Tabla de hash de Dict
La estructura eficiente de la tabla de hash de clave-valor de Python se denomina “dict”. El contenido de un dict se puede escribir como una serie de pares clave-valor entre llaves { }, p.ej., dict = {key1:value1, key2:value2, ... }. El "dict vacío" es solo un par vacío de llaves {}.
Para buscar o establecer un valor en un diccionario, se usan corchetes, p.ej., dict['foo'] busca el valor bajo la clave "foo". Las cadenas, los números y las tuplas funcionan como claves, y cualquier tipo puede ser un valor. Otros tipos pueden o no funcionar correctamente como claves (las cadenas y tuplas funcionan bien, ya que son inmutables). La búsqueda de un valor que no está en el dict arroja un KeyError. Utiliza "in" para verificar si la clave está en el dict, o usa dict.get(key), que muestra el valor, o None, si la clave no está presente (o get(key, not-found) te permite especificar qué valor mostrar en el caso not-found).
## Can build up a dict by starting with the empty dict {} ## and storing key/value pairs into the dict like this: ## dict[key] = value-for-that-key dict = {} dict['a'] = 'alpha' dict['g'] = 'gamma' dict['o'] = 'omega' print(dict) ## {'a': 'alpha', 'o': 'omega', 'g': 'gamma'} print(dict['a']) ## Simple lookup, returns 'alpha' dict['a'] = 6 ## Put new key/value into dict 'a' in dict ## True ## print(dict['z']) ## Throws KeyError if 'z' in dict: print(dict['z']) ## Avoid KeyError print(dict.get('z')) ## None (instead of KeyError)
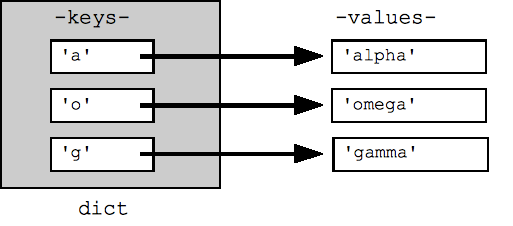
Un bucle for en un diccionario itera sobre sus claves de forma predeterminada. Las claves aparecerán en un orden arbitrario. Los métodos dict.keys() y dict.values() devuelven listas de claves o valores de manera explícita. También hay un elemento items() que muestra una lista de tuplas (clave, valor), que es la forma más eficiente de examinar todos los datos de pares clave-valor en el diccionario. Todas estas listas se pueden pasar a la función order().
## By default, iterating over a dict iterates over its keys. ## Note that the keys are in a random order. for key in dict: print(key) ## prints a g o ## Exactly the same as above for key in dict.keys(): print(key) ## Get the .keys() list: print(dict.keys()) ## dict_keys(['a', 'o', 'g']) ## Likewise, there's a .values() list of values print(dict.values()) ## dict_values(['alpha', 'omega', 'gamma']) ## Common case -- loop over the keys in sorted order, ## accessing each key/value for key in sorted(dict.keys()): print(key, dict[key]) ## .items() is the dict expressed as (key, value) tuples print(dict.items()) ## dict_items([('a', 'alpha'), ('o', 'omega'), ('g', 'gamma')]) ## This loop syntax accesses the whole dict by looping ## over the .items() tuple list, accessing one (key, value) ## pair on each iteration. for k, v in dict.items(): print(k, '>', v) ## a > alpha o > omega g > gamma
Nota sobre la estrategia: Desde el punto de vista del rendimiento, el diccionario es una de tus mejores herramientas y debes usarlo siempre que sea posible para organizar los datos con facilidad. Por ejemplo, puedes leer un archivo de registro en el que cada línea comience con una dirección IP y almacenar los datos en un diccionario con la dirección IP como clave y la lista de líneas donde aparece como el valor. Una vez que hayas leído el archivo completo, podrás buscar cualquier dirección IP y ver la lista de líneas de manera instantánea. El diccionario toma datos dispersos y los convierte en algo coherente.
