Python 內建一個名為「str」的字串類別包含許多便利功能 (有一個較舊的模組名為「string」,而不應使用)。字串常值可用雙引號或單引號包住,但單引號較常使用。反斜線逸出在單引號和雙引號常值中的運作方式都一樣,例如:\n\」。雙引號字串常值可包含不含引號的單引號 (例如 "I do not do it"),而同樣地單引號字串則可包含雙引號。字串常值可以跨越多行,但每一行結尾都必須有反斜線 \ 才能逸出新行。三引號內的字串常值 """或「''」可涵蓋多行文字。
Python 字串「無法變更」代表這些變數在建立後即無法變更 (Java 字串也會使用這個不可變樣式)。由於字串無法變更,因此我們建構「新」字串,以代表計算的值。例如,運算式 ('hello' + 'there') 會納入 2 個字串「hello」以及並建立新字串「hellothere」
字串中的字元可透過標準 [ ] 語法存取,就像 Java 和 C++ 一樣,Python 使用的索引都是從零開始,因此如果 s 是「hello」s[1] 是「e」。如果索引超出字串的邊界,Python 就會引發錯誤。Python 樣式 (與 Perl 不同) 會在無法判斷效果時暫停,而非只製造預設值。方便好用的「Slice」語法 (下方) 也可擷取字串中的任何子字串。len(string) 函式會傳回字串長度。[ ] 語法和 len() 函式實際上適用於任何序列類型,例如字串、清單等。Python 會嘗試讓不同作業類型都能一致地運作。Python 新手瞭解:請勿使用「len」做為變數名稱,以免阻斷 len() 函式。開頭的「+」運算子可以串連兩個字串。請注意,下列程式碼中的變數不會預先宣告,只需指派變數後即可。
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
不同於 Java,「+」無法自動將數字或其他型別轉換為字串格式。str() 函式可將值轉換為字串格式,以便與其他字串合併。
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
對於數字,標準運算子 +、/、* 的運作方式與一般運算子相同。沒有 ++ 運算子,但 +=、-= 以此類推。如果您需要整數除法,請使用 2 個斜線,例如:6 // 5 是 1
「列印」函式通常會輸出一或多個 Python 項目,後接換行。「原始」字串常值前面加上「r」然後傳遞所有字元而不進行特殊處理,因此「r'x\nx'」會求出長度-4 字串「x\nx」。 「列印」可以使用多個引數來變更其輸出方式 (請參閱 python.org 列印函式定義),例如 設定「end」到「」就能在所有項目列印完成後再列印新行。
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
字串方法
以下是一些最常見的字串方法。方法與函式類似,但會「on」執行物件如果 變數 是字串,則程式碼 s.lower() 會對該字串物件執行 low() 方法,並傳回結果 (這個概念在物件上執行方法,就是構成物件方向程式設計 (OOP) 的基本概念之一)。以下是一些最常見的字串方法:
- s.lower(), s.upper() -- 會傳回小寫字串或大寫版本
- s.strip() -- 傳回從開頭和結尾移除空白字元的字串
- s.isalpha()/s.isdigit()/s.isspace()... -- 測試所有字串字元是否位於各種字元類別中
- s.startswith('other'), s.endswith('other') -- 測試字串是否以指定的其他字串開始或結束
- s.find('other') -- 搜尋 s 中的指定其他字串 (非規則運算式),並傳回該字串開頭的第一個索引,如果找不到,則傳回開頭是 -1
- s.replace('old', 'new') -- 會傳回包含所有「舊」的字串已由「new」取代
- s.split('delim') -- 傳回由指定分隔符號分隔的子字串清單。分隔符號並非規則運算式,只是文字。「aaa,bbb,ccc'.split(,)」['aaa'、'bbb'、'ccc']。為方便特殊情況,s.split() (不含引數) 會分割給所有空白字元。
- s.join(list) -- 與 split() 相反,會使用字串做為分隔符號,合併指定清單中的元素。例如:'---'.join(['aaa', 'bbb', 'ccc']) ->aaa---bbb---ccc
透過 Google 搜尋「python str」應會將您導向官方的 python.org 字串方法,其中列出所有 str 方法。
Python 沒有獨立的字元類型。而是 s[8] 這類運算式會傳回含有該字元的字串-length-1。使用這個 string-length-1 時,運算子 ==、<=、... 可以如預期般運作,因此大部分不必知道 Python 沒有獨立的純量「char」類型。
字串切片
「片段」語法很適合用來參照序列的子部分,通常是字串和清單。切片 s[start:end] 是從開頭的元素開始,並延伸到 (但不包括結尾) 的元素。假設我們將 s =「Hello」
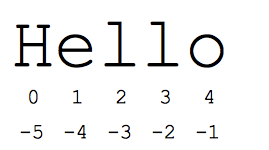
- s[1:4] 是「ell」-- 索引從索引 1 開始,最多可延伸至 4,但不包含索引 4
- s[1:] 是「ello」-- 省略任一索引預設為字串的開頭或結尾
- s[:] 是「Hello」-- 如果省略兩者,系統會一律複製整個內容 (這是複製字串或清單等序列的 Python 方法)
