As tarefas do aprendizado supervisionado são bem definidas e podem ser aplicadas a uma infinidade de cenários, como a identificação de spam ou a previsão de precipitação.
Conceitos básicos de aprendizado supervisionado
O machine learning supervisionado é baseado nos seguintes conceitos principais:
- Dados
- Modelo
- Treinamento
- Avaliando
- Inferência
Dados
Os dados são a força motriz do ML. Os dados vêm na forma de palavras e números armazenados em tabelas ou como valores de pixels e formas de onda capturados em arquivos de imagem e áudio. Armazenamos dados relacionados em conjuntos de dados. Por exemplo, podemos ter um conjunto de dados com os seguintes itens:
- Imagens de gatos
- Preços de imóveis
- Informações sobre a previsão do tempo
Os conjuntos de dados são compostos de exemplos individuais que contêm recursos e um rótulo. Você pode pensar em um exemplo como análogo a uma única linha em uma planilha. Os atributos são os valores que um modelo supervisionado usa para prever o rótulo. O rótulo é a "resposta", ou o valor que queremos que o modelo preveja. Em um modelo meteorológico que prevê chuvas, os recursos podem ser latitude, longitude, temperatura, umidade, cobertura de nuvem, direção do vento e pressão atmosférica. O rótulo seria valor de chuva.
Aqueles que contêm atributos e um rótulo são chamados de exemplos rotulados.
Dois exemplos rotulados

Por outro lado, os exemplos não rotulados contêm atributos, mas nenhum rótulo. Depois que você cria um modelo, o modelo prevê o rótulo dos atributos.
Dois exemplos sem rótulos
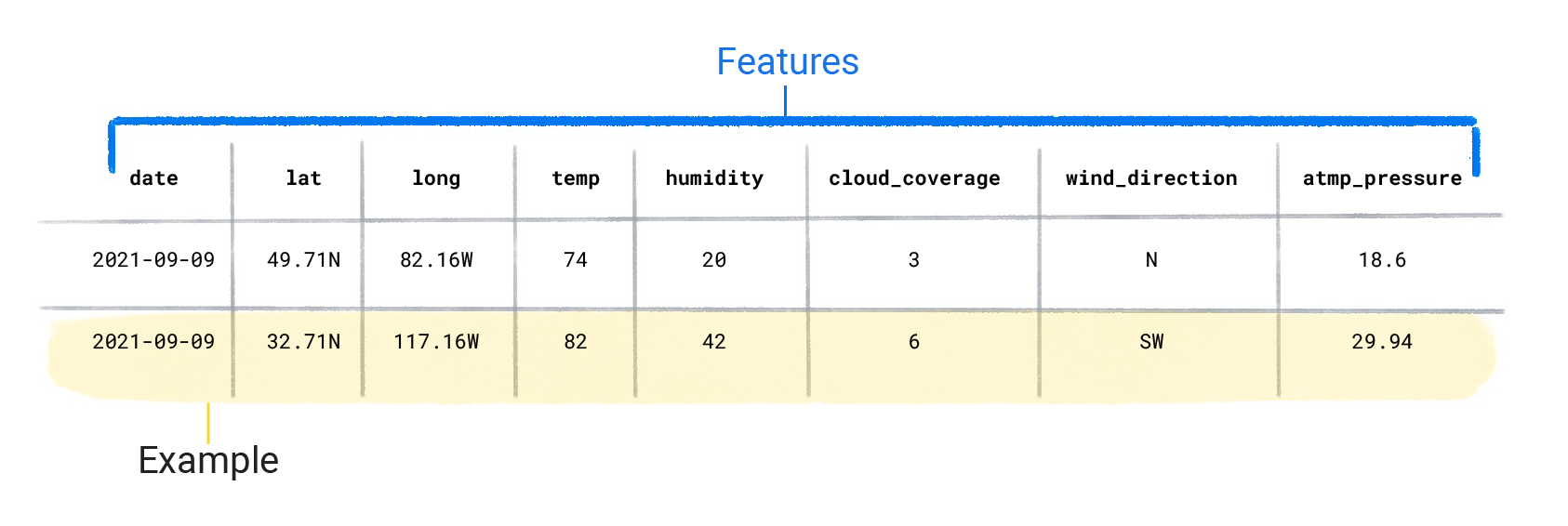
Características do conjunto de dados
Um conjunto de dados é caracterizado por seu tamanho e diversidade. O tamanho indica o número de exemplos. A diversidade indica o intervalo que esses exemplos abrangem. Bons conjuntos de dados são grandes e altamente diversificados.
