טבלת גיבוב (hash) הכתבה
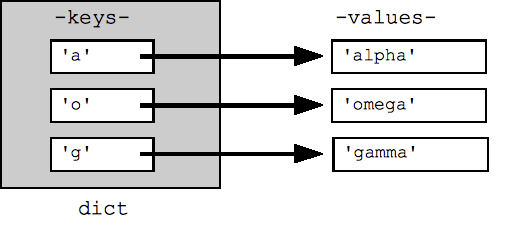
המבנה של טבלת גיבוב (hash) יעיל/ערך ב-Python נקרא 'dict'. אפשר לכתוב את התוכן של הכתבה כסדרה של צמדי מפתח/ערך בתוך סוגריים מסולסלים { }, לדוגמה dict = {key1:value1, key2:value2, ... }. 'ההכתבה ריקה' הוא פשוט זוג ריק של סוגריים מסולסלים {}.
כדי לחפש או להגדיר ערך בהכתבה משתמשים בסוגריים מרובעים, למשל. dict['foo'] מחפש את הערך מתחת למפתח 'foo'. מחרוזות, מספרים וצמדים פועלים כמפתחות, וכל סוג יכול להיות ערך. סוגים אחרים עשויים לפעול בצורה לא תקינה כמפתחות (מחרוזות וצמודים פועלים בצורה נקייה כי הם לא ניתנים לשינוי). חיפוש ערך שלא מופיע בהכתבה גורם לשגיאה KeyError - השתמש ב-"in" כדי לבדוק אם המפתח נמצא בהכתבה, או להשתמש בפונקציה dict.get(key) שמחזירה את הערך. האפשרות 'None' אם המפתח לא קיים (או get(key, not-found) מאפשרת לציין איזה ערך שיוחזר במקרה שלא נמצא).
## Can build up a dict by starting with the empty dict {} ## and storing key/value pairs into the dict like this: ## dict[key] = value-for-that-key dict = {} dict['a'] = 'alpha' dict['g'] = 'gamma' dict['o'] = 'omega' print(dict) ## {'a': 'alpha', 'o': 'omega', 'g': 'gamma'} print(dict['a']) ## Simple lookup, returns 'alpha' dict['a'] = 6 ## Put new key/value into dict 'a' in dict ## True ## print(dict['z']) ## Throws KeyError if 'z' in dict: print(dict['z']) ## Avoid KeyError print(dict.get('z')) ## None (instead of KeyError)
לולאת <for> במילון עוברת על המפתחות שלו כברירת מחדל. המפתחות יופיעו בסדר שרירותי. השיטות dict.keys() ו-dict.values() מחזירות רשימות של המפתחות או הערכים באופן מפורש. יש גם שיטה של items() שמחזירה רשימה של התאמות (מפתח, ערך) – זו הדרך היעילה ביותר לבחון את כל הנתונים של ערכי המפתח במילון. אפשר להעביר את כל הרשימות האלה לפונקציה generateed() .
## By default, iterating over a dict iterates over its keys. ## Note that the keys are in a random order. for key in dict: print(key) ## prints a g o ## Exactly the same as above for key in dict.keys(): print(key) ## Get the .keys() list: print(dict.keys()) ## dict_keys(['a', 'o', 'g']) ## Likewise, there's a .values() list of values print(dict.values()) ## dict_values(['alpha', 'omega', 'gamma']) ## Common case -- loop over the keys in sorted order, ## accessing each key/value for key in sorted(dict.keys()): print(key, dict[key]) ## .items() is the dict expressed as (key, value) tuples print(dict.items()) ## dict_items([('a', 'alpha'), ('o', 'omega'), ('g', 'gamma')]) ## This loop syntax accesses the whole dict by looping ## over the .items() tuple list, accessing one (key, value) ## pair on each iteration. for k, v in dict.items(): print(k, '>', v) ## a > alpha o > omega g > gamma
הערה לגבי אסטרטגיה: מנקודת מבט של ביצועים, המילון הוא אחד מהכלים החשובים ביותר, ומומלץ להשתמש בו כדרך קלה לארגון נתונים. לדוגמה, אתם יכולים לקרוא קובץ יומן שבו כל שורה מתחילה בכתובת IP, ולאחסן את הנתונים לצו לפי כתובת ה-IP כמפתח ואת רשימת השורות שבהן הם מופיעים כערך. לאחר שתקראו את הקובץ כולו, תוכלו לחפש כל כתובת IP ולראות מיד את רשימת השורות שלה. המילון לוקח נתונים מפוזרים והופך אותם לנתונים עקביים.
