
Ein Google Cloud Search-Schema ist eine JSON-Struktur, in der die Objekte, Attribute und Optionen definiert sind, die beim Indexieren und Abfragen Ihrer Daten verwendet werden. Daten aus Ihrem Repository werden mithilfe eines Inhaltsconnectors gelesen und basierend auf Ihrem registrierten Schema strukturiert und indexiert.
Ein Schema erstellen Sie, indem Sie in der API ein JSON-Schemaobjekt bereitstellen und es anschließend registrieren. Sie müssen für jedes Ihrer Repositories ein Schemaobjekt registrieren, bevor Ihre Daten indexiert werden können.
In diesem Dokument werden die Grundlagen der Schemaerstellung behandelt. Informationen zum Optimieren Ihres Schemas für eine bessere Suche finden Sie unter Suchqualität verbessern.
Schema erstellen
Führen Sie die folgenden Schritte aus, um ein Schema für Cloud Search zu erstellen:
- Zu erwartendes Nutzerverhalten identifizieren
- Datenquelle initialisieren
- Schema erstellen
- Vollständiges Beispielschema
- Schema registrieren
- Daten indexieren
- Schema testen
- Schema anpassen
Zu erwartendes Nutzerverhalten bestimmen
Wenn Sie antizipieren, welche Art von Abfragen Ihre Nutzer stellen werden, können Sie auf dieser Grundlage die Strategie für Ihr Schema festlegen.
Bei einer Filmdatenbank könnten Nutzer z. B. die Abfrage „Zeige mir alle Filme, in denen Robert Redford mitspielt“ eingeben. Das heißt, Ihr Schema sollte Suchergebnisse des Musters „Alle Filme, in denen ein bestimmter Schauspieler mitspielt“ unterstützen.
So definieren Sie Ihr Schema so, dass es den Verhaltensmustern Ihrer Nutzer entspricht:
- Analysieren Sie unterschiedliche Suchanfragen von verschiedenen Nutzern.
- Ermitteln Sie die Objekte, die in Abfragen verwendet werden könnten. Objekte sind logische, zusammengehörige Datensätze, z. B. ein Film in einer Filmdatenbank.
- Ermitteln Sie die Eigenschaften und Werte, aus denen das Objekt besteht und die in Abfragen verwendet werden könnten. Attribute sind die indexierbaren Attribute eines Objekts. Sie können primitive Werte oder andere Objekte enthalten. Ein Filmobjekt kann beispielsweise Attribute wie den Titel und das Veröffentlichungsdatum des Films als primitive Werte haben. Das Filmobjekt kann auch andere Objekte wie Darsteller enthalten, die eigene Eigenschaften wie Name oder Rolle haben.
- Geben Sie Beispiele für gültige Werte für Unterkünfte an. Werte sind die tatsächlichen Daten, die für eine Property indexiert werden. Der Titel eines Films in Ihrer Datenbank könnte beispielsweise „Indiana Jones und der verlorene Schatz“ lauten.
- Bestimmen Sie die Sortier- und Rankingoptionen, die Ihre Nutzer gerne verwenden. Wenn Nutzer Filme abfragen, möchten Sie diese möglicherweise chronologisch sortieren und ein Ranking nach Zuschauerbewertung vornehmen, anstatt sie alphabetisch nach Titel zu sortieren.
- Optional: Überlegen Sie, ob eine Ihrer Properties einen spezifischeren Kontext darstellt, in dem Suchanfragen ausgeführt werden könnten, z. B. die Position oder Abteilung der Nutzer, damit Vorschläge zur automatischen Vervollständigung basierend auf dem Kontext bereitgestellt werden können. Wenn Nutzer beispielsweise in einer Filmdatenbank suchen, sind sie möglicherweise nur an einem bestimmten Filmgenre interessiert. Nutzer können festlegen, welche Genres bei ihren Suchanfragen berücksichtigt werden sollen, möglicherweise als Teil ihres Nutzerprofils. Wenn ein Nutzer dann beginnt, eine Suchanfrage für Filme einzugeben, werden nur Filme in seinem bevorzugten Genre, z. B. „Actionfilme“, als Vorschläge für die automatische Vervollständigung angezeigt.
