Les tâches de l'apprentissage supervisé sont bien définies et peuvent être appliquées à une multitude de scénarios, comme l'identification du spam ou la prévision des précipitations.
Concepts fondamentaux de l'apprentissage supervisé
Le machine learning supervisé repose sur les concepts de base suivants:
- Données
- Modèle
- Formation
- Évaluation
- Inférence
Données
Les données sont le moteur du ML. Les données se présentent sous la forme de mots et de nombres stockés dans des tableaux, ou sous la forme de valeurs de pixels et de formes d'onde capturées dans des images et des fichiers audio. Nous stockons les données associées dans des ensembles de données. Par exemple, nous pouvons avoir un ensemble de données composé des éléments suivants:
- Images de chats
- Prix des logements
- Informations météo
Les ensembles de données sont constitués d'exemples individuels contenant des caractéristiques et un libellé. Vous pouvez considérer un exemple comme étant analogue à une seule ligne dans une feuille de calcul. Les caractéristiques sont les valeurs qu'un modèle supervisé utilise pour prédire le libellé. L'étiquette correspond à la "réponse", ou à la valeur que nous souhaitons que le modèle prédise. Dans un modèle météorologique qui prédit les précipitations, les caractéristiques peuvent être la latitude, la longitude, la température, l'humidité, la couverture nuageuse, la direction du vent et la pression atmosphérique. Le libellé est quantité de précipitations.
Les exemples qui contiennent à la fois des caractéristiques et une étiquette sont appelés exemples étiquetés.
Deux exemples avec étiquettes

À l'inverse, les exemples sans libellé contiennent des caractéristiques, mais aucun libellé. Une fois le modèle créé, il prédit l'étiquette à partir des caractéristiques.
Deux exemples sans étiquette
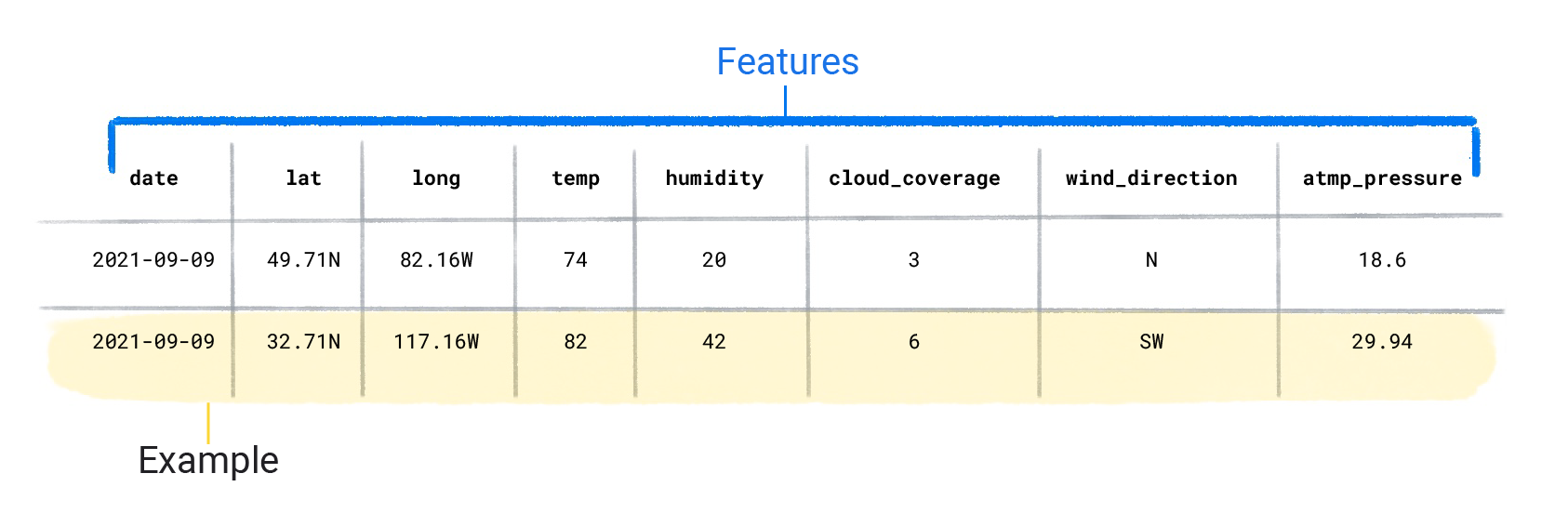
Caractéristiques de l'ensemble de données
Un ensemble de données est caractérisé par sa taille et sa diversité. La taille indique le nombre d'exemples. La diversité indique la plage couverte par ces exemples. Les bons ensembles de données sont à la fois volumineux et très diversifiés.
