تتضمن لغة بايثون فئة سلسلة مضمنة تُسمى str به العديد من الميزات المفيدة (هناك وحدة قديمة تسمى "سلسلة" لا يجب عليك استخدامها). يمكن وضع القيم الحرفية للسلسلة إما بين علامتَي اقتباس مزدوجتَين أو مفردتَين، على الرغم من استخدام علامات الاقتباس المفردة بشكل أكثر شيوعًا. تعمل عمليات إلغاء الشرطة المائلة للخلف بالطريقة المعتادة لكل من القيم الحرفية المفردة والمزدوجة بين علامتي الاقتباس - على سبيل المثال \n \" \". ويمكن أن تحتوي السلسلة الحرفية ذات علامتي الاقتباس المزدوجة على علامات اقتباس مفردة بدون أي ضجة (على سبيل المثال، "لم أفعل ذلك") ويمكن كذلك أن تحتوي السلسلة المفردة ذات علامتي الاقتباس على علامات اقتباس مزدوجة. يمكن أن تمتد السلسلة الحرفية عبر أسطر متعددة، ولكن يجب أن تكون هناك شرطة مائلة للخلف \ في نهاية كل سطر للخروج من السطر الجديد. سلسلة القيم الحرفية داخل علامات اقتباس ثلاثية، """ أو '''، يمكن أن تمتد لعدة أسطر من النص.
سلاسل بايثون "غير قابلة للتغيير" مما يعني أنه لا يمكن تغييرها بعد إنشائها (تستخدم سلاسل Java أيضًا هذا النمط غير القابل للتغيير). بما أنه لا يمكن تغيير السلاسل، فإننا ننشئ سلاسل *جديدة* أثناء تمثيل القيم المحسوبة. على سبيل المثال، يستخدم التعبير ('hello' + 'there') في السلسلتين 'hello' و"هناك" وتنشئ سلسلة جديدة "hellothere".
يمكن الوصول إلى الأحرف في سلسلة ما باستخدام البنية القياسية [ ]، وعلى غرار Java وC++ ، تستخدم بايثون فهرسة قائمة على صفر، لذلك إذا كانت s هي 'hello' s[1] هي 'e'. إذا كان الفهرس خارج حدود السلسلة، تعرض بايثون خطأ. أسلوب بايثون (على عكس Perl) يتوقّف إذا لم تستطع أن تحدد ما يجب فعله، بدلاً من تكوين قيمة افتراضية. "شريحة" مفيدة (أدناه) أيضًا على استخراج أي سلسلة فرعية من سلسلة. ترجع الدالة len(string) طول السلسلة. يعمل بناء الجملة [ ] والدالة len() في الواقع على أي نوع تسلسل - السلاسل، والقوائم، وما إلى ذلك. تحاول بايثون تنفيذ عملياتها بشكل متسق عبر أنواع مختلفة. Python مبتدئ: لا تستخدم "len" كاسم متغير لتجنب حظر الدالة len(). يعمل الرمز "+" يمكن للمشغل إجراء تسلسل لسلسلتين. لاحظ في التعليمة البرمجية أدناه أن المتغيرات لم يتم تعريفها مسبقًا - ما عليك سوى تعيينها لها ثم الانتقال.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
على عكس Java، فإن الرمز "+" لا تحوّل الأرقام أو الأنواع الأخرى تلقائيًا إلى شكل سلسلة. تحول الدالة str() القيم إلى نموذج سلسلة بحيث يمكن دمجها مع سلاسل أخرى.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