- s[1:100] 是「ello」-- 過長的索引超出字串長度
標準的零開始索引號碼可讓使用者輕鬆存取接近字串開頭的字元。Python 將使用負數做為替代方法,讓您輕鬆存取字串結尾的字元:s[-1] 是最後一個字元「o」,s[-2] 是「l」排下一個字元等等負索引數會從字串末尾往回計算:
- s[-1] 為「o」-- 最後一個字元 (從結尾處的第 1 個字元)
- s[-4] 是「e」-- 結尾的第 4 個
- s[:-3] 是「他」-- 開頭,但不包含最後 3 個字元。
- s[-3:] 是「llo」-- 從結尾的第 3 個字元開始,並延伸至字串結尾。
這是對任何索引 n「s[:n] + s[n:] == s」而言有巧妙的切片真相。即使 n 或大於 n 也是如此。或者,使用其他方式的 s[:n] 和 s[n:] 一律將字串分為兩個字串部分,並保留所有字元。我們會在稍後的清單章節中說明,片段功能也適用於清單。
字串格式
Python 的其中一項妙用 就是將物件自動轉換為 適合列印的字串兩種內建方式執行此操作的方法是格式化字串 常值 (又稱為「f-strings」),以及叫用 str.format()。
格式化字串常值
在下列情況中,您通常會看到格式化字串常值:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
格式化常值字串的前置字串是「f」(例如用於原始字串的「r」前置字元)。 大括號 '{}' 以外的任何文字而非直接輸出出來「{}」中包含的運算式是 會依據 格式規格 設定格式有許多巧妙,包括截斷與 轉換成科學記號,並靠左/右/置中對齊。
想要輸出物件表格時,f-strings 非常實用 代表要對齊的不同物件屬性的資料欄
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
字串 %
Python 還有一個類似 printf() 的設施,用來將一個字串組合在一起。% 運算子會使用左側的 printf 類型格式字串 (%d int、%s 字串、%f/%g 浮點),以及右側元組中相符的值 (元組由半形逗號分隔的值組成,通常位於括號內):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
上面這行的內容很長,假設您想要將它分行。你無法只將「%」後方的線條就像使用其他語言一樣,Python 預設會將每一行視為單獨的陳述式,因此您不必在各行輸入半形分號。如要修正這個問題,請用外括號括住整個運算式,這樣運算式即可涵蓋多行。這種跨行程式碼技巧適用於各種分組結構,詳細說明如下:( )、 [ ] 和 { }。
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
好了,但這條線仍很長。Python 能讓您將一行切斷成多個區塊,然後系統會自動串連這些區塊。因此,如要縮短這行文字的長度,我們可以這麼做:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
字串 (Unicode 與位元組)
一般 Python 字串是 unicode。
Python 也支援由純位元組組成的字串 (字串常值前方須加上前置字串「b」) 例如:
> byte_string = b'A byte string' > byte_string b'A byte string'
unicode 字串是位元組字串中的不同物件型別,但各種程式庫,例如 如果傳送任何一種字串,規則運算式就可以正常運作。
如要將一般 Python 字串轉換為位元組,請對字串呼叫 encode() 方法。另一方面,位元組字串 decode() 方法會將已編碼的純位元組轉換成萬國碼 (Unicode) 字串:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
以下範例顯示如何開啟帶有某種編碼的文字檔並解讀 Unicode 字串。
陳述式
Python 不會使用 { } 來包住 if/loops/function 等的程式碼區塊。Python 會改用冒號 (:) 和縮排/空白字元將陳述式分組。表示不需要在括號中 (與 C++/Java 有顯著差異) 的布林測試,可以包含 *elif* 和 *else* 子句 (記憶法:「elif」這個字的長度與「else」這個字的長度相同)。
任何值都可以做為 if-test 使用。「零」值的所有計數都會計為 false:無、0、空白字串、空白清單、空白字典。另外還有包含兩個值的布林值類型:True 和 False (轉換為 int,兩者均為 1 和 0)。Python 常用的比較作業如下:==、!=、<、<=、>、>=。有別於 Java 和 C,== 已超載以便處理字串。布林運算子是寫出的字詞 *and*、*or*,*不是* (Python 不會使用 C-style && || !)。全天候提供飲料推薦的健康應用程式的程式碼如下所示。請注意,然後/else 陳述式每個區塊的開頭都是 :,且陳述式依縮排分組:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
我發現省略「:」是我最常輸入的語法錯誤,通常是因為輸入了這一種程式碼,而不是 C++/Java 的習慣。另外,也不要用括號括住布林測試,因為這是 C/Java 的習慣。如果程式碼很短,您可以將程式碼放在「:」之後的同一行,例如,這適用於函式、迴圈等。不過,有些人認為,為了分行分隔,內容較為易讀。
if time_hour < 10: print('coffee') else: print('water')