Python에는 'str'이라는 기본 제공 문자열 클래스가 있습니다. (사용하지 말아야 할 'string'이라는 이전 모듈이 있음) 문자열 리터럴은 큰따옴표 또는 작은따옴표로 묶을 수 있지만 작은따옴표가 더 일반적으로 사용됩니다. 백슬래시 이스케이프는 작은따옴표와 큰따옴표로 묶인 리터럴 모두에서 일반적인 방식으로 작동합니다. 예를 들어 \n \' \' 큰따옴표로 묶인 문자열 리터럴은 복잡하지 않은 작은따옴표를 포함할 수 있으며 (예: "I was it not do it")과 마찬가지로 작은따옴표로 묶인 문자열에도 큰따옴표가 포함될 수 있습니다. 문자열 리터럴은 여러 줄에 걸쳐 있을 수 있지만 줄바꿈을 이스케이프하려면 각 줄 끝에 백슬래시(\)가 있어야 합니다. 삼중따옴표 안의 문자열 리터럴, """ 여러 줄의 텍스트로 구성할 수 있습니다.
Python 문자열은 '변경할 수 없습니다'. 즉, 생성된 후에는 변경할 수 없습니다 (Java 문자열도 이 불변 스타일을 사용합니다). 문자열은 변경할 수 없으므로 계산된 값을 나타내기 위해 *새* 문자열을 생성합니다. 예를 들어 표현식 ('hello' + 'there')는 2개의 문자열 'hello'를 받습니다. 그리고 '거기'가 새로운 문자열 'hellothere'을 빌드합니다.
문자열의 문자는 표준 [ ] 구문을 사용하여 액세스할 수 있으며, Java 및 C++와 마찬가지로 Python은 0 기반 색인 생성을 사용하므로 s가 'hello'인 경우 s[1] 은 'e'입니다. 색인이 문자열의 범위를 벗어나면 Python에서 오류가 발생합니다. Perl과 달리 Python 스타일은 기본값을 구성하는 대신 무엇을 해야 할지 결정하지 못하는 경우 중단합니다. 편리한 '슬라이스' 구문 (아래)도 문자열에서 하위 문자열을 추출할 수 있습니다. len(string) 함수는 문자열의 길이를 반환합니다. [ ] 구문과 len() 함수는 실제로 문자열, 목록 등 모든 시퀀스 유형에서 작동합니다. Python은 여러 유형에서 작업이 일관되게 작동하도록 합니다. Python 초보자를 위한 참고사항: 'len'을 사용하지 마세요. len() 함수를 차단하지 않아도 됩니다. 맨 앞에 있는 '+'는 연산자는 두 문자열을 연결할 수 있습니다. 아래 코드에서 변수는 사전 선언되지 않습니다. 변수에 할당하기만 하면 됩니다.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
Java와 달리 '+'는 는 숫자나 다른 유형을 문자열 형식으로 자동 변환하지 않습니다. str() 함수는 다른 문자열과 결합할 수 있도록 값을 문자열 형식으로 변환합니다.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
숫자의 경우 표준 연산자 +, /, * 가 일반적인 방식으로 작동합니다. ++ 연산자는 없지만 +=, -= 등은 작동합니다. 정수 나눗셈을 사용하려면 슬래시 2개를 사용합니다. 예: 6 // 5는 1입니다.
'인쇄' 함수는 일반적으로 하나 이상의 Python 항목 뒤에 줄바꿈을 출력합니다. '원시' 문자열 리터럴 앞에 'r'이 있음 백슬래시의 특별한 처리 없이 모든 문자를 통과하므로 r'x\nx' 길이 4 문자열 'x\nx'로 평가됩니다. 'print' 여러 인수를 사용하여 출력 방식을 변경할 수 있습니다 (python.org 출력 함수 정의 참조). 'end' 설정 대상: "" 모든 항목의 인쇄가 완료된 후 더 이상 줄바꿈을 출력하지 않습니다.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
문자열 메서드
다음은 가장 일반적인 문자열 메서드입니다. 메서드는 함수와 같지만 'on'에서 실행됩니다. 객체입니다. 변수 s가 문자열이면 코드 s.lower()가 해당 문자열 객체에서 lower() 메서드를 실행하고 결과를 반환합니다. 객체에서 실행되는 메서드에 관한 개념은 객체 지향 프로그래밍 (OOP)을 구성하는 기본 개념 중 하나입니다. 다음은 가장 일반적인 문자열 메서드입니다.
- s.lower(), s.upper() -- 문자열의 소문자 또는 대문자 버전을 반환합니다.
- s.strip() -- 시작과 끝에서 공백이 삭제된 문자열을 반환합니다.
- s.isalpha()/s.isdigit()/s.isspace()... -- 모든 문자열 문자가 다양한 문자 클래스에 있는지 테스트합니다.
