
1. Sebelum memulai
Codelab ini didesain untuk mengembangkan hasil akhir codelab sebelumnya dalam seri ini untuk deteksi spam komentar menggunakan TensorFlow.js.
Dalam codelab terakhir, Anda membuat halaman web yang berfungsi penuh untuk blog video fiksi. Anda dapat memfilter komentar untuk spam sebelum dikirim ke server untuk disimpan, atau ke klien lain yang terhubung, menggunakan model deteksi spam komentar terlatih yang didukung oleh TensorFlow.js di browser.
Hasil akhir codelab tersebut ditampilkan di bawah ini:
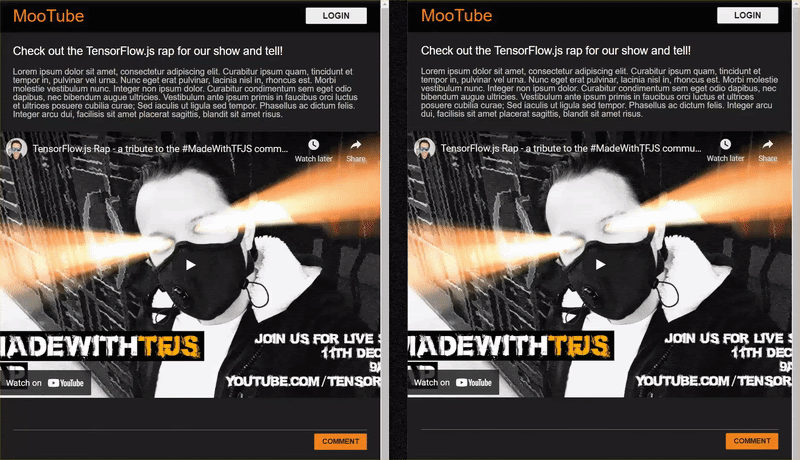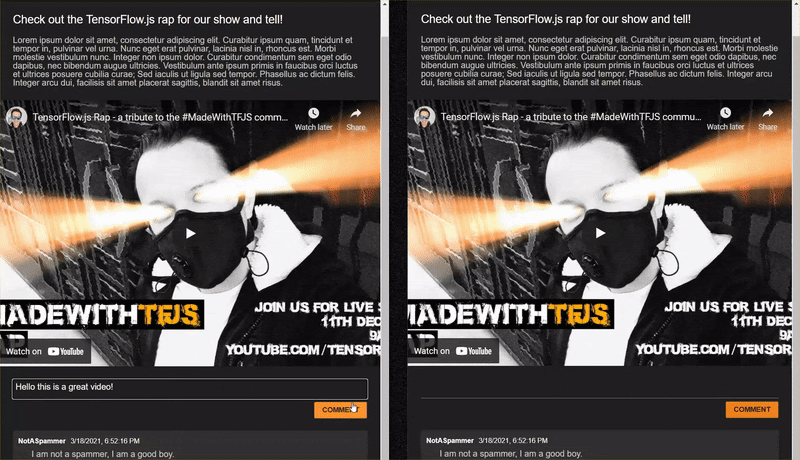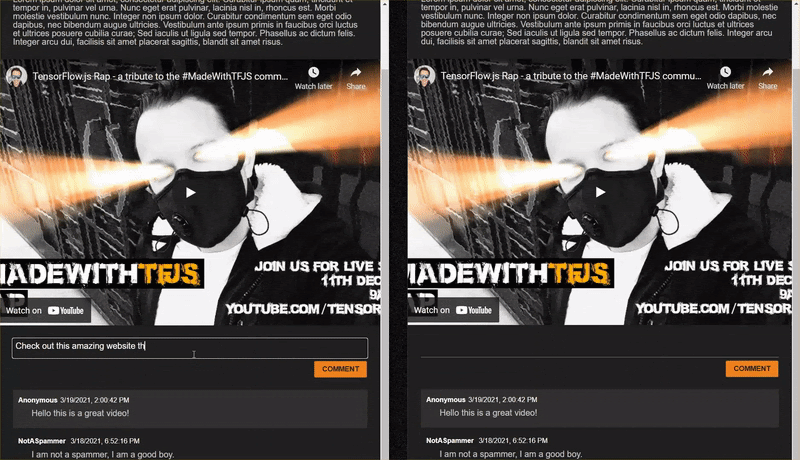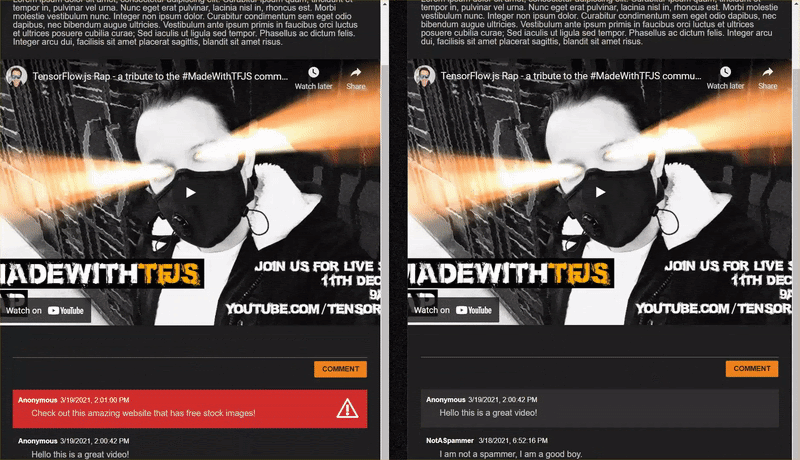
Meskipun berfungsi dengan sangat baik, ada sejumlah kasus ekstrem untuk dijelajahi bahwa tindakan tersebut tidak dapat dideteksi. Anda dapat melatih ulang model untuk memperhitungkan situasi yang tidak dapat ditangani.