بالنسبة للأرقام، تعمل العوامل القياسية، +، /، * بالطريقة المعتادة. لا يوجد عامل ++، لكن +=، و-=، وما إلى ذلك. إذا كنت تريد قسمة عدد صحيح، استخدم شرطتين مائلتين -- مثل 6 // 5 هو 1
"المطبوعة" عادةً ما تطبع عنصرًا أو أكثر من عناصر بايثون متبوعة بسطر جديد. "أوّلية" تكون السلسلة الحرفية مسبوقة بـ "r" ويمرر جميع الأحرف بدون معاملة خاصة للشرطات المائلة للخلف، لذلك r'x\nx' لتقييمه إلى سلسلة length-4 الخاصة 'x\nx'. "طباعة" يمكن أن تأخذ عدة وسيطات لتغيير طريقة الطباعة (راجع تعريف دالة الطباعة python.org) مثل إعداد "النهاية" إلى "" عدم طباعة سطر جديد بعد الانتهاء من طباعة جميع العناصر.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
طرق السلاسل
في ما يلي بعض أكثر طرق السلسلة شيوعًا. الطريقة أشبه بالدالة، لكنها تقوم بتشغيل "on" كائن. إذا كان المتغير s عبارة عن سلسلة، فإن التعليمة البرمجية s.lower() تشغّل طريقة Low() على كائن السلسلة هذا وتُرجع النتيجة (فكرة الطريقة التي تعمل على كائن ما هي إحدى الأفكار الأساسية التي تشكل البرمجة الموجهة للكائنات، OOP). في ما يلي بعض أكثر طرق السلسلة شيوعًا:
- s.lower(), s.upper() -- يؤدي إلى إرجاع إصدار الأحرف الصغيرة أو الكبيرة من السلسلة
- s.strip() -- لعرض سلسلة مع إزالة المسافة البيضاء من البداية والنهاية
- s.isalpha()/s.isdigital()/s.isspace()... -- تختبر ما إذا كانت جميع أحرف السلسلة في فئات الأحرف المختلفة
- s.startswith('other'), s.endswith('other') -- تختبر ما إذا كانت السلسلة تبدأ أو تنتهي بالسلسلة الأخرى المحددة.
- s.find('other') -- يبحث عن السلسلة الأخرى المحددة (وليس تعبيرًا عاديًا) داخل s، ويعرض أول فهرس حيث يبدأ أو -1 إذا لم يتم العثور عليه
- s.replace('old', 'new') -- يعرض سلسلة حيث جميع مواضع 'old' تم استبدالها بـ "جديد"
- s.split('delim') -- تعرض قائمة بالسلاسل الفرعية المفصولة بالمحدِّد المعين. المحدِّد ليس تعبيرًا عاديًا، بل نصًّا فقط. 'aaa,bbb,ccc'.split(',') -> ['aaa'، 'bbb'، 'ccc']. كحالة خاصة مناسبة s.split() (بدون وسيطات) يتم تقسيمها على جميع أحرف المسافات البيضاء.
- s.join(list) -- مقابل split()، يضم العناصر الموجودة في القائمة المحددة معًا باستخدام السلسلة كمُحدِّد. مثلاً: '---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
عملية بحث على Google عن "python str" إلى طرق سلسلة python.org الرسمية التي تسرد جميع طرق str.
ليس للغة بايثون نوع حرف منفصل. بدلاً من ذلك، يعرض تعبير مثل s[8] سلسلة-length-1 تحتوي على الحرف. باستخدام سلسلة-length-1، تعمل عوامل التشغيل ==, <=, ... كما هو متوقع، لذا لست بحاجة إلى معرفة أنّ بايثون ليس لديها مقياس "شار" منفصل. الكتابة.