- s.startswith('other'), s.endswith('other') -- 문자열이 지정된 다른 문자열로 시작하거나 끝나는지 테스트합니다.
- s.find('other') -- s 내에서 주어진 다른 문자열 (정규 표현식이 아님)을 검색하고 해당 문자열이 시작되는 첫 번째 색인을 반환하고 찾을 수 없는 경우 -1을 반환합니다.
- s.replace('old', 'new') -- 'old'가 모두 나오는 문자열을 반환합니다. 'new'로 대체되었습니다.
- s.split('delim') -- 지정된 구분 기호로 구분된 하위 문자열 목록을 반환합니다. 구분자는 정규 표현식이 아니라 텍스트입니다. 'aaa,bbb,ccc'.split(',') -> ['aaa', 'bbb', 'ccc'] 등입니다. 편리한 특수 사례로 s.split() (인수 없음) 는 모든 공백 문자로 분할합니다.
- s.join(list) -- split()과 반대이며 문자열을 구분 기호로 사용하여 지정된 목록의 요소를 결합합니다. 예: '---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
'python str'에 대한 Google 검색 모든 문자열 메서드가 나열된 공식 python.org 문자열 메서드로 안내되어야 합니다.
Python에는 별도의 문자 유형이 없습니다. 대신 s[8] 과 같은 표현식은 문자를 포함하는 string-length-1을 반환합니다. 이 string-length-1을 사용하면 연산자 ==, <=, ... 모두 예상대로 작동하므로 대부분 Python에 별도의 스칼라 '문자'가 없다는 것을 알 필요가 없습니다. 있습니다.
슬라이스
'슬라이스' 구문은 시퀀스의 하위 부분(일반적으로 문자열과 목록)을 참조할 수 있는 편리한 방법입니다. 슬라이스 s[start:end] 는 시작 부분에서 시작하여 끝부분까지는 포함되지 않는 요소입니다. s = "Hello"라고 가정합니다.
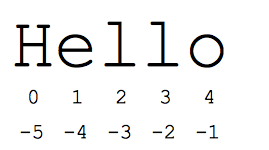
- s[1:4] 는 'ell' -- 색인 1에서 시작하여 색인 4까지 확장되지만 색인 4까지 포함되지 않는 문자
- s[1:] 는 'ello' -- 색인을 생략하면 기본적으로 문자열의 시작 또는 끝이 됩니다.
- s[:] 는 'Hello'입니다. -- 둘 다 생략하면 항상 전체의 사본이 제공됩니다. 이는 문자열이나 목록과 같은 시퀀스를 복사하는 비구단적인 방법입니다.
- s[1:100] 'ello' -- 색인이 너무 크면 문자열 길이로 잘립니다.
0부터 시작하는 표준 색인 번호를 사용하면 문자열 시작 부분 근처의 문자에 쉽게 액세스할 수 있습니다. 또는 Python은 음수를 사용하여 문자열 끝에 있는 문자에 쉽게 액세스할 수 있도록 합니다. s[-1] 은 마지막 문자 'o', s[-2] 는 'l'입니다. 다음 문자 등입니다. 음수 색인 숫자는 문자열 끝에서 다시 계산됩니다.
- s[-1] 은 'o'입니다. -- 마지막 문자 (끝부터 첫 번째)
- s[-4] 는 'e'입니다. -- 끝에서 4번째
- s[:-3] 은 '그' 마지막 3자까지 올라가지만 포함되지 않습니다.
- s[-3:] 은 'llo'입니다. -- 끝에서 세 번째 문자부터 시작하여 문자열 끝까지 이어집니다.
모든 색인 n에 대해 s[:n] + s[n:] == s인 슬라이스의 깔끔한 원칙입니다. 이는 n 음수이거나 범위를 벗어난 경우에도 작동합니다. 즉, s[:n] 및 s[n:] 은 항상 문자열을 두 개의 문자열 부분으로 나누어 모든 문자를 보존합니다. 나중에 목록 섹션에서 살펴보겠지만 슬라이스는 목록에도 사용할 수 있습니다.
문자열 형식 지정
Python이 할 수 있는 한 가지 멋진 일은 객체를 자동으로 출력에 적합한 문자열입니다. 이를 위한 두 가지 기본 제공 방법은 문자열 형식 지정입니다. 리터럴("f-strings"이라고도 함)을 사용하고 str.format()을 호출합니다.
형식이 지정된 문자열 리터럴
다음과 같은 상황에서 사용되는 형식이 지정된 문자열 리터럴이 자주 사용됩니다.
