监督式学习的任务定义明确,可应用于各种场景,例如识别垃圾内容或预测降水量。
监督式学习的基础概念
监督式机器学习基于以下核心概念:
- 数据
- 型号
- 培训
- 正在评估
- 推理
数据
数据是机器学习的推动力。数据以存储在表格中的字词和数字的形式提供,或以图片和音频文件中捕获的像素和波形的值的形式提供。我们会在数据集中存储相关数据。例如,我们可能有以下数据集:
- 猫的图片
- 房价
- 天气信息
数据集由包含特征和标签的各个示例组成。您可以将示例视为类似于电子表格中的单行。特征是监督式模型用于预测标签的值。标签是“答案”,即我们希望模型预测的值。在用于预测降雨量的天气模型中,特征可以是纬度、经度、温度、湿度、云量、风向和大气压。标签为降雨量。
同时包含特征和标签的示例称为有标签示例。
两个有标签的示例

与之相反,无标签示例包含特征,但没有标签。创建模型后,模型会根据特征预测标签。
两个无标签示例
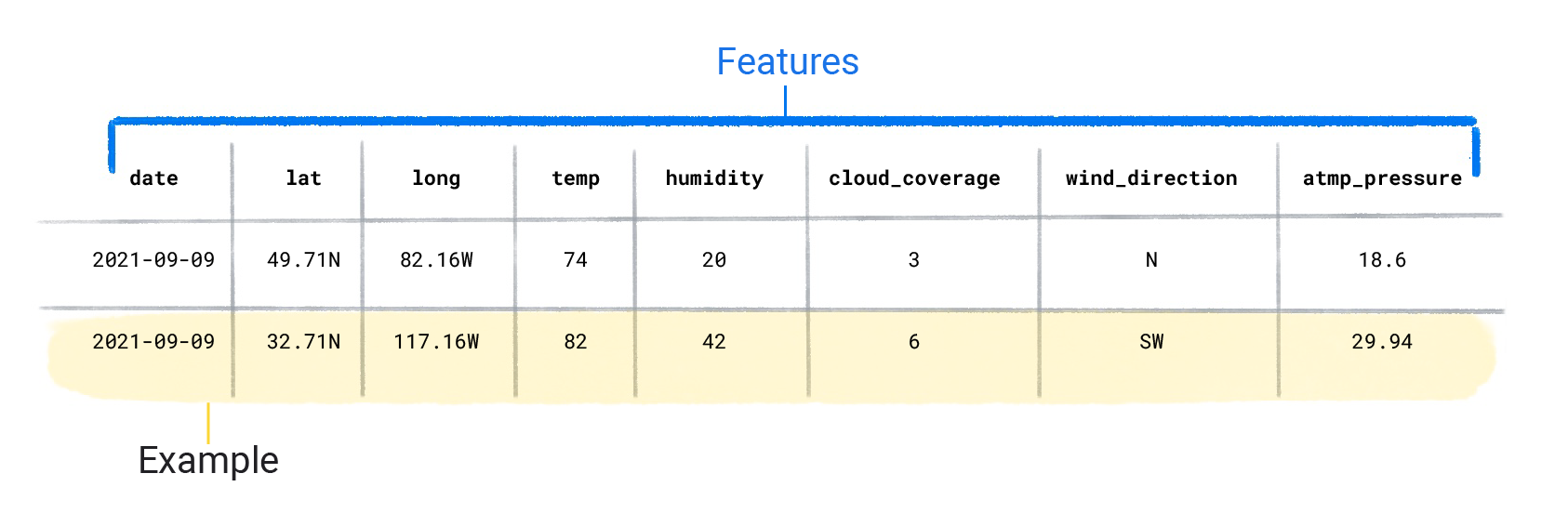
数据集特征
数据集的特点在于其大小和多样性。大小表示示例数量。多样性表示这些示例涵盖的范围。优质的数据集既大又多样。
