
1. 시작하기 전에
지난 10년 동안 웹 및 모바일은 점점 더 사회적 및 양방향으로 발전했으며 멀티미디어 지원, 댓글 지원 등이 지원되면서 현재는 수만 명의 사용자가 다소 인기 있는 웹사이트에서도 실시간으로 진행되고 있습니다.
또한 스팸 발송자가 이러한 시스템을 악용하고 다른 사람이 작성한 게시물, 동영상, 게시물과 관련성이 낮은 콘텐츠를 연결하여 가시도를 높일 수 있는 기회도 되었습니다.
차단된 단어 목록과 같은 오래된 스팸 감지 방법은 쉽게 우회할 수 있으며 복잡성이 지속적으로 발전하는 고급 스팸 봇과 일치하지 않습니다. 이제 오늘로 넘어가서 이제 이러한 스팸을 감지하도록 학습된 머신러닝 모델을 사용할 수 있습니다.
과거에는 댓글을 사전 필터링하기 위해 머신러닝 모델을 실행했지만 서버 측에서 TensorFlow.js를 사용할 경우 이제 자바스크립트를 통해 브라우저에서 머신러닝 모델을 클라이언트 측에서 실행할 수 있습니다. 스팸이 백엔드에 도달하기 전에 중지할 수도 있으므로 서버 측 리소스가 많이 소모될 수 있습니다.
아시다시피 머신러닝은 요즘 모든 산업에서 요즘 큰 인기를 끌고 있습니다. 웹 개발자로서 이러한 기능을 사용하기 위해 첫 발걸음을 내딛으려면 어떻게 해야 할까요?
이 Codelab에서는 자연어 처리 (컴퓨터에서 인간의 언어를 이해하는 기술)를 사용해 댓글 스팸의 매우 실질적인 문제를 해결하는 빈 캔버스에서 웹 앱을 빌드하는 방법을 설명합니다. 오늘날 수많은 인기 웹 애플리케이션에서 작업할 때 많은 웹 개발자가 이 문제를 겪으며, 이 Codelab을 통해 이러한 문제를 효율적으로 해결할 수 있습니다.
기본 요건
이 Codelab은 TensorFlow.js로 선행 학습된 모델을 사용해 보고자 하는 머신러닝이 처음인 웹 개발자를 위해 작성되었습니다.
이 실습에서는 HTML5, CSS, 자바스크립트에 익숙하다고 가정합니다.
과정 내용
다음을 수행합니다.
- TensorFlow.js의 정의 및 자연어 처리를 위한 모델 자세히 알아보기
- 실시간 댓글 섹션이 있는 가상의 동영상 블로그용으로 간단한 HTML / CSS / JS 웹페이지를 빌드합니다.
- TensorFlow.js를 사용하면 입력된 문장이 스팸일 가능성이 있는지 예측할 수 있는 선행 학습된 머신러닝 모델을 로드하고 그 경우 사용자가 댓글을 검토 대기 중으로 경고할 수 있습니다.
- 머신러닝 모델에서 사용할 수 있는 방식으로 댓글 문장을 인코딩하여 분류합니다.
- 머신러닝 모델의 출력을 해석하여 댓글을 자동으로 신고할지 결정합니다. 이 가상 UX는 작업 중인 모든 웹사이트에서 재사용할 수 있고 모든 클라이언트 사용 사례에 맞게 조정할 수 있습니다. 일반 블로그, 포럼 또는 Drupal과 같은 CMS의 형태일 수 있습니다.
깔끔한 디자인 어려운 일인가요? 정품이 아닙니다. 이제 해킹해 볼까요?
필요한 항목
- Glitch.com 계정은 팔로우하는 것이 좋으며, 직접 수정 및 실행할 수 있는 웹 제공 환경을 사용해도 됩니다.
2 TensorFlow.js란 무엇인가요?

TensorFlow.js는 자바스크립트로 실행할 수 있는 오픈소스 머신러닝 라이브러리입니다. 또한 Python으로 작성된 원본 TensorFlow 라이브러리를 기반으로 하며, 이 개발자 환경과 자바스크립트 생태계용 API 세트를 다시 만드는 것을 목표로 합니다.
어디에서 사용할 수 있나요?
자바스크립트의 이동성을 감안하여 이제 단일 언어로 작성하고 다음과 같은 모든 플랫폼에서 손쉽게 머신러닝을 수행할 수 있습니다.
- 바닐라 자바스크립트를 사용하는 웹브라우저의 클라이언트 측
- 서버 측은 물론 Raspberry Pi와 같은 IoT 기기까지 Node.js 사용
- Electron을 사용하는 데스크톱 앱
- React Native를 사용하는 네이티브 모바일 앱
또한 TensorFlow.js는 각 환경 내에서 여러 백엔드 (예: CPU 또는 WebGL과 같이 환경 내에서 실행할 수 있는 실제 하드웨어 기반 환경)를 지원합니다. 이 컨텍스트에서 '백엔드'는 서버 측 환경을 의미하는 것이 아닙니다. 실행을 위한 백엔드가 WebGL에서 클라이언트 측이 될 수 있으므로 호환성을 보장하고 빠른 실행 속도를 유지할 수 있습니다. 현재 TensorFlow.js는 다음을 지원합니다.
- 기기의 그래픽 카드 (GPU)에서 WebGL 실행 - GPU 가속으로 대형 모델 (크기 3MB 이상)을 실행하는 가장 빠른 방법입니다.
- CPU에서 웹 어셈블리 (WASM) 실행: 예를 들어 이전 세대 휴대전화를 비롯하여 기기 전반에서 CPU 성능을 개선합니다. 그래픽 프로세서에 콘텐츠를 업로드하는 오버헤드로 인해 WebGL을 사용할 때보다 CPU에서 더 빠르게 실행될 수 있는 소형 모델 (크기가 3MB 미만)에 더 적합합니다.
- CPU 실행 - 대체는 다른 환경에서 사용할 수 없어야 합니다. 세 가지 속도 중 가장 느립니다. 하지만 항상 필요한 정보를 제공해 드립니다.
참고: 실행할 기기를 알고 있는 경우 이 백엔드 중 하나를 강제 적용할 수 있습니다. 아니면 이 백엔드를 자동으로 결정하도록 TensorFlow.js에서 결정해도 됩니다. 지정하지 않습니다.
클라이언트 측 초능력
클라이언트 컴퓨터의 웹브라우저에서 TensorFlow.js를 실행하면 고려해 볼 만한 여러 이점이 있습니다.
