
1. 准备工作
本 Codelab 是基于本系列之前的 Codelab 的最终结果而设计的,本 Codelab 旨在通过 TensorFlow.js 检测垃圾评论。
在上一个 Codelab 中,您为一个虚构的视频博客创建了一个功能完备的网页。借助由浏览器中的 TensorFlow.js 支持的预训练垃圾评论检测模型,您可以在将评论发送到服务器进行存储或发送到其他连接的客户端之前,对评论进行过滤。
该 Codelab 的最终结果如下所示:
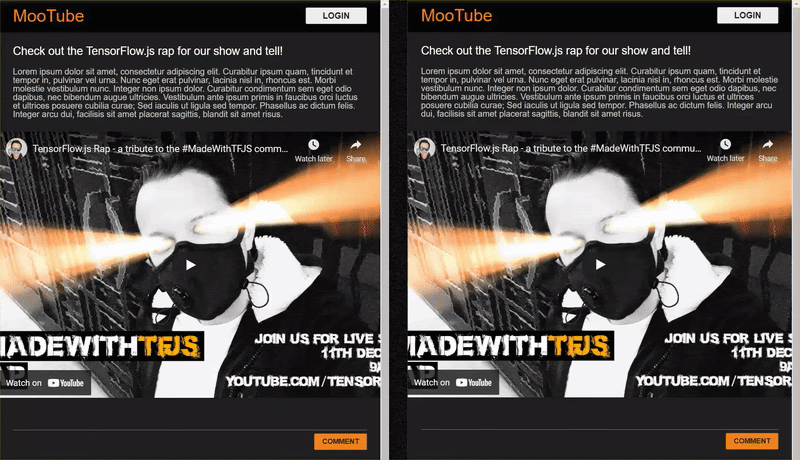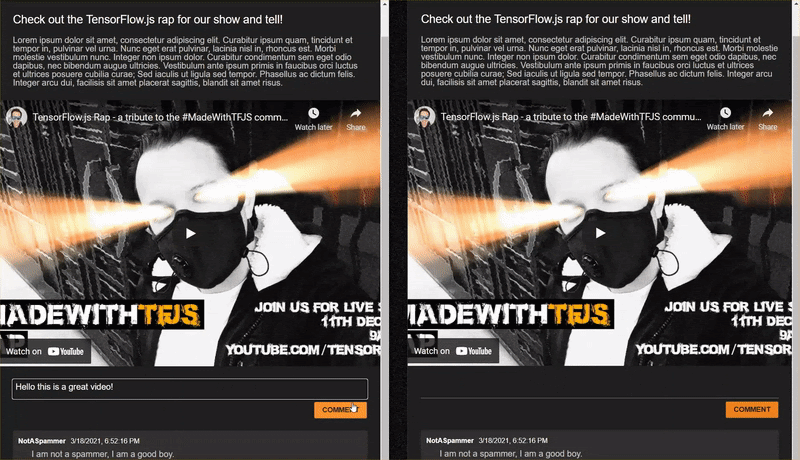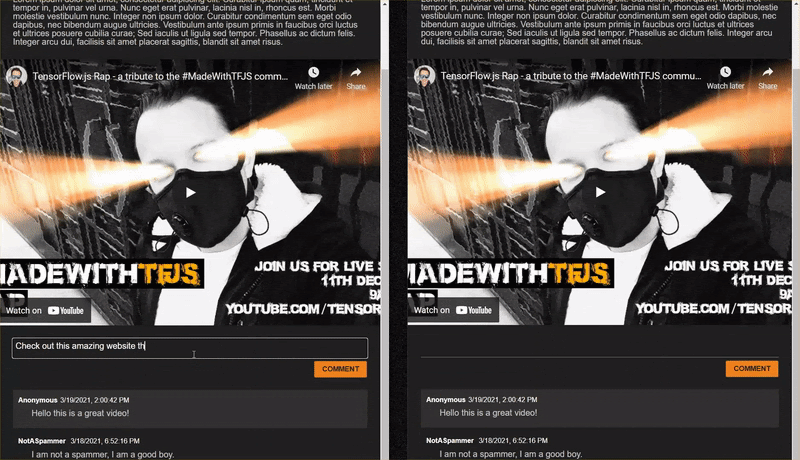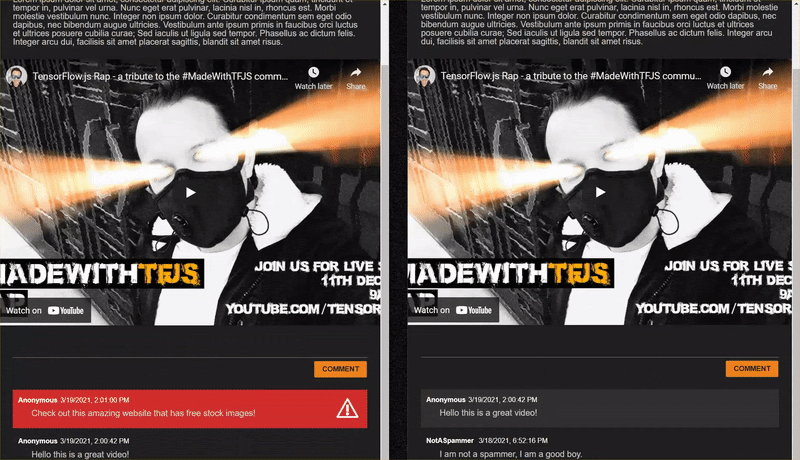
虽然这种方法非常有效,但还有一些极端情况需要探索无法检测到。您可以重新训练模型,使其无法处理无法处理的情况。
此 Codelab 将重点介绍如何使用自然语言处理(一种通过计算机理解人类语言的艺术),并向您展示如何修改您创建的现有 Web 应用(强烈建议您按顺序学习 Codelab{/1 }) 来解决垃圾评论的真正问题,许多 Web 开发者在处理当今日益流行的热门 Web 应用时,肯定会遇到这些问题。
在此 Codelab 中,您将进一步重新训练机器学习模型,以根据当前趋势或热门讨论主题(允许您使模型保持最新状态和考虑相关因素)随时间推移不断变化的垃圾邮件内容此类更改。
前提条件
- 完成了本系列中的第一个 Codelab。
- 具备网络技术(包括 HTML、CSS 和 JavaScript)方面的基础知识。
构建内容
您将为假视频博客重复使用包含实时评论部分的先前构建的网站,并升级该网站以使用 TensorFlow.js 加载经过训练的自定义垃圾内容检测模型版本,这样它就能在以前可能会出现的极端情况下表现更好。当然,作为 Web 开发者和工程师,您可以更改这一假设的用户体验,使其能够在日常工作中可能用到的任何网站上重复使用,并调整解决方案以适应任何客户用例(可能是博客、论坛或一些 CMS 格式,例如 Drupal。
让我们开始吧...
