Задачи контролируемого обучения четко определены и могут применяться к множеству сценариев, например к выявлению спама или прогнозированию осадков.
Базовые концепции контролируемого обучения
Контролируемое машинное обучение основано на следующих основных концепциях:
- Данные
- Модель
- Обучение
- Оценка
- Вывод
Данные
Данные являются движущей силой машинного обучения. Данные поступают в виде слов и чисел, хранящихся в таблицах, или в виде значений пикселей и сигналов, зафиксированных в изображениях и аудиофайлах. Мы храним связанные данные в наборах данных. Например, у нас может быть следующий набор данных:
- Изображения кошек
- Цены на жилье
- Информация о погоде
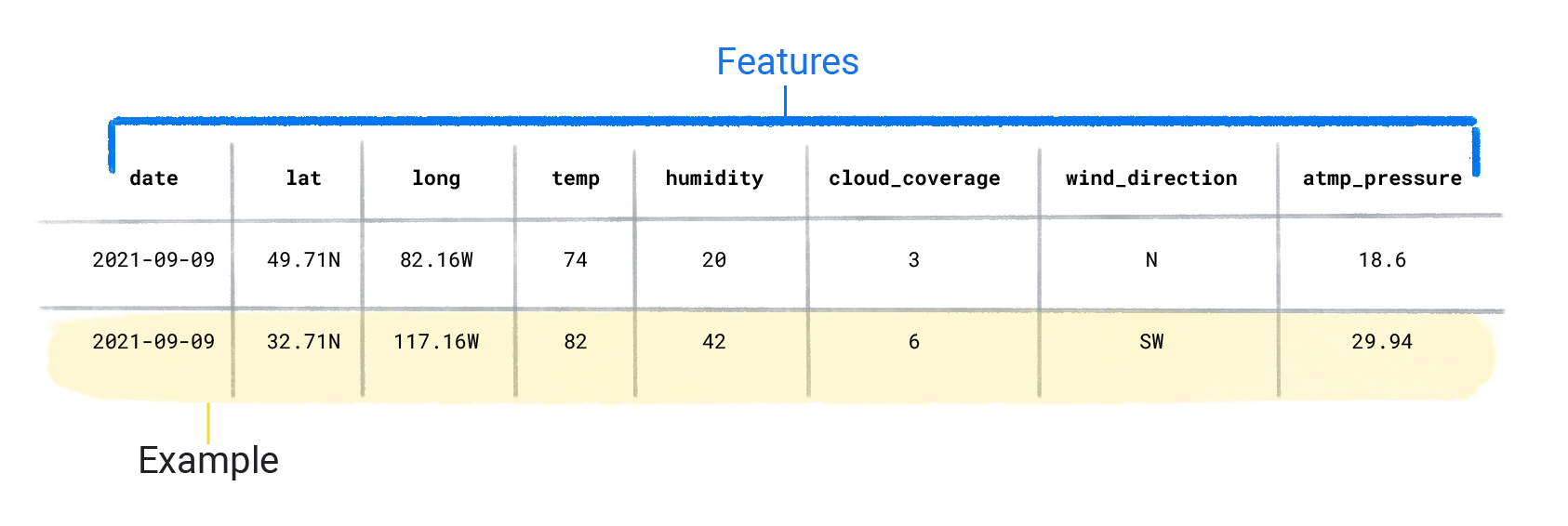
Наборы данных состоят из отдельных примеров , содержащих функции и метки . Вы можете рассматривать пример как аналог одной строки в электронной таблице. Функции — это значения, которые контролируемая модель использует для прогнозирования метки. Метка — это «ответ» или значение, которое мы хотим, чтобы модель предсказывала. В модели погоды, которая предсказывает осадки, такими характеристиками могут быть широта , долгота , температура , влажность , облачность , направление ветра и атмосферное давление . На этикетке будет указано количество осадков .