- Erstellen Sie eine Liste dieser Objekte, Attribute und Beispielwerte, die bei der Suche verwendet werden können. Einzelheiten zur Verwendung dieser Liste finden Sie im Abschnitt Operatoroptionen festlegen.
Datenquelle initialisieren
Eine Datenquelle stellt die Daten aus einem Repository dar, die in Google Cloud indexiert und gespeichert wurden. Eine Anleitung zum Initialisieren einer Datenquelle finden Sie im Hilfeartikel Integration von Drittanbietern.
Die Suchergebnisse eines Nutzers werden von der Datenquelle zurückgegeben. Wenn er auf ein Suchergebnis klickt, wird er von Cloud Search über die URL, die in der Indexierungsanfrage bereitgestellt wird, zum tatsächlichen Element weitergeleitet.
Objekte definieren
Die Grundeinheit für Daten in einem Schema ist das Objekt, auch Schemaobjekt genannt, d. h. eine logische Datenstruktur. In einer Filmdatenbank ist „Film“ eine logische Datenstruktur. Ein anderes Objekt könnte „Person“ sein, für die am Film beteiligten Darsteller und Crew-Mitglieder.
Jedes Objekt in einem Schema verfügt über eine Reihe von Attributen, die das Objekt beschreiben, z. B. „Titel“ und „Dauer“ für einen Film oder „Name“ und „Geburtsdatum“ für eine Person. Attribute eines Objekts können primitive Werte oder andere Objekte enthalten.
In Abbildung 1 sehen Sie die Film- und Personenobjekte ("movie" und "person") mit ihren zugehörigen Attributen.
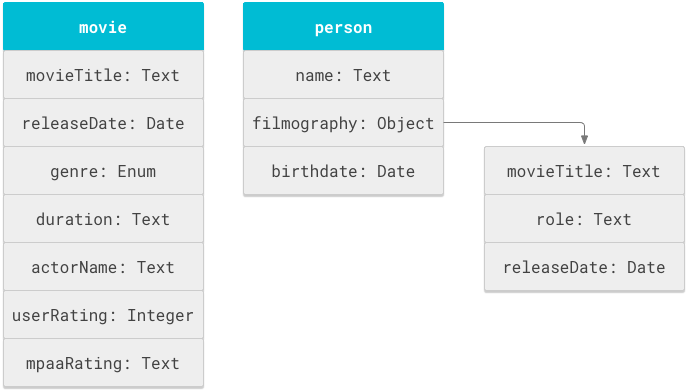
Ein Cloud Search-Schema besteht im Wesentlichen aus einer Liste von Angaben zu Objektdefinitionen, die im Tag objectDefinitions angegeben werden. Im folgenden Schema-Snippet sehen Sie solche Angaben im Tag objectDefinitions für die Schemaobjekte „Film“ ("movie") und „Person“ ("person").
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
Wenn Sie ein Schemaobjekt definieren, geben Sie ihm einen name, der noch nicht für andere Objekte im Schema verwendet wird. Normalerweise verwenden Sie für name einen Wert, der das Objekt beschreibt, z. B. movie für ein Filmobjekt. Das Feld name wird im Schema als Hauptkennung für indexierbare Objekte verwendet. Weitere Informationen zum Feld name finden Sie in der Objektdefinition.
Objekt-Attribute definieren
Wie in der Referenz für ObjectDefinition angegeben, folgt auf den Objektnamen eine Reihe von options und eine Liste von propertyDefinitions.
Die options kann außerdem aus freshnessOptions und displayOptions bestehen.
freshnessOptions werden verwendet, um ein Ranking nach Aktualität eines Elements vorzunehmen. Mit den displayOptions legen Sie fest, ob in den Suchergebnissen für ein Objekt bestimmte Label und Attribute angezeigt werden.
Im Abschnitt propertyDefinitions geben Sie die Attribute für ein Objekt an, z. B. den Filmtitel und das Veröffentlichungsdatum.
Im folgenden Snippet sehen Sie das Objekt movie mit zwei Attributen: movieTitle und releaseDate.