Les ensembles de données peuvent être volumineux et variés, volumineux mais non variés, ou petits mais très variés. En d'autres termes, un grand ensemble de données ne garantit pas une diversité suffisante, et un ensemble de données très diversifié ne garantit pas un nombre d'exemples suffisant.
Par exemple, un ensemble de données peut contenir 100 ans de données, mais uniquement pour le mois de juillet. Utiliser ce jeu de données pour prédire les précipitations en janvier produirait de mauvaises prévisions. À l'inverse, un ensemble de données peut ne couvrir que quelques années, mais contenir tous les mois. Cet ensemble de données peut produire de mauvaises prédictions, car il ne contient pas suffisamment d'années pour tenir compte de la variabilité.
Testez vos connaissances
Un ensemble de données peut également être caractérisé par le nombre de ses éléments géographiques. Par exemple, certains ensembles de données météorologiques peuvent contenir des centaines d'éléments, allant des images satellites aux valeurs de couverture nuageuse. D'autres ensembles de données ne peuvent contenir que trois ou quatre éléments, comme l'humidité, la pression atmosphérique et la température. Les ensembles de données comportant plus de fonctionnalités peuvent aider un modèle à découvrir des tendances supplémentaires et à effectuer de meilleures prédictions. Cependant, les ensembles de données comportant plus de caractéristiques ne pas toujours produisent des modèles qui génèrent de meilleures prédictions, car certaines caractéristiques peuvent n'avoir aucune relation causale avec l'étiquette.
Modèle
Dans l'apprentissage supervisé, un modèle est l'ensemble complexe de nombres qui définit la relation mathématique entre des schémas de caractéristiques d'entrée spécifiques et des valeurs de libellé de sortie spécifiques. Le modèle découvre ces tendances au cours de l'entraînement.
Formation
Avant qu'un modèle supervisé puisse effectuer des prédictions, il doit être entraîné. Pour entraîner un modèle, nous lui fournissons un ensemble de données avec des exemples étiquetés. L'objectif du modèle est de trouver la meilleure solution pour prédire les étiquettes à partir des caractéristiques. Le modèle trouve la meilleure solution en comparant sa valeur prédite à la valeur réelle du libellé. En fonction de la différence entre les valeurs prévues et réelles (définie comme la perte), le modèle met à jour progressivement sa solution. En d'autres termes, le modèle apprend la relation mathématique entre les caractéristiques et l'étiquette afin de pouvoir effectuer les meilleures prédictions sur des données non visibles.
Par exemple, si le modèle a prédit 1.15 inches de pluie, mais que la valeur réelle était .75 inches, le modèle modifie sa solution afin que sa prédiction soit plus proche de .75 inches. Une fois que le modèle a examiné chaque exemple de l'ensemble de données (dans certains cas, plusieurs fois), il arrive à une solution qui effectue les meilleures prédictions, en moyenne, pour chacun des exemples.
L'exemple suivant montre comment entraîner un modèle:
Le modèle reçoit un seul exemple annoté et fournit une prédiction.
