
1. शुरू करने से पहले
इस कोडलैब में, आपको ओरिजनल ब्लॉग-स्पैम-कमेंट डेटासेट से बनाए गए टेक्स्ट क्लासिफ़िकेशन मॉडल को अपडेट करने का तरीका बताया गया है. हालांकि, इसे आपके अपने कमेंट से बेहतर बनाया गया है, ताकि आपके पास एक ऐसा मॉडल हो जो आपके डेटा के साथ काम करे.
ज़रूरी शर्तें
यह कोडलैब, Flutter ऐप्लिकेशन में टेक्स्ट क्लासिफ़िकेशन की सुविधा इस्तेमाल करने से जुड़ी जानकारी वाले पाथवे का हिस्सा है. इस पाथवे में दिए गए कोडलैब, क्रम से दिए गए हैं. आपको जिस ऐप्लिकेशन और मॉडल पर काम करना है उसे पहले ही बनाया गया हो. ऐसा तब किया गया हो, जब आपने कोडलैब के निर्देशों का पालन किया हो. अगर आपने अब तक पिछली गतिविधियां पूरी नहीं की हैं, तो कृपया उन्हें अभी पूरा करें:
- TensorFlow Lite Model Maker कोडलैब की मदद से, स्पैम टिप्पणी का पता लगाने वाले मॉडल को ट्रेन करना
- टिप्पणियों में स्पैम का पता लगाने के लिए, Flutter ऐप्लिकेशन बनाने से जुड़ी कोडलैब
आपको क्या सीखने को मिलेगा
- TensorFlow Lite Model Maker की मदद से, स्पैम वाली टिप्पणियों का पता लगाने वाला मॉडल ट्रेन करें कोडलैब में बनाए गए टेक्स्ट क्लासिफ़िकेशन मॉडल को अपडेट करने का तरीका.
- अपने मॉडल को पसंद के मुताबिक बनाने का तरीका, ताकि वह आपके ऐप्लिकेशन में सबसे ज़्यादा होने वाले स्पैम को ब्लॉक कर सके.
आपको किन चीज़ों की ज़रूरत होगी
- Flutter ऐप्लिकेशन और स्पैम फ़िल्टर करने वाला मॉडल, जिसे आपने पिछली गतिविधियों में देखा और बनाया था.
2. टेक्स्ट क्लासिफ़िकेशन की सुविधा को बेहतर बनाना
- इस रिपॉज़िटरी को क्लोन करके और
tfserving-flutter/codelab2/finishedफ़ोल्डर से ऐप्लिकेशन लोड करके, इस कोड का कोड पाया जा सकता है. - TensorFlow Serving Docker इमेज शुरू करने के बाद, बनाए गए ऐप्लिकेशन में
