
Google Cloud Search 架构采用 JSON 结构,其中定义了将数据编入索引及查询数据时要使用的对象、属性和选项。您的内容连接器会从存储区中读取数据,并根据您注册的架构设计数据结构以及将数据编入索引。
您可以通过向 API 提供一个 JSON 架构对象,然后注册该对象来创建架构。在将数据编入索引之前,必须先为每个存储区注册一个架构对象。
本文档介绍了创建架构方面的基础知识。如欲了解如何调整架构以改善搜索体验,请参阅提高搜索质量。
创建架构
下面列出了创建 Cloud Search 架构所需执行的步骤:
确定预期用户行为
预测用户执行的查询类型有助于引导您制定架构创建策略。
例如,在针对电影数据库发出查询时,您可能预测用户会执行诸如“显示由 Robert Redford 主演的所有电影”之类的查询。因此,您的架构必须支持根据“特定演员参演的所有电影”条件查询所得的结果。
要定义架构以反映用户的行为模式,建议执行以下任务:
- 评估不同用户所需的各种查询。
- 确定查询中可能使用的对象。对象是指相关数据的逻辑集合,例如电影数据库中的电影。
- 确定用于构成对象并可在查询中使用的属性和值。属性是指可编入索引的对象特征;它们可以包含原始值或其他对象。例如,电影对象可能具有作为原始值的电影标题和发布日期等属性。电影对象还可能包含其他对象(例如演员),这些对象具有各自的属性(例如其姓名或角色)。
- 确定属性的示例有效值。值是指为属性编入索引的实际数据。例如,电影数据库可能包含一部名为“夺宝奇兵”(Raiders of the Lost Ark) 的电影。
- 确定用户所需的排序和排名选项。例如,在查询电影时,用户可能希望按时间顺序排列查询结果并按收视率进行排名,而不需要按标题的字母顺序排序。
- (可选)考虑您的某个媒体资源是否代表可能执行搜索的更具体情境,例如用户的职位或部门,以便根据情境提供自动补全建议。例如,对于搜索电影数据库的用户,他们可能只对某种类型的电影感兴趣。用户可以定义他们希望搜索结果返回的类型,可能在其用户个人资料中进行定义。然后,当用户开始输入电影查询时,系统只会在自动补全建议中显示用户偏好的类型(例如“动作片”)的电影。
- 创建一份可在搜索中使用的对象、属性和示例值列表(如需详细了解如何使用此列表,请参阅定义运算符选项部分)。
初始化数据源
数据源表示存储区中已编入索引并存储在 Google Cloud 中的数据。有关初始化数据源的说明,请参阅管理第三方数据源。
用户的搜索结果通过数据源返回。当用户点击搜索结果时,Cloud Search 会使用索引请求中提供的网址将用户定向到实际项。
定义对象
在架构中,基本数据单元是对象(也称为“架构对象”),它表示数据的逻辑结构。在电影数据库中,一个对象(即数据的逻辑结构)是“movie”。另一个对象可能是“person”,用于表示电影中涉及的演员和工作人员。
架构中的每个对象都有一系列用于描述该对象的属性或特性,例如 movie 对象具有标题和时长属性,而 person 对象具有姓名和生日属性。对象的属性可以包含原始值或其他对象。
图 1 显示了 movie 和 person 对象以及相关属性。
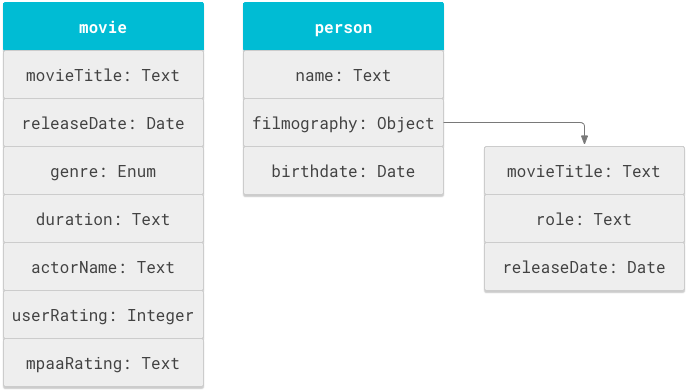
Cloud Search 架构实际上是在 objectDefinitions 标记中定义的一系列对象定义语句。以下架构代码段显示了 movie 和 person 架构对象对应的 objectDefinitions 语句。
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
定义架构对象时,为该对象提供的 name 必须在架构所含的其他所有对象中保持唯一。通常情况下,您应使用一个可以描述该对象的 name 值,例如,使用 movie 来表示 movie 对象。架构服务会将 name 字段用作可编入索引的对象的键标识符。如需进一步了解 name 字段,请参阅对象定义。
定义对象属性
如 ObjectDefinition 的参考文档中所述,对象名称后跟一组 options 和一个 propertyDefinitions 列表。options 还可以进一步由 freshnessOptions 和 displayOptions 组成。freshnessOptions 用于根据项的新鲜度调整该项在搜索结果中的排名。displayOptions 用于定义特定标签和属性是否显示在对象的搜索结果中。
propertyDefinitions 部分用于定义对象的属性,例如影片标题和发布日期。
以下代码段显示了具有 movieTitle 和 releaseDate 两个属性的 movie 对象。
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
PropertyDefinition 包含以下几项:
name字符串。- 不限定类型的选项列表,例如上述代码段中的
