
1. शुरू करने से पहले
पिछले एक दशक में, वेब ऐप्लिकेशन अब पहले से कहीं ज़्यादा सोशल और इंटरैक्टिव हो गए हैं. अब मल्टीमीडिया और टिप्पणियों के साथ-साथ और भी बहुत कुछ रीयल-टाइम में लोकप्रिय हो रहा है.
साथ ही, इससे स्पैम करने वाले लोगों को ऐसे सिस्टम का गलत इस्तेमाल करने का मौका मिलता है. साथ ही, दूसरों के लिखे गए लेखों, वीडियो, और पोस्ट में कम गंभीर कॉन्टेंट को शामिल करने की कोशिश की जाती है, ताकि ज़्यादा से ज़्यादा लोग उसे देख सकें.
स्पैम का पता लगाने के पुराने तरीके, जैसे कि ब्लॉक किए गए शब्दों की सूची को आसानी से बायपास किया जा सकता है. वे स्पैम वाले बेहतर बॉट से किसी भी तरह से मेल नहीं खाते, जिनकी वजह से यह समस्या लगातार बढ़ती जा रही है. अब आप आगे से, ऐसे मशीन लर्निंग मॉडल का इस्तेमाल कर सकते हैं जिन्हें इस तरह के स्पैम का पता लगाने की ट्रेनिंग दी गई है.
आम तौर पर, टिप्पणियों को पहले से फ़िल्टर करने के लिए मशीन लर्निंग मॉडल चलाने पर सर्वर काम करता था, लेकिन अब TensorFlow.js से आप JavaScript के ज़रिए ब्राउज़र में मशीन लर्निंग मॉडल क्लाइंट साइड को लागू कर सकते हैं. आप स्पैम को रोक सकते हैं. इसके लिए सर्वर के पीछे वाले हिस्से को छूने से पहले ही, सर्वर के लिए महंगे रिसॉर्स सेव हो जाते हैं.
जैसा कि आपको पता होगा कि मशीन लर्निंग आज-कल ज़्यादातर लोगों की पसंद के मुताबिक काम कर रही है, लेकिन वेब डेवलपर के तौर पर इन क्षमताओं का इस्तेमाल करने के लिए आपको क्या करना होगा?
यह कोडलैब आपको खाली कैनवस से वेब ऐप्लिकेशन बनाने का तरीका बताता है. यह स्पैम टिप्पणी की असल समस्या से निपटने के लिए, सामान्य भाषा प्रोसेसिंग (कंप्यूटर की मदद से मानव भाषा को समझने की कला) का इस्तेमाल करता है. कई वेब डेवलपर को यह समस्या तब आती है, जब वे आज के लोकप्रिय वेब ऐप्लिकेशन की बढ़ती संख्या में से एक पर काम कर रहे हैं और इस कोडलैब से आपको इन समस्याओं को कुशलता से हल करने में मदद मिलेगी.
ज़रूरी शर्तें
यह कोडलैब उन वेब डेवलपर के लिए लिखा गया है जो मशीन लर्निंग में नए हैं. ये लोग TensorFlow.js के साथ, पहले से प्रशिक्षित मॉडल का इस्तेमाल शुरू करना चाहते हैं.
इस लैब के लिए, HTML5, सीएसएस, और JavaScript के बारे में जानकारी है.
आप क्या #39;जानेंगे
आप:
- TensorFlow.js क्या है और यह किन भाषाओं में होता है, इस बारे में ज़्यादा जानें.
- एक रीयल टाइम टिप्पणी सेक्शन के साथ एक काल्पनिक वीडियो ब्लॉग के लिए एक सरल एचटीएमएल / सीएसएस / जेएस वेबपेज बनाएं.
- TensorFlow.js का इस्तेमाल करके पहले से प्रशिक्षित मशीन लर्निंग मॉडल का इस्तेमाल करें. इससे यह अंदाज़ा लगाया जा सकता है कि कोई वाक्य स्पैम हो सकता है या नहीं. अगर ऐसा है, तो उपयोगकर्ता को यह सूचना दें कि उसकी टिप्पणी समीक्षा के लिए रोक दी गई है.
- टिप्पणियों के वाक्यों को इस तरह से कोड में बदलें कि मशीन लर्निंग मॉडल से उनका इस्तेमाल किया जा सके और फिर उन्हें कैटगरी में बांटा जा सके.
- यह तय करने के लिए कि टिप्पणी अपने-आप फ़्लैग हो या नहीं, मशीन लर्निंग मॉडल के आउटपुट की जानकारी पाएं. इस काल्पनिक UX का इस्तेमाल ऐसी किसी भी वेबसाइट पर किया जा सकता है जिस पर आप काम कर सकते हैं और उसे क्लाइंट के इस्तेमाल के किसी भी उदाहरण में फ़िट किया जा सकता है — यह कोई सामान्य ब्लॉग, फ़ोरम या Drupal जैसे किसी कॉन्टेंट मैनेजमेंट सिस्टम का हो सकता है.
कितनी साफ़-सुथरी. क्या यह करना मुश्किल है? नहीं. तो चलिए, हैकिंग शुरू करते हैं...
आपको क्या चाहिए
- Glitch.com खाते को साथ रखना पसंद है. आप चाहें, तो वेब सर्विंग एनवायरमेंट का इस्तेमाल करके, वीडियो में बदलाव कर सकते हैं और इसे खुद चला सकते हैं.
2. TensorFlow.js क्या है?

TensorFlow.js ओपन सोर्स मशीन लर्निंग लाइब्रेरी है, जो कहीं भी JavaScript चला सकती है. यह #39;Python में लिखी गई मूल TensorFlow लाइब्रेरी पर आधारित है. इसका मकसद, डेवलपर के अनुभव और JavaScript नेटवर्क के लिए एपीआई के सेट को फिर से बनाना है.
इसका इस्तेमाल कहां किया जा सकता है?
JavaScript की पोर्टेबिलिटी को देखते हुए, अब आप एक भाषा में लिख सकते हैं. साथ ही, आसानी से इन सभी प्लैटफ़ॉर्म पर मशीन लर्निंग कर सकते हैं:
- वैनिला JavaScript का इस्तेमाल करके, वेब ब्राउज़र में क्लाइंट साइड
- Node.js का इस्तेमाल करके सर्वर साइड और यहां तक कि Raspबेरी पाई जैसे IoT डिवाइस
- Electron का इस्तेमाल करके डेस्कटॉप ऐप्लिकेशन
- React Native ऐप्लिकेशन का इस्तेमाल करके नेटिव मोबाइल ऐप्लिकेशन
TensorFlow.js, इनमें से हर एनवायरमेंट में एक से ज़्यादा बैकएंड के साथ भी काम करता है. उदाहरण के लिए, यह सीपीयू या WebGL जैसे असल हार्डवेयर पर आधारित हो सकता है. एक "backend&कोटेशन; इस संदर्भ में सर्वर साइड एनवायरमेंट का मतलब नहीं है - उदाहरण के लिए, WebGL में क्लाइंट का साइडबैक ऐक्सेस जा सकता है) ताकि यह पक्का किया जा सके कि यह काम करता है और चीज़ों को तेज़ी से चलाता है. फ़िलहाल, TensorFlow.js:
- डिवाइस पर मौजूद ग्राफ़िक परफ़ॉर्मेंस कोड(#39;s ग्राफ़िक्स कार्ड) (जीपीयू) - यह जीपीयू ऐक्सेलरेशन के साथ बड़े मॉडल (3 एमबी से ज़्यादा साइज़) का सबसे तेज़ तरीका है.
- CPU पर वेब असेंबली (WASM) का एक्ज़ीक्यूशन - डिवाइसों के सीपीयू की परफ़ॉर्मेंस को बेहतर बनाने के लिए. उदाहरण के लिए, पुराने जनरेशन के मोबाइल फ़ोन. यह छोटे मॉडल (3 एमबी से कम का साइज़) के लिए बेहतर है. यह असल में किसी ग्राफ़िक प्रोसेसर पर कॉन्टेंट अपलोड करने की वजह से, WebGL के मुकाबले CPU पर ज़्यादा तेज़ी से काम कर सकता है.
- सीपीयू एक्ज़ीक्यूशन - फ़ॉलबैक, कोई अन्य एनवायरमेंट उपलब्ध नहीं होना चाहिए. यह तीन में से सबसे धीमी है, लेकिन आपकी मदद के लिए हमेशा तैयार है.
ध्यान दें: अगर आप जानते हैं कि आप किस डिवाइस पर काम करेंगे, तो आप इनमें से किसी एक बैकएंड को ज़बरदस्ती लागू कर सकते हैं या अगर आप यह तय नहीं करते हैं, तो आप TensorFlow.js को आपके लिए तय करने दे सकते हैं.
क्लाइंट साइड सुपर पावर
क्लाइंट मशीन पर वेब ब्राउज़र में TensorFlow.js चलाने से कई फ़ायदे हो सकते हैं.
