가장 쉽게 정렬하는 방법은 saved(list) 함수를 사용하는 것입니다. 이 함수는 목록을 가져와 해당 요소가 정렬된 새 목록을 반환합니다. 원래 목록은 변경되지 않습니다.
a = [5, 1, 4, 3] print(sorted(a)) ## [1, 3, 4, 5] print(a) ## [5, 1, 4, 3]
정렬() 함수에 목록을 전달하는 것이 가장 일반적이지만, 실제로는 모든 종류의 반복 가능한 컬렉션을 입력으로 사용할 수 있습니다. 아래와 같이 이전의 list.sort() 메서드를 대안으로 사용할 수 있습니다. saved() 함수는 정렬()에 비해 사용하기 더 편할 것 같아서 saved()를 사용하는 것이 좋습니다.
정렬된() 함수는 선택적 인수를 통해 맞춤설정할 수 있습니다. saved() 선택적 인수 역방향=True입니다. 예: kind(list, replace=True)는 역순으로 정렬합니다.
strs = ['aa', 'BB', 'zz', 'CC'] print(sorted(strs)) ## ['BB', 'CC', 'aa', 'zz'] (case sensitive) print(sorted(strs, reverse=True)) ## ['zz', 'aa', 'CC', 'BB']
key=를 사용한 맞춤 정렬
더 복잡한 맞춤 정렬의 경우 saved()는 선택적 'key='를 사용합니다. '키' 지정 비교 전에 각 요소를 변환하는 함수입니다. 키 함수는 값 1개를 가져와 값 1개를 반환하며 반환된 '프록시'는 값은 정렬 내 비교에 사용됩니다.
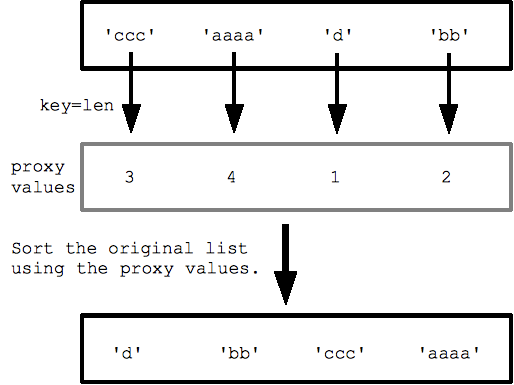
예를 들어 문자열 목록에서 key=len (기본 제공 len() 함수)을 지정하면 문자열이 가장 짧은 것부터 가장 긴 것 순으로 정렬됩니다. 정렬은 각 문자열에 대해 len()을 호출하여 프록시 길이 값 목록을 가져온 다음 해당 프록시 값으로 정렬합니다.
strs = ['ccc', 'aaaa', 'd', 'bb'] print(sorted(strs, key=len)) ## ['d', 'bb', 'ccc', 'aaaa']
또 다른 예로 'str.lower'를 지정하면 됩니다. 키 함수는 정렬에서 대문자와 소문자를 동일하게 처리하도록 강제하는 방법입니다.
## "key" argument specifying str.lower function to use for sorting print(sorted(strs, key=str.lower)) ## ['aa', 'BB', 'CC', 'zz']
다음과 같이 자체 MyFn을 키 함수로 전달할 수도 있습니다.
## Say we have a list of strings we want to sort by the last letter of the string. strs = ['xc', 'zb', 'yd' ,'wa'] ## Write a little function that takes a string, and returns its last letter. ## This will be the key function (takes in 1 value, returns 1 value). def MyFn(s): return s[-1] ## Now pass key=MyFn to sorted() to sort by the last letter: print(sorted(strs, key=MyFn)) ## ['wa', 'zb', 'xc', 'yd']
성을 기준으로 정렬한 다음 이름으로 정렬하는 등 더 복잡한 정렬의 경우 다음과 같은 itemgetter 또는 attrgetter 함수를 사용할 수 있습니다.
from operator import itemgetter # (first name, last name, score) tuples grade = [('Freddy', 'Frank', 3), ('Anil', 'Frank', 100), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(1,0)) # [('Anil', 'Frank', 100), ('Freddy', 'Frank', 3), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(0,-1)) #[('Anil', 'Wang', 24), ('Anil', 'Frank', 100), ('Freddy', 'Frank', 3)]
정렬() 메서드
category()의 대안으로, 목록의sort() 메서드는 해당 목록을 오름차순으로 정렬합니다.예를 들면 다음과 같습니다. list.sort()를 사용할 수 있습니다. 정렬() 메서드는 기본 목록을 변경하고 None을 반환하므로 다음과 같이 사용합니다.
alist.sort() ## correct alist = blist.sort() ## Incorrect. sort() returns None
위의 것은sort()에 대한 매우 일반적인 오해로, 정렬된 목록을 *반환하지 않습니다*. 정렬() 메서드는 목록에서 호출해야 합니다. 열거 가능한 컬렉션에서는 작동하지 않습니다 (그러나 위의 {7} 겁니다. . 정렬() 메서드는 '정렬()' 함수보다 먼저 작성되었으므로 이전 코드에서 보게 될 가능성이 높습니다. 정렬() 메서드는 새 목록을 만들 필요가 없으므로 정렬할 요소가 이미 목록에 있는 경우 조금 더 빠를 수 있습니다.