isReturnable。 - 类型及其关联的专用选项,例如上述代码段中的
textPropertyOptions和retrievalImportance。 operatorOptions,用于描述如何将属性用作搜索运算符。- 一个或多个
displayOptions,例如上述代码段中的displayLabel。
属性的 name 在所属对象中必须保持唯一,但在其他对象和子对象中可以使用相同名称。在图 1 中,电影的标题和发布日期被定义了两次:一次是在 movie 对象中,另一次是在 person 对象的 filmography 子对象中。此架构重复使用了 movieTitle 字段,因此可以支持以下两种搜索行为:
- 当用户搜索电影的标题时,显示电影搜索结果。
- 当用户搜索由某演员参演的电影的标题时,显示演职人员搜索结果。
同样地,该架构还重复使用了 releaseDate 字段,因为该字段对于两个 movieTitle 字段具有相同含义。
在开发自己的架构时,建议考虑采用何种方式可能会使存储区中具有相关字段,而这些字段包含要在架构中声明多次的数据。
添加不限定类型的选项
PropertyDefinition 会列出所有属性都通用的常规搜索功能选项,无论数据类型如何。
isReturnable- 指明该属性是否标识应通过 Query API 在搜索结果中返回的数据。所有电影媒体资源示例均可退货。不可返回值的属性可用于搜索结果或对结果进行排名,但不会返回给用户。isRepeatable- 指明该属性是否允许使用多个值。例如,一部电影只能有一个发布日期,但可以有多名演员。isSortable- 表示该属性可用于排序。对于可重复的属性,此选项不能为 true。例如,搜索到的电影结果可以按发布日期或收视率排序。isFacetable- 表示该属性可用于生成分面。构面用于优化搜索结果。通过构面,用户可以查看初始结果,然后添加条件或构面来进一步优化这些结果。对于对象类型的属性,该选项不能为 true,并且只有在isReturnable为 true 时才能设置该选项。此外,只有枚举、布尔和文本类型的属性支持此选项。例如,在我们的示例架构中,我们可以将genre、actorName、userRating和mpaaRating设为可生成构面,以使它们能够用于以互动方式优化搜索结果。isWildcardSearchable表示用户可以对此媒体资源执行通配符搜索。此选项仅适用于文本属性。文本字段上的通配符搜索功能的运作方式取决于 exactMatchWithOperator 字段中设置的值。如果exactMatchWithOperator设置为true,系统会将文本值作为一个原子值进行标记化,并对其执行通配符搜索。例如,如果文本值为science-fiction,则通配符查询science-*与其匹配。如果exactMatchWithOperator设置为false,系统会对文本值进行分词,并对每个令牌执行通配符搜索。例如,如果文本值为“科幻”,则通配符查询sci*或fi*与该项匹配,但science-*与该项不匹配。
这些通用搜索功能参数均为布尔值;它们的默认值都是 false,但必须设置为 true 才能使用。
下表显示了针对 movie 对象的所有属性应设置为 true 的布尔值参数:
| 属性 | isReturnable |
isRepeatable |
isSortable |
isFacetable |
isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle |
true | true | |||
releaseDate |
true | true | |||
genre |
true | true | true | ||
duration |
true | ||||
actorName |
true | true | true | true | |
userRating |
true | true | |||
mpaaRating |
true | true |
对于 genre 和 actorName,isRepeatable 均设置为 true,因为一部电影可以属于多个类型,并且通常具有多名演员。如果某个属性是可重复的属性或包含在可重复的子对象中,则该属性不能用于排序。
定义类型
PropertyDefinition 参考部分列出了多个 xxPropertyOptions,其中 xx 是特定类型(例如 boolean)。要设置属性的数据类型,您必须定义适当的数据类型对象。为属性定义数据类型对象即会确立该属性的数据类型。例如,如果为 movieTitle 属性定义 textPropertyOptions,则表示电影标题为文本类型。以下代码段显示了通过 textPropertyOptions 设置数据类型的 movieTitle 属性。
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
