Python ma wbudowaną klasę ciągu znaków o nazwie „str” i wiele przydatnych funkcji (jest starszy moduł o nazwie „string”, którego nie należy używać). Literały łańcuchowe mogą być ujęte w cudzysłowy pojedyncze lub podwójne, ale częściej stosowane są cudzysłowy pojedyncze. Zmiana znaczenia odwrotnego ukośnika działa w zwykły sposób zarówno w przypadku literałów ujętych w cudzysłów, jak i literału w cudzysłowie, np. \n ”. Literał łańcuchowy ujęty w cudzysłów może zawierać pojedyncze cudzysłowy (np. „Nie to zrobiłem”), a pojedynczy ciąg cudzysłowu może zawierać podwójne cudzysłowy. Literał łańcuchowy może obejmować wiele wierszy, ale na końcu każdego wiersza musi znajdować się ukośnik lewy \, aby poprzedzał nowy wiersz. literały łańcuchowe w potrójnym cudzysłowie, """ lub „””, mogą obejmować wiele wierszy tekstu.
Ciągi w języku Python są „stałe” co oznacza, że nie można ich zmienić po utworzeniu (ciągi znaków w języku Java także korzystają z tego stylu stałego). Ciągów znaków nie można zmieniać, dlatego tworzymy *nowe* ciągi, aby przedstawić obliczone wartości. Na przykład wyrażenie „witaj” + „tam” przyjmuje 2 ciągi „cześć” i „tam” i tworzy nowy ciąg „hellothere”.
Dostęp do znaków w ciągu znaków można uzyskać przy użyciu standardowej składni [ ] i tak jak w przypadku Javy i C++, Python używa indeksowania zerowego, jeśli więc argument s to „hello”. s[1] to „e”. Jeśli indeks jest poza zakresem ciągu, Python zgłasza błąd. Styl Python (inaczej niż Perl) ma za zadanie zatrzymać działanie, jeśli nie informuje, co zrobić, zamiast po prostu utworzyć wartość domyślną. Wygodny „wycinek” (poniżej) umożliwia również wyodrębnianie dowolnego podłańcucha z ciągu znaków. Funkcja len(string) zwraca długość ciągu znaków. Składnia [ ] i funkcja len() działają w przypadku każdego typu sekwencji – ciągów tekstowych, list itd. Python stara się, aby jego operacje działały spójnie w różnych typach. Dla nowicjuszy Pythona nie używaj słowa „len” jako nazwę zmiennej, aby uniknąć blokowania funkcji len(). Znak „+” może połączyć dwa ciągi. Zwróć uwagę na to, że zmienne nie są wstępnie zadeklarowane w kodzie – wystarczy, że je przypiszesz i gotowe.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
W przeciwieństwie do Javy przed znakiem „+” nie konwertuje automatycznie liczb ani innych typów na postać ciągu. Funkcja str() konwertuje wartości na ciąg znaków, aby można je było łączyć z innymi ciągami.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
W przypadku liczb standardowe operatory +, /, * działają w zwykły sposób. Nie ma operatora ++, ale +=, -= itp. działają. Aby dzielić liczbę całkowitą, użyj 2 ukośników, np. 6 // 5 to 1
Element „print” zwykle wyświetla jeden lub więcej elementów języka Python, po którym następuje znak nowego wiersza. Nieprzetworzony literał łańcuchowy jest poprzedzony znakiem „r” i przekazuje wszystkie znaki bez specjalnego traktowania ukośników wstecznych, przez co r'x\nx' zwraca ciąg znaków „długość-4” „x\nx”. „drukuj” może przyjąć kilka argumentów, aby zmienić sposób wyświetlania elementów (zobacz definicję funkcji drukowania w python.org), na przykład ustawianie „end”; do „” , aby nie drukować nowego wiersza po zakończeniu drukowania wszystkich elementów.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
Metody ciągów znaków
Oto kilka najpopularniejszych metod związanych z ciągami znaków. Metoda jest jak funkcja, ale działa „on” nad obiektem. Jeśli zmienna s jest ciągiem, kod s.lower() uruchamia metodę Low() w obiekcie ciągu i zwraca wynik (ta koncepcja metody działająca na obiekcie to jedna z podstawowych koncepcji składających się na programowanie zorientowane obiektowo, OOP). Oto kilka najczęstszych sposobów używania ciągu znaków:
- s.lower(), s.upper() – zwraca wersję ciągu znaków małymi lub wielkimi literami.
- s.strip() – zwraca ciąg z usuniętymi odstępami na początku i na końcu.