Codelab ini berfokus pada penggunaan pemrosesan bahasa alami (gambar untuk memahami bahasa manusia dengan komputer) dan menunjukkan cara mengubah aplikasi web yang ada yang Anda buat (sebaiknya Anda mengambil codelab secara berurutan{/1 }), untuk mengatasi masalah spam komentar yang sangat nyata, yang pasti akan dihadapi oleh banyak developer web saat mereka mengerjakan salah satu aplikasi web populer yang jumlahnya terus bertambah saat ini.
Dalam codelab ini, Anda akan melangkah lebih jauh dengan melatih ulang model ML untuk memperhitungkan perubahan di konten pesan spam yang mungkin berkembang dari waktu ke waktu, berdasarkan tren saat ini atau topik diskusi populer yang memungkinkan Anda untuk terus memperbarui model dan memperhitungkan perubahan tersebut.
Prasyarat
- Menyelesaikan codelab pertama dalam seri ini.
- Pengetahuan dasar tentang teknologi web termasuk HTML, CSS, dan JavaScript.
Yang akan Anda buat
Anda akan menggunakan kembali situs yang dibuat sebelumnya untuk blog video fiktif dengan bagian komentar real time dan mengupgradenya untuk memuat versi model deteksi spam yang dilatih khusus menggunakan TensorFlow.js, sehingga berperforma lebih baik pada kasus ekstrem yang sebelumnya akan gagal data. Tentu saja, sebagai developer dan engineer web, Anda dapat mengubah UX hipotetis ini untuk digunakan kembali di situs mana pun yang mungkin Anda kerjakan dalam peran sehari-hari, dan menyesuaikan solusinya agar cocok dengan kasus penggunaan klien mana pun - mungkin blog, forum, atau beberapa CMS, seperti Drupal, misalnya.
Ayo meretas...
Yang akan Anda pelajari
Anda akan:
- Identifikasi kasus ekstrem yang menyebabkan model terlatih gagal
- Melatih kembali Model Klasifikasi Spam yang dibuat menggunakan Model Maker.
- Ekspor model berbasis Python ini ke format TensorFlow.js untuk digunakan di browser.
- Perbarui model yang dihosting dan kamusnya dengan model yang baru dilatih dan periksa hasilnya
Memahami lab ini adalah HTML5, CSS, dan JavaScript. Anda juga akan menjalankan beberapa kode Python melalui notebook "co lab" untuk melatih ulang model yang dibuat menggunakan Model Maker, tetapi tidak terbiasa dengan Python untuk melakukannya.
2. Menyiapkan kode
Sekali lagi, Anda akan menggunakan Glitch.com untuk menghosting dan mengubah aplikasi web. Jika belum menyelesaikan codelab prasyarat, Anda dapat meng-clone hasil akhir di sini sebagai titik awal. Jika Anda memiliki pertanyaan tentang cara kerja kode, sebaiknya Anda menyelesaikan codelab sebelumnya yang telah membahas cara membuat aplikasi web yang berfungsi ini sebelum melanjutkan.
Di Glitch, cukup klik tombol remix this untuk menyalinnya dan membuat kumpulan file baru yang dapat Anda edit.
3 Menemukan kasus ekstrem di solusi sebelumnya
Jika Anda membuka situs yang telah selesai dibuat yang baru saja Anda clone dan mencoba mengetik beberapa komentar, Anda akan melihat bahwa sering kali komentar berfungsi dengan semestinya, memblokir komentar yang terdengar seperti spam seperti yang diharapkan, dan mengizinkan melalui respons yang sah.
Namun, jika Anda curang dan mencoba hal-hal untuk merusak model tersebut, Anda mungkin akan berhasil dalam beberapa titik. Dengan sedikit uji coba, Anda dapat membuat contoh seperti yang ditunjukkan di bawah ini secara manual. Coba tempelkan kode ini ke aplikasi web yang ada, periksa konsol, dan lihat probabilitas yang muncul jika komentar tersebut adalah spam:
Komentar sah yang diposting tanpa masalah (negatif benar):
- "Wow, saya menyukai video itu, pekerjaannya luar biasa." Probabilitas Spam: 47.91854%
- "Benar-benar menyukai demo ini. Ada detail lainnya?" Probabilitas Spam: 47.15898%
- "Situs apa yang dapat saya pelajari lebih lanjut?" Probabilitas Spam: 15.32495%
Ini sangat bagus. Probabilitas untuk semua pilihan di atas cukup rendah dan berhasil dijalankan melalui SPAM_THRESHOLD default dari probabilitas minimum 75% sebelum tindakan dilakukan (ditentukan dalam kode script.js dari codelab sebelumnya).
Sekarang mari kita coba menulis komentar yang lebih vulgar yang ditandai sebagai spam meskipun tidak...
Komentar sah yang ditandai sebagai spam (positif palsu):
- "Bisakah seseorang menautkan situs untuk masker yang dikenakannya?" Probabilitas Spam: 98.46466%
- "Dapatkah saya membeli lagu ini di Spotify? Beri tahu seseorang!" Probabilitas Spam: 94.40953%
- "Bisakah seseorang menghubungi saya untuk memberikan detail tentang cara mendownload TensorFlow.js?" Probabilitas Spam: 83.20084%
Maaf. Sepertinya komentar yang sah ini akan ditandai sebagai spam jika memang diizinkan. Bagaimana cara mengatasinya?
Salah satu opsi sederhana adalah meningkatkan SPAM_THRESHOLD agar lebih dari 98,5% yakin. Jika demikian, komentar yang salah diklasifikasikan ini akan diposting. Dengan mempertimbangkan hal itu, mari kita lanjutkan dengan hasil lain yang mungkin di bawah ini...