学习内容
您将学习以下内容:
- 识别预训练模型在哪些极端情况下失败
- 重新训练使用 Model Maker 创建的垃圾内容分类模型。
- 将这个基于 Python 的模型导出为 TensorFlow.js 格式,以在浏览器中使用。
- 使用新训练的模型更新托管模型及其字典,并查看结果
本实验假设您熟悉 HTML5、CSS 和 JavaScript。您还将通过“co lab”笔记本运行一些 Python 代码,以重新训练使用 Model Maker 创建的模型,但您不必熟悉 Python。
2. 开始设置代码
您将再次使用 Glitch.com 来托管和修改 Web 应用。如果您尚未完成必备 Codelab,则可以在此处克隆最终结果作为起点。如果您对代码的工作原理有疑问,强烈建议您完成之前的 Codelab,了解如何继续构建这个有效的 Web 应用,然后再继续。
在 Glitch 上,只需点击重新混音按钮即可创建分支,并生成一组新的文件供您编辑。
3.探索之前解决方案中的极端情况
如果您打开刚刚复制的已完成网站并尝试输入一些评论,那么您会发现该评论在大部分情况下都能按预期发挥作用,可以屏蔽那些疑似垃圾内容的评论,以及允许合法回复。
不过,如果您能够巧妙地尝试短语和短语来破坏模型,也许会在某个时候取得成功。通过一些试验和错误,您可以手动创建如下所示的示例。尝试将这些内容粘贴到现有 Web 应用,检查控制台,并查看垃圾评论返回的可能性:
没有问题发布的合法评论(真负例):
- “哇,我喜欢这个视频,太棒了。” 垃圾内容概率:47.91854%
- “非常喜欢这些演示!想了解更多详情?” 垃圾内容概率:47.15898%
- “我可以转到哪个网站了解详情?” 垃圾内容概率:15.32495%
太棒了,上述所有选项的概率都非常低,SPAM_THRESHOLD 75% 的用户采取行动前的概率降幅(定义script.js代码)。
现在,让我们试着撰写一些更紧张一点的前贴评论,虽然这些评论并非如此...
被标记为垃圾内容的合法评论(假正例):
- “有人可以关联他戴的口罩的网站吗?” 垃圾内容概率:98.46466%
- “我可以在 Spotify 上购买这首歌曲吗?请告诉我!” 垃圾内容概率:94.40953%
- “有人可以联系我详细解释如何下载 TensorFlow.js 吗?” 垃圾内容概率:83.20084%
糟糕!这些本该允许发表的合法评论似乎被标记为了垃圾内容。如何解决此问题?
一个简单的选项是将 SPAM_THRESHOLD 的置信度提高到 98.5% 以上。在这种情况下,系统会发布这些分类有误的评论。因此,让我们继续了解其他可能的结果...
垃圾评论(垃圾评论):
- “这很棒,但是我网站上最好下载链接。” 垃圾内容概率:99.77873%
- “我知道某些人可以买到一些药物,他们只需查看我的 pr0file 即可了解详情” 垃圾内容概率:98.46955%
- “请查看我的个人资料,下载更精彩的视频!http://example.com”:垃圾内容概率:96.26383%
好了,这与我们最初的 75% 阈值一样按预期运行,但是在上一步中,您已将 SPAM_THRESHOLD 的置信度更改为 98.5% 以上,这意味着此处将允许 2 个示例,所以阈值可以采纳过高。也许 96% 更好?不过,如果您这么做,那么当上一条评论的合法性为 98.46466% 时,会将其标记为垃圾评论(假正例)。
在这种情况下,最好捕获所有这些真实的垃圾评论,并简单地针对上述失败情况重新训练。通过将阈值设置为 96%,所有实际的阳性样本仍会被捕获,且您可以消除上述两个假正例。只更改一个数字还不错。
让我们继续...
允许发布的垃圾评论(假负例):
- “请查看我的个人资料,下载更精彩的精彩视频!” 垃圾内容概率:7.54926%
- “享受健身班的折扣,查看 pr0file!” 垃圾内容概率:17.49849%
- “哇,股票刚刚上涨了!赶早行动! 垃圾内容概率:20.42894%
对于这些注释,您无需进一步更改 SPAM_THRESHOLD 值。将垃圾内容的门槛从 96% 降至 9% 左右会导致真实评论被标记为垃圾评论 - 其中一个评论虽然合法,但仍然有 58% 的评分。处理此类评论的唯一方法是,使用训练数据中包含的此类极端情况重新训练模型,以便学习根据垃圾内容来调整其视图。
虽然目前唯一的选项是重新训练模型,但当您决定调用垃圾内容来改善性能时,也了解到了如何优化阈值。对人类而言,75% 似乎相当有把握,但在此模型下,您需要提高到接近 81.5% 才能通过示例输入取得更好的效果。
没有哪个魔法值适用于不同的模型,在根据真实模型的数据找出合适的模型后,需要根据模型来设置此阈值。
在某些情况下,假正例(或负例)可能会导致严重后果(例如在医疗行业),因此您可以将阈值调整为非常高,并针对未达到最低标准的广告客户申请更多人工审核。这是开发者的选择,需要进行一些实验。
4.重新训练垃圾评论检测模型
在上一部分中,您指出了对于模型而言失败的许多极端情况,唯一的选择是重新训练模型以适应这些情况。在正式版系统中,您可能会发现这些评论随时间推移而发生变化,因为有人将某条评论手动标记为垃圾评论后又被允许发布,或者管理员审核被举报的评论时意识到某些评论实际上并非垃圾评论,因此可以将此类评论标记为需要重新训练。假设您针对这些极端情况收集了大量新数据(为获得最佳效果,您应该尽可能使用这些新语句的某些变体),我们将继续向您展示如何在考虑这些极端情况下重新训练模型。
预制模型回顾
您使用的预制模型是由第三方通过 Model Maker 创建的模型,该模型使用“平均字词嵌入”模型运作。
由于该模型是使用 Model Maker 构建的,因此您需要暂时切换到 Python 以重新训练模型,然后将创建的模型导出为 TensorFlow.js 格式,以便在浏览器中使用。幸好,模型制作工具让他们的模型使用变得非常简单,所以我们可以轻松按照说明操作,我们将引导您完成该过程,因此,如果您以前从未使用过 Python,请不要担心!