- s.isalpha()/s.isdigit()/s.isspace()... – sprawdza, czy wszystkie znaki ciągu należą do różnych klas znaków
- s.startswith('other'), s.endswith('other') – sprawdza, czy ciąg zaczyna się czy kończy danym innym ciągiem znaków.
- s.find('other') – wyszukuje inny ciąg znaków (nie wyrażenie regularne) w s. i zwraca pierwszy indeks, od którego zaczyna się jego część, lub -1, jeśli go nie znaleziono.
- s.replace('old', 'new') - zwraca ciąg, w którym wszystkie wystąpienia słowa „stary” zostały zastąpione przez wartość „new”
- s.split('delim') -- zwraca listę podłańcuchów oddzielonych danym separatorem. Separator nie jest wyrażeniem regularnym, a tylko tekst. 'aaa,bbb,ccc'.split(',') -> [„aaa”, „bbb”, „ccc”]. Jako wygodne rozwiązanie specjalne funkcja s.split() (bez argumentów) dzieli na wszystkie znaki odstępu.
- s.join(list) – przeciwieństwo funkcji podział(), łączy elementy danej listy ze sobą przy użyciu ciągu znaków jako separatora. np. '---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
Wyszukiwanie w Google hasła „python str” powinien prowadzić do oficjalnych metod w języku python.org związanych z ciągami tekstowymi, które zawierają listę wszystkich metod str.
W Pythonie nie ma osobnego typu znaków. Zamiast tego wyrażenie takie jak s[8] zwraca ciąg znaków o długości-1 zawierającym znak. W przypadku ciągu o długości-1 operatory ==, <=, ... działają zgodnie z oczekiwaniami, więc przeważnie nie musisz wiedzieć, że Python nie ma osobnego skalarnego „charu”. typu.
Wycinki sznurka
Wycinek to poręczny sposób odwoływania się do podrzędnych części sekwencji, zwykle ciągów tekstowych i list. Wycinek [start:end] to elementy zaczynające się od początku i rozciągające się aż do końca. Załóżmy, że mamy s = "Cześć"
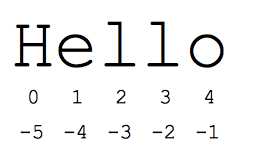
- s[1:4] to „ell” – znaki rozpoczynające się od indeksu 1 i przechodzące do indeksu 4 włącznie
- s[1:] to „ello” – pominięcie któregoś z indeksu powoduje domyślnie umieszczenie indeksu na początku lub na końcu ciągu.
- s[:] to „Hello” -- Pominięcie obu tych elementów zawsze daje nam kopię całego materiału (jest to pytonny sposób kopiowania sekwencji, takiej jak ciąg czy lista).
- s[1:100] to „ello” Zbyt duży indeks jest skracany do długości ciągu znaków.
Standardowe liczby liczone od zera dają łatwy dostęp do znaków na początku ciągu. Python zamiast niego używa liczb ujemnych, aby umożliwić łatwy dostęp do znaków na końcu ciągu: s[-1] to ostatni znak „o”, s[-2] to „l”. następny znak itd. Ujemne wartości indeksu są odliczane od końca ciągu znaków:
- s[-1] to „o” -- ostatni znak (pierwszy od końca)
- s[-4] to „e” -- 4. od końca
- s[:-3] to „He” ostatnie 3 znaki, ale bez nich.
- s[-3:] to „llo” -- od trzeciego znaku od końca do końca ciągu.
Jest to prosty truizm wycinków, że dla dowolnego indeksu n s[:n] + s[n:] == s. Ta funkcja działa nawet w przypadku n wartości ujemnych lub poza zakresem. Możesz też użyć innego sposobu s[:n] i s[n:], aby zawsze podzielić ciąg na dwie części, zachowując przy tym wszystkie znaki. Jak widać później w sekcji z listą, wycinki działają również z listami.
Formatowanie ciągu znaków
Pyton może automatycznie konwertować obiekty to ciąg odpowiedni do druku. Można to zrobić na dwa wbudowane sposoby: ciągi tekstowe nazywane też „ciągami f” i wywoływaniem str.format().
Sformatowane literały łańcuchowe
Formatowanie literałów ciągów jest często spotykane w takich sytuacjach:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
Sformatowany ciąg literału jest poprzedzony literą „f” (np. prefiks „r” używany w przypadku nieprzetworzonych ciągów znaków). Tekst poza nawiasami klamrowymi „{}” są drukowane. Wyrażenia zawarte w „{}” to są drukowane według specyfikacji formatu opisanej specyfikację formatu. Możesz korzystać z wielu różnych funkcji formatowania, w tym obcinania konwersji do notacji naukowej i wyrównania do lewej/prawej/środkowej wartości.