Komentar spam yang ditandai sebagai spam (positif benar):
- "Bagus sekali, tetapi periksa link download di situs saya yang lebih bagus!" Probabilitas Spam: 99.77873%
- "Saya tahu beberapa orang yang bisa memberi Anda obat, lihat saja pr0file saya untuk detailnya" Probabilitas Spam: 98.46955%
- "Lihat profil saya untuk mendownload video yang lebih menakjubkan lagi yang lebih baik! http://example.com" Probabilitas Spam: 96,26383%
Oke, jadi kode ini berfungsi seperti yang diharapkan dengan nilai minimum 75% yang asli, tetapi mengingat pada langkah sebelumnya Anda mengubah SPAM_THRESHOLD menjadi lebih dari 98,5%, artinya 2 contoh di sini akan diizinkan, jadi mungkin nilai minimumnya terlalu tinggi. Apakah 96% lebih baik? Namun, jika Anda melakukannya, salah satu komentar di bagian sebelumnya (positif palsu) akan ditandai sebagai spam jika dianggap sah karena diberi rating 98,46466%.
Dalam kasus ini, mungkin yang terbaik adalah menangkap semua komentar spam yang sebenarnya ini dan melatih ulang kegagalan di atas. Dengan menetapkan ambang batas ke 96%, semua positif benar tetap tercatat dan Anda menghapus 2 positif palsu (PP) di atas. Tidak terlalu buruk jika Anda hanya mengubah satu angka.
Mari kita lanjutkan...
Komentar spam yang diizinkan untuk diposting (negatif palsu):
- "Lihat profil saya untuk mendownload lebih banyak video menakjubkan yang lebih bagus!" Probabilitas Spam: 7.54926%
- "Dapatkan diskon untuk kelas pelatihan gym kami. Lihat pr0file!" Probabilitas Spam: 17.49849%
- "Saham OMG GOOG baru saja muncul! Ayo terlambat sebelum!" Probabilitas Spam: 20.42894%
Untuk komentar ini, Anda tidak perlu melakukan apa pun hanya dengan mengubah nilai SPAM_THRESHOLD lebih lanjut. Menurunkan nilai minimum untuk spam dari 96% menjadi ~9% akan menyebabkan komentar asli ditandai sebagai spam - salah satunya memiliki rating 58% meskipun sah. Satu-satunya cara untuk menangani komentar semacam ini adalah dengan melatih ulang model menggunakan kasus ekstrem seperti yang disertakan dalam data pelatihan agar model tersebut mempelajari cara menyesuaikan pandangannya terhadap dunia tentang apa itu spam atau bukan.
Meskipun satu-satunya opsi saat ini adalah untuk melatih ulang model, Anda juga melihat bagaimana Anda dapat menyempurnakan nilai minimum saat memutuskan untuk memanggil sesuatu yang spam guna meningkatkan performa. Sebagai manusia, 75% tampaknya cukup yakin, tetapi untuk model ini, Anda perlu meningkat mendekati 81,5% agar lebih efektif dengan contoh input.
Tidak ada nilai ajaib yang berfungsi dengan baik di berbagai model, dan nilai minimum ini harus ditetapkan per model setelah bereksperimen dengan data dunia nyata untuk mengetahui apa yang berfungsi dengan baik.
Mungkin ada beberapa situasi ketika positif palsu (atau negatif) dapat memiliki konsekuensi serius (misalnya, dalam industri medis) sehingga Anda dapat menyesuaikan ambang agar sangat tinggi dan meminta peninjauan manual lebih lanjut bagi mereka yang tidak memenuhi ambang batas. Ini adalah pilihan Anda sebagai developer dan memerlukan eksperimen.
4. Melatih kembali model deteksi spam komentar
Di bagian sebelumnya, Anda mengidentifikasi sejumlah kasus ekstrem yang gagal untuk model dengan satu-satunya opsi adalah melatih ulang model untuk memperhitungkan situasi ini. Dalam sistem produksi, Anda dapat menemukan komentar ini dari waktu ke waktu karena orang menandai komentar sebagai spam secara manual yang dilewati atau moderator yang meninjau komentar yang dilaporkan menyadari bahwa beberapa komentar sebenarnya bukan spam dan dapat menandai komentar tersebut untuk dilatih ulang. Dengan asumsi Anda telah mengumpulkan banyak data baru untuk kasus ekstrem ini (untuk hasil terbaik, Anda harus memiliki beberapa variasi dari kalimat baru ini jika Anda bisa), sekarang kami akan melanjutkan dengan menunjukkan cara melatih ulang model dengan mempertimbangkan kasus ekstrem tersebut.
Rangkuman model siap pakai
Model siap pakai yang Anda gunakan adalah model yang dibuat oleh pihak ketiga melalui Model Maker yang menggunakan model "penyematan kata rata-rata" agar berfungsi.
Saat model di-build dengan Model Maker, Anda perlu beralih singkat ke Python untuk melatih ulang model, kemudian mengekspor model yang dibuat ke format TensorFlow.js sehingga Anda dapat menggunakannya di browser. Untungnya Model Maker memudahkan penggunaan model mereka, jadi ini sangat mudah dilakukan dan kami akan memandu Anda melewati prosesnya, jadi jangan khawatir jika Anda belum pernah menggunakan Python sebelumnya.
Colab
Karena Anda tidak terlalu khawatir dengan codelab ini jika ingin menyiapkan server Linux dengan semua utilitas Python yang diinstal, Anda dapat menjalankan kode melalui browser web menggunakan "Colab Notebook". Notebook ini dapat terhubung ke "backend" - yang hanya merupakan server dengan beberapa hal yang telah terinstal, yang dengannya Anda dapat mengeksekusi kode arbitrer dalam browser web dan melihat hasilnya. Hal ini sangat berguna untuk pembuatan prototipe yang cepat atau untuk digunakan dalam tutorial seperti ini.
Cukup buka colab.research.google.com dan layar sambutan akan muncul seperti yang ditunjukkan berikut:
Sekarang klik tombol Notebook Baru di kanan bawah jendela pop-up dan Anda akan melihat kolom kosong seperti ini:
Bagus. Langkah berikutnya adalah menghubungkan kolaborasi frontend ke beberapa server backend agar Anda dapat mengeksekusi kode Python yang akan ditulis. Lakukan dengan mengklik Hubungkan di kanan atas, lalu pilih Hubungkan ke runtime yang dihosting.

