Python には「str」という名前の文字列クラスが組み込まれている多くの便利な機能があります(「string」という名前の古いモジュールもありますが、使用すべきではありません)。文字列リテラルは二重引用符または一重引用符で囲むことができますが、一重引用符がより一般的に使用されます。バックスラッシュによるエスケープは、一重引用符と二重引用符で囲まれたリテラルの両方で通常どおり機能します。\n \をご覧ください。二重引用符で囲まれた文字列リテラルには、簡単に一重引用符を含めることができ(例: 「私はそれを実行しませんでした」)。同様に、一重引用符で囲まれた文字列にも二重引用符を含めることができます。文字列リテラルは複数の行にまたがっても構いませんが、改行をエスケープするには、各行の末尾にバックスラッシュ \ が必要です。三重引用符で囲まれた文字列リテラル(""")複数行のテキストにまたがります。
Python の文字列は「不変」であるつまり、作成後に変更することはできません(Java 文字列でも、この不変スタイルが使用されます)。文字列は変更できないため、計算された値を表すときに *新しい* 文字列を作成します。たとえば、式 ('hello' + 'there') は 2 つの文字列 'hello' を受け取ります。「there」は新しい文字列「hellothere」が作成されます。
文字列内の文字には標準の [ ] 構文を使用してアクセスできます。Java や C++ と同様に、Python ではゼロベースのインデックスを使用するため、s が「hello」の場合、s[1] は「e」です。インデックスが文字列の境界外にある場合、Python でエラーが発生します。Python のスタイルは(Perl とは異なり)、デフォルト値を作り出すのではなく、処理内容がわからない場合に停止します。便利な「スライス」構文(下記)も機能します。文字列から任意の部分文字列を抽出することもできます。len(string) 関数は文字列の長さを返します。[ ] 構文と len() 関数は、実際には文字列やリストなど、どのようなシーケンス型でも機能します。Python は、さまざまな型にわたって操作が一貫して動作するようにします。Python 初心者向けの注意点: 「len」を使用しない変数名として使用する必要があります。「+」演算子は 2 つの文字列を連結できます。以下のコードでは、変数が事前に宣言されていません。変数に代入して実行してください。
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
Java とは異なり、「+」はは数値やその他の型を自動的に文字列形式に変換しません。str() 関数は、値を文字列形式に変換して、他の文字列と結合できるようにします。
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
数値の場合、標準演算子である +、/、* は通常どおりに機能します。++ 演算子はありませんが、+=、-= などは機能します。整数の除算を行う場合は、2 つのスラッシュを使用します(例:6 // 5 は 1 である
「印刷」関数は通常、Python の項目を 1 つ以上出力し、その後に改行を続けます。「raw」文字列リテラルの先頭に「r」が付きますバックスラッシュの特別な処理なしですべての char を渡します。したがって、r'x\nx'長さ 4 の文字列「x\nx」に評価されます。 「print」次のように複数の引数を取り、出力方法を変更できます(python.org の print 関数の定義をご覧ください)。 「end」の設定""のすべての項目の印刷が終了した後に、改行が出力されないようにしました。
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
String メソッド
最も一般的な文字列メソッドを以下に示します。メソッドは関数に似ていますが、「オン」で作成します。変数 s が文字列の場合、コード s.lower() は文字列オブジェクトに対して lower()メソッドを実行し、結果を返します(オブジェクトで実行されるメソッドという考え方は、オブジェクト指向プログラミング(OOP)を構成する基本的な考え方の一つです)。最も一般的な文字列メソッドを以下に示します。
- s.lower(), s.upper() -- 小文字または大文字の文字列を返します
- s.strip() -- 先頭と末尾の空白文字を削除した文字列を返します
- s.isalpha()/s.isdigit()/s.isspace()... -- すべての文字列文字がさまざまな文字クラスに含まれているかどうかをテストします。
- s.startswith('other'), s.endswith('other') -- 文字列が指定された他の文字列で開始されるか終了するかをテストします
- s.find('other') -- s 内で指定された他の文字列(正規表現ではない)を検索し、その文字列で始まる最初のインデックスを返します。見つからない場合は -1 を返します。
- s.replace('old', 'new') -- すべての 'old' を含む文字列を返します。「new」に置き換えられています
- s.split('delim') -- 指定された区切り文字で区切られた部分文字列のリストを返します。区切り文字は正規表現ではなく、単なるテキストです。'aaa,bbb,ccc'.split(',') ->['aaa', 'bbb', 'ccc']。便利な特殊なケースとして、s.split() は(引数なし)、すべての空白文字で分割します。
- s.join(list) -- split() の逆で、文字列を区切り文字として使用して、指定されたリスト内の要素を結合します。例:'---'.join(['aaa', 'bbb', 'ccc']) ->aaa---bbb---ccc
Google で「python str」を検索するすべての str メソッドを一覧表示した公式の python.org 文字列メソッドが表示されます。
Python には個別の文字型はありません。代わりに、s[8] のような式は、文字を含む string-length-1 を返します。この文字列の長さ-1 では、==、<=、... などの演算子はすべて期待どおりに機能します。そのため、Python に別のスカラー「char」があることをほとんど知る必要はありません。あります。
文字列スライス
「スライス」構文は、シーケンスのサブ部分(通常は文字列やリスト)を参照するのに便利な方法です。スライス s[start:end] は、開始位置から終了位置まで続く要素です。終了点は含まれません。s = "Hello" であるとします。
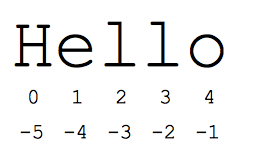
- s[1:4] は「ell」です。-- インデックス 1 から始まり、インデックス 4 を含まない文字。
- s[1:] は「ello」です-- どちらかのインデックスを省略すると、デフォルトで文字列の先頭か末尾になります
- s[:] は「Hello」である-- 両方を省略すると、常に全体のコピーが得られます(これは、文字列やリストなどのシーケンスをコピーする Python の方法です)。
