बोलकर दी जाने वाली हैश टेबल
Python के कुशल कुंजी/वैल्यू हैश टेबल स्ट्रक्चर को "शब्दकोश" कहा जाता है. कोडिंग के कॉन्टेंट को ब्रैकेट { } में, कुंजी:वैल्यू पेयर की सीरीज़ के तौर पर लिखा जा सकता है, उदाहरण के लिए dict = {key1:value1, key2:value2, ... }. "खाली डिक्शनरी" कर्ली ब्रेसेस का एक खाली जोड़ा है. {}.
डिक्शनरी में कोई वैल्यू देखने या सेट करने में स्क्वेयर ब्रैकेट का इस्तेमाल किया जाता है, उदाहरण के लिए dict['foo'], 'foo' कुंजी में वैल्यू को खोजता है. स्ट्रिंग, संख्याएं, और ट्यूपल, कुंजियों की तरह काम करते हैं और इनमें से कोई भी टाइप, वैल्यू हो सकता है. ऐसा भी हो सकता है कि दूसरी तरह की कुंजियां सही तरीके से काम न करें, क्योंकि स्ट्रिंग और टपल अच्छी तरह से काम करते हैं, क्योंकि ये आपस में नहीं बदले जा सकते. जो मान डिक्शनरी में नहीं है उसे देखने पर KeyError दिखती है -- "in" का इस्तेमाल करें यह देखने के लिए कि क्या कीबोर्ड में कुंजी मौजूद है या dict.get(key) का इस्तेमाल करें, जो वैल्यू दिखाता है. वहीं, कुंजी के मौजूद न होने पर, कोई वैल्यू नहीं मिलती है. इसके अलावा, get(key, not-found) का इस्तेमाल करके यह तय किया जा सकता है कि 'नहीं मिले मामले' में, कौनसी वैल्यू दी जाए.
## Can build up a dict by starting with the empty dict {} ## and storing key/value pairs into the dict like this: ## dict[key] = value-for-that-key dict = {} dict['a'] = 'alpha' dict['g'] = 'gamma' dict['o'] = 'omega' print(dict) ## {'a': 'alpha', 'o': 'omega', 'g': 'gamma'} print(dict['a']) ## Simple lookup, returns 'alpha' dict['a'] = 6 ## Put new key/value into dict 'a' in dict ## True ## print(dict['z']) ## Throws KeyError if 'z' in dict: print(dict['z']) ## Avoid KeyError print(dict.get('z')) ## None (instead of KeyError)
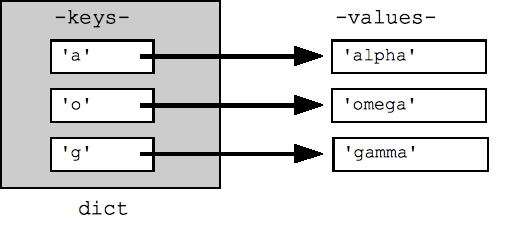
किसी शब्दकोश पर लूप के लिए A, डिफ़ॉल्ट रूप से उसकी कुंजियों पर फिर से दोहराया जाता है. कुंजियां, किसी भी क्रम में दिखेंगी. dict.keys() और dict.values() तरीकों में, कुंजियों या वैल्यू की साफ़ तौर पर सूची दी जाती है. item() की मदद से (कुंजी, वैल्यू) टूपल की सूची मिलती है. यह डिक्शनरी में मौजूद सभी मुख्य वैल्यू के डेटा की जांच करने का सबसे बेहतर तरीका है. ये सभी सूचियां सॉर्ट की गई() फ़ंक्शन में पास की जा सकती हैं.
