Python มีคลาสสตริงในตัวชื่อ "str" พร้อมด้วยฟีเจอร์ที่มีประโยชน์มากมาย (มีโมดูลที่เก่ากว่าชื่อ "สตริง" ซึ่งคุณไม่ควรใช้) สัญพจน์สตริงสามารถใช้เครื่องหมายคำพูดแบบคู่หรือเครื่องหมายคำพูดเดี่ยวก็ได้ แม้ว่าเครื่องหมายคำพูดแบบเดี่ยวจะนิยมใช้มากกว่า การใช้อักขระหลีกกับเครื่องหมายแบ็กสแลชจะทำงานตามปกติภายในทั้งลิเทอรัลยกสูงเดี่ยวและคู่ที่อยู่ในเครื่องหมายคำพูด เช่น \n \" \" ลิเทอรัลของสตริงที่มีเครื่องหมายคำพูดคู่สามารถมีเครื่องหมายคำพูดแบบเดี่ยวได้โดยไม่มีความยุ่งยาก (เช่น "ฉันไม่ได้ทำ") และในทำนองเดียวกันสตริงที่มีเครื่องหมายคำพูดเดี่ยวสามารถมีเครื่องหมายคำพูดคู่ได้ สตริงตามตัวอักษรสามารถครอบคลุมหลายบรรทัด แต่ต้องมีแบ็กสแลช \ ที่ท้ายแต่ละบรรทัดเพื่อไม่ให้ขึ้นบรรทัดใหม่ สตริงลิเทอรัลภายในเครื่องหมายคำพูด 3 ตัว """ หรือ ''' อาจครอบคลุมถึงข้อความหลายบรรทัด
สตริง Python เป็นแบบ "เปลี่ยนแปลงไม่ได้" ซึ่งหมายความว่าไม่สามารถเปลี่ยนแปลงได้หลังจากสร้างแล้ว (สตริง Java ใช้รูปแบบที่เปลี่ยนแปลงไม่ได้นี้ด้วย) เนื่องจากสตริงนั้นเปลี่ยนแปลงไม่ได้ เราจึงสร้างสตริง *ใหม่* ขึ้นมาเพื่อแสดงค่าที่คำนวณแล้ว ตัวอย่างเช่น นิพจน์ ("สวัสดี" + "มี") จะใช้คำว่า "สวัสดี" 2 สตริง และ "ตรงนั้น" และสร้างสตริงใหม่ว่า "hellothere"
อักขระในสตริงสามารถเข้าถึงได้โดยใช้ไวยากรณ์ [ ] มาตรฐาน และเช่นเดียวกับ Java และ C++ นั้น Python จะใช้การจัดทำดัชนีแบบศูนย์ ดังนั้นหาก s คือ 'hello' s[1] คือ 'e' หากดัชนีอยู่นอกขอบเขตของสตริง Python จะทำให้เกิดข้อผิดพลาด รูปแบบ Python (ต่างจาก Perl) คือจะหยุดหากบอกไม่ได้ว่าต้องทำอะไร แทนที่จะสร้างแค่ค่าเริ่มต้น "สไลซ์" ที่ใช้งานง่าย ไวยากรณ์ (ด้านล่าง) ยังใช้ในการแยกสตริงย่อยจากสตริงได้ด้วย ฟังก์ชัน len(string) จะแสดงผลความยาวของสตริง ไวยากรณ์ [ ] และฟังก์ชัน len() ทำงานได้ในลำดับประเภทใดก็ได้ เช่น สตริง รายการ ฯลฯ Python จะพยายามทำให้การดำเนินการต่างๆ สอดคล้องกันในประเภทต่างๆ Python มือใหม่ Gotcha: อย่าใช้ "len" เป็นชื่อตัวแปรเพื่อหลีกเลี่ยงการปิดกั้นฟังก์ชัน len() เครื่องหมาย "+" สามารถเชื่อมสองสตริงเข้าด้วยกัน โปรดสังเกตในโค้ดด้านล่างว่าตัวแปรไม่ได้มีการประกาศไว้ล่วงหน้า ให้คุณกําหนดตัวแปรแล้วก็ไปได้เลย
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
ปุ่ม '+' ต่างจาก Java ไม่แปลงตัวเลขหรือประเภทอื่นๆ เป็นรูปแบบสตริงโดยอัตโนมัติ ฟังก์ชัน str() จะแปลงค่าเป็นรูปแบบสตริงเพื่อให้รวมกับสตริงอื่นๆ ได้