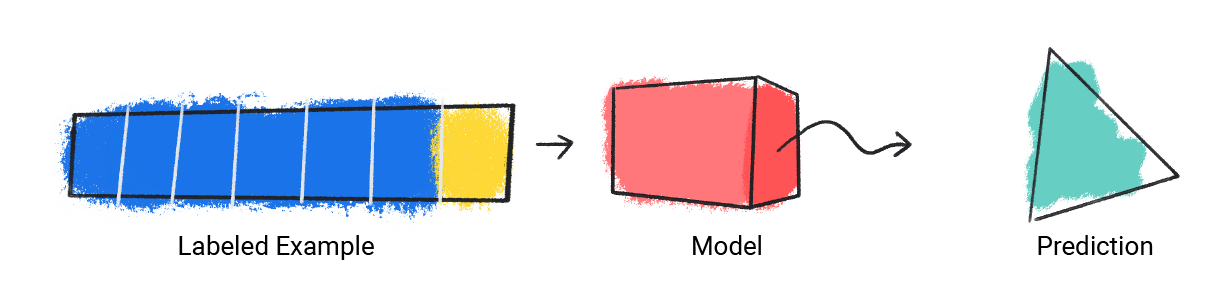
Figure 1 : Modèle de ML effectuant une prédiction à partir d'un exemple étiqueté.
Le modèle compare sa valeur prédite à la valeur réelle et met à jour sa solution.
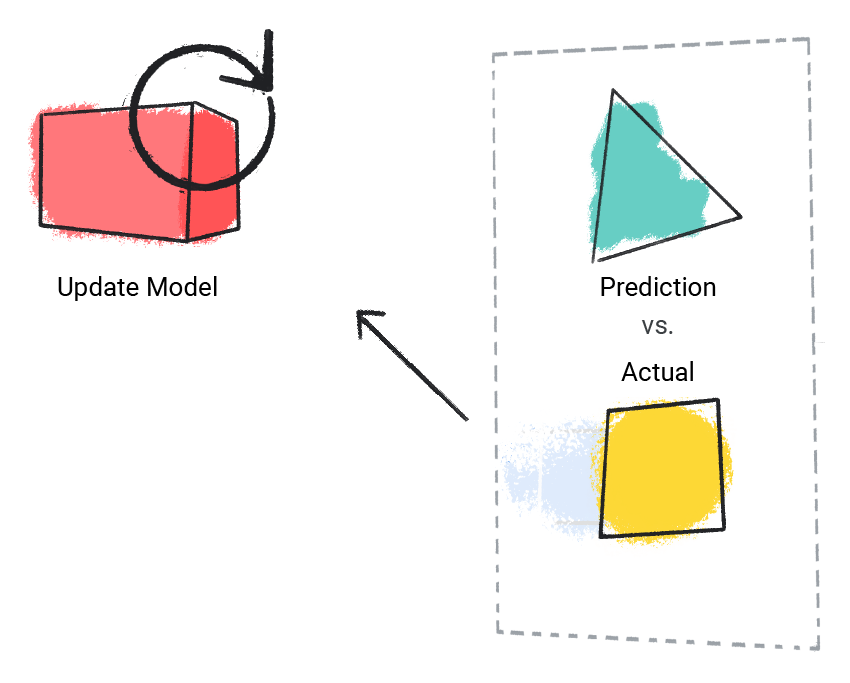
Figure 2 : Modèle de ML mettant à jour sa valeur prédite.
Le modèle répète ce processus pour chaque exemple étiqueté de l'ensemble de données.