Примеры, которые содержат как функции, так и метку, называются помеченными примерами .
Два помеченных примера

Напротив, примеры без меток содержат функции, но не имеют меток. После создания модели она прогнозирует метку на основе функций.
Два немаркированных примера
Характеристики набора данных
Набор данных характеризуется своим размером и разнообразием. Размер указывает количество примеров. Разнообразие указывает на диапазон, охватываемый этими примерами. Хорошие наборы данных большие и очень разнообразные.
Наборы данных могут быть большими и разнообразными, большими, но не разнообразными, или маленькими, но очень разнообразными. Другими словами, большой набор данных не гарантирует достаточного разнообразия, а очень разнообразный набор данных не гарантирует достаточного количества примеров.
Например, набор данных может содержать данные за 100 лет, но только за июль. Использование этого набора данных для прогнозирования количества осадков в январе приведет к плохим прогнозам. И наоборот, набор данных может охватывать только несколько лет, но содержать каждый месяц. Этот набор данных может давать плохие прогнозы, поскольку он не содержит достаточного количества лет для учета изменчивости.
Проверьте свое понимание
Набор данных также можно охарактеризовать количеством его признаков. Например, некоторые наборы погодных данных могут содержать сотни объектов, начиная от спутниковых изображений и заканчивая значениями облачности. Другие наборы данных могут содержать только три или четыре характеристики, такие как влажность, атмосферное давление и температура. Наборы данных с большим количеством функций могут помочь модели обнаружить дополнительные закономерности и сделать более точные прогнозы. Однако наборы данных с большим количеством объектов не всегда создают модели, которые дают более точные прогнозы, поскольку некоторые объекты могут не иметь причинно-следственной связи с меткой.
Модель
В обучении с учителем модель представляет собой сложный набор чисел, которые определяют математическую связь между конкретными шаблонами входных объектов и конкретными значениями выходных меток. Модель обнаруживает эти закономерности посредством обучения.
Обучение
Прежде чем контролируемая модель сможет делать прогнозы, ее необходимо обучить. Чтобы обучить модель, мы даем ей набор данных с помеченными примерами. Цель модели — найти лучшее решение для прогнозирования меток на основе функций. Модель находит лучшее решение, сравнивая его прогнозируемое значение с фактическим значением метки. На основе разницы между прогнозируемыми и фактическими значениями, определяемыми как потери , модель постепенно обновляет свое решение. Другими словами, модель изучает математическую взаимосвязь между признаками и меткой, чтобы можно было делать оптимальные прогнозы на основе невидимых данных.
Например, если модель предсказала 1.15 inches дождя, но фактическое значение составило .75 inches , модель модифицирует свое решение так, чтобы ее прогноз был ближе к .75 inches . После того, как модель рассмотрела каждый пример в наборе данных (в некоторых случаях несколько раз), она приходит к решению, которое в среднем дает наилучшие прогнозы для каждого из примеров.
Ниже показано обучение модели:
Модель принимает один помеченный пример и дает прогноз.
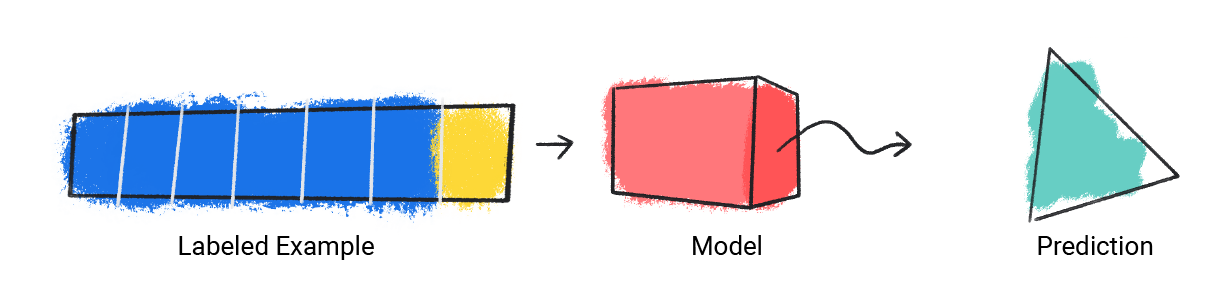
Рисунок 1 . Модель машинного обучения, делающая прогноз на основе помеченного примера.