- s[1:100] は 'ello'-- 大きすぎるインデックスを文字列長まで切り捨てる
標準のゼロベースのインデックス番号を使用すると、文字列の先頭付近の文字に簡単にアクセスできます。代わりに、Python は負の数を使用して、文字列の末尾の文字に簡単にアクセスできるようにします。s[-1] は最後の文字「o」、s[-2] は「l」最後から 2 番目の文字などを照合できます。負のインデックス番号は、文字列の末尾からカウントされます。
- s[-1] は「o」-- 最後の文字(末尾から 1 文字)
- s[-4] は「e」です。-- 末尾から 4 番目
- s[:-3] は「He」-- 最後の 3 文字は除く。
- s[-3:] は「llo」-- 末尾から 3 文字目から文字列の末尾まで。
これは、任意のインデックス n(s[:n] + s[n:] == s)に対するスライスの単純な事実です。これは、n 個の負の数や境界外の場合にも有効です。言い換えると、s[:n] と s[n:] では常に文字列を 2 つの文字列部分に分割し、すべての文字を節約します。後述のリストセクションで説明するように、スライスはリストでも機能します。
文字列の形式
Python でできることの一つは オブジェクトを自動的に変換し 出力に適した文字列です。これを行うための 2 つの組み込み方法は、書式設定された文字列です。 リテラル(「f-strings」とも呼ばれます)、str.format() の呼び出し。
フォーマットされた文字列リテラル
フォーマット済み文字列リテラルは、次のような状況でよく使用されます。
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
書式設定されたリテラル文字列の先頭には「f」が付きます。(未加工の文字列に使用される接頭辞「r」など)。 中かっこ「{}」の外のテキスト直接出力されます。「{}」に含まれる式 記載されている形式仕様に従って出力されます。 形式の仕様を確認してください 書式には、文字の切り捨てや 指数表記への変換や左右中央揃えでの変換です。
f 文字列は、物体の表を出力したいときに非常に便利です。 さまざまなオブジェクト属性を表す列が
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
文字列 %
Python には、文字列をまとめるための古い printf() のような機能もあります。% 演算子は、左側に printf 型のフォーマット文字列(%d int、%s 文字列、%f/%g 浮動小数点)と、右側にタプル内の一致する値(タプルはカンマで区切られた値で構成され、通常は括弧でグループ化された値)を受け取ります。
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
上記の行は長すぎます。2 行に分割するとします。「%」の後の行を分割することはできませんこれは Python のデフォルトでは各行を別々のステートメントとして扱うためです(プラスの面では、各行でセミコロンを入力する必要がないのはそのためです)。これを修正するには、式全体を外側の括弧で囲みます。この場合、式を複数行にわたって記述できます。この行をまたいだこの手法は、下記のさまざまなグループ化構造で機能します: ( )、[ ]、{ }。
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
良い例ですが、行列が少し長くなっています。Python では、線をチャンクに分割すると、自動的に連結されます。この行をさらに短くするには、次のようにします。
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
文字列(Unicode とバイト)
通常の Python 文字列は Unicode です。
Python では、書式なしバイト(文字列リテラルの前に接頭辞「b」で示される)で構成される文字列もサポートされます。 例:
> byte_string = b'A byte string' > byte_string b'A byte string'
Unicode 文字列はバイト文字列とは異なる型のオブジェクトですが、 正規表現は、いずれかのタイプの文字列を渡しても正しく機能します。
通常の Python 文字列をバイトに変換するには、文字列に対して encode() メソッドを呼び出します。逆方向には、バイト文字列 decode() メソッドで、エンコードされた書式なしバイトを Unicode 文字列に変換します。
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
ファイル読み取りセクションに、エンコードを使用してテキスト ファイルを開き、Unicode 文字列を読み取る方法を示す例があります。
if ステートメント
Python では、if/loops/function などのコードブロックを囲むために { } を使用しません。その代わりに、Python ではコロン(:)とインデント/空白文字を使用してステートメントをグループ化します。if のブール値テストでは、かっこで囲む必要はありません(C++/Java との大きな違い)。また、*elif* 句と *else* 句を含めることができます(ニーモニック: 「elif」という単語の長さは「else」という単語と同じ長さです)。
任意の値を if-test として使用できます。「ゼロ」値はすべて false としてカウントされます(なし、0、空の文字列、空のリスト、空の辞書)。True と False の 2 つの値を持つブール値型もあります(int に変換され、これらは 1 と 0 です)。Python には通常の比較演算(==、!=、<、<=、>、>=)があります。Java や C とは異なり、== は文字列で正しく動作するようにオーバーロードされます。ブール演算子は、*and*、*or*、*not* というスペルアウトされた単語です(Python では C スタイルの && || ! は使用しません)。1 日を通して飲み物のレコメンデーションを提供する健康アプリのコードは次のようになります。then/else ステートメントの各ブロックが : で始まり、ステートメントがインデントでグループ化されていることに注目してください。
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
「:」を省略すると、上記のようなコードを入力する際に最もよくある構文のミスです。おそらく、C++/Java の習慣ではなく、入力が必要な追加のものだからです。また、ブール値のテストをかっこで囲まないでください。これは C/Java の習慣です。コードが短い場合は、このように「:」の後の同じ行にコードを配置します(これは関数やループなどにも当てはまります)。ただし、行を区切った方が読みやすいと感じる人もいます。
if time_hour < 10: print('coffee') else: print('water')
演習: string1.py
このセクションの内容を練習するには、基本演習の string1.py の演習をお試しください。