Хэш-таблица Dict
Эффективная структура хэш-таблицы ключей/значений Python называется «dict». Содержимое dict может быть записано как серия пар ключ:значение в фигурных скобках { }, например dict = {ключ1:значение1, ключ2:значение2, ... }. «Пустой словарь» — это просто пустая пара фигурных скобок {}.
Для поиска или установки значения в dict используются квадратные скобки, например, dict['foo'] ищет значение по ключу 'foo'. Строки, числа и кортежи работают как ключи, а значением может быть любой тип. Другие типы могут работать или не работать корректно в качестве ключей (строки и кортежи работают корректно, поскольку они неизменяемы). Поиск значения, которого нет в словаре, вызывает ошибку KeyError - используйте «in», чтобы проверить, находится ли ключ в словаре, или используйте dict.get(key), который возвращает значение или None, если ключ отсутствует ( или get(key, not-found) позволяет указать, какое значение возвращать в случае, если оно не найдено).
## Can build up a dict by starting with the empty dict {} ## and storing key/value pairs into the dict like this: ## dict[key] = value-for-that-key dict = {} dict['a'] = 'alpha' dict['g'] = 'gamma' dict['o'] = 'omega' print(dict) ## {'a': 'alpha', 'o': 'omega', 'g': 'gamma'} print(dict['a']) ## Simple lookup, returns 'alpha' dict['a'] = 6 ## Put new key/value into dict 'a' in dict ## True ## print(dict['z']) ## Throws KeyError if 'z' in dict: print(dict['z']) ## Avoid KeyError print(dict.get('z')) ## None (instead of KeyError)
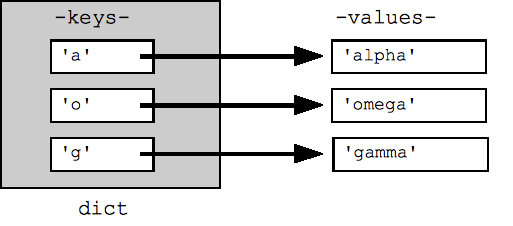
Цикл for в словаре по умолчанию перебирает его ключи. Ключи появятся в произвольном порядке. Методы dict.keys() и dict.values() явно возвращают списки ключей или значений. Существует также метод items(), который возвращает список кортежей (ключ, значение), что является наиболее эффективным способом проверки всех данных значений ключа в словаре. Все эти списки можно передать в функцию sorted().
## By default, iterating over a dict iterates over its keys. ## Note that the keys are in a random order. for key in dict: print(key) ## prints a g o ## Exactly the same as above for key in dict.keys(): print(key) ## Get the .keys() list: print(dict.keys()) ## dict_keys(['a', 'o', 'g']) ## Likewise, there's a .values() list of values print(dict.values()) ## dict_values(['alpha', 'omega', 'gamma']) ## Common case -- loop over the keys in sorted order, ## accessing each key/value for key in sorted(dict.keys()): print(key, dict[key]) ## .items() is the dict expressed as (key, value) tuples print(dict.items()) ## dict_items([('a', 'alpha'), ('o', 'omega'), ('g', 'gamma')]) ## This loop syntax accesses the whole dict by looping ## over the .items() tuple list, accessing one (key, value) ## pair on each iteration. for k, v in dict.items(): print(k, '>', v) ## a > alpha o > omega g > gamma
Примечание по стратегии: с точки зрения производительности словарь является одним из лучших инструментов, и вам следует использовать его там, где это возможно, как простой способ организации данных. Например, вы можете прочитать файл журнала, где каждая строка начинается с IP-адреса, и сохранить данные в словаре, используя IP-адрес в качестве ключа и список строк, где он отображается в качестве значения. Прочитав весь файл, вы можете найти любой IP-адрес и мгновенно увидеть список его строк. Словарь собирает разрозненные данные и превращает их во что-то связное.
Диктовское форматирование
Оператор % удобно заменяет значения из словаря в строку по имени:
h = {} h['word'] = 'garfield' h['count'] = 42 s = 'I want %(count)d copies of %(word)s' % h # %d for int, %s for string # 'I want 42 copies of garfield' # You can also use str.format(). s = 'I want {count:d} copies of {word}'.format(h)
Дель
Оператор «del» выполняет удаление. В простейшем случае он может удалить определение переменной, как если бы эта переменная не была определена. Del также можно использовать для элементов или фрагментов списка, чтобы удалить эту часть списка и записи из словаря.
var = 6 del var # var no more! list = ['a', 'b', 'c', 'd'] del list[0] ## Delete first element del list[-2:] ## Delete last two elements print(list) ## ['b'] dict = {'a':1, 'b':2, 'c':3} del dict['b'] ## Delete 'b' entry print(dict) ## {'a':1, 'c':3}
Файлы
Функция open() открывает и возвращает дескриптор файла, который можно использовать для чтения или записи файла обычным способом. Код f = open('name', 'r') открывает файл в переменной f, готовый к операциям чтения, и после завершения использует f.close(). Вместо «r» используйте «w» для записи и «a» для добавления. Стандартный цикл for работает для текстовых файлов, перебирая строки файла (это работает только для текстовых, а не двоичных файлов). Техника цикла for — это простой и эффективный способ просмотреть все строки текстового файла:
# Echo the contents of a text file f = open('foo.txt', 'rt', encoding='utf-8') for line in f: ## iterates over the lines of the file print(line, end='') ## end='' so print does not add an end-of-line char ## since 'line' already includes the end-of-line. f.close()
Чтение по одной строке имеет то преимущество, что не весь файл должен умещаться в памяти одновременно — это удобно, если вы хотите просмотреть каждую строку в 10-гигабайтном файле, не используя 10 гигабайт памяти. Метод f.readlines() считывает весь файл в память и возвращает его содержимое в виде списка строк. Метод f.read() считывает весь файл в одну строку, что может быть удобным способом обработки всего текста одновременно, например, с помощью регулярных выражений, которые мы увидим позже.
Для записи метод f.write(string) — это самый простой способ записать данные в открытый выходной файл. Или вы можете использовать «print» с открытым файлом, например «print(string, file=f)».
Файлы Юникод
Для чтения и записи файлов в кодировке Unicode используйте режим «t» и явно укажите кодировку:
with open('foo.txt', 'rt', encoding='utf-8') as f: for line in f: # here line is a *unicode* string with open('write_test', encoding='utf-8', mode='wt') as f: f.write('\u20ACunicode\u20AC\n') # €unicode€ # AKA print('\u20ACunicode\u20AC', file=f) ## which auto-adds end='\n'
Упражняйтесь в постепенном развитии
Создавая программу на Python, не пишите все за один шаг. Вместо этого определите только первую веху, например: «Ну, первый шаг — извлечь список слов». Напишите код, чтобы добраться до этой вехи, и просто распечатайте свои структуры данных в этот момент, а затем вы можете выполнить sys.exit(0), чтобы программа не убегала вперед к невыполненным частям. Как только код вехи заработает, вы можете работать над кодом для следующей вехи. Возможность просмотреть распечатку ваших переменных в одном состоянии может помочь вам подумать о том, как вам нужно преобразовать эти переменные, чтобы перейти к следующему состоянию. Python очень быстро работает с этим шаблоном, что позволяет вам внести небольшие изменения и запустить программу, чтобы увидеть, как она работает. Воспользуйтесь этим быстрым поворотом и создайте свою программу небольшими шагами.
Упражнение: wordcount.py
Объединив весь основной материал Python — строки, списки, словари, кортежи, файлы — попробуйте выполнить сводное упражнение wordcount.py в разделе «Базовые упражнения» .