Модель сравнивает прогнозируемое значение с фактическим значением и обновляет свое решение.
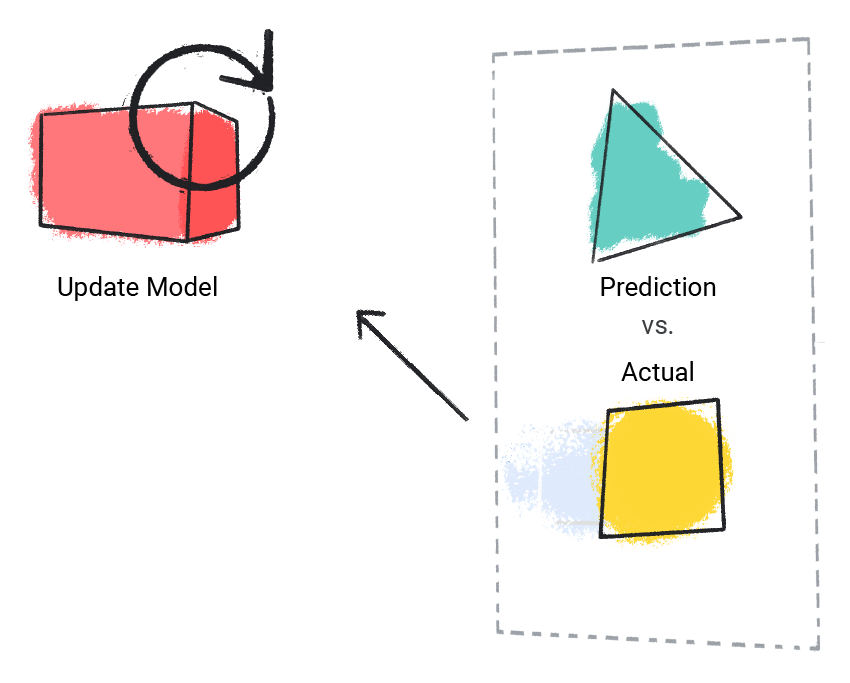
Рисунок 2 . Модель машинного обучения обновляет прогнозируемое значение.
Модель повторяет этот процесс для каждого помеченного примера в наборе данных.
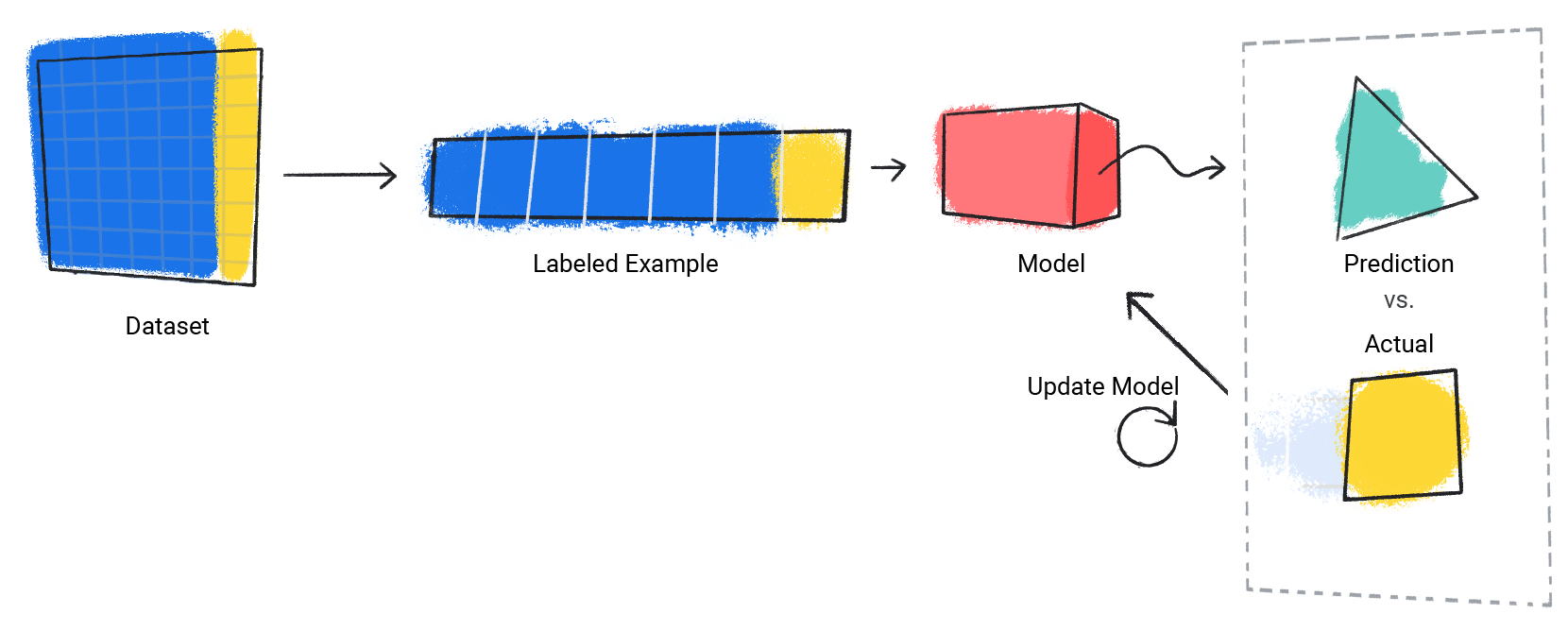
Рисунок 3 . Модель ML обновляет свои прогнозы для каждого помеченного примера в наборе обучающих данных.
Таким образом, модель постепенно узнает правильную связь между функциями и меткой. Это постепенное понимание также является причиной того, почему большие и разнообразные наборы данных создают лучшую модель. Модель получила больше данных с более широким диапазоном значений и уточнила понимание взаимосвязи между функциями и меткой.
Во время обучения специалисты по машинному обучению могут вносить небольшие корректировки в конфигурации и функции, которые модель использует для прогнозирования. Например, некоторые функции обладают большей предсказательной силой, чем другие. Таким образом, специалисты по машинному обучению могут выбирать, какие функции модель будет использовать во время обучения. Например, предположим, что набор данных о погоде содержит функцию time_of_day . В этом случае специалист по машинному обучению может добавить или удалить time_of_day во время обучения, чтобы увидеть, делает ли модель более точные прогнозы с ним или без него.
Оценка
Мы оцениваем обученную модель, чтобы определить, насколько хорошо она обучена. Когда мы оцениваем модель, мы используем помеченный набор данных, но даем модели только функции набора данных. Затем мы сравниваем прогнозы модели с истинными значениями метки.