buy my book to learn online tradingडालें. इसके बाद, gRPC > Classify पर क्लिक करें.
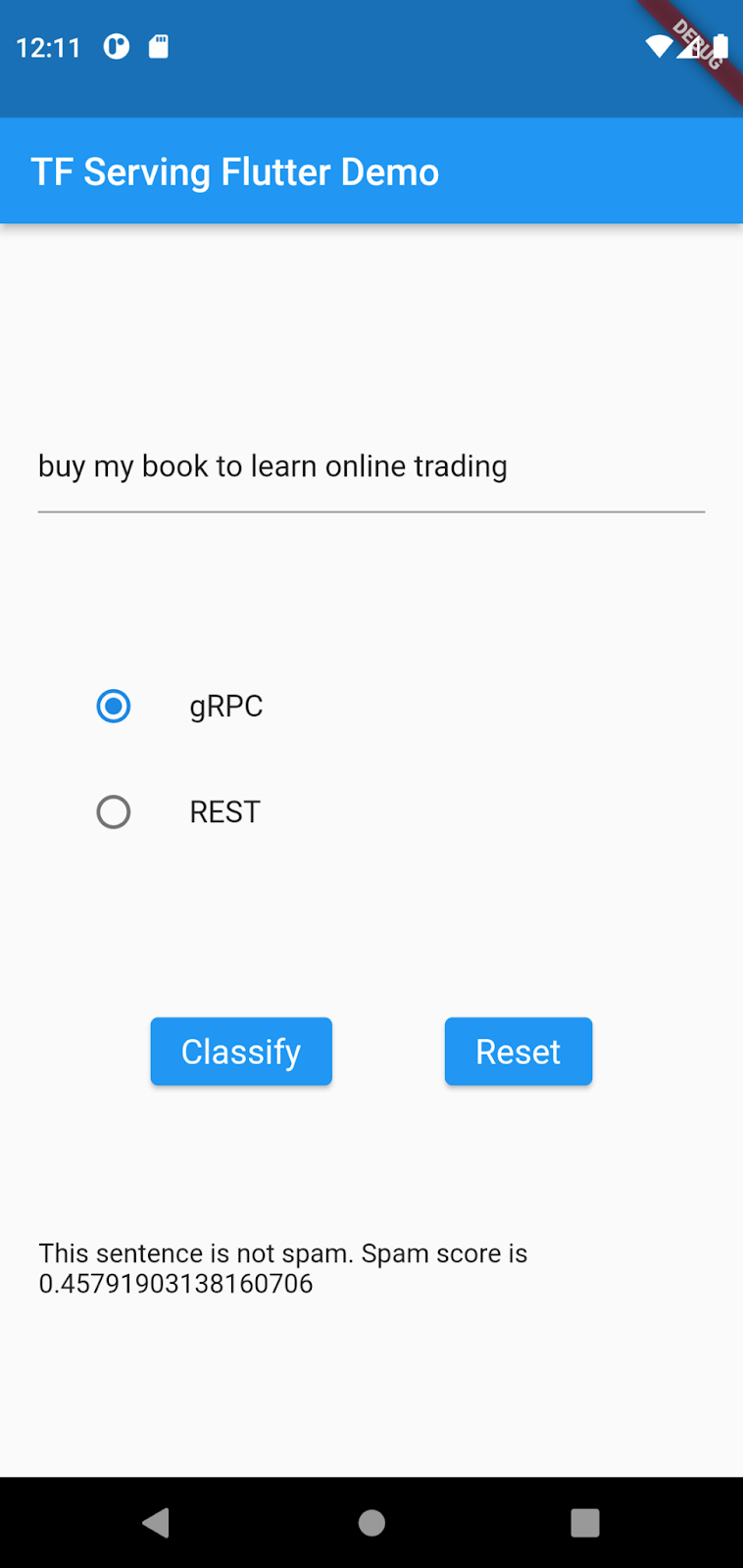
ऐप्लिकेशन का स्पैम स्कोर कम है, क्योंकि ओरिजनल डेटासेट में ऑनलाइन ट्रेडिंग के बारे में ज़्यादा जानकारी नहीं है. साथ ही, मॉडल को यह नहीं पता कि यह स्पैम है. इस कोडलैब में, मॉडल को नए डेटा के साथ अपडेट किया जाता है, ताकि मॉडल उसी वाक्य को स्पैम के तौर पर पहचान सके!
3. अपनी CSV फ़ाइल में बदलाव करना
ओरिजनल मॉडल को ट्रेन करने के लिए, एक डेटासेट बनाया गया था. यह डेटासेट, CSV (lmblog_comments.csv) फ़ाइल के तौर पर बनाया गया था. इसमें करीब एक हज़ार टिप्पणियां थीं. इन टिप्पणियों को स्पैम या स्पैम नहीं के तौर पर लेबल किया गया था. (अगर आपको CSV फ़ाइल की जांच करनी है, तो उसे किसी भी टेक्स्ट एडिटर में खोलें.)
CSV फ़ाइल में, पहली लाइन में कॉलम के बारे में जानकारी होनी चाहिए. इन कॉलम को commenttext और spam के तौर पर लेबल किया गया है. इसके बाद की हर लाइन में यह फ़ॉर्मैट होता है:

दाईं ओर मौजूद लेबल को स्पैम के लिए true वैल्यू और स्पैम नहीं के लिए false वैल्यू असाइन की गई है. उदाहरण के लिए, तीसरी लाइन को स्पैम माना जाता है.
अगर लोग आपकी वेबसाइट पर ऑनलाइन ट्रेडिंग के बारे में मैसेज भेजकर स्पैम करते हैं, तो अपनी वेबसाइट के सबसे नीचे स्पैम टिप्पणियों के उदाहरण जोड़े जा सकते हैं. उदाहरण के लिए:
online trading can be highly highly effective,true online trading can be highly effective,true online trading now,true online trading here,true online trading for the win,true
- फ़ाइल को
lmblog_comments.csvजैसे किसी नए नाम से सेव करें, ताकि इसका इस्तेमाल किसी नए मॉडल को ट्रेन करने के लिए किया जा सके.
