
Cuando creas un conector de comunidad, cada campo que defines en el
esquema
requiere un tipo de datos. El tipo de datos define el tipo primitivo del campo, como
BOOLEAN, STRING, NUMBER, etcétera.
Además de los tipos de datos, Looker Studio también usa tipos semánticos.
Los tipos semánticos ayudan a describir el tipo de información que representan los datos. Para
ejemplo, un campo con un tipo de datos NUMBER puede representar semánticamente una moneda
cantidad o porcentaje y un campo con un tipo de datos STRING pueden
representan una ciudad. Para ver qué tipos semánticos están disponibles, consulta el
documentación sobre tipos semánticos
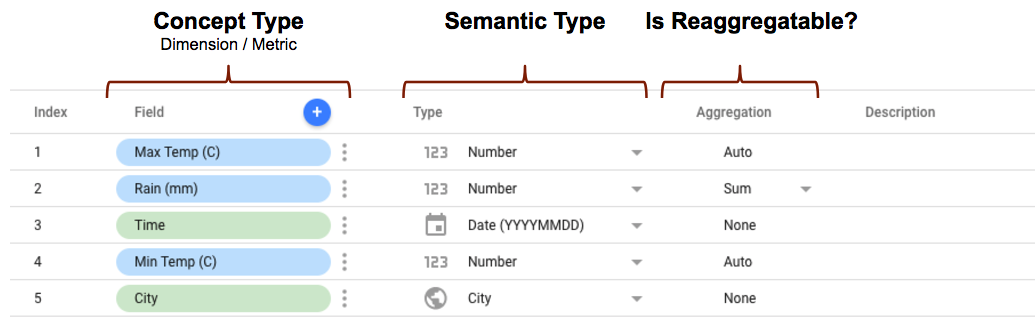
Esquema del Conector de la comunidad y campos de Looker Studio
Cuando defines el esquema para tu Community Connector, hay varios propiedades para cada campo que determinarán cómo se representa el campo y en Looker Studio. Por ejemplo:
- El conceptType es
definido en el esquema del conector con la propiedad
conceptType. Esta determina si el campo se trata como una dimensión o una métrica. Puedes encontrar una explicación sobre la diferencia entre las métricas y las dimensiones. en Dimensiones y métricas. - El tipo semántico puede estar definidos en el esquema del conector o pueden detectarse automáticamente de Looker Studio en función del tipo de dato definida en el conector y los valores de datos que muestra el conector. Consulta Detección automática de tipos semánticos para obtener detalles sobre cómo funciona.
- El tipo de agregación determina si los valores de las métricas (dimensiones
se pueden volver a agregar. Configura el
semantics.isReaggregatablede la propiedad entruese usará de forma predeterminada la agregaciónSUM; de lo contrario, será se define enAuto. También puedes establecer manualmente el tipo de agregación predeterminado para los campos reagregables con eldefaultAggregationTypepropiedad.
Cuando configuras y conectas con un conector en Looker Studio, los campos
editor muestra el esquema completo del conector según cómo lo hayas definido
las propiedades anteriores. Si incluiste los tipos semánticos,
mostrar según lo hayas definido. Si utilizas
detección automática de tipos semánticos, y luego, los campos
aparecerán cuando se detecten.
Configura la información semántica
Hay dos formas de establecer la información semántica. Puedes establecer la semántica de forma manual o confiar en que Looker Studio la detectará automáticamente.
Por ejemplo, si tienes un número que representa semánticamente el dólar estadounidense, Looker Studio no podrá detectar automáticamente este tipo semántico. Además, la detección semántica automática requiere que Looker Studio genere datos y recuperar llamadas para cada campo de tu esquema. Si especificas el esquema de forma manual en su lugar, no se realizarán llamadas de recuperación de datos. En caso de que conozcas el o tipo semántico (p.ej., moneda, porcentaje, fecha, etc.) de tus datos, se recomienda configurar esto explícitamente en el esquema para mejorar la precisión y el rendimiento y otras razones.
Configura los tipos semánticos de forma manual (recomendado)
Si conoces tus tipos semánticos, puedes definir manualmente semantics para cada
schema. Puedes encontrar todos los detalles sobre las propiedades disponibles para ti
en la página de referencia de campos. Si
si eliges definir tipos semánticos manuales, se recomienda que definas
semanticType y semanticGroup para cada campo. Si proporcionas estos datos de forma manual,
el proceso de detección automática de tipos semánticos, no se ejecutará. Si
configurar manualmente algunos de tus campos, pero no todos,
especifica el valor predeterminado Text, Number o Boolean, según el dataType
especificadas para el campo.
