Python memiliki class string bawaan bernama "str" dengan banyak fitur berguna (ada modul lama bernama "string" yang tidak boleh Anda gunakan). Literal string dapat ditutup dengan tanda kutip ganda atau tunggal, meskipun tanda kutip tunggal lebih umum digunakan. Escape garis miring terbalik berfungsi seperti biasa dalam literal kutip tunggal dan ganda -- misalnya \n \ \". Literal string dengan tanda kutip ganda dapat berisi tanda kutip tunggal tanpa keributan (mis. "Saya tidak melakukannya") dan juga string yang dikutip tunggal dapat berisi tanda kutip ganda. Literal string dapat mencakup beberapa baris, tetapi harus ada garis miring terbalik \ di akhir setiap baris untuk meng-escape baris baru. Literal string di dalam tanda kutip tiga, """ atau ''', dapat mencakup beberapa baris teks.
String Python "tidak dapat diubah" yang berarti mereka tidak dapat diubah setelah dibuat (string Java juga menggunakan gaya yang tidak dapat diubah ini). Karena string tidak dapat diubah, kita membuat string *baru* selagi kita merepresentasikan nilai yang dihitung. Jadi, misalnya ekspresi ('hello' + 'there') menggunakan 2 string 'hello' dan 'di sana' dan membuat {i>string<i} baru 'hellothere'.
Karakter dalam string dapat diakses menggunakan sintaksis [ ] standar, dan seperti Java dan C++, Python menggunakan pengindeksan berbasis nol, jadi jika s adalah 'hello' s[1] adalah 'e'. Jika indeks melebihi batas untuk string, Python akan memunculkan error. Gaya Python (tidak seperti Perl) adalah berhenti jika tidak dapat mengetahui apa yang harus dilakukan, bukan hanya membuat nilai default. "Slice" yang praktis {i>syntax<i} (di bawah) juga bekerja untuk mengekstrak {i>substring<i} dari suatu {i>string<i}. Fungsi len(string) mengembalikan panjang {i>string<i}. Sintaks [ ] dan fungsi len() sebenarnya bekerja pada semua jenis urutan -- {i>string<i}, daftar, dll.. Python mencoba membuat operasinya bekerja secara konsisten pada berbagai jenis. Pengguna baru Python mendapat: jangan gunakan "len" sebagai nama variabel untuk menghindari pemblokiran fungsi len(). Tanda '+' operator dapat menggabungkan dua {i>string<i}. Perhatikan kode di bawah ini bahwa variabel tidak dideklarasikan sebelumnya -- cukup tetapkan ke variabel tersebut dan lanjutkan.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
Tidak seperti Java, tanda '+' tidak secara otomatis mengonversi angka atau jenis lainnya menjadi bentuk {i>string<i}. Fungsi str() mengubah nilai menjadi bentuk string sehingga dapat digabungkan dengan {i>string<i} lain.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
Untuk angka, operator standar, +, /, * berfungsi seperti biasa. Tidak ada operator ++, tetapi +=, -=, dll. berfungsi. Jika Anda ingin pembagian bilangan bulat, gunakan 2 garis miring -- misalnya 6 // 5 adalah 1
"Cetakan" fungsi biasanya mencetak satu atau beberapa item {i>python<i} diikuti oleh baris baru. "raw" literal string diawali dengan 'r' dan meneruskan semua karakter tanpa perlakuan khusus terhadap garis miring terbalik, jadi r'x\nx' mengevaluasi ke string length-4 'x\nx'. "cetak" dapat menggunakan beberapa argumen untuk mengubah cara mencetak sesuatu (lihat definisi fungsi cetak python.org) seperti menyetel "end" ke "" untuk tidak lagi mencetak baris baru setelah selesai mencetak semua item.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
Metode String
Berikut adalah beberapa metode {i>string<i} yang paling umum. Suatu metode sama seperti fungsi, tetapi berjalan "on" objek. Jika variabel s berupa string, maka kode s.lower() menjalankan metode lower() pada objek string tersebut dan menampilkan hasilnya (ide tentang metode yang berjalan pada objek ini merupakan salah satu ide dasar yang membentuk Object Oriented Programming, OOP). Berikut adalah beberapa metode string yang paling umum:
- s.lower(), s.upper() -- mengembalikan versi huruf kecil atau huruf besar dari {i>string<i}
- s.strip() -- mengembalikan string dengan spasi kosong yang dihapus dari awal dan akhir
- s.isalpha()/s.isdigit()/s.isspace()... -- menguji apakah semua karakter string berada dalam berbagai kelas karakter
- s.startswith('other'), s.endswith('other') -- menguji apakah string dimulai atau diakhiri dengan string lain yang diberikan
- s.find('other') -- mencari string lain yang diberikan (bukan ekspresi reguler) dalam s, dan mengembalikan indeks pertama tempatnya dimulai atau -1 jika tidak ditemukan
- s.override('old', 'new') -- menampilkan string dengan semua kemunculan 'old' telah diganti dengan 'baru'
- s.split('delim') -- mengembalikan daftar {i>substring<i} yang dipisahkan oleh pembatas yang diberikan. {i>Delimiter<i} bukan merupakan ekspresi reguler, melainkan hanya teks. 'aaa,bbb,ccc'.split(',') -> ['aaa', 'bbb', 'ccc']. Sebagai kasus khusus yang praktis, s.split() (tanpa argumen) akan memisahkan semua karakter spasi kosong.
