В Python есть встроенный класс строк с именем «str» со множеством полезных функций (есть более старый модуль с именем «string», который вам не следует использовать). Строковые литералы могут быть заключены в двойные или одинарные кавычки, хотя чаще используются одинарные кавычки. Обратная косая черта работает обычным способом как в одинарных, так и в двойных кавычках - например, \n \' \". Строковый литерал в двойных кавычках может содержать одинарные кавычки без каких-либо проблем (например, «Я этого не делал»), а также одинарные кавычки. Строка может содержать двойные кавычки. Строковый литерал может занимать несколько строк, но в конце каждой строки должна быть обратная косая черта \, чтобы избежать символа новой строки. Строковые литералы внутри тройных кавычек, """ или "'', могут занимать несколько строк. текста.
Строки Python являются «неизменяемыми», что означает, что их нельзя изменить после создания (строки Java также используют этот неизменяемый стиль). Поскольку строки не могут быть изменены, мы создаем *новые* строки для представления вычисленных значений. Так, например, выражение («привет» + «здесь») принимает две строки «привет» и «здесь» и создает новую строку «привет».
Доступ к символам в строке можно получить с помощью стандартного синтаксиса [ ], и, как Java и C++, Python использует индексацию, начинающуюся с нуля, поэтому, если s равно 'hello', s[1] равно 'e'. Если индекс выходит за пределы строки, Python выдает ошибку. Стиль Python (в отличие от Perl) предполагает остановку, если он не может сказать, что делать, а не просто создание значения по умолчанию. Удобный синтаксис «срез» (ниже) также позволяет извлечь из строки любую подстроку. Функция len(string) возвращает длину строки. Синтаксис [ ] и функция len() фактически работают с любым типом последовательности — строками, списками и т. д. Python пытается обеспечить согласованную работу своих операций для разных типов. Проблема для новичков в Python: не используйте «len» в качестве имени переменной, чтобы не блокировать функцию len(). Оператор «+» может объединить две строки. Обратите внимание, что в приведенном ниже коде переменные не объявляются заранее — просто присвойте им значения и приступайте.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
В отличие от Java, «+» не преобразует числа или другие типы автоматически в строковую форму. Функция str() преобразует значения в строковую форму, чтобы их можно было комбинировать с другими строками.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
Для чисел стандартные операторы +, /, * работают обычным образом. Оператора ++ нет, но +=, -= и т.д. работают. Если вы хотите целочисленное деление, используйте 2 косые черты, например 6 // 5 равно 1.
Функция «print» обычно распечатывает один или несколько элементов Python, за которыми следует перевод строки. «Необработанный» строковый литерал имеет префикс «r» и пропускает все символы без специальной обработки обратной косой черты, поэтому r'x\nx' оценивается как строка длины 4 'x\nx'. «print» может принимать несколько аргументов, чтобы изменить способ печати (см. определение функции печати на python.org ), например, установить для «end» значение «», чтобы больше не печатать новую строку после завершения печати всех элементов.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
Строковые методы
Вот некоторые из наиболее распространенных строковых методов. Метод похож на функцию, но он выполняется «на» объекте. Если переменная s является строкой, то код s.lower() запускает метод low() для этого строкового объекта и возвращает результат (идея метода, выполняемого для объекта, является одной из основных идей, составляющих Object Ориентированное программирование (ООП). Вот некоторые из наиболее распространенных строковых методов:
- s.lower(), s.upper() — возвращает версию строки в нижнем или верхнем регистре.
- s.strip() — возвращает строку с удаленными пробелами в начале и конце.
- s.isalpha()/s.isdigit()/s.isspace()... -- проверяет, находятся ли все строковые символы в различных классах символов.
- s.startswith('other'), s.endswith('other') — проверяет, начинается или заканчивается строка заданной другой строкой
- s.find('other') — ищет данную другую строку (не регулярное выражение) внутри s и возвращает первый индекс, с которого она начинается, или -1, если не найдено
- s.replace('old', 'new') — возвращает строку, в которой все вхождения слова «старый» заменены на «новый».
- s.split('delim') — возвращает список подстрок, разделенных заданным разделителем. Разделитель не является регулярным выражением, это просто текст. 'aaa,bbb,ccc'.split(',') -> ['aaa', 'bbb', 'ccc']. В качестве удобного особого случая s.split() (без аргументов) разбивается на все пробельные символы.
- s.join(list) — противоположность функции Split(), объединяет элементы данного списка вместе, используя строку в качестве разделителя. например '---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
Поиск в Google по запросу «python str» должен привести вас к официальным строковым методам python.org , в которых перечислены все методы str.
В Python нет отдельного типа символов. Вместо этого выражение типа s[8] возвращает строку длиной 1, содержащую символ. При такой длине строки-1 операторы ==, <=, ... работают так, как и следовало ожидать, поэтому в большинстве случаев вам не нужно знать, что в Python нет отдельного скалярного типа «char».
Срезы струн
Синтаксис «срез» — это удобный способ ссылки на части последовательностей — обычно строки и списки. Срез s[start:end] — это элементы, начинающиеся с начала и продолжающиеся до конца, но не включая его. Предположим, у нас есть s = «Привет»
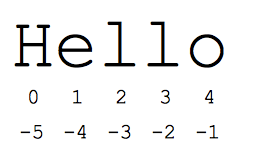
- s[1:4] — это «ell» — символы, начинающиеся с индекса 1 и продолжающиеся до индекса 4, но не включая его.
- s[1:] — это «ello» — без индекса по умолчанию в начале или конце строки.
- s[:] — это «Привет» — пропуск обоих всегда дает нам копию всего этого (это питонический способ копирования последовательности, такой как строка или список)
- s[1:100] — это «ello» — слишком большой индекс усекается до длины строки.