निजता
आप क्लाइंट मशीन पर डेटा को प्रशिक्षित और अलग-अलग कैटगरी में बांट सकते हैं. इसके लिए, डेटा को किसी तीसरे पक्ष के वेब सर्वर पर भेजने की ज़रूरत नहीं पड़ती. कई बार ऐसा हो सकता है कि स्थानीय कानूनों का पालन करना ज़रूरी हो, जैसे कि जीडीपीआर. उदाहरण के लिए, ऐसा डेटा जिसे उपयोगकर्ता अपनी मशीन पर रखकर किसी तीसरे पक्ष को नहीं भेजना चाहते.
रफ़्तार
आपको रिमोट सर्वर पर डेटा भेजने की ज़रूरत नहीं होती, इसलिए अनुमान लगाना (डेटा की कैटगरी तय करना) ज़्यादा तेज़ हो सकता है. इससे भी बेहतर तरीका यह है कि आपके पास डिवाइस, कैमरे, माइक्रोफ़ोन, जीपीएस, एक्सलरोमीटर जैसे डिवाइस के सेंसर का सीधा ऐक्सेस हो, ताकि उपयोगकर्ता आपको ऐक्सेस दे सके.
पहुंच और आकलन
दुनिया भर में बस एक क्लिक करके, आप किसी व्यक्ति को भेजे गए लिंक पर क्लिक करके, उसके ब्राउज़र में वेब पेज खोल सकते हैं. साथ ही, अपने बनाए गए कॉन्टेंट का इस्तेमाल भी कर सकते हैं. CUDA ड्राइवर के साथ जटिल सर्वर साइड Linux सेटअप की ज़रूरत नहीं है. बस मशीन लर्निंग सिस्टम का इस्तेमाल करने के लिए और भी बहुत कुछ चाहिए.
लागत
किसी सर्वर का मतलब यह नहीं है कि आपको सिर्फ़ अपनी HTML, सीएसएस, JS, और मॉडल फ़ाइलों को होस्ट करने के लिए सीडीएन देना होगा. सीडीएन की कीमत का खर्च, सर्वर (संभावित तौर पर बने ग्राफ़िक कार्ड वाले) को 24/7 चलाने पर नहीं पड़ता.
सर्वर साइड की सुविधाएं
TensorFlow.js के Node.js को लागू करने से, ये सुविधाएं चालू हो जाती हैं.
CUDA के लिए पूरी सहायता
सर्वर साइड पर, ग्राफ़िक कार्ड से तेज़ी लाने के लिए, आपको NVIDIA CUDA ड्राइवर इंस्टॉल करना होगा. ऐसा करने पर, TensorFlow ग्राफ़िक कार्ड के साथ काम कर पाएगा, ( WebGL का इस्तेमाल करने वाले ब्राउज़र में नहीं - किसी इंस्टॉल की ज़रूरत नहीं है). हालांकि, सीयूडीए की पूरी सुविधा के साथ, आप ग्राफ़िक कार्ड का कम इस्तेमाल कर सकते हैं. इस वजह से, आपको तेज़ी से ट्रेनिंग और अनुमान लगाने का समय मिल सकता है. परफ़ॉर्मेंस, Python TensorFlow को लागू करने के हिसाब से एक जैसा है, क्योंकि दोनों ही C++ का बैकएंड शेयर करते हैं.
मॉडल साइज़
रिसर्च के लिए बनाए गए सबसे नए मॉडल के लिए, हो सकता है कि आप बहुत बड़े मॉडल का इस्तेमाल कर रहे हों, जिनका साइज़ गीगाबाइट (जीबी) हो सकता है. प्रति ब्राउज़र टैब मेमोरी के उपयोग की सीमाओं के कारण ये मॉडल वर्तमान में वेब ब्राउज़र में नहीं चलाए जा सकते. इन बड़े मॉडल को चलाने के लिए, आप अपने सर्वर पर मौजूद हार्डवेयर की खास जानकारी के साथ Node.js का इस्तेमाल कर सकते हैं. इसके लिए, आपको ऐसे मॉडल को बेहतर तरीके से चलाना होगा.
आईओटी
Node.js Raspबेरी पाई जैसे लोकप्रिय सिंगल बोर्ड कंप्यूटर पर काम करता है. इसका मतलब है कि आप ऐसे डिवाइस पर भी TensorFlow.js मॉडल चला सकते हैं.
रफ़्तार
Node.js को JavaScript में लिखा गया है, जिसका मतलब है कि यह सिर्फ़ समय में कंपाइल करने में इस्तेमाल होता है. इसका मतलब यह है कि आपको Node.js का इस्तेमाल करते समय, परफ़ॉर्मेंस में सुधार दिख सकता है. ऐसा इसलिए है, क्योंकि इसे रनटाइम के दौरान ऑप्टिमाइज़ किया जाएगा. खास तौर पर, ऐसा तब किया जाएगा, जब किसी प्री-प्रोसेसिंग का इस्तेमाल किया जा रहा हो. इसका एक बढ़िया उदाहरण इस केस स्टडी में देखा जा सकता है, जो दिखाता है कि Hugging Face ने किस तरह अपने नैचुरल लैंग्वेज प्रोसेसिंग मॉडल के लिए, Node.js का इस्तेमाल करके परफ़ॉर्मेंस को दो गुना बेहतर किया.
अब आप TensorFlow.js की बुनियादी बातें जान चुके हैं. इसके काम करने के साथ-साथ, इसके कुछ और फ़ायदे भी काम में शुरू हो जाते हैं!
3. पहले से प्रशिक्षित मॉडल
मुझे पहले से प्रशिक्षित मॉडल का इस्तेमाल क्यों करना चाहिए?
अगर किसी लोकप्रिय मॉडल को पहले से ट्रेनिंग दी गई है, तो इसके कई फ़ायदे हैं. हालांकि, इसके लिए ज़रूरी है कि यह आपके इस्तेमाल के उदाहरण के हिसाब से सही हो, जैसे:
- आपको ट्रेनिंग का डेटा खुद इकट्ठा करने की ज़रूरत नहीं है. डेटा को सही फ़ॉर्मैट में तैयार करना और उसे इस तरह से लेबल करना कि मशीन लर्निंग सिस्टम इस जानकारी की मदद से सीख सके. इसमें बहुत समय लग सकता है और यह महंगा भी हो सकता है.
- कम खर्च और समय में किसी आइडिया को तेज़ी से प्रोटोटाइप करने की सुविधा.
ज़रूरत के मुताबिक कोई पॉइंट नहीं बनाया जा सकता; जब पहले से ट्रेनिंग वाला मॉडल आपके लिए ज़रूरी हो, तो आप अपने क्रिएटिव आइडिया को लागू करने के लिए मॉडल से मिली जानकारी का इस्तेमाल कर सकते हैं. - आर्ट रिसर्च की स्थिति का इस्तेमाल करना. पहले से प्रशिक्षित मॉडल अक्सर लोकप्रिय रिसर्च पर आधारित होते हैं. इससे आपको उन मॉडल का एक्सपोज़र मिलता है. साथ ही, असल दुनिया में उनकी परफ़ॉर्मेंस को भी समझ सकते हैं.
- इस्तेमाल में आसानी और ज़्यादा जानकारी वाले दस्तावेज़. इस तरह के मॉडल की लोकप्रियता के आधार पर.
- लर्निंग ट्रांसफ़र क्षमताएं. पहले से तैयार किए गए कुछ मॉडल, ट्रांसफ़र करने की सुविधा देते हैं. आम तौर पर, यह मशीन लर्निंग के एक टास्क से सीखी गई जानकारी को दूसरे मिलते-जुलते उदाहरण में ट्रांसफ़र करती है. उदाहरण के लिए, कुत्तों की पहचान करने के लिए, मूल रूप से प्रशिक्षित मॉडल को फिर से कुत्तों की पहचान करना सिखाया जा सकता है. इसके लिए, फ़ीड का नया डेटा देने की ज़रूरत होती है. यह जल्दी हो जाएगा, क्योंकि आपने खाली कैनवस से शुरुआत नहीं की है. मॉडल, बिल्लियों को पहचानने के लिए पहले सीखे गए तरीके का इस्तेमाल करके नई चीज़ को पहचान लेता है. आखिरकार, कुत्तों की आंखों और कानों में भी अंतर होता है. इसलिए, अगर उन्हें पहले से ही उन सुविधाओं को ढूंढने का तरीका पता है, तो वे आधी रात में ही मौजूद हैं. मॉडल को अपने डेटा पर ज़्यादा तेज़ी से फिर से सिखाएं.
पहले से प्रशिक्षित टिप्पणी की पहचान करने वाला मॉडल
आप स्पैम टिप्पणी का पता लगाने वाली अपनी ज़रूरत के लिए, वर्ड एम्बेडिंग मॉडल का औसत आर्किटेक्चर इस्तेमाल करेंगे. हालांकि, अगर आप किसी ऐसे मॉडल का इस्तेमाल करने की कोशिश करते हैं जिसे कोई प्रशिक्षित नहीं किया गया है, तो ऐसा करना बेहतर होगा कि वह स्पैम हो या न हो.