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
Eine PropertyDefinition besteht aus den folgenden Elementen:
- einen
name-String. - Eine Liste mit typunabhängigen Optionen, z. B.
isReturnableim vorherigen Snippet. - Ein Typ und die dazugehörigen typspezifischen Optionen, z. B.
textPropertyOptionsundretrievalImportanceim vorherigen Snippet. - Ein
operatorOptions, um zu beschreiben, wie das Attribut als Suchoperator verwendet wird - Eine oder mehrere
displayOptions, z. B.displayLabelim vorherigen Snippet
Der name eines Attributs muss innerhalb des Objekts, in dem es sich befindet, einmalig sein. Derselbe Name kann jedoch in anderen Objekten und Unterobjekten verwendet werden.
In Abbildung 1 wurden der Filmtitel und das Veröffentlichungsdatum zweimal angegeben: einmal im Objekt movie und noch einmal im Unterobjekt filmography des Objekts person. Für dieses Schema wird das Feld movieTitle so verwendet, dass zwei Arten von Suchverhalten vom Schema unterstützt werden:
- Suchergebnisse für Filme anzeigen, wenn Nutzer nach dem Titel eines Films suchen
- Suchergebnisse für Personen anzeigen, wenn Nutzer nach Filmtiteln suchen, in denen ein bestimmter Schauspieler mitgespielt hat
Auf ähnliche Weise wird im Schema das Feld releaseDate verwendet, da es für die beiden Felder movieTitle dieselbe Bedeutung hat.
Berücksichtigen Sie beim Entwickeln Ihres eigenen Schemas, inwiefern in Ihrem Repository verwandte Felder mit Daten enthalten sein könnten, die Sie mehr als einmal deklarieren möchten.
Typunabhängige Optionen hinzufügen
In der PropertyDefinition sind allgemeine Optionen für Suchfunktionen aufgelistet, die für alle Attribute gelten, unabhängig vom Datentyp.
isReturnable: Gibt an, ob mit dem jeweiligen Attribut Daten identifiziert werden, die in Suchergebnissen über die Query API zurückgegeben werden sollten. Alle Beispiel-Filmeigenschaften können zurückgegeben werden. Nicht rückgabefähige Attribute können für die Suche oder das Ranking von Ergebnissen verwendet werden, ohne dass Sie an den Nutzer zurückgegeben werden.isRepeatable: Gibt an, ob für ein Attribut mehrere Werte zulässig sind. Beispielsweise hat ein Film nur ein Veröffentlichungsdatum, es können jedoch mehrere Schauspieler in ihm mitspielen.isSortable: Gibt an, dass das Attribut als Kriterium für die Sortierung verwenden kann. Dies kann nicht für Attribute gelten, die wiederholbar sind. Beispielsweise können Filme in einer Ergebnisliste nach dem Veröffentlichungsdatum oder der Zuschauerbewertung sortiert werden.isFacetable: Gibt an, dass das Attribut verwendet werden kann, um Facets zu generieren. Diese werden zum Verfeinern der Suchergebnisse verwendet. Dabei werden die Ergebnisse der ersten Suche angezeigt und Nutzer können dann Kriterien, d. h. Facets hinzufügen, um die Ergebnisse weiter zu verfeinern. Diese Option kann für Attribute des Typs „Objekt“ nicht auf „wahr“ festgelegt werden. FürisReturnablemuss jedoch „wahr“ angegeben sein, damit diese Option verwendet werden kann. Generell wird diese Option nur für Attribute vom Typ „Aufzählung“, „Bool“ und „Text“ unterstützt. Im Beispielschema könnten Siegenre,actorName,userRatingundmpaaRatingals facettierbar festlegen, um eine interaktive Verfeinerung der Suchergebnisse zu ermöglichen.isWildcardSearchablegibt an, dass Nutzer eine Platzhaltersuche für diese Property durchführen können. Diese Option ist nur für Texteigenschaften verfügbar. Wie die Wildcard-Suche im Textfeld funktioniert, hängt vom Wert ab, der im Feld exactMatchWithOperator festgelegt ist. WennexactMatchWithOperatorauftruegesetzt ist, wird der Textwert als atomarer Wert tokenisiert und es wird eine Platzhaltersuche damit durchgeführt. Wenn der Textwert beispielsweisescience-fictionist, stimmt er mit der Platzhalterabfragescience-*überein. WennexactMatchWithOperatorauffalsefestgelegt ist, wird der Textwert tokenisiert und für jedes Token wird eine Platzhaltersuche durchgeführt. Wenn der Textwert beispielsweise „Science-Fiction“ lautet, stimmen die Platzhalterabfragensci*oderfi*mit dem Element überein,science-*hingegen nicht.