개인정보 보호
타사 웹 서버로 데이터를 전송하지 않고도 클라이언트 컴퓨터에서 데이터를 학습시키고 분류할 수 있습니다. 이러한 사례는 GDPR과 같은 현지 법규를 준수해야 하는 경우나 사용자가 자신의 컴퓨터에 보관하고 제3자에게 전송하지 않으려는 데이터를 처리해야 하는 경우가 있습니다.
속도
원격 서버로 데이터를 전송할 필요가 없기 때문에 추론 (데이터 분류 작업)이 더 빨라질 수 있습니다. 또한 사용자가 카메라에 액세스할 수 있게 하면 카메라, 마이크, GPS, 가속도계와 같은 기기의 센서에 직접 액세스할 수도 있습니다.
도달범위 및 규모
클릭 한 번으로 전 세계의 모든 사용자가 내가 보낸 링크를 클릭하여 브라우저에서 웹페이지를 열고 내가 만든 링크를 활용할 수 있습니다. CUDA 드라이버가 포함된 복잡한 서버 측 Linux 설정이 필요 없으며 머신러닝 시스템만 있으면 됩니다.
비용
서버가 없다는 것은 HTML, CSS, JS 및 모델 파일을 호스팅하기 위해 CDN만 있으면 된다는 의미입니다. CDN 비용은 연중무휴로 실행되는 그래픽 카드를 잠재적으로 유지하는 것보다 훨씬 저렴합니다.
서버 측 기능
TensorFlow.js의 Node.js 구현을 활용하면 다음과 같은 기능이 사용 설정됩니다.
완벽한 CUDA 지원
서버 측에서 그래픽 카드 가속의 경우 NVIDIA CUDA 드라이버를 설치하여 TensorFlow가 그래픽 카드와 호환되도록 해야 합니다 (WebGL을 사용하는 브라우저와는 달리 설치 필요 없음). 하지만 CUDA를 완벽하게 지원하므로 그래픽 카드의 하위 수준 기능을 충분히 활용하여 학습과 추론 시간을 단축할 수 있습니다. 성능은 동일한 C++ 백엔드를 공유하므로 Python TensorFlow 구현과 동일합니다.
모델 크기
연구에서 최신 모델의 경우 크기가 매우 큰 모델(기가바이트 포함)을 사용할 수도 있습니다. 브라우저 탭당 메모리 사용량 제한으로 인해 현재 웹브라우저에서 이러한 모델을 실행할 수 없습니다. 이렇게 큰 모델을 실행하려면 모델을 효율적으로 실행하는 데 필요한 하드웨어 사양으로 자체 서버에서 Node.js를 사용하면 됩니다.
IOT
Node.js는 Raspberry Pi와 같이 널리 사용되는 단일 보드 컴퓨터에서 지원됩니다. 따라서 이러한 기기에서도 TensorFlow.js 모델을 실행할 수 있습니다.
속도
Node.js는 자바스크립트로 작성되므로, 적시 컴파일만의 이점을 누릴 수 있습니다. 즉, Node.js를 사용하면 런타임 시 최적화되며, 특히 실행 중인 모든 사전 처리에서 성능이 향상될 수 있습니다. 우수사례에서 이러한 예를 잘 살펴보면 Hugging Face가 Node.js를 사용하여 자연어 처리 모델을 2배 개선한 결과를 살펴볼 수 있습니다.
지금까지 TensorFlow.js를 실행할 수 있는 기본사항과 몇 가지 이점을 배웠으니 이제 유용한 작업을 시작하겠습니다.
3. 선행 학습된 모델
선행 학습된 모델을 사용하는 이유는 무엇인가요?
다음과 같이 원하는 사용 사례에 적합하게 인기 있는 선행 학습된 모델로 시작할 경우 여러 가지 이점이 있습니다.
- 학습 데이터를 직접 수집할 필요가 없습니다. 데이터를 올바른 형식으로 준비하고 머신러닝 시스템이 데이터를 학습할 수 있도록 라벨을 지정하는 데는 많은 시간과 노력이 소요될 수 있습니다.
- 비용과 시간이 절감된 아이디어로 신속하게 프로토타입을 제작할 수 있습니다.
선행 학습된 모델이 필요한 작업을 수행하는 데 충분한 역할을 할 수 있으므로 '바퀴를 다시 사용해야 하는' 부분은 없습니다. 모델이 제공한 지식을 사용해 광고 소재 아이디어를 구현하는 데 집중할 수 있습니다. 가 있는지 진단합니다. - 최신 연구 조사. 선행 학습된 모델이 인기 연구를 기반으로 하는 경우가 많기 때문에 모델의 실제 사용 내역은 물론 실제 모델에 대한 노출도 가능합니다.
- 사용 편의성 및 광범위한 문서. 이러한 모델의 인기도에 따라
- 전이 학습 기능. 일부 선행 학습된 모델은 전이 학습 기능을 제공하는데, 이는 본질적으로 한 머신러닝 작업에서 학습한 정보를 또 다른 유사한 예시로 전달하는 관행입니다. 예를 들어, 고양이를 인식하도록 학습시킨 모델을 새로 학습시킨 경우 개를 인식하도록 재학습할 수 있습니다. 이렇게 하면 빈 캔버스로 시작할 필요가 없으므로 속도가 더 빨라집니다. 모델은 이미 고양이를 인식하도록 학습한 내용을 사용하여 새 것을 인식할 수 있습니다. 개는 눈과 귀도 갖고 있기 때문에 이미 이러한 특징을 찾는 방법을 안다면 고양이도 마찬가지입니다. 훨씬 더 빠른 방식으로 자체 데이터로 모델을 다시 학습시키세요.
선행 학습된 댓글 스팸 감지 모델
이 Codelab에서는 댓글 스팸 감지 요구사항에 평균 단어 임베딩 모델 아키텍처를 사용하지만 학습되지 않은 모델을 사용하려고 하는 경우, 문장이 스팸인지 잘못 추측할 수 있습니다.
모델을 유용하게 만들려면 커스텀 데이터 학습이 필요합니다. 이 경우 스팸이 아닌 댓글의 형태를 학습할 수 있습니다. 이렇게 하면 나중에 항목을 올바르게 분류할 가능성이 커집니다.
다행히 누군가가 이 댓글 스팸 분류 작업의 정확한 모델 아키텍처를 이미 학습했으므로 시작점으로 사용할 수 있습니다. 동일한 모델 아키텍처를 사용하여 선행 학습된 모델을 찾아서 댓글 작성에 사용된 언어를 감지하거나 작성된 텍스트를 기반으로 웹사이트 문의 양식 데이터를 특정 회사팀으로 자동으로 라우팅해야 하는지를 예측하는 등의 작업을 할 수 있습니다. 예: 판매 (제품 문의) 또는 엔지니어링 (기술적 버그 및 의견) 이러한 학습 데이터로 충분한 모델을 사용하면 각 경우에 이러한 텍스트를 분류하여 웹 앱의 기능을 강화하고 조직의 효율성을 높이는 방법을 배울 수 있습니다.