一个属性只能有一个关联的数据类型。例如,在我们的电影架构中,releaseDate 只能是日期(例如2016-01-13)或字符串(例如January 13, 2016),但不能同时使用这两者。
以下数据类型对象用于为示例电影架构中的属性指定数据类型:
| 属性 | 数据类型对象 |
|---|---|
movieTitle |
textPropertyOptions |
releaseDate |
datePropertyOptions |
genre |
enumPropertyOptions |
duration |
textPropertyOptions |
actorName |
textPropertyOptions |
userRating |
integerPropertyOptions |
mpaaRating |
textPropertyOptions |
您为媒体资源选择的数据类型取决于您的预期用例。在此假想的电影架构场景中,用户需要按时间顺序对结果排序,因此 releaseDate 属于日期类型对象。例如,如果预期用例是比较多年来 12 月份和 1 月份的电影上映量,那么选择字符串格式可能会非常实用。
配置类型特有的选项
PropertyDefinition 参考部分提供了适用于每种类型的选项。大多数类型特有选项都是可选的,但 enumPropertyOptions 中的 possibleValues 列表除外。此外,您还可以使用 orderedRanking 选项将值两两之间进行排名。以下代码段显示了通过 textPropertyOptions 设置数据类型的 movieTitle 属性,该属性包含类型特有选项 retrievalImportance。
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
以下是示例架构中使用的其他类型特有选项:
| 属性 | 类型 | 类型特有选项 |
|---|---|---|
movieTitle |
textPropertyOptions |
retrievalImportance |
releaseDate |
datePropertyOptions |
|
genre |
enumPropertyOptions |
|
duration |
textPropertyOptions |
|
actorName |
textPropertyOptions |
|
userRating |
integerPropertyOptions |
orderedRanking,maximumValue |
mpaaRating |
textPropertyOptions |
定义运算符选项
除了类型特有选项之外,每种类型属性还有一组可选的 operatorOptions。这些选项用于描述该属性如何用作搜索运算符。以下代码段显示了通过 textPropertyOptions 设置数据类型的 movieTitle 属性,该属性包含类型特有选项 retrievalImportance 和 operatorOptions。
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
每个 operatorOptions 都有一个 operatorName,例如 movieTitle 的 title。运算符名称是相应房源的搜索运算符。搜索运算符是您预期用户在缩小搜索范围时使用的实际参数。例如,要根据标题搜索电影,用户应输入 title:movieName,其中 movieName 是电影的名称。
运算符名称不必与属性名称相同,而是应该能够反映组织中的用户最常用的词语。例如,如果您的用户更喜欢使用“name”而不是“title”来表示电影标题,则应将运算符名称设置为“name”。
您可以对多个属性使用相同运算符名称,前提是所有属性都解析为相同类型。在查询期间使用共有的运算符名称时,系统将检索使用该运算符名称的所有属性。例如,假设 movie 对象具有 plotSummary 和 plotSynopsis 属性,并且这些属性的 operatorName 均为 plot。只要这两个属性都是文本类型 (textPropertyOptions),使用 plot 搜索运算符的单个查询就会检索这两者。
除了 operatorName 之外,可排序属性的 operatorOptions 还可以包含 lessThanOperatorName 和 greaterThanOperatorName 字段。用户可以使用这些选项来根据与提交值的比较结果创建查询。
最后,textOperatorOptions 的 operatorOptions 中包含一个 exactMatchWithOperator 字段。如果将 exactMatchWithOperator 设置为 true,则查询字符串必须与整个属性值匹配,而不仅仅匹配在文本中找到的内容。在运算符搜索和构面匹配项中,文本值会被视为一个原子值。