Setelah terhubung, Anda akan melihat ikon RAM dan Disk muncul di tempatnya, seperti ini:
Hebat! Sekarang Anda bisa memulai coding dengan Python untuk melatih ulang model Model Maker. Cukup ikuti langkah-langkah di bawah ini.
Langkah 1
Di sel pertama yang saat ini kosong, salin kode di bawah. Ini akan menginstal TensorFlow Lite Model Maker untuk Anda menggunakan pengelola paket Python yang disebut "pip" (mirip dengan npm yang kebanyakan pembaca codelab ini mungkin lebih akrab dengan ekosistem JS):
!pip install -q tflite-model-maker
Namun, menempelkan kode ke dalam sel tidak akan mengeksekusinya. Selanjutnya, arahkan kursor ke sel abu-abu tempat Anda menempelkan kode di atas, dan ikon "putar" kecil akan muncul di sebelah kiri sel seperti yang disorot di bawah:
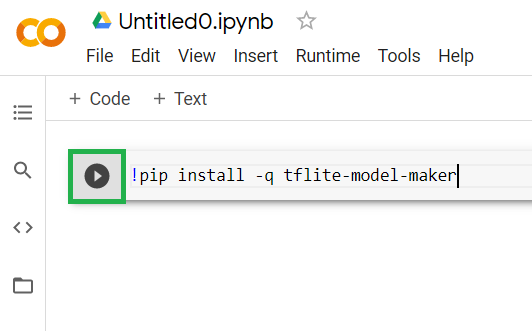 Klik tombol putar untuk mengeksekusi kode yang baru saja diketik di sel.
Klik tombol putar untuk mengeksekusi kode yang baru saja diketik di sel.
Sekarang Anda akan melihat produsen model sedang diinstal:
Setelah eksekusi sel ini selesai seperti yang ditunjukkan, lanjutkan ke langkah berikutnya di bawah.
Langkah 2
Selanjutnya, tambahkan sel kode baru seperti yang ditunjukkan sehingga Anda dapat menempelkan beberapa kode lagi setelah sel pertama dan mengeksekusinya secara terpisah:
Sel berikutnya yang dijalankan akan memiliki sejumlah impor yang harus digunakan oleh kode di notebook lainnya. Salin dan tempel di bawah ini dalam sel baru yang dibuat:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
Cukup umum, bahkan jika Anda tidak terbiasa dengan Python. Anda hanya mengimpor beberapa utilitas dan fungsi Model Maker yang diperlukan untuk pengklasifikasi spam. Tindakan ini juga akan memeriksa apakah Anda menjalankan TensorFlow 2.x yang merupakan persyaratan untuk menggunakan Model Maker.
Terakhir, seperti sebelumnya, eksekusi sel dengan menekan ikon "putar" saat Anda mengarahkan kursor ke sel, lalu menambahkan sel kode baru untuk langkah berikutnya.
Langkah 3
Selanjutnya, Anda akan mendownload data dari server jarak jauh ke perangkat Anda, dan menetapkan variabel training_data sebagai jalur dari file lokal yang didownload:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/laurencemoroney-blog.appspot.com/jm_blog_comments_extras.csv', extract=False)
Model Maker dapat melatih model dari file CSV sederhana seperti yang didownload. Anda hanya perlu menentukan kolom mana yang menyimpan teks dan mana yang menyimpan label tersebut. Anda akan melihat cara melakukannya di Langkah 5. Jangan ragu untuk langsung mendownload file CSV guna melihat isi filenya jika Anda mau.
Anda akan melihat bahwa nama file ini adalah jm_blog_comments_extras.csv - file ini hanyalah data pelatihan asli yang kami gunakan untuk membuat model spam komentar pertama digabungkan dengan data kasus ekstrem baru yang Anda temukan sehingga semuanya berada dalam satu file. Anda juga memerlukan data pelatihan asli yang digunakan untuk melatih model selain kalimat baru yang ingin Anda pelajari.
Opsional: Jika Anda mendownload file CSV ini dan memeriksa beberapa baris terakhir, Anda akan melihat contoh kasus ekstrem yang sebelumnya tidak berfungsi dengan benar. Model tersebut baru saja ditambahkan ke akhir data pelatihan yang sudah ada sehingga model siap pakai yang digunakan untuk melatih dirinya sendiri.
Eksekusi sel ini, lalu setelah selesai mengeksekusi, tambahkan sel baru, dan lanjutkan ke langkah 4.
Langkah 4
Saat menggunakan Model Maker, Anda tidak mem-build model dari awal. Anda biasanya menggunakan model yang ada yang kemudian akan Anda sesuaikan dengan kebutuhan Anda.
Model Maker menyediakan beberapa penyematan model pra-pelajari yang dapat Anda gunakan, tetapi yang paling sederhana dan cepat untuk dimulai adalah average_word_vec yang digunakan dalam codelab sebelumnya untuk membuat situs Anda. Berikut kodenya:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Lanjutkan dan jalankan setelah Anda menempelkannya ke sel baru.
Memahami
num_words
parameter
Ini adalah jumlah kata yang Anda inginkan untuk digunakan model. Anda mungkin berpikir bahwa semakin banyak semakin baik, tetapi secara umum ada jatah manis berdasarkan frekuensi setiap kata digunakan. Jika Anda menggunakan setiap kata di seluruh korpus, Anda dapat berakhir dengan model yang mencoba mempelajari dan menyeimbangkan bobot kata yang hanya digunakan sekali - ini tidak terlalu berguna. Anda akan menemukan dalam korpus teks bahwa banyak kata hanya digunakan sekali atau dua kali, dan umumnya tidak layak digunakan dalam model karena memiliki dampak yang dapat diabaikan pada sentimen secara keseluruhan. Jadi, Anda dapat menyesuaikan model pada jumlah kata yang diinginkan dengan menggunakan parameter num_words. Angka yang lebih kecil akan memiliki model yang lebih kecil dan lebih cepat, tetapi bisa kurang akurat karena mengenali lebih sedikit kata. Angka yang lebih besar akan memiliki model yang lebih besar dan mungkin lebih lambat. Menemukan titik ideal adalah kunci dan Anda bebas memutuskan sebagai engineer machine learning untuk mengetahui mana yang terbaik untuk kasus penggunaan Anda.
