
Quando você cria um conector da comunidade, cada campo definido no esquema requer um tipo de dados. O tipo de dados define o tipo primitivo do campo, como BOOLEAN, STRING, NUMBER etc.
Além dos tipos de dados, o Looker Studio também usa tipos semânticos.
Os tipos semânticos ajudam a descrever quais informações os dados representam. Por exemplo, um campo com um tipo de dados NUMBER pode representar semanticamente um valor monetário ou uma porcentagem, enquanto um campo com tipo de dados STRING pode representar de forma semântica uma cidade. Para ver os tipos semânticos disponíveis, consulte a documentação sobre tipos semânticos.
Esquema do conector da comunidade e campos do Looker Studio
Quando você define o esquema para seu conector da comunidade, há várias propriedades para cada campo que determinarão como ele será representado e usado no Looker Studio. Exemplo:
- O conceptType é definido no esquema do conector usando a propriedade
conceptType. Essa propriedade determina se o campo será tratado como uma dimensão ou métrica. Confira uma explicação sobre a diferença entre métricas e dimensões no artigo Dimensões e métricas. - O tipo semântico pode ser definido no esquema do conector ou detectado automaticamente pelo Looker Studio com base na propriedade do tipo de dados definida no seu conector e nos valores de dados retornados por ele. Consulte Detecção automática do tipo semântico para ver detalhes sobre como isso funciona.
- O tipo de agregação determina se é possível agregar novamente os valores de métrica (as dimensões
são ignoradas). Definir a propriedade
semantics.isReaggregatablecomotruevai padronizar a agregaçãoSUM. Caso contrário, ela será definida comoAuto. Você também pode escolher o tipo de agregação padrão para os campos reagregáveis usando a propriedadedefaultAggregationType.
Quando você configura e se conecta usando um conector no Looker Studio, o editor de campos mostra o esquema completo para o conector com base em como você definiu as propriedades acima. Se você incluiu os tipos semânticos, eles serão exibidos da maneira como você os definiu. Se estiver usando a detecção automática do tipo semântico, os campos serão exibidos conforme foram detectados.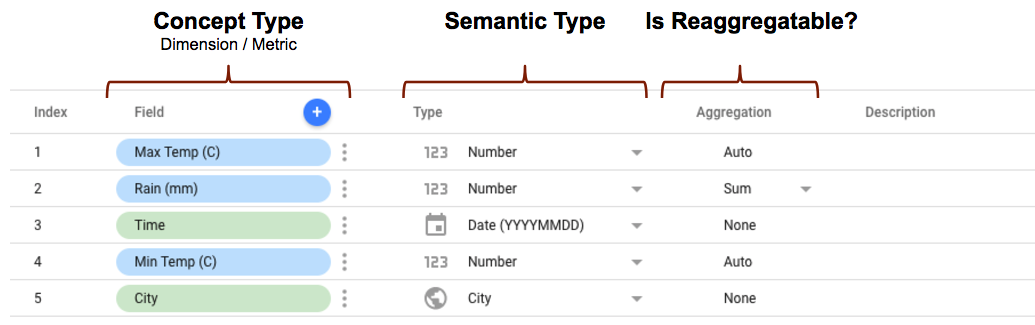
Definir informações semânticas
Há duas maneiras de definir informações semânticas. Você pode definir a semântica de campo manualmente ou deixar que o Looker Studio a detecte de maneira automática.
Por exemplo, se você tiver um número que represente semanticamente dólares americanos, o Looker Studio não poderá detectar esse tipo semântico de forma automática. Além disso, a detecção automática da semântica requer que o Looker Studio faça chamadas de busca de dados para cada campo do seu esquema. Se você especificar o esquema manualmente, nenhuma chamada de busca de dados será feita. Caso você saiba o tipo semântico (por exemplo, moeda, porcentagem, data etc.) das suas informações, recomendamos que o configure no esquema para melhorar a precisão e o desempenho.
Definir tipos semânticos manualmente (recomendado)
Se você souber seus tipos semânticos, poderá definir semantics manualmente para cada campo do esquema. Veja todos os detalhes sobre as propriedades disponíveis para você na página de referência do campo. Se optar por especificar manualmente os tipos semânticos, é recomendável que você defina semanticType e semanticGroup para todos os campos. Quando você fornece as propriedades, o processo de detecção automática do tipo semântico não é executado. Se você definir manualmente alguns dos seus campos, mas não todos, aqueles que você não especificar serão definidos por padrão como Text, Number ou Boolean, dependendo do dataType escolhido para o campo.