향후 Codelab에서는 Model Maker를 사용하여 선행 학습된 댓글 스팸 모델을 다시 학습시키고 자체 댓글 데이터에서 성능을 개선하는 방법을 학습합니다. 지금은 기존 댓글 스팸 감지 모델을 시작점으로 삼아 초기 웹 앱을 첫 번째 프로토타입으로 작동하게 합니다.
이 선행 학습된 댓글 스팸 감지 모델은 Google 엔지니어가 여러 일반적인 사용 사례에 맞게 사전 제작된 모델을 게시할 수 있는 Google의 머신러닝 모델 저장소인 TF Hub로 게시된 웹사이트에 게시되었습니다. (예: 각 카테고리 내의 특정 사용 사례에 관한 텍스트, 비전, 사운드 등) 이 Codelab의 뒷부분에서 웹 앱에 사용할 지금 모델 파일을 다운로드하세요.
아래와 같이 JS 모델의 다운로드 버튼을 클릭합니다.

4. 코드 설정
필요한 항목
- 최신 웹브라우저
- HTML, CSS, 자바스크립트, Chrome DevTools (콘솔 출력 보기)에 관한 기본 지식
코딩을 진행하겠습니다.
Google에서는 Glitch.com Node.js Express 상용구 템플릿을 만들었으며, 이제 클릭 한 번으로 이 Codelab의 기본 상태로 클론할 수 있습니다.
Glitch에서는 '리믹스' 버튼을 클릭하여 포크한 다음 수정할 수 있는 새로운 파일 세트를 만듭니다.
매우 간단한 스켈레톤은 www 폴더 내에 다음 파일을 제공합니다.
- HTML 페이지 (index.html)
- 스타일시트 (style.css)
- 자바스크립트 코드 (script.js)를 작성할 파일
편의를 위해 HTML 파일에 다음과 같은 TensorFlow.js 라이브러리 가져오기도 추가했습니다.
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
그런 다음 package.json 및 server.js를 통해 간단한 Node Express 서버를 통해 이 www 폴더를 제공합니다.
5 앱 HTML 상용구
시작하기
모든 프로토타입에는 발견 항목을 렌더링할 수 있는 몇 가지 기본 HTML 스캐폴딩이 필요합니다. 지금 설정하세요. 다음을 추가합니다.
- 페이지 제목
- 설명 텍스트
- 동영상 블로그 항목을 나타내는 자리표시자 동영상
- 댓글을 보고 입력할 수 있는 영역
index.html를 열고 기존 코드를 붙여넣기하여 다음 기능을 설정합니다.
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
세분화
위의 주요 HTML 코드 중 일부를 추가하여 추가한 주요 내용을 강조하겠습니다.
- 페이지 제목에
<h1>태그를 추가하고<header>에 모두 포함된 로그인 버튼의<a>태그를 추가했습니다. 그런 다음 기사 제목에<h2>를 추가하고 동영상 설명에<p>태그를 추가했습니다. 특별한 혜택이 없습니다. - 임의의 YouTube 동영상을 삽입하는
iframe태그를 추가했습니다. 현재는 강력한 TensorFlow.js 랩을 자리표시자로 사용하고 있지만 iframe의 URL을 변경하여 원하는 동영상을 여기에 게재할 수도 있습니다. 실제로 프로덕션 웹사이트에서 모든 값은 조회 중인 페이지에 따라 백엔드에서 동적으로 렌더링됩니다. - 마지막으로
sectionID가 'comments'인 ID와 클래스가 있음div새 댓글을 작성하고button를 탭하여 새 댓글 및 정렬되지 않은 댓글 목록을 제출합니다. 각 목록 항목 내span태그에 사용자 이름과 게시 시간이 있고 마지막으로p태그에 댓글 자체가 있습니다. 현재 주석 2개는 자리표시자로 하드 코딩되어 있습니다.
출력을 미리 보면 다음과 같이 표시됩니다.

너무 멋지네요. 이제 스타일을 추가해보겠습니다.
6. 스타일 추가
요소 기본값
먼저 방금 추가한 HTML 요소의 스타일을 추가하여 올바르게 렌더링되도록 합니다.
모든 브라우저 및 OS에서 댓글 시작 지점을 설정하려면 CSS 재설정을 적용하세요. 다음을 사용하여 style.css 콘텐츠를 덮어씁니다.
style.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
그런 다음, 유용한 CSS를 추가하여 사용자 인터페이스를 실현합니다.
위에서 style.css를 추가한 재설정 CSS 코드 아래에 다음을 추가합니다.
style.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
완료되었습니다. 위 두 가지 코드로 스타일을 성공적으로 덮어쓰면 실시간 미리보기가 다음과 같이 표시됩니다.

주요 요소에 대한 마우스 오버 효과를 위한 스위트, 야간 모드, 매력적인 CSS 전환을 기본으로 제공합니다. 잘하고 있어요. 이제 자바스크립트를 사용하여 일부 동작 로직을 통합합니다.
7 자바스크립트: DOM 조작 및 이벤트 핸들러
주요 DOM 요소 참조
먼저, 스타일 지정을 위한 일부 CSS 클래스 상수를 정의하고 코드의 후반부에서 조작하거나 액세스해야 하는 페이지의 주요 부분에 액세스할 수 있는지 확인합니다.
먼저 script.js의 내용을 다음 상수로 바꿉니다.
script.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
댓글 게시 처리
다음으로, POST_COMMENT_BTN에 이벤트 리스너와 처리 함수를 추가하여 작성된 댓글 텍스트를 가져와 처리가 시작되었음을 나타내는 CSS 클래스를 설정합니다. 처리가 이미 진행 중인 경우 버튼을 클릭하지 않았는지 확인합니다.
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
웹페이지를 새로고침하고 댓글을 게시하려고 하면 이제 댓글 버튼과 텍스트가 회색조로 표시됩니다. 콘솔에 다음과 같은 댓글이 출력됩니다.

기본 HTML / CSS / JS 스켈레톤을 확보했으므로 머신러닝 모델로 다시 돌아가 멋진 웹페이지와 통합할 수 있습니다.
8 머신러닝 모델 제공
모델을 로드할 준비가 되었습니다. 이렇게 하려면 먼저 Codelab에서 이전에 다운로드한 모델 파일을 웹사이트에 업로드하여 코드 내에서 호스팅되고 사용할 수 있도록 해야 합니다.