Diese allgemeinen Suchfunktionsparameter sind alle boolesche Werte. Sie haben den Standardwert false und müssen auf true festgelegt werden, um verwendet werden zu können.
In der folgenden Tabelle sehen Sie die booleschen Parameter, die für alle Attribute des Objekts movie auf true festgelegt werden:
| Attribut | isReturnable |
isRepeatable |
isSortable |
isFacetable |
isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle |
wahr | wahr | |||
releaseDate |
wahr | wahr | |||
genre |
wahr | wahr | wahr | ||
duration |
wahr | ||||
actorName |
wahr | wahr | wahr | wahr | |
userRating |
wahr | wahr | |||
mpaaRating |
wahr | wahr |
isRepeatable ist sowohl für genre als auch für actorName auf true festgelegt, da ein Film zu mehreren Genres gehören kann und darin normalerweise auch mehr als ein Schauspieler mitspielt. Ein Attribut kann nicht sortiert werden, wenn es wiederholbar ist oder in einem wiederholbaren Unterobjekt enthalten ist.
Typ definieren
Im Abschnitt PropertyDefinition sind mehrere xxPropertyOptions aufgelistet, bei denen xx für einen bestimmten Typ steht, z. B. boolean. Wenn Sie den Datentyp für ein Attribut festlegen möchten, müssen Sie das entsprechende Datentypobjekt definieren. Wenn Sie ein Datentypobjekt für eine Property definieren, wird der Datentyp dieser Property festgelegt. Wenn Sie z. B. textPropertyOptions für das Attribut movieTitle festlegen, bedeutet dies, dass der Filmtitel den Typ „Text“ hat. Im folgenden Snippet sehen Sie das Attribut movieTitle. Sein Datentyp wird von textPropertyOptions bestimmt.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
Jedes Attribut kann nur einen Datentyp haben. Für das Filmschema heißt das beispielsweise, dass releaseDate nur aus einem Datum (z.B. 2016-01-13) oder ein String (z.B. January 13, 2016), aber nicht beides.
Hier sehen Sie die Datentypobjekte, mit denen die Datentypen für die Attribute im Beispielschema angegeben werden:
| Attribut | Datentypobjekt |
|---|---|
movieTitle |
textPropertyOptions |
releaseDate |
datePropertyOptions |
genre |
enumPropertyOptions |
duration |
textPropertyOptions |
actorName |
textPropertyOptions |
userRating |
integerPropertyOptions |
mpaaRating |
textPropertyOptions |
Welchen Datentyp Sie für ein Attribut auswählen, hängt vom Nutzerverhalten ab, das Sie erwarten.
Für das Filmschema gehen Sie z. B. davon aus, dass Nutzer Ergebnisse chronologisch sortieren möchten, releaseDate ist also ein Datenobjekt.
Wenn Sie aber zum Beispiel erwarten, dass Nutzer Veröffentlichungen von Filmen im Dezember der letzten Jahre mit denen vergleichen möchten, die in einem Januar stattgefunden haben, könnte ein String-Format nützlich sein.
Typspezifische Optionen konfigurieren
Im Abschnitt PropertyDefinition finden Sie Informationen zu den Optionen der einzelnen Typen. Die meisten typspezifischen Optionen sind optional, außer der Liste mit possibleValues in den enumPropertyOptions. Außerdem können Sie mit der Option orderedRanking Werte relativ zueinander ranken. Im folgenden Snippet sehen Sie das Attribut movieTitle. Sein Datentyp wird dabei von textPropertyOptions festgelegt. Außerdem wird die typspezifische Option retrievalImportance verwendet.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
Hier sehen Sie die zusätzlichen typspezifischen Optionen, die im Beispielschema verwendet werden:
| Attribut | Typ | Typspezifische Optionen |
|---|---|---|
movieTitle |
textPropertyOptions |
retrievalImportance |
releaseDate |
datePropertyOptions |
|
genre |
enumPropertyOptions |
|
duration |
textPropertyOptions |
|
actorName |
textPropertyOptions |
|
userRating |
integerPropertyOptions |
orderedRanking, maximumValue |
mpaaRating |
textPropertyOptions |
Operatoroptionen festlegen
Zusätzlich zu typspezifischen Optionen verfügt jeder Typ über eine Reihe optionaler operatorOptions. Diese Optionen beschreiben, wie das Attribut als Suchoperator verwendet wird. Im folgenden Snippet sehen Sie das Attribut movieTitle. Sein Datentyp wird dabei von textPropertyOptions festgelegt. Außerdem werden die typspezifischen Optionen retrievalImportance und operatorOptions verwendet.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
Jede operatorOptions hat eine operatorName, z. B. title für eine movieTitle. Der Operatorname ist der Suchoperator für das Attribut. Ein Suchoperator ist der tatsächliche Parameter, den Nutzer vermutlich verwenden werden, um eine Suche einzugrenzen. Wenn beispielsweise Filme über ihren Titel gesucht werden sollen, gibt der Nutzer title:movieName ein. Dabei ist movieName der Name eines Films.
