
1. 事前準備
過去十年來,網路應用程式變得更加社交性和互動性,同時支援數十萬名使用者,即使是在很熱門的網站中,也可能為數十萬使用者提供即時支援,以支援各種多媒體、留言等功能。
而這也代表垃圾內容發布者有機會濫用這類系統,並將較不有意義的內容與其他人所撰寫的文章、影片和訊息聯繫在一起,試圖提高能見度。
而舊式垃圾內容偵測方法 (例如封鎖字詞清單) 可輕鬆略過,而且與進階垃圾郵件機器人並無法全面配合其複雜性。現在,我們很快就能改用新的機器學習模型,現在您訓練完成之後,可以使用經過訓練的機器學習模型來偵測這類垃圾內容。
過去,執行伺服器端的預先篩選註解可能是在伺服器端執行,但有了 TensorFlow.js,您現在可以透過瀏覽器,透過 JavaScript 用戶端執行機器學習模型。您甚至可以在傳送接尾前就停止傳送垃圾內容,這或許會節省成本的伺服器端資源。
大家或許都知道,機器學習在今天幾乎都是熱門的話題,幾乎可以接觸到所有產業,但該如何取得這些功能以身為網頁程式開發人員的第一步?
本程式碼研究室將示範如何使用自然語言處理技術 (也就是透過電腦理解使用者語言,藉此從空白畫布中建構一個能解決垃圾留言的真實問題) 網路應用程式。許多網頁程式開發人員為了處理這個問題而成為許多熱門網路應用程式中的一項問題,因此這個問題就已經存在。這個程式碼研究室能讓您有效解決這些問題。
事前準備
本程式碼研究室是專為剛開始使用機器學習技術的網站開發人員所設計,旨在開始使用 TensorFlow.js 的預先訓練模型。
本研究室假設您已熟悉 HTML5、CSS 和 JavaScript 相關知識。
您將會瞭解的內容
您將學會以下內容:
- 進一步瞭解 TensorFlow.js 以及適用於自然語言處理的模型。
- 為一個虛構的影片網誌打造簡單的 HTML / CSS / JS 網頁,並提供即時留言區。
- 使用 TensorFlow.js 載入預先訓練的機器學習模型,可預測使用者輸入的語句是否為垃圾資訊。
- 以機器學習模型的語句進行編碼,再由機器學習模型使用,以便進行分類。
- 解讀機器學習模型的輸出結果,藉此決定是否要自動檢舉評論。這種假設機制可在任何使用者重複使用的網站中使用,而且可配合任何客戶用途 (例如 Drupal) 進行調整。
超棒。很難做到嗎?答錯了。讓我們開始吧...
軟硬體需求
- 建議透過 Glitch.com 帳戶執行後續作業,或是使用您自行編輯及執行的網路服務環境。
2. 什麼是 TensorFlow.js?

TensorFlow.js 是一種開放原始碼機器學習程式庫,可執行 JavaScript。此程式碼是以以 Python 編寫的原始 TensorFlow 程式庫為基礎,旨在為 JavaScript 生態系統重建這項開發人員體驗和一組 API。
哪些地方可以使用?
現在,有了 JavaScript 的可攜性,您現在可以輕鬆在 1 種語言中撰寫各種語言,並在下列平台上輕鬆執行機器學習:
- 網路瀏覽器中的用戶端使用 vanilla JavaScript
- 使用 Node.js 的伺服器端,甚至 IoT 裝置,例如 Raspberry Pi
- 使用 Electron 的電腦版應用程式
- 使用 React Native 的原生行動應用程式
TensorFlow.js 也支援在這些環境中執行多個後端 (例如,實際執行中的硬體型環境,例如 CPU 或 WebGL)。「後端」在這種情況下,並不代表伺服器端環境,例如用於執行後端的後端可能是 WebGL 中的用戶端),以確保相容性並加快運作速度。TensorFlow.js 目前支援:
- 在裝置上執行 WebGL 執行 (GPU) - 這是使用 GPU 加速功能執行較大型模型 (大小超過 3MB) 的最快方法。
- 在 CPU 上執行 Web 組合 (WASM) - 可改善跨裝置的 CPU 效能,例如使用舊款手機。這種配置更適合大小較小的模型 (大小小於 3MB),因此在使用 WASM 的 CPU 時,實際執行的速度會比包含 WebGL 的執行速度更快,因為內容上傳需經過圖形圖形處理。
- CPU 執行 - 不得使用其他環境。這是前 3 名中最慢的,但隨時都可以。
注意:如果您知道要執行的裝置,就可以選擇強制使用其中一個後端;如果未指定,可以讓 TensorFlow.js 為您決定。
用戶端超能力
在用戶端電腦上的網路瀏覽器上執行 TensorFlow.js,可能會帶來許多好處。
隱私權
您可以對用戶端電腦上的資料進行訓練和分類,而不需將資料傳送至第三方網路伺服器。有時候,您可能必須遵守當地法律,例如 GDPR,或是處理使用者想保留在機器上,且不會傳送給第三方的資料。
速度
由於你不需要將資料傳送到遠端伺服器,因此推論 (將資料分類) 的速度可能更快。更棒的是,如果使用者授權給您,您就可以直接存取裝置的感應器,例如相機、麥克風、GPS 和加速計等等。
觸及率和規模
全世界的使用者只要按一下滑鼠,就能傳送您傳送的連結、在瀏覽器中開啟網頁,並運用您的文章。完全不必使用機器學習系統來設定複雜的伺服器端 Linux,更不需要使用機器學習系統。
費用
沒有任何伺服器,您只需要支付費用即可成為 CDN 代管 HTML、CSS、JS 和模型檔案。CDN 的成本遠比保持 24 小時全天候運作的伺服器 (可能是附加圖形卡) 便宜許多。
伺服器端功能