Memahami
wordvec_dim
parameter
Parameter wordvec_dim adalah jumlah dimensi yang ingin Anda gunakan untuk vektor setiap kata. Dimensi ini pada dasarnya adalah karakteristik yang berbeda (yang dibuat oleh algoritme machine learning saat pelatihan) yang dapat diukur dengan kata tertentu yang dapat digunakan oleh program untuk mencoba dan mengaitkan kata yang serupa dengan cara yang bermakna.
Misalnya, jika Anda memiliki dimensi terkait seberapa "medis" sebuah kata, kata seperti "pil" dapat memiliki skor tinggi di sini dalam dimensi ini, dan dikaitkan dengan kata memiliki skor tertinggi lainnya seperti "xray", tetapi "cat" akan mendapat skor rendah pada dimensi ini. Ternyata "dimensi medis" berguna untuk menentukan spam saat digabungkan dengan dimensi potensial lain yang mungkin dipertimbangkan untuk digunakan, yang signifikan.
Dalam kasus kata dengan skor sangat tinggi dalam "dimensi medis", data tersebut mungkin menemukan bahwa dimensi kedua yang menghubungkan kata dengan tubuh manusia mungkin berguna. Kata seperti "kaki", "lengan", "leher" juga bisa memiliki skor yang tinggi dalam dimensi medis.
Model ini dapat menggunakan dimensi tersebut untuk mengaktifkannya guna mendeteksi kata-kata yang kemungkinan besar terkait dengan spam. Mungkin email spam lebih cenderung berisi kata-kata yang merupakan bagian tubuh medis dan manusia.
Aturan praktis yang ditentukan dari penelitian adalah bahwa akar keempat jumlah kata berfungsi dengan baik untuk parameter ini. Jadi, jika saya menggunakan 2.000 kata, titik awal yang baik untuk hal ini adalah 7 dimensi. Jika Anda mengubah jumlah kata yang digunakan, Anda juga dapat mengubahnya.
Memahami
seq_len
parameter
Model umumnya sangat kaku dalam hal nilai input. Untuk model bahasa, ini berarti bahwa model bahasa dapat mengklasifikasikan kalimat dengan panjang dan statis tertentu. Hal tersebut ditentukan oleh parameter seq_len, dengan'length urutan'. Jika Anda mengonversi kata menjadi angka (atau token), kalimat akan menjadi urutan token tersebut. Jadi, model Anda akan dilatih (dalam hal ini) untuk mengklasifikasikan dan mengenali kalimat yang memiliki 20 token. Jika lebih panjang, kalimat tersebut akan dipotong. Jika lebih pendek, codelab tersebut akan menggunakan padding - seperti dalam codelab pertama dalam seri ini.
Langkah 5 - muat data pelatihan
Sebelumnya Anda mendownload file CSV. Kini saatnya menggunakan loader data untuk mengubahnya menjadi data pelatihan yang dapat dikenali model.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
Jika membuka file CSV di editor, Anda akan melihat bahwa setiap baris hanya memiliki dua nilai, dan ini dijelaskan dengan teks di baris pertama file. Biasanya setiap entri dianggap sebagai 'kolom'. Anda akan melihat bahwa deskripsi untuk kolom pertama adalah commenttext, dan entri pertama di setiap baris adalah teks komentar.
Demikian pula, deskripsi untuk kolom kedua adalah spam, dan Anda akan melihat bahwa entri kedua di setiap baris adalah TRUE atau FALSE untuk menunjukkan apakah teks tersebut dianggap sebagai spam komentar atau bukan. Properti lainnya menetapkan spesifikasi model yang Anda buat di langkah 4, bersama dengan karakter pembatas, yang dalam hal ini adalah koma karena file dipisahkan koma. Anda juga menetapkan parameter acak untuk mengatur ulang data pelatihan secara acak sehingga hal-hal yang mungkin serupa atau dikumpulkan bersama akan disebarkan secara acak di seluruh set data.
Kemudian, Anda akan menggunakan data.split() untuk memisahkan data ke dalam data pelatihan dan pengujian. 0,9 menunjukkan bahwa 90% set data akan digunakan untuk pelatihan, sisanya untuk pengujian.
Langkah 6 - Buat model
Tambahkan sel lain tempat kita akan menambahkan kode untuk mem-build model:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
Tindakan ini akan membuat model pengklasifikasi teks dengan Model Maker, dan Anda menentukan data pelatihan yang ingin digunakan (yang ditentukan pada langkah 4), spesifikasi model (yang juga disiapkan pada langkah 4), dan sejumlah iterasi pelatihan, dalam kasus ini 50.
Prinsip dasar Machine Learning adalah machine learning adalah bentuk pencocokan pola. Awalnya, browser akan memuat bobot terlatih untuk kata-kata, dan mencoba untuk mengelompokkannya dengan'prediksi' yang mana yang dikelompokkan bersama menunjukkan spam, dan mana yang tidak. Pertama kali, kemungkinan mendekati 50:50, karena model hanya memulai seperti yang ditunjukkan di bawah ini:

Kemudian model ini akan mengukur hasilnya, dan mengubah bobot model untuk menyesuaikan prediksinya, dan akan mencoba lagi. Ini adalah iterasi pelatihan. Jadi, dengan menentukan epochs=50, epochs=50 akan melalui 'loop' tersebut 50 kali seperti yang ditunjukkan:

Jadi, pada saat Anda mencapai epoch ke-50, model tersebut akan melaporkan tingkat akurasi yang jauh lebih tinggi. Dalam hal ini menampilkan 99,1%.