मॉडल को उपयोगी बनाने के लिए, इसे कस्टम डेटा पर ट्रेनिंग देने की ज़रूरत होती है. ऐसा करने पर, यह जान पाएगा कि स्पैम और बिना स्पैम वाली टिप्पणियां कैसी दिखती हैं. इससे उस जानकारी को, आने वाले समय में सही कैटगरी में बांटने का बेहतर मौका मिलेगा.
शुक्र है कि स्पैम टिप्पणी की कैटगरी तय करने के इस काम के लिए, किसी ने पहले ही मॉडल के इस आर्किटेक्चर को तैयार कर लिया है. इसलिए, आप इसे शुरुआत की जगह के तौर पर इस्तेमाल कर सकते हैं. आपको अलग-अलग काम करने के लिए एक ही मॉडल आर्किटेक्चर का इस्तेमाल करके पहले से प्रशिक्षित दूसरे मॉडल मिल सकते हैं, जैसे कि यह पता लगाना कि कोई टिप्पणी किस भाषा में लिखी गई थी या यह अनुमान लगाना कि वेबसाइट संपर्क फ़ॉर्म डेटा किसी लिखित कंपनी (उदा. बिक्री (प्रॉडक्ट पूछताछ)) या इंजीनियरिंग (तकनीकी गड़बड़ी या सुझाव) के आधार पर अपने-आप किसी खास कंपनी टीम को भेजा जाना चाहिए या नहीं. ज़रूरत के मुताबिक ट्रेनिंग डेटा मिलने से, इस तरह का मॉडल हर मामले में, इस तरह के टेक्स्ट की कैटगरी तय कर सकता है. इससे, आपके वेब ऐप्लिकेशन को बेहतर सुविधाएं मिलती हैं और आपके संगठन की परफ़ॉर्मेंस बेहतर होती है.
आने वाले समय में शुरू होने वाला कोड लैब में जाकर, आप यह जान सकते हैं कि मॉडल मेकर का इस्तेमाल करके, स्पैम टिप्पणी के इस मॉडल को फिर से ट्रेनिंग दी जाए. साथ ही, इसकी मदद से आप टिप्पणी के डेटा पर अपनी परफ़ॉर्मेंस को बेहतर बना सकते हैं. फ़िलहाल, आप स्पैम का पता लगाने वाले मौजूदा मॉडल का इस्तेमाल शुरुआत करने वाले पॉइंट के तौर पर करेंगे. यह शुरुआती वेब ऐप्लिकेशन को पहले प्रोटोटाइप के तौर पर काम करने में मदद करेगा.
TF Hub नाम की एक वेबसाइट पर, स्पैम टिप्पणी की पहचान करने वाला यह मॉडल तैयार किया है. इस वेबसाइट का रखरखाव Google करता है. एमएल इंजीनियर, इस टेक्नोलॉजी के इस्तेमाल से जुड़े कई सामान्य मामलों के लिए, पहले से बनाए गए मॉडल प्रकाशित कर सकते हैं. जैसे, टेक्स्ट, विज़न, साउंड वगैरह. आगे बढ़ें और कोड कोड में बाद में वेब ऐप्लिकेशन में इस्तेमाल करने के लिए, अभी मॉडल फ़ाइलें डाउनलोड करें.
JS मॉडल के लिए डाउनलोड बटन पर क्लिक करें, जैसा कि नीचे दिखाया गया है:

4. कोड सेट अप करें
आपको क्या चाहिए
- एक आधुनिक वेब ब्राउज़र.
- एचटीएमएल, सीएसएस, JavaScript, और Chrome DevTools के बारे में बुनियादी जानकारी (कंसोल का आउटपुट देखकर).
आइए, कोडिंग करते हैं.
हमने Glitch.com Node.js Express बॉयलरप्लेट टेंप्लेट बनाया है, ताकि आप सिर्फ़ एक क्लिक करके इस कोड लैब के लिए अपनी मूल स्थिति के तौर पर क्लोन कर सकें.
ग्लिच पर, इसे फ़ोर्क करने और एक नई फ़ाइल बनाने के लिए, इसमें &kot;remix&&tt बटन पर क्लिक करें.
यह बहुत छोटा कंकाल हमें www फ़ोल्डर में नीचे दी गई फ़ाइलें देता है:
- एचटीएमएल पेज (index.html)
- स्टाइलशीट (style.css)
- हमारा JavaScript कोड (script.js) लिखने के लिए फ़ाइल
आपकी सुविधा के लिए, हमने एचटीएमएल फ़ाइल में TensorFlow.js लाइब्रेरी का इंपोर्ट भी जोड़ा है, जो ऐसा दिखता है:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
इसके बाद, हम www फ़ोल्डर को package.json और server.js के ज़रिए एक साधारण Node Express सर्वर से दिखाते हैं
5. ऐप्लिकेशन एचटीएमएल बॉयलरप्लेट
आपकी शुरुआत की जगह क्या है?
सभी प्रोटोटाइप के लिए कुछ बुनियादी एचटीएमएल मचान की ज़रूरत होती है, जिन पर आप अपने नतीजों को रेंडर कर सकते हैं. इसे अभी सेट अप करें. आप इसे जोड़ने वाले हैं:
- पेज का शीर्षक
- कुछ जानकारी देने वाला टेक्स्ट
- वीडियो ब्लॉग एंट्री दिखाने वाला प्लेसहोल्डर वीडियो
- टिप्पणियां देखने और लिखने के लिए एक क्षेत्र
index.html खोलें और ऊपर दी गई सुविधाओं को सेट अप करने के लिए, मौजूदा कोड पर चिपकाएं. इसके लिए:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
इसे बांटना
आपकी जोड़ी गई कुछ ज़रूरी चीज़ों को हाइलाइट करने के लिए, ऊपर दिए गए कुछ एचटीएमएल कोड को ब्रेकडाउन करें.
- आपने पेज पर मौजूद शीर्षक के लिए
<h1>टैग जोड़ा है. साथ ही,<header>में मौजूद लॉगिन बटन के लिए<a>टैग भी जोड़ा है. इसके बाद, लेख के शीर्षक के लिए<h2>और वीडियो के ब्यौरे के लिए<p>टैग जोड़ा गया. यहां कुछ विशेष नहीं है. - आपने एक
iframeटैग जोड़ा है, जो किसी आर्बिट्ररी वीडियो को एम्बेड करता है. अभी के लिए आप एक प्लेसहोल्डर के रूप में TensorFlow.jss के बेहतरीन रैप का इस्तेमाल कर रहे हैं, लेकिन आप iframe का यूआरएल बदलकर, यहां कोई भी वीडियो डाल सकते हैं. असल में, किसी प्रोडक्शन वेबसाइट पर ये सभी वैल्यू बैकएंड के हिसाब से रेंडर की जाएंगी, जो कि देखे जा रहे पेज पर निर्भर करती हैं. - आखिर में, आपने &\ot;comments&कोटेशन; के आईडी और क्लास के साथ
sectionजोड़ा है; जिसमें नई टिप्पणियां लिखने के लिएbuttonके साथ-साथ एक कॉन्टेंट में बदलाव करने लायकdivशामिल है. साथ ही, आप नई टिप्पणी सबमिट करने के लिएbuttonका इस्तेमाल कर सकते हैं. आपके पास हर टैग आइटम में,spanटैग में उपयोगकर्ता नाम और पोस्ट करने का समय है. इसके बाद,pटैग में खुद ही टिप्पणी करें. 2 उदाहरण टिप्पणियों को अभी एक प्लेसहोल्डर के रूप में हार्ड कोड किया गया है.
अगर आप अभी आउटपुट की झलक देख रहे हैं, तो यह कुछ ऐसा दिखना चाहिए:

यह बहुत बेकार लग रहा है. इसलिए, कुछ स्टाइल जोड़ने का समय आ गया है...
6. शैली जोड़ें
एलिमेंट डिफ़ॉल्ट
सबसे पहले, ठीक से जोड़े गए एचटीएमएल एलिमेंट के लिए स्टाइल जोड़ें.
सभी ब्राउज़र और ओएस पर टिप्पणी शुरू करने के पॉइंट के लिए, सीएसएस रीसेट लागू करके शुरू करें. style.css कॉन्टेंट को इन चीज़ों के साथ ओवरराइट करें:
style.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
इसके बाद, यूज़र इंटरफ़ेस में जान डालने के लिए, कुछ उपयोगी सीएसएस को जोड़ें.
आपने ऊपर जो रीसेट सीएसएस कोड जोड़ा है उसके नीचे style.css के आखिर में इन्हें जोड़ें:
style.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
वाह! आपको बस इतना ही चाहिए. अगर आप ऊपर दिए गए 2 कोड कोड के साथ अपनी शैलियों को सफलतापूर्वक ओवरराइट कर देते हैं, तो आपका लाइव पूर्वावलोकन अब ऐसा दिखाई देना चाहिए:

डिफ़ॉल्ट रूप से स्वीट, नाइट मोड, और मुख्य एलिमेंट पर माउस घुमाने के आकर्षक सीएसएस ट्रांज़िशन. बहुत बढ़िया. अब JavaScript का इस्तेमाल करके, व्यवहार से जुड़े कुछ लॉजिक जोड़ें.
