Dict হ্যাশ টেবিল
পাইথনের দক্ষ কী/মান হ্যাশ টেবিল গঠনকে "ডিক্ট" বলা হয়। একটি ডিক্টের বিষয়বস্তু কী-এর একটি সিরিজ হিসাবে লেখা যেতে পারে: ধনুর্বন্ধনীর মধ্যে মান জোড়া { }, যেমন dict = {key1:value1, key2:value2, ... }। "খালি ডিক্ট" হল একটি খালি জোড়া কোঁকড়া ধনুর্বন্ধনী {}।
ডিক্টে একটি মান খুঁজতে বা সেট করার জন্য বর্গাকার বন্ধনী ব্যবহার করা হয়, যেমন dict['foo'] কী 'foo'-এর অধীনে মানটি দেখায়। স্ট্রিং, সংখ্যা এবং টিপল কী হিসাবে কাজ করে এবং যেকোন ধরনের মান হতে পারে। অন্যান্য প্রকারগুলি কী হিসাবে সঠিকভাবে কাজ করতে পারে বা নাও করতে পারে (স্ট্রিং এবং টিপল পরিষ্কারভাবে কাজ করে যেহেতু তারা অপরিবর্তনীয়)। ডিক্টে নেই এমন একটি মান খুঁজলে একটি কী-এরর হয় -- কীটি ডিক্টে আছে কিনা তা পরীক্ষা করতে "in" ব্যবহার করুন, অথবা dict.get(কী) ব্যবহার করুন যা মান ফেরত দেয় বা কী উপস্থিত না থাকলে None ( অথবা get(key, not-found) আপনাকে অ-প্রাপ্ত ক্ষেত্রে কোন মানটি ফেরত দিতে হবে তা নির্দিষ্ট করতে দেয়)।
## Can build up a dict by starting with the empty dict {} ## and storing key/value pairs into the dict like this: ## dict[key] = value-for-that-key dict = {} dict['a'] = 'alpha' dict['g'] = 'gamma' dict['o'] = 'omega' print(dict) ## {'a': 'alpha', 'o': 'omega', 'g': 'gamma'} print(dict['a']) ## Simple lookup, returns 'alpha' dict['a'] = 6 ## Put new key/value into dict 'a' in dict ## True ## print(dict['z']) ## Throws KeyError if 'z' in dict: print(dict['z']) ## Avoid KeyError print(dict.get('z')) ## None (instead of KeyError)
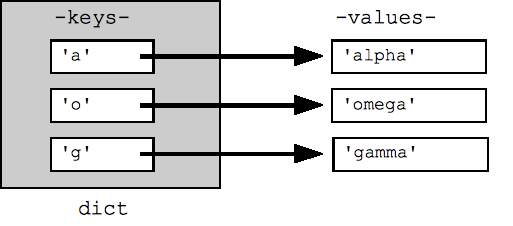
একটি অভিধানে লুপের জন্য একটি ডিফল্টরূপে তার কীগুলির উপর পুনরাবৃত্তি করে। চাবি একটি নির্বিচারে প্রদর্শিত হবে. dict.keys() এবং dict.values() পদ্ধতিগুলি স্পষ্টভাবে কী বা মানগুলির তালিকা প্রদান করে। এছাড়াও একটি আইটেম() রয়েছে যা (কী, মান) টিপলের একটি তালিকা প্রদান করে, যা অভিধানে সমস্ত মূল মান ডেটা পরীক্ষা করার সবচেয়ে কার্যকর উপায়। এই সমস্ত তালিকা sorted() ফাংশনে পাস করা যেতে পারে।
## By default, iterating over a dict iterates over its keys. ## Note that the keys are in a random order. for key in dict: print(key) ## prints a g o ## Exactly the same as above for key in dict.keys(): print(key) ## Get the .keys() list: print(dict.keys()) ## dict_keys(['a', 'o', 'g']) ## Likewise, there's a .values() list of values print(dict.values()) ## dict_values(['alpha', 'omega', 'gamma']) ## Common case -- loop over the keys in sorted order, ## accessing each key/value for key in