例如,假设将具有 genre 属性的 Book 或 Movie 对象编入索引。类型可以包括“Science-Fiction”“Science”和“Fiction”。如果将 exactMatchWithOperator 设为 false 或省略,则搜索某个类型或选择“Science”或“Fiction”细分也会返回“Science-Fiction”的结果,因为系统会对文本进行标记化处理,并且“Science-Fiction”中存在“Science”和“Fiction”标记。如果 exactMatchWithOperator 为 true,则该文本会被视为单个标记,因此“Science”和“Fiction”都与“Science-Fiction”不匹配。
(可选)添加 displayOptions 部分
任何 propertyDefinition 部分的末尾都会有一个可选的 displayOptions 部分。此部分包含一个 displayLabel 字符串。displayLabel 是一个简单易懂的文本标签,建议对房源使用。如果属性被配置为使用 ObjectDisplayOptions 显示,则此标签将显示在属性前面。如果属性被配置为显示,但未定义 displayLabel,则将仅显示属性值。
以下代码段显示了 displayLabel 设置为“Title”的 movieTitle 属性。
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
以下是示例架构中 movie 对象的所有属性的 displayLabel 值:
| 属性 | displayLabel |
|---|---|
movieTitle |
Title |
releaseDate |
Release date |
genre |
Genre |
duration |
Run length |
actorName |
Actor |
userRating |
Audience score |
mpaaRating |
MPAA rating |
(可选)添加 suggestionFilteringOperators[] 部分
任何 propertyDefinition 部分的末尾都会有一个可选的 suggestionFilteringOperators[] 部分。您可以在此部分中定义用于过滤自动补全建议的属性。例如,您可以定义 genre 运算符,以便根据用户的首选电影类型过滤建议。然后,当用户输入搜索查询时,系统只会在自动补全建议中显示与其首选类型相符的电影。
注册架构
要使 Cloud Search 查询返回结构化数据,您必须将您的架构注册到 Cloud Search 架构服务中。要注册架构,您需要提供在初始化数据源步骤中获取的数据源 ID。
使用该数据源 ID 发出 UpdateSchema 请求,即可注册您的架构。
发出以下 HTTP 请求以注册您的架构(详情见 UpdateSchema 参考页面):
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
您的请求正文应包含以下内容:
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
使用 validateOnly 选项,您无需实际注册架构也可测试其有效性。
将数据编入索引
注册架构后,请使用索引调用填充数据源。索引编制操作通常在内容连接器中完成。
对于电影架构,针对单部电影的 REST API 索引请求如下所示:
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
请注意 objectType 字段中 movie 的值如何与架构中的对象定义名称匹配。通过匹配这两个值,Cloud Search 可以了解索引编制期间要使用的架构对象。
还要注意架构属性 releaseDate 的索引如何使用该属性继承的 year、month 和 day 子属性,因为该属性通过 datePropertyOptions 定义为 date 数据类型。但是,由于架构中未定义 year、month 和 day,因此您无法单独查询其中某一属性(例如 year)。
另外,请注意如何使用一系列值将可重复属性 actorName 编入索引。
识别潜在的索引问题
以下是与架构和索引相关的两大最常见问题:
您的索引请求包含未向架构服务注册的架构对象或属性名称。此问题会导致该属性或对象被忽略。
索引请求中属性的类型值不同于架构中注册的类型。此问题会导致 Cloud Search 在编制索引时返回错误。
使用多种查询类型测试架构
在注册您的架构以将其用于大型生产数据存储区之前,建议先使用一个小型测试数据存储区对其进行测试。通过使用小型测试存储区测试架构,您可以快速对架构作出调整并删除已编入索引的数据,而不会影响大型索引或现有生产索引。对于测试数据存储区,建议创建一个仅向测试用户提供授权的 ACL,以使其他用户不会在搜索结果中看到此数据。
