Python ha una classe stringa integrata denominata "str" con molte utili funzioni (esiste un modulo precedente denominato "string" che non dovresti usare). I valori letterali stringa possono essere racchiusi tra virgolette singole o doppie, sebbene siano più comunemente utilizzate le virgolette singole. I caratteri di escape con barra rovesciata funzionano come di consueto nei valori letterali con virgolette singole e doppie, ad esempio \n \' \", Un valore letterale stringa tra virgolette singole può contenere virgolette singole senza problemi (ad es. "Non l'ho fatto") e allo stesso modo una stringa tra virgolette può contenere virgolette doppie. Un valore letterale stringa può estendersi su più righe, ma deve essere presente una barra rovesciata \ alla fine di ogni riga per evitare la nuova riga. Stringhe letterali tra virgolette triple, """ o "'", possono estendersi su più righe di testo.
Le stringhe Python sono "immutabili" il che significa che non possono essere modificate dopo la creazione (anche le stringhe Java utilizzano questo stile immutabile). Poiché le stringhe non possono essere modificate, per rappresentare i valori calcolati, costruiamo *nuove* stringhe. Quindi, ad esempio, l'espressione ("hello" + "there") prende le 2 stringhe "hello" e "ci" e crea una nuova stringa "hellothere'.
È possibile accedere ai caratteri in una stringa utilizzando la sintassi standard [ ] e, come Java e C++, Python utilizza l'indicizzazione su base zero, quindi se s è "hello" s[1] è "e". Se l'indice non rientra nei limiti della stringa, Python genera un errore. Lo stile Python (a differenza di Perl) viene bloccato se non sa cosa fare, piuttosto che creare un valore predefinito. La pratica sezione la sintassi (di seguito) funziona anche per estrarre qualsiasi sottostringa da una stringa. La funzione len(string) restituisce la lunghezza di una stringa. La sintassi [ ] e la funzione len() funzionano effettivamente su qualsiasi tipo di sequenza: stringhe, elenchi ecc. Python cerca di far funzionare le operazioni in modo coerente su tipi diversi. Godcha per principianti Python: non usare "len" come nome di variabile per evitare di bloccare la funzione len(). Il "+" può concatenare due stringhe. Nota nel codice riportato di seguito che le variabili non sono pre-dichiarate, ma è sufficiente assegnarle e procedere.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
A differenza di Java, il tasto "+" non converte automaticamente numeri o altri tipi in formato stringa. La funzione str() converte i valori in una forma stringa in modo che possano essere combinati con altre stringhe.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
Per i numeri, gli operatori standard +, /, * funzionano come di consueto. Non è presente alcun operatore ++, ma +=, -= e così via funzionano. Se desideri la divisione di numeri interi, utilizza 2 barre, ad esempio 6 // 5 è 1
La "stampa" di solito stampa uno o più elementi Python seguiti da una nuova riga. Un modello "grezzo" il valore letterale stringa è preceduto dal prefisso "r" e passa tutti i caratteri senza utilizzare le barre rovesciate, quindi r'x\nx' restituisce la stringa length-4 "x\nx". "stampa" può prendere diversi argomenti per cambiare il modo in cui stampa i contenuti (vedi la definizione della funzione di stampa di Python), come impostazione "fine" a "" di non stampare più una nuova riga al termine della stampa di tutti gli elementi.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
Metodi con stringhe
Di seguito sono riportati alcuni dei metodi per le stringhe più comuni. Un metodo è simile a una funzione, ma viene eseguito "on" un oggetto. Se la variabile s è una stringa, il codice s.lower() esegue il metodo low() su quell'oggetto stringa e restituisce il risultato (l'idea di un metodo in esecuzione su un oggetto è una delle idee di base alla base della programmazione OOP). Ecco alcuni dei metodi per le stringhe più comuni:
- s.lower(), s.upper() -- restituisce la versione in lettere minuscole o maiuscole della stringa
- s.strip() -- restituisce una stringa con spazi vuoti rimossi dall'inizio e dalla fine
- s.isalpha()/s.isdigit()/s.isspace()... -- verifica se tutti i caratteri della stringa sono nelle varie classi di caratteri
- s.startswith('other'), s.endswith('other') -- verifica se la stringa inizia o termina con l'altra stringa specificata
- s.find('other'): cerca l'altra stringa specificata (non un'espressione regolare) all'interno di s e restituisce il primo indice nel punto in cui inizia o -1 se non viene trovato
- s.replace('old', 'new') -- restituisce una stringa in cui tutte le occorrenze di "old" sono state sostituite da "nuove"
- s.split('delim') -- restituisce un elenco di sottostringhe separate dal delimitatore specificato. Il delimitatore non è un'espressione regolare, è solo un testo. 'aaa,bbb,bbb'.split(',') -> ['aaa', 'bbb', 'Cc']. Come comodo caso speciale, s.split() (senza argomenti) si divide in base a tutti i caratteri di spazio vuoto.