- s.join(list) - kebalikan dari split(), menggabungkan elemen dalam daftar yang diberikan bersama-sama menggunakan {i>string<i} sebagai pembatas. mis. '---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
Penelusuran Google untuk "python str" akan mengarahkan Anda ke metode string python.org resmi yang mencantumkan semua metode str.
Python tidak memiliki jenis karakter terpisah. Sebagai gantinya, ekspresi seperti s[8] mengembalikan string-length-1 yang berisi karakter. Dengan {i>string-length-1<i} itu, operator ==, <=, ... semua berfungsi seperti yang Anda harapkan, jadi kebanyakan Anda tidak perlu tahu bahwa Python tidak memiliki "char" skalar yang terpisah. .
Slice String
"Slice" {i>syntax<i} adalah cara praktis untuk merujuk pada sub-bagian urutan -- biasanya {i>string<i} dan daftar. Potongan irisan[start:end] adalah elemen yang dimulai dari awal dan memanjang hingga tetapi tidak termasuk akhir. Misalkan kita memiliki s = "Hello"
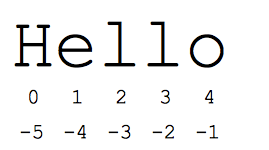
- s[1:4] adalah 'ell' -- karakter mulai dari indeks 1 dan berlanjut hingga tetapi tidak termasuk indeks 4
- s[1:] adalah 'ello' -- menghilangkan salah satu indeks secara default ke awal atau akhir string
- s[:] adalah 'Hello' -- menghilangkan keduanya selalu memberi kita salinan semuanya (ini adalah cara pythonic untuk menyalin urutan seperti string atau daftar)
- s[1:100] adalah 'ello' -- indeks yang terlalu besar dipotong hingga ke panjang string
Nomor indeks berbasis nol standar memberikan akses mudah ke karakter di dekat awal string. Sebagai alternatif, Python menggunakan angka negatif untuk memberikan akses mudah ke karakter di akhir {i>string<i}: s[-1] adalah karakter terakhir 'o', s[-2] adalah 'l' karakter berikutnya, dan seterusnya. Jumlah indeks negatif menghitung kembali dari akhir string:
- s[-1] adalah 'o' -- karakter terakhir (pertama dari akhir)
- s[-4] adalah 'e' -- Peringkat keempat dari akhir
- s[:-3] adalah 'Dia' -- naik tetapi tidak termasuk 3 karakter terakhir.
- s[-3:] adalah 'llo' -- dimulai dengan karakter ke-3 dari akhir dan diperluas ke akhir string.
Ini adalah susunan irisan yang rapi untuk setiap indeks n, s[:n] + s[n:] == s. Ini berfungsi bahkan untuk n negatif atau di luar batas. Atau dengan kata lain s[:n] dan s[n:] selalu mempartisi string menjadi dua bagian string, yang mempertahankan semua karakter. Seperti yang akan kita lihat di bagian daftar nanti, slice juga dapat digunakan dengan daftar.
Pemformatan string
Satu hal rapi yang dapat dilakukan {i>python<i} adalah mengonversi objek secara otomatis menjadi string yang cocok untuk pencetakan. Dua cara bawaan untuk melakukan ini adalah string berformat literal, juga disebut “f-strings”, dan memanggil str.format().
Literal string yang diformat
Anda akan sering melihat literal string berformat digunakan dalam situasi seperti:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
String literal berformat diawali dengan 'f' (seperti awalan 'r' yang digunakan untuk string mentah). Semua teks di luar tanda kurung kurawal '{}' akan dicetak secara langsung. Ekspresi yang dimuat dalam '{}' adalah dicetak menggunakan spesifikasi format yang dijelaskan dalam spesifikasi format. Ada banyak hal rapi yang dapat Anda lakukan dengan pemformatan, termasuk pemotongan dan konversi ke notasi ilmiah dan penyelarasan kiri/kanan/tengah.