Alguns conjuntos de dados são grandes e diversos. No entanto, alguns conjuntos de dados são grandes, mas têm baixa diversidade, e outros são pequenos, mas altamente diversificados. Em outras palavras, um conjunto grande de dados não garante diversidade suficiente, e um conjunto de dados altamente diversificado não garante exemplos suficientes.
Por exemplo, um conjunto de dados pode conter 100 anos de dados, mas apenas para o mês de julho. O uso desse conjunto de dados para prever a chuva em janeiro produziria previsões ruins. Por outro lado, um conjunto de dados pode abranger apenas alguns anos, mas contém todos os meses. Esse conjunto de dados pode produzir previsões ruins porque não contém anos suficientes para considerar a variabilidade.
Teste seu conhecimento
Um conjunto de dados também pode ser caracterizado pelo número de atributos. Por exemplo, alguns conjuntos de dados meteorológicos podem conter centenas de atributos, que variam de imagens de satélite a valores de cobertura de nuvem. Outros conjuntos de dados podem conter apenas três ou quatro atributos, como umidade, pressão atmosférica e temperatura. Conjuntos de dados com mais recursos podem ajudar um modelo a descobrir padrões adicionais e fazer previsões melhores. No entanto, conjuntos de dados com mais atributos nem sempre produzem modelos que fazem previsões melhores, porque alguns recursos podem não ter relação causal com o rótulo.
Modelo
No aprendizado supervisionado, um modelo é a coleção complexa de números que definem a relação matemática de padrões de atributos de entrada específicos para valores específicos de rótulo de saída. O modelo descobre esses padrões com o treinamento.
Treinamento
Antes que um modelo supervisionado possa fazer previsões, ele precisa ser treinado. Para treinar um modelo, fornecemos a ele um conjunto de dados com exemplos rotulados. O objetivo do modelo é encontrar a melhor solução para prever os rótulos dos atributos. O modelo encontra a melhor solução comparando o valor previsto com o valor real do rótulo. Com base na diferença entre os valores previstos e reais, definidos como a perda, o modelo atualiza gradualmente a solução. Em outras palavras, o modelo aprende a relação matemática entre os atributos e o rótulo para fazer as melhores previsões em dados não vistos.
Por exemplo, se o modelo previu 1.15 inches de chuva, mas o valor real foi .75 inches, o modelo modifica a solução para que a previsão se aproxime de .75 inches. Depois de analisar cada exemplo no conjunto de dados (em alguns casos, várias vezes), o modelo chega a uma solução que faz as melhores previsões, em média, para cada um dos exemplos.
Veja a seguir o treinamento de um modelo:
O modelo recebe um único exemplo rotulado e fornece uma previsão.
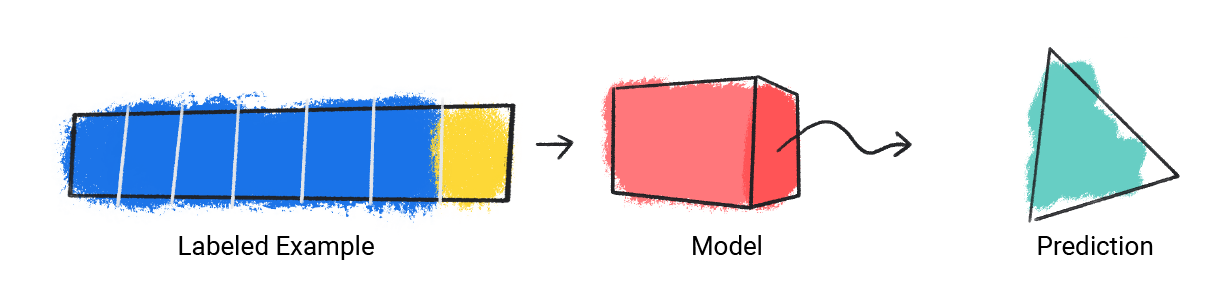
Figura 1. Um modelo de ML fazendo uma previsão com base em um exemplo rotulado.