利用 TensorFlow.js 的 Node.js 實作可以啟用下列功能。
全面支援 CUDA
在伺服器端,想要加速顯示圖形卡,您必須安裝 NVIDIA CUDA 驅動程式,讓 TensorFlow 搭配顯示卡 (與使用 WebGL 的瀏覽器不同,無需安裝)不過,在完全支援 CUDA 的情況下,您可以充分運用顯示卡的低功耗功能,進而縮短訓練和推論時間。效能與 Python TensorFlow 實作程序不相上下,因為兩者都共用相同的 C++ 後端。
模型大小
為了從研究中取得最先進的模型,您可能正在使用規模龐大的模型 (可能是 GB)。由於每個瀏覽器分頁的記憶體用量限制,這類模型目前無法在網路瀏覽器中執行。如要執行這些較大型的模型,您可以在自己的伺服器上使用 Node.js,並依據硬體規格,有效執行這類模型。
IOT
許多熱門單板電腦 (例如 Raspberry Pi) 都支援 Node.js,因此您也可以在這些裝置上執行 TensorFlow.js 模型。
速度
Node.js 是以 JavaScript 編寫而成,因此能從時間編譯中獲益。這表示,您在使用 Node.js 時會遇到一些效能提升的情形,因為它會在執行階段進行最佳化,特別是您執行的任何預先處理作業。這份個案研究顯示絕佳範例,當中顯示 Hugging Face 如何使用 Node.js,讓自然語言處理模型的效能提升 2 倍。
現在你已瞭解 TensorFlow.js 的基本功能、可執行的位置以及一些優點,接著就讓我們開始吧!
3. 預先訓練模型
為什麼要使用預先訓練模型?
如果能依據您的需求使用熱門的預先訓練模型,即可享有許多優勢,例如:
- 不需要自行收集訓練資料。以正確的格式準備資料並加上標籤,讓機器學習系統能夠從中學習,因此可能會耗費大量時間與成本。
- 可快速設計出想法並降低成本和時間。
。 - 使用最先進的研究。預先訓練模型通常是根據熱門研究結果提供,因此可讓您深入瞭解這類模型在現實世界中的表現。
- 易用性和詳盡的說明文件。因為這類模型相當熱門。
- 遷移學習功能。部分預先訓練模型提供遷移學習功能,基本上是將學習學習的資訊從機器學習工作轉移至另一個類似的範例。舉例來說,如果您提供新的訓練資料,原先可以訓練到辨識貓咪的模型,系統可能會重新訓練辨識狗資料。這樣做可以加快執行速度,因為您無法開始使用空白畫布。這個模型可運用所學內容辨識貓咪,然後辨識出新的事物,因此狗的眼睛和耳朵都完全無法理解,因此如果已經知道如何找到這些功能,我們就在一半了。以更迅速的方式針對自己的資料重新訓練模型。
預先訓練的垃圾留言偵測模型
您將使用「平均文字嵌入」模型架構來滿足垃圾留言偵測的需求。不過,如果您嘗試使用未訓練的模型,則不可能被猜測到句子中是否是垃圾資訊。
這個模型必須經過訓練才能瞭解自訂資料,因此它能協助瞭解垃圾留言和非垃圾留言的樣貌。如此一來,日後有必要將分類結果正確分類。
幸好,已經有人針對這個垃圾留言分類工作進行了完整的模型架構訓練,因此你可以將其當做起點做為起點。您或許會發現使用相同模型架構的其他預先訓練模型,能執行各種不同的操作,例如偵測評論的撰寫語言,或根據網站的文字 (例如銷售產品、產品諮詢) 或工程 (技術錯誤或意見回饋),自動預測網站聯絡表單資料是否應轉送到特定公司團隊。取得足夠的訓練資料後,這類模型可以學會在各種情況下將這類文字分類,進而為您的網頁應用程式提供強大功能,並提升貴機構的效率。
在未來的程式碼研究室研究室中,您將瞭解如何使用 Model Maker 重新訓練這個預先訓練的垃圾留言模型,進一步改善您自己的留言資料成效。以目前來說,您將以現有的垃圾留言偵測模型做為起點,讓初始網路應用程式成為第一個原型。
這個預先訓練的垃圾留言偵測模型已發布到名為 TF Hub 的網站。TF Hub 是 Google 維護的機器學習模型存放區,可供機器學習工程師用於發布各種常見用途,例如文字、視覺、聲音等等,以用於上述各個特定用途。您可以先下載模型檔案,以便稍後用於這個程式碼研究室的網路應用程式中。
按一下 JS 模型的下載按鈕,如下所示:

4. 設定程式碼
軟硬體需求
- 新世代網路瀏覽器。
- 對 HTML、CSS、JavaScript 和 Chrome DevTools 的基本概念 (查看主控台輸出內容)。
讓我們開始編寫程式碼
我們已經建立了一個 Glitch.com Node.js Express 公式化模板一個模板,您可以一個開始,只需一個,您只需一個副本即可作為此代碼實驗室的基地。
在 Glitch 中,只要按一下 [重混此項目] 按鈕就能建立檔案,並製作一組新的檔案供您編輯。
這種十分簡潔的骨骼功能,讓我們在 www 資料夾中提供下列檔案:
- HTML 網頁 (index.html)
- 樣式表 (style.css)
- 用於撰寫 JavaScript 程式碼的檔案 (script.js)
為了方便您起見,我們也在 HTML 檔案中加入了 TensorFlow.js 程式庫的匯入功能,如下所示:
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
然後,我們透過 package.json 和 server.js,透過簡單的 Node Express 伺服器提供這個 www 資料夾
5. 應用程式 HTML 公式化
你的起點是什麼?