sorted(dict.keys()): print(key, dict[key]) ## .items() is the dict expressed as (key, value) tuples print(dict.items()) ## dict_items([('a', 'alpha'), ('o', 'omega'), ('g', 'gamma')]) ## This loop syntax accesses the whole dict by looping ## over the .items() tuple list, accessing one (key, value) ## pair on each iteration. for k, v in dict.items(): print(k, '>', v) ## a > alpha o > omega g > gamma
কৌশল নোট: কার্যক্ষমতার দৃষ্টিকোণ থেকে, অভিধানটি আপনার সর্বশ্রেষ্ঠ সরঞ্জামগুলির মধ্যে একটি, এবং আপনার এটি ব্যবহার করা উচিত যেখানে আপনি ডেটা সংগঠিত করার একটি সহজ উপায় হিসাবে পারেন৷ উদাহরণস্বরূপ, আপনি একটি লগ ফাইল পড়তে পারেন যেখানে প্রতিটি লাইন একটি আইপি ঠিকানা দিয়ে শুরু হয় এবং আইপি ঠিকানাটিকে কী হিসাবে ব্যবহার করে একটি ডিক্টে ডেটা সংরক্ষণ করতে পারেন এবং লাইনের তালিকা যেখানে এটি মান হিসাবে প্রদর্শিত হয়। একবার আপনি পুরো ফাইলটি পড়ে ফেললে, আপনি যে কোনও আইপি ঠিকানা দেখতে পারেন এবং তাত্ক্ষণিকভাবে এর লাইনগুলির তালিকা দেখতে পারেন। অভিধানটি বিক্ষিপ্ত ডেটা গ্রহণ করে এবং এটিকে কিছু সুসংগত করে তোলে।
ডিক্ট ফরম্যাটিং
% অপারেটর একটি ডিক্ট থেকে নাম দ্বারা একটি স্ট্রিংয়ে মান প্রতিস্থাপন করতে সুবিধাজনকভাবে কাজ করে:
h = {} h['word'] = 'garfield' h['count'] = 42 s = 'I want %(count)d copies of %(word)s' % h # %d for int, %s for string # 'I want 42 copies of garfield' # You can also use str.format(). s = 'I want {count:d} copies of {word}'.format(h)
দেল
"ডেল" অপারেটর মুছে ফেলার কাজ করে। সহজ ক্ষেত্রে, এটি একটি পরিবর্তনশীলের সংজ্ঞা অপসারণ করতে পারে, যেন সেই পরিবর্তনশীলটিকে সংজ্ঞায়িত করা হয়নি। তালিকার অংশ মুছে ফেলার জন্য এবং অভিধান থেকে এন্ট্রি মুছে ফেলার জন্য তালিকার উপাদান বা স্লাইসেও Del ব্যবহার করা যেতে পারে।
var = 6 del var # var no more! list = ['a', 'b', 'c', 'd'] del list[0] ## Delete first element del list[-2:] ## Delete last two elements print(list) ## ['b'] dict = {'a':1, 'b':2, 'c':3} del dict['b'] ## Delete 'b' entry print(dict) ## {'a':1, 'c':3}
ফাইল
open() ফাংশনটি একটি ফাইল হ্যান্ডেল খোলে এবং রিটার্ন করে যা সাধারণ উপায়ে একটি ফাইল পড়তে বা লিখতে ব্যবহার করা যেতে পারে। কোড f = open('name', 'r') ফাইলটিকে f ভেরিয়েবলে খোলে, অপারেশন পড়ার জন্য প্রস্তুত, এবং শেষ হলে f.close() ব্যবহার করুন। 'r'-এর পরিবর্তে, লেখার জন্য 'w' এবং append-এর জন্য 'a' ব্যবহার করুন। স্ট্যান্ডার্ড ফর-লুপ টেক্সট ফাইলের জন্য কাজ করে, ফাইলের লাইনের মাধ্যমে পুনরাবৃত্তি করে (এটি শুধুমাত্র টেক্সট ফাইলের জন্য কাজ করে, বাইনারি ফাইল নয়)। ফর-লুপ কৌশলটি একটি পাঠ্য ফাইলের সমস্ত লাইন দেখার একটি সহজ এবং কার্যকর উপায়:
# Echo the contents of a text file f = open('foo.txt', 'rt', encoding='utf-8') for line in f: ## iterates over the lines of the file print(line, end='') ## end='' so print does not add an end-of-line char ## since 'line' already includes the end-of-line. f.close()
একবারে একটি লাইন পড়ার চমৎকার গুণ রয়েছে যে সব ফাইলকে একবারে মেমরিতে ফিট করার দরকার নেই -- যদি আপনি 10 গিগাবাইট মেমরি ব্যবহার না করে একটি 10 গিগাবাইট ফাইলের প্রতিটি লাইন দেখতে চান তবে সহজ৷ f.readlines() মেথড পুরো ফাইলটিকে মেমরিতে রিড করে এবং এর রেখার তালিকা হিসেবে এর বিষয়বস্তু ফেরত দেয়। f.read() পদ্ধতিটি পুরো ফাইলটিকে একটি একক স্ট্রিং-এ রিড করে, যা একযোগে পাঠ্যের সাথে মোকাবিলা করার একটি সহজ উপায় হতে পারে, যেমন রেগুলার এক্সপ্রেশনের সাথে আমরা পরে দেখব।
লেখার জন্য, f.write(string) পদ্ধতি হল একটি খোলা আউটপুট ফাইলে ডেটা লেখার সবচেয়ে সহজ উপায়। অথবা আপনি "print(string, file=f)" এর মতো একটি খোলা ফাইলের সাথে "প্রিন্ট" ব্যবহার করতে পারেন।
ফাইল ইউনিকোড
ইউনিকোড এনকোড করা ফাইলগুলি পড়তে এবং লিখতে একটি `'t'` মোড ব্যবহার করুন এবং স্পষ্টভাবে একটি এনকোডিং নির্দিষ্ট করুন:
with open('foo.txt', 'rt', encoding='utf-8') as f: for line in f: # here line is a *unicode* string with open('write_test', encoding='utf-8', mode='wt') as f: f.write('\u20ACunicode\u20AC\n') # €unicode€ # AKA print('\u20ACunicode\u20AC', file=f) ## which auto-adds end='\n'
ব্যায়াম ক্রমবর্ধমান উন্নয়ন
একটি পাইথন প্রোগ্রাম তৈরি করা, পুরো জিনিসটি এক ধাপে লিখবেন না। পরিবর্তে শুধুমাত্র একটি প্রথম মাইলফলক চিহ্নিত করুন, যেমন "ভালভাবে প্রথম ধাপ হল শব্দের তালিকা বের করা।" সেই মাইলফলকে যাওয়ার জন্য কোডটি লিখুন, এবং সেই সময়ে আপনার ডেটা স্ট্রাকচার প্রিন্ট করুন, এবং তারপর আপনি একটি sys.exit(0) করতে পারেন যাতে প্রোগ্রামটি তার অকৃতকার্য অংশগুলিতে এগিয়ে না যায়। মাইলস্টোন কোডটি কাজ করার পরে, আপনি পরবর্তী মাইলস্টোনের জন্য কোডে কাজ করতে পারেন। একটি অবস্থায় আপনার ভেরিয়েবলের প্রিন্টআউট দেখতে সক্ষম হওয়া আপনাকে পরবর্তী অবস্থায় যেতে সেই ভেরিয়েবলগুলিকে কীভাবে রূপান্তর করতে হবে তা ভাবতে সাহায্য করতে পারে। পাইথন এই প্যাটার্নের সাথে খুব দ্রুত, আপনাকে সামান্য পরিবর্তন করতে এবং এটি কীভাবে কাজ করে তা দেখতে প্রোগ্রাম চালানোর অনুমতি দেয়। অল্প পদক্ষেপে আপনার প্রোগ্রামটি তৈরি করতে সেই দ্রুত পরিবর্তনের সুবিধা নিন।
অনুশীলনী: wordcount.py
সমস্ত মৌলিক পাইথন উপাদানগুলিকে একত্রিত করে -- স্ট্রিং, তালিকা, নির্দেশাবলী, টিপলস, ফাইলগুলি -- মৌলিক অনুশীলনের সারাংশ wordcount.py অনুশীলনটি চেষ্টা করুন।