- s.join(list) - di fronte a split(), unisce gli elementi nell'elenco fornito utilizzando la stringa come delimitatore. ad es. '---'.join(['aaa', 'bbb', 'Cc']) -> aaa---bbb---ccc
Una ricerca Google con "python str" dovrebbe portarti ai metodi stringa di python.org ufficiali che elencano tutti i metodi str.
Python non ha un tipo di carattere separato. Al contrario, un'espressione come s[8] restituisce una stringa-length-1 contenente il carattere. Con questa stringa-length-1, gli operatori ==, <=, ... funzionano tutti come ci si aspetterebbe, quindi per lo più non è necessario sapere che Python non ha un "car" scalare separato di testo.
Sezioni di stringhe
La "sezione" la sintassi è un modo pratico per fare riferimento a sottoparti di sequenze, in genere stringhe ed elenchi. La sezione s[start:end] corrisponde agli elementi che iniziano dall'inizio e si estendono fino alla fine esclusa. Supponiamo di avere s = "Ciao"
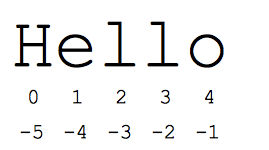
- s[1:4] è "ell" -- caratteri che iniziano da indice 1 e si estendono fino all'indice 4 escluso
- s[1:] è "ello" -- omettendo uno dei due indici, il valore predefinito sarà l'inizio o la fine della stringa
- s[:] è "Ciao" - omettendo entrambi, si ottiene sempre una copia del tutto (questo è il metodo Python per copiare una sequenza come una stringa o un elenco).
- s[1:100] è "ello" -- un indice troppo grande viene troncato alla lunghezza della stringa
Gli indici standard in base zero consentono di accedere facilmente ai caratteri vicini all'inizio della stringa. In alternativa, Python utilizza numeri negativi per dare facile accesso ai caratteri alla fine della stringa: s[-1] è l'ultimo carattere "o", s[-2] è "l" il penultimo carattere e così via. I numeri di indice negativi vengono conteggiati a partire dalla fine della stringa:
- s[-1] è "o" -- ultimo carattere (1° dalla fine)
- s[-4] è "e" -- 4° dalla fine
- s[:-3] è "Lui" -- andando fino agli ultimi 3 caratteri esclusi.
- s[-3:] è "llo" -- che inizia con il terzo carattere dalla fine e si estende fino alla fine della stringa.
Si tratta di una vergogna estrema sulle sezioni che, per qualsiasi indice, è s[:n] + s[n:] == s. Funziona anche per n valori negativi o fuori limite. Oppure, in un altro modo, s[:n] e s[n:] suddividono sempre la stringa in due parti, conservando tutti i caratteri. Come vedremo più avanti nella sezione dell'elenco, le sezioni funzionano anche con gli elenchi.
Formattazione delle stringhe
Python può convertire automaticamente gli oggetti una stringa adatta alla stampa. Due modi integrati per farlo: la stringa formattata chiamati anche "f-strings" e richiamando str.format().
