많은 문제에 확률 근사치가 필요합니다. 로지스틱 회귀는 확률을 계산하는 매우 효율적인 메커니즘입니다. 사실상 다음과 같은 두 가지 방법 중 하나로 반환된 확률을 사용할 수 있습니다.
- "
- 이진 카테고리로 변환됩니다.
이 확률을 어떻게 사용할 것인지 생각해 봅시다. 한밤중에 개가 짖는 확률을 예측하기 위해 로지스틱 회귀 모델을 만든다고 가정해 보겠습니다. 이 확률을 다음과 같이 지칭합니다.
\[p(bark | night)\]
로지스틱 회귀 모델이 \(p(bark | night) = 0.05\)를 예측하면 1년 이상 개의 강아지는 약 18번 깨어 있습니다.
\[\begin{align} startled &= p(bark | night) \cdot nights \\ &= 0.05 \cdot 365 \\ &~= 18 \end{align} \]
대부분의 경우 로지스틱 회귀 출력을 이진 분류 문제에 해결책으로 매핑합니다. 이 경우 목표는 가능한 두 라벨 중 하나 (예: '스팸' 또는 '스팸 아님'). 이후 모듈에서는 여기에 중점을 둡니다.
로지스틱 회귀 모델이 어떻게 항상 0과 1 사이의 값을 보장하는지 궁금할 수 있습니다. 이때 다음과 같이 정의된 시그모이드 함수가 동일한 특성을 가진 출력을 생성합니다.
시그모이드 함수는 다음 플롯을 생성합니다.
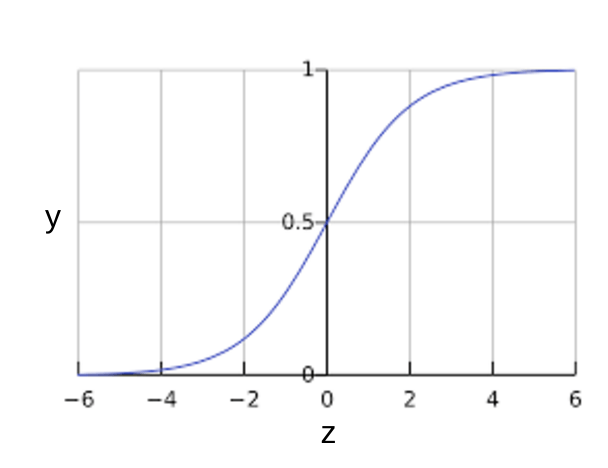
그림 1: 시그모이드 함수
로지스틱 회귀를 사용하여 학습된 모델의 선형 레이어 출력을 \(z\) 나타내면 \(sigmoid(z)\) 가 0과 1 사이의 값 (확률)을 얻게 됩니다. 수학적 용어로는 다음과 같습니다.
각 매개변수는 다음과 같습니다.
- \(y'\) 는 특정 예의 로지스틱 회귀 모델의 출력입니다.
- \(z = b + w_1x_1 + w_2x_2 + \ldots + w_Nx_N\)
- \(w\) 값은 모델의 학습된 가중치이며, \(b\) 는 편향입니다.
- \(x\) 값은 특정 예시의 특성 값입니다.
시그모이드의 역 \(z\) 은 \(1\) 라벨 (예: "dog bark"를 \(0\)라벨 확률 (예: 개 짖는 소리 없음):
다음은 ML 라벨이 있는 시그모이드 함수입니다.

그림 2: 로지스틱 회귀 출력
더하기 아이콘을 클릭하여 로지스틱 회귀 추론 계산 샘플을 확인합니다.
다음과 같은 편향과 가중치를 학습한 특성 3개를 갖는 로지스틱 회귀 모델이 있다고 가정해 보겠습니다.
$$\begin{align} b &= 1 \\ w_1 &= 2 \\ w_2 &= -1 \\ w_3 &= 5 \end{align} $$또한 특정 예에 대해 다음과 같은 특성값을 사용한다고 가정해 보겠습니다.
$$\begin{align} x_1 &= 0 \\ x_2 &= 10 \\ x_3 &= 2 \end{align} $$따라서 로그 오즈는 다음과 같습니다.
다음과 같습니다.
$$(1) + (2)(0) + (-1)(10) + (5)(2) = 1$$따라서 이 예시의 로지스틱 회귀 예측은 0.731입니다.

그림 3: 73.1% 확률