먼저, 아직 다운로드하지 않은 경우 이 Codelab을 시작할 때 모델에 다운로드한 파일의 압축을 풉니다. 안에 다음 파일이 포함된 디렉터리가 표시됩니다.

여기에 어떤 항목이 있나요?
model.json- 학습된 TensorFlow.js 모델을 구성하는 파일 중 하나입니다. 나중에 이 파일을 TensorFlow.js 코드에서 참조하게 됩니다.group1-shard1of1.bin- 이 파일은 TensorFlow.js 모델의 학습된 가중치 (기본적으로 분류 작업을 잘 학습한 다수의 숫자)가 포함된 바이너리 파일로, 다운로드를 위해 서버의 특정 위치에 호스팅되어야 합니다.vocab- 이 이상한 파일은 확장자가 없는 모델 제작자의 말로, 모델이 단어의 사용 방법을 이해할 수 있도록 문장에서 단어를 인코딩하는 방법을 보여줍니다. 이 내용은 다음 섹션에서 자세히 알아봅니다.labels.txt- 모델에서 예측하는 결과 클래스 이름이 간단히 포함됩니다. 이 모델의 경우 텍스트 편집기에서 파일을 열면 'false' 및 'true'가 나열됩니다. 'spam' 또는 'spam'은 예측 출력으로 표시됩니다.
TensorFlow.js 모델 파일 호스팅
먼저 서버에서 생성된 model.json 파일과 *.bin 파일을 웹 페이지를 통해 액세스할 수 있도록 합니다.
Glitch에 파일 업로드
- Glitch 프로젝트의 왼쪽 패널에 있는 assets 폴더를 클릭합니다.
- 애셋 업로드를 클릭하고
group1-shard1of1.bin폴더를 선택하여 이 폴더에 업로드합니다. 이제 업로드되면 다음과 같이 표시됩니다.

- 이제
model.json파일에서도 동일한 작업을 실행합니다. 파일 2개가 다음과 같이 assets 폴더에 있어야 합니다.

- 방금 업로드한
group1-shard1of1.bin파일을 클릭합니다. URL을 해당 위치로 복사할 수 있습니다. 다음과 같이 이 경로를 지금 복사하세요.

- 이제 화면 왼쪽 하단에서 Tools(도구) > Terminal(터미널)을 클릭합니다. 터미널 창이 로드될 때까지 기다립니다. 로드되면 다음을 입력하고 Enter 키를 눌러 디렉터리를
www폴더로 변경합니다.
터미널:
cd www
- 그런 다음
wget를 사용하여 방금 업로드한 파일 2개를 다운로드하도록 아래의 URL을 Glitch에 있는 assets 폴더의 파일에 대해 생성한 URL로 바꿉니다 (각 파일의 맞춤 URL은 애셋 폴더 확인). 또는 저장용량 버킷). 두 URL 사이의 접두어와 사용해야 하는 URL은 아래 URL과 다를 수 있지만 모습은 유사합니다.
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
이제 www 폴더에 업로드된 파일의 사본이 만들어졌지만 지금 이상한 이름으로 다운로드되었습니다.
- 터미널에
ls를 입력하고 Enter 키를 누릅니다. 다음과 같은 화면을 볼 수 있습니다.

mv명령어를 사용하여 파일 이름을 변경할 수 있습니다. 콘솔에 다음을 입력하고 각 줄 뒤에 다음을 <kbd>Enter</kbd> 또는 <kbd>반환</kbd>을 누릅니다.
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- 마지막으로 터미널에
refresh을 입력하고 <kbd>Enter</kbd>를 눌러 Glitch 프로젝트를 새로고침합니다.
terminal:
refresh
- 새로고침하면 이제 사용자 인터페이스의
www폴더에model.json및group1-shard1of1.bin가 표시됩니다.

이제 브라우저에서 실제 코드와 함께 업로드된 모델 파일을 사용할 수 있습니다.
9. 호스팅된 TensorFlow.js 모델 로드 및 사용
이제 업로드된 TensorFlow.js 모델을 일부 데이터로 로드하여 작동하는지 테스트할 수 있습니다.
지금은 아래와 같은 입력 데이터 데이터가 좀 더 알기 쉽게 표시되며 (숫자 배열) 생성 방식은 다음 섹션에서 설명합니다. 지금은 숫자 배열로 확인해 보세요. 이 단계에서는 모델이 오류 없이 답변을 제공하는지 테스트하는 것이 중요합니다.
script.js 파일 끝에 다음 코드를 추가하고 Glitch 애셋 폴더에 파일을 업로드할 때 생성한 model.json 파일의 경로로 MODEL_JSON_URL 문자열 값을 바꿔야 합니다. 사용합니다 Glitch에 있는 assets 폴더에서 파일을 클릭하면 URL을 찾을 수 있습니다.
아래 새 코드의 주석을 읽고 각 줄의 역할을 파악합니다.
script.js
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
프로젝트가 올바르게 설정되어 있으면 이제 로드된 모델을 사용하여 전달된 입력의 결과를 예측할 때 콘솔 창에 다음과 같은 결과가 표시됩니다.

콘솔에 2개의 숫자가 출력됩니다.
- 0.99960
- 0.0003989
이 수치는 다소 어리석어 보일 수 있지만 실제로는 모델에서 입력한 입력의 분류를 확률로 나타냅니다. 하지만 무엇을 나타내나요?
로컬 머신에 다운로드한 모델 파일에서 labels.txt 파일을 열면 다음과 같은 2개의 필드가 있습니다.
- 거짓
- 참
이 경우 모델은99.96011% (입력 객체에 0.9996011로 표시됨) 사용자가 제공한 입력[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] 이었습니다스팸해제 (예: 거짓)
false는 labels.txt의 첫 번째 라벨이며 출력 예측과 관련되는 방식을 알려주는 콘솔 인쇄의 첫 번째 출력으로 표시됩니다.
지금까지 출력을 해석하는 방법을 알아보았습니다. 그렇다면 입력으로 제공된 수많은 숫자가 정확히 무엇인지 어떻게 알 수 있을까요? 모델에서 사용할 수 있도록 문장을 이 형식으로 변환하는 방법은 무엇일까요? 이를 위해 토큰화와 텐서에 관해 알아야 합니다. 꼭 확인해 보세요.
10. 토큰화 및 텐서
토큰화
그 결과 머신러닝 모델은 다수의 숫자를 입력으로 사용할 수 있는 것으로 나타났습니다. 사용해야 하는 이유 기본적으로 머신러닝 모델은 체인으로 연결된 수학 연산이기 때문에 숫자가 아닌 무언가를 전달하면 다루기 어렵습니다. 그렇다면 이제 로드된 모델에 사용할 문장을 문장으로 변환하려면 어떻게 해야 할까요?
