Python'da "str" adlı yerleşik bir dize sınıfı bulunur birçok pratik özellikle birlikte (kullanmamanız gereken "dize" adlı eski bir modül vardır). Tek tırnak işareti daha yaygın olarak kullanılsa da dize değişmez değerleri çift veya tek tırnak içine alınabilir. Ters eğik çizgi kaçışları, hem tek hem de çift tırnak işareti içinde normal şekilde çalışır (ör. \n \' \" seçeneğini belirleyin. Çift tırnak içine alınmış bir dize dizesinde herhangi bir karmaşa olmadan tek tırnak işareti bulunabilir (örneğin, "Ben yapmadım") ve benzer şekilde tek tırnak içine alınan tek bir dize çift tırnak içerebilir. Bir dize değişmez değeri birden çok satırı kapsayabilir, ancak yeni satırdan kurtulmak için her satırın sonunda ters eğik çizgi (\) olmalıdır. Üçlü tırnak işareti içindeki dize değişmez değerleri, "" birden çok satıra yayılabilir.
Python dizeleri "değişmez" Bu, oluşturulduktan sonra değiştirilemez (Java dizeleri de bu sabit stili kullanır). Dizeler değiştirilemeyeceğinden, hesaplanan değerleri temsil ederken *yeni* dizeler oluştururuz. Yani, örneğin ('merhaba' + 'orada' ifadesi 2 dizeyi 'merhaba' ve "orada" ve "hellothere" adlı yeni bir dize oluşturur.
Bir dizedeki karakterlere standart [ ] söz dizimi kullanılarak erişilebilir ve Java ve C++ gibi Python sıfır tabanlı dizine ekleme kullanır. Dolayısıyla, s "hello" ise s[1] "e"dir. Dizin, dizeyle ilgili sınırların dışındaysa Python hata verir. Python stili (Perl'in aksine), varsayılan bir değer oluşturmak yerine ne yapılması gerektiğini söyleyemiyorsa uygulamayı durdurmaktır. Kullanışlı "dilim" söz dizimi (aşağıda), bir dizeden herhangi bir alt dizeyi ayıklamak için de çalışır. len(string) işlevi, bir dizenin uzunluğunu döndürür. [ ] söz dizimi ve len() işlevi dizeler, listeler vb. tüm dizi türlerinde çalışır. Python, işlemlerinin farklı türlerde tutarlı şekilde çalışmasını sağlamaya çalışır. Python yeni başlayan getcha: "len" kullanmayın işlevini değişken adı olarak kullanabilirsiniz. "+" operatörü iki dizeyi birleştirebilir. Aşağıdaki kodda değişkenlerin önceden bildirilmediğine dikkat edin, yalnızca onlara atayın ve başlayın.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
Java'dan farklı olarak, '+' , sayıları veya diğer türleri otomatik olarak dize biçimine dönüştürmez. str() işlevi, değerleri diğer dizelerle birleştirilebilmesi için bir dize biçimine dönüştürür.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
Sayılar için +, /, * standart operatörleri normal şekilde çalışır. ++ operatörü yoktur, ancak +=, -= vb. çalışır. Tam sayıyı bölmek istiyorsanız 2 eğik çizgi kullanın (ör. 6 // 5 1'dir
"Baskı" işlevi, normalde bir veya daha fazla python öğesini ve ardından yeni bir satır yazdırır. Bir "ham" dize sabit değerinin başında "r" bulunur ve tüm karakterleri ters eğik çizgilere özel uygulama tabi tutulmadan geçirir. Dolayısıyla r'x\nx' uzunluk-4 dizesi olan "x\nx" sonucunu verir. "yazdır" öğelerin yazdırılma şeklini değiştirmek için birkaç bağımsız değişken alabilir (bkz. python.org yazdırma işlevi tanımı). "bitiş" ayarını yapma "" olarak değiştirin artık tüm öğelerin yazdırılması bittikten sonra yeni bir satır yazdırmamak için.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
Dize Yöntemleri
En yaygın dize yöntemlerinden bazıları aşağıda verilmiştir. Yöntem bir fonksiyon gibidir ancak "on" üzerinden çalışır olabilir. s değişkeni bir dizeyse s.lower() kodu bu dize nesnesinde bottom() yöntemini çalıştırır ve sonucu döndürür (bir nesne üzerinde çalıştırılan bu yöntem fikri, Object Oriented Programming, OOP'u oluşturan temel fikirlerden biridir). En yaygın dize yöntemlerinden bazıları şunlardır:
- s.lower(), s.upper() -- dizenin küçük veya büyük harfli sürümünü döndürür
- s.strip() -- Başından ve sonundan boşluk kaldırıldığı bir dize döndürür
- s.isalpha()/s.isfinger()/s.isspace()... -- Tüm dize karakterlerinin çeşitli karakter sınıflarında olup olmadığını test eder
- s.startswith('other'), s.endswith('other') -- Dizenin belirtilen diğer dizeyle başlayıp bitmediğini test eder
- s.find('other') -- s içinde belirtilen diğer dizeyi (normal ifade değil) arar ve bu dizenin başladığı ilk dizini veya bulunamazsa -1'i döndürür
- s.replace('old', 'new') -- Şunun tüm 'old' geçtiği yerlerdeki bir dizeyi döndürür , 'new' ile değiştirildi
- s.split('delim') -- Verilen ayırıcıyla ayrılan alt dizelerin listesini döndürür. Ayırıcı, normal bir ifade değildir, yalnızca metindir. 'aaa,bbb,ccc'.split(',') -> ['aaa', 'bbb', 'ccc']. Kullanışlı özel bir durum olarak s.split() (bağımsız değişken olmadan) tüm boşluk karakterlerinde bölünür.