شرائط السلاسل
"الشريحة" طريقة سهلة للإشارة إلى الأجزاء الفرعية من التسلسلات -- وهي عادةً السلاسل والقوائم. الشريحة s[start:end] هي العناصر التي تبدأ من البداية وتمتد حتى النهاية ولكن لا تشمل النهاية. لنفترض أن لدينا s = "مرحبًا"
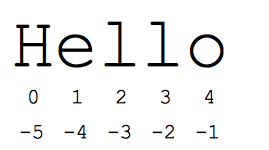
- s[1:4] هي 'ell' -- أحرف تبدأ بالفهرس 1 وتمتد حتى الفهرس 4 ولكن لا تشمله
- s[1:] هو 'ello' -- حذف القيم الافتراضية للفهرس في بداية السلسلة أو نهايتها
- s[:] هي "مرحبًا" - حذف كليهما يعطينا دائمًا نسخة من الأمر برمته (هذه هي الطريقة بايثونية لنسخ تسلسل مثل سلسلة أو قائمة)
- الحرف اللاتيني s[1:100] هو 'ello' -- يتم اقتطاع الفهرس الكبير جدًا وصولاً إلى طول السلسلة
تتيح أرقام الفهرس القياسية القائمة على الصفر سهولة الوصول إلى الأحرف بالقرب من بداية السلسلة. وكبديل لذلك، تستخدم بايثون الأرقام السالبة لتسهيل الوصول إلى الأحرف الموجودة في نهاية السلسلة: s[-1] هو آخر حرف 'o'، s[-2] هو 'l' الحرف التالي إلى الأخير، وهكذا. يتم احتساب أرقام الفهرس السالبة من نهاية السلسلة:
- s[-1] هو 'o' -- الحرف الأخير (الأول من النهاية)
- s[-4] هو 'e' -- الرابع من النهاية
- s[:-3] هو "هو" -- بحيث تصل إلى آخر 3 أحرف ولكن لا تشملها.
- s[-3:] هي 'llo' -- بدءًا من الحرف الثالث من النهاية ويمتد حتى نهاية السلسلة.
وهي حقيقة متقنة للشرائح، أي إذا كان أي فهرس n، s[:n] + s[n:] == s. وهذا ينطبق حتى مع عدد n سالب أو خارج الحدود. أو ضع بطريقة أخرى s[:n] وs[n:] دائمًا لتقسيم السلسلة إلى جزأين من السلسلة، مع الاحتفاظ بجميع الأحرف. وكما سنرى في قسم القائمة لاحقًا، تعمل الشرائح مع القوائم أيضًا.
تنسيق السلسلة
من بين الأشياء الجيدة التي يمكن أن تفعلها لغة بايثون تحويل الكائنات تلقائيًا إلى سلسلة مناسبة للطباعة. هناك طريقتان مضمّنتان لإجراء ذلك وهما سلسلة منسَّقة والأحرف الحرفية، وتسمى أيضًا "f-strings"، ويستدعي str.format().
القيم الحرفية للسلسلة المنسَّقة
سترى غالبًا قيمًا حرفية منسَّقة للسلسلة في حالات مثل:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
السلسلة الحرفية المنسَّقة تكون مسبوقة بـ "f" (مثل البادئة 'r' المستخدمة للسلاسل الأولية). أي نص خارج الأقواس المعقوفة '{}' تتم طباعتها مباشرةً. التعبيرات الموجودة في '{}' هي باستخدام مواصفات التنسيق الموضحة في مواصفات التنسيق هناك الكثير من الأشياء الرائعة التي يمكنك القيام بها باستخدام التنسيق بما في ذلك اقتطاع التحويل إلى التدوين العلمي والمحاذاة لليسار/اليمين/الوسط.
تعد السلاسل النصية مفيدة للغاية عندما ترغب في طباعة جدول كائنات وترغب في الأعمدة التي تمثل سمات الكائنات المختلفة لتتم محاذاتها مثل
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
% للسلسلة
تضم بايثون أيضًا منشأة قديمة تشبه printf() لتجميع سلسلة. يأخذ عامل النسبة % سلسلة تنسيق printf-type على اليسار (%d int، %s سلسلة، %f/%g نقطة عائمة)، والقيم المطابقة في صف على اليمين (يتكون الصف من قيم مفصولة بفواصل، تكون عادة داخل أقواس):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
السطر أعلاه طويل نوعًا ما -- لنفترض أنك تريد تقسيمه إلى أسطر منفصلة. لا يمكنك تقسيم السطر بعد علامة "%" كما تفعل في اللغات الأخرى، حيث إن بايثون تتعامل بشكل افتراضي مع كل سطر كعبارة منفصلة (وعلى الجانب الإيجابي، هذا هو السبب في أننا لا نحتاج إلى كتابة فواصل منقوطة على كل سطر). لإصلاح ذلك، ضع التعبير بأكمله في مجموعة خارجية من الأقواس -- ثم يُسمح للتعبير بالامتداد لتشمل أسطر متعددة. يعمل أسلوب التعابير البرمجية عبر الأسطر مع بُنى التجميع المختلفة والمفصّلة أدناه: ( )، [ ]، { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
هذا أفضل، لكن الخط لا يزال طويلاً بعض الشيء. تتيح لك لغة بايثون قطع أي سطر إلى أجزاء، حيث يتم إنشاء تسلسل له تلقائيًا بعد ذلك. إذًا، لنجعل هذا السطر أقصر، يمكننا إجراء ذلك:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
السلاسل (يونيكود مقابل البايت)
سلاسل بايثون العادية هي يونيكود.