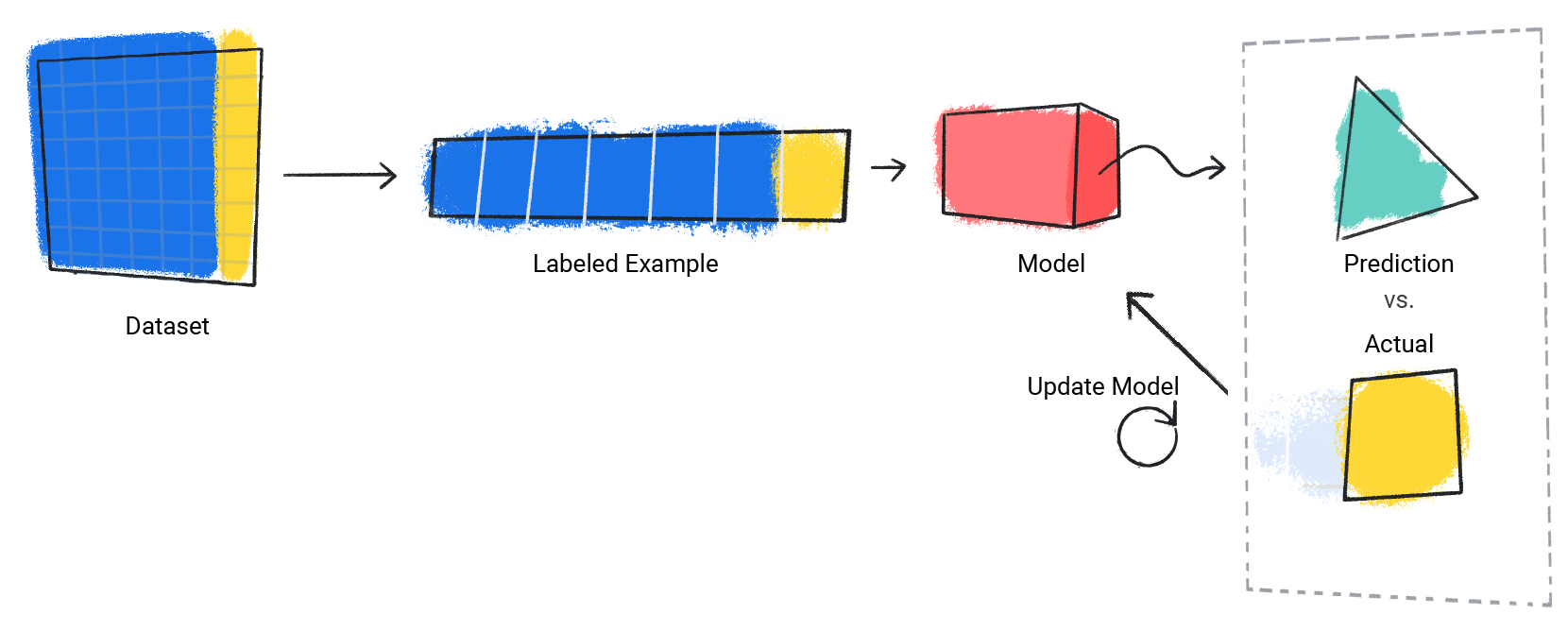
Figure 3. Modèle de ML mettant à jour ses prédictions pour chaque exemple étiqueté de l'ensemble de données d'entraînement.
De cette manière, le modèle apprend progressivement la relation correcte entre les caractéristiques et l'étiquette. C'est aussi pour cette raison que les ensembles de données volumineux et diversifiés génèrent un meilleur modèle. Le modèle a vu plus de données avec une plage de valeurs plus large et a affiné sa compréhension de la relation entre les caractéristiques et l'étiquette.
Lors de l'entraînement, les professionnels du ML peuvent apporter des ajustements subtils aux configurations et aux fonctionnalités utilisées par le modèle pour effectuer des prédictions. Par exemple, certaines caractéristiques ont plus de pouvoir prédictif que d'autres. Par conséquent, les professionnels du ML peuvent sélectionner les fonctionnalités que le modèle utilise lors de l'entraînement. Par exemple, supposons qu'un ensemble de données météorologiques contienttime_of_day comme caractéristique. Dans ce cas, un professionnel du ML peut ajouter ou supprimer time_of_day pendant l'entraînement pour voir si le modèle effectue de meilleures prédictions avec ou sans lui.
Évaluation
Nous évaluons un modèle entraîné pour déterminer dans quelle mesure il a appris. Lorsque nous évaluons un modèle, nous utilisons un ensemble de données libellé, mais nous ne fournissons au modèle que les caractéristiques de l'ensemble de données. Nous comparons ensuite les prédictions du modèle aux valeurs réelles de l'étiquette.