## By default, iterating over a dict iterates over its keys. ## Note that the keys are in a random order. for key in dict: print(key) ## prints a g o ## Exactly the same as above for key in dict.keys(): print(key) ## Get the .keys() list: print(dict.keys()) ## dict_keys(['a', 'o', 'g']) ## Likewise, there's a .values() list of values print(dict.values()) ## dict_values(['alpha', 'omega', 'gamma']) ## Common case -- loop over the keys in sorted order, ## accessing each key/value for key in sorted(dict.keys()): print(key, dict[key]) ## .items() is the dict expressed as (key, value) tuples print(dict.items()) ## dict_items([('a', 'alpha'), ('o', 'omega'), ('g', 'gamma')]) ## This loop syntax accesses the whole dict by looping ## over the .items() tuple list, accessing one (key, value) ## pair on each iteration. for k, v in dict.items(): print(k, '>', v) ## a > alpha o > omega g > gamma
रणनीति के हिसाब से नोट: परफ़ॉर्मेंस के मामले में डिक्शनरी आपके सबसे अच्छे टूल में से एक है. आपको अपने डेटा को व्यवस्थित तरीके से रखने के लिए, इसका इस्तेमाल करना चाहिए. उदाहरण के लिए, एक लॉग फ़ाइल पढ़ी जा सकती है जिसमें हर लाइन किसी आईपी पते से शुरू होती है. साथ ही, आईपी पते को कुंजी के तौर पर इस्तेमाल करके, डेटा को लिखवाने की सुविधा में स्टोर किया जा सकता है. साथ ही, वैल्यू के तौर पर दिखने वाली लाइनों की सूची दी जा सकती है. पूरी फ़ाइल पढ़ने के बाद, कोई भी आईपी पता खोजें और तुरंत उसकी लाइनों की सूची देखें. डिक्शनरी स्कैटर डेटा को इकट्ठा करके, उसमें मौजूद चीज़ों को आसान बनाती है.
लिखवाने की फ़ॉर्मैटिंग
% ऑपरेटर की मदद से, डिक्शनरी में मौजूद वैल्यू को नाम के हिसाब से किसी स्ट्रिंग में आसानी से बदला जा सकता है:
h = {} h['word'] = 'garfield' h['count'] = 42 s = 'I want %(count)d copies of %(word)s' % h # %d for int, %s for string # 'I want 42 copies of garfield' # You can also use str.format(). s = 'I want {count:d} copies of {word}'.format(h)
Del
"डेल" ऑपरेटर मिटाता है. सबसे आसान मामले में, यह वैरिएबल की परिभाषा को हटा सकता है, जैसे कि उस वैरिएबल को तय नहीं किया गया हो. सूची के उस हिस्से को मिटाने और शब्दकोश से एंट्री मिटाने के लिए, सूची के एलिमेंट या स्लाइस पर भी Del का इस्तेमाल किया जा सकता है.
var = 6 del var # var no more! list = ['a', 'b', 'c', 'd'] del list[0] ## Delete first element del list[-2:] ## Delete last two elements print(list) ## ['b'] dict = {'a':1, 'b':2, 'c':3} del dict['b'] ## Delete 'b' entry print(dict) ## {'a':1, 'c':3}
फ़ाइलें
Open() फ़ंक्शन एक बार खुल जाता है और एक फ़ाइल हैंडल दिखाता है, जिसे किसी फ़ाइल को सामान्य तरीके से पढ़ने या लिखने के लिए इस्तेमाल किया जा सकता है. कोड f = open('name', 'r') फ़ाइल को वैरिएबल f में खोलता है, जो पढ़ने के लिए तैयार है, और पूरा हो जाने पर f.close() का इस्तेमाल करें. 'r' के बजाय, 'w' का इस्तेमाल करें लिखने के लिए और 'a' जोड़ने के लिए. लूप के लिए मानक सुविधा, टेक्स्ट फ़ाइलों के लिए काम करती है. यह फ़ाइल की लाइनों के ज़रिए बार-बार होती है (यह सुविधा सिर्फ़ टेक्स्ट फ़ाइलों के लिए काम करती है, बाइनरी फ़ाइलों के लिए नहीं). 'लूप के लिए' तकनीक, टेक्स्ट फ़ाइल में सभी लाइनों को देखने का आसान और असरदार तरीका है:
# Echo the contents of a text file f = open('foo.txt', 'rt', encoding='utf-8') for line in f: ## iterates over the lines of the file print(line, end='') ## end='' so print does not add an end-of-line char ## since 'line' already includes the end-of-line. f.close()
एक समय में एक पंक्ति पढ़ने की गुणवत्ता अच्छी है, जो सभी फ़ाइलों को एक समय में मेमोरी में फ़िट करने की आवश्यकता नहीं होती -- यह तब आसान है जब आप 10 गीगाबाइट्स मेमोरी का उपयोग किए बिना किसी 10 गीगाबाइट फ़ाइल की प्रत्येक पंक्ति को देखना चाहें. f.readlines() तरीका, पूरी फ़ाइल को मेमोरी में पढ़ता है और उसके कॉन्टेंट को इसकी लाइनों की सूची के तौर पर दिखाता है. f.read() वाला तरीका, पूरी फ़ाइल को एक स्ट्रिंग में पढ़ता है. इससे, टेक्स्ट को एक ही बार में मैनेज किया जा सकता है. रेगुलर एक्सप्रेशन का इस्तेमाल बाद में किया जाएगा.
लिखने के लिए, f.write(string) तरीका किसी खुली आउटपुट फ़ाइल पर डेटा लिखने का सबसे आसान तरीका है. या "प्रिंट करें" का इस्तेमाल करें "print(string, file=f)" जैसी खुली फ़ाइल होनी चाहिए.
फ़ाइलें यूनिकोड
यूनिकोड में बदली गई फ़ाइलों को पढ़ने और लिखने के लिए, `'t'` मोड का इस्तेमाल करें. साथ ही, कोड में बदलने के तरीके के बारे में साफ़ तौर पर बताएं:
with open('foo.txt', 'rt', encoding='utf-8') as f: for line in f: # here line is a *unicode* string with open('write_test', encoding='utf-8', mode='wt') as f: f.write('\u20ACunicode\u20AC\n') # €unicode€ # AKA print('\u20ACunicode\u20AC', file=f) ## which auto-adds end='\n'
एक्सरसाइज़ इंक्रीमेंटल डेवलपमेंट
Python प्रोग्राम बनाने के लिए, हर चीज़ एक बार में न लिखें. इसके बजाय, कोई पहली उपलब्धि बताएं, जैसे कि "सबसे पहला कदम है शब्दों की सूची निकालना." उस माइलस्टोन तक पहुंचने के लिए कोड लिखें और उस समय बस अपने डेटा स्ट्रक्चर को प्रिंट करें. इसके बाद, sys.exit(0) किया जा सकता है, जिससे प्रोग्राम पूरा न हो. माइलस्टोन कोड काम करने के बाद, अगले माइलस्टोन के लिए कोड पर काम किया जा सकता है. किसी एक राज्य में अपने वैरिएबल के प्रिंटआउट को देखने से आपको यह समझने में मदद मिल सकती है कि अगली स्थिति में पहुंचने के लिए आपको उन वैरिएबल को कैसे बदलना है. Python, इस पैटर्न को तुरंत इस्तेमाल कर लेता है. इससे, आपको अपने हिसाब से थोड़ा बदलाव करने और प्रोग्राम को चलाने की सुविधा मिलती है, ताकि यह देखा जा सके कि यह कैसे काम करता है. इस सुविधा की मदद से, कम समय में आसानी से अपना प्रोग्राम बनाया जा सकता है.
व्यायाम: Wordcount.py
Python के सभी बुनियादी मटीरियल -- स्ट्रिंग, लिस्ट, लिखवाने, ट्यूपल, और फ़ाइलें के साथ-साथ, सामान्य कसरतों में खास जानकारी wordcount.py प्रैक्टिस करने की सुविधा आज़माएं.