{i>f-string<i} sangat berguna ketika Anda ingin mencetak tabel objek dan ingin kolom yang mewakili atribut objek yang berbeda untuk diselaraskan seperti
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
% String
Python juga memiliki fasilitas seperti printf() yang lebih lama untuk menyusun string. Operator % mengambil string format jenis printf di sebelah kiri (%d int, string %s, %f/%g floating point), dan nilai yang cocok dalam tuple di sebelah kanan (tuple dibuat dari nilai yang dipisahkan dengan koma, biasanya dikelompokkan di dalam tanda kurung):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
Baris di atas agak panjang -- misalnya Anda ingin membaginya menjadi baris terpisah. Anda tidak bisa begitu saja memisahkan garis setelah '%' seperti yang mungkin Anda lakukan dalam bahasa lain, karena secara default Python memperlakukan setiap baris sebagai pernyataan terpisah (di sisi positifnya, inilah mengapa kita tidak perlu mengetik titik koma di setiap baris). Untuk memperbaikinya, sertakan seluruh ekspresi dalam kumpulan tanda kurung luar -- maka ekspresi ini diizinkan untuk mencakup beberapa baris. Teknik kode lintas-garis ini berfungsi dengan berbagai konstruksi pengelompokan yang diperinci di bawah ini: ( ), [ ], { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Itu lebih baik, tetapi antreannya masih sedikit panjang. Python memungkinkan Anda memotong baris menjadi potongan-potongan, yang kemudian akan digabungkan secara otomatis. Jadi, untuk membuat baris ini lebih pendek, kita bisa melakukan ini:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
String (Unicode vs byte)
String Python reguler adalah unicode.
Python juga mendukung string yang terdiri dari byte biasa (ditunjukkan dengan awalan 'b' di depan literal string) seperti:
> byte_string = b'A byte string' > byte_string b'A byte string'
String unicode adalah tipe objek yang berbeda dari {i>string<i} byte tetapi berbagai pustaka seperti ekspresi reguler berfungsi dengan benar jika salah satu jenis string diteruskan.
Untuk mengonversi string Python reguler ke byte, panggil metode encode() pada string. Sebaliknya, metode decode() string byte mengonversi byte biasa yang dienkode menjadi string unicode:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
Di bagian pembacaan file, ada contoh yang menunjukkan cara membuka file teks dengan beberapa encoding dan membacakan string unicode.
Pernyataan If
Python tidak menggunakan { } untuk menutup blok kode untuk if/loops/function dll.. Sebagai gantinya, Python menggunakan titik dua (:) dan indentasi/spasi kosong ke pernyataan grup. Pengujian boolean untuk if tidak perlu berada dalam tanda kurung (perbedaan besar dari C++/Java) dan dapat memiliki klausa *elif* dan *else* (mnemonik: kata "elif" panjangnya sama dengan kata "else").
Setiap nilai dapat digunakan sebagai if-test. "Nol" semua nilai dihitung sebagai salah: Tidak ada, 0, string kosong, daftar kosong, kamus kosong. Ada juga tipe Boolean dengan dua nilai: True dan False (dikonversi menjadi int, yaitu 1 dan 0). Python memiliki operasi perbandingan biasa: ==, !=, <, <=, >, >=. Tidak seperti Java dan C, == kelebihan beban agar dapat bekerja dengan benar dengan {i>string<i}. Operator boolean adalah kata yang dieja *and*, *atau*, *not* (Python tidak menggunakan C-style && || !). Berikut ini tampilan kode untuk aplikasi kesehatan yang memberikan rekomendasi minuman sepanjang hari -- perhatikan bagaimana setiap blok pernyataan kemudian/else dimulai dengan : dan pernyataan tersebut dikelompokkan berdasarkan indentasinya:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
Saya mendapati bahwa menghilangkan ":" adalah kesalahan sintaks saya yang paling umum ketika mengetik kode semacam di atas, mungkin karena itu adalah hal tambahan yang harus diketik vs. kebiasaan C++/Java saya. Selain itu, jangan letakkan pengujian boolean dalam tanda kurung -- itu adalah kebiasaan C/Java. Jika kodenya pendek, Anda dapat meletakkan kode di baris yang sama setelah ":", seperti ini (ini juga berlaku untuk fungsi, loop, dll.), meskipun beberapa orang merasa lebih mudah dibaca untuk menempatkan kode di baris terpisah.
if time_hour < 10: print('coffee') else: print('water')
Latihan: string1.py
Untuk mempraktikkan materi di bagian ini, coba latihan string1.py di Latihan Dasar.