所有原型均需具備一些基本的 HTML 鷹架,以便在其上呈現發現。立即設定。您要新增:
- 網頁標題
- 部分說明文字
- 代表影片網誌文章的預留位置影片
- 可檢視和輸入意見的區域
開啟「index.html」並貼上現有的程式碼,以設定上述功能:
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
細分
我們來細分部分 HTML 程式碼,藉此突顯你新增的幾項重點。
- 您加入了網頁標題的
<h1>標記,以及<header>中同時包含用於登入按鈕的<a>標記。然後您為了報導標題而加入<h2>,以及為影片說明加上<p>標記。這裡沒有任何特殊內容。 - 你新增了可嵌入任意 YouTube 影片的
iframe標記。您目前已經使用 TensorFlow.js 饒舌風格做為預留位置,但只要變更 iframe 的網址,就可以在這裡放置任何影片。實際上,在實際執行網站上,這些值會根據後端動態顯示,而視使用者瀏覽的頁面而定。 - 最後,您添加了一個
section,其一個 ID 和“評論”一類。它包含可調查的div以及用一個button提交新的評論以及一個未排序的評論列表。您在每個清單項目中的span標記內都有使用者名稱和時間,最後在p標記中加註本身。有 2 個範例註解目前是以硬式編碼方式寫入註解。
如果您現在預覽輸出內容,其外觀應該會如下所示:

看來你真的很糟糕,現在該添加一些風格...
6. 新增樣式
元素預設值
首先,請為您剛新增的 HTML 元素新增樣式,確保其顯示正確。
首先套用 CSS 重設,以便在所有瀏覽器和作業系統中加註註解。使用以下內容覆寫 style.css 內容:
style.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
接下來,請附加一些實用的 CSS,讓使用者介面更生動活潑。
請將以下內容加到您在上方新增的重設 CSS 程式碼的 style.css 結尾:
style.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
漂亮!以上就是您需要的一切。如果您成功用以上 2 段程式碼來覆寫您的樣式,即時預覽畫面現在應如下所示:

甜美、夜間模式以及迷人的 CSS 轉場效果,用來針對關鍵元素使用懸停效果。看起來沒問題。現在,我們使用 JavaScript 整合一些行為邏輯。
7. JavaScript:DOM 操控 &&; 事件處理常式
參照金鑰 DOM 元素
首先,您必須存取網頁中需要操控或存取的幾個重要部分,以及定義一些 CSS 類別常數以設定樣式。
首先,將 script.js 的內容替換為以下常數:
指令碼
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
處理留言
接下來,請為 POST_COMMENT_BTN 新增事件監聽器和處理函式,以便擷取書面留言文字並設定 CSS 類別,以表示作業已開始。請注意,如果系統正在執行處理作業,請確認您已檢查該按鈕。
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
漂亮!當您重新整理網頁並嘗試張貼評論時,現在您會看到 [評論] 按鈕和文字變為灰階;在主控台中,您應該會看到像是下面這樣列印的註解:

現在您有了基本的 HTML / CSS / JS 骨骼,現在只要把注意力轉回機器學習模型,就可以和精美的網頁整合。
8. 提供機器學習模型
您即將準備好載入模型。不過您必須先
首先,請先下載您針對這個程式碼研究室所下載的模型下載的檔案。您應該會看到包含以下檔案的目錄:

你有哪些功能?