Langkah 7 - Ekspor Model
Setelah pelatihan selesai, Anda dapat mengekspor model tersebut. TensorFlow melatih model dalam formatnya sendiri, dan ini perlu dikonversi ke format TensorFlow.js untuk digunakan di halaman web. Cukup tempel perintah berikut di sel baru dan jalankan:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
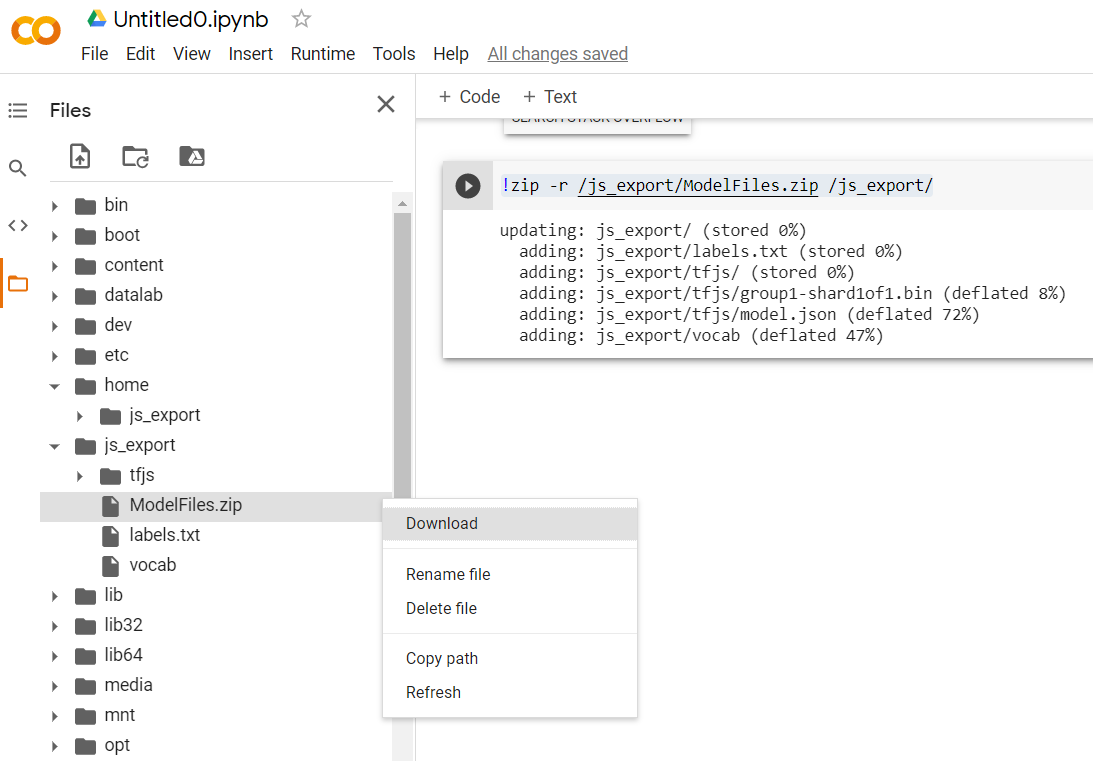
!zip -r /js_export/ModelFiles.zip /js_export/
Setelah menjalankan kode ini, jika Anda mengklik ikon folder kecil di sebelah kiri Colab, Anda dapat membuka folder yang diekspor di atas (di direktori utama - Anda mungkin perlu naik tingkat) dan menemukan paket zip file yang diekspor terdapat di ModelFiles.zip.
Download file zip ini ke komputer Anda sekarang karena Anda akan menggunakan file tersebut seperti di codelab pertama:
Bagus. Bagian Python sudah selesai, Anda kini dapat kembali ke lahan JavaScript yang Anda kenal dan sukai. Fiuh!
5. Menayangkan model machine learning baru
Anda sekarang hampir siap untuk memuat model. Sebelum melakukannya, Anda harus mengupload file model baru yang didownload sebelumnya di codelab agar file tersebut dihosting dan dapat digunakan dalam kode Anda.
Pertama, jika Anda belum melakukannya, ekstrak file untuk model yang baru saja didownload dari notebook Colab Model Maker yang baru saja Anda jalankan. Anda akan melihat file berikut terdapat dalam berbagai foldernya:
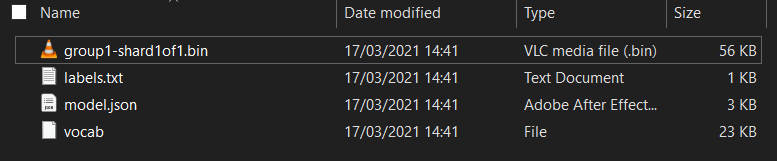
Apa yang Anda miliki di sini?
model.json- Ini adalah salah satu file yang membentuk model TensorFlow.js terlatih. Anda akan mereferensikan file tertentu ini dalam kode JS.group1-shard1of1.bin- Ini adalah file biner yang berisi banyak data yang disimpan untuk model TensorFlow.js yang diekspor dan harus dihosting di server Anda untuk didownload dalam direktori yang sama sepertimodel.jsondi atas.vocab- File aneh tanpa ekstensi ini adalah sesuatu dari Pembuat Model yang menunjukkan kepada kita cara mengenkode kata dalam kalimat sehingga model memahami cara menggunakannya. Anda akan mempelajari lebih dalam hal ini di bagian berikutnya.labels.txt- Ini hanya berisi nama class yang dihasilkan yang akan diprediksi oleh model. Untuk model ini, jika Anda membuka file ini di editor teks, file tersebut hanya mencantumkan "false" dan "true" yang menunjukkan "bukan spam" atau "spam" sebagai output prediksi.
Menghosting file model TensorFlow.js
Pertama-tama, tempatkan file model.json dan *.bin yang dibuat di server web sehingga Anda dapat mengaksesnya melalui halaman web.