7. JavaScript: DOM में हेर-फेर और इवेंट हैंडलर
मुख्य डीओएम एलिमेंट का रेफ़रंस देना
सबसे पहले, यह पक्का करें कि पेज के मुख्य हिस्सों को ऐक्सेस किया जा सकता हो, जिन्हें आपको बाद में कोड में हेर-फेर करना या ऐक्सेस करना होगा. साथ ही, स्टाइलिंग के लिए कुछ सीएसएस क्लास कॉन्सटेंट तय कर सकते हैं.
script.js के कॉन्टेंट को इन कॉन्सटेंट से बदलकर शुरू करें:
script.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
टिप्पणी पोस्ट करने की प्रक्रिया को मैनेज करना
इसके बाद, POST_COMMENT_BTN में एक इवेंट लिसनर और हैंडलिंग फ़ंक्शन जोड़ें, ताकि यह लिखित टिप्पणी वाले टेक्स्ट को कैप्चर कर सके और एक सीएसएस क्लास सेट कर सके. इससे पता चलता है कि प्रोसेसिंग शुरू हो चुकी है. ध्यान दें, अगर प्रोसेसिंग पहले से जारी है, तो यह पक्का कर लें कि आपने पहले ही इस बटन पर क्लिक न किया हो.
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
वाह! अगर आप वेबपेज को रीफ़्रेश करते हैं और टिप्पणी को पोस्ट करने की कोशिश करते हैं, तो अब आपको 'टिप्पणी करें' बटन और टेक्स्ट ग्रेस्केल में दिखने लगेंगे. साथ ही, कंसोल में आपको यह टिप्पणी प्रिंट की हुई दिखेगी:

अब आपके पास एक बेसिक एचटीएमएल / सीएसएस / जेएस कंकाल है, यह अपने ध्यान को मशीन लर्निंग मॉडल पर वापस ले जाने का समय है, ताकि आप इसे खूबसूरत वेबपेज के साथ जोड़ सकें.
8. मशीन लर्निंग मॉडल दिखाना
आप मॉडल को लोड करने के लिए करीब-करीब तैयार हैं. हालांकि, ऐसा करने से पहले आपको कोडलैब में पहले से डाउनलोड की गई मॉडल फ़ाइलें अपलोड करनी होंगी, ताकि उन्हें होस्ट किया जा सके और कोड में इस्तेमाल किया जा सके.
सबसे पहले, अगर आपने पहले से ऐसा नहीं किया है, तो इस कोडलैब के शुरू में मॉडल के लिए डाउनलोड की गई फ़ाइलों को अनज़िप करें. आपको डायरेक्ट्री में नीचे दी गई फ़ाइलें शामिल दिखेंगी:

आपके पास यहां क्या है?
model.json- यह प्रशिक्षित TensorFlow.js मॉडल में से एक फ़ाइल है. आप इस खास फ़ाइल को बाद में अपने TensorFlow.js कोड में रेफ़र करेंगे.group1-shard1of1.bin- यह एक बाइनरी फ़ाइल होती है, जिसमें TensorFlow.js मॉडल के ट्रेनिंग वाले वेट (इसमें क्लास का काम करने के लिए कई संख्याएं शामिल होती हैं) जिन्हें डाउनलोड करने के लिए, आपके सर्वर पर कहीं भी होस्ट करना होगा.vocab- बिना एक्सटेंशन वाली यह अजीब फ़ाइल, मॉडल मेकर की एक ऐसी चीज़ है जो हमें वाक्यों में शब्दों को कोड में बदलने का तरीका बताती है, ताकि मॉडल यह समझ सके कि उनका इस्तेमाल कैसे किया जाता है. हम अगले सेक्शन में इसके बारे में ज़्यादा जानकारी देंगे.labels.txt- इसमें सिर्फ़ क्लास के नाम शामिल होते हैं, जिनका अनुमान मॉडल लगाता है. इस मॉडल के लिए, अगर आप इस फ़ाइल को अपने टेक्स्ट एडिटर में खोलते हैं, तो इसमें &अनुमान है कि कोटेशन गलत है.
TensorFlow.js मॉडल फ़ाइलें होस्ट करना
पहले model.json और *.bin फ़ाइलें जो वेब सर्वर पर जनरेट की गई थीं, ताकि आप उन्हें वेब पेज से ऐक्सेस कर सकें.
ग्लिच फ़ाइलों में फ़ाइलें अपलोड करना
- अपने ग्लिच प्रोजेक्ट के बाएं पैनल में, एसेट फ़ोल्डर पर क्लिक करें.
- एसेट अपलोड करें पर क्लिक करें और इस फ़ोल्डर में अपलोड करने के लिए
group1-shard1of1.binचुनें. अपलोड होने के बाद यह कुछ ऐसा दिखाई देगा:

- वाह! अब
model.jsonफ़ाइल के लिए भी ऐसा ही करें. दो फ़ाइलें आपके एसेट फ़ोल्डर में इस तरह की होनी चाहिए:

- अभी-अभी अपलोड की गई
group1-shard1of1.binफ़ाइल पर क्लिक करें. आप यूआरएल को उसकी जगह पर कॉपी कर सकते हैं. इस पाथ को अभी कॉपी करें, जैसा कि दिखाया गया है:

- अब स्क्रीन के नीचे बाईं ओर, टूल &g; टर्मिनल पर क्लिक करें. टर्मिनल विंडो के लोड होने का इंतज़ार करें. लोड होने के बाद, इन फ़ोल्डर को टाइप करें. इसके बाद,
wwwफ़ोल्डर में डायरेक्ट्री बदलने के लिए, Enter दबाएं:
टर्मिनल:
cd www
- इसके बाद, नीचे दिए गए यूआरएल को ग्लिच पर एसेट फ़ोल्डर में फ़ाइलों के लिए जनरेट किए गए यूआरएल से बदलकर, अपलोड की गई दो फ़ाइलों को डाउनलोड करें (
wgetहर फ़ाइल और कस्टम यूआरएल के लिए एसेट फ़ोल्डर की जांच करें). ध्यान दें कि दो यूआरएल के बीच में स्पेस होना चाहिए और आप जिस यूआरएल का इस्तेमाल करना चाहते हैं वह नीचे दिए गए यूआरएल से अलग होगा, लेकिन वे एक जैसे दिखेंगे:
टर्मिनल
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
सुपर, अब आपने www फ़ोल्डर में अपलोड की गई फ़ाइलों की एक कॉपी बना ली है. हालांकि, अब वे अजीब नामों के साथ डाउनलोड हो जाएंगी.
- टर्मिनल में
lsलिखें और Enter दबाएं. आपको कुछ इस तरह दिखेगा:

mvनिर्देश का इस्तेमाल करके, आप फ़ाइलों के नाम बदल सकते हैं. कंसोल में इनमें से कोई एक टाइप करें और हर लाइन के बाद <, &ker>Enter</ अपील करें;और
टर्मिनल:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- आखिर में, टर्मिनल में
refreshका टाइप करके ग्लिच प्रोजेक्ट को रीफ़्रेश करें. साथ ही, <ker>Enter</KMZ> दबाएं:
टर्मिनल:
refresh
- रीफ़्रेश करने के बाद, अब आपको यूज़र इंटरफ़ेस के
wwwफ़ोल्डर मेंmodel.jsonऔरgroup1-shard1of1.binदिखेंगे:

वाह! अब आप ब्राउज़र में, कुछ असल कोड के साथ अपलोड की गई मॉडल फ़ाइलों का इस्तेमाल करने के लिए तैयार हैं.
9. & होस्ट किया गया TensorFlow.js मॉडल इस्तेमाल करें
अब आप ऐसे पॉइंट पर हैं जहां अपलोड किए गए TensorFlow.js मॉडल को कुछ डेटा के साथ लोड करके, यह देखा जा सकता है कि वह काम करता है या नहीं.
फ़िलहाल, आपको उदाहरण के तौर पर नीचे इनपुट का जो डेटा दिखेगा वह रहस्यपूर्ण (संख्या की श्रेणी) जैसा दिखेगा और जनरेट होने के तरीके के बारे में अगले सेक्शन में बताया जाएगा. अभी के लिए, इसे एक संख्या वाली संख्या के तौर पर देखें. इस स्तर पर, यह टेस्ट करना ज़रूरी है कि मॉडल हमें बिना किसी गड़बड़ी के जवाब देता है.