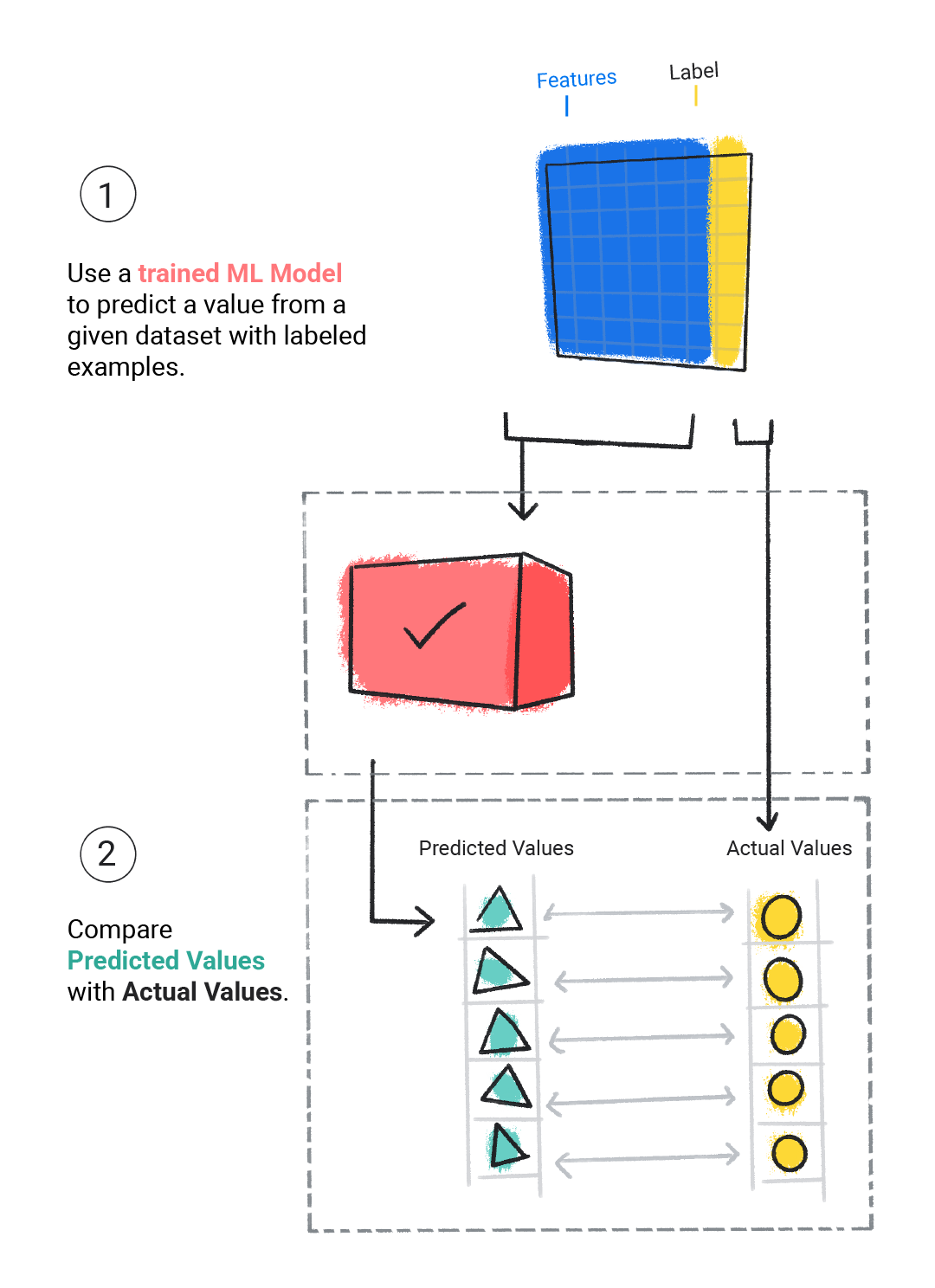
Рисунок 4 . Оценка модели ML путем сравнения ее прогнозов с фактическими значениями.
В зависимости от прогнозов модели мы можем провести дополнительное обучение и оценку перед развертыванием модели в реальном приложении.
Проверьте свое понимание
Вывод
Как только мы будем удовлетворены результатами оценки модели, мы можем использовать ее для прогнозирования, называемого умозаключением , на немаркированных примерах. В примере с погодным приложением мы предоставим модели текущие погодные условия, такие как температура, атмосферное давление и относительная влажность, и она спрогнозирует количество осадков.