Colab
在本 Codelab 中,您不太想要设置一个安装了各种 Python 实用程序的 Linux 服务器,因此只需使用网络浏览器通过“Colab 笔记本”执行代码即可。这些笔记本可以连接到“后端”,后端服务器只是预安装了一些内容的服务器,然后您就可以通过该浏览器在网络浏览器中执行任意代码并查看结果。这对于快速设计原型或用于此类教程非常有用。
只需访问 colab.research.google.com,您将看到一个欢迎屏幕,如下所示:
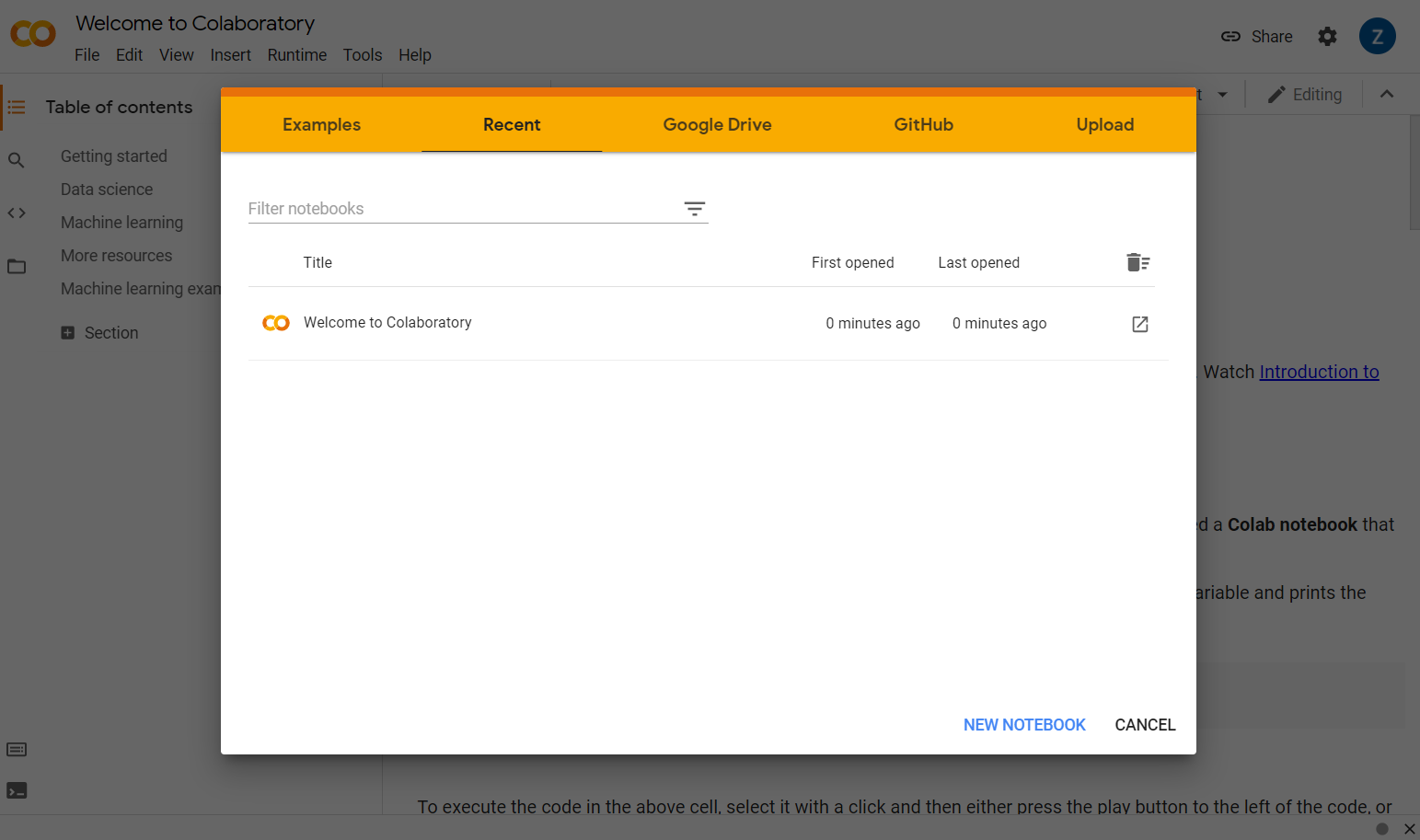
现在,点击弹出式窗口右下角的 New Notebook(新建笔记本)按钮,您应该会看到如下所示的空白 Colab。
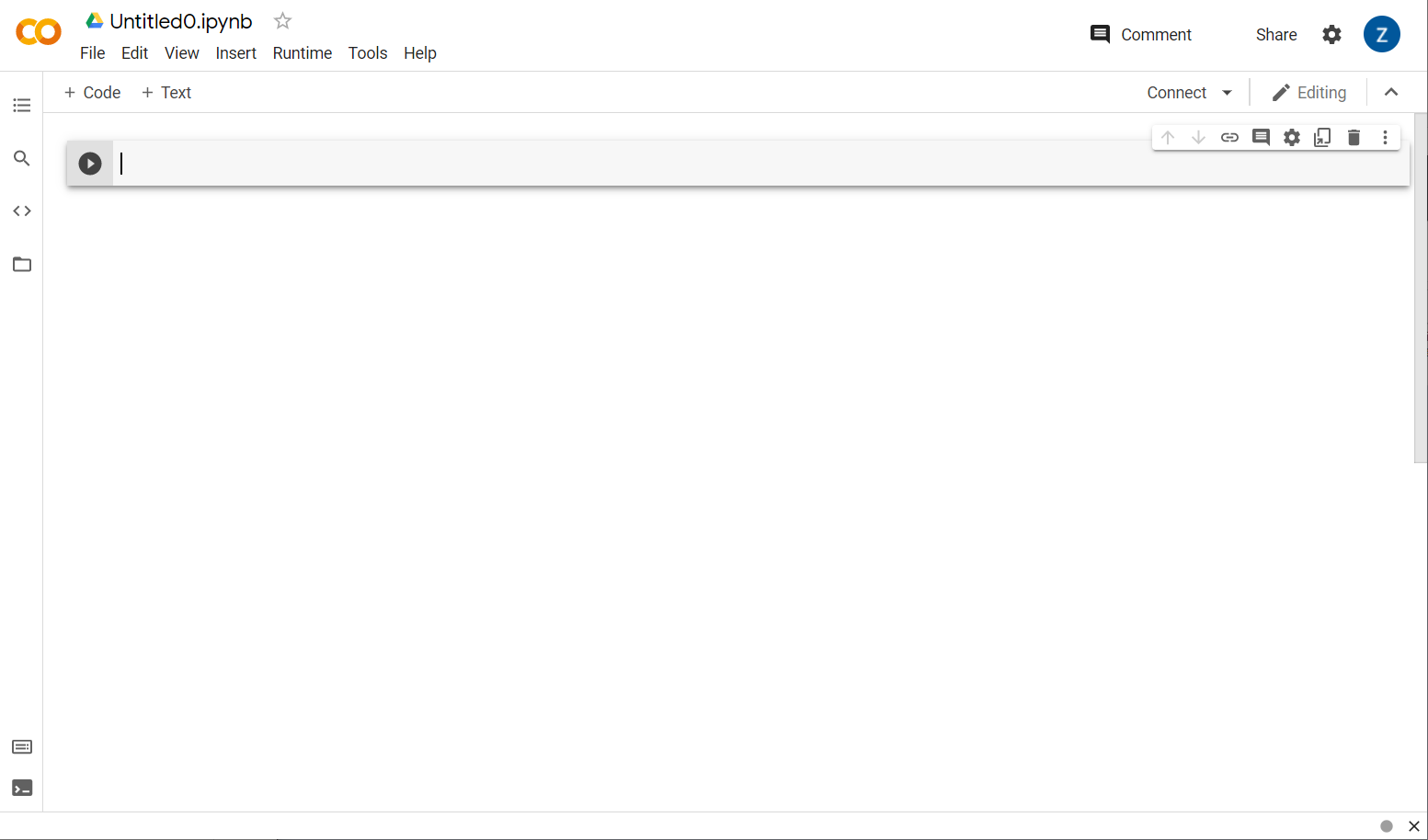
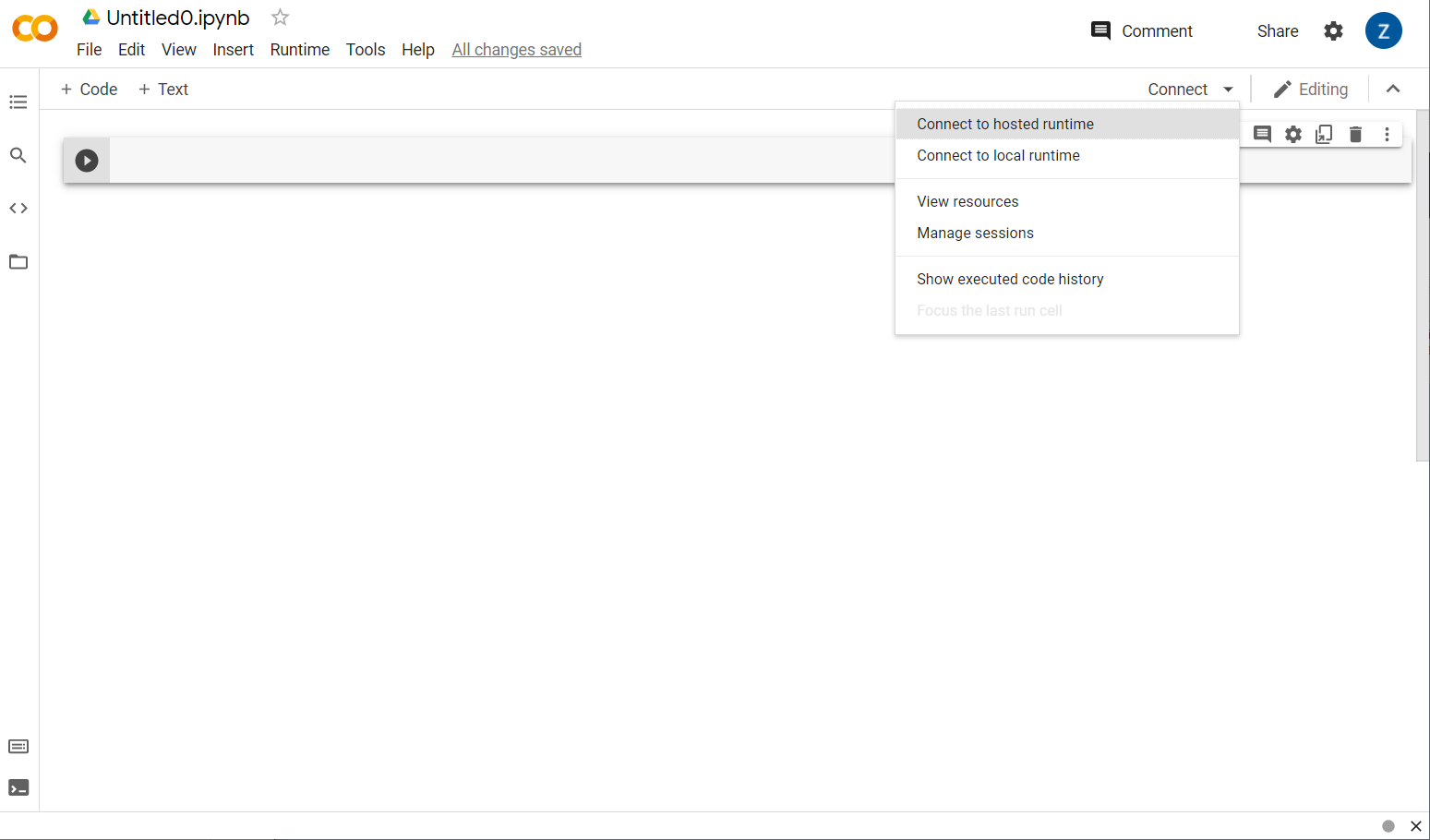
太好了!下一步是将前端 Colab 连接到某个后端服务器,以便执行您将编写的 Python 代码。为此,请点击右上方的连接,然后选择连接到托管的运行时。
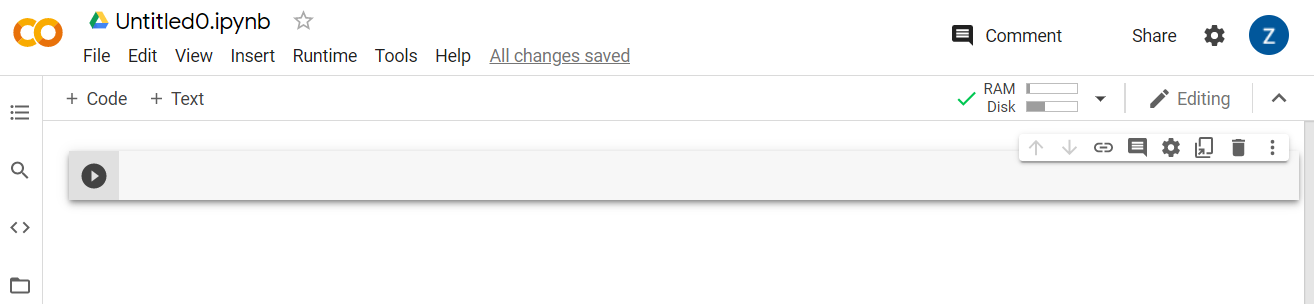
连接后,您应该会看到 RAM 和磁盘图标显示在相应的位置,如下所示:
太棒了!您现在可以开始使用 Python 编写代码来重新训练模型。为此,请按以下步骤操作:
第 1 步
在目前为空的单元格中,复制以下代码。它将使用 Python 的软件包管理器(名为“pip”)安装 TensorFlow Lite Model Maker(这与 npm 相似,但此 Codelab 的大多数读者可能都更熟悉 JS 生态系统中的这个组件):
!pip install -q tflite-model-maker
不过,将代码粘贴到单元格中并不会执行该代码。接下来,将鼠标指针悬停在您粘贴上述代码的灰色单元格上,单元格左侧会显示一个小的“播放”图标,突出显示如下:
 点击“播放”按钮即可执行刚刚在单元格中输入的代码。
点击“播放”按钮即可执行刚刚在单元格中输入的代码。
您现在会看到正在安装的模型制作工具:
如上所示完成此单元格的执行后,请继续执行下面的下一步。
第 2 步
接下来,添加一个如下所示的新代码单元格,以便在第一个单元格后粘贴一些代码并单独执行:
执行的下一个单元格将具有许多导入项,笔记本的其余部分中的代码需要使用这些导入项。将以下内容复制并粘贴到创建的新单元格中:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
相当熟悉的内容,即使您不熟悉 Python。您只是导入了垃圾邮件分类器所需的一些实用程序和 Model Maker 函数。系统还会检查是否运行 TensorFlow 2.x(这是使用 Model Maker 的必要条件)。