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
สำหรับตัวเลข โอเปอเรเตอร์มาตรฐาน +, /, * จะทำงานตามปกติ ไม่มีโอเปอเรเตอร์ ++ แต่ใช้ +=, -= ได้ ฯลฯ หากต้องการการหารจำนวนเต็ม ให้ใช้เครื่องหมายทับ 2 ตัว เช่น 6 // 5 เท่ากับ 1
"สิ่งพิมพ์" โดยปกติจะพิมพ์รายการ Python อย่างน้อย 1 รายการตามด้วยบรรทัดใหม่ "ข้อมูลดิบ" สตริงลิเทอรัลนำหน้าด้วย "r" และส่งผ่านอักขระทั้งหมดได้โดยไม่ต้องใช้แบ็กสแลชเป็นพิเศษ ดังนั้น r'x\nx' ประเมินเป็นสตริงความยาว 4 "x\nx" "พิมพ์" อาจมีหลายอาร์กิวเมนต์ในการเปลี่ยนแปลงวิธีพิมพ์ข้อมูล (ดูคำจำกัดความของฟังก์ชันการพิมพ์ Python.org) เช่น การตั้งค่า "สิ้นสุด" ถึง "" เพื่อไม่ให้พิมพ์บรรทัดใหม่หลังจากพิมพ์รายการทั้งหมดเสร็จแล้ว
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
หลักการที่ใช้สตริง
ต่อไปนี้เป็นเมธอดสตริงที่ใช้กันมากที่สุดบางส่วน เมธอดก็เหมือนกับฟังก์ชัน แต่จะเรียกใช้ "on" ออบเจ็กต์ หากตัวแปร s เป็นสตริง โค้ด s.lower() จะเรียกใช้เมธอด bottom() ในออบเจ็กต์สตริงนั้น และแสดงผลลัพธ์ (แนวคิดเกี่ยวกับเมธอดที่ทำงานบนออบเจ็กต์นี้เป็นหนึ่งในแนวคิดพื้นฐานที่ประกอบกันขึ้นเป็น Object Oriented Programming, OOP) วิธีสตริงที่ใช้กันมากที่สุดมีดังนี้
- s.lower(), s.upper() -- แสดงผลสตริงเวอร์ชันตัวพิมพ์เล็กหรือตัวพิมพ์ใหญ่
- s.strip() -- แสดงสตริงที่มีช่องว่างที่ลบจากจุดเริ่มต้นและจุดสิ้นสุด
- s.isalpha()/s.isdigit()/s.isspace()... -- ทดสอบว่าอักขระสตริงทั้งหมดอยู่ในคลาสอักขระที่หลากหลายหรือไม่
- s.startswith('other'), s.endswith('other') -- ทดสอบว่าสตริงเริ่มต้นหรือลงท้ายด้วยสตริงอื่นที่กำหนด
- s.find('other') -- ค้นหาสตริงอื่นที่ระบุ (ไม่ใช่นิพจน์ทั่วไป) ภายใน s และแสดงผลดัชนีแรกที่จุดเริ่มต้นหรือ -1 หากไม่พบ
- s.replace('old', 'new') -- แสดงผลสตริงที่รายการ 'old ทั้งหมด' ถูกแทนที่ด้วย "ใหม่"
- s.split('delim') -- แสดงรายการสตริงย่อยที่คั่นด้วยตัวคั่นที่กำหนด ตัวคั่นไม่ใช่นิพจน์ทั่วไป แต่เป็นเพียงข้อความ 'aaa,bbb,ccc'.split(',') -> (aaa,bbb,ccc'.split(',') -> ['aaa', 'bbb', 'ccc'] เพื่อเป็นกรณีพิเศษ s.split() (ไม่มีอาร์กิวเมนต์) จะแยกอักขระช่องว่างทั้งหมด
- s.join(list) -- ตรงข้ามกับSplit() รวมองค์ประกอบต่างๆ ในรายการที่กำหนดเข้าด้วยกันโดยใช้สตริงเป็นตัวคั่น เช่น '---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