정확한 프로세스는 모델과 모델마다 다르지만, 다운로드한 모델 파일에는 vocab,라는 파일이 하나 더 있으며 이는 데이터를 인코딩하는 방법의 핵심입니다.
컴퓨터의 로컬 텍스트 편집기에서 vocab를 열면 다음과 같이 표시됩니다.

기본적으로 이 테이블은 모델이 학습한 의미 있는 단어를 이해할 수 있는 숫자로 변환하는 방법을 보여주는 조회 테이블입니다. <PAD>, <START>, <UNKNOWN> 파일의 상단에는 다음과 같은 특수한 사례가 있습니다.
<PAD>- '패딩'의 약자입니다. 머신러닝 모델의 경우 문장 길이에 관계없이 고정된 수의 입력을 가지고 있는 것으로 나타났습니다. 사용된 모델은 입력에 항상 숫자가 20개라고 예상합니다 (모델의 제작자가 정의했으며 모델을 다시 학습시키면 변경할 수 있음). 따라서 '동영상 좋아요'와 같은 구문이 있는 경우에는 배열에 남아 있는 공백을<PAD>토큰을 나타내는 0으로 채웁니다. 문장이 20단어보다 크면 이 요구사항에 맞게 분할하고 작은 문장 여러 개로 여러 분류해야 합니다.<START>- 항상 문장의 시작을 나타내는 첫 번째 토큰입니다. 이전 단계의 입력 예에서 '1'로 시작하는 숫자 배열이<START>토큰을 나타내는 것을 확인할 수 있습니다.<UNKNOWN>- 추측할 수 있듯이 단어가 이 조회에 존재하지 않는 경우 숫자로 '2'로 표시된<UNKNOWN>토큰을 사용하면 됩니다.
다른 모든 단어는 조회에 존재하고 연결된 특수 번호를 가지고 있기 때문에 이를 사용하거나 존재하지 않는데, 이 경우에는 <UNKNOWN> 토큰 번호를 대신 사용합니다.
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
이제 나머지 단어가 <START> 또는 <PAD> 토큰이고 배열에 숫자가 20개이므로 4단어로 구성된 문장임을 확인할 수 있습니다. 자, 이제 더 이해가 되기 시작했어요.
제가 써 준 문장은 '나는 강아지가 좋아'라는 문장입니다. 위의 스크린샷에서 'I'가 숫자 '3'으로 변환되었음을 알 수 있습니다. 다른 단어를 찾아보면 상응하는 숫자도 찾을 수 있을 것입니다.
텐서
ML 모델이 수치 입력을 수락하기 전에 마지막 장애물이 있습니다. 숫자 배열을 텐서로 알려진 형식으로 변환해야 합니다. 아쉽게도 TensorFlow를 기반으로 하는 TensorFlow의 이름을 기반으로 모델의 이름이 지정되었습니다.