تتيح بايثون أيضًا استخدام سلاسل مكونة من وحدات بايت عادية (يُشار إليها بالبادئة 'b' أمام السلسلة الحرفية) مثل:
> byte_string = b'A byte string' > byte_string b'A byte string'
سلسلة يونيكود هي نوع مختلف من الكائنات عن سلسلة البايت إلا أن المكتبات المتنوعة مثل تعمل التعبيرات العادية بشكل صحيح إذا تم تمرير أي من نوعي السلسلة.
لتحويل سلسلة Python عادية إلى بايت، يمكنك استدعاء طريقة encode() في السلسلة. بالاتجاه الآخر، تحوّل طريقة فك ترميز سلسلة بايت بايت وحدة البايت العادية المشفرة إلى سلسلة يونيكود:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
في قسم قراءة الملف، يوجد مثال يوضح كيفية فتح ملف نصي باستخدام نوع من الترميز وقراءة سلاسل يونيكود.
عبارة If
لا تستخدم بايثون { } لتضمين كتل رموز برمجية لـ if/loops/function وما إلى ذلك. بدلاً من ذلك، تستخدم بايثون النقطتين (:) والمسافة البادئة/المسافة البيضاء لتجميع العبارات. لا يلزم أن يكون الاختبار المنطقي لـ if بين قوسين (فرق كبير عن C++/Java)، ويمكن أن يحتوي على العبارتين *elif* و *else* (الذاكرة: كلمة "elif" هي نفس طول كلمة "else").
يمكن استخدام أي قيمة كدالة if-test. "الصفر" يتم احتساب جميع القيم على أنها خطأ: لا شيء، 0، سلسلة فارغة، قائمة فارغة، قاموس فارغ. هناك أيضًا نوع منطقي بقيمتين: True وFalse (يتم تحويلهما إلى عدد صحيح، وهما 1 و0). تتضمن بايثون عمليات المقارنة المعتادة: ==، !=، <، <=، >، >=. على عكس Java وC، يتم تحميل == بشكل زائد للعمل بشكل صحيح مع السلاسل. العوامل المنطقية هي الكلمات الإملائية *و*، *أو*، *not* (لا تستخدم بايثون النمط C && || !). في ما يلي الشكل الذي قد يبدو عليه الرمز لتطبيق متعلّق بالصحة يقدّم اقتراحات بخصوص المشروبات على مدار اليوم -- لاحظ كيف تبدأ كل مجموعة من عبارات البحث/الأخرى بـ : ويتم تجميع العبارات حسب المسافة البادئة:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
أجد أنّ حذف ":" هو الخطأ الأكثر شيوعًا في بناء الجملة عند الكتابة في النوع أعلاه من الرموز، ربما نظرًا لأن هذا شيء إضافي يجب كتابته مقارنةً بعادات C++/Java. أيضًا، لا تضع الاختبار المنطقي بين قوسين -- فهذا عادة C/Java. إذا كانت التعليمة البرمجية قصيرة، يمكنك وضع الرمز في نفس السطر بعد ":" مثل هذا (ينطبق هذا على الدوال والحلقات التكرارية وما إلى ذلك أيضًا)، على الرغم من أن بعض الأشخاص يشعرون أنه من الأسهل وضع مسافة للأشياء في أسطر منفصلة.
if time_hour < 10: print('coffee') else: print('water')
تمرين: string1.py
للتدرب على المواد الواردة في هذا القسم، جرِّب التمرين string1.py في التمارين الأساسية.