- s.join(list) -- split() fonksiyonunun tersine, belirtilen listedeki öğeleri sınırlayıcı olarak dizeyi kullanarak birleştirir. ör. '---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
"Python str" için bir Google araması sizi tüm str yöntemlerinin listelendiği resmi python.org dize yöntemlerine yönlendirir.
Python'da ayrı bir karakter türü yoktur. Bunun yerine, s[8] gibi bir ifade, karakteri içeren bir string-length-1 değerini döndürür. Bu string-length-1 dizesiyle ==, <=, ... operatörlerinin tümü beklediğiniz gibi çalışır. Bu nedenle, çoğu zaman Python'da ayrı bir skaler "karakter" olmadığını bilmeniz gerekmez türü.
İp Dilimleri
"Dilim" söz dizimi, dizilerin alt bölümlerine (genellikle dizeler ve listeler) atıfta bulunmanın kullanışlı bir yoludur. Dilim s[start:end], başlangıçta başlayıp bitişe kadar uzanan ancak sonu içermeyen öğelerdir. s = "Hello" olduğunu varsayalım
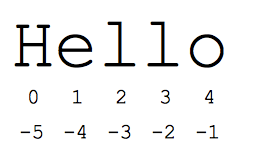
- s[1:4] "ell"dir -- dizin 1'den başlayıp dizin 4'e kadar uzanan ancak dizin 4'ü içermeyen karakterler
- s[1:] "ello"dur -- dizinlerden birinin atlanması, varsayılan olarak dizenin başlangıcına veya sonuna ayarlanır
- s[:], "Merhaba" -- Her ikisinin de atlanması bize her zaman tüm öğenin bir kopyasını verir (bu, bir dizi veya liste gibi bir diziyi kopyalamanın pitonik yoludur)
- s[1:100] "ello"dur -- çok büyük bir dizin dize uzunluğuna kadar kısaltılır
Standart sıfır tabanlı dizin numaraları, dizenin başına yakın olan karakterlere kolay erişim sağlar. Alternatif olarak, Python, dizenin sonundaki karakterlere kolay erişim sağlamak için negatif sayılar kullanır: s[-1], "o" karakteri, s[-2] ise "l" olur değiştirilebilir. Negatif dizin sayıları, dizenin sonundan itibaren geri sayılır:
- s[-1] 'o'dur -- son karakter (sondan 1.)
- s[-4] 'e'dir -- sondan 4.
- s[:-3] 'O'dur en fazla olacak ancak son 3 karakter dahil edilemeyecek.
- s[-3:] 'llo'dur (sondan 3. karakterle başlar ve dizenin sonuna kadar devam eder).
Bu, herhangi bir endeks n, s[:n] + s[n:] == s için sorunsuz bir dilim gerçeğidir. Bu, n negatif veya aralık dışında olanlar için de geçerlidir. Başka bir deyişle s[:n] ve s[n:] dizelerini her zaman iki dize parçasına bölerek tüm karakterler korunsun. Daha sonra liste bölümünde göreceğimiz gibi, dilimler listelerle de çalışır.
Dize biçimlendirmesi
Python'un yapabileceği bir başka şey de nesneleri otomatik olarak bir dize. Bunu yapmanın iki yerleşik yolu, olarak da adlandırılır.