Veja a seguir um exemplo de esquema simples que define manualmente os tipos semânticos. Income é definido como a moeda, e Filing Year como a data.
Resolver problemas relacionados aos tipos semânticos manuais
Se você definir seus tipos semânticos para os dados subjacentes de maneira incorreta, eles não funcionarão adequadamente. Isso é difícil de testar, mas há algumas estratégias para ajudar a encontrar problemas.
- Retorne duas ou três linhas dos seus dados em vez de tudo, e faça a inspeção manual.
- Crie uma tabela no Looker Studio que use apenas o campo que você está tentando verificar.
- Preste muita atenção aos campos
GeoeDate, porque eles têm o formato mais rigoroso.
Detecção automática do tipo semântico
Se você não tiver definido nenhum tipo semântico no seu esquema, o Looker Studio vai tentar detectá-lo automaticamente com base na propriedade do tipo de dados e no formato dos valores de dados retornados pelo seu conector.
Estas são as etapas do processo de detecção automática:
- Solicite o esquema executando a função
getSchemado seu conector da comunidade. - Itere usando lotes de campos definidos no esquema do conector e envie solicitações
getDatapara os campos. As solicitaçõesgetDatasão executadas com o parâmetrosampleExtractiondefinido comotruepara indicar que as solicitações de dados são para fins de detecção semântica. - Com base no tipo de dados de campo e no formato do valor retornado da solicitação
getData, identifique o tipo semântico do campo.
Opções de detecção automática do tipo semântico
Quando o Looker Studio executa a função getData de um conector da comunidade para detecção semântica, a solicitação recebida terá uma propriedade sampleExtraction que será definida como true. Os dados retornados pelo seu conector são usados apenas pelo Looker Studio para identificar o tipo semântico do campo. Como o valor não será usado para nenhum outro propósito, não são necessários dados reais da sua fonte externa.
Há várias maneiras de melhorar a detecção do tipo semântico no seu código:
Recomendado: transmita valores predefinidos
Retorne um valor predefinido para cada campo que melhor representa o tipo semântico e é conhecido por ser detectado corretamente pelo Looker Studio. Por exemplo: se o tipo semântico de um campo for País, um valor comoITserá retornado para "Itália". Outra vantagem dessa abordagem é que ela é muito mais rápida, já que não é necessário fazer solicitações HTTP ao serviço de terceiros para receber dados.Retornar apenas n registros
Se o serviço de terceiros do qual você recebe dados for compatível com os limites de linha ao solicitar dados, retorne um pequeno subconjunto de linhas para o Looker Studio em vez do conjunto de dados completo. Isso vai limitar a quantidade de dados que você precisa transmitir ao Looker Studio para cada solicitação de detecção semântica.Solicite todas as colunas e armazene a resposta em cache
Se for possível solicitar todas as colunas para o serviço de terceiros do qual você está buscando dados, na primeira solicitação de detecção semântica recebida do Looker Studio, busque todas as colunas e armazene os resultados em cache. Para as solicitações de detecção semântica subsequentes, busque valores de coluna do cache em vez de fazer outras solicitações HTTP para o serviço de terceiros.Não faça nada diferente
Você pode optar por não implementar nenhuma acomodação específica para solicitações em quesampleExtractioné definido comotrue. Isso fará com que o processo de detecção semântica seja mais lento, já que o Looker Studio terá que buscar todos os dados para esse processo. Além disso, a taxa de solicitação da sua fonte de dados externa será afetada, já que muitos pedidos de detecção semântica serão executadas em paralelo.
Formatos reconhecidos para detecção automática do tipo semântico
Data e hora
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- Hora: época por segundos, microssegundos, milissegundos e nanossegundos.
Informações geográficas
- Nome ou código do continente
- Nome ou código do subcontinente
- Nome ou código da região
- Nome ou código do país Consulte também ISO_3166-1.
- Cidade
- Valores de latitude e longitude separados por vírgula
- Nome e código da Área designada do mercado (DMA)