model.json- 這些是構成訓練 TensorFlow.js 模型的其中一個檔案。您稍後將在您的 TensorFlow.js 程式碼中參照這個特定檔案。group1-shard1of1.bin- 這個二進位檔案包含 TensorFlow.js 模型的已訓練權重 (基本上是經過大量處理的分類工作量),且必須託管於伺服器上的某個位置進行下載。vocab- 這個無副檔名的奇怪檔案是「模型製作工具」提供的一些內容,目的是說明如何將句子中的文字編碼,讓模型瞭解如何使用這些文字。下一節會進一步說明。labels.txt:這個模型只包含模型預測後產生的類別名稱。開啟這個模型模式後,在文字編輯器中開啟這個檔案時,系統只會列出「false」和「true」字樣,表示「非垃圾郵件」或「垃圾郵件」是預測的輸出結果。
代管 TensorFlow.js 模型檔案
首先請將 model.json 和 *.bin 產生的檔案放在網路伺服器上,以便透過網路存取。
將檔案上傳至 Glitch
- 按一下 Glitch 專案左側面板中的 assets 資料夾。
- 按一下 [上傳素材資源],然後選取
group1-shard1of1.bin即可上傳到這個資料夾。完成上述步驟後:

- 漂亮!現在,對
model.json檔案進行相同操作。您的 assets 資料夾中應有 2 個檔案,如下所示:

- 按一下您剛上傳的
group1-shard1of1.bin檔案。您可以將網址複製到原來的位置。立即複製此路徑,如下所示:

- 現在,按一下畫面左下方的 [Tools] (工具) > [Terminal] (終端機)。等待終端機視窗載入。載入後,請輸入以下內容並按下 Enter 鍵,將目錄變更為
www資料夾:
終端機:
cd www
- 接著,使用
wget下載您剛上傳的 2 個檔案,只要將下方網址替換成您在 Glitch 的 assets 資料夾中為檔案產生的網址即可 (請檢查每個檔案的資產資料夾的素材資源資料夾)。請注意,這兩個網址之間的空間和您需要的網址不同,如下所示:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
你現在已經建立這些檔案到「www」資料夾的副本,但現在已利用奇怪的名稱下載這些檔案。
- 在終端機中輸入「
ls」,然後按下 Enter 鍵。您將看見類似下方的內容:

- 使用
mv指令即可重新命名檔案。請在主控台中輸入以下內容,然後在每一行後面按下 <kbd>Enter</kbd> 或 <kbd>return</lt//kbd>
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- 最後,在終端機上輸入
refresh來重新整理 Glitch 專案,然後按下 <kbd>Enter</kbd>:
terminal:
refresh
- 重新整理後,您應該會在使用者介面的
www資料夾中看到model.json和group1-shard1of1.bin:

漂亮!您現在可以在瀏覽器中使用上傳過的程式碼,搭配一些實際的程式碼。
9. 載入 &&;使用代管的 TensorFlow.js 模型
您現在可以測試利用已載入的部分資料載入已上傳的 TensorFlow.js 模型,看看模型是否能夠正常運作。
目前,下方範例輸入的資料看起來很神秘 (一串數字),這些數字是如何產生,我們會在下節中說明。目前只能以數字陣列的形式查看。在這個階段中,請務必測試模型是否能正確回答問題。
在 script.js 檔案結尾加入下列程式碼,並將 MODEL_JSON_URL 字串值替換成您在上個步驟將檔案上傳到 Glitch 資產資料夾時產生的 model.json 檔案路徑。(別忘了,您可以在 Glitch 的 assets 資料夾中點選該檔案,找出檔案網址)。
請閱讀下列新程式碼的註解,瞭解每一行的作用:
script.js
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
如果專案設定正確,則現在,當您使用載入的模型來預測從輸入專案所接收到的結果後,就會看到在主控台視窗中列印的下列項目,如下所示:

控制台中會顯示 2 組已列印的號碼:
- 0.9996011
- 0.0003989
儘管這項數據看起來很複雜,但這些數字實際上代表了模型分類到你輸入的內容的可能性。但它們代表什麼?
如果您是從本機電腦上下載的已下載模型檔案開啟 labels.txt 檔案,您就會發現該檔案還有 2 個欄位:
- 錯誤
- 是
因此,本模型中的模型指出,您提供的輸入內容 (在結果物件中顯示為 0.9996011) 是 99.96011%,也就是 [1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]「不是」垃圾內容 (也就是「False」)。
請注意,false 是 labels.txt 中的第一個標籤,並以主控台列印中第一個輸出的形式呈現,方便您瞭解輸出預測結果的相關結果。
好的,你現在知道如何解讀輸出內容,但確切的輸入值又是一連串的數字,該如何將句子轉換為這個格式供模型使用?為此,您需要瞭解代碼化與張量的用法。快繼續往下閱讀吧!
10. 代碼化 &張量
代碼化
因此,機器學習模型只能接受許多數字做為輸入內容。原因何在?基本上,這是因為機器學習模型基本上是一連串的數學運算,所以如果你把一個數字當成非數字,就很難處理這種。現在,這個問題會改成如何將句子轉換為數字,以便搭配你載入的模型使用?
確切的流程因模型而異,但是對於此,模型下載檔案中還有一個檔案,名稱為 vocab,,這是編碼資料的關鍵。
立即在裝置的本機文字編輯器中開啟 vocab,即可看到下列資訊:

基本上,這個查詢表格說明如何將有意義的字詞轉換為模型可解讀的數字。檔案頂端還有一些特殊情況,例如 <PAD>、<START> 和 <UNKNOWN>:
<PAD>- 此為「邊框間距」的縮寫。結果顯示,無論句子長短,機器學習模型可能都會提供固定數量的輸入資料。使用的模型預期預期會輸入 20 個數字 (此模型是由模型建立者所定義,如果重新訓練模型的話,可能會變更)。因此,如果您的詞組是「我喜歡影片」,請以 0's 取代陣列中的其餘空格,代表<PAD>符記。如果句子超過 20 個字,您應該將它分割出來,使其符合此需求,並且可以對許多小句進行多個分類。<START>- 這一律是表示句子開頭的第一個符記。您會在上一個範例範例中,看到以「1」開頭的數字數字陣列,這代表的是<START>符記。<UNKNOWN>- 如您所見,如果這個字查詢中沒有字詞,您只要將「<UNKNOWN>」符號表示 (以「2」表示) 這個數字即可。
其他字詞都是在查詢中,而且有一組與之相關的特殊號碼,因此您可以使用該字詞或不存在,在此情況下,請改用 <UNKNOWN> 符記編號。
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
您現在可以看到這句話包含 4 個字,其餘的則為 <START> 或 <PAD> 個符記,且陣列中有 20 個數字。好的,讓它變得更有意義
我對這句話的句子是「我愛狗」從上方的螢幕擷取畫面中,您可以看到「I」;這個數字會轉換為數字「3」,正確。或者,如果您查詢的是其他字詞,也可以找到對應的數字。
張量
機器學習模型需要接受最後一個輸入值。必須將數字陣列轉換成稱為 Tensor 的領域。是的,你猜得,TensorFlow 正是以這個方式命名,也就是「Tensors 的流程」,基本上是透過模型進行。
什麼是 Tensor?