नीचे दी गई कोड को अपनी script.js फ़ाइल के आखिर में जोड़ें. साथ ही, पक्का करें कि आपने पिछली फ़ाइल में अपने ग्लिच एसेट फ़ोल्डर में फ़ाइल अपलोड करते समय, MODEL_JSON_URL स्ट्रिंग वैल्यू को अपने model.json फ़ाइल के पाथ से बदल दिया हो. (याद रखें, आप ग्लिच के एसेट फ़ोल्डर में फ़ाइल को ढूंढने के लिए उस पर क्लिक कर सकते हैं).
हर लाइन का काम समझने के लिए, नए कोड की टिप्पणियां पढ़ें:
script.js
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
अगर प्रोजेक्ट सही तरीके से सेट अप किया गया, तो आपको कंसोल की विंडो में प्रिंट की गई कुछ जानकारी दिखेगी. यह जानकारी तब दी जाएगी, जब आप लोड किए गए मॉडल का इस्तेमाल करके, इनपुट पास करने के लिए नतीजे का अनुमान लगाएंगे:

कंसोल में, आपको प्रिंट किए गए दो नंबर दिखेंगे:
- 0.9996011
- 0.0003989
हालांकि, यह सुनने में आसान लग सकता है, लेकिन असल में ये संख्याएं इस बात की संभावना दिखाती हैं कि मॉडल के हिसाब से जो कैटगरी आपने डाली है वह है या नहीं. हालांकि, वे क्या दिखाते हैं?
अगर आप अपनी लोकल मशीन पर मौजूद डाउनलोड की गई मॉडल फ़ाइलों से labels.txt फ़ाइल खोलते हैं, तो आप देखेंगे कि इसमें दो फ़ील्ड भी हैं:
- गलत
- सही
इसलिए, इस मामले में मॉडल कह रहा है कि यह 99.96011% पक्का है (नतीजे वाले ऑब्जेक्ट में 0.9996011 के तौर पर दिखाया गया है कि आपने जो इनपुट दिया था वह [1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] था (जिसे स्पैम नहीं था (यानी गलत था).
ध्यान दें कि labels.txt में पहला लेबल false था और इसे कंसोल प्रिंट में पहले आउटपुट के ज़रिए दिखाया जाता है. इससे पता चलता है कि आउटपुट का अनुमान कैसे जुड़ा है.
ठीक है, अब आपको पता है कि आउटपुट को कैसे समझा जा सकता है, लेकिन असल में इनपुट के तौर पर जो संख्याएं दी गई थीं उनमें बड़ी संख्या क्या थी और आप वाक्यों को इस फ़ॉर्मैट में कैसे बदल सकते हैं? उसके लिए, आपको टोकन और टोकन के बारे में जानना होगा. आगे पढ़ें!
10. टोकन और एएमपी; Tensor
टोकनाइज़ेशन
इससे, यह पता चलता है कि मशीन लर्निंग मॉडल में, इनपुट के तौर पर सिर्फ़ कुछ नंबर स्वीकार किए जा सकते हैं. क्यों? असल में, ऐसा इसलिए है, क्योंकि मशीन लर्निंग मॉडल में असल में कई गणित से जुड़े काम होते हैं. इसलिए, अगर आप इसे किसी ऐसी संख्या में पास करते हैं जो नंबर नहीं है, तो इससे निपटने में आपको मुश्किल होगी. तो अब सवाल यह उठता है कि आप जिस मॉडल को लोड करते हैं उसके साथ इस्तेमाल करने के लिए, वाक्यों को संख्याओं में कैसे बदला जाता है?
वैसे तो पूरी प्रक्रिया एक मॉडल से दूसरे मॉडल में अलग होती है, लेकिन इसके लिए आपके पास डाउनलोड की गई मॉडल फ़ाइलों में एक और फ़ाइल होती है जिसका नाम vocab, है और यह आपके डेटा को कोड में बदलने का तरीका है.
आगे बढ़ें और अपनी मशीन पर किसी स्थानीय टेक्स्ट एडिटर में vocab खोलें. इसके बाद, आपको कुछ ऐसा दिखेगा:

बुनियादी तौर पर यह एक लुकअप टेबल है, जिसमें बताया गया है कि काम के शब्दों को ऐसी संख्याओं में कैसे बदला जाए जिन्हें मॉडल समझ सके. फ़ाइल <PAD>, <START>, और <UNKNOWN> के सबसे ऊपर कुछ खास मामले भी हैं:
<PAD>- यह छोटी &जगह (“कोट]; के लिए छोटा है. यह पता चलता है कि मशीन लर्निंग मॉडल में एक तय संख्या में इनपुट होने चाहिए, चाहे आपकी वाक्य कितनी भी लंबी हो. मॉडल का इस्तेमाल करने के लिए यह ज़रूरी है कि इनपुट के लिए हमेशा 20 संख्याएं दी जाएं (यह मॉडल के क्रिएटर ने तय किया था और अगर आप मॉडल को फिर से ट्रेनिंग देते हैं, तो इसमें बदलाव किया जा सकता है). इसलिए, अगर आपके पास & कोटेशन जैसे कोई वाक्यांश है, तो मुझे वीडियो और कोट पसंद है; आप बाकी खाली स्पेस को 0's से भर देंगे, जो<PAD>टोकन को दिखाते हैं. अगर वाक्य में 20 से ज़्यादा शब्द हैं, तो आपको उसे अलग करना होगा, ताकि वह इस ज़रूरी शर्त के मुताबिक हो. इसके बजाय, आपको कई छोटे-छोटे वाक्यों में कई कैटगरी तय करनी होंगी.<START>- वाक्य की शुरुआत दिखाने के लिए, यह हमेशा पहला टोकन होता है. आपने पिछले चरणों में उदाहरण के तौर पर इनपुट के तौर पर, संख्याओं की श्रेणी को &&tt11&kot; से शुरू किया होगा - यह<START>टोकन का प्रतिनिधित्व कर रहा था.<UNKNOWN>- जैसा कि आपने अंदाज़ा लगाया होगा कि अगर शब्दों के इस लुकअप में शब्द मौजूद नहीं है, तो आप संख्या के तौर पर<UNKNOWN>टोकन (&&tt) से दिखाया गया है.
हर दूसरे शब्द के लिए, यह या तो लुकअप में मौजूद होता है और एक खास नंबर होता है. इसलिए, आप इसका इस्तेमाल करेंगे या यह मौजूद नहीं होगा. ऐसे में, आप इसके बजाय <UNKNOWN> टोकन नंबर का इस्तेमाल करेंगे.
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
अब आप देख सकते हैं कि यह चार शब्दों वाला एक वाक्य था, क्योंकि बाकी के <START> या <PAD> टोकन थे और श्रेणी में 20 नंबर थे. ठीक है, मैं थोड़ी और जानकारी इकट्ठा करना शुरू कर रही हूँ.
असल में जो वाक्य मैंने इसके लिए लिखा है वह "मुझे अपने कुत्ते से लगाव है". आप ऊपर दिए गए स्क्रीनशॉट से देख सकते हैं कि यह & &? /? को सही में बदला गया है. अगर आप दूसरे शब्दों को खोजते हैं, तो आपको उनसे जुड़े नंबर भी मिलेंगे.
सेंसर
एमएल मॉडल, अंक के रूप में दिए गए आपके इनपुट को स्वीकार करेगा, उससे पहले एक ही समस्या आती है. आपको संख्याओं की श्रेणी को Tensor के नाम से बदलना होगा. साथ ही, हां, आपने इसका अंदाज़ा लगाया होगा कि TensorFlow का नाम इन चीज़ों के नाम पर रखा गया है. असल में Tensors का फ़्लो ज़रूरी है.
टेनर क्या होता है?
TensorFlow.org की आधिकारिक परिभाषा:
&kot;Tensors एक तरह की कई डाइमेंशन वाली होती हैं. सभी टेंज़र नहीं बदले जा सकते: आप कभी भी टेंसर के कॉन्टेंट को अपडेट नहीं कर सकते, सिर्फ़ नए टेंसर को बना सकते हैं.
आसान अंग्रेज़ी में, किसी भी डाइमेंशन के श्रेणी के लिए सिर्फ़ एक काल्पनिक नाम है, जिसमें कुछ ऐसे फ़ंक्शन हैं जो Tensor ऑब्जेक्ट में बनाए गए हैं. ये मशीन लर्निंग डेवलपर के तौर पर हमारे लिए उपयोगी हैं. हालांकि, आपको यह ध्यान रखना चाहिए कि Tensor, सिर्फ़ एक टाइप का डेटा सेव करता है, जैसे कि सभी पूर्णांक या फ़्लोटिंग-पॉइंट के नंबर.एक बार बनाए जाने के बाद, आप Tenor के कॉन्टेंट को कभी नहीं बदल सकते. इसलिए, आप इसे स्थायी नंबर के तौर पर नंबर के तौर पर समझ सकते हैं!
फ़िलहाल, इसकी चिंता न करें. कम से कम, इस पर ध्यान दें कि यह मशीन लर्निंग मॉडल के लिए एक से ज़्यादा डाइमेंशन वाला स्टोरेज सिस्टम है, जब तक कि आप इसके बारे में इस तरह किसी अच्छी किताब के बारे में ज़्यादा नहीं जान देते. हमारा सुझाव है कि अगर आप Tensors और उन्हें इस्तेमाल करने के तरीकों के बारे में ज़्यादा जानना चाहते हैं.