最后,和以前一样,将鼠标悬停在单元格上时按“播放”图标来执行单元格,然后添加新的代码单元格以供下一步使用。
第 3 步
接下来,您需要将数据从远程服务器下载到您的设备,并将 training_data 变量设置为最终生成的本地文件的路径:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/laurencemoroney-blog.appspot.com/jm_blog_comments_extras.csv', extract=False)
Model Maker 可以通过简单的 CSV 文件训练模型,例如下载的文件。您只需指定哪些列包含文本,哪些列包含标签。您将在第 5 步中了解如何操作。如有需要,您可以直接自行下载 CSV 文件以查看其中包含的内容。
您一定非常热衷于查看此文件的名称为 jm_blog_comments_extras.csv - 此文件只是我们用于生成首条垃圾评论模型的原始训练数据与发现的新边缘情况数据结合在一起,以便全部保存在同一个文件中。除了您想要学习的新句子之外,您还需要用于训练模型的原始训练数据。
可选:如果您下载此 CSV 文件并查看最后几行内容,则会看到之前无法正常运行的极端情况的示例。它们刚刚添加到了现有训练数据的末尾,即预训练的模型,用于训练模型。
执行此单元格,然后在其完成执行后,添加新的单元格,然后转到第 4 步。
第 4 步
使用 Model Maker 时,您无需从头开始构建模型。您通常会使用现有模型,并根据需要进行自定义。
Model Maker 提供了多个您可以使用的预学模型嵌入,但最快速、最简单的入门方式是 average_word_vec,在之前的 Codelab 中,您将使用它来构建您的网站。代码如下:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
接下来,将所选内容粘贴到新单元格后,再运行一次。
了解
num_words
parameter
这是您希望模型使用的字词数。您可能认为这部分内容越有效,但系统一般会根据每个字词的使用频率找到最佳的点。如果您使用整个语料库中的每个字词,最终可能会导致模型尝试学习并平衡仅使用一次的字词的权重 - 这并非很有用。在任何文本语料库中,您会发现许多单词只使用一次或两次,通常不值得在模型中使用,因为它们对总体情感的影响微乎其微。因此,您可以使用 num_words 参数,根据所需的字词数量调整模型。这里的数字越小,模型速度越快,但速度可能会越小,因为识别的字词越少。这里的数值越大,模型越大且速度可能会越慢。找到最佳方案是关键所在,机器学习工程师将负责确定最适合您的用例的方案。
了解
wordvec_dim
parameter
wordvec_dim 参数是您希望为每个字词的向量使用的维度数。这些维度本质上是不同的特征(在训练时由机器学习算法创建),程序可使用这些特征尝试以某种有意义的方式尝试并最有效地关联相似的字词。