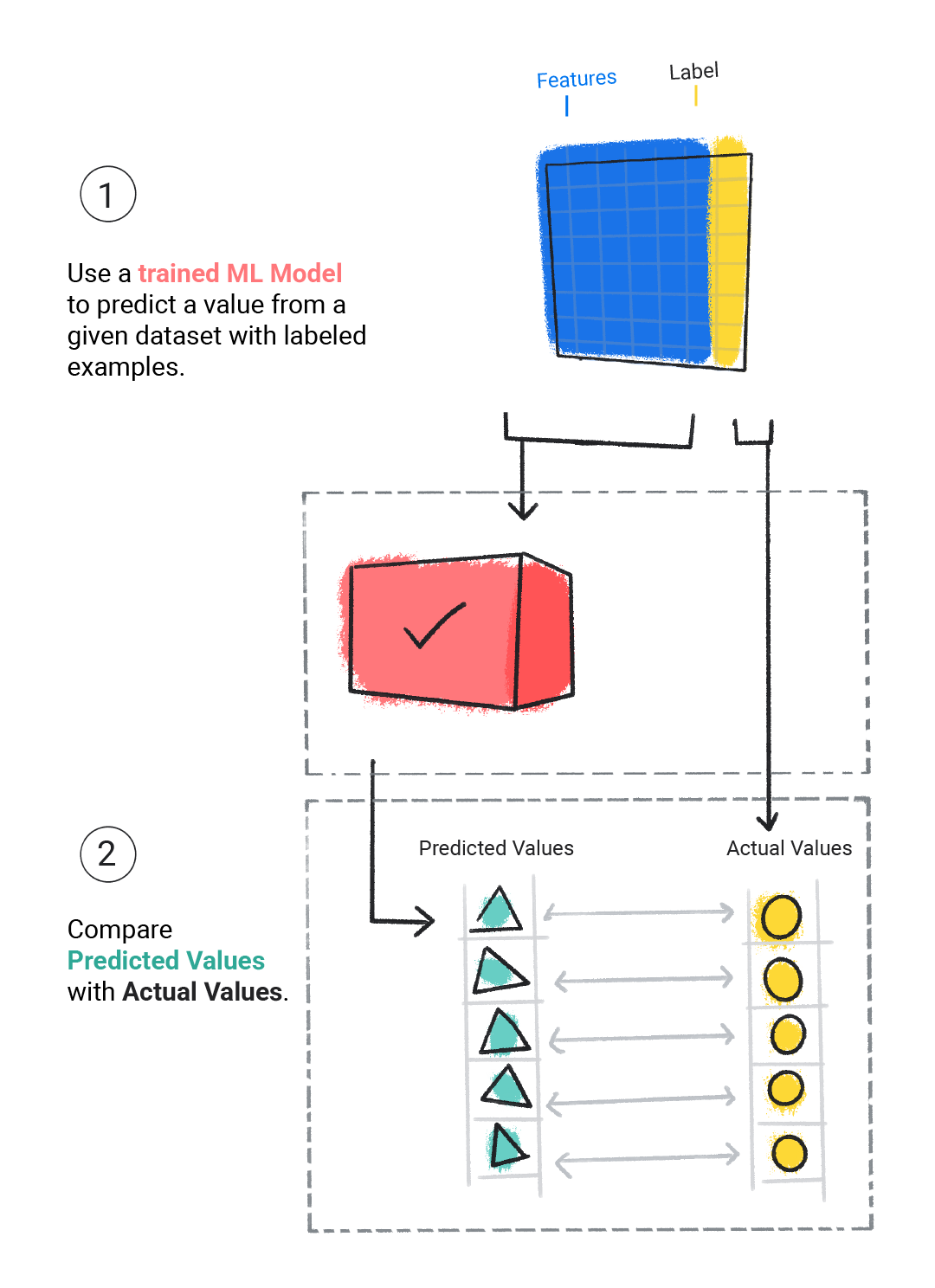
Figure 4. Évaluer un modèle de ML en comparant ses prédictions aux valeurs réelles.
En fonction des prédictions du modèle, nous pouvons effectuer davantage d'entraînement et d'évaluation avant de le déployer dans une application réelle.
Testez vos connaissances
Inférence
Une fois que nous sommes satisfaits des résultats de l'évaluation du modèle, nous pouvons l'utiliser pour effectuer des prédictions, appelées inférences, sur des exemples non étiquetés. Dans l'exemple de l'application météo, nous fournirions au modèle les conditions météorologiques actuelles (comme la température, la pression atmosphérique et l'humidité relative), et il prédirait la quantité de précipitations.