Ciągi f są bardzo przydatne, gdy chcesz wydrukować tabelę obiektów i chcesz kolumny reprezentujące różne atrybuty obiektów do wyrównania,
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
% ciągu znaków
Python ma również starszą funkcję w stylu Printf() do tworzenia ciągów znaków. Operator % pobiera z lewej strony ciąg w formacie typu Printf (%d int, ciąg %s, liczba zmiennoprzecinkowa %f/%g) i pasujące wartości w krotce po prawej (krotka składa się z wartości rozdzielonych przecinkami, zwykle w nawiasach):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
Powyższy wiersz jest dość długi – załóżmy, że chcesz podzielić go na osobne wiersze. Nie można podzielić wiersza po znaku „%” tak jak w innych językach, ponieważ Python domyślnie traktuje każdy wiersz jako osobną instrukcję (po drugie, nie trzeba wpisywać średników w każdym wierszu). Aby rozwiązać ten problem, umieść całe wyrażenie w zewnętrznym zestawie nawiasów – wtedy może ono obejmować wiele wierszy. Ta technika łączenia kodu obejmuje różne konstrukcje grupowania opisane poniżej: ( ), [ ], { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Tak jest lepiej, ale kolejka jest jeszcze trochę długa. Python umożliwia podzielenie linii na fragmenty, które zostaną automatycznie połączone. Aby więc jeszcze bardziej skrócić tę linię, możemy to zrobić:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Ciągi znaków (Unicode a bajty)
Zwykłe ciągi znaków w języku Python są kodem Unicode.
Python obsługuje również ciągi tekstowe złożone ze zwykłych bajtów (oznaczonych prefiksem „b” przed literałem). lubię:
> byte_string = b'A byte string' > byte_string b'A byte string'
Ciąg Unicode to inny typ obiektu niż ciąg bajtów, ale różne biblioteki, takie jak wyrażenia regularne działają poprawnie, jeśli przekazywane są oba typy ciągów.
Aby przekonwertować zwykły ciąg Pythona na bajty, wywołaj w ciągu znaków metodę encode(). W przeciwnym razie metoda decode() łańcucha bajtów przekształca zakodowane zwykłe bajty na ciąg Unicode:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
W sekcji odczytywania plików znajdziesz przykład pokazujący, jak otworzyć plik tekstowy z określonym kodowaniem i odczytać na głos ciągi znaków Unicode.
Instrukcja If
Python nie używa { } do obejmowania bloków kodu na przykład na potrzeby operacji typu if, pętle, funkcji itp. Zamiast nich do grupowania instrukcji w Pythonie używany jest dwukropek (:) oraz wcięcie i odstępy. Test logiczny dla argumentu „jeśli” nie musi być umieszczony w nawiasie (duża różnica w porównaniu z językiem C++/Java), może też mieć klauzule *elif* i *else* (mnemotechnika: słowo „elif” ma taką samą długość jak słowo „else”).
W teście if-test można używać dowolnej wartości. „Zero” Wszystkie wartości liczą się jako fałsz: Brak, 0, pusty ciąg znaków, pusta lista, pusty słownik. Istnieje również typ logiczny z 2 wartościami: True (Prawda) i False (Fałsz) (po przekonwertowaniu na liczbę całkowitą, czyli 1 i 0). Python wykonuje standardowe operacje porównania: ==, !=, <, <=, >, >=. W przeciwieństwie do Javy i C == jest przeciążone, aby działać prawidłowo z ciągami znaków. Operatory logiczne to wpisane słowa *i*, *lub*, *nie* (w Pythonie nie używa się znaków && || !). Oto jak może wyglądać kod w przypadku aplikacji związanej ze zdrowiem, w której każdego dnia pojawiają się zalecenia dotyczące napojów. Zwróć uwagę, że każdy blok z przecinkiem zaczyna się od znaku :, a wyrażenia są pogrupowane według wcięcia:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
Widzę, że pominięto „:” to mój najczęstszy błąd składni podczas pisania powyższego kodu. Chyba że trzeba to już głównie o to w końcu chodzi o moje nawyki związane z C++/Java. Nie używaj też wartości logicznych w nawiasach – to nawyk w C/Java. Jeśli kod jest krótki, możesz umieścić go w tym samym wierszu po znaku „:” w taki sposób (dotyczy to również funkcji, pętli itp.), chociaż niektórzy uważają, że rozłożenie elementów w oddzielnych wierszach jest wygodniejsze.
if time_hour < 10: print('coffee') else: print('water')
Ćwiczenie: string1.py
Aby przećwiczyć materiał zawarty w tej sekcji, wykonaj ćwiczenie string1.py w Ćwiczeniach podstawowych.