Tensor란 무엇인가요?
TensorFlow.org의 공식 정의에 따르면 다음과 같습니다.
"Tensor는 유형이 동일한 다차원 배열입니다. 모든 텐서는 변경할 수 없습니다. 텐서의 콘텐츠를 업데이트할 수 없으며 새 토큰만 만들면 됩니다."
간단히 말해, 머신러닝 개발자에게 유용한 Tensor 객체에 일부 함수가 내장된 모든 측정기준의 멋진 수학적 이름입니다. 하지만 텐서는 모든 정수 또는 모든 부동 소수점 수와 같은 1가지 유형의 데이터만 저장하며, 텐서를 만든 후에는 텐서의 콘텐츠를 변경할 수 없으므로 숫자의 영구 저장소 상자라고 생각할 수 있습니다.
지금은 이 부분에 관해 너무 걱정하지 않아도 됩니다. 적어도 머신러닝 모델을 작동하는 다차원 저장 메커니즘으로 생각하시기 바랍니다. TensorFlow를 자세히 알아보고 싶다면 이 책과 같은 유용한 책을 심층적으로 살펴보는 것이 좋습니다. 방법을 살펴보겠습니다
정리: 코딩 텐서 및 토큰화
그렇다면 코드에서 이 vocab 파일을 어떻게 사용할 건가요? 좋은 질문입니다.
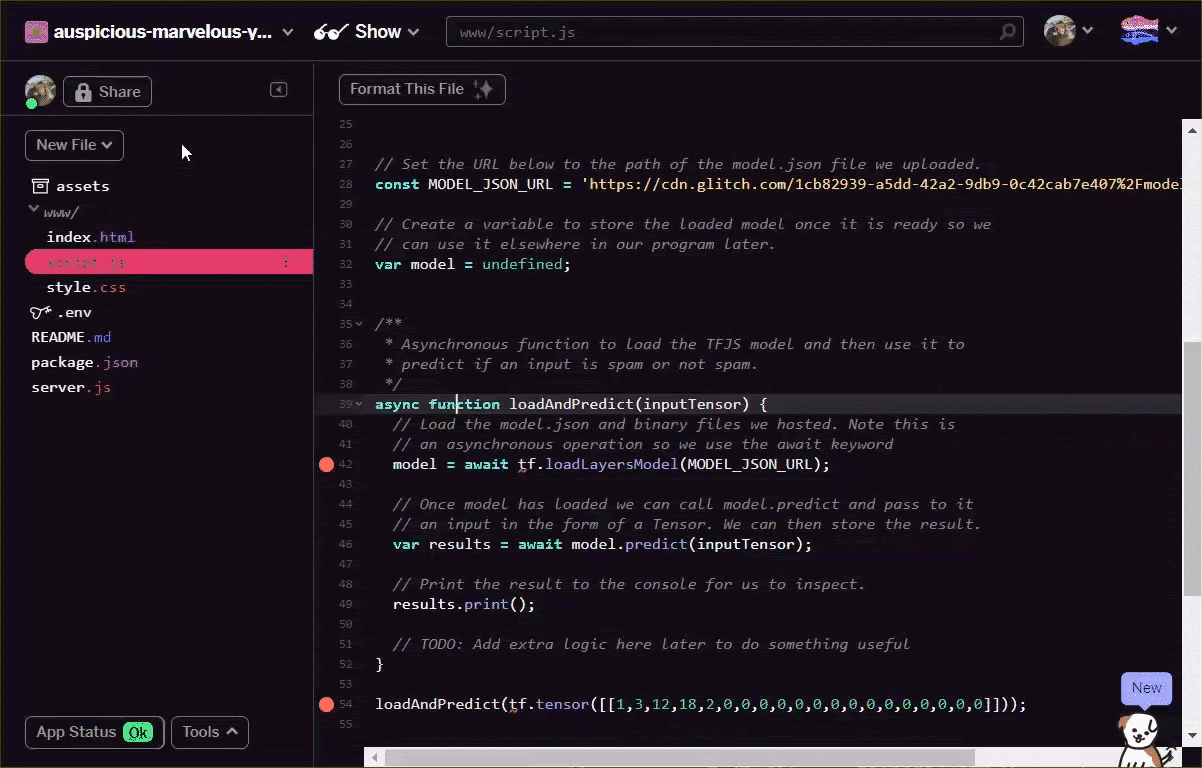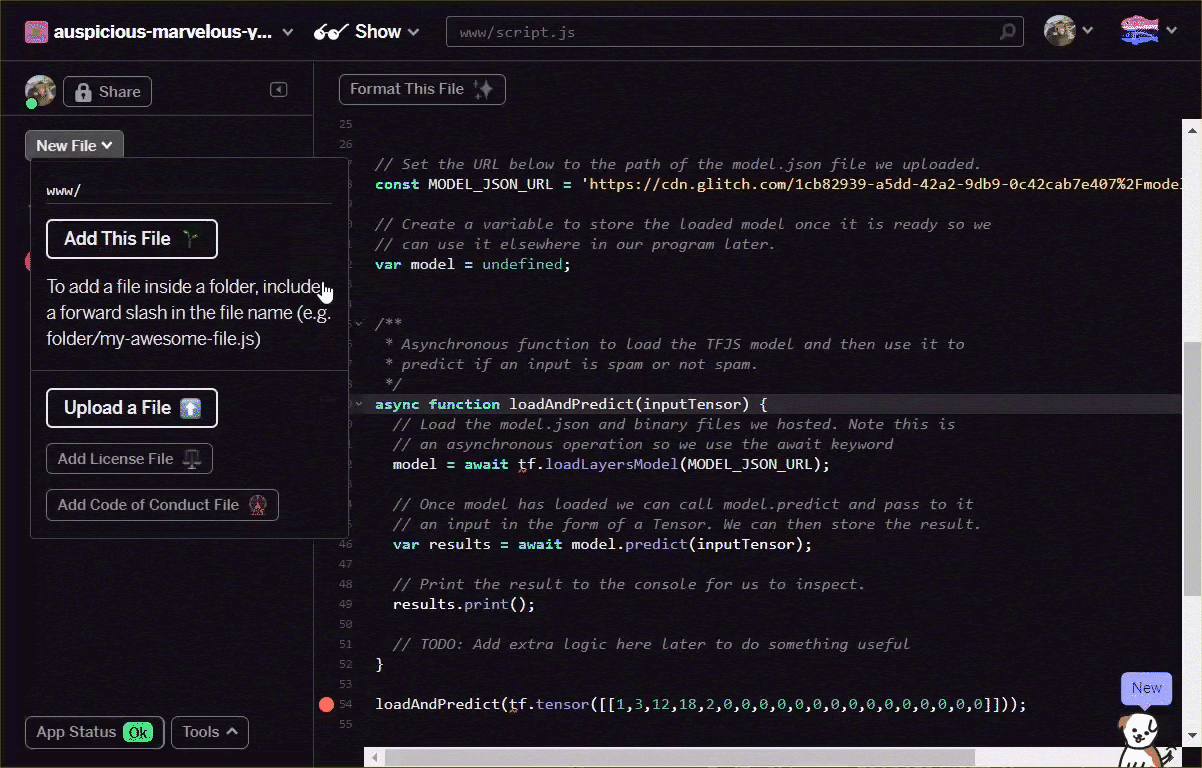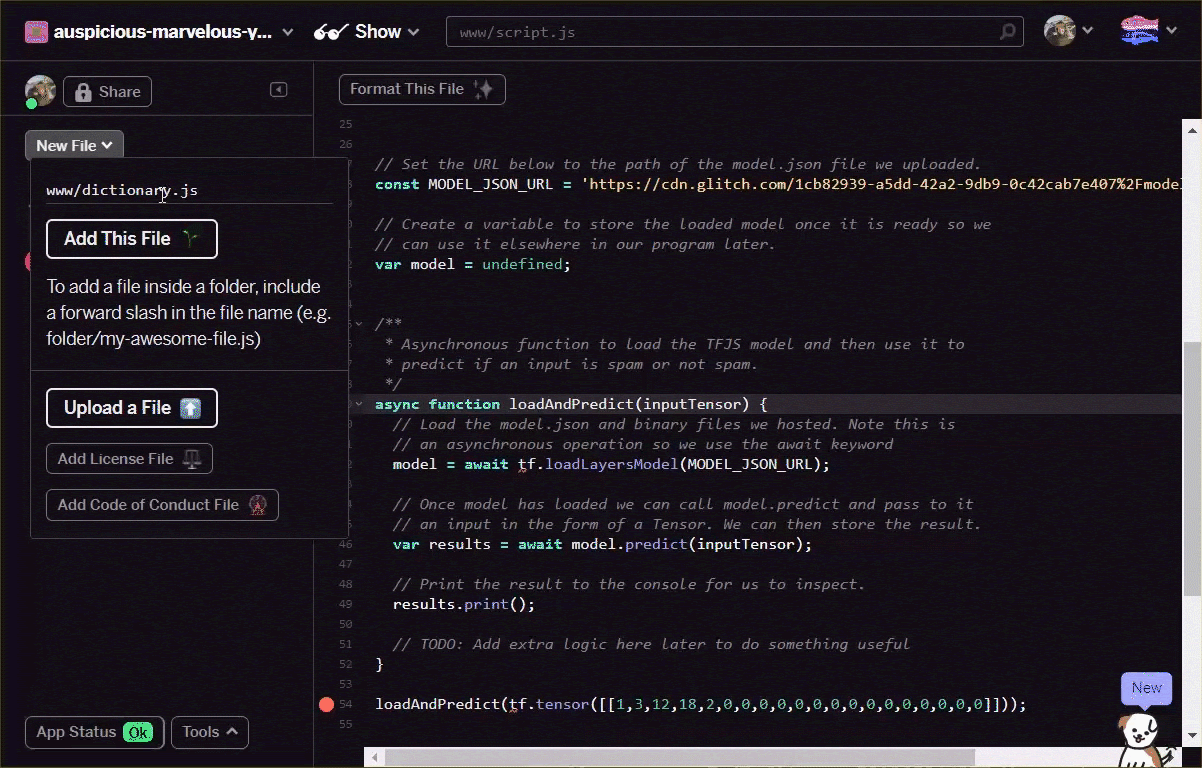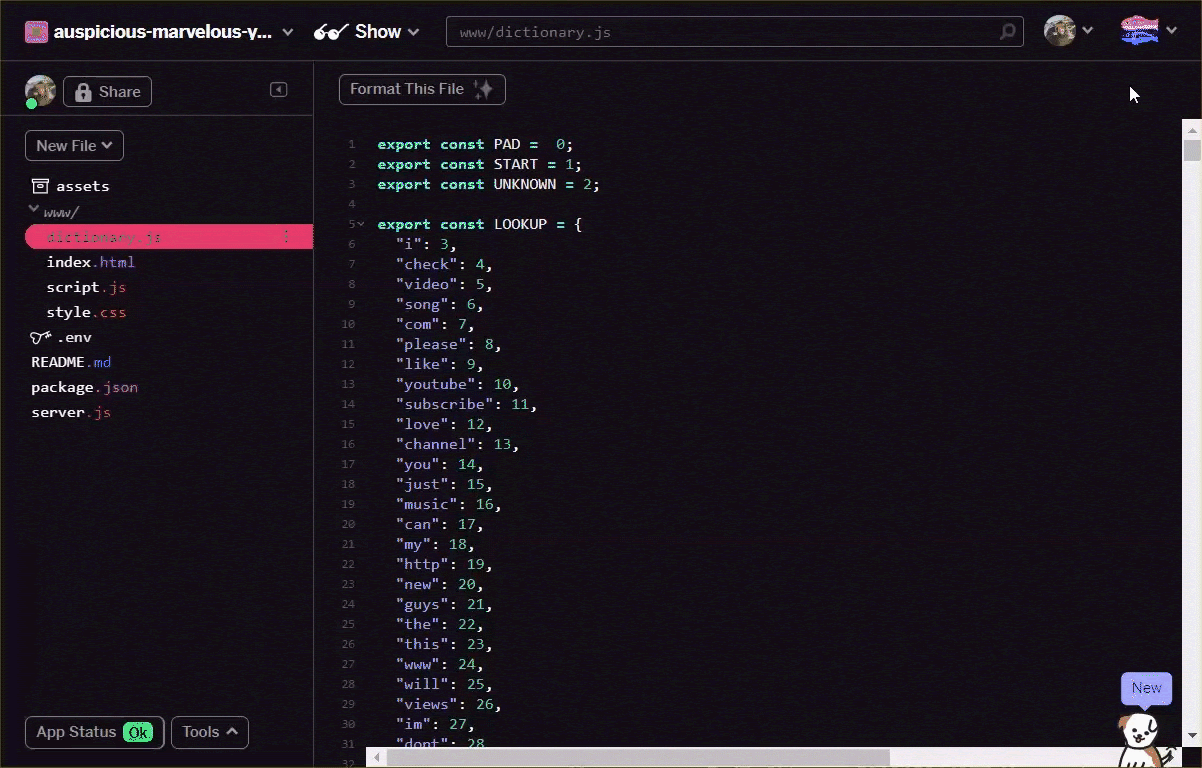
그 자체로 이 파일은 JS 개발자에게 별로 유용하지 않습니다. 단순히 가져와서 사용할 수 있는 자바스크립트 객체인 경우 훨씬 더 효과적입니다. 이 파일의 데이터를 다음과 같은 형식으로 변환하는 것이 얼마나 간단한지 알 수 있습니다.
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
원하는 텍스트 편집기를 사용하여 vocab 파일을 찾기 및 바꾸기 형식의 형식으로 쉽게 변환할 수 있습니다. 그러나 사전 제작 도구를 사용하면 이를 더 쉽게 할 수 있습니다.
이 작업을 미리 실행하고 vocab 파일을 올바른 형식으로 저장하면 이 작업을 수행할 때마다 페이지를 로드할 때마다 파싱하지 않아도 되므로 CPU 리소스가 낭비됩니다. 더 나은 자바스크립트 객체의 속성은 다음과 같습니다.