例如,如果您的某个维度衡量的是某个字词的“医疗”,那么“药丸”等字词在此维度中得分可能会较高,并且会与“xray”等其他高分字词关联,但“猫”得分较低。因此,当与可能决定重要的其他潜在维度结合使用时,“医疗维度”对于确定垃圾内容非常有用。
如果某些字词在“医疗维度”中得分较高,那么次级维度可能有助于将字词与人体联系起来。“腿”、“手臂”、“颈部”等字词在此方面的得分较高,但在医学维度中也是如此。
然后,该模型可以使用这些维度来检测更有可能与垃圾内容相关的字词。或许垃圾邮件更有可能包含同时属于身体部位和人体部位的字词。
根据研究中的经验法则,字词数量的第四根根适用于此参数。因此,如果我使用 2000 个字词,最好从 7 个维度入手。如果您更改了字词数量,也可以进行更改。
了解
seq_len
parameter
在输入值方面,模型通常非常严格。对于语言模型,这意味着语言模型可以对特定静态长度的句子进行分类。这由 seq_len 参数确定,其中的参数表示“序列长度”。将字词转换为数字(或词法单元)时,一个句子就会成为这些词法单元的序列。因此,您的模型将接受训练(在本例中为)对具有 20 个词法单元的句子进行分类和识别。如果句子长度超过此值,则会被截断。如果长度较短,则需要填充,如本系列中的第一个 Codelab 所示。
第 5 步 - 加载训练数据
您之前下载了 CSV 文件。现在,该使用数据加载器将其转换为模型可识别的训练数据了。
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
在编辑器中打开 CSV 文件后,您会看到每行只有 2 个值,这些值在文件的第一行中会带有文字说明。通常每个条目都被视为一个“列”。您会看到第一列的描述符是 commenttext,每行中的第一个条目是注释的文本。
同样,第二列的描述符是 spam,每行上的第二个条目是 TRUE 或 FALSE,表示该文本是否为是否被视为垃圾评论。其他属性可设置您在第 4 步中创建的模型规范以及分隔符,在此例中,该分隔符是英文逗号,表示文件是以英文逗号分隔的。此外,您还设置了一个 shuffle 参数,用于随机重新排列训练数据,以便在整个数据集中随机分布相似或一起收集的内容。
然后,您将使用 data.split() 将数据拆分为训练和测试数据。0.9 表示数据集中有 90% 用于训练,其余用于测试。
第 6 步 - 构建模型
添加另一个单元格,我们将在其中添加代码以构建模型:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
这会使用 Model Maker 创建一个文本分类器模型,并指定要使用的训练数据(在第 4 步中定义)、模型规范(也在第 4 步中设置)以及多个周期数(在在此示例中为 50 个。