Valori letterali stringa formattati
Spesso vedrai valori letterali stringa formattati utilizzati in situazioni come:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
Una stringa letterale formattata è preceduta dal prefisso "f" (come il prefisso "r" per le stringhe non elaborate). Qualsiasi testo esterno alle parentesi graffe "{}" vengono stampati direttamente. Espressioni contenute in "{}" sono vengono stampati utilizzando le specifiche del formato descritte in le specifiche del formato. Ci sono molte cose interessanti che puoi fare con la formattazione, tra cui troncamento e conversione in notazione scientifica e allineamento a sinistra/destra/centro.
le f-string sono molto utili quando desideri stampare una tabella di oggetti e vuoi le colonne che rappresentano i vari attributi degli oggetti devono essere allineate
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
% stringa
Python ha anche una vecchia funzionalità simile a Printf() per creare una stringa. L'operatore % prende una stringa di formato di tipo Printf a sinistra (%d int, stringa %s, %f/%g in virgola mobile) e i valori corrispondenti in una tupla a destra (una tupla è composta da valori separati da virgole, generalmente raggruppati tra parentesi):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
La riga riportata qui sopra è piuttosto lunga. Supponiamo che tu voglia suddividerla in righe separate. Non puoi semplicemente dividere la riga dopo "%" come in altri linguaggi, poiché per impostazione predefinita Python considera ogni riga come un'istruzione separata (sul lato positivo, questo è il motivo per cui non è necessario digitare punti e virgola su ogni riga). Per risolvere questo problema, racchiudi l'intera espressione in una parentesi esterna. In seguito, l'espressione può estendersi su più righe. Questa tecnica basata sul codice funziona con i vari costrutti di raggruppamento descritti di seguito: ( ), [ ], { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Meglio, ma la linea è ancora un po' lunga. Python consente di dividere una riga in blocchi, che verranno poi concatenati automaticamente. Quindi, per rendere questa riga ancora più corta, possiamo fare questo:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Stringhe (Unicode e byte)
Le stringhe Python normali sono Unicode.
Python supporta anche stringhe composte da byte semplici (indicati dal prefisso "b" davanti a un valore letterale stringa) come:
> byte_string = b'A byte string' > byte_string b'A byte string'
Una stringa Unicode è un tipo diverso di oggetto rispetto a una stringa di byte, ma varie librerie come le espressioni regolari funzionano correttamente se vengono trasmessi entrambi i tipi di stringa.
Per convertire una stringa Python regolare in byte, chiama il metodo encode() sulla stringa. Andando nell'altra direzione, il metodo decode() della stringa di byte converte i byte semplici codificati in una stringa Unicode:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
Nella sezione relativa alla lettura dei file, è presente un esempio che mostra come aprire un file di testo con una certa codifica e leggere le stringhe Unicode.
Dichiarazione IF
Python non utilizza { } per racchiudere blocchi di codice per if/loops/function ecc.. Python utilizza invece i due punti (:) e il rientro/spazio vuoto per raggruppare le istruzioni. Il test booleano per un "if" non deve necessariamente essere tra parentesi (molto differenza rispetto a C++/Java) e può avere clausole *elif* e *else* (mnemonico: la parola "elif" è della stessa lunghezza della parola "else").
Qualsiasi valore può essere utilizzato come if-test. Lo "zero" i valori vengono tutti conteggiati come false: nessuno, 0, stringa vuota, elenco vuoto, dizionario vuoto. Esiste anche un tipo booleano con due valori: True e False (convertiti in un numero intero, ovvero 1 e 0). Python esegue le consuete operazioni di confronto: ==, !=, <, <=, >, >=. A differenza di Java e C, == è sovraccarico per funzionare correttamente con le stringhe. Gli operatori booleani sono le parole digitate *e*, *or*, *not* (Python non utilizza lo stile C && || !). Ecco come potrebbe presentarsi il codice per un'app per la salute che fornisce consigli sulle bevande durante la giornata. Nota come ogni blocco di istruzioni "then" o "else" inizia con un simbolo ":" e le istruzioni sono raggruppate per rientro:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
Ho notato che omettendo il carattere ":" è l'errore di sintassi più comune quando digito il tipo di codice sopra indicato, probabilmente perché è un'altra cosa da digitare rispetto alle mie abitudini C++/Java. Inoltre, non mettere il test booleano tra parentesi perché è un'abitudine in C/Java. Se il codice è breve, puoi inserirlo nella stessa riga dopo il carattere ":", in questo modo (questo vale anche per le funzioni, i loop e così via), anche se alcune persone ritengono che sia più leggibile distanziare i valori su righe separate.
if time_hour < 10: print('coffee') else: print('water')
Esercizio: string1.py
Per esercitarti con il materiale di questa sezione, prova l'esercizio string1.py negli Esercizi di base.