การค้นหา "python str" ใน Google จะนำคุณไปยังเมธอดสตริง python.org อย่างเป็นทางการ ซึ่งจะแสดงเมธอด str ทั้งหมด
Python ไม่มีประเภทอักขระแยกต่างหาก โดยนิพจน์ เช่น s[8] จะแสดงผลสตริงความยาว-1 ที่มีอักขระนั้นแทน ด้วยสตริง-length-1 โอเปอเรเตอร์ ==, <=, ... ทั้งหมดจะทำงานตามที่คาดไว้ ดังนั้น ส่วนใหญ่แล้วคุณจึงไม่จำเป็นต้องทราบว่า Python ไม่มีสเกลาร์ "char" แยกต่างหาก ประเภท
เชือกสไลซ์
"Slice" ไวยากรณ์เป็นวิธีที่มีประโยชน์ในการอ้างอิงส่วนย่อยของลำดับ ซึ่งโดยทั่วไปจะเป็นสตริงและรายการ ส่วน s[start:end] คือองค์ประกอบที่เริ่มจากจุดเริ่มต้นและขยายไปถึงจุดสิ้นสุด แต่ไม่รวมจุดสิ้นสุด สมมติว่าเรามี s = "สวัสดี"
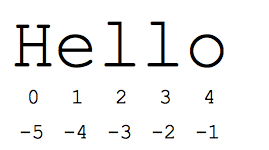
- s[1:4] คือ 'ell' -- อักขระที่เริ่มต้นที่ดัชนี 1 และขยายไปจนถึง แต่ไม่รวมดัชนี 4
- s[1:] คือ 'ello' -- ละเว้นค่าเริ่มต้นของดัชนีที่จุดเริ่มต้นหรือจุดสิ้นสุดของสตริง
- s[:] คือ "สวัสดี" -- การละเว้นทั้ง 2 อย่างจะเป็นการคัดลอกข้อความทั้งหมดเสมอ (นี่เป็นวิธีแบบ Pythonic ในการคัดลอกลำดับ เช่น สตริงหรือรายการ)
- s[1:100] คือ 'ello' -- ดัชนีที่มีขนาดใหญ่เกินไปจะถูกตัดทอนเหลือเท่ากับความยาวของสตริง
หมายเลขดัชนีมาตรฐานแบบ 0 สามารถเข้าถึงอักขระที่อยู่ใกล้จุดเริ่มต้นของสตริงได้อย่างง่ายดาย อีกวิธีหนึ่ง Python จะใช้ตัวเลขลบเพื่อให้สามารถเข้าถึงอักขระที่ท้ายสตริงได้อย่างง่ายดาย โดย s[-1] คืออักขระตัวสุดท้าย 'o' ส่วน s[-2] คือ 'l' เป็นอักขระตัวถัดไป เป็นต้น จำนวนดัชนีที่เป็นค่าลบจะนับย้อนกลับจากจุดสิ้นสุดของสตริง:
- s[-1] คือ 'o' -- อักขระสุดท้าย (ตัวแรกจากท้ายสุด)
- s[-4] คือ 'e' -- ลำดับที่ 4 จากตอนท้าย
- s[:-3] คือ 'เขา' -- ไม่เกิน 3 อักขระสุดท้าย
- s[-3:] คือ 'llo' -- ขึ้นต้นด้วยอักขระตัวที่ 3 จากส่วนท้ายและขยายไปจนถึงส่วนท้ายของสตริง
ค่านี้เป็นข้อเท็จจริงที่ถูกต้องของชิ้นส่วนที่สำหรับดัชนี n ใดๆ ก็ตาม s[:n] + s[n:] == s ซึ่งใช้ได้แม้กระทั่งกับ n ลบหรืออยู่นอกขอบเขต หรืออีกวิธีคือ s[:n] และ s[n:] จะแบ่งพาร์ติชันสตริงออกเป็น 2 ส่วนเสมอเพื่อรักษาอักขระทั้งหมด เราจะเห็นในส่วนรายการในภายหลัง ส่วนต่างๆ ก็ใช้ร่วมกับรายการได้เช่นกัน
การจัดรูปแบบสตริง
สิ่งหนึ่งที่ Python ทำได้ก็คือ แปลงวัตถุโดยอัตโนมัติ สตริงที่เหมาะสำหรับการพิมพ์ ซึ่งทำได้ 2 วิธีคือจัดรูปแบบสตริง ลิเทอรัล หรือที่เรียกว่า "f-strings" และการเรียกใช้ str.format()