튜플
튜플은 (x, y) 좌표와 같은 고정된 크기의 요소 그룹입니다. 튜플은 목록과 비슷하지만, 불변하고 크기를 변경하지 않는다는 점이 다릅니다 (포함된 요소 중 하나가 변경 가능할 수 있으므로 튜플은 엄격하게 불변성이 아님). 튜플은 일종의 '구조체'를 재생한다. 역할을 하며, 논리적이고 고정된 크기의 값 번들을 편리하게 전달할 수 있습니다. 여러 값을 반환해야 하는 함수는 값의 튜플만 반환할 수 있습니다. 예를 들어 3차원 좌표 목록을 만들려는 경우 Python의 자연스러운 표현은 튜플의 목록입니다. 여기서 각 튜플은 1개 (x, y, z) 그룹을 보유하는 크기 3입니다.
튜플을 생성하려면 괄호 안에 값을 쉼표로 구분하여 나열하면 됩니다. 'empty' tuple은 빈 괄호 쌍일 뿐입니다. 튜플에서 요소에 액세스하는 것은 목록과 비슷합니다. len(), [ ], for, in 등은 모두 동일하게 작동합니다.
tuple = (1, 2, 'hi') print(len(tuple)) ## 3 print(tuple[2]) ## hi tuple[2] = 'bye' ## NO, tuples cannot be changed tuple = (1, 2, 'bye') ## this works
size-1 튜플을 만들려면 고립된 요소 뒤에 쉼표가 와야 합니다.
tuple = ('hi',) ## size-1 tuple
구문에서 재미있는 사례이기는 하지만 쉼표는 튜플을 괄호로 묶어 넣는 일반적인 사례와 구분하는 데 필요합니다. 경우에 따라 괄호를 생략할 수 있으며 Python은 튜플이 원하는 쉼표에서 보게 됩니다.
변수 이름이 동일한 크기의 튜플에 튜플을 할당하면 해당하는 모든 값이 할당됩니다. 튜플의 크기가 동일하지 않으면 오류가 발생합니다. 이 기능은 목록에도 사용할 수 있습니다.
(x, y, z) = (42, 13, "hike") print(z) ## hike (err_string, err_code) = Foo() ## Foo() returns a length-2 tuple
목록 이해 (선택사항)
목록 이해는 고급 기능으로, 경우에 따라 유용하지만 연습에는 필요하지 않으며 처음에 배울 필요가 없습니다 (이 섹션은 건너뛸 수 있음). 목록 이해는 전체 목록으로 확장되는 표현식을 작성하는 간단한 방법입니다. 목록 num [1, 2, 3, 4]가 있다고 가정해 보겠습니다. 이 목록의 제곱[1, 4, 9, 16] 목록을 계산하기 위한 목록 이해는 다음과 같습니다.
nums = [1, 2, 3, 4] squares = [ n * n for n in nums ] ## [1, 4, 9, 16]
문법은 [ expr for var in list ]입니다. for var in list는 일반적인 for 루프처럼 보이지만 콜론 (:)은 없습니다. 왼쪽의 expr은 요소마다 한 번씩 평가되어 새 목록의 값을 제공합니다. 다음은 문자열이 포함된 예입니다. 여기서 각 문자열은 '!!!'가 있는 대문자로 변경됩니다. 추가됨:
strs = ['hello', 'and', 'goodbye'] shouting = [ s.upper() + '!!!' for s in strs ] ## ['HELLO!!!', 'AND!!!', 'GOODBYE!!!']
for 루프 오른쪽에 if 테스트를 추가하여 결과를 좁힐 수 있습니다. if 테스트는 테스트가 true인 요소만 포함하여 각 요소에 대해 평가됩니다.
## Select values <= 2 nums = [2, 8, 1, 6] small = [ n for n in nums if n <= 2 ] ## [2, 1] ## Select fruits containing 'a', change to upper case fruits = ['apple', 'cherry', 'banana', 'lemon'] afruits = [ s.upper() for s in fruits if 'a' in s ] ## ['APPLE', 'BANANA']
연습문제: list1.py
이 섹션의 자료를 연습하려면 정렬 및 튜플을 사용하는 list1.py의 이후 문제를 시도해 보세요 (기본 연습 내).