সাজানোর সবচেয়ে সহজ উপায় হল সাজানো (তালিকা) ফাংশন, যা একটি তালিকা নেয় এবং সাজানো ক্রমে সেই উপাদানগুলির সাথে একটি নতুন তালিকা প্রদান করে। মূল তালিকা পরিবর্তন করা হয় না.
a = [5, 1, 4, 3] print(sorted(a)) ## [1, 3, 4, 5] print(a) ## [5, 1, 4, 3]
এটি sorted() ফাংশনে একটি তালিকা পাস করা সবচেয়ে সাধারণ, কিন্তু প্রকৃতপক্ষে এটি যেকোনো ধরনের পুনরাবৃত্তিযোগ্য সংগ্রহ ইনপুট হিসাবে নিতে পারে। পুরোনো list.sort() পদ্ধতিটি একটি বিকল্প নিচে বিস্তারিত। sort() ফাংশন sort() এর তুলনায় ব্যবহার করা সহজ বলে মনে হয়, তাই আমি sorted() ব্যবহার করার পরামর্শ দিই।
sorted() ফাংশন ঐচ্ছিক আর্গুমেন্টের মাধ্যমে কাস্টমাইজ করা যেতে পারে। sorted() ঐচ্ছিক আর্গুমেন্ট reverse=True, যেমন sorted(list, reverse=True), এটিকে পিছনের দিকে সাজায়।
strs = ['aa', 'BB', 'zz', 'CC'] print(sorted(strs)) ## ['BB', 'CC', 'aa', 'zz'] (case sensitive) print(sorted(strs, reverse=True)) ## ['zz', 'aa', 'CC', 'BB']
কী= দিয়ে কাস্টম বাছাই
আরও জটিল কাস্টম সাজানোর জন্য, sorted() একটি ঐচ্ছিক "key=" একটি "কী" ফাংশন নির্দিষ্ট করে যা তুলনা করার আগে প্রতিটি উপাদানকে রূপান্তরিত করে। কী ফাংশনটি 1 মান নেয় এবং 1 মান প্রদান করে এবং প্রত্যাবর্তিত "প্রক্সি" মানটি সাজানোর মধ্যে তুলনা করার জন্য ব্যবহার করা হয়।
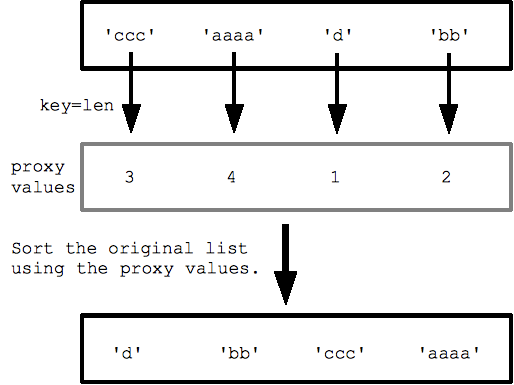
উদাহরণস্বরূপ, স্ট্রিংগুলির একটি তালিকার সাথে, key=len (বিল্ট ইন len() ফাংশন নির্দিষ্ট করে স্ট্রিংগুলিকে দৈর্ঘ্য অনুসারে বাছাই করে, সবচেয়ে ছোট থেকে দীর্ঘতম পর্যন্ত। প্রক্সি দৈর্ঘ্যের মানগুলির তালিকা পেতে প্রতিটি স্ট্রিংয়ের জন্য বাছাই len() কে কল করে এবং তারপরে সেই প্রক্সি মানগুলির সাথে সাজানো হয়।
strs = ['ccc', 'aaaa', 'd', 'bb'] print(sorted(strs, key=len)) ## ['d', 'bb', 'ccc', 'aaaa']
আরেকটি উদাহরণ হিসাবে, কী ফাংশন হিসাবে "str.lower" নির্দিষ্ট করা হল বড় হাতের এবং ছোট হাতের অক্ষর একই আচরণ করার জন্য বাছাইকে বাধ্য করার একটি উপায়:
## "key" argument specifying str.lower function to use for sorting print(sorted(strs, key=str.lower)) ## ['aa', 'BB', 'CC', 'zz']
এছাড়াও আপনি আপনার নিজের MyFn-এ কী ফাংশন হিসাবে পাস করতে পারেন, যেমন:
## Say we have a list of strings we want to sort by the last letter of the string. strs = ['xc', 'zb', 'yd' ,'wa'] ## Write a little function that takes a string, and returns its last letter. ## This will be the key function (takes in 1 value, returns 1 value). def MyFn(s): return s[-1] ## Now pass key=MyFn to sorted() to sort by the last letter: print(sorted(strs, key=MyFn)) ## ['wa', 'zb', 'xc', 'yd']
আরও জটিল বাছাইয়ের জন্য যেমন শেষ নাম অনুসারে বাছাই করা তারপর প্রথম নাম অনুসারে, আপনি আইটেমজেটার বা অ্যাট্রগেটার ফাংশনগুলি ব্যবহার করতে পারেন যেমন:
from operator import itemgetter # (first name, last name, score) tuples grade = [('Freddy', 'Frank', 3), ('Anil', 'Frank', 100), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(1,0)) # [('Anil', 'Frank', 100), ('Freddy', 'Frank', 3), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(0,-1)) #[('Anil', 'Wang', 24), ('Anil', 'Frank', 100), ('Freddy', 'Frank', 3)]
sort() পদ্ধতি
sorted() এর বিকল্প হিসাবে, একটি তালিকার sort() পদ্ধতিটি তালিকাটিকে আরোহী ক্রমে সাজায়, যেমন list.sort()। sort() পদ্ধতি অন্তর্নিহিত তালিকা পরিবর্তন করে এবং None প্রদান করে, তাই এটিকে এভাবে ব্যবহার করুন:
alist.sort() ## correct alist = blist.sort() ## Incorrect. sort() returns None
উপরেরটি sort() এর সাথে একটি খুব সাধারণ ভুল বোঝাবুঝি -- এটি সাজানো তালিকাটি *ফেরত করে না*। sort() পদ্ধতি একটি তালিকায় কল করা আবশ্যক; এটি কোনো গণনাযোগ্য সংগ্রহে কাজ করে না (তবে উপরের সাজানো() ফাংশনটি যেকোনো কিছুতে কাজ করে)। sort() পদ্ধতিটি sorted() ফাংশনের পূর্ববর্তী, তাই আপনি সম্ভবত এটি পুরানো কোডে দেখতে পাবেন। sort() পদ্ধতিতে একটি নতুন তালিকা তৈরি করার প্রয়োজন নেই, তাই এটিকে একটু দ্রুত হতে পারে যদি সাজানোর উপাদানগুলি ইতিমধ্যেই একটি তালিকায় রয়েছে।
টিপলস
একটি টিপল হল উপাদানগুলির একটি নির্দিষ্ট আকারের গ্রুপিং, যেমন একটি (x, y) কো-অর্ডিনেট। টিপলগুলি তালিকার মতো, তবে এগুলি অপরিবর্তনীয় এবং আকার পরিবর্তন করে না (টুপলগুলি কঠোরভাবে অপরিবর্তনীয় নয় যেহেতু অন্তর্ভুক্ত উপাদানগুলির একটি পরিবর্তনযোগ্য হতে পারে)। পাইথনে Tuples একধরনের "struct" ভূমিকা পালন করে -- সামান্য যৌক্তিক, স্থির আকারের মানের বান্ডিলের কাছাকাছি যাওয়ার একটি সুবিধাজনক উপায়। একটি ফাংশন যা একাধিক মান ফেরত দিতে হবে তা কেবলমাত্র একগুণ মান ফেরত দিতে পারে। উদাহরণস্বরূপ, যদি আমি 3-ডি স্থানাঙ্কগুলির একটি তালিকা পেতে চাই, তবে প্রাকৃতিক পাইথন উপস্থাপনাটি টিপলের একটি তালিকা হবে, যেখানে প্রতিটি টিপল একটি (x, y, z) গ্রুপ ধরে 3 আকারের।
একটি টিপল তৈরি করতে, কমা দ্বারা পৃথক বন্ধনীর মধ্যে মানগুলি তালিকাভুক্ত করুন। "খালি" টিপলটি বন্ধনীর একটি খালি জোড়া মাত্র। একটি টিপলে উপাদানগুলি অ্যাক্সেস করা ঠিক একটি তালিকার মতো -- len(), [ ], for, in, ইত্যাদি সব একই কাজ করে।