Namen von Betreibern müssen nicht mit dem von Attributen übereinstimmen. Verwenden Sie stattdessen Operatornamen, die die gebräuchlichsten Wörter widerspiegeln, die von Nutzern in Ihrer Organisation verwendet werden. Wenn die Nutzer beispielsweise für Filmtitel eher den Begriff „Name“ anstelle von „Titel“ verwenden, sollte „Name“ als Name für den Operator gewählt werden.
Sie können denselben Operatornamen für mehrere Attribute verwenden, solange diese alle denselben Typ haben. Wenn Sie eine Abfrage mit einem gemeinsam genutzten Operatornamen durchführen, werden alle Attribute abgerufen, für die er verwendet wird. Gehen Sie z. B. davon aus, das Objekt „Film“ hätte die Attribute plotSummary und plotSynopsis und für jedes dieser Attribute würde plot als operatorName verwendet. Wenn beide dieser Attribute den Typ „Text“ haben (textPropertyOptions), werden auch beide abgefragt, wenn eine einzelne Abfrage den Suchoperator plot verwendet.
Zusätzlich zu operatorName können Attribute, die sortierbar sind, in operatorOptions die Felder lessThanOperatorName und greaterThanOperatorName haben.
Nutzer können mit diesen Optionen Abfragen erstellen, die auf Vergleichen mit einem übergebenen Wert basieren.
Schließlich gibt es für textOperatorOptions in operatorOptions das Feld exactMatchWithOperator. Wenn Sie exactMatchWithOperator auf true festlegen, muss der Abfragestring mit dem Attributwert vollständig übereinstimmen, also nicht nur innerhalb des Texts gefunden werden können.
Der Textwert wird in Operatorsuchen und Facet-Treffern als ein atomarer Wert behandelt.
Stellen Sie sich z. B. vor, dass Buch- oder Filmobjekte mit Genre-Attributen indexiert werden sollen.
Zu den Genres könnten „Science-Fiction“, „Science“ und „Fiction“ gehören. Wenn exactMatchWithOperator auf false festgelegt oder weggelassen wird, werden bei der Suche nach einem Genre oder bei Auswahl der Facette „Science“ oder „Fiction“ auch Ergebnisse für „Science-Fiction“ zurückgegeben, da der Text tokenisiert wird und die Tokens „Science“ und „Fiction“ in „Science-Fiction“ enthalten sind.
Wenn exactMatchWithOperator true ist, wird der Text als einzelnes Token behandelt. Das bedeutet, Sie erhalten keine Suchergebnisse für „Science-Fiction“, wenn Sie nur nach „Science“ oder nur nach „Fiction“ suchen.
Optional: Fügen Sie den Abschnitt displayOptions hinzu.
Am Ende jedes propertyDefinition-Abschnitts gibt es den optionalen Abschnitt displayOptions. Dieser Abschnitt enthält einen displayLabel-String.
displayLabel ist ein empfohlenes und nutzerfreundliches Textlabel für das Attribut. Wenn die Anzeige eines Attributs mithilfe von ObjectDisplayOptions konfiguriert wird, wird dieses Label vor dem Attribut angezeigt. Ist die Anzeige des Attributs konfiguriert und displayLabel wurde nicht festgelegt, wird nur der Attributwert angezeigt.