Стандартные индексные числа, отсчитываемые от нуля, обеспечивают легкий доступ к символам в начале строки. В качестве альтернативы Python использует отрицательные числа, чтобы облегчить доступ к символам в конце строки: s[-1] — это последний символ «o», s[-2] — это «l» предпоследний символ. чар и так далее. Отрицательные индексные числа отсчитываются от конца строки:
- s[-1] равно 'o' -- последний символ (первый с конца)
- s[-4] — это «e» — четвертое с конца
- s[:-3] — это «Он» — вплоть до последних трех символов, но не включая их.
- s[-3:] — это «llo» — начиная с третьего символа с конца и до конца строки.
Это ясная истина для срезов: для любого индекса n s[:n] + s[n:] == s . Это работает даже для n отрицательных или выходящих за пределы. Или, другими словами, s[:n] и s[n:] всегда разделяют строку на две части, сохраняя все символы. Как мы увидим позже в разделе о списках, срезы также работают со списками.
Форматирование строк
Одна изящная вещь, которую может сделать Python, — это автоматическое преобразование объектов в строку, пригодную для печати. Два встроенных способа сделать это — форматированные строковые литералы, также называемые «f-строками», и вызов str.format().
Форматированные строковые литералы
Вы часто будете видеть форматированные строковые литералы, используемые в таких ситуациях, как:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
Форматированная литеральная строка имеет префикс «f» (аналогично префиксу «r», используемому для необработанных строк). Любой текст за пределами фигурных скобок «{}» выводится напрямую. Выражения, содержащиеся в '{}', выводятся с использованием спецификации формата, описанной в спецификации формата. С форматированием можно сделать множество интересных вещей, включая усечение и преобразование в экспоненциальное представление, а также выравнивание по левому/правому/центру.
f-строки очень полезны, когда вы хотите распечатать таблицу объектов и хотите, чтобы столбцы, представляющие различные атрибуты объекта, были выровнены, например
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
Нить %
В Python также есть более старая функция, похожая на printf(), для объединения строк. Оператор % принимает строку формата типа printf слева (%d int, строка %s, %f/%g с плавающей запятой) и соответствующие значения в кортеже справа (кортеж состоит из значений, разделенных запятые, обычно сгруппированные в скобках):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
Приведенная выше строка довольно длинная — предположим, вы хотите разбить ее на отдельные строки. Вы не можете просто разделить строку после '%', как это можно сделать в других языках, поскольку по умолчанию Python рассматривает каждую строку как отдельный оператор (с другой стороны, именно поэтому нам не нужно вводить точки с запятой в каждой строке). линия). Чтобы исправить это, заключите все выражение во внешние круглые скобки — тогда выражение сможет занимать несколько строк. Этот метод межстрочного кода работает с различными конструкциями группировки, подробно описанными ниже: ( ), [ ], { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Так уже лучше, но очередь все равно немного длинная. Python позволяет разрезать строку на куски, которые затем автоматически объединяются. Итак, чтобы сделать эту строку еще короче, мы можем сделать следующее:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Строки (Юникод против байтов)
Обычные строки Python имеют кодировку Unicode.
Python также поддерживает строки, состоящие из простых байтов (обозначаемых префиксом «b» перед строковым литералом), например:
> byte_string = b'A byte string' > byte_string b'A byte string'
Строка Юникода — это объект, отличный от байтовой строки, но различные библиотеки, такие как регулярные выражения, работают правильно, если передается любой тип строки.
Чтобы преобразовать обычную строку Python в байты, вызовите для этой строки метод encode(). Идя в другом направлении, метод decode() байтовой строки преобразует закодированные простые байты в строку Юникода:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
В разделе чтения файлов приведен пример, показывающий, как открыть текстовый файл с некоторой кодировкой и прочитать строки Юникода.
Если заявление
Python не использует { } для включения блоков кода для if/циклов/функций и т. д. Вместо этого Python использует двоеточие (:) и отступы/пробелы для группировки операторов. Логический тест для if не обязательно должен быть в круглых скобках (большое отличие от C++/Java), и он может содержать предложения *elif* и *else* (мнемоника: слово «elif» имеет ту же длину, что и слово « еще").
Любое значение можно использовать в качестве проверки if. Все «нулевые» значения считаются ложными: нет, 0, пустая строка, пустой список, пустой словарь. Также существует тип Boolean с двумя значениями: True и False (преобразованный в int, это 1 и 0). В Python есть обычные операции сравнения: ==, !=, <, <=, >, >=. В отличие от Java и C, == перегружен для корректной работы со строками. Логические операторы — это написанные слова *and*, *or*, *not* (Python не использует стиль C && || !). Вот как может выглядеть код приложения для здоровья, предоставляющего рекомендации по напиткам в течение дня — обратите внимание, что каждый блок операторов then/else начинается с :, а операторы сгруппированы по отступам:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
Я считаю, что пропуск знака ":" является моей самой распространенной синтаксической ошибкой при вводе приведенного выше кода, вероятно, потому, что это дополнительная вещь, которую нужно вводить по сравнению с моими привычками C++/Java. Кроме того, не заключайте логический тест в круглые скобки — это привычка C/Java. Если код короткий, вы можете поместить его в одну строку после «:», вот так (это также относится к функциям, циклам и т. д.), хотя некоторые люди считают, что более читабельно выносить элементы на отдельные строки.
if time_hour < 10: print('coffee') else: print('water')
Упражнение: string1.py
Чтобы попрактиковаться в материале этого раздела, попробуйте упражнение string1.py в разделе «Базовые упражнения» .