"객체 속성 이름은 유효한 자바스크립트 문자열이거나 빈 문자열을 포함하여 문자열로 변환할 수 있는 모든 이름입니다. 하지만 유효한 자바스크립트 식별자가 아닌 속성 이름 (예: 공백 또는 하이픈이 있거나 숫자로 시작하는 속성 이름)은 대괄호 표기법을 통해서만 액세스할 수 있습니다."
따라서 대괄호 표기법을 사용하면 이와 같은 간단한 변환을 통해 보다 효율적인 조회 테이블을 만들 수 있습니다.
더 유용한 형식으로 변환하기
텍스트 편집기를 통해 직접 또는 여기에서 이 도구를 사용하여 어휘 파일을 위 형식으로 변환합니다. 결과 출력을 www 폴더 내에 dictionary.js로 저장합니다.
Glitch에서는 이 위치에 새 파일을 만들고 다음과 같이 변환 결과를 붙여넣기만 하면 됩니다.
위에서 설명한 형식으로 저장된 dictionary.js 파일을 만든 후에는 이제 script.js 맨 위에 다음 코드를 추가하여 방금 작성한 dictionary.js 모듈을 가져올 수 있습니다. 여기에서는 여분의 상수 ENCODING_LENGTH를 정의하여 코드의 후반부에서 얼마나 패딩할지 알 수 있습니다. 이때 단어 배열을 다음으로 사용할 수 있는 적합한 텐서로 변환하는 tokenize 함수와 함께 사용합니다. 모델의 입력
각 줄의 기능에 대한 자세한 내용은 아래 코드의 주석을 확인하세요.
script.js
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
이제 handleCommentPost() 함수로 돌아가서 새 버전의 함수로 바꿉니다.
추가된 내용은 다음 코드의 코드를 참조하세요.
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
마지막으로, 댓글이 스팸으로 감지되면 loadAndPredict() 함수를 업데이트하여 스타일을 설정합니다.
지금은 스타일을 변경하기만 하면 됩니다. 그러나 나중에 일종의 검토 대기열에서 댓글을 보류하거나 전송되지 않도록 선택할 수 있습니다.
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
1일 실시간 업데이트: Node.js + Websocket
이제 스팸 감지가 가능한 프런트엔드를 갖추게 되었습니다. 이제 최종 도착 URL은 Node.js와 일부 WebSocket을 함께 사용하여 실시간 통신을 하고 스팸이 아닌 추가된 모든 댓글을 실시간으로 업데이트하는 것입니다.