Menghapus file model yang ada
Saat Anda mengembangkan hasil akhir codelab pertama dalam seri ini, Anda harus menghapus file model yang ada yang diupload terlebih dahulu. Jika Anda menggunakan Glitch.com, cukup periksa panel file di sebelah kiri untuk model.json dan group1-shard1of1.bin, klik dropdown menu 3 titik untuk setiap file dan pilih hapus seperti yang ditunjukkan:
Mengupload file baru ke Glitch
Bagus. Sekarang upload yang baru:
- Buka folder assets di panel sebelah kiri project Glitch dan hapus aset lama yang diupload jika namanya sama.
- Klik upload aset, lalu pilih
group1-shard1of1.binuntuk diupload ke folder ini. Sekarang akan terlihat seperti ini setelah diupload:

- Bagus. Sekarang lakukan hal yang sama untuk file model.json juga, sehingga 2 file akan berada di folder aset seperti ini:
- Jika Anda mengklik file
group1-shard1of1.binyang baru saja Anda upload, Anda akan dapat menyalin URL ke lokasinya. Salin jalur ini sekarang seperti yang ditunjukkan berikut:
- Sekarang di kiri bawah layar, klik Alat > Terminal. Tunggu hingga jendela terminal dimuat.
- Setelah dimuat, ketik perintah berikut, lalu tekan enter untuk mengubah direktori ke folder
www:
terminal:
cd www
- Selanjutnya, gunakan
wgetuntuk mendownload 2 file yang baru saja diupload dengan mengganti URL di bawah dengan URL yang Anda buat untuk file di folder aset pada Glitch (periksa folder aset untuk setiap URL kustom file).
Perhatikan bahwa jarak antara dua URL dan URL yang perlu Anda gunakan akan berbeda dengan yang ditampilkan, tetapi akan terlihat mirip:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Keren! Sekarang Anda telah membuat salinan file yang diupload ke folder www.
Namun, saat ini file akan didownload dengan nama yang aneh. Jika Anda mengetik ls di terminal dan menekan enter, Anda akan melihat sesuatu seperti ini:

- Menggunakan perintah
mvganti nama file. Ketik hal berikut ke konsol dan tekan enter setelah setiap baris:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Terakhir, muat ulang project Glitch dengan mengetik
refreshdi terminal dan tekan enter:
terminal:
refresh
Setelah memuat ulang, Anda sekarang akan melihat model.json dan group1-shard1of1.bin di folder www antarmuka pengguna:
Bagus. Langkah terakhir adalah memperbarui file dictionary.js.
- Konversikan file vocab baru yang didownload ke format JS yang benar secara manual melalui editor teks atau gunakan alat ini, lalu simpan output sebagai
dictionary.jsdi folderwwwAnda. Jika sudah memiliki filedictionary.js, Anda dapat menyalin dan menempelkan konten baru di dalamnya, lalu menyimpan file tersebut.
Hore! Anda berhasil memperbarui semua file yang diubah dan jika sekarang Anda mencoba dan menggunakan situs web, Anda akan melihat bagaimana model yang dilatih ulang seharusnya dapat memperhitungkan kasus ekstrem yang ditemukan dan dipelajari seperti yang ditunjukkan:
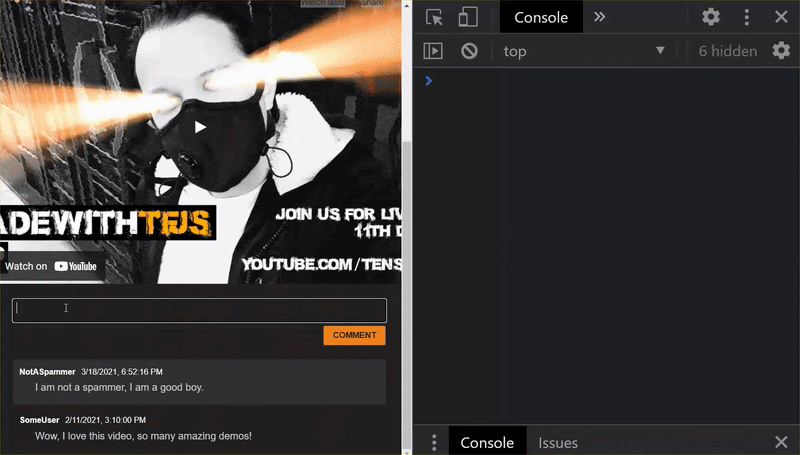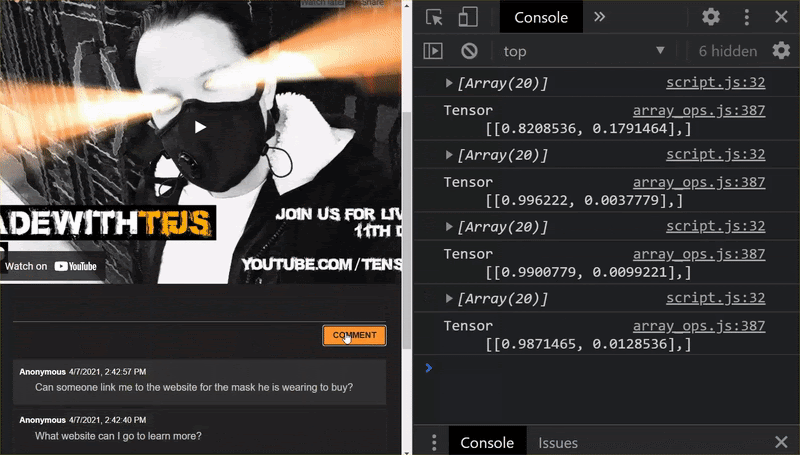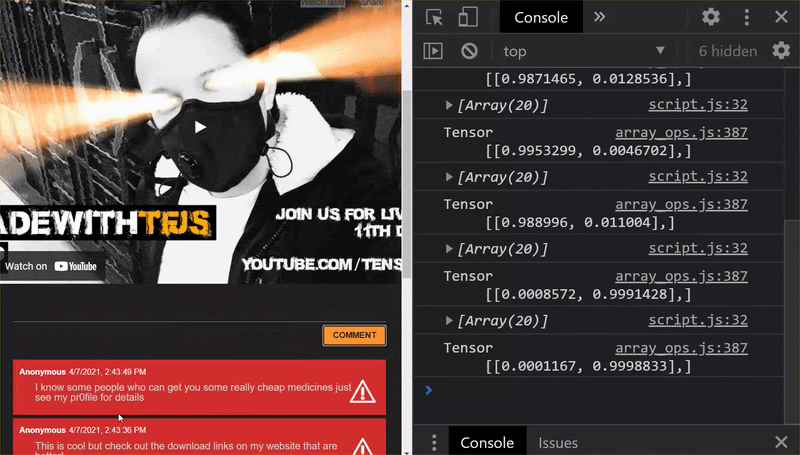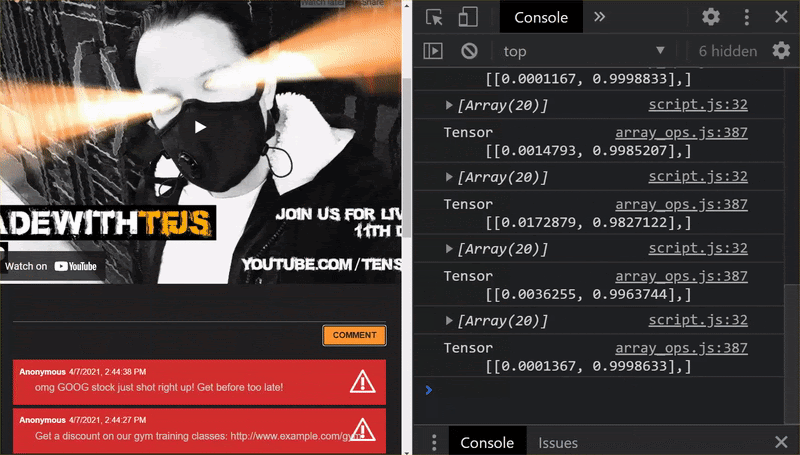
Seperti yang Anda lihat, 6 kelompok pertama kini diklasifikasikan dengan benar sebagai bukan spam, dan kelompok ke-2 dari 6 kelompok tersebut semuanya diidentifikasi sebagai spam. Sempurna!