O modelo compara o valor previsto com o valor real e atualiza a solução.
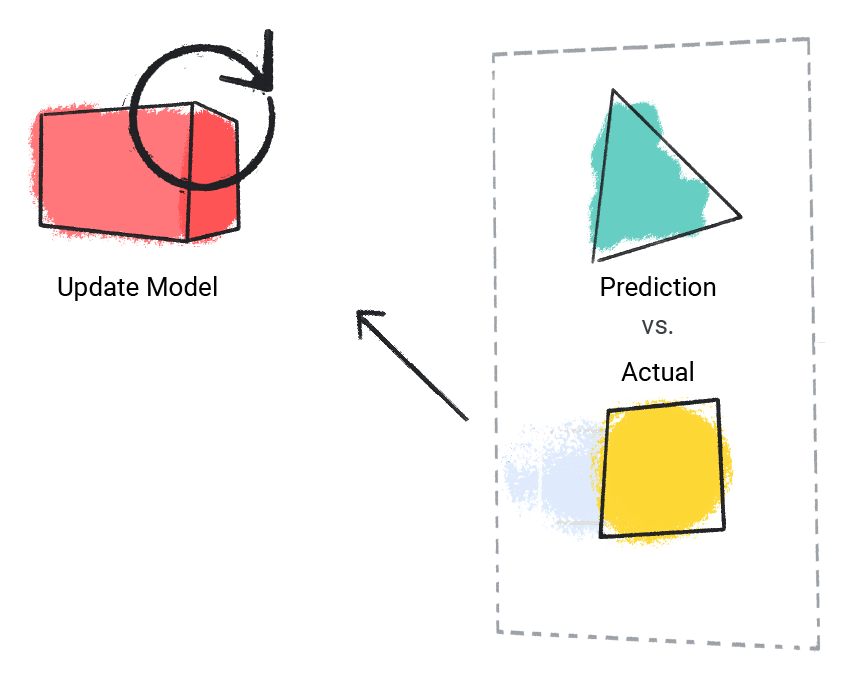
Figura 2. Um modelo de ML atualizando o valor previsto.
O modelo repete esse processo para cada exemplo rotulado no conjunto de dados.