소켓.io
Socket.io는 작성 시점에 Node.js와 함께 WebSocket을 사용하는 가장 일반적인 방법 중 하나입니다. 최상위 디렉터리의 www 폴더의 상위 폴더에 있는 package.json를 수정하여 socket.io를 종속 항목 중 하나로 포함하도록 Glitch에 빌드에 Socket.io 라이브러리를 포함하도록 지시합니다. :
패키지를 만듭니다. json
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
업데이트가 완료되면 socket.io 라이브러리를 포함하도록 www 폴더 내의 index.html를 업데이트합니다.
script.js의 HTML 스크립트 태그 가져오기 위에 index.html 파일의 끝부분에 다음 코드 줄을 배치하기만 하면 됩니다.
index.html
<script src="/socket.io/socket.io.js"></script>
이제 index.html 파일에 스크립트 태그 3개가 있어야 합니다.
- TensorFlow.js 라이브러리 가져오기
- 방금 추가한 두 번째 socket.io를 가져옵니다.
- 마지막은 script.js 코드를 가져오는 것입니다.
그런 다음 server.js를 수정하여 노드 내에 socket.io를 설정하고 연결된 모든 클라이언트에 수신된 메시지를 릴레이하는 간단한 백엔드를 만듭니다.
Node.js 코드의 역할에 대한 설명은 아래 코드 주석을 참조하세요.
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
이제 socket.io 이벤트를 수신하는 웹 서버가 생겼습니다. 예를 들어 클라이언트에서 새 주석이 오면 comment 이벤트가 있으며, 클라이언트는 클라이언트 측 코드가 원격 주석을 렌더링하기 위해 수신할 remoteComment 이벤트를 내보냅니다. 따라서 마지막으로 socket.io 로직을 클라이언트 측 코드에 추가하여 이러한 이벤트를 방출하고 처리해야 합니다.
먼저 script.js의 끝에 다음 코드를 추가하여 socket.io 서버에 연결하고 수신된 remoteComment 이벤트를 수신 대기 / 처리합니다.
script.js
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
마지막으로, loadAndPredict 함수에 코드를 추가하여 댓글이 스팸이 아닌 경우 socket.io 이벤트를 내보냅니다. 이 메시지를 통해 다른 연결된 클라이언트를 업데이트할 수 있습니다. 이 메시지의 내용이 위에 작성한 server.js 코드를 통해 전달되기 때문입니다.
기존 loadAndPredict 함수를 다음 구문으로 바꿉니다. 이 코드는 최종 스팸 검사에 else 문을 추가합니다. 여기서 스팸이 아닌 경우 socket.emit()을 호출하여 모든 댓글 데이터를 전송할 수 있습니다.
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
잘하셨습니다. 올바르게 팔로우했다면 이제 index.html 페이지의 인스턴스 2개를 열 수 있습니다.
스팸이 아닌 댓글을 게시하면 다른 클라이언트에서 즉시 렌더링됩니다. 댓글이 스팸인 경우 전송되지 않고 프런트엔드에서 스팸으로만 다음과 같이 표시됩니다.

12. 축하합니다
축하합니다. 웹브라우저용 TensorFlow.js를 사용해 머신러닝 애플리케이션을 실제로 사용해 본다면 댓글 스팸 감지를 위한 첫걸음을 내디뎠습니다.
사용해 보고 다양한 댓글로 테스트해 보면 여전히 잘 알려진다는 것을 알 수 있습니다. 또한 문장이 20단어보다 길 경우 모델이 입력 단어 20개를 인식하므로 실패하게 됩니다.
이 경우 장문의 문장을 20개 단어로 나눈 다음 각 하위 문장의 스팸 가능성을 고려하여 표시 여부를 결정해야 할 수 있습니다. 이를 위해 여러 접근 방식을 실험해 볼 수 있는 선택적 추가 작업으로 남겨 두겠습니다.
또한다음 Codelab에서는 이 모델을 다시 학습시키는 방법을 설명합니다. 를 사용합니다. 현재 감지하지 않는 특이 사례의 커스텀 주석 데이터를 사용하거나 20단어보다 큰 문장을 처리할 수 있도록 모델의 입력 기대치를 변경한 다음 TensorFlow.js로 모델을 내보내고 사용합니다.
문제가 있는 경우 코드를 여기에 제공된 전체 버전과 비교하여 누락된 부분이 있는지 확인하세요.
요약
이 Codelab에서는 다음 사항을 다루었습니다.
- TensorFlow.js의 정의와 자연어 처리를 위한 모델 알아보기
- 예시 웹사이트의 실시간 댓글을 허용하는 가상 웹사이트를 만들었습니다.
- 웹페이지의 TensorFlow.js를 통한 댓글 스팸 감지에 적합한 선행 학습된 머신러닝 모델을 로드했습니다.
- 로드된 머신러닝 모델과 함께 사용할 문장을 인코딩하고 텐서 내부에 인코딩을 캡슐화하는 방법을 알아봤습니다.
- 검토를 위해 댓글을 보류할지 결정하는 데 도움이 되도록 머신러닝 모델의 출력을 해석하고, 그렇지 않으면 연결된 다른 클라이언트에게 실시간으로 릴레이하기 위해 서버로 전송했습니다.
다음 단계
작업을 시작할 준비가 되었다면 실제로 사용할 수 있는 실제 사용 사례에 맞게 이 머신러닝 모델 상용구를 확장하려면 어떤 광고 소재 아이디어를 떠올릴 수 있을까요?
결과물 공유
오늘날의 창의적인 작업을 다른 창작 사례에 손쉽게 적용할 수 있습니다. 기존과는 달리 사고를 멈추고 계속 해킹하는 것이 좋습니다.
잊지 말고 소셜 미디어에서#MadeWithTFJS 프로젝트가 Google에서 추천될 수 있는 해시태그TensorFlow 블로그 심지어향후 일정 가 있는지 진단합니다. 여러분의 의견을 기다리겠습니다.
TensorFlow.js Codelab 심층 탐구
- 댓글 스팸 모델을 다시 학습시켜 이 댓글의 2부를 확인하여 현재 스팸으로 감지되지 않는 극단적인 사례를 고려합니다.
- Firebase 호스팅을 사용하여 TensorFlow.js 모델을 대규모로 배포하고 호스팅하세요.
- TensorFlow.js로 사전 제작된 사물 감지 모델을 사용하여 스마트 웹캠 만들기
확인할 웹사이트
- TensorFlow.js 공식 웹사이트
- TensorFlow.js 사전 제작 모델
- TensorFlow.js API
- TensorFlow.js Show & Tell — 영감을 얻고 다른 사람들이 만든 내용을 확인해 보세요.