इस ग्लॉसरी में मशीन लर्निंग के सामान्य शब्दों के साथ-साथ, TensorFlow से जुड़े खास शब्दों के बारे में बताया गया है.
जवाब
एब्लेशन
किसी सुविधा या कॉम्पोनेंट को कुछ समय के लिए हटाकर उसकी अहमियत का आकलन करने की तकनीक मॉडल. इसके बाद, उस सुविधा या कॉम्पोनेंट के बिना, मॉडल को फिर से ट्रेनिंग दी जाए और अगर फिर से ट्रेन किए गए मॉडल की परफ़ॉर्मेंस बहुत खराब रही, तो हो सकता है कि हटाई गई सुविधा या कॉम्पोनेंट उसमें अहम भूमिका हो.
उदाहरण के लिए, मान लें कि आपने 10 सुविधाओं पर क्लासिफ़िकेशन मॉडल को ट्रेनिंग दी है और टेस्ट सेट पर 88% सटीक हासिल किया है. पहली सुविधा की अहमियत जानने के लिए, सिर्फ़ नौ अन्य सुविधाओं का इस्तेमाल करके मॉडल को फिर से ट्रेनिंग दी जा सकती है. अगर फिर से ट्रेन किया गया मॉडल काफ़ी खराब परफ़ॉर्म करता है (उदाहरण के लिए, 55% सटीक), तो हटाई गई सुविधा शायद अहम थी. इसके उलट, अगर फिर से रजिस्टर किया गया मॉडल उतना ही अच्छा परफ़ॉर्म करता है तो शायद वह सुविधा ज़्यादा ज़रूरी नहीं थी.
एब्लेशन इन चीज़ों की अहमियत जानने में भी मदद कर सकता है:
- बड़े कॉम्पोनेंट, जैसे कि किसी बड़े एमएल सिस्टम का पूरा सबसिस्टम
- प्रोसेस या तकनीकें, जैसे कि डेटा प्रीप्रोसेसिंग का चरण
दोनों ही मामलों में, आपको दिखेगा कि कॉम्पोनेंट को हटाने के बाद, सिस्टम की परफ़ॉर्मेंस में किस तरह से बदलाव होता है या वह नहीं बदलता है.
A/B टेस्टिंग
दो या उससे ज़्यादा तकनीकों की तुलना करने का आंकड़ों का तरीका—A और B. आम तौर पर, A एक मौजूदा तकनीक है और B एक नई तकनीक है. A/B टेस्टिंग से सिर्फ़ यह पता नहीं चलता कि कौनसी तकनीक बेहतर परफ़ॉर्म कर रही है, बल्कि यह भी पता चल जाता है कि फ़र्क़ आंकड़ों के हिसाब से अहम है या नहीं.
आम तौर पर, A/B टेस्टिंग में दो तकनीकों पर एक ही मेट्रिक की तुलना की जाती है. उदाहरण के लिए, दो तकनीकों की तुलना में मॉडल सटीक कैसे है? हालांकि, A/B टेस्टिंग की मदद से मेट्रिक की किसी भी सीमित संख्या की तुलना भी की जा सकती है.
ऐक्सेलरेटर चिप
खास तरह के हार्डवेयर कॉम्पोनेंट की कैटगरी, जिसे डीप लर्निंग एल्गोरिदम के लिए ज़रूरी कंप्यूटेशन के काम के लिए डिज़ाइन किया गया है.
आम तौर पर इस्तेमाल किए जाने वाले सीपीयू की तुलना में, ऐक्सेलरेटर चिप (या कम शब्दों में कहें, तो ऐक्सेलरेटर) ट्रेनिंग और अनुमान वाले टास्क की स्पीड और क्षमता को बेहतर बना सकते हैं. ये न्यूरल नेटवर्क (न्यूरल नेटवर्क) और कंप्यूटर की तुलना में इस तरह के ज़्यादा मुश्किल टास्क को ट्रेनिंग देने के लिए बिलकुल सही हैं.
ऐक्सेलरेटर चिप के उदाहरणों में ये शामिल हैं:
- Google की Tensor प्रोसेसिंग यूनिट (TPU), जिनमें डीप लर्निंग के लिए खास तौर पर बनाया गया हार्डवेयर है.
- NVIDIA के जीपीयू, शुरुआत में ग्राफ़िक प्रोसेसिंग के लिए डिज़ाइन किए गए हैं. हालांकि, इन्हें साथ-साथ प्रोसेस करने के लिए डिज़ाइन किया गया है, जिससे प्रोसेसिंग की स्पीड बढ़ सकती है.