Im folgenden Snippet sehen Sie das Attribut movieTitle. Als displayLabel wurde „Title“ (Titel) festgelegt.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
Die folgende Liste enthält die displayLabel-Werte aller Attribute des Objekts movie im Beispielschema:
| Attribut | displayLabel |
|---|---|
movieTitle |
Title |
releaseDate |
Release date |
genre |
Genre |
duration |
Run length |
actorName |
Actor |
userRating |
Audience score |
mpaaRating |
MPAA rating |
Optional: Abschnitt suggestionFilteringOperators[] hinzufügen
Am Ende jedes propertyDefinition-Abschnitts gibt es den optionalen Abschnitt suggestionFilteringOperators[]. In diesem Abschnitt können Sie eine Property definieren, mit der Vorschläge zur automatischen Vervollständigung gefiltert werden. Sie können beispielsweise den Operator genre definieren, um Vorschläge basierend auf dem bevorzugten Filmgenre des Nutzers zu filtern. Wenn der Nutzer dann seine Suchanfrage eingibt, werden nur Filme angezeigt, die seinem bevorzugten Genre entsprechen.
Schema registrieren
Damit bei Cloud Search-Abfragen strukturierte Daten zurückgegeben werden, müssen Sie Ihr Schema beim Cloud Search-Schemadienst registrieren. Dafür benötigen Sie die Datenquellen-ID, die Sie während des Schritts Datenquelle initialisieren erhalten haben.
Mithilfe der Datenquellen-ID können Sie eine UpdateSchema-Anforderung ausgeben, um Ihr Schema zu registrieren.
Verwenden Sie die im Artikel zu UpdateSchema erläuterte HTTP-Anforderung, um Ihr Schema zu registrieren:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
Der Body Ihrer Anfrage sollte Folgendes enthalten:
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
Mit der Option validateOnly können Sie die Gültigkeit Ihres Schemas testen, ohne es tatsächlich zu registrieren.
Daten indexieren
Sobald Ihr Schema registriert ist, können Sie die Datenquelle mithilfe von Index-Aufrufen befüllen. Die Indexierung erfolgt in der Regel über Ihren Inhaltsconnector.
Unter Verwendung des Filmschemas würde eine Anforderung über eine REST API, einen einzelnen Film zu indexieren, folgendermaßen aussehen:
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
Wie Sie sehen können, stimmt der Wert von movie im Feld objectType mit dem Namen der Objektdefinition im Schema überein. Dadurch ist festgelegt, welche Schemaobjekte von Cloud Search während der Indexierung verwendet werden müssen.
Außerdem sehen Sie, dass bei der Indexierung des Schemaattributs releaseDate die Unterattribute year, month und day verwendet werden, die geerbt wurden, weil der Datentyp des Attributs releaseDate über datePropertyOptions als date festgelegt wurde.
Da year, month und day jedoch nicht im Schema definiert sind, können Sie diese Attribute (z.B. year) einzeln.
Außerdem wird das wiederholbare Attribut actorName über eine Liste von Werten indexiert.
Mögliche Indexierungsprobleme erkennen
Die zwei häufigsten Probleme im Zusammenhang mit Schemas und Indexierung sind die folgenden:
Ihre Indexierungsanfrage enthält ein Schemaobjekt oder einen Attributnamen, der nicht beim Schemadienst registriert wurde. Dies führt dazu, dass das Attribut oder das Objekt ignoriert werden.
Der Typ des Attributs in Ihrer Indexierungsanfrage stimmt nicht mit dem für das Schema registrierten überein. Dies führt dazu, dass von Cloud Search bei der Indexierung ein Fehler zurückgegeben wird.
Schema mithilfe von mehreren Abfragetypen testen
Bevor Sie Ihr Schema für ein großes Produktionsdatenrepository registrieren, sollten Sie es zunächst mit einem kleineren Testdatenrepository verwenden. So können Sie schnell Änderungen an Ihrem Schema vornehmen und die indexierten Daten löschen, ohne dass dies Auswirkungen auf einen größeren Index oder einen vorhandenen Produktionsindex hat. Erstellen Sie für ein Testdatenrepository eine ACL, über die nur ein Testnutzer autorisiert wird. So werden diese Daten nicht in den Suchergebnissen anderer Nutzer angezeigt.
