
构建社区连接器时,您在架构中定义的每个字段都要对应一种数据类型。数据类型定义了字段的基本类型,例如
BOOLEAN、STRING、NUMBER 等
除了数据类型之外,Looker Studio 还使用语义类型。
语义类型可帮助描述数据表示的信息类型。例如,数据类型为 NUMBER 的字段在语义上可以表示货币金额或百分比,而数据类型为 STRING 的字段在语义上可以表示城市。要查看可以使用哪些语义类型,请查阅语义类型文档
社区连接器架构和 Looker Studio 字段
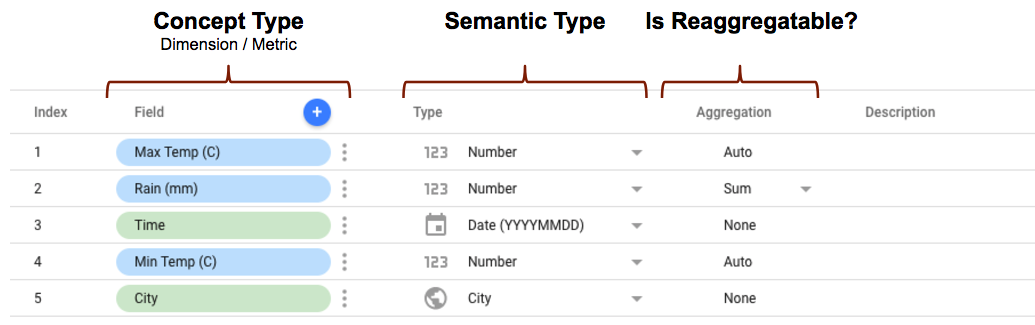
定义社区连接器架构时,您会遇到多种 每个字段的属性,这些属性将决定字段的表示方式; 数据。例如:
- conceptType 为
使用
conceptType属性在连接器架构中定义。这个 属性决定了该字段是维度还是指标。 有关指标和维度之间的差异的说明,请参阅 在 维度和指标。 - 语义类型 可以在连接器架构中定义,也可以由系统自动检测 生成的内容 data type 属性在 及其返回的数据值。请参阅 自动语义类型检测 其工作原理。
- 汇总类型决定着指标值(维度
可以重新汇总。设置
semantics.isReaggregatable属性设为true,则默认为SUM聚合,否则为 设为Auto。此外,您还可以使用defaultAggregationType属性为可重新聚合的字段手动设置默认聚合类型。
当您在 Looker Studio 中使用连接器进行配置和连接时,这些字段
编辑器会根据您定义的方式显示连接器的完整架构
上述属性如果您已纳入语义类型,则字段将按照您定义的方式显示。如果您使用的是
自动语义类型检测,那么对
与检测到的代码完全相同
设置语义信息
设置语义信息的方式有两种。您可以设置 语义检测或依靠 Looker Studio 自动检测。
例如,如果某个数字在语义上表示美元, Looker Studio 无法自动检测此语义类型。 此外,自动语义检测需要 Looker Studio 将数据 提取对架构中每个字段的调用反之,如果您手动指定架构,则不会发起任何数据提取调用。如果您知道数据的语义类型(例如,货币、百分比、日期等),出于准确度和效果考虑,我们建议您在架构中进行明确设置。
手动设置语义类型(推荐)
如果您知道自己的语义类型,则可以手动为每个架构字段定义 semantics。如需了解可用属性的完整详细信息,请访问字段参考页面。如果您选择定义手动语义类型,建议您为每个字段定义 semanticType 和 semanticGroup。手动提供这些属性时,系统不会运行自动语义类型检测流程。如果您手动为部分字段(而非全部字段)设置语义类型,则您未指定的字段的语义类型默认为 Text、Number 或 Boolean,具体取决于为字段指定的 dataType。
以下是一个简单的架构示例,该架构可手动设置语义
。Income 设为货币,Filing Year 设为日期。
对手动语义类型进行问题排查
如果您未正确设置基础数据的语义类型,这些数据将无法正常工作。要测试此类问题并非易事,但您可以执行以下操作来帮助发现问题。
- 返回 2 行或 3 行数据(而非全部数据),然后手动返回 进行检查。
- 在 Looker Studio 中创建一个表格,该表格仅使用您要尝试的字段 检查。
- 密切留意
Geo和Date字段,因为它们的格式最为严格。
自动语义类型检测
如果您尚未在架构中定义任何语义类型,请使用 Looker Studio 都会尝试根据 data type 属性和格式 您的连接器返回的数据值之一。
自动检测流程的步骤如下:
- 执行社区连接器的
getSchema函数,以请求架构。 - 反复迭代连接器架构中定义的批量字段并解决相关问题
getData会请求这些字段。getData请求使用sampleExtraction参数执行 设置为true,表示数据请求用于语义检查 检测。 - 根据字段数据类型和
getData请求返回的值的格式来确定字段的语义类型。
处理自动语义类型检测的选项
当 Looker Studio 针对以下各项执行社区连接器的 getData 函数时:
语义检测的目的,传入请求将包含
sampleExtraction 属性,该属性将设为 true。由
Looker Studio 只会使用连接器来识别
字段。由于该值不用于任何其他用途,因此不需要来自外部来源的实际数据。
您可以通过以下几种方法改进代码的语义类型检测:
建议:传递预定义值
为每个字段返回最能表示语义的预定义值 并且已知被 Looker Studio 可正确检测到。 例如,如果某个字段的语义类型是“国家/地区”,则返回IT(对应意大利)等值。这种方法的另一好处是处理速度要快得多,因为它不需要您向第三方服务发起 HTTP 请求以获取数据。仅返回 n 个记录
您从中提取数据的第三方服务支持行数上限 然后改为将一小部分行返回到 Looker Studio 完整数据集。这会限制您需要向 Looker Studio(适用于每个语义检测请求)。请求所有列并缓存响应
是否可以从 用于提取数据,然后在收到第一个语义检测请求时 提取所有列并缓存结果。对于后续语义检测请求,请从缓存中提取列值,而不是向第三方服务发起额外的 HTTP 请求。执行相同的操作
对于sampleExtraction已设为true的请求,您可以选择不做任何具体调整。这会导致语义检测 因为 Looker Studio 必须提取所有数据 语义检测流程。此外,由于许多语义检测请求都是并行执行的,因此这种方法还会影响对外部数据源的请求速率。
适用于自动语义类型检测的认可的格式
日期与时间
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- 时间:秒、微秒、毫秒和纳秒(新纪元时间)。
地理位置
- 大陆名称或代码
- 次大陆名称或代码
- 地区名称或代码
- 国家/地区名称或代码。此外, 请参阅 ISO_3166-1。
- 城市名称
- 以逗号分隔的经纬度值
- 特定媒体市场区域 (DMA) 名称和代码