有些数据集既大又多样。不过,有些数据集很大,但多样性较低,有些数据集很小,但多样性很高。换句话说,数据集规模大并不保证多样性足够,多样性足够也不保证示例足够。
例如,一个数据集可能包含 100 年的数据,但仅限 7 月份。如果使用此数据集来预测 1 月份的降雨量,预测结果会不准确。反之,数据集可能仅涵盖几年,但包含每个月的数据。由于此数据集包含的年份不足以反映变异性,因此可能会产生不准确的预测结果。
检查您的理解情况
数据集还可以通过其特征数量进行描述。例如,某些天气数据集可能包含数百个地图项,从卫星图像到云层覆盖率值都有。其他数据集可能只包含三四个特征,例如湿度、大气压和温度。包含更多特征的数据集可以帮助模型发现更多模式并做出更准确的预测。不过,包含更多特征的数据集并不一定会生成能做出更准确预测的模型,因为某些特征可能与标签没有因果关系。
型号
在监督式学习中,模型是一组复杂的数字,用于定义特定输入特征模式与特定输出标签值之间的数学关系。模型会通过训练发现这些模式。
培训
监督式模型必须先接受训练,然后才能进行预测。为了训练模型,我们会向模型提供包含标记示例的数据集。模型的目标是找出根据特征预测标签的最佳解决方案。该模型会将其预测值与标签的实际值进行比较,以找到最佳解决方案。模型会根据预测值与实际值之间的差异(定义为“损失”)逐步更新其解决方案。换句话说,模型会学习特征与标签之间的数学关系,以便对未见过的数据做出最准确的预测。