ลิเทอรัลของสตริงที่จัดรูปแบบ
คุณมักจะเห็นสตริงที่มีการจัดรูปแบบโดยใช้ในสถานการณ์ต่อไปนี้
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
สตริงลิเทอรัลที่มีการจัดรูปแบบจะมี "f" นำหน้า (เช่น คำนำหน้า "r" ที่ใช้สำหรับสตริงดิบ) ข้อความที่อยู่นอกวงเล็บปีกกา "{}" จะถูกพิมพ์ออกมาโดยตรง นิพจน์ที่อยู่ใน '{}' คือ พิมพ์ออกมาโดยใช้ข้อกำหนดรูปแบบที่อธิบายไว้ใน ข้อกำหนดรูปแบบ คุณสามารถทำสิ่งต่างๆ มากมายเกี่ยวกับการจัดรูปแบบ รวมถึงการตัดข้อความ การแปลงเป็นสัญกรณ์วิทยาศาสตร์และการจัดแนวชิดซ้าย/ขวา/กึ่งกลาง
f-string จะมีประโยชน์มาก เมื่อคุณต้องการพิมพ์ตารางออบเจ็กต์ และต้องการ คอลัมน์ที่แสดงแอตทริบิวต์ออบเจ็กต์ต่างๆ ที่จะจัดเรียง เช่น
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
สตริง %
นอกจากนี้ Python ยังมีเครื่องมือที่คล้าย displayf() ที่เก่ากว่าสำหรับรวบรวมสตริง ตัวดำเนินการ % จะใช้สตริงรูปแบบ Printf-type ทางด้านซ้าย (%d int, สตริง %s, จุดลอยตัว %f/%g) และค่าที่ตรงกันใน Tuple ทางด้านขวา (Tuple จะสร้างค่าโดยคั่นด้วยคอมมา โดยทั่วไปจะจัดกลุ่มไว้ในวงเล็บ)
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
บรรทัดด้านบนค่อนข้างยาว สมมติว่าคุณต้องการแบ่งบรรทัดด้านบนให้เป็นบรรทัดแยกกัน คุณไม่สามารถแยกบรรทัดหลังเครื่องหมาย '%' เหมือนที่คุณอาจในภาษาอื่นๆ เนื่องจากโดยค่าเริ่มต้น Python จะถือว่าแต่ละบรรทัดเป็นคำสั่งที่แยกจากกัน (ในด้านบวก เราจะไม่ต้องพิมพ์เครื่องหมายเซมิโคลอนในแต่ละบรรทัด) ในการแก้ไขปัญหานี้ ให้ใส่นิพจน์ทั้งหมดไว้ในวงเล็บชุดด้านนอก แล้วนิพจน์นี้ก็ได้รับอนุญาตให้ขยายหลายบรรทัดได้ เทคนิคการทำโค้ดข้ามบรรทัดนี้สามารถทำงานร่วมกับโครงสร้างการจัดกลุ่มต่างๆ ตามรายละเอียดด้านล่าง ( ), [ ], { }
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
ดีกว่า แต่แถวยังยาวไปหน่อย Python ให้คุณตัดเส้นแบ่งเป็นส่วนๆ ซึ่งจากนั้นก็จะต่อกันโดยอัตโนมัติ ดังนั้นเพื่อทำให้บรรทัดนี้สั้นลง เราสามารถทำดังนี้:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
สตริง (Unicode เทียบกับไบต์)
สตริง Python ปกติจะเป็น Unicode
นอกจากนี้ Python ยังรองรับสตริงที่ประกอบด้วยไบต์ธรรมดา (แสดงโดยคำนำหน้า "b" ที่ด้านหน้าของสัญพจน์ของสตริง) อย่างเช่น:
> byte_string = b'A byte string' > byte_string b'A byte string'