सटीक
सही क्लासिफ़िकेशन के सुझावों की संख्या को, अनुमानों की कुल संख्या से भाग दिया जाता है. यानी:
उदाहरण के लिए, अगर किसी मॉडल ने 40 सही अनुमान दिए हैं और 10 गलत अनुमान लगाए हैं, तो उसका नतीजा कितना सटीक होगा:
बाइनरी क्लासिफ़िकेशन, सही सुझावों और गलत अनुमानों की अलग-अलग कैटगरी के लिए खास नाम देता है. इसलिए, बाइनरी क्लासिफ़िकेशन के लिए सटीक फ़ॉर्मूला इस तरह है:
कहां:
- TP, ट्रू पॉज़िटिव (सही अनुमान) की संख्या होती है.
- TN, सही नेगेटिव (सही अनुमान) की संख्या है.
- FP गलत सकारात्मक (गलत पूर्वानुमान) की संख्या है.
- FN, गलत नेगेटिव (गलत अनुमान) की संख्या होती है.
सटीक जानकारी और याद रखें की मदद से, सटीक जानकारी की तुलना करें.
ऐक्शन गेम
रीइन्फ़ोर्समेंट लर्निंग में, वह तकनीक जिससे एजेंट, एनवायरमेंट के स्टेट के बीच ट्रांज़िशन करता है. एजेंट, नीति का इस्तेमाल करके कार्रवाई चुनता है.
ऐक्टिवेशन फ़ंक्शन
एक ऐसा फ़ंक्शन जो न्यूरल नेटवर्क को सुविधाओं और लेबल के बीच नैनलाइनर (मुश्किल) के संबंधों को समझने में मदद करता है.
ऐक्टिवेशन से जुड़े लोकप्रिय फ़ंक्शन में ये शामिल हैं:
ऐक्टिवेशन फ़ंक्शन के प्लॉट कभी भी सीधी लाइन नहीं होते हैं. उदाहरण के लिए, ReLU ऐक्टिवेशन फ़ंक्शन के प्लॉट में दो सीधी लाइनें होती हैं:

सिगमॉइड ऐक्टिवेशन फ़ंक्शन का प्लॉट इस तरह दिखता है:

उदाहरण देखने के लिए आइकॉन पर क्लिक करें.
न्यूरल नेटवर्क में, ऐक्टिवेशन फ़ंक्शन न्यूरॉन के सभी इनपुट के वेट किए गए योग में बदलाव करते हैं. भारित योग की गणना करने के लिए, न्यूरॉन प्रासंगिक मानों और भार के उत्पादों को जोड़ता है. उदाहरण के लिए, मान लें कि किसी न्यूरॉन के लिए काम के इनपुट में ये चीज़ें शामिल हैं:
| इनपुट वैल्यू | इनपुट वज़न |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0मान लें कि इस न्यूरल नेटवर्क के डिज़ाइनर ने सिगमॉइड फ़ंक्शन को ऐक्टिवेशन फ़ंक्शन के तौर पर चुना है. इस मामले में, न्यूरॉन -2.0 के सिग्मॉइड की गणना करता है, जो करीब 0.12 होता है. इसलिए, न्यूरल नेटवर्क में अगली लेयर पर न्यूरॉन, -2.0 के बजाय 0.12 को पास करता है. नीचे दिए गए डायग्राम में, प्रोसेस के ज़रूरी हिस्से को दिखाया गया है:

ऐक्टिव लर्निंग
ट्रेनिंग का एक तरीका, जिसमें एल्गोरिदम कुछ डेटा चुनता है. ऐक्टिव लर्निंग की सुविधा तब ज़्यादा फ़ायदेमंद होती है, जब लेबल किए गए उदाहरण बहुत कम या महंगे हों. बिना सोचे-समझे लेबल किए गए उदाहरणों की अलग-अलग रेंज की तलाश करने के बजाय, एक ऐक्टिव लर्निंग एल्गोरिदम कुछ खास तरह के उदाहरणों की खोज करता है, जो सीखने के लिए ज़रूरी होते हैं.
AdaGrad
यह एक बेहतरीन ग्रेडिएंट डिसेंट एल्गोरिदम है, जो हर पैरामीटर के ग्रेडिएंट को फिर से स्केल करता है. इससे हर पैरामीटर को एक अलग लर्निंग रेट मिलता है. पूरी जानकारी के लिए, AdaGrad का यह पेपर देखें.