tuple = (1, 2, 'hi') print(len(tuple)) ## 3 print(tuple[2]) ## hi tuple[2] = 'bye' ## NO, tuples cannot be changed tuple = (1, 2, 'bye') ## this works
একটি আকার-1 টিপল তৈরি করতে, একমাত্র উপাদানটিকে একটি কমা দ্বারা অনুসরণ করতে হবে।
tuple = ('hi',) ## size-1 tuple
সিনট্যাক্সে এটি একটি মজার কেস, কিন্তু বন্ধনীতে এক্সপ্রেশন রাখার সাধারণ কেস থেকে টিপলকে আলাদা করতে কমা প্রয়োজন। কিছু ক্ষেত্রে আপনি বন্ধনী বাদ দিতে পারেন এবং পাইথন কমা থেকে দেখতে পাবে যে আপনি একটি টিপল করতে চান।
পরিবর্তনশীল নামের একটি অভিন্ন আকারের টিপলে একটি টিপল বরাদ্দ করা সমস্ত সংশ্লিষ্ট মানগুলিকে বরাদ্দ করে। যদি tuples একই আকার না হয়, এটি একটি ত্রুটি নিক্ষেপ. এই বৈশিষ্ট্যটি তালিকার জন্যও কাজ করে।
(x, y, z) = (42, 13, "hike") print(z) ## hike (err_string, err_code) = Foo() ## Foo() returns a length-2 tuple
তালিকা বোঝা (ঐচ্ছিক)
তালিকা বোঝা একটি আরও উন্নত বৈশিষ্ট্য যা কিছু ক্ষেত্রে চমৎকার কিন্তু অনুশীলনের জন্য প্রয়োজন হয় না এবং এটি এমন কিছু নয় যা আপনাকে প্রথমে শিখতে হবে (অর্থাৎ আপনি এই বিভাগটি এড়িয়ে যেতে পারেন)। একটি তালিকা বোধগম্য হল একটি অভিব্যক্তি লেখার একটি কম্প্যাক্ট উপায় যা একটি সম্পূর্ণ তালিকায় প্রসারিত হয়। ধরুন আমাদের একটি তালিকা সংখ্যা [1, 2, 3, 4] আছে, এখানে তাদের বর্গক্ষেত্রগুলির একটি তালিকা গণনা করার জন্য তালিকা বোঝার উপায় রয়েছে [1, 4, 9, 16]:
nums = [1, 2, 3, 4] squares = [ n * n for n in nums ] ## [1, 4, 9, 16]
সিনট্যাক্স হল [ expr for var in list ] -- for var in list একটি নিয়মিত ফর-লুপের মতো দেখায়, কিন্তু কোলন (:) ছাড়াই। নতুন তালিকার মান দেওয়ার জন্য প্রতিটি উপাদানের জন্য তার বাম দিকের expr একবার মূল্যায়ন করা হয়। এখানে স্ট্রিং সহ একটি উদাহরণ রয়েছে, যেখানে প্রতিটি স্ট্রিং '!!!' দিয়ে বড় হাতের অক্ষরে পরিবর্তিত হয়েছে। সংযুক্ত:
strs = ['hello', 'and', 'goodbye'] shouting = [ s.upper() + '!!!' for s in strs ] ## ['HELLO!!!', 'AND!!!', 'GOODBYE!!!']
ফলাফল সংকীর্ণ করতে আপনি ফর-লুপের ডানদিকে একটি if পরীক্ষা যোগ করতে পারেন। if পরীক্ষা প্রতিটি উপাদানের জন্য মূল্যায়ন করা হয়, শুধুমাত্র সেই উপাদানগুলি সহ যেখানে পরীক্ষাটি সত্য।
## Select values <= 2 nums = [2, 8, 1, 6] small = [ n for n in nums if n <= 2 ] ## [2, 1] ## Select fruits containing 'a', change to upper case fruits = ['apple', 'cherry', 'banana', 'lemon'] afruits = [ s.upper() for s in fruits if 'a' in s ] ## ['APPLE', 'BANANA']
ব্যায়াম: list1.py
এই বিভাগে উপাদান অনুশীলন করার জন্য, list1.py- এ পরবর্তী সমস্যাগুলি চেষ্টা করুন যা বাছাই এবং টিপল ব্যবহার করে ( বেসিক অনুশীলনে )।