Tabella Dict Hash
L'efficiente struttura di tabelle hash chiave/valore di Python è chiamata "dict". I contenuti di un dict possono essere scritti come una serie di coppie chiave-valore tra parentesi graffe { }, ad esempio. dict = {chiave1:valore1, chiave2:valore2, ... }. Il "detto vuoto" è solo una coppia di parentesi graffe vuote {}.
La ricerca o l'impostazione di un valore in una dettatura utilizza le parentesi quadre, ad esempio dict['foo'] cerca il valore sotto la chiave "foo". Stringhe, numeri e tuple funzionano come chiavi e qualsiasi tipo può essere un valore. Altri tipi potrebbero non funzionare correttamente come chiavi (stringhe e tuple funzionano in modo chiaro in quanto immutabili). La ricerca di un valore non compreso genera un KeyError. Utilizza "in" per verificare se la chiave è nel dict oppure utilizza dict.get(key) che restituisce il valore oppure None se la chiave non è presente (oppure get(key, not-found) consente di specificare quale valore restituire nel caso non trovato).
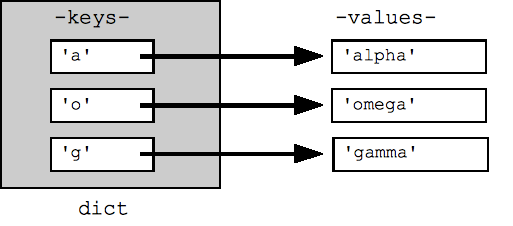
## Can build up a dict by starting with the empty dict {} ## and storing key/value pairs into the dict like this: ## dict[key] = value-for-that-key dict = {} dict['a'] = 'alpha' dict['g'] = 'gamma' dict['o'] = 'omega' print(dict) ## {'a': 'alpha', 'o': 'omega', 'g': 'gamma'} print(dict['a']) ## Simple lookup, returns 'alpha' dict['a'] = 6 ## Put new key/value into dict 'a' in dict ## True ## print(dict['z']) ## Throws KeyError if 'z' in dict: print(dict['z']) ## Avoid KeyError print(dict.get('z')) ## None (instead of KeyError)
Un ciclo for su un dizionario esegue l'iterazione sulle relative chiavi per impostazione predefinita. Le chiavi verranno visualizzate in ordine arbitrario. I metodi dict.keys() e dict.values() restituiscono esplicitamente elenchi di chiavi o valori. C'è anche un elemento items() che restituisce un elenco di tuple (chiave, valore), che rappresenta il modo più efficiente per esaminare tutti i dati delle coppie chiave-valore nel dizionario. Tutti questi elenchi possono essere passati alla funzione ordinati().
## By default, iterating over a dict iterates over its keys. ## Note that the keys are in a random order. for key in dict: print(key) ## prints a g o ## Exactly the same as above for key in dict.keys(): print(key) ## Get the .keys() list: print(dict.keys()) ## dict_keys(['a', 'o', 'g']) ## Likewise, there's a .values() list of values print(dict.values()) ## dict_values(['alpha', 'omega', 'gamma']) ## Common case -- loop over the keys in sorted order, ## accessing each key/value for key in sorted(dict.keys()): print(key, dict[key]) ## .items() is the dict expressed as (key, value) tuples print(dict.items()) ## dict_items([('a', 'alpha'), ('o', 'omega'), ('g', 'gamma')]) ## This loop syntax accesses the whole dict by looping ## over the .items() tuple list, accessing one (key, value) ## pair on each iteration. for k, v in dict.items(): print(k, '>', v) ## a > alpha o > omega g > gamma
Nota sulla strategia: dal punto di vista delle prestazioni, il dizionario è uno dei tuoi migliori strumenti e dovresti utilizzarlo dove è possibile come modo semplice per organizzare i dati. Ad esempio, potresti leggere un file di log in cui ogni riga inizia con un indirizzo IP e archiviare i dati in un dettato utilizzando l'indirizzo IP come chiave e l'elenco di righe in cui appare come valore. Dopo aver letto l'intero file, puoi cercare qualsiasi indirizzo IP e visualizzare immediatamente il relativo elenco di righe. Il dizionario acquisisce dati sparsi e li trasforma in qualcosa di coerente.