TensorFlow.org 的官方定義包括:
Tensor 是統一的多維度陣列。所有張量都無法變更:您無法更新張量的內容,而只能建立新的張量。」
在此簡單來說,對於任何維度的陣列來說,它只是單純的數學名稱,而且其內建功能也已內建於 Tensor 物件中,有些功能則可做為機器學習開發人員使用。但請注意,Tensors 只會儲存 1 種類型的資料,例如所有整數或所有浮點數字,而且一旦建立後就無法變更 Tensor 的內容,因此您可以將其視為永久性數字的儲存方塊!
目前也不必擔心這類問題。其中最簡單來說,您應該將機器學習模型視為適合與機器學習模型搭配使用的多維度儲存機制,然後深入研究這個類似書的好書。如果您想深入瞭解 Tensor 的使用方式和使用方式,我們強烈建議使用。
完整整合:程式設計張力和代碼化
那麼,如何在程式碼中使用該 vocab 檔案?問得好!
對 JS 開發人員來說,這個檔案本身並不實用。如果這是您可以匯入並使用的 JavaScript 物件,會是更好的選擇。您可以看到轉換檔案的資料格式是否簡單,就像這樣:
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
使用您慣用的文字編輯器,就能輕鬆地將 vocab 檔案轉換為這種格式,並搭配尋找與取代。不過,您也可以使用這項預製工具簡化操作。
只要預先完成這項作業,並以正確的格式儲存 vocab 檔案,即可避免系統在每次網頁載入時皆進行這項轉換和剖析,這會造成 CPU 資源浪費。更棒的是,JavaScript 物件具有下列屬性:
"物件屬性名稱可以是任何有效的 JavaScript 字串,或是可轉換為字串的任何字串,包括空白字串。不過,非有效 JavaScript ID 的屬性名稱 (例如包含空格或連字號,或是以數字開頭的資源名稱) 都只能透過方括號標記法進行存取。
因此,只要採用方括號標記法,您就可以透過這個簡單的轉換指令建立效果良好的查詢表格。
轉換為更實用的格式
使用您的文字編輯器自行將 vocab 檔案轉換為上述格式,或是在這裡使用這項工具。將產生的輸出內容儲存為 www 資料夾中的 dictionary.js。
使用 Glitch 時,您只需在此位置建立新檔案,然後貼上轉換結果即可儲存,如下所示:
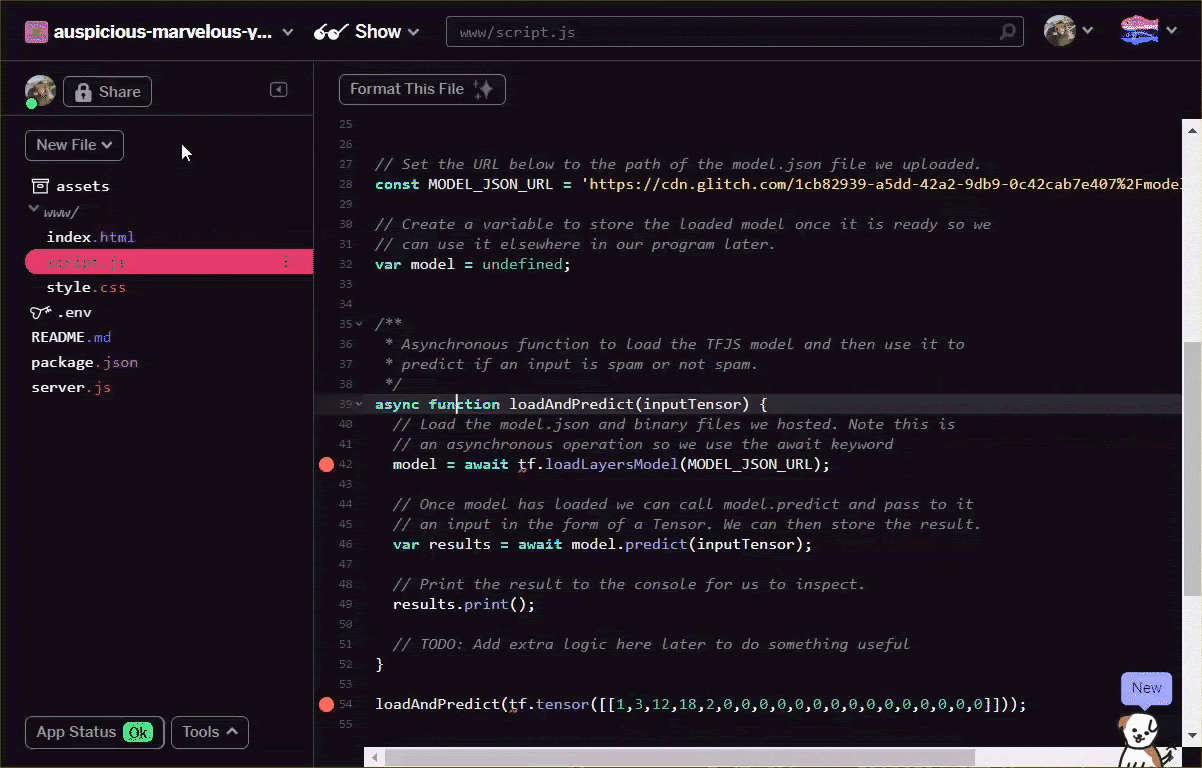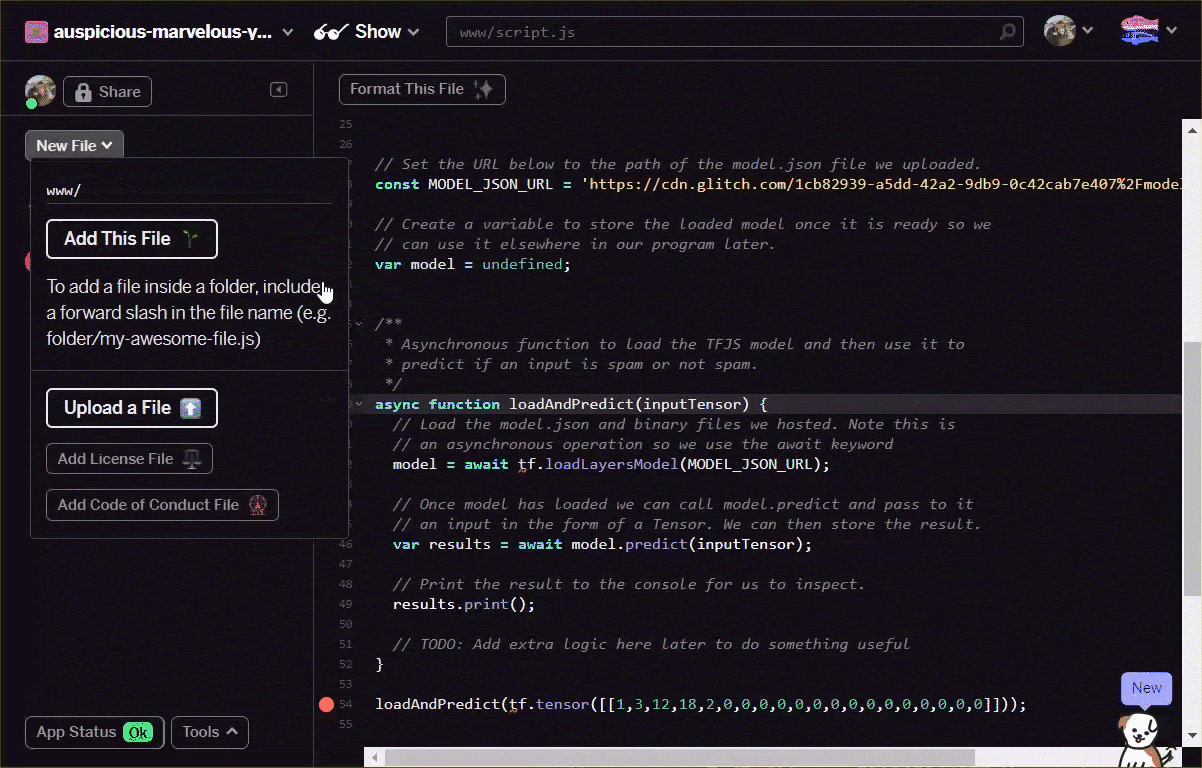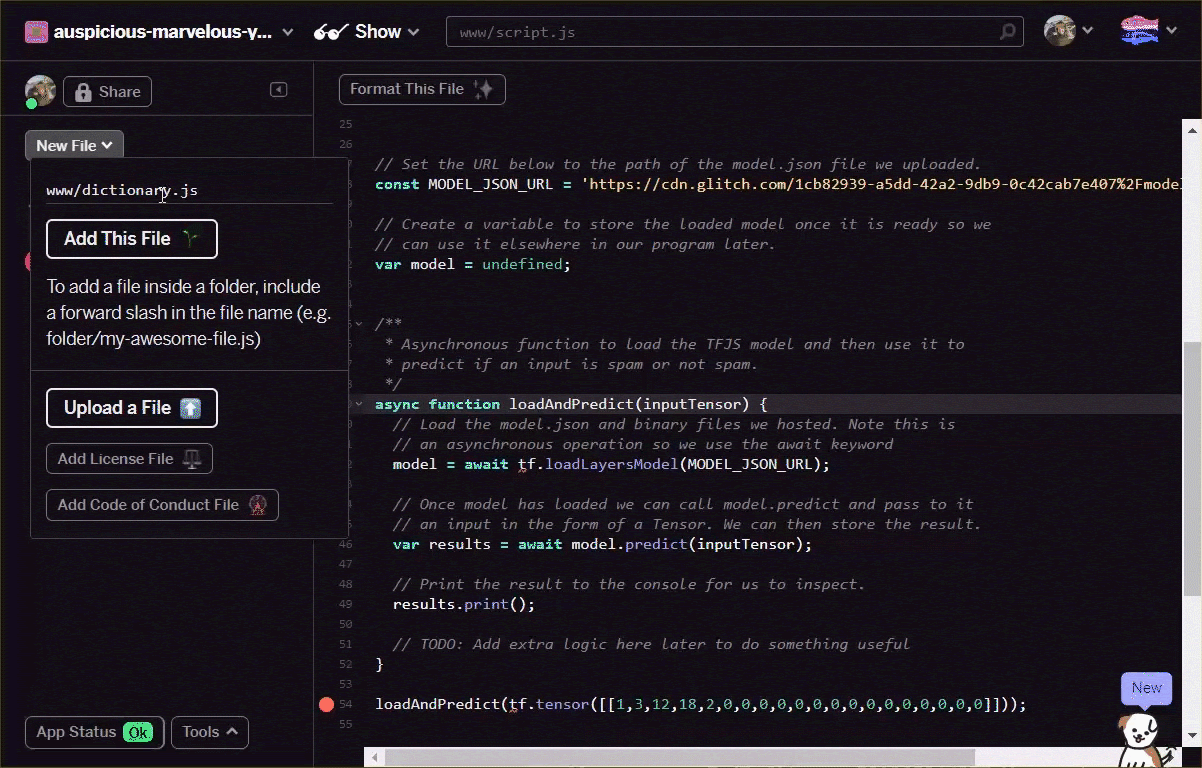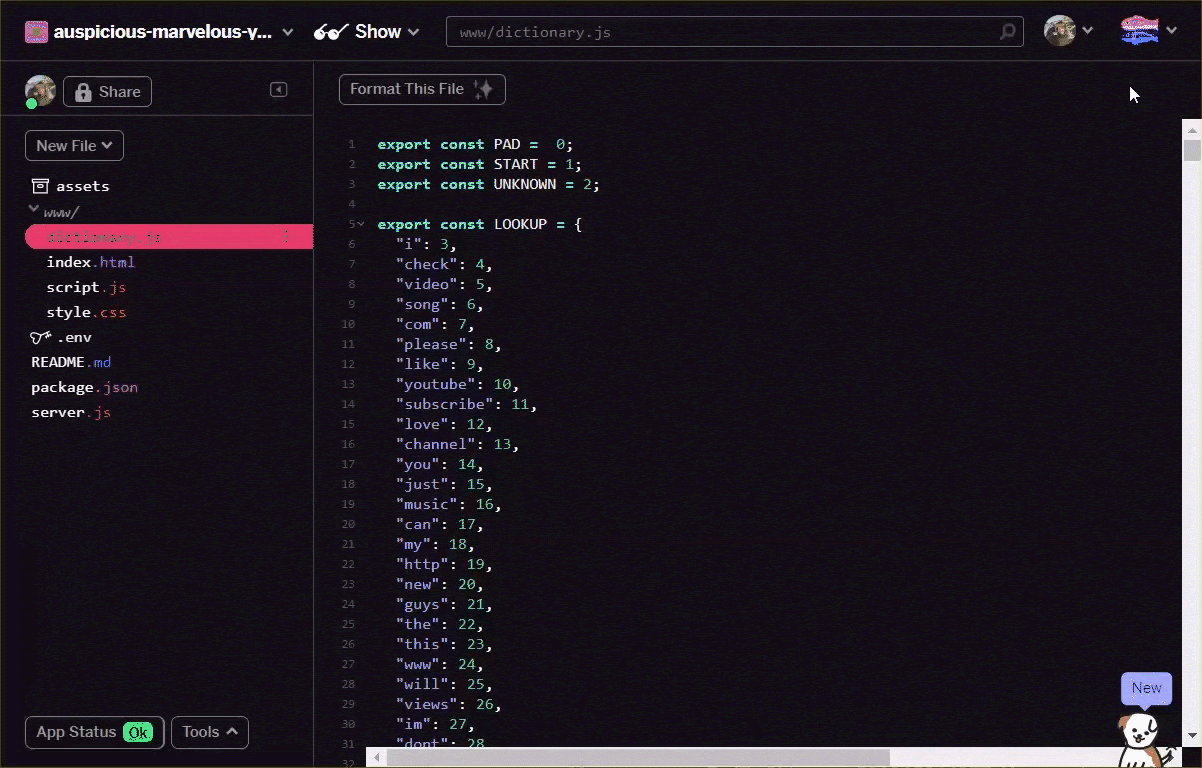
以上述格式儲存 dictionary.js 檔案後,您就可以將下列程式碼附加到 script.js 的最上方,以匯入剛寫入的 dictionary.js 模組。在本文中,您也會定義額外的常數 ENCODING_LENGTH,以便日後在程式碼中著解多少,以及 tokenize 函式將用來將一串字詞轉換為適當的張量,以便用來輸入模型。
請參閱下列程式碼中的註解,進一步瞭解每一行的用途:
script.js
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
太好了,現在請回到 handleCommentPost() 函式,用這個新版函式取代這個函式。
查看程式碼,即可針對您新增的內容發表留言:
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
最後,如果偵測到垃圾留言,請更新 loadAndPredict() 函式來設定樣式。
目前,你只需變更樣式,但你之後可以選擇將留言留待審核特定審核佇列,或是停止張貼留言。
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. 即時更新:Node.js + Websockets
現在您擁有一個能有效偵測垃圾資訊的前端,可運用最終的 Node.js 搭配部分 websocket 進行即時通訊,並即時更新所有不含垃圾留言的留言。
Socket.io (Socket.io)
Socket.io 是最常用的方法 (撰寫時),將 Nodesocket 與 Node.js 搭配使用。請直接在頂層目錄 (位於 www 資料夾的上層資料夾) 中編輯 package.json,將 Socket.io 程式庫納入版本中,讓 Glitch 將 Socket.io 程式庫加入版本中。
package. json
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
漂亮!更新後,請在 www 資料夾中更新 index.html,以納入 socket.io 程式庫。
只要在這一行的 index.html 檔案結尾處,將以下這一行程式碼插入到 Script.js 的 HTML 指令碼代碼上方:
<script src="/socket.io/socket.io.js"></script>
現在您的 index.html 檔案中應該有 3 個指令碼標記:
- 第一次匯入 TensorFlow.js 程式庫
- 您剛新增的 socket.io 匯入項目
- 最後一項動作應該匯入 script.js 程式碼
接著,編輯 server.js 以在節點內設定 socket.io 並建立簡易後端,以轉送傳送至所有連線用戶端的郵件。
請參閱以下程式碼註解,瞭解 Node.js 程式碼執行的作業:
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
漂亮!現在,您的網路伺服器正在監聽 socket.io 事件。換句話說,當用戶端收到新的註解時,您就會收到 comment 事件,而伺服器會發出 remoteComment 事件,而用戶端程式碼會監聽該事件以顯示遠端註解。最後,請在用戶端程式碼中加入 socket.io 邏輯,以發送並處理這些事件。
首先,將下列程式碼加入 script.js 的結尾以連線至 socket.io 伺服器,並且監聽 / 處理收到的 RemoteComment 事件:
script.js
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
最後,在 loadAndPredict 函式中加入一些程式碼,即可在註解不是垃圾郵件時發出 socket.io 事件。這樣一來,您就能透過新的評論更新其他已連結的用戶端,因為這則訊息的內容會透過您在上方撰寫的 server.js 代碼轉發給他們。
只要將以下程式碼取代既有的 loadAndPredict 函式,就能將 else 陳述式新增至最後的垃圾郵件檢查 (如果評論不是垃圾留言),您可以呼叫 socket.emit() 來傳送所有留言資料:
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
做得好!只要正確操作,就能開啟 index.html 專頁的 2 個例項。
當您發布非垃圾評論時,應該很快就會在其他用戶端上發布評論。垃圾留言一律不會傳送,而是會在前端產生內容,而被標示為垃圾留言的標記如下:

12. 恭喜
恭喜!您已透過網路瀏覽器使用 TensorFlow.js 實際執行機器學習應用程式,成功偵測垃圾留言!