สตริง Unicode เป็นออบเจ็กต์ประเภทที่แตกต่างจากสตริงแบบไบต์แต่เป็นไลบรารีที่หลากหลาย เช่น นิพจน์ทั่วไปจะทำงานอย่างถูกต้องหากส่งสตริงประเภทใดประเภทหนึ่ง
หากต้องการแปลงสตริง Python ปกติเป็นไบต์ ให้เรียกใช้เมธอด encode() ในสตริง ในอีกทิศทางหนึ่ง วิธีถอดรหัสสตริงไบต์ (Byte string decode()) จะแปลงไบต์ธรรมดาที่เข้ารหัสเป็นสตริง Unicode ดังนี้
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
ในส่วนการอ่านไฟล์จะมีตัวอย่างที่แสดงวิธีเปิดไฟล์ข้อความที่มีการเข้ารหัสและอ่านสตริง Unicode
หากใบแจ้งยอด
Python ไม่ได้ใช้ { } เพื่อล้อมรอบบล็อกโค้ดสำหรับ if/loops/function ฯลฯ แต่ Python จะใช้เครื่องหมายโคลอน (:) และการเยื้อง/ช่องว่างเพื่อจัดกลุ่มคำสั่ง การทดสอบบูลีนสำหรับถ้าไม่จำเป็นต้องอยู่ในวงเล็บ (ความแตกต่างอย่างมากจาก C++/Java) และอาจมีเครื่องหมาย *elif* และ *else* (ช่วยจำ: คำว่า "elif" มีความยาวเท่ากับคำว่า "else")
ค่าใดก็ได้สามารถใช้เป็นการทดสอบ if-test ได้ "ศูนย์" ค่าทั้งหมดจะนับเป็นเท็จ: ไม่มี, 0, สตริงว่างเปล่า, รายการว่างเปล่า, พจนานุกรมว่างเปล่า นอกจากนี้ยังมีประเภทบูลีนที่มี 2 ค่า ได้แก่ จริง และเท็จ (แปลงเป็น int ซึ่งก็คือ 1 และ 0) Python มีการดำเนินการเปรียบเทียบตามปกติ: ==, !=, <, <=, >, >= == มีการโหลดมากเกินไปเพื่อให้ทำงานกับสตริงได้อย่างถูกต้อง ซึ่งต่างจาก Java และ C โอเปอเรเตอร์บูลีนคือคำที่สะกดว่า *และ*, *หรือ*, *ไม่* (Python ไม่ใช้รูปแบบ C&& || !) โค้ดสำหรับแอปสุขภาพที่มีคำแนะนำเรื่องเครื่องดื่มตลอดทั้งวัน จะมีลักษณะดังต่อไปนี้ สังเกตวิธีที่แต่ละบล็อกของคำสั่งหลังจากนั้นขึ้นต้นด้วย : และจัดกลุ่มข้อความตามการเยื้อง
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
ฉันพบว่าการละเว้น ":" เป็นความผิดพลาดทางไวยากรณ์ที่พบได้บ่อยที่สุดเมื่อพิมพ์โค้ดประเภทด้านบน ซึ่งน่าจะเป็นเพราะต้องพิมพ์เพิ่มเติม เมื่อเทียบกับนิสัยการใช้ C++/Java ของฉัน และอย่าทำการทดสอบบูลีนในวงเล็บ ซึ่งเป็นนิสัย C/Java อยู่แล้ว หากโค้ดสั้น คุณสามารถวางโค้ดไว้ในบรรทัดเดียวกันหลัง ":" เช่นนี้ (เช่น มีผลกับฟังก์ชัน ลูป ฯลฯ) แม้ว่าบางคนจะรู้สึกว่าโค้ดนั้นอ่านได้ง่ายกว่าการแบ่งแยกสิ่งต่างๆ ในแต่ละบรรทัด
if time_hour < 10: print('coffee') else: print('water')
แบบฝึกหัด: string1.py
หากต้องการฝึกฝนเนื้อหาในส่วนนี้ ให้ลองทำแบบฝึกหัด string1.py ในแบบฝึกหัดพื้นฐาน