
建構社群連接器時,您在結構定義中定義的每個欄位都需要資料類型。資料類型會定義欄位的原始類型,例如 BOOLEAN、STRING、NUMBER 等。
除了資料類型以外,Looker Studio 也會使用語意類型。
語意類型有助於說明資料代表的資訊類型。舉例來說,含有 NUMBER 資料類型的欄位可能會透過語意方式代表貨幣金額或百分比,而含有 STRING 資料類型的欄位可以透過語意方式代表城市。如要查看可用的語意類型,請參閱語意類型說明文件
Community Connector 結構定義和 Looker Studio 欄位
定義社群連接器的結構定義時,每個欄位都有各種屬性,決定該欄位在 Looker Studio 中的表示和使用方式。例如:
- conceptType 是在連接器結構定義中使用
conceptType屬性定義。這項屬性會決定該欄位是否被視為維度或指標。如需指標和維度之間的差異,請參閱「維度和指標」一文。 - 可以在連接器結構定義中定義「語意類型」,或是讓 Looker Studio 根據連接器中定義的資料類型屬性和連接器傳回的資料值自動偵測。如要進一步瞭解這項功能的運作方式,請參閱「自動語意類型偵測」。
- 匯總類型可決定指標值 (忽略維度) 是否可重新匯總。將
semantics.isReaggregatable屬性設為true將預設為SUM匯總,否則會設為Auto。您也可以使用defaultAggregationType屬性,手動設定可匯總欄位的預設匯總類型。
當您在 Looker Studio 中使用連接器設定及連線時,欄位編輯器會根據您在上述屬性的定義方式,顯示連接器的完整結構定義。如果您已加入語意類型,這些類型就會按照您的定義顯示。如果您使用自動語意類型偵測,系統便會在偵測到欄位時顯示這些欄位。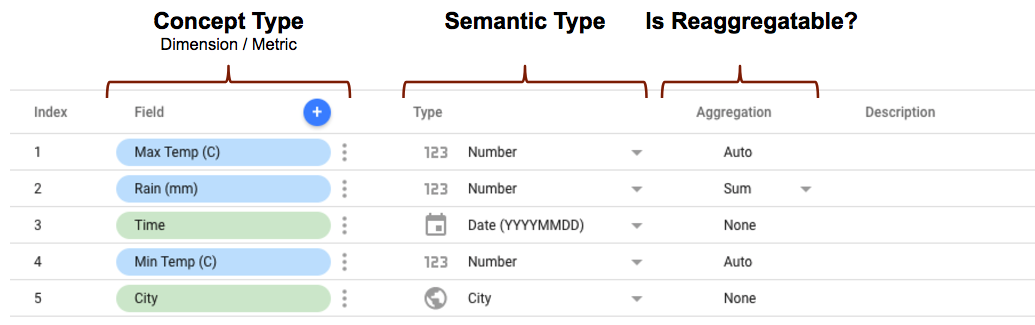
設定語意資訊
設定語意資訊的方法有兩種。您可以手動設定欄位語意,也可以使用 Looker Studio 自動偵測。
舉例來說,如果您的數字在語意上代表美元,Looker Studio 將無法自動偵測這個語意類型。此外,自動語意偵測功能需要 Looker Studio 為結構定義的每個欄位發出資料擷取呼叫。如果您改為手動指定結構定義,系統就不會發出資料擷取呼叫。如果您知道資料的語意類型 (例如貨幣、百分比、日期等),建議基於準確性和效能考量,在結構定義中明確設定。
手動設定語意類型 (建議)
如果您知道語意類型,可以為每個結構定義欄位手動定義 semantics。如需可用屬性的完整詳細資料,請參閱欄位參考資料頁面。如果選擇定義手動語意類型,建議您為每個欄位定義 semanticType 和 semanticGroup。透過手動提供這些屬性,系統不會執行自動語意類型偵測程序。如果您手動設定部分 (非全部) 欄位,則未指定的預設欄位會是 Text、Number 或 Boolean,視欄位指定的 dataType 而定。
以下是手動設定語意類型的簡單結構定義範例。已設為「Income」幣別,Filing Year 設為日期。
手動語意類型疑難排解
如果您未正確設定基礎資料的語意類型,這些類型將無法正常運作。測試並不容易,但您可以執行一些操作來協助找出問題。
- 傳回 2 或 3 個資料列 (而非所有資料),然後手動檢查。
- 在 Looker Studio 中,建立僅使用您要檢查欄位的資料表。
- 請特別注意
Geo和Date欄位,因為這些欄位的格式最為嚴格。
自動語意類型偵測
如果尚未在結構定義中定義任何語意類型,Looker Studio 會嘗試依據資料類型屬性和連接器傳回的資料值格式,嘗試自動偵測這些類型。
自動偵測程序步驟如下:
- 執行社群連接器的
getSchema函式以要求結構定義。 - 將連接器結構定義中定義的多個欄位分批進行疊代,並發出
getData要求這些欄位。系統會透過設為true的sampleExtraction參數執行getData要求,指出資料要求是用於語意偵測。 - 根據欄位資料類型和
getData要求傳回的值格式,識別欄位的語意類型。
自動語意類型偵測作業的處理選項
當 Looker Studio 為了偵測語意而執行社群連接器的 getData 函式時,傳入的要求會包含設為 true 的 sampleExtraction 屬性。連接器傳回的資料只會用於 Looker Studio 來識別欄位的語意類型。由於該值不會用於任何其他用途,因此不需要外部來源的實際資料。
您可以透過以下幾種方式,改善程式碼中的語意類型偵測功能:
建議:傳遞預先定義的值
針對代表欄位語意類型且已知會由 Looker Studio 正確偵測的每個欄位傳回預先定義的值。舉例來說,如果欄位的語意類型為「Country」,則會傳回像是義大利的IT等值。這種做法的另一個好處是,會比較快,因為不需要向第三方服務提出資料要求 HTTP 要求。僅傳回n記錄數量
如果您擷取資料的第三方服務在要求資料時支援資料列限制,則會將一小部分的資料列傳回 Looker Studio,而非完整的資料集。這會限制您必須針對每個語意偵測要求傳送至 Looker Studio 的資料量。要求所有資料欄並快取回應
如果您可以針對您要擷取資料的第三方服務要求所有資料欄,則從 Looker Studio 收到的第一個語意偵測要求時,擷取所有資料欄並快取結果。對於後續的語意偵測要求,會從快取擷取資料欄值,而不是向第三方服務發出額外的 HTTP 要求。「不進行任何操作」
您可以選擇不為sampleExtraction設為true的要求實作任何特定輔助。這會導致 Semantic Detection 速度變慢,因為 Looker Studio 必須擷取所有資料,才能用於語意偵測程序。此外,這也會影響傳送至外部資料來源的要求比率,因為許多語意偵測要求將會同時執行。
自動語意類型偵測作業的識別格式
日期與時間
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- 時間:以秒、微量、毫米和奈米為單位計算的 Epoch 紀元時間。
地理區域
- 洲別名稱或代碼
- 子洲別名稱或代碼
- 區域名稱或代碼
- 國家/地區名稱或代碼。另請參閱 ISO_3166-1。
- 城市名稱
- 以半形逗號分隔的經緯度值
- 指定行銷區域 (DMA) 名稱和代碼