Formato de dictados
El operador % funciona convenientemente para sustituir los valores de un diccionario en una string por nombre:
h = {} h['word'] = 'garfield' h['count'] = 42 s = 'I want %(count)d copies of %(word)s' % h # %d for int, %s for string # 'I want 42 copies of garfield' # You can also use str.format(). s = 'I want {count:d} copies of {word}'.format(h)
Supr
La "del" realiza eliminaciones. En el caso más simple, puede quitar la definición de una variable, como si no se hubiera definido esa variable. "D" también se puede usar en elementos de lista o porciones para borrar esa parte de la lista y entradas de un diccionario.
var = 6 del var # var no more! list = ['a', 'b', 'c', 'd'] del list[0] ## Delete first element del list[-2:] ## Delete last two elements print(list) ## ['b'] dict = {'a':1, 'b':2, 'c':3} del dict['b'] ## Delete 'b' entry print(dict) ## {'a':1, 'c':3}
Archivos
Se abre la función open() y muestra un controlador de archivo que se puede usar para leer o escribir un archivo de la manera habitual. El código f = open('name', 'r') abre el archivo en la variable f, listo para operaciones de lectura, y usa f.close() cuando finaliza. En lugar de “r”, use “w” para escribir y “a” para adjuntar. El bucle for estándar funciona para archivos de texto, iterando a través de las líneas del archivo (esto funciona solo para archivos de texto, no binarios). La técnica de bucle for es una manera simple y eficiente de ver todas las líneas en un archivo de texto:
# Echo the contents of a text file f = open('foo.txt', 'rt', encoding='utf-8') for line in f: ## iterates over the lines of the file print(line, end='') ## end='' so print does not add an end-of-line char ## since 'line' already includes the end-of-line. f.close()
Leer una línea a la vez tiene la excelente calidad de que no todo el archivo necesita caber en la memoria a la vez, algo útil si quieres ver cada línea de un archivo de 10 gigabytes sin usar 10 gigabytes de memoria. El método f.readlines() lee todo el archivo en la memoria y muestra su contenido como una lista de sus líneas. El método f.read() lee todo el archivo en una sola cadena, que puede ser una manera práctica de tratar todo el texto a la vez, como con las expresiones regulares que veremos más adelante.
Para escribir, el método f.write(string) es la forma más fácil de escribir datos en un archivo abierto de salida. O puedes usar "imprimir" con un archivo abierto, como "print(string, file=f)".
Archivos Unicode
Para leer y escribir archivos codificados con Unicode, usa un modo `'t'` y especifica una codificación de forma explícita:
with open('foo.txt', 'rt', encoding='utf-8') as f: for line in f: # here line is a *unicode* string with open('write_test', encoding='utf-8', mode='wt') as f: f.write('\u20ACunicode\u20AC\n') # €unicode€ # AKA print('\u20ACunicode\u20AC', file=f) ## which auto-adds end='\n'
Desarrollo incremental del ejercicio
Si estás creando un programa de Python, no escribas todo en un solo paso. En cambio, identifica solo el primer hito, p.ej., "el primer paso es extraer la lista de palabras". Escribe el código para llegar a ese hito y simplemente imprime tus estructuras de datos en ese punto. Luego, puedes hacer una sys.exit(0) para que el programa no se ejecute por delante con sus partes no terminadas. Una vez que el código del hito funcione, puedes trabajar en el código para el siguiente hito. Poder ver la impresión de tus variables en un estado puede ayudarte a pensar en cómo necesitas transformar esas variables para llegar al siguiente estado. Python es muy rápido con este patrón, lo que te permite hacer un pequeño cambio y ejecutar el programa para ver cómo funciona. Aprovecha ese tiempo de respuesta rápido para crear tu programa en pequeños pasos.
Ejercicio: wordcount.py
Si combinas todo el material básico de Python (cadenas, listas, diccionarios, tuplas y archivos), prueba el ejercicio de resumen wordcount.py en los Ejercicios básicos.