Formattazione dettatura
L'operatore % funziona comodamente per sostituire i valori di un dict in una stringa per nome:
h = {} h['word'] = 'garfield' h['count'] = 42 s = 'I want %(count)d copies of %(word)s' % h # %d for int, %s for string # 'I want 42 copies of garfield' # You can also use str.format(). s = 'I want {count:d} copies of {word}'.format(h)
Canc
Il "del" che esegue le eliminazioni. Nel caso più semplice, viene rimossa la definizione di una variabile, come se questa non fosse stata definita. Can può essere utilizzato anche su elementi o sezioni dell'elenco per eliminare quella parte dell'elenco e le voci da un dizionario.
var = 6 del var # var no more! list = ['a', 'b', 'c', 'd'] del list[0] ## Delete first element del list[-2:] ## Delete last two elements print(list) ## ['b'] dict = {'a':1, 'b':2, 'c':3} del dict['b'] ## Delete 'b' entry print(dict) ## {'a':1, 'c':3}
File
La funzione open() si apre e restituisce un handle di file che può essere utilizzato per leggere o scrivere un file come di consueto. Il codice f = open('name', 'r') apre il file nella variabile f, pronto per le operazioni di lettura, e utilizza f.close() al termine. Invece di "r", utilizza "w" per scrivere e "un" per l'aggiunta. Lo standard for-loop funziona per i file di testo, ripetendo le righe del file (questo funziona solo per i file di testo, non per i file binari). La tecnica for-loop è un modo semplice ed efficace per osservare tutte le righe di un file di testo:
# Echo the contents of a text file f = open('foo.txt', 'rt', encoding='utf-8') for line in f: ## iterates over the lines of the file print(line, end='') ## end='' so print does not add an end-of-line char ## since 'line' already includes the end-of-line. f.close()
Leggere una riga alla volta ha la qualità piacevole che non tutto il file ha bisogno di entrare in memoria contemporaneamente, utile se vuoi esaminare ogni riga in un file da 10 gigabyte senza utilizzare 10 gigabyte di memoria. Il metodo f.readlines() legge l'intero file in memoria e ne restituisce il contenuto sotto forma di elenco delle righe. Il metodo f.read() legge l'intero file in un'unica stringa, il che può essere un modo pratico per gestire il testo tutto in una volta, come nel caso delle espressioni regolari che vedremo più avanti.
Per la scrittura, il metodo f.write(string) è il modo più semplice per scrivere dati in un file di output aperto. In alternativa, puoi utilizzare "print" con un file aperto come "print(string, file=f)".
File Unicode
Per leggere e scrivere file con codifica Unicode, utilizza una modalità "t" e specifica esplicitamente una codifica:
with open('foo.txt', 'rt', encoding='utf-8') as f: for line in f: # here line is a *unicode* string with open('write_test', encoding='utf-8', mode='wt') as f: f.write('\u20ACunicode\u20AC\n') # €unicode€ # AKA print('\u20ACunicode\u20AC', file=f) ## which auto-adds end='\n'
Fai pratica con uno sviluppo incrementale
Stai creando un programma Python, non scrivere tutto in un solo passaggio. Identifica solo un primo traguardo, ad esempio "Beh, il primo passo è estrarre l'elenco di parole." Scrivi il codice per raggiungere questo traguardo e stampa le tue strutture di dati a quel punto, quindi puoi eseguire un comando sys.exit(0) in modo che il programma non prosegua nelle sue parti non completate. Una volta che il codice del traguardo funziona, è possibile lavorare sul codice per il traguardo successivo. Essere in grado di esaminare la stampa delle variabili in uno stato può aiutarti a pensare a come devi trasformarle per arrivare allo stato successivo. Python è molto veloce con questo pattern, permettendoti di apportare piccole modifiche ed eseguire il programma per vedere come funziona. Approfitta di questa rapida procedura per creare il tuo programma in pochi passaggi.
Esercizio: wordcount.py
Combinando tutto il materiale Python di base (stringhe, elenchi, detti, tuple, file), prova l'esercizio riepilogativo wordcount.py negli Esercizi di base.