עיצוב הכתבה
האופרטור % פועל בצורה נוחה כדי להחליף ערכים מהכתבה במחרוזת לפי שם:
h = {} h['word'] = 'garfield' h['count'] = 42 s = 'I want %(count)d copies of %(word)s' % h # %d for int, %s for string # 'I want 42 copies of garfield' # You can also use str.format(). s = 'I want {count:d} copies of {word}'.format(h)
Del
סימן 'דל' מבצע מחיקות. במקרה הפשוט ביותר, אפשר להסיר את ההגדרה של משתנה כאילו הוא לא הוגדר. ניתן להשתמש ב-Dell גם ברכיבי רשימה או בפרוסות כדי למחוק חלק זה ברשימה ולמחוק ערכים ממילון.
var = 6 del var # var no more! list = ['a', 'b', 'c', 'd'] del list[0] ## Delete first element del list[-2:] ## Delete last two elements print(list) ## ['b'] dict = {'a':1, 'b':2, 'c':3} del dict['b'] ## Delete 'b' entry print(dict) ## {'a':1, 'c':3}
קבצים
הפונקציה open() נפתחת ומחזירה מזהה קובץ שבו ניתן להשתמש כדי לקרוא או לכתוב קובץ בדרך הרגילה. הקוד f = open('name', 'r') פותח את הקובץ במשתנה f, מוכן לפעולות קריאה ומשתמש ב-f.close() בסיום הפעולה. במקום 'r', עדיף להשתמש ב-w לכתיבה, ו-'a' להוספה. הסטנדרט של for-loop מתאים לקובצי טקסט, וחוזר על עצמו דרך השורות של הקובץ (האפשרות הזו זמינה רק בקובצי טקסט ולא בקבצים בינאריים). השיטה 'לולאה' היא דרך פשוטה ויעילה להסתכל על כל השורות בקובץ טקסט:
# Echo the contents of a text file f = open('foo.txt', 'rt', encoding='utf-8') for line in f: ## iterates over the lines of the file print(line, end='') ## end='' so print does not add an end-of-line char ## since 'line' already includes the end-of-line. f.close()
קריאה של שורה אחת בכל פעם היא באיכות נחמדה שלא כל הקובץ צריך להיכנס לזיכרון בבת אחת – כדאי להשתמש באפשרות הזו אם רוצים להסתכל על כל שורה בקובץ בגודל 10 ג'יגה בייט בלי להשתמש ב-10 ג'יגה בייט של זיכרון. שיטת f.readlines() מקריאה את הקובץ כולו לזיכרון ומחזירה את התוכן שלו כרשימה של השורות. שיטת f.read() מקריאה את הקובץ כולו במחרוזת אחת, וכך היא יכולה להיות דרך נוחה לטפל בטקסט כולו בבת אחת, כמו למשל בביטויים רגולריים שיופיעו מאוחר יותר.
לכתיבה, השיטה f.write(string) היא הדרך הקלה ביותר לכתוב נתונים בקובץ פלט פתוח. אפשר גם להשתמש ב'הדפסה'. עם קובץ פתוח כמו "print(string, file=f)".
Unicode של קבצים
כדי לקרוא ולכתוב קבצים בקידוד Unicode, צריך להשתמש במצב 't' ולציין קידוד מפורש:
with open('foo.txt', 'rt', encoding='utf-8') as f: for line in f: # here line is a *unicode* string with open('write_test', encoding='utf-8', mode='wt') as f: f.write('\u20ACunicode\u20AC\n') # €unicode€ # AKA print('\u20ACunicode\u20AC', file=f) ## which auto-adds end='\n'
התפתחות מצטברת של פעילות גופנית
במהלך פיתוח תוכנה Python, אל תכתבו את כל הקוד בפעולה אחת. במקום זאת, נסו לזהות רק את ציון הדרך הראשון, למשל: "השלב הראשון הוא להוציא את רשימת המילים". כותבים את הקוד כדי להגיע לאבן הדרך הזו, ומדפיסים את מבני הנתונים באותו רגע, ואז אפשר לבצע sys.exit(0) כדי שהתוכנית לא תעבור לחלקים שלא בוצעו. אחרי שקוד אבן הדרך פועל, אפשר לעבוד על הקוד כדי ליצור את אבן הדרך הבאה. אם אתם יכולים לעיין בתדפיסים של המשתנים במצב אחד, תוכלו לחשוב איך צריך לשנות את המשתנים האלה כדי להגיע למצב הבא. Python מהיר מאוד עם הדפוס הזה, מה שמאפשר לכם לבצע שינוי קטן ולהריץ את התוכנה כדי לראות איך היא פועלת. נצלו את התהליך המהיר הזה כדי לבנות את התוכנית שלכם בשלבים קטנים.
תרגיל: wordcount.py
השילוב של כל חומרי ה-Python הבסיסיים – מחרוזות, רשימות, טריגרים, טפלים וקבצים – זמין לתרגיל הסיכום wordcount.py בתרגילים בסיסיים.