机器学习的基本原则是,它是一种模式匹配。最初,它会加载单词的预训练权重,并尝试将它们归入一个“预测”组合,其中哪些组合在一起会指示垃圾内容,哪些不是。第一次,可能接近 50:50,因为该模型只是刚刚开始使用,如下所示:

然后,它会衡量此操作的结果,并更改模型的权重以调整其预测,并且它会再次尝试。这是一个纪元。因此,如果指定 epochs=50,将会经历该“循环” 50 次,如下所示:

因此,到了第 50 个周期时,该模型报告的准确性要高得多。在本例中为 99.1%!
第 7 步 - 导出模型
训练完成后,您可以导出模型。TensorFlow 以自己的格式训练模型,这需要转换为 TensorFlow.js 格式,才能在网页上使用。只需将以下内容粘贴到新单元格中并执行即可:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
执行此代码后,如果您点击 Colab 左侧的小文件夹图标,则可导航到您导出到上面的文件夹(在根目录中,您可能需要上级),然后找到已导出 ModelFiles.zip 个中包含的文件。
立即将 zip 文件下载到您的计算机,您可以像在第一个 Codelab 中一样使用这些文件:
太好了!Python 部分已结束,现在您可以返回到自己熟悉并喜爱的 JavaScript 平台。哈!
5. 提供新的机器学习模型
现在,您几乎可以开始加载模型了。不过,您必须先上传之前在 Codelab 中下载的新模型文件,以便在您的代码中托管和使用这些文件,然后才能执行此操作。
首先,如果刚刚从 Model Maker Colab 笔记本中下载的模型,请将其解压缩。您应该会在其各种文件夹中看到以下文件:
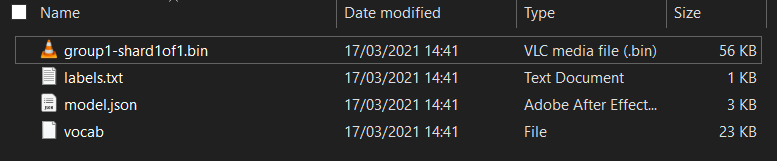
您在这里有什么?
model.json- 这是经过训练的 TensorFlow.js 模型的一个文件。您需要在 JS 代码中引用此特定文件。group1-shard1of1.bin- 这是一个二进制文件,其中包含导出的 TensorFlow.js 模型的许多已保存数据,并且需要托管在您服务器上的某处,以便与上面的model.json位于同一目录中进行下载。vocab- 这种没有扩展名的奇怪文件来自 Model Maker,它展示了如何对句子中的字词进行编码,以便模型了解如何使用它们。我们将在下一部分中对此进行详细介绍。labels.txt- 此属性仅包含模型将预测的结果类名称。对于此模型,如果您在文本编辑器中打开此文件,其中只会列出“false”和“true”,表示“这不是垃圾邮件”或“垃圾邮件”。
托管 TensorFlow.js 模型文件
首先,将生成的 model.json 和 *.bin 文件放在网络服务器上,以便您通过网页访问这些文件。