सब कुछ एक साथ करें: कोडिंग टेंसर और टोकनाइज़ेशन
आप कोड में vocab फ़ाइल का इस्तेमाल कैसे करते हैं? बहुत अच्छा सवाल है!
JS डेवलपर के रूप में इस फ़ाइल पर इसका #इस्तेमाल नहीं हो सकता. बेहतर होगा, अगर यह एक JavaScript ऑब्जेक्ट होता, जिसे आप आसानी से इंपोर्ट और इस्तेमाल कर सकते. आप देख सकते हैं कि इस फ़ाइल के डेटा को इस तरह के फ़ॉर्मैट में बदलना कितना आसान होगा:
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
अपने पसंदीदा टेक्स्ट एडिटर का इस्तेमाल करके, आप vocab फ़ाइल को ऐसे फ़ॉर्मैट में आसानी से बदल सकते हैं जिसमें कुछ को ढूंढकर बदला जा सके. हालांकि, इस काम को आसान बनाने के लिए आप पहले से बने इस टूल का इस्तेमाल भी कर सकते हैं.
यह काम पहले से करने और vocab फ़ाइल को सही फ़ॉर्मैट में सेव करने से, आपको यह कन्वर्ज़न करने और हर पेज लोड होने पर पार्स करने से रोका जाता है. यह सीपीयू के संसाधनों की बर्बादी है. इससे भी बेहतर तरीका यह है कि JavaScript ऑब्जेक्ट में ये प्रॉपर्टी होती हैं:
&कोटेशन; ऑब्जेक्ट प्रॉपर्टी का नाम कोई भी मान्य JavaScript स्ट्रिंग हो सकती है. इसके अलावा, यह ऐसी कोई भी स्ट्रिंग हो सकती है जिसे स्ट्रिंग में बदला जा सके. इसमें खाली स्ट्रिंग भी शामिल है. हालांकि, जो प्रॉपर्टी नाम मान्य JavaScript आइडेंटिफ़ायर नहीं है (उदाहरण के लिए, किसी प्रॉपर्टी के नाम में स्पेस या हाइफ़न है या वह किसी संख्या से शुरू होता है) सिर्फ़ स्क्वेयर ब्रैकेट वाले नोटेशन का इस्तेमाल करके ऐक्सेस किया जा सकता है;
इस तरह, अगर आप स्क्वेयर ब्रैकेट वाले नोटेशन का इस्तेमाल करते हैं, तो आप इस आसान ट्रांसफ़ॉर्मेशन के ज़रिए एक ज़्यादा असरदार लुकअप टेबल बना सकते हैं.
ज़्यादा काम के फ़ॉर्मैट में बदलना
अपनी टेक्स्ट फ़ाइल को ऊपर दिए गए फ़ॉर्मैट में बदलें. इसके लिए, टेक्स्ट एडिटर की मदद से मैन्युअल तरीके से खुद निर्देश दें या इस टूल का इस्तेमाल करके. इससे मिलने वाले आउटपुट को dictionary.js www फ़ोल्डर में सेव करें.