例如,如果模型预测降雨量为 1.15 inches,但实际值为 .75 inches,则模型会修改其解决方案,使其预测结果更接近 .75 inches。在模型查看数据集中的每个示例(在某些情况下,会多次查看)后,它会得出一个解决方案,该解决方案能针对每个示例做出平均最佳预测。
以下代码演示了如何训练模型:
该模型接受单个标记示例,并提供预测结果。
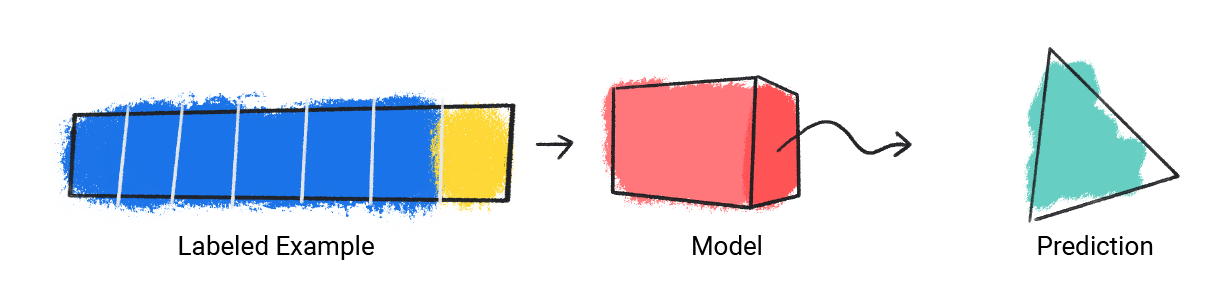
图 1. 机器学习模型根据标记的示例进行预测。
模型会将其预测值与实际值进行比较,并更新其解决方案。
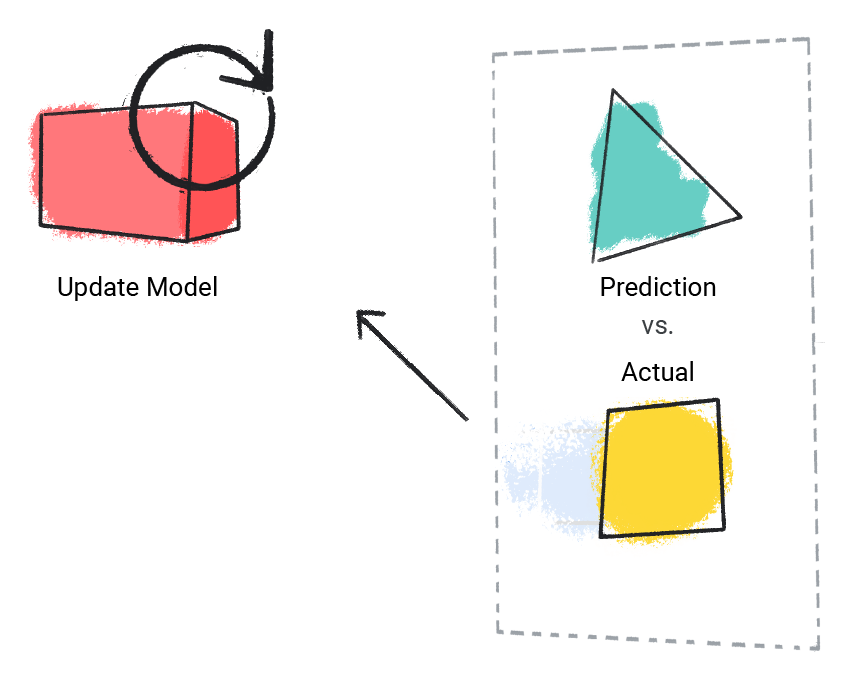
图 2. 机器学习模型正在更新其预测值。
模型会对数据集中的每个标记示例重复此过程。
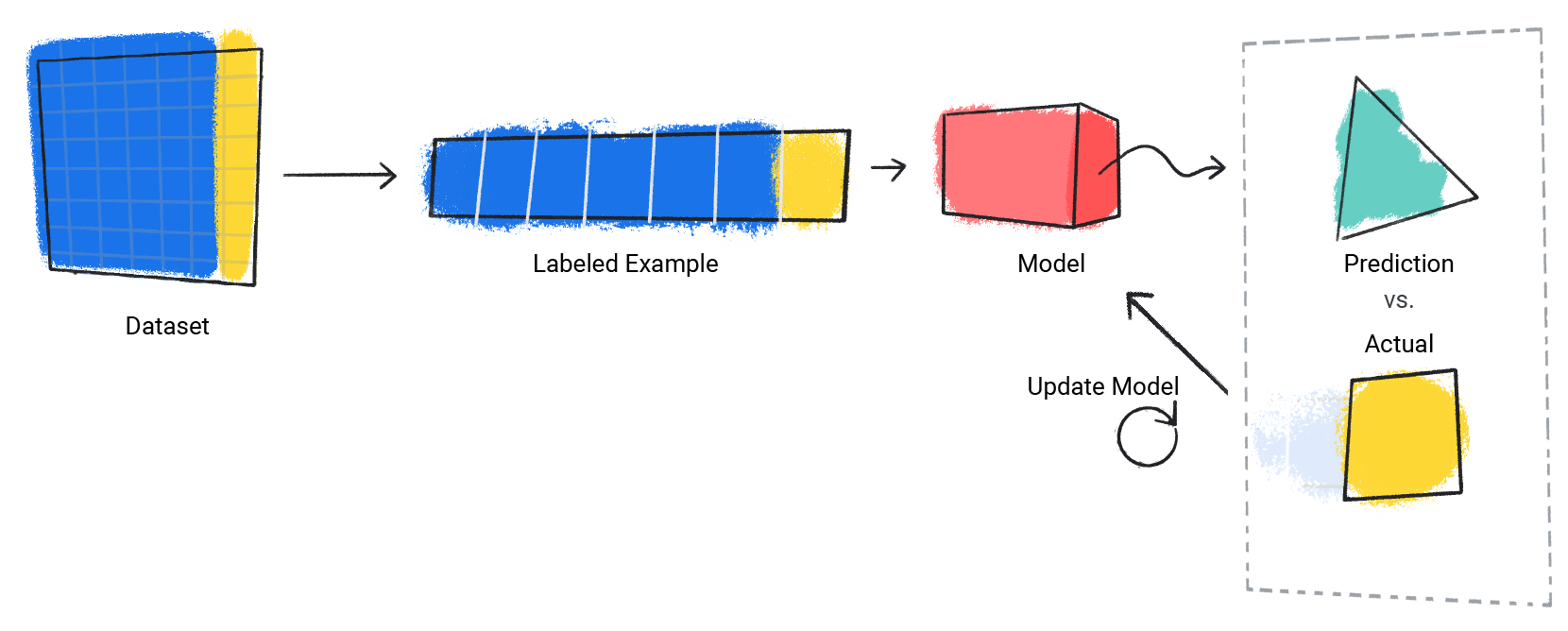
图 3. 机器学习模型正在更新训练数据集中每个标记示例的预测结果。
这样,模型会逐渐学习特征与标签之间的正确关系。这种逐步理解也是大型多样化数据集能够生成更好模型的原因。模型看到了更多值范围更广的数据,并对特征与标签之间的关系有了更深入的了解。