現在就試試看吧!透過各種不同的留言功能進行測試,您可能會注意到有些問題,您也會發現,如果輸入的句子長度超過 20 個字,由於目前預期的是 20 個字的輸入內容,因此可能會失敗。
在這種情況下,您可能需要將長句分成 20 個字,然後再將每個子句子的垃圾郵件機率納入考量,據此判斷是否要顯示。我們會將這個工作設為選擇性的額外工作,方便您進行實驗,因為有許多方式可以解決這個問題。
在下一個程式碼研究室中,我們會示範如何針對目前偵測不到的邊緣案例,使用自訂註解來重新訓練這個模型。此外,您甚至可以變更模型的輸入預期值,以便處理超過 20 個字的句子,然後匯出模型並使用 TensorFlow.js。
如果發生問題,請將您的程式碼與這裡的完整版本進行比較,並確認是否有任何遺漏。
重點回顧
在本程式碼研究室中,您:
- 瞭解 TensorFlow.js 是什麼,以及哪些模型可以用於自然語言處理
- 打造一個虛構的網站,以範例網站提供即時評論。
- 已載入預先訓練的機器學習模型,適合透過 TensorFlow.js 在網頁上偵測垃圾留言。
- 瞭解如何將句子編碼成載入的機器學習模型,並將該編碼封裝在 Tensor 中。
- 解讀機器學習模型的輸出結果,決定是否要將留言留待審核。
後續步驟
現在您有了基本的基礎,可以開始運用哪些創意構想,為這個實際使用案例擴展這個機器學習模型,以實際應用?
與我們分享您的成果
您也可以根據目前其他創意應用實例輕鬆調整目前製作的內容。不過,我們鼓勵您花太多心力思考新方法,並克服駭客入侵的問題。
別忘了使用 #MadeWithTFJS 主題標記在社交媒體上標記我們,有機會在 TensorFlow 網誌或未來活動中展示您的專案。我們非常期待看到你的創作內容。
可提供更多的 TensorFlow.js 程式碼研究室
- 請參閱本系列的第 2 單元,瞭解如何重新訓練垃圾留言模型,將目前未偵測為垃圾內容的極端情況視為垃圾內容。
- 使用 Firebase 託管來大規模部署和託管 TensorFlow.js 模型。
- 搭配 TensorFlow.js 使用預製物件偵測模型,打造智慧網路攝影機
結帳網站
- TensorFlow.js 官方網站
- TensorFlow.js 預製模型
- TensorFlow.js API
- TensorFlow.js Show & Tell — 激發創作靈感,看看其他人製作的成果。