Informationen zum Erstellen einer Suchoberfläche, mit der Sie Suchanfragen validieren können, finden Sie im Artikel Die Suchoberfläche.
In diesem Abschnitt finden Sie verschiedene Beispielabfragen, mit denen das Filmschema getestet werden kann.
Mit einer generischen Abfrage testen
Eine generische Abfrage gibt alle Elemente in der Datenquelle zurück, die einen bestimmten String enthalten. Mithilfe einer Suchoberfläche können Sie solche Abfragen für die Filmdatenquelle ausführen, indem Sie den Begriff "Titanic" eingeben und die Eingabetaste drücken. Als Suchergebnis sollten alle Filme mit dem Begriff „Titanic“ zurückgegeben werden.
Mit einem Operator testen
Durch das Hinzufügen eines Operators zur Abfrage werden die Ergebnisse auf die Elemente beschränkt, die diesem Operatorwert entsprechen. Sie können beispielsweise den Operator actor verwenden, um alle Filme zu finden, in denen ein bestimmter Schauspieler mitspielt. Mithilfe einer Suchoberfläche können Sie eine solche Operatorabfrage durchführen, indem Sie einfach ein Operator=Wert-Paar eingeben, z. B. "actor:Zane", und dann auf die Eingabetaste drücken. Alle Filme, in denen Zane mitspielt, sollten in den Suchergebnissen angezeigt werden.
Schema anpassen
Auch nachdem ein Schema produktiv verwendet wird, müssen Sie weiterhin prüfen, ob es für Ihre Nutzer hilfreich ist oder Verbesserungspotenzial besteht. Sie können Ihr Schema an die folgenden Szenarien anpassen:
- Indexieren eines Felds, das noch nicht indexiert wurde: Möglicherweise suchen Ihre Nutzer wiederholt über den Namen eines Regisseurs nach Filmen. Dann sollten Sie Ihr Schema so anpassen, dass „Name des Regisseurs“ als Operator unterstützt wird.
- Die Namen von Suchoperatoren werden auf Grundlage von Nutzerfeedback geändert. Operatornamen sollten nutzerfreundlich sein. Wenn Ihre Nutzer ständig den falschen Operatornamen verwenden, sollten Sie ihn möglicherweise ändern.
Neuindexierung nach einer Schemaänderung
Wenn Sie einen der folgenden Werte in Ihrem Schema geändert haben, müssen Sie Ihre Daten nicht noch einmal indexieren. Sie können einfach eine neue UpdateSchema-Anfrage senden und Ihr Index funktioniert weiterhin:
- Namen von Mobilfunkanbietern
- Ganzzahlige Minimal- und Maximalwerte
- Ranking nach Ganzzahl oder Aufzählungstyp
- Aktualitätsoptionen.
- Anzeigeoptionen
Bei den daraus folgenden Änderungen funktionieren zuvor indexierte Daten weiterhin gemäß dem zuvor registrierten Schema. Bei folgenden Änderungen müssen Sie jedoch vorhandene Einträge neu indexieren, damit Änderungen dem aktualisierten Schema entsprechend angezeigt werden:
- Ein neues Attribut oder ein Objekt hinzufügen oder entfernen
- Ändern von
isReturnable,isFacetableoderisSortablevonfalseintrue
Die Optionen isFacetable oder isSortable sollten Sie nur auf true festlegen, wenn es für die Verwendung wirklich erforderlich ist.
Wenn Sie Ihr Schema aktualisieren, indem Sie eine Property mit isSuggestable kennzeichnen, müssen Sie Ihre Daten neu indexieren. Dies führt zu einer Verzögerung bei der Verwendung der automatischen Vervollständigung für diese Property.
Nicht zulässige Attributänderungen
Einige Schemaänderungen sind nicht zulässig, auch wenn Sie Ihre Daten danach neu indexieren, da dadurch der Index beschädigt wird oder schlechte oder inkonsistente Suchergebnisse erzeugt werden. Dazu gehören Änderungen an:
- Attributdatentyp
- Attributnamen
exactMatchWithOperator-Einstellung.retrievalImportance-Einstellung.
Es gibt jedoch eine Möglichkeit, diese Einschränkung zu umgehen.