在训练期间,机器学习从业者可以对模型用于进行预测的配置和特征进行微妙调整。例如,某些特征的预测能力比其他特征更强。因此,机器学习从业者可以选择模型在训练期间使用哪些特征。例如,假设某个天气数据集包含 time_of_day 作为地图项。在这种情况下,机器学习从业者可以在训练期间添加或移除 time_of_day,以了解模型在添加或移除 time_of_day 后能否做出更准确的预测。
正在评估
我们会评估训练好的模型,以确定其学习效果。评估模型时,我们使用标记数据集,但只向模型提供数据集的特征。然后,我们将模型的预测结果与标签的真实值进行比较。
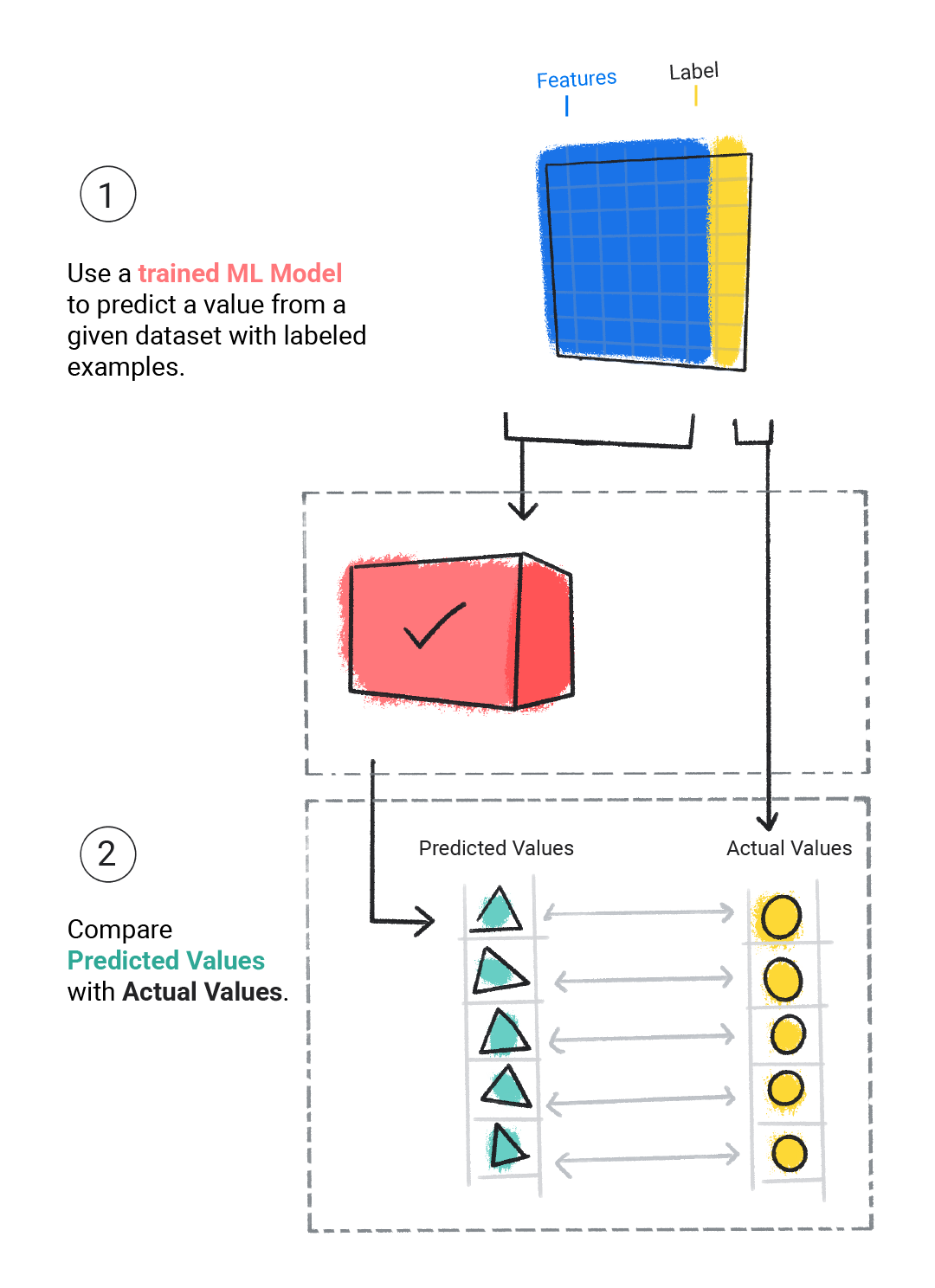
图 4. 通过将机器学习模型的预测结果与实际值进行比较来评估模型。
根据模型的预测结果,我们可能会在将模型部署到真实应用之前进行更多训练和评估。
检查您的理解情况
推理
对模型评估结果感到满意后,我们就可以使用该模型对无标签示例进行预测(称为推理)。在天气应用示例中,我们会向模型提供当前天气状况(例如温度、大气压和相对湿度),然后模型会预测降雨量。