ग्लिच पर, आप इस जगह पर एक नई फ़ाइल बना सकते हैं. साथ ही, सेव करने के बाद कन्वर्ज़न के नतीजे में पेस्ट कर सकते हैं:
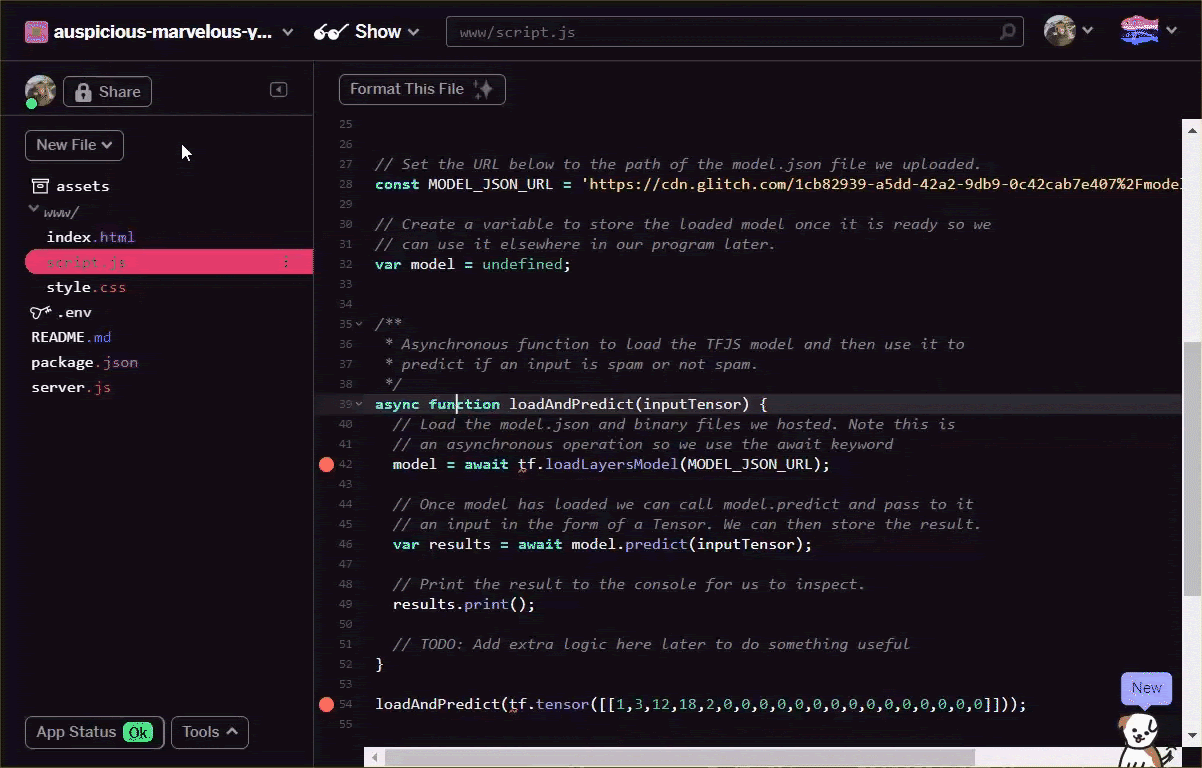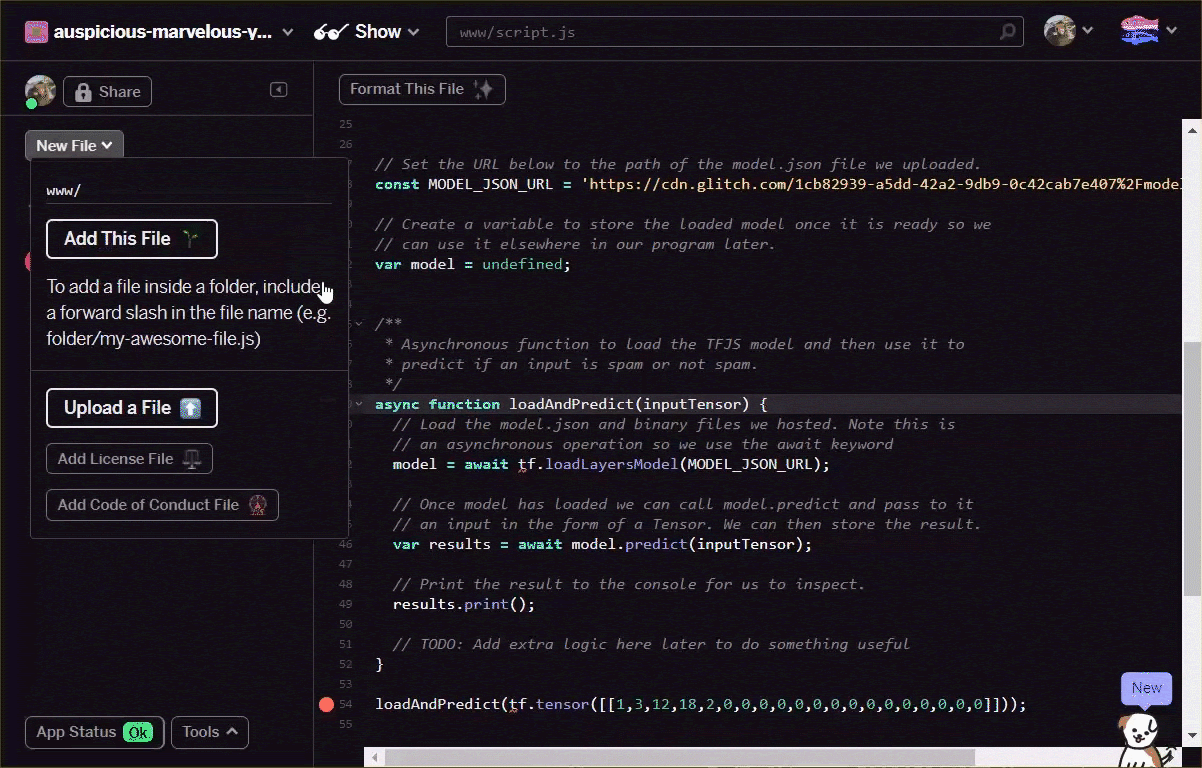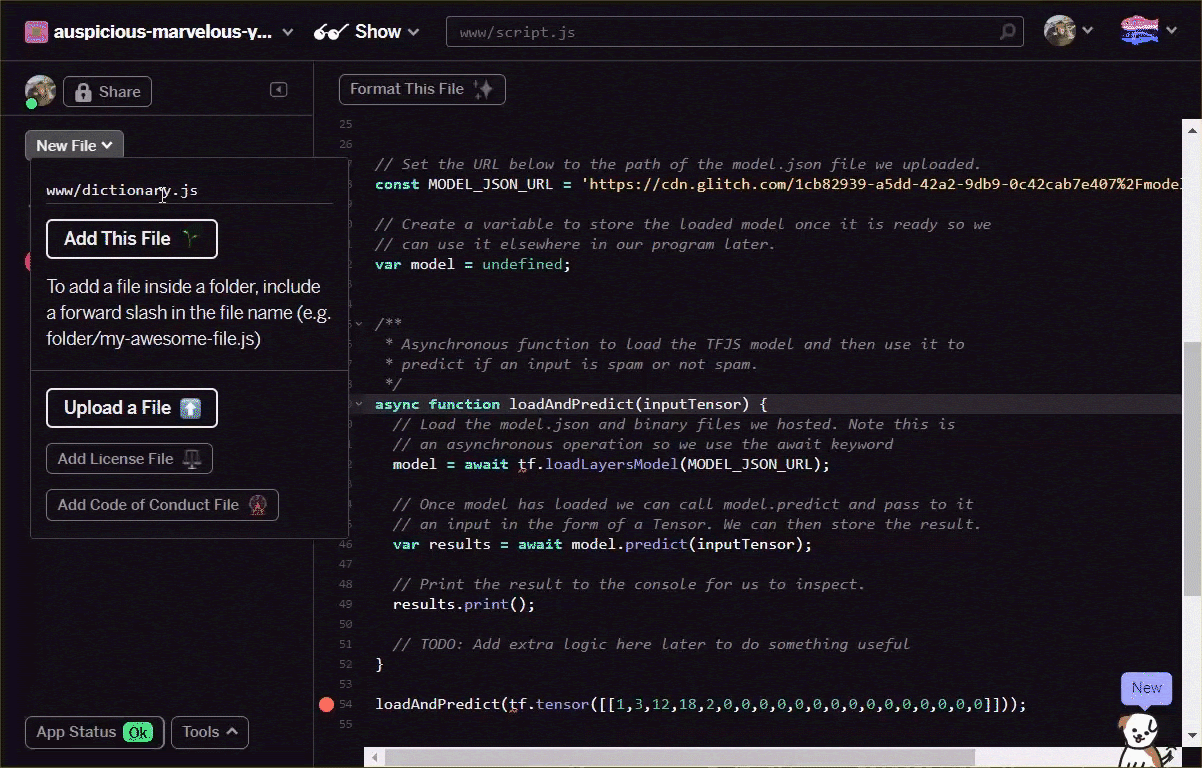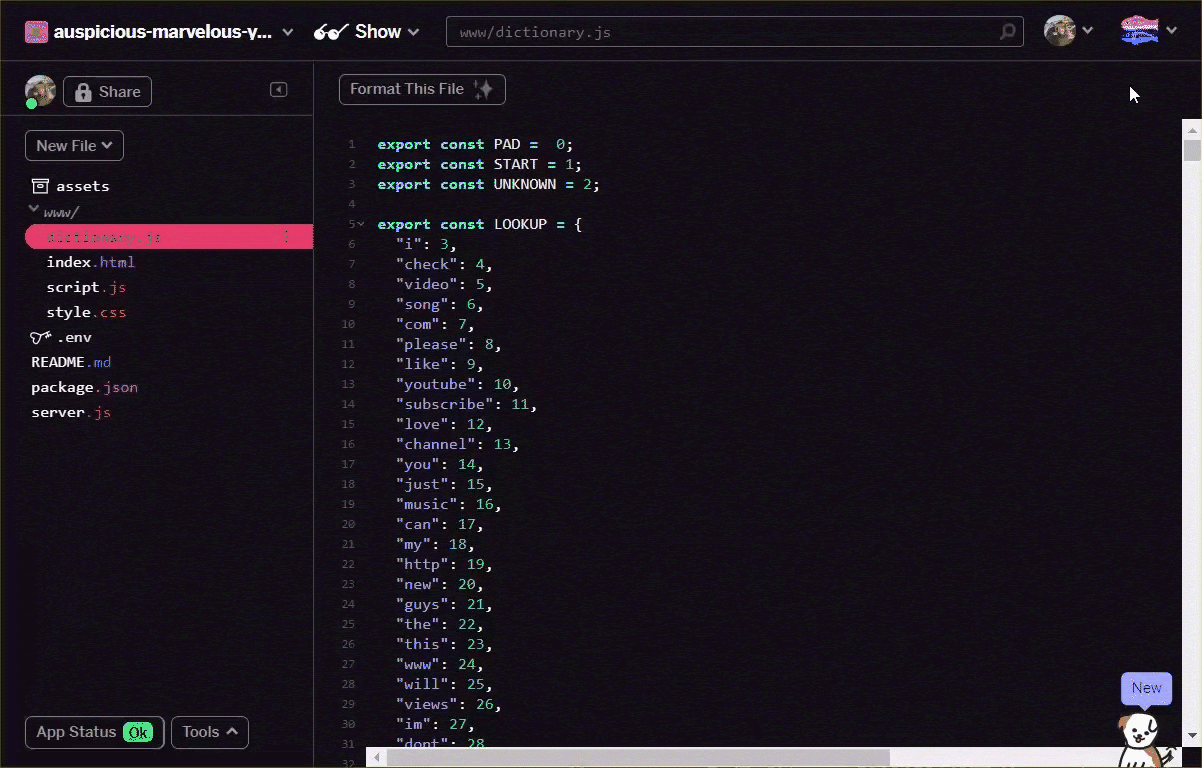
ऊपर बताए गए फ़ॉर्मैट में सेव की गई dictionary.js फ़ाइल होने के बाद, आप अभी लिखे गए dictionary.js मॉड्यूल को इंपोर्ट करने के लिए, नीचे दिए गए कोड को script.js में सबसे ऊपर जोड़ सकते हैं. यहां आप एक अतिरिक्त स्थिर मान भी परिभाषित करते हैं, ताकि आप कोड में बाद में टैप किए जाने वाले हिस्से की संख्या के साथ-साथ tokenize फ़ंक्शन के बारे में भी जान सकें. इस ENCODING_LENGTH फ़ंक्शन का इस्तेमाल करके आप शब्दों की श्रेणी को सही टेंसर में बदल सकते हैं, जिसे मॉडल के इनपुट के तौर पर इस्तेमाल किया जा सके.
हर लाइन का काम करने के तरीके के बारे में ज़्यादा जानकारी के लिए, नीचे दिए गए कोड में दी गई टिप्पणियां देखें:
script.js
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
बढ़िया, अब handleCommentPost() फ़ंक्शन पर वापस जाएं और इसे फ़ंक्शन के इस नए वर्शन से बदलें.
आपने जो वीडियो जोड़ा है उस पर की गई टिप्पणियों का कोड देखें:
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
अगर किसी टिप्पणी को स्पैम के तौर पर मार्क किया जाता है, तो शैली सेट करने के लिए, loadAndPredict() फ़ंक्शन को अपडेट करें.
फ़िलहाल, आप स्टाइल बदलेंगे, लेकिन बाद में आप टिप्पणी को किसी तरह की मॉडरेशन सूची में रोक सकते हैं या उसे भेजने से रोक सकते हैं.
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. रीयल-टाइम अपडेट: Node.js + Websockets
अब आपके पास स्पैम की पहचान करने की सुविधा है. पहेली का आखिरी हिस्सा, रीयल-टाइम बातचीत के लिए कुछ websockets के साथ Node.js का इस्तेमाल करना है. साथ ही, स्पैम होने के बाद, जोड़ी गई किसी भी टिप्पणी को रीयल टाइम में अपडेट करना होता है.
