أسهل طريقة للفرز هي باستخدام الدالة sorted(list) التي تأخذ قائمة وترجع قائمة جديدة بهذه العناصر بترتيب فرز. لم يتم تغيير القائمة الأصلية.
a = [5, 1, 4, 3] print(sorted(a)) ## [1, 3, 4, 5] print(a) ## [5, 1, 4, 3]
من الشائع تمرير قائمة إلى الدالة sorted()، ولكن في الحقيقة يمكن أن تُستخدم كمدخلات لأي نوع من المجموعات القابلة للتكرار. طريقة list.sort() الأقدم هي بديل مفصل أدناه. يبدو أن الدالة sorted() أسهل في الاستخدام مقارنة بـ sorted()، لذلك أوصي باستخدام sorted().
يمكن تخصيص الدالة sorted() من خلال وسيطات اختيارية. الوسيطة الاختيارية sorted() للخلف=True، على سبيل المثال sorted(list, opposite=True)، تجعلها تقوم بالفرز بشكل عكسي.
strs = ['aa', 'BB', 'zz', 'CC'] print(sorted(strs)) ## ['BB', 'CC', 'aa', 'zz'] (case sensitive) print(sorted(strs, reverse=True)) ## ['zz', 'aa', 'CC', 'BB']
فرز مخصص باستخدام المفتاح=
للحصول على فرز مخصص أكثر تعقيدًا، تتخذ sorted() "key=" اختياريًا لتحديد "مفتاح" التي تُحوِّل كل عنصر قبل المقارنة. تستخدم الدالة الرئيسية قيمة واحدة وتعرض قيمة واحدة، ويكون "الخادم الوكيل" الذي تم عرضه تُستخدم للمقارنات داخل الفرز.
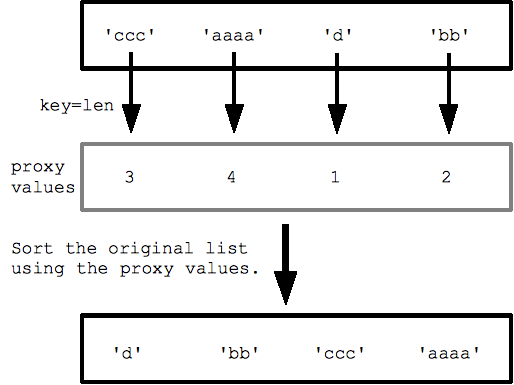
على سبيل المثال باستخدام قائمة من السلاسل، يؤدي تحديد key=len (دالة len() المضمنة) إلى فرز السلاسل حسب الطول، من الأقصر إلى الأطول. يستدعي الفرز len() لكل سلسلة للحصول على قائمة قيم طول الخادم الوكيل، ثم يقوم بالفرز باستخدام قيم الخادم الوكيل هذه.
strs = ['ccc', 'aaaa', 'd', 'bb'] print(sorted(strs, key=len)) ## ['d', 'bb', 'ccc', 'aaaa']
ومثال آخر على ذلك، تحديد "str.lower" لأن الدالة الرئيسية هي طريقة لإجبار الفرز على التعامل مع الأحرف الكبيرة والصغيرة بالطريقة نفسها:
## "key" argument specifying str.lower function to use for sorting print(sorted(strs, key=str.lower)) ## ['aa', 'BB', 'CC', 'zz']
يمكنك أيضًا ضبط MyFn الخاص بك كدالة رئيسية، على النحو التالي:
## Say we have a list of strings we want to sort by the last letter of the string. strs = ['xc', 'zb', 'yd' ,'wa'] ## Write a little function that takes a string, and returns its last letter. ## This will be the key function (takes in 1 value, returns 1 value). def MyFn(s): return s[-1] ## Now pass key=MyFn to sorted() to sort by the last letter: print(sorted(strs, key=MyFn)) ## ['wa', 'zb', 'xc', 'yd']
لإجراء فرز أكثر تعقيدًا مثل الفرز حسب اسم العائلة ثم الاسم الأول، يمكنك استخدام الدالتين itemgetter أو atrgetter على النحو التالي:
from operator import itemgetter # (first name, last name, score) tuples grade = [('Freddy', 'Frank', 3), ('Anil', 'Frank', 100), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(1,0)) # [('Anil', 'Frank', 100), ('Freddy', 'Frank', 3), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(0,-1)) #[('Anil', 'Wang', 24), ('Anil', 'Frank', 100), ('Freddy', 'Frank', 3)]
طريقة sort()
كبديل لـ sorted()، تعمل طريقة sort() في القائمة على فرز القائمة بترتيب تصاعدي، على سبيل المثال list.sort(). تُغير طريقة sort() القائمة الأساسية وتعرض "None" (بلا)، لذا استخدمها على النحو التالي:
alist.sort() ## correct alist = blist.sort() ## Incorrect. sort() returns None
ما ورد أعلاه هو سوء فهم شائع جدًا مع sort() -- فإنه *لا تعرض* القائمة التي تم فرزها. يجب استدعاء طريقة sort() على قائمة؛ فهي لا تعمل على أي مجموعة قابلة للتعداد (لكن دالة sorted() أعلاه تعمل على أي شيء). يسبق طريقة sort() الدالة sorted()، لذا يحتمل أن تراها في التعليمة البرمجية القديمة. لا تحتاج طريقة sort() إلى إنشاء قائمة جديدة، لذا يمكن أن تكون أسرع قليلاً في حال كانت العناصر المراد فرزها موجودة بالفعل في قائمة.