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
형식이 지정된 리터럴 문자열에는 'f'가 접두사로 붙습니다. (원시 문자열에 사용되는 'r' 접두사 등) 중괄호 '{}' 밖의 텍스트 출력됩니다. '{}'에 포함된 식 입니다 는 형식 사양을 참고하세요 텍스트에는 자르기, 텍스트 줄바꿈 등 다양한 서식 지정 기능이 과학적 표기법 및 왼쪽/오른쪽/중앙 정렬로 변환할 수 있습니다.
f-문자열은 객체의 표를 출력하고 싶을 때 정렬될 다른 객체 속성을 나타내는 열
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
문자열 비율
Python에는 문자열을 조합하는 오래된 printf()와 유사한 기능도 있습니다. % 연산자는 왼쪽에서 printf 유형의 형식 문자열 (%d int, %s 문자열, %f/%g 부동 소수점)을 가져오고 오른쪽의 튜플에 일치하는 값을 가져옵니다 (튜플은 쉼표로 구분된 값으로 구성되며 일반적으로 괄호 안에 그룹화됨).
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
위의 줄은 약간 깁니다. 여러 줄로 나누고 싶다고 가정해 보겠습니다. '%' 뒤의 선을 분할할 수는 없습니다. 기본적으로 Python은 각 줄을 별도의 명령문으로 취급하기 때문입니다 (긍정적인 면이 있기 때문에 각 줄에 세미콜론을 입력할 필요가 없음). 이 문제를 해결하려면 표현식 전체를 바깥쪽 괄호 쌍으로 묶습니다. 그러면 표현식이 여러 줄에 걸쳐 표시될 수 있습니다. 이러한 코드 전반적 기법은 아래에 설명된 다양한 그룹화 구성( ), [ ], { }에서 작동합니다.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
더 낫지만 아직 줄이 조금 깁니다. Python을 사용하면 줄을 청크로 잘라낸 다음 자동으로 연결할 수 있습니다. 이 줄을 더 짧게 만들기 위해 다음과 같이 할 수 있습니다.
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
문자열 (유니코드와 바이트)
일반 Python 문자열은 유니코드입니다.
Python은 일반 바이트로 구성된 문자열도 지원합니다 (문자열 리터럴 앞에 접두사 'b'로 표시됨). 예를 들면 다음과 같습니다.
> byte_string = b'A byte string' > byte_string b'A byte string'
유니코드 문자열은 바이트 문자열과 다른 유형의 객체이지만, 정규 표현식은 두 가지 유형의 문자열을 전달하면 올바르게 작동합니다.
일반 Python 문자열을 바이트로 변환하려면 문자열에서 encode() 메서드를 호출합니다. 다른 방향으로 byte string decode() 메서드는 인코딩된 일반 바이트를 유니코드 문자열로 변환합니다.
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
파일 읽기 섹션에는 인코딩이 포함된 텍스트 파일을 열고 유니코드 문자열을 읽는 방법을 보여주는 예가 있습니다.
If 문
Python은 if/loops/function 등의 코드 블록을 묶는 데 { }를 사용하지 않습니다. 대신 Python은 콜론 (:)과 들여쓰기/공백을 사용하여 문을 그룹화합니다. if에 대한 불리언 테스트는 괄호 안에 있을 필요가 없으며 (C++/Java와 큰 차이), *elif* 및 *else* 절이 있을 수 있습니다 (니모닉: 단어 'elif'는 단어 'else'와 길이가 같음).
모든 값을 if-test로 사용할 수 있습니다. '0' 값은 모두 false로 간주됩니다(없음, 0, 빈 문자열, 빈 목록, 빈 사전). True와 False라는 두 개의 값이 있는 부울 유형도 있습니다 (정수로 변환되면 1과 0임). Python에는 일반적인 비교 연산(==, !=, <, <=, >, >=)이 있습니다. Java 및 C와 달리 == 은 문자열로 올바르게 작동하도록 오버로드됩니다. 부울 연산자는 *and*, *or*, *not*으로 표기된 단어입니다(Python은 C 스타일 && || !를 사용하지 않음). 다음은 하루 종일 음료 추천을 제공하는 건강 앱의 코드는 다음과 같습니다. when/else 구문의 각 블록이 :로 시작하고 문은 들여쓰기로 그룹화됩니다.
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
':'가 생략된 것으로 확인되었습니다. 위의 코드를 입력할 때 가장 흔하게 발생하는 문법 실수는 아마도 C++/Java 습관에 비해 입력해야 하는 추가 항목이기 때문일 것입니다. 또한 불리언 테스트를 괄호로 묶지 마세요. 이는 C/Java 습관입니다. 코드가 짧으면 다음과 같이 ':' 다음에 코드를 같은 줄에 배치할 수 있습니다 (함수, 루프 등에도 적용됨). 다만 일부 사람들은 별도의 행에 간격을 두는 것이 더 읽기 쉽다고 생각합니다.
if time_hour < 10: print('coffee') else: print('water')
연습문제: string1.py
이 섹션의 자료를 연습하려면 기본 연습의 string1.py 연습을 시도해 보세요.