Socket.io
Socket.io, Node.js के साथ websockets का इस्तेमाल करने के सबसे लोकप्रिय तरीकों में से एक है (राइटिंग के समय). आगे बढ़ें और ग्लिच को बताएं कि आप डिपेंडेंसी में से एक के तौर पर socket.io को शामिल करने के लिए, सबसे ऊपर के लेवल की डायरेक्ट्री (www फ़ोल्डर में) में package.json बदलाव करके, Socket.io लाइब्रेरी को बिल्ड में शामिल करें:
package. json
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
वाह! अपडेट होने के बाद, अगली बार socket.io लाइब्रेरी को शामिल करने के लिए www फ़ोल्डर में index.html को अपडेट करें.
index.html फ़ाइल के आखिर के पास, स्क्रिप्ट के लिए एचटीएमएल स्क्रिप्ट टैग इंपोर्ट के ऊपर कोड की यह लाइन रखें:
index.html
<script src="/socket.io/socket.io.js"></script>
अब आपके पास अपनी index.html फ़ाइल में तीन स्क्रिप्ट टैग होने चाहिए:
- TensorFlow.js लाइब्रेरी को पहली बार इंपोर्ट करना
- आपने अभी-अभी जो दूसरा socket.io इंपोर्ट किया है
- और अंत में script.js कोड इंपोर्ट किया जाना चाहिए.
इसके बाद, नोड में socket.io सेट अप करने के लिए server.js में बदलाव करें और सभी कनेक्ट किए गए क्लाइंट को मिले मैसेज को रिले करने के लिए एक आसान बैकएंड बनाएं.
Node.js कोड के काम करने के तरीके के बारे में जानने के लिए, नीचे दी गई कोड टिप्पणियां देखें:
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
वाह! अब आपके पास एक वेब सर्वर है, जो socket.io इवेंट सुन रहा है. किसी क्लाइंट के नई टिप्पणी आने पर, आपके पास comment इवेंट होता है. साथ ही, सर्वर remoteComment इवेंट भेजता है, जिन्हें क्लाइंट की तरफ़ से की जाने वाली टिप्पणी रेंडर करने के लिए सुना जाता है. इसलिए, आखिर में यह ज़रूरी है कि क्लाइंट साइड कोड में socket.io लॉजिक जोड़ा जाए, ताकि इन इवेंट को एमिट किया और मैनेज किया जा सके.
सबसे पहले, नीचे दिए गए कोड को script.js के आखिर में जोड़ें. इससे आप socket.io सर्वर से कनेक्ट हो पाएंगे. साथ ही, रिमोट टिप्पणी वाले इवेंट को सुन सकेंगे/हटा सकते हैं:
script.js
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
आखिर में, अगर कोई टिप्पणी स्पैम नहीं है, तो socket.io इवेंट की शुरुआत करने के लिए, loadAndPredict फ़ंक्शन में कुछ कोड जोड़ें. इससे आप कनेक्ट किए गए दूसरे क्लाइंट को इस नई टिप्पणी से अपडेट कर सकेंगे, क्योंकि इस मैसेज का कॉन्टेंट ऊपर लिखे गए server.js कोड से उन्हें भेज दिया जाएगा.
अपने मौजूदा loadAndPredict फ़ंक्शन को नीचे दिए गए कोड से बदलें. इस कोड से else स्पैम को फ़ाइनल स्पैम जांच में जोड़ा जाता है. अगर यह स्पैम नहीं है, तो टिप्पणी का सारा डेटा भेजने के लिए socket.emit() पर कॉल करें:
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
आपने कमाल कर दिया! अगर आपने सही तरीके से फ़ॉलो किया है, तो अब आप अपने index.html पेज के दो इंस्टेंस खोल पाएंगे.
जो टिप्पणियां स्पैम नहीं हैं उन्हें पोस्ट करने पर, आपको दूसरे क्लाइंट पर उन्हें तुरंत रेंडर होता हुआ दिखेगा. अगर टिप्पणी स्पैम है, तो उसे कभी भी भेजा नहीं जाएगा. इसके बजाय, उसे फ़्रंटएंड पर स्पैम के तौर पर मार्क किया जाएगा, जिससे सिर्फ़ इसी हिस्से को जनरेट किया जाएगा:

12. बधाई हो
बधाई हो, आपने असल में आवेदन करने के लिए वेब ब्राउज़र में TensorFlow.js से मशीन लर्निंग का इस्तेमाल करने के लिए पहला कदम उठाया है - स्पैम स्पैम का पता लगाने के लिए!
इसे आज़माएं, अलग-अलग तरह की टिप्पणियों की जांच करें. ऐसा हो सकता है कि आपको अब भी कुछ चीज़ें देखने को मिलें. आप यह भी देखेंगे कि अगर आप 20 शब्दों से ज़्यादा का कोई वाक्य डालते हैं, तो वह अभी फ़ेल हो जाएगा, क्योंकि मॉडल 20 शब्दों के इनपुट की उम्मीद करता है.
इस मामले में आपको लंबे वाक्यों को 20 शब्दों में बांटना पड़ सकता है. इसके बाद, हर वाक्य के स्पैम होने की संभावना को ध्यान में रखते हुए, यह तय करना चाहिए कि दिखाना है या नहीं. हम इसे आपके लिए एक वैकल्पिक अतिरिक्त काम के रूप में रखेंगे, ताकि आप उसके लिए कई तरीके अपना सकें.
अगले कोडलैब (कोड बनाना सीखना) में, हम आपको दिखाएंगे कि अभी इस मॉडल के लिए अपनी पसंद के मुताबिक टिप्पणी के डेटा का इस्तेमाल करके, इस तरह के मामलों को फिर से कैसे दिखाया जा सकता है. इसके अलावा, हम मॉडल की उम्मीद के मुताबिक बदलाव भी कर सकते हैं, ताकि 20 शब्दों से बड़े वाक्य को हैंडल किया जा सके. इसके बाद, उस मॉडल को TensorFlow.js से एक्सपोर्ट और इस्तेमाल करें.
अगर किसी वजह से आपको समस्याएं आ रही हैं, तो अपने कोड की तुलना यहां दिए गए इस वर्शन से करें और देखें कि आपसे कोई अपडेट छूट गया है या नहीं.
रीकैप
इस कोडलैब में आप:
- जानें कि TensorFlow.js क्या है और प्राकृतिक भाषा प्रोसेसिंग के लिए कौनसे मॉडल मौजूद हैं
- ऐसी काल्पनिक वेबसाइट बनाई गई है जो उदाहरण वाली वेबसाइट के लिए रीयल टाइम टिप्पणियों की अनुमति देती है.
- वेब पेज पर TensorFlow.js के ज़रिए स्पैम टिप्पणी का पता लगाने के लिए, पहले से प्रशिक्षित मशीन लर्निंग मॉडल लोड किया गया.
- लोड किए गए मशीन लर्निंग मॉडल के साथ इस्तेमाल करने के लिए वाक्यों को कोड में बदलने का तरीका जानना और कोड में बदलने की प्रक्रिया को टेंसर में बदलना.
- मशीन लर्निंग मॉडल के आउटपुट के बारे में जानकारी दी गई. इससे यह तय किया जा सकेगा कि आपको टिप्पणी को समीक्षा के लिए रोकना है या नहीं. अगर नहीं, तो रीयल टाइम में सर्वर से जुड़े दूसरे क्लाइंट को भेजने के लिए सर्वर को भेजी जाती है.
आगे क्या करना है?
अब जब आप काम करना शुरू कर चुके हैं, तो आप इस क्रिएटिव लर्निंग मॉडल को अपने इस्तेमाल के लिए कैसे बना सकते हैं?
अपने अनुभव हमारे साथ शेयर करें
आप आज की किसी भी क्रिएटिव गतिविधि को भी आसानी से बढ़ा सकते हैं. हमारा सुझाव है कि आप बॉक्स के बाहर सोचें और हैकिंग करना जारी रखें.
हमें #MadeWithTFJS हैशटैग का इस्तेमाल करके, सोशल मीडिया पर टैग करें. इससे, आपके प्रोजेक्ट को हमारे TensorFlow ब्लॉग में या आने वाले समय के इवेंट में भी दिखाया जा सकेगा. हमें यह देखकर खुशी होगी कि आप क्या बनाते हैं.
ज़्यादा जानकारी के लिए TensorFlow.js कोडलैब (कोड बनाना सीखना) देखें
- स्पैम टिप्पणी के मॉडल को फिर से बनाने का तरीका जानने के लिए, इस सीरीज़ का दूसरा भाग देखें. इससे पता चलता है कि फ़िलहाल यह स्पैम के तौर पर मार्क नहीं किए गए हैं.
- TensorFlow.js मॉडल को बड़े पैमाने पर डिप्लॉय और होस्ट करने के लिए, Firebase होस्टिंग का इस्तेमाल करें.
- TensFlowFlow.js के साथ पहले से बने ऑब्जेक्ट का पता लगाने वाले मॉडल का इस्तेमाल करके, स्मार्ट वेबकैम बनाएं
चेक आउट करने के लिए वेबसाइटें
- TensorFlow.js की आधिकारिक वेबसाइट
- TensorFlow.js के पहले से बने मॉडल
- TensorFlow.js एपीआई
- TensorFlow.js शो & बताएं — प्रेरणा लें और देखें कि अन्य लोगों ने क्या बनाया है.