ danych obiektu.
- Nazwa właściwości.
- Ustawienie
exactMatchWithOperator. - Ustawienie
retrievalImportance.
Można jednak obejść to ograniczenie.
Wprowadzanie złożonej zmiany schematu
Aby uniknąć zmian, które mogłyby spowodować słabe wyniki wyszukiwania lub uszkodzić indeks wyszukiwania, usługa Cloud Search uniemożliwia wprowadzanie pewnych rodzajów zmian w żądaniach UpdateSchema po zindeksowaniu repozytorium. Na przykład po ustawieniu typu danych lub nazwy właściwości nie można ich zmienić. Nie można wprowadzić tych zmian za pomocą prostego UpdateSchema, nawet jeśli ponownie zindeksujesz dane.
W sytuacjach, gdy musisz wprowadzić w schemacie zmianę, która jest niedozwolona, możesz często wprowadzić serię dozwolonych zmian, które przyniosą ten sam skutek. Ogólnie oznacza to najpierw migrację z uwzględnieniem zaktualizowanych właściwości z użyciem starszej definicji obiektu na nowszą, a potem wysłanie żądania indeksowania, które wykorzystuje tylko nowszą usługę.
Aby zmienić typ danych lub nazwę usługi:
- Dodaj nową właściwość do definicji obiektu w schemacie. Użyj innej nazwy niż ta, którą chcesz zmienić.
- Prześlij żądanie UpdateSchema z nową definicją. Pamiętaj, aby w prośbie przesłać cały schemat, w tym zarówno nową, jak i starą usługę.
Uzupełnij indeks z repozytorium danych. Aby uzupełnić indeks, wyślij wszystkie żądania indeksowania za pomocą nowej usługi, ale nie starej, ponieważ spowodowałoby to podwójne zliczanie dopasowań zapytań.
- Podczas indeksowania wstecznego sprawdź nową usługę i ustaw ją jako domyślną zamiast starej, aby uniknąć niespójności.
- Po zakończeniu wypełniania uruchom zapytania testowe w celu weryfikacji.
Usuń starą usługę. Prześlij kolejne żądanie UpdateSchema bez starej nazwy usługi i nie używaj już starej nazwy w przyszłych żądaniach indeksowania.
Przejdź do nowej usługi wszystkie elementy, które korzystają ze starej usługi. Jeśli na przykład zmienisz nazwę usługi z twórca na autor, musisz zaktualizować kod zapytania, aby używać w nim słowa autor zamiast twórca.
Cloud Search przechowuje informacje o usuniętym zasobie lub obiekcie przez 30 dni, aby chronić przed ponownym użyciem, które mogłoby spowodować nieoczekiwane wyniki indeksowania. W ciągu tych 30 dni musisz usunąć wszystkie odwołania do usuniętego obiektu lub usługi, w tym wykluczyć je z przyszłych żądań indeksowania. Dzięki temu, jeśli później zdecydujesz się przywrócić tę usługę lub obiekt, możesz to zrobić w sposób, który nie spowoduje zmiany w prawidłowej strukturze indeksu.
Ograniczenia rozmiaru
Cloud Search nakłada limity na rozmiar obiektów i schematów uporządkowanych danych. Te limity to:
- Maksymalna liczba obiektów najwyższego poziomu to 10.
- Maksymalna głębokość hierarchii uporządkowanych danych wynosi 10 poziomów.
- Łączna liczba pól w obiekcie jest ograniczona do 1000, w tym liczba pól prymitywnych oraz suma liczby pól w każdym zagnieżdżonym obiekcie.
Następne kroki
Oto kilka kolejnych kroków, które możesz wykonać:
Utwórz interfejs wyszukiwania, aby przetestować schemat.
Dostosuj schemat, aby poprawić jakość wyszukiwania.
Utwórz schemat, który zapewni optymalną interpretację zapytań.
Dowiedz się, jak wykorzystać schemat
_dictionaryEntrydo definiowania synonimów terminów powszechnie używanych w Twojej firmie. Aby używać schematu_dictionaryEntry, zapoznaj się z artykułem Definiowanie synonimów.Utwórz oprogramowanie sprzęgające.