الصفوف
الصف هو مجموعة من العناصر ذات الحجم الثابت، مثل تنسيق (س، ص). الصفوف تشبه القوائم، باستثناء أنها غير قابلة للتغيير ولا تغير الحجم (الصفوف ليست قابلة للتغيير تمامًا لأن أحد العناصر المتضمّنة يمكن أن يكون قابلاً للتغيير). تلعب الصفوف نوعًا من "الهيكل" في لغة بايثون، وهي طريقة ملائمة لتمرير مجموعة قيم منطقية وثابتة الحجم. يمكن للدالة التي تحتاج إلى إرجاع قيم متعددة أن تعرض صفًا من القيم فقط. على سبيل المثال، إذا أردت الحصول على قائمة من الإحداثيات ثلاثية الأبعاد، فسيكون تمثيل بايثون الطبيعي عبارة عن قائمة من الصفوف، حيث يكون حجم كل صف 3 فيه مجموعة واحدة (x، y، z).
لإنشاء صف، ما عليك سوى سرد القيم داخل أقواس مفصولة بفواصل. "الفارغ" الصف هو مجرد زوج فارغ من الأقواس. يُعد الوصول إلى العناصر في الصف تمامًا مثل القائمة -- len() و[ ] وfor وin وما إلى ذلك يعمل بالطريقة نفسها.
tuple = (1, 2, 'hi') print(len(tuple)) ## 3 print(tuple[2]) ## hi tuple[2] = 'bye' ## NO, tuples cannot be changed tuple = (1, 2, 'bye') ## this works
لإنشاء صف ذي حجم 1، يجب أن يتبع العنصر الوحيد فاصلة.
tuple = ('hi',) ## size-1 tuple
إنها حالة مضحكة في بناء الجملة، لكن الفاصلة ضرورية لتمييز الصف عن الحالة العادية لوضع تعبير بين قوسين. في بعض الحالات، يمكنك حذف الأقواس، وسترى بايثون الفواصل التي تريدها الصف.
يؤدي تعيين صف لعدد متطابق من أسماء المتغيرات إلى تعيين جميع القيم المقابلة. إذا لم يكن عدد الصفوف بنفس الحجم، سيحدث خطأ. ويمكن استخدام هذه الميزة مع القوائم أيضًا.
(x, y, z) = (42, 13, "hike") print(z) ## hike (err_string, err_code) = Foo() ## Foo() returns a length-2 tuple
عمليات فهم القائمة (اختياري)
تعد طريقة فهم القائمة ميزة أكثر تقدمًا وهي رائعة في بعض الحالات ولكنها ليست ضرورية للتمارين وهي ليست شيئًا تحتاج إلى تعلمه في البداية (أي يمكنك تخطي هذا القسم). فهم القائمة هو طريقة مضغوطة لكتابة تعبير يتوسع إلى قائمة كاملة. لنفترض أن لدينا قائمة بالأرقام [1، 2، 3، 4]، إليك طريقة فهم القائمة لحساب قائمة مربعاتها [1، 4، 9، 16]:
nums = [1, 2, 3, 4] squares = [ n * n for n in nums ] ## [1, 4, 9, 16]
البنية هي [ expr for var in list ] -- يبدو أن for var in list مثل تكرار حلقي عادي، ولكن بدون النقطتين (:). يتم تقييم expr على يساره مرة واحدة لكل عنصر لإعطاء قيم القائمة الجديدة. في ما يلي مثال على السلاسل، حيث يتم تغيير كل سلسلة إلى أحرف كبيرة مع "!" ملحق:
strs = ['hello', 'and', 'goodbye'] shouting = [ s.upper() + '!!!' for s in strs ] ## ['HELLO!!!', 'AND!!!', 'GOODBYE!!!']
يمكنك إضافة اختبار if إلى يمين الحلقة for لتضييق نطاق النتيجة. يتم تقييم اختبار if لكل عنصر، بما في ذلك فقط العناصر التي يكون فيها الاختبار true.
## Select values <= 2 nums = [2, 8, 1, 6] small = [ n for n in nums if n <= 2 ] ## [2, 1] ## Select fruits containing 'a', change to upper case fruits = ['apple', 'cherry', 'banana', 'lemon'] afruits = [ s.upper() for s in fruits if 'a' in s ] ## ['APPLE', 'BANANA']
تمرين: list1.py
للتدرب على المواد في هذا القسم، جرّب لاحقًا المسائل في list1.py التي تستخدم التصنيف والصفوف (في التمارين الأساسية).