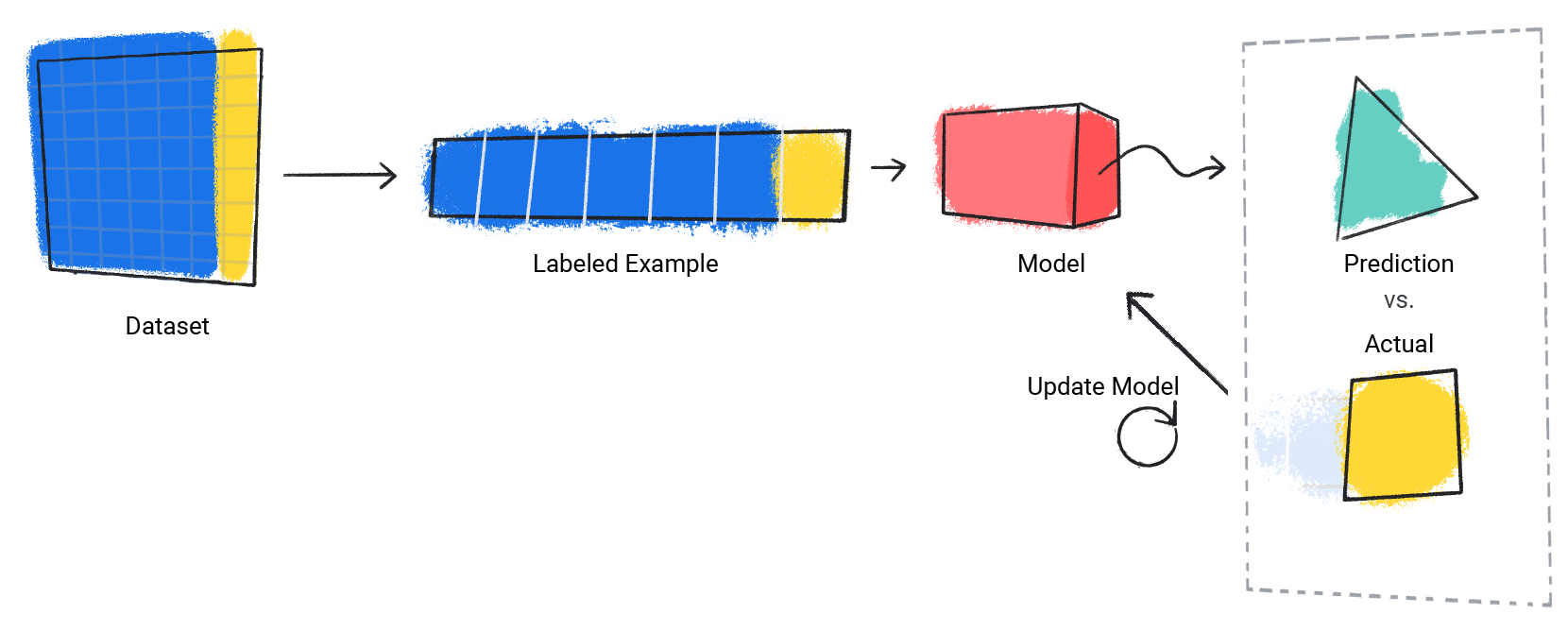
Figura 3. um modelo de ML atualizando as previsões para cada exemplo rotulado no conjunto de dados de treinamento.
Dessa forma, o modelo aprende gradualmente a relação correta entre os recursos e o rótulo. Essa compreensão gradual também é por que conjuntos de dados grandes e diversos produzem um modelo melhor. O modelo viu mais dados com uma gama mais ampla de valores e refinou sua compreensão da relação entre os atributos e o rótulo.
Durante o treinamento, os profissionais de ML podem fazer ajustes sutis nas
configurações e recursos que o modelo usa para fazer previsões. Por exemplo, certos atributos têm mais poder de previsão do que outros. Portanto, os profissionais de ML
podem selecionar quais atributos o modelo usa durante o treinamento. Por exemplo, suponha que um conjunto de dados meteorológicos contenha time_of_day como um atributo. Nesse caso, um profissional de ML pode adicionar ou remover time_of_day durante o treinamento para ver se o modelo faz previsões melhores com ou sem ele.
Avaliando
Avaliamos um modelo treinado para determinar quão bem ele aprendeu. Quando avaliamos um modelo, usamos um conjunto de dados rotulado, mas só informamos os atributos do conjunto de dados ao modelo. Em seguida, comparamos as previsões do modelo com os valores verdadeiros do rótulo.