Biçimlendirilmiş dize değişmez değerleri
Genellikle aşağıdaki gibi durumlarda kullanılan biçimlendirilmiş düz dize değerleri görürsünüz:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
Biçimlendirilmiş bir düz dize "f" ile başlar (ör. işlenmemiş dizeler için kullanılan "r" öneki gibi). Süslü ayraçlar "{}" dışındaki metinler doğrudan basılır. "{}" içinde bulunan ifadeler şunlardır: aşağıda açıklandığı biçim spesifikasyonu kullanılarak yazdırılır biçim özelliklerine bakın. Kırpma ve kısaltma gibi biçimlendirmelerle yapabileceğiniz birçok etkili bilimsel gösterime ve sola/sağa/ortaya hizasına dönüştürme.
f dizeleri, bir nesne tablosu yazdırmak istediğinizde çok kullanışlıdır. farklı nesne özelliklerini temsil eden sütunlarla aynı hizaya
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
Dize yüzdesi
Python'da ayrıca bir dize oluşturmak için Printf() benzeri eski bir olanak bulunur. % operatörü, solda bir Printf türü biçim dizesi (%d int, %s string, %f/%g kayan nokta) ve sağdaki bir numarada eşleşen değerler alır (tuple, virgülle ayrılmış değerlerden oluşur ve genellikle parantez içinde gruplanır):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
Yukarıdaki satır biraz uzun. Bu satırı ayrı satırlara ayırmak istediğinizi varsayalım. "%" işaretinden sonra gelen satırı bölemezsiniz Diğer dillerde olduğu gibi, Python varsayılan olarak her satırı ayrı bir ifade olarak ele alır (bu nedenle de her satıra noktalı virgül koymamız gerekmez). Bunu düzeltmek için tüm ifadeyi bir dış parantez içine alın. Böylece ifadenin birden fazla satırı kapsamasına izin verilir. Bu satırlar arası kod tekniği, aşağıda ayrıntıları verilen çeşitli gruplandırma yapılarıyla çalışır: ( ), [ ], { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Daha iyi olsa da sıra biraz uzun. Python, bir dizilimi parçalara ayırmanıza olanak tanır. Bu parçalar daha sonra otomatik olarak birleştirilir. Dolayısıyla, bu satırı daha da kısaltmak için şunu yapabiliriz:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Dizeler (Unicode / bayt)
Normal Python dizeleri unicode'dur.
Python, düz baytlardan oluşan dizeleri de destekler (bir dize değişmez değerinin önünde "b" önekiyle gösterilir) örneğin:
> byte_string = b'A byte string' > byte_string b'A byte string'
Unicode dizesi, bir bayt dizesinden farklı bir nesne türüdür, ancak Normal ifadeler, dize türlerinden biri iletildiyse doğru şekilde çalışır.
Normal bir Python dizesini baytlara dönüştürmek için dizede encode() yöntemini çağırın. Diğer yönde gidersek bayt dizesi decode() yöntemi, kodlanmış düz baytları bir unicode dizesine dönüştürür:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
Dosya okuma bölümünde, bir metin dosyasının bazı kodlamalarla nasıl açılacağını ve unicode dizelerinin nasıl okunacağını gösteren bir örnek bulunmaktadır.
If ifadesi
Python, if/looops/function vb. için kod bloklarını eklemek için { } kullanmaz. Python, ifadeleri gruplandırmak için bunun yerine iki nokta üst üste (:) ve girinti/boşluk kullanır. "If" boole testinin parantez içinde olması gerekmez (C++/Java ile arasındaki büyük fark) ve *elif* ile *else* deyimleri içerebilir (hatırlatıcı: "elif" kelimesi "else" ile aynı uzunluktadır).
Herhangi bir değer, if-test olarak kullanılabilir. "Sıfır" değerlerin tümü yanlış olarak sayılır: Yok, 0, boş dize, boş liste, boş sözlük. Ayrıca şu iki değere sahip bir Boole türü vardır: True ve False (bunlar int'e dönüştürülür, bunlar 1 ve 0'dır). Python'da normal karşılaştırma işlemleri kullanılır: ==, !=, <, <=, >, >=. Java ve C'nin aksine ==, dizelerle doğru bir şekilde çalışmak için aşırı yüklenmiştir. Boole operatörleri, *and*, *or*, *not* şeklinde yazılan kelimelerdir (Python, C stili && || ! ifadesini kullanmaz). Gün boyunca içecek önerileri sunan bir sağlık uygulaması için kod aşağıdaki gibi görünebilir. Her bir after/else ifadesi blokunun nasıl bir : ile başladığına ve ifadelerin girintilerine göre gruplandırıldığına dikkat edin:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
":" Yukarıdaki türden kodları yazarken en sık karşılaştığım söz dizimi hatasıdır. Muhtemelen bu, C++/Java alışkanlıklarıma kıyasla yazılacak ek bir şey olduğu için. Ayrıca, boole testini parantez içine almayın. Bu bir C/Java alışkanlığıdır. Kod kısaysa, kodu ":" karakterinden sonra aynı satıra yerleştirebilirsiniz. Bu şekilde (bu, işlevler, döngüler, vb. için de geçerlidir), ancak bazı kişiler, alanları ayrı satırlara yerleştirmenin daha okunaklı olduğunu düşünebilir.
if time_hour < 10: print('coffee') else: print('water')
Alıştırma: string1.py
Bu bölümdeki materyallerle ilgili alıştırma yapmak için Temel Alıştırmalar'daki string1.py alıştırmasını deneyin.