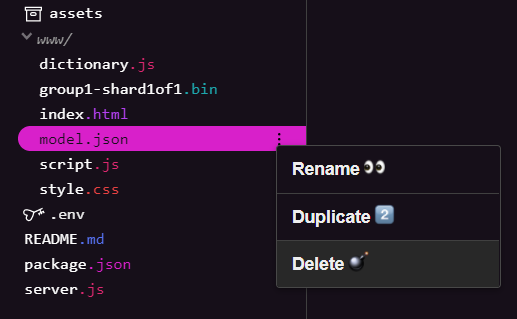
删除现有模型文件
在学习本系列第一个 Codelab 的最终结果时,您首先必须删除上传的现有模型文件。如果您使用的是 Glitch.com,只需在左侧的文件面板中找到 model.json 和 group1-shard1of1.bin,点击各个文件的三点状下拉菜单,然后选择 delete 即可,如下所示:
将新文件上传到 Glitch
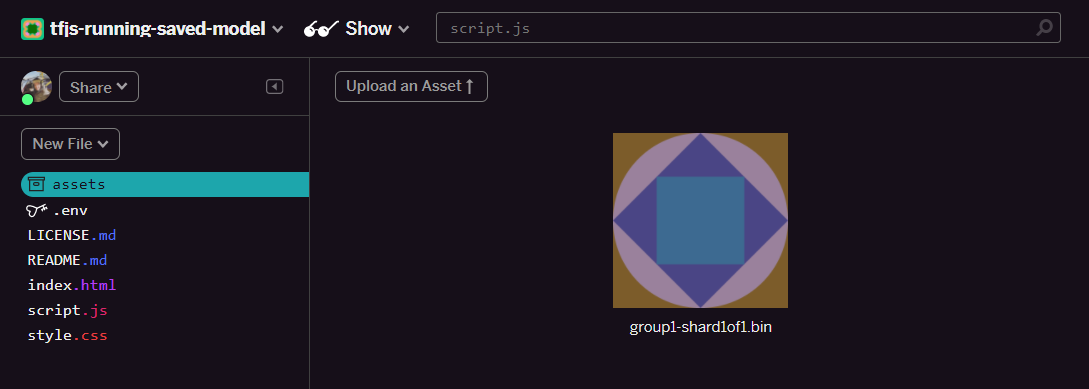
太好了!现在,请上传新素材资源:
- 打开 Glitch 项目左侧面板中的 assets 文件夹,然后删除上传的所有同名的旧资源。
- 点击上传素材资源,然后选择
group1-shard1of1.bin以将其上传到此文件夹。现在,上传后应如下所示:
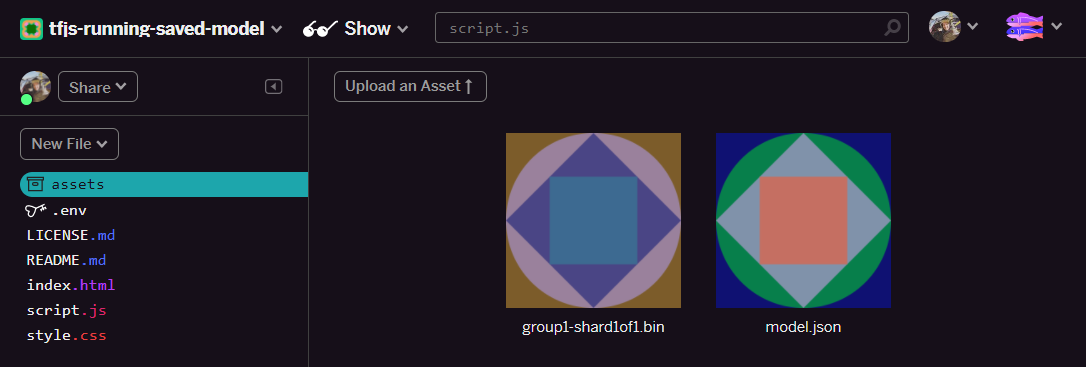
- 太好了!现在也对 model.json 文件执行相同操作,以便 2 个文件位于资源文件夹中,如下所示:
- 如果您点击刚刚上传的
group1-shard1of1.bin文件,可以将网址复制到其位置。立即复制此路径,如下所示:
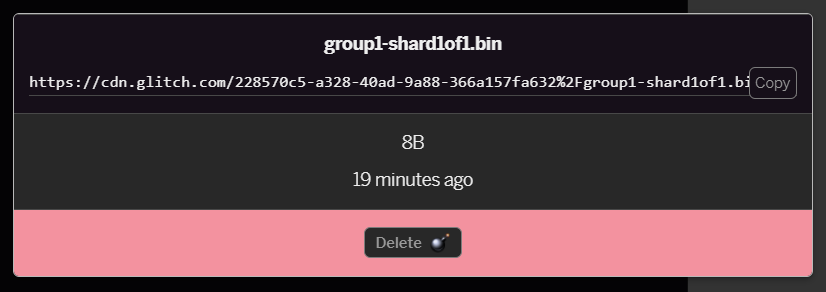
- 现在,点击屏幕左下角的工具 > 终端。等待终端窗口加载。
- 加载完成后,输入以下内容,然后按 Enter 键将目录更改为
www文件夹:
terminal:
cd www
- 接下来,使用
wget下载刚刚上传的 2 个文件,只需将下面的网址替换为您在 Glitch 的素材资源文件夹中为这些文件生成的网址(检查素材资源的文件夹中每个文件的自定义网址)即可。
请注意,两个网址之间的空格以及需要使用的网址与显示的网址不同,但看起来是相似的:
终端
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
太好了!您现在已经创建了上传到 www 文件夹的文件的副本。
不过,现在它们会使用奇怪的名称下载。如果您在终端中输入 ls 并按 Enter 键,则会看到如下内容:

- 使用
mv命令重命名这些文件。在控制台中输入以下内容,并在每行后按 Enter 键:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- 最后,在终端中输入
refresh以刷新 Glitch 项目,然后按 Enter 键:
terminal:
refresh
刷新后,您现在应该会在界面的 www 文件夹中看到 model.json 和 group1-shard1of1.bin:
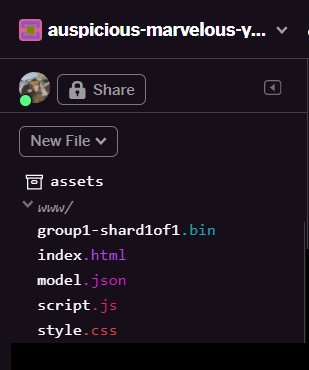
太好了!最后一步是更新 dictionary.js 文件。