El siguiente es un ejemplo de un esquema simple en el que se configuran de forma manual las semánticas
de tipos de datos. Income se establece como moneda, y Filing Year como fecha.
Solución de problemas de tipos semánticos manuales
Si configuras tus tipos semánticos de forma incorrecta para los datos subyacentes, no funcionan correctamente. Esto puede ser difícil de probar, pero hay algunas cosas que puedes hacer para ayudar a encontrar problemas.
- Devuelve 2 o 3 filas de tus datos en lugar de todos y, luego, manualmente. inspeccionarlo.
- Crea una tabla en Looker Studio que solo use el campo que intentas de verificación.
- Presta mucha atención a los campos
GeoyDate, ya que tienen la mayor más estrictos.
Detección automática de tipos semánticos
Si no definiste ningún tipo semántico en tu esquema, entonces Looker Studio intentará detectarlas automáticamente data type y el formato de los valores de datos que muestra el conector.
Los pasos del proceso de detección automática son los siguientes:
- Ejecuta el comando
función
getSchemade la conector de comunidad. - Iterar por lotes de campos definidos en el esquema y problema del conector
getDatasolicita los campos. Las solicitudesgetDatase ejecutan con el parámetrosampleExtraction. se establece entruepara indicar que las solicitudes de datos son para fines semánticos de detección de intrusiones. - Según el tipo de datos de campo y el formato del valor devuelto por el
getData, identifica el tipo semántico del campo.
Opciones para controlar la detección automática de tipos de semántica
Cuando Looker Studio ejecuta la función getData de un conector de comunidad para
para la detección semántica, la solicitud entrante contendrá un
La propiedad sampleExtraction, que se configurará como true. Los datos devueltos por
Looker Studio usa el conector para identificar el tipo semántico de
en el campo. Como el valor no se usará para ningún otro propósito, no
requieren datos reales de tu fuente externa.
Existen varias formas de mejorar la detección de tipos semánticos en tu código:
Recomendación: Pasa valores predefinidos
Muestra un valor predefinido para cada campo que mejor represente la semántica tipo de campo para el campo y que Looker Studio lo detecta de forma correcta. Por ejemplo, si el tipo semántico de un campo es Country, muestra un comoITpara Italia. El otro beneficio de este enfoque es que es mucho más rápida, ya que no requiere que hagas solicitudes HTTP o un servicio de terceros para datos.Muestra solo la cantidad n de registros
Si el servicio de terceros desde el que recuperas datos admite límites de filas cuando solicites datos, devuelve un pequeño subconjunto de filas a Looker Studio. del conjunto de datos completo. Esto limitará la cantidad de datos que debes pasar Looker Studio para cada solicitud de detección semántica.Solicita todas las columnas y almacena la respuesta en caché
Si es posible solicitar todas las columnas del servicio de terceros desde en la que recuperarás los datos en la primera solicitud de detección semántica recibidos de Looker Studio para recuperar todas las columnas y almacenar en caché los resultados Para las solicitudes posteriores de detección semántica recuperan valores de columnas de la caché en lugar de hacer solicitudes HTTP adicionales al servicio de terceros.No hagas nada diferente.
Puedes optar por no implementar ninguna adaptación específica para las solicitudes en las quesampleExtractionse establece entrue. Esto provocará que la detección semántica sea más lento, ya que Looker Studio deberá recuperar todos los datos del Proceso de detección semántica. Esto afectará el porcentaje de solicitudes a tu fuente de datos externa, ya que muchas solicitudes de detección semántica serán se ejecutan en paralelo.
Formatos reconocidos para la detección automática de tipos semánticos
Fecha y hora
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- Tiempo: época para segundo, micro, mili y nano.
Ubicación geográfica
- Código o nombre del continente
- Nombre o código del subcontinente
- Nombre o código de la región
- Nombre o código del país. También consulta ISO_3166-1.
- Nombre de la ciudad
- Valor de latitud y longitud separados por comas
- Nombre y código del Área de marketing designada (DMA)