Komplexe Schemaänderungen vornehmen
Sobald ein Repository indexiert wurde, werden bestimmte Änderungen über UpdateSchema-Anforderungen in Cloud Search verhindert, um schlechte Suchergebnissen oder einen fehlerhaften Suchindex zu vermeiden. Beispielsweise können der Datentyp und der Name eines Attributs nicht mehr geändert werden, nachdem sie festgelegt wurden. Es ist nicht möglich, diese Änderungen über eine UpdateSchema-Anforderung vorzunehmen, selbst wenn Sie Ihre Daten neu indexieren.
Sollte eine solche nicht zulässige Änderung an Ihrem Schema notwendig sein, können Sie oft dasselbe Ergebnis erzielen, indem Sie mehrere zulässige Änderungen vornehmen. Im Allgemeinen umfasst dies zunächst die Migration indexierter Attribute von einer älteren Objektdefinition in eine neuere und das Senden einer Indexierungsanforderung, die nur das neuere Attribut verwendet.
So ändern Sie den Datentyp oder den Namen einer Property:
- Fügen Sie der Objektdefinition in Ihrem Schema ein neues Attribut hinzu. Verwenden Sie einen anderen Namen als den des Attributs, das Sie ändern möchten.
- Führen Sie mit der neuen Definition eine UpdateSchema-Anforderung aus. Denken Sie daran, das gesamte Schema, einschließlich des neuen und des alten Attributs, in der Anforderung zu senden.
Füllen Sie den Index wieder aus dem Datenrepository auf. Senden Sie dazu alle Indexierungsanforderungen mit dem neuen Attribut, nicht jedoch mit dem alten Attribut, da dies dazu führen würde, dass Abfrageübereinstimmungen doppelt gezählt werden.
- Prüfen Sie während des Backfills der Indexierung, ob die neue Property vorhanden ist, und verwenden Sie andernfalls standardmäßig die alte Property, um inkonsistentes Verhalten zu vermeiden.
- Führen Sie nach erfolgtem Auffüllen Testabfragen zur Überprüfung aus.
Löschen Sie das alte Attribut. Senden Sie eine weitere UpdateSchema-Anfrage ohne den alten Attributnamen und verwenden Sie ihn in zukünftigen Indexierungsanfragen nicht mehr.
Migrieren Sie alles, worin das alte Attribut verwendet wird, in das neue. Wenn Sie beispielsweise den Attributnamen von „Urheber“ zu „Autor“ ändern, müssen Sie Ihren Abfragecode so aktualisieren, dass „Autor“ verwendet wird, wo bisher „Urheber“ verwendet wurde.
In Cloud Search werden alle gelöschten Attribute oder Objekte 30 Tage lang gespeichert, um zu verhindern, dass sie wieder verwendet werden, was unerwartete Indexierungsergebnisse verursachen würde. Innerhalb dieses Zeitraums sollten die gelöschten Objekte oder Attribute nicht mehr verwendet werden und sollten auch von zukünftigen Indexabfragen ausgeschlossen werden. Dadurch wird sichergestellt, dass Sie das Attribut oder Objekt später wieder instanziieren können, ohne die Korrektheit des Index zu gefährden.
Größenbeschränkungen
Bei Cloud Search gibt es Größenbeschränkungen für strukturierte Datenobjekte und Schemas. Diese Limits sind:
- Die oberste Ebene kann maximal 10 Objekte haben.
- Die maximale Tiefe einer strukturierten Datenhierarchie beträgt 10 Ebenen.
- Die Gesamtzahl der Felder in einem Objekt ist auf 1.000 begrenzt. Dies umfasst die Anzahl der primitiven Felder plus die Summe der Felder in jedem verschachtelten Objekt.
Nächste Schritte
Als Nächstes könnten Sie Folgendes tun:
Erstellen Sie eine Suchoberfläche, um Ihr Schema zu testen.
Optimieren Sie Ihr Schema, um die Suchqualität zu verbessern.
Strukturieren Sie ein Schema für eine optimale Abfrageauswertung.
Informieren Sie sich, wie Sie das Schema
_dictionaryEntrynutzen können, um Synonyme für Begriffe zu bestimmen, die in Ihrem Unternehmen häufig verwendet werden. Weitere Informationen zur Verwendung des_dictionaryEntry-Schemas finden Sie unter Synonyme definieren.Erstellen Sie einen Connector.