- 通过文本编辑器或使用此工具将新下载的词汇表文件转换为正确的 JS 格式,并将生成的输出结果保存为
dictionary.js并保存到www文件夹中。如果您已有dictionary.js文件,只需将新的内容复制并粘贴到该文件中,然后保存文件即可。
棒极了!您已成功更新所有已更改的文件;如果您现在尝试使用和使用该网站,您会注意到重新训练模型应该如何考虑发现和学习的极端情况,如下所示:
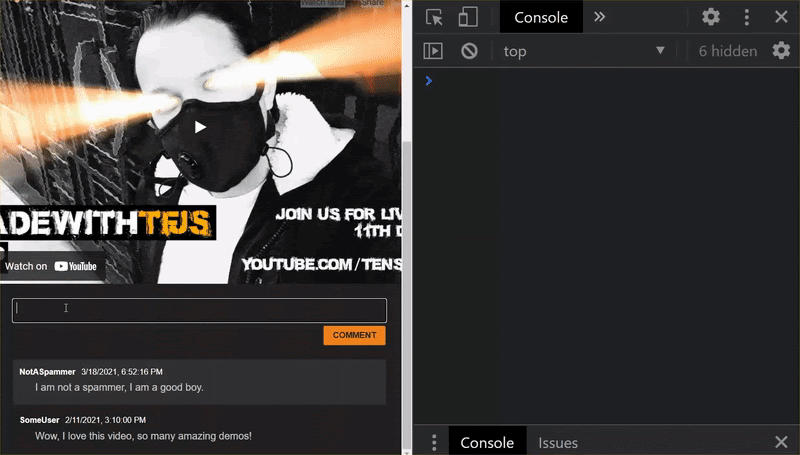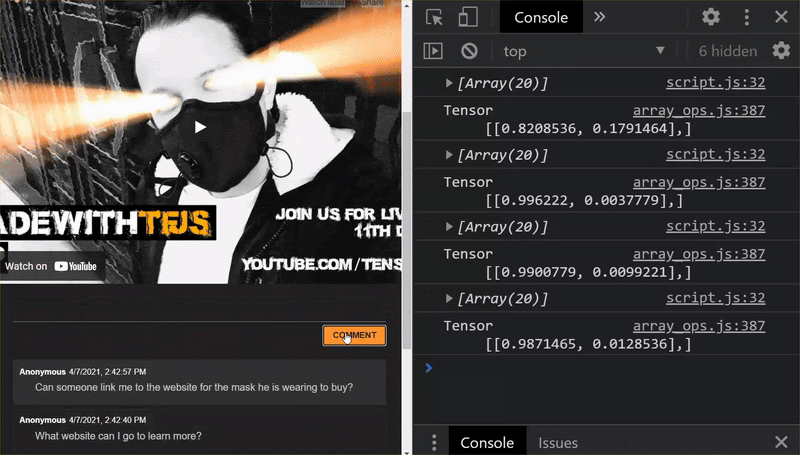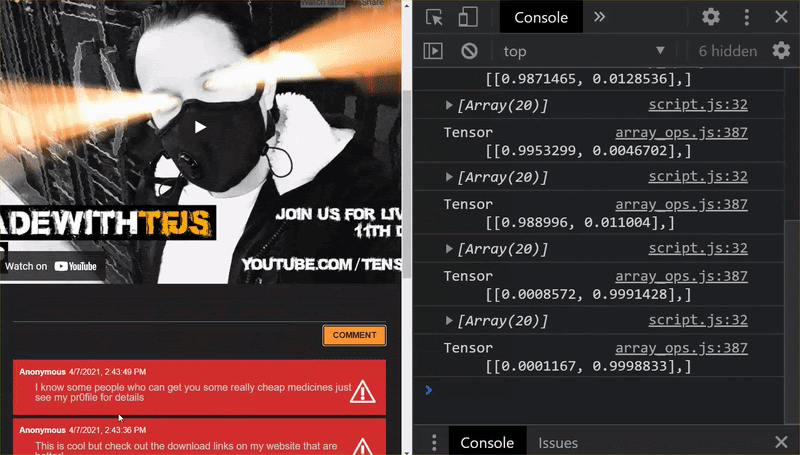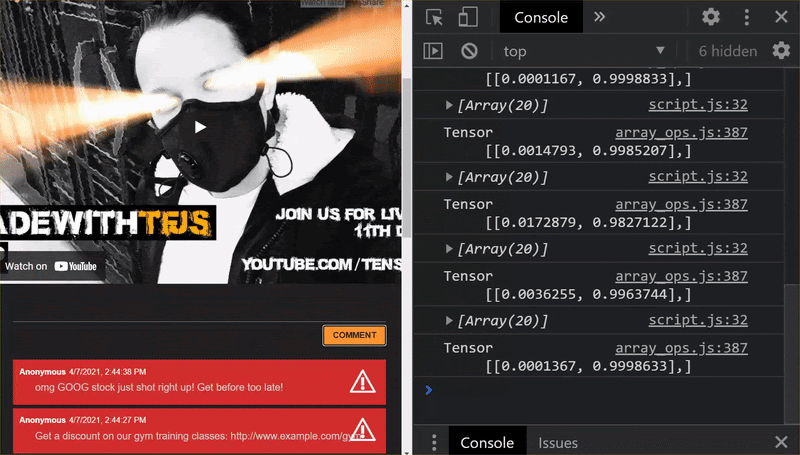
如您所见,前 6 段现在被正确地归类为垃圾邮件,而第 2 批次(共 6 批)都标识为垃圾邮件。完美!
我们还可以尝试一些变体,看看能否很好地泛化。原来有一句失败的句子,例如:
“天哪,我们的股票刚刚上涨了!赶早行动!
此问题现在被正确归类为垃圾邮件,但如果您将其更改为:
”因此,XYZ 的股价只是上涨了!赶快买货,为时已晚!”
在这里,即使只是更改了股票符号和措辞,您也仍然能够识别出这是 98% 的垃圾邮件。
当然,如果您真正想要破坏这种新模型,就能够成功,从而收集更多的训练数据,以最有可能针对您可能遇到的常见情况捕获更多独特的变体。在后续的 Codelab 中,我们将向您展示如何在实时数据被标记后,持续改进您的模型。
6.恭喜!
恭喜,您已成功地重新训练现有的机器学习模型,使其能够针对找到的极端情况进行更新,并将这些更改部署到 TensorFlow.js 中,以用于实际应用。
回顾
在本 Codelab 中,您学习了以下内容:
- 发现在使用预制垃圾评论模型时不起作用的极端情况
- 重新训练了 Model Maker 模型,以考虑您发现的极端情况
- 已将经过训练的新模型导出为 TensorFlow.js 格式
- 已更新您的 Web 应用以使用新文件
后续操作
此更新非常有效,但与任何 Web 应用一样,更新会随着时间的推移而发生。如果应用能随着时间不断自我完善,效果会好很多,不必每次都由我们手动操作。设想一下,在您有 100 条标记为不正确分类的新评论后,如何自动重新训练模型。 戴上您的常规网络工程帽子,您或许可以想出如何创建流水线以自动执行该操作。如果没有,不用担心,请学习本系列的下一个 Codelab,它会教您如何操作。
与我们分享您的成果
您也可以轻松地将今天创作的内容用于其他创意用例,并鼓励您跳出思维定式并继续进行创作。
记得使用 #MadeWithTFJS 标签在社交媒体上关注我们,争取让您的项目有机会在 TensorFlow 博客甚至 将来举办的活动。我们期待看到您的作品。