इस कोडलैब के बाकी हिस्से के लिए, दिए गए उदाहरण का इस्तेमाल करें. इसे Cloud Storage पर होस्ट किया गया है और इसमें ऑनलाइन ट्रेडिंग से जुड़े अपडेट शामिल हैं. अगर आपको अपने डेटासेट का इस्तेमाल करना है, तो कोड में मौजूद यूआरएल को बदला जा सकता है.
4. नए डेटा के साथ मॉडल को फिर से ट्रेन करें
मॉडल को फिर से ट्रेन करने के लिए, (SpamCommentsModelMaker.ipynb) से कोड का फिर से इस्तेमाल किया जा सकता है. हालांकि, इसे नए CSV डेटासेट पर पॉइंट करें. इसे lmblog_comments_extras.csv कहा जाता है. अगर आपको अपडेट किए गए कॉन्टेंट के साथ पूरी नोटबुक चाहिए, तो इसे SpamCommentsUpdateModelMaker.ipynb. के तौर पर देखा जा सकता है
अगर आपके पास Colaboratory का ऐक्सेस है, तो इसे सीधे लॉन्च किया जा सकता है. इसके अलावा, रिपॉज़िटरी से कोड पाएं और फिर उसे अपनी पसंद के नोटबुक एनवायरमेंट में चलाएं.
अपडेट किया गया कोड, इस कोड स्निपेट की तरह दिखता है:
training_data = tf.keras.utils.get_file(fname='comments-spam-extras.csv',
origin='https://storage.googleapis.com/laurencemoroney-blog.appspot.com/
lmblog_comments_extras.csv',
extract=False)
ट्रेनिंग के दौरान, आपको यह देखना चाहिए कि मॉडल अब भी ज़्यादा सटीक तरीके से ट्रेन हो रहा है या नहीं:

/mm_update_spam_savedmodel के पूरे फ़ोल्डर को कंप्रेस करें और जनरेट की गई mm_update_spam_savedmodel.zip फ़ाइल डाउनलोड करें.
# Rename the SavedModel subfolder to a version number
!mv /mm_update_spam_savedmodel/saved_model /mm_update_spam_savedmodel/123
!zip -r mm_update_spam_savedmodel.zip /mm_update_spam_savedmodel/
5. Docker शुरू करें और अपने Flutter ऐप्लिकेशन को अपडेट करें
- डाउनलोड की गई
mm_update_spam_savedmodel.zipफ़ाइल को किसी फ़ोल्डर में अनज़िप करें. इसके बाद, पिछले कोडलैब से Docker कंटेनर इंस्टेंस को रोकें और उसे फिर से शुरू करें. हालांकि,PATH/TO/UPDATE/SAVEDMODELप्लेसहोल्डर को उस फ़ोल्डर के पूरे पाथ से बदलें जिसमें आपकी डाउनलोड की गई फ़ाइलें मौजूद हैं):
docker run -it --rm -p 8500:8500 -p 8501:8501 -v "PATH/TO/UPDATE/SAVEDMODEL:/models/spam-detection" -e MODEL_NAME=spam-detection tensorflow/serving
- अपने पसंदीदा कोड एडिटर में
lib/main.dartफ़ाइल खोलें. इसके बाद, उस हिस्से को ढूंढें जोinputTensorNameऔरoutTensorNameवैरिएबल को तय करता है:
const inputTensorName = 'input_3';
const outputTensorName = 'dense_5';
inputTensorNameवैरिएबल को ‘input_1'वैल्यू औरoutputTensorNameवैरिएबल को'dense_1'वैल्यू पर फिर से असाइन करें:
const inputTensorName = 'input_1';
const outputTensorName = 'dense_1';
- डाउनलोड की गई
vocab.txtफ़ाइल कोlib/assets/फ़ोल्डर में कॉपी करें, ताकि मौजूदा फ़ाइल की जगह नई फ़ाइल आ जाए. - Android एम्युलेटर से, टेक्स्ट क्लासिफ़िकेशन वाले Flutter ऐप्लिकेशन को मैन्युअल तरीके से हटाएं.