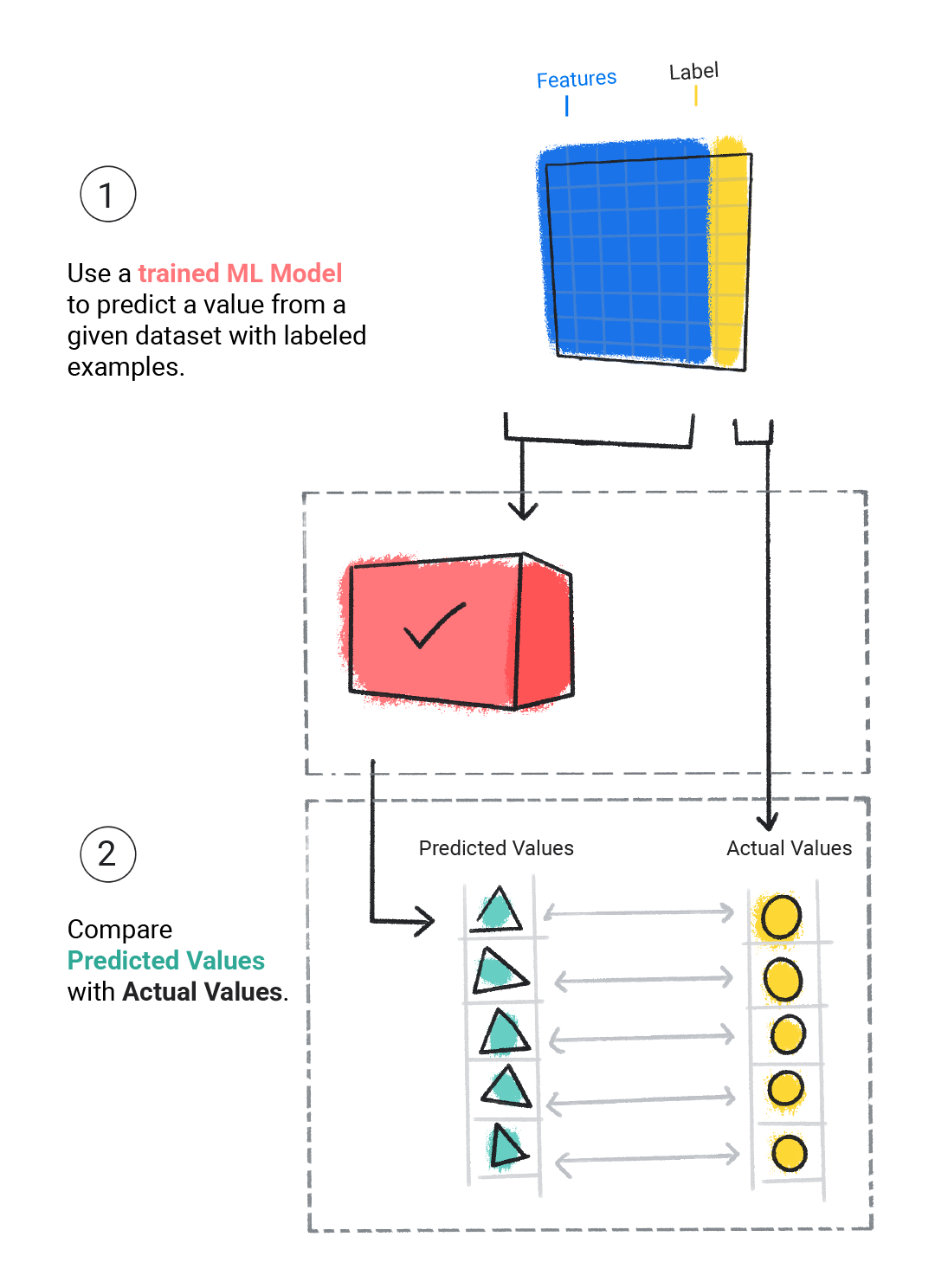
Figura 4. Avaliar um modelo de ML comparando as previsões com os valores reais.
Dependendo das previsões do modelo, é possível treinar e avaliar mais antes de implantá-lo em um aplicativo real.
Teste seu conhecimento
Inferência
Quando estivermos satisfeitos com os resultados da avaliação do modelo, poderemos usá-lo para fazer previsões, chamadas de inferências, em exemplos não rotulados. No exemplo do app meteorológico, forneceríamos ao modelo as condições climáticas atuais, como temperatura, pressão atmosférica e umidade relativa, e ele preveria a quantidade de chuva.