Mari kita coba beberapa variasi untuk melihat apakah variasi tersebut sesuai. Awalnya, terdapat kalimat yang gagal seperti:
"Om saham GOOG baru saja muncul! Ayo terlambat!"
Hal ini sekarang diklasifikasikan dengan benar sebagai spam, tetapi apa yang akan terjadi jika Anda mengubahnya menjadi:
"Jadi, nilai saham XYZ baru saja meningkat! Beli beberapa sebelum terlambat!"
Di sini, Anda mendapat prediksi sebesar 98% kemungkinan berupa spam yang benar meskipun Anda telah mengubah simbol saham dan susunan katanya sedikit.
Tentu saja, jika Anda benar-benar mencoba merusak model baru ini, Anda akan mampu melakukannya, dan akan mengumpulkan lebih banyak data pelatihan untuk mendapatkan kesempatan terbaik dalam menangkap variasi yang lebih unik untuk situasi umum yang cenderung Anda temui secara online. Dalam codelab mendatang, kami akan menunjukkan cara untuk terus meningkatkan kualitas model Anda dengan data live saat dilaporkan.
6. Selamat!
Selamat, Anda telah berhasil melatih ulang model machine learning yang ada untuk mengupdate sendiri agar berfungsi untuk kasus ekstrem yang Anda temukan dan men-deploy perubahan tersebut ke browser dengan TensorFlow.js untuk aplikasi dunia nyata.
Rangkuman
Dalam codelab ini, Anda:
- Ditemukan kasus ekstrem yang tidak berfungsi saat menggunakan model spam komentar yang telah dibuat sebelumnya
- Melatih kembali model Maker untuk mempertimbangkan kasus ekstrem yang Anda temukan
- Mengekspor model terlatih baru ke format TensorFlow.js
- Mengupdate aplikasi web Anda untuk menggunakan file baru
Apa selanjutnya?
Jadi, update ini berjalan dengan baik, tetapi seperti halnya aplikasi web lainnya, perubahan akan terjadi seiring waktu. Akan jauh lebih baik jika aplikasi terus meningkat sendiri dari waktu ke waktu daripada harus melakukannya secara manual setiap kali. Dapatkah Anda memikirkan cara mengotomatisasi langkah-langkah ini untuk melatih ulang model secara otomatis setelah Anda, misalnya, memiliki 100 komentar baru yang ditandai sebagai salah diklasifikasikan? Gunakan topi teknik web biasa dan Anda mungkin dapat mengetahui cara membuat pipeline untuk melakukannya secara otomatis. Jika tidak, jangan khawatir, cari codelab berikutnya dalam seri yang akan menunjukkan caranya.
Bagikan hal yang Anda buat dengan kami
Anda juga dapat dengan mudah memperluas hasil yang Anda buat hari ini untuk kasus penggunaan materi iklan lainnya, dan sebaiknya Anda berpikir secara kreatif dan tetap meretas.
Jangan lupa untuk menge-tag kami di media sosial menggunakan hashtag #MadeWithTFJS agar project Anda mendapat peluang untuk ditampilkan di blog TensorFlow atau bahkan acara mendatang. Kami ingin sekali melihat hasil kreasi Anda.
Codelab TensorFlow.js lainnya untuk memperdalam pemahaman
- Gunakan hosting Firebase untuk men-deploy dan menghosting model TensorFlow.js dalam skala besar.
- Membuat webcam dengan cerdas menggunakan model deteksi objek siap pakai dengan TensorFlow.js
Beberapa situs untuk dipelajari
- Situs resmi TensorFlow.js
- Model siap pakai TensorFlow.js
- API TensorFlow.js
- Show & Tell TensorFlow.js - dapatkan inspirasi dan lihat apa yang telah dibuat orang lain.