- ऐप्लिकेशन लॉन्च करने के लिए, अपने टर्मिनल में
'flutter run'कमांड चलाएं. - ऐप्लिकेशन में,
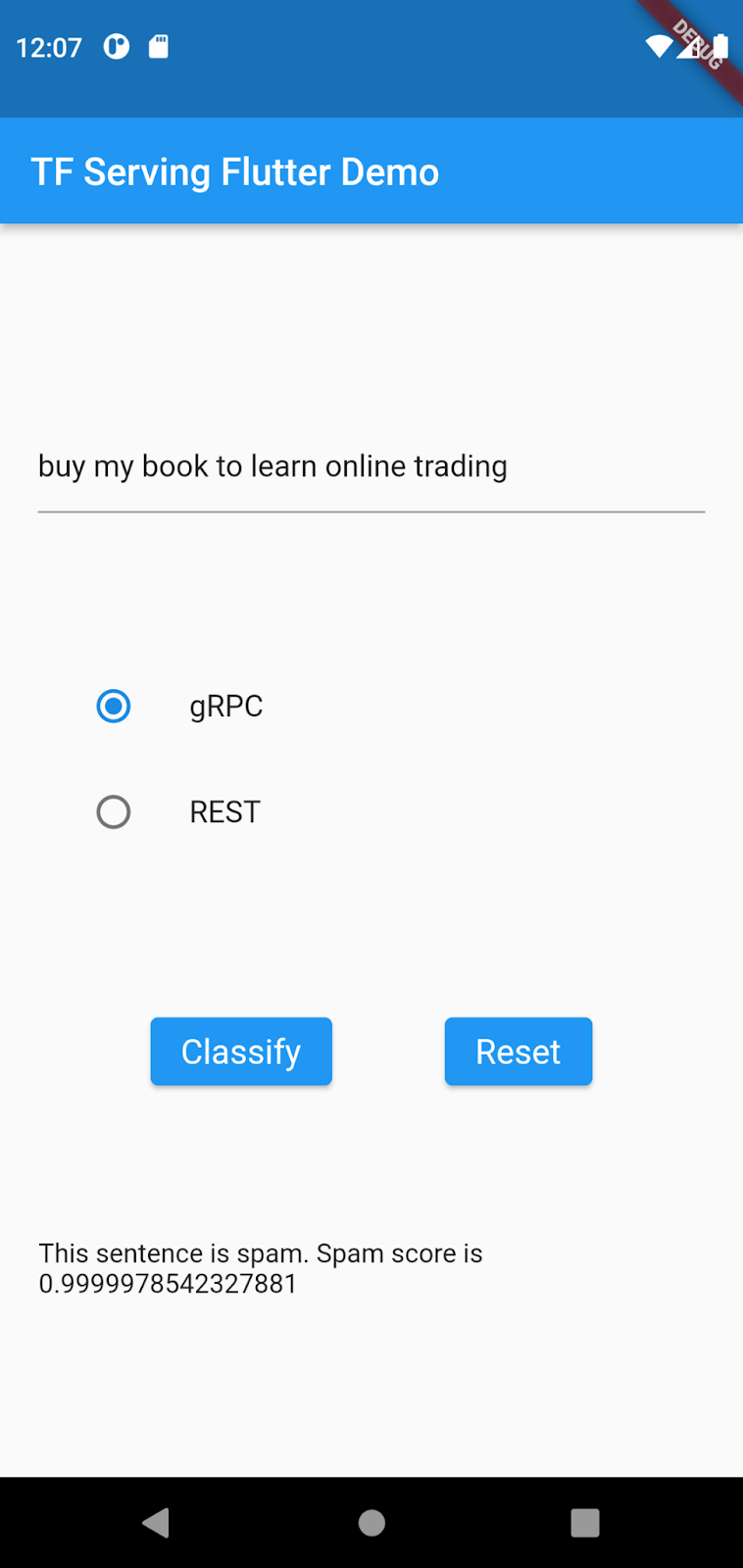
buy my book to learn online tradingडालें. इसके बाद, gRPC > Classify पर क्लिक करें.
अब मॉडल को बेहतर बनाया गया है, ताकि वह मेरी किताब खरीदो से लेकर ऑनलाइन ट्रेडिंग जैसे कॉन्टेंट को स्पैम के तौर पर पहचान सके.
6. बधाई हो
आपने नए डेटा के साथ मॉडल को फिर से ट्रेन किया है. साथ ही, इसे Flutter ऐप्लिकेशन के साथ इंटिग्रेट किया है. इसके अलावा, आपने स्पैम वाले नए वाक्यों का पता लगाने की सुविधा को अपडेट किया है!