एजेंट
इन्फ़ोर्समेंट लर्निंग में, वह इकाई जो नीति का इस्तेमाल करती है, ताकि एनवायरमेंट के स्टेट के बीच ट्रांज़िशन होने पर, उम्मीद के मुताबिक रिटर्न जनरेट किया जा सके.
आम तौर पर, एजेंट एक ऐसा सॉफ़्टवेयर होता है जो अपने लक्ष्य को पूरा करने के लिए, कई तरह की कार्रवाइयां करता है. साथ ही, इन बदलावों के हिसाब से खुद को ढालने की क्षमता भी रखता है. उदाहरण के लिए, एलएलएम पर आधारित एजेंट, प्लान बनाने के लिए रीइन्फ़ोर्समेंट लर्निंग की नीति लागू करने के बजाय एलएलएम का इस्तेमाल कर सकते हैं.
एगलोमेरेटिव क्लस्टरिंग
हैरारकल क्लस्टरिंग देखें.
गड़बड़ी की पहचान करना
आउटलायर की पहचान करने की प्रोसेस. उदाहरण के लिए, अगर किसी सुविधा का माध्य 100 है और उसका स्टैंडर्ड डीविएशन 10 है, तो गड़बड़ी की पहचान करने वाली सुविधा से 200 वैल्यू को संदिग्ध के तौर पर फ़्लैग करना चाहिए.
AR
ऑगमेंटेड रिएलिटी (एआर) का छोटा नाम.
पीआर कर्व के नीचे का क्षेत्र
PR AUC (पीआर कर्व के दायरे में आने वाला क्षेत्र) देखें.
आरओसी कर्व के दायरे वाला क्षेत्रफल
AUC (आरओसी कर्व के दायरे वाला क्षेत्र) देखें.
आर्टिफ़िशियल जनरल इंटेलिजेंस
यह एक ऐसा सिस्टम है जो इंसानों को छोड़कर, समस्या का हल निकालने, क्रिएटिविटी दिखाने, और ज़रूरत के हिसाब से ढलने के अलग-अलग तरीकों का इस्तेमाल करता है. उदाहरण के लिए, आर्टिफ़िशियल सामान्य इंटेलिजेंस दिखाने वाला प्रोग्राम, टेक्स्ट का अनुवाद कर सकता है, सिंफ़नी तैयार कर सकता है और ऐसे गेम में महारत हासिल कर सकता है जिनका अभी तक आविष्कार नहीं हुआ है.
आर्टिफ़िशियल इंटेलिजेंस
कोई ऐसा प्रोग्राम या model जो मुश्किल कामों को हल कर सके. उदाहरण के लिए, टेक्स्ट का अनुवाद करने वाला प्रोग्राम या मॉडल या ऐसा प्रोग्राम या मॉडल जो रेडियोलॉजिक इमेज की मदद से बीमारियों की पहचान करता हो, दोनों में आर्टिफ़िशियल इंटेलिजेंस हो.
आम तौर पर, मशीन लर्निंग, आर्टिफ़िशियल इंटेलिजेंस का एक सब-फ़ील्ड है. हालांकि, हाल ही के सालों में, कुछ संगठनों ने आर्टिफ़िशियल इंटेलिजेंस और मशीन लर्निंग का इस्तेमाल एक-दूसरे की जगह पर करना शुरू कर दिया है.
ध्यान देना
न्यूरल नेटवर्क में इस्तेमाल किया जाने वाला एक तरीका, जो किसी खास शब्द या शब्द के हिस्से की अहमियत बताता है. ध्यान रखें, यह जानकारी की वह मात्रा कम कर देता है जिसकी ज़रूरत किसी मॉडल को अगले टोकन/शब्द का अनुमान लगाने के लिए होती है. ध्यान देने के सामान्य तरीके में, इनपुट के सेट पर वज़न का इस्तेमाल किया जा सकता है. इसमें हर इनपुट के वेट का हिसाब, न्यूरल नेटवर्क के किसी अन्य हिस्से से लगाया जाता है.
खुद का ध्यान रखने की सुविधा और एक साथ कई लोगों का ध्यान खींचने के मामले में जाएं. ये ट्रांसफ़ॉर्मर बनाने में अहम भूमिका निभाते हैं.
विशेषता
feature के लिए समानार्थी शब्द.
मशीन लर्निंग की निष्पक्षता में, एट्रिब्यूट का मतलब अक्सर लोगों से जुड़े वर्णों से होता है.
एट्रिब्यूट सैंपलिंग
डिसिज