要创建用于验证搜索查询的搜索界面,请参阅搜索界面。
本部分包含可用于测试电影架构的几个不同示例查询。
使用通用查询进行测试
通用查询返回数据源中包含特定字符串的所有项。您可以在搜索界面中输入“titanic”一词并按 Return 键对电影数据源运行通用查询。搜索结果中应该会返回所有带有“titanic”字样的电影。
使用运算符进行测试
在查询中添加运算符可将结果限制为与该运算符值匹配的项。例如,您可能需要使用 actor 运算符来查找由特定演员主演的全部电影。使用搜索界面时,只需输入运算符/值对(例如“actor:Zane”)并按 Return 键,即可执行此运算符查询。搜索结果中应该会返回 Zane 参演的所有电影。
调整架构
在您的架构和数据被使用之后,您可以继续监控哪些对您的用户有用,哪些对他们无用。对于以下情况,建议您适当调整架构:
- 将尚未编入索引的字段编入索引。例如,您的用户可能会根据导演姓名反复搜索电影,因此您可以调整架构以支持使用导演姓名作为运算符。
- 根据用户反馈更改搜索运算符名称。运算符名称应该是简单易懂的。如果您的用户总是“记错”运算符名称,建议您更改此名称。
架构更改后重新编制索引
更改架构中的以下任何值都不需要将数据重新编入索引。您只需提交一个新的 UpdateSchema 请求,您的索引仍会继续正常运作:
- 运算符名称。
- 整数类型的最小值和最大值。
- 按整数值和枚举值排序的排名。
- 新鲜度选项。
- 显示选项。
对于以下更改,先前已编入索引的数据将继续根据先前注册的架构工作。但是,如果更新后的架构发生了以下更改,则现有条目必须重新编入索引,这些更改才能体现在该架构中:
- 添加新的属性或对象,或者移除现有属性或对象
- 将
isReturnable、isFacetable或isSortable从false更改为true。
只有在已明确用例和需求的情况下,您才能将 isFacetable 或 isSortable 设置为 true。
最后,如果您通过标记媒体资源 isSuggestable 来更新架构,则必须重新编制数据索引,这会导致该媒体资源的自动补全功能出现延迟。
不允许的属性更改
有些架构更改是不允许的,即使将数据重新编入索引也是如此,因为这些更改会破坏索引,或者产生不良或不一致的搜索结果。具体包括对以下项的更改:
- 属性数据类型。
- 属性名称。
- “
exactMatchWithOperator”设置。 - “
retrievalImportance”设置。
但是,有一种方法可以解决该限制。
对架构进行复杂更改
为避免会导致搜索结果不佳或搜索索引损坏的更改,Cloud Search 会在存储区被编入索引后阻止 UpdateSchema 请求中的某些类型更改。例如,属性的数据类型或名称在设置后即无法更改。您无法通过简单的 UpdateSchema 请求实现这些更改,即使将数据重新编入索引也是如此。
如果您必须对架构进行其他不允许的更改,通常可以通过执行一系列允许的更改来实现相同效果。一般来说,这需要先将已编入索引的属性从旧对象定义迁移到较新的对象定义,然后发送一个仅使用较新属性的索引请求。
以下步骤演示了如何更改媒体资源的数据类型或名称:
- 在架构的对象定义中添加新属性。请使用与要更改的属性不同的名称。
- 使用新定义发出 UpdateSchema 请求。请务必在请求中发送整个架构,包括新旧属性。
从数据存储区回填索引。要回填索引,请使用新属性发送所有索引请求,而不要使用旧属性,否则会导致将查询匹配项重复统计两次。
- 在索引回填期间,检查新属性并默认使用旧属性,以免出现不一致的行为。
- 回填完成后,运行测试查询以进行验证。
删除旧属性。再次发出 UpdateSchema 请求但不带旧属性名称,并且在以后的索引请求中停止使用旧属性名称。
将旧属性的所有用例都迁移到新属性。例如,如果您将属性名称从 creator 更改为 author,则必须更新查询代码才能在之前引用 creator 的地方使用 author。
Cloud Search 会将所有被删除的媒体资源或对象的记录都保留 30 天,以防因重复使用而导致异常索引结果。在这 30 天里,您应该从被删除对象或属性的所有用例中迁出,包括在以后的索引请求中将其略去。这样做可以确保您日后决定恢复该属性或对象时,可以保持索引的正确性。
了解大小限制
Cloud Search 对结构化数据对象和架构的大小施加了限制。具体限制如下:
- 顶层对象的数量不得超过 10 个。
- 结构化数据层次结构的深度不得超过 10 级。
- 对象中的字段总数不得超过 1000 个,其中包括原始字段的数量以及各嵌套对象中的字段总数。
后续步骤
以下是您后续可执行的几个步骤:
创建一个搜索界面来测试您的架构。
调整架构以提高搜索质量。
了解如何利用
_dictionaryEntry架构为公司常用的术语定义同义词。如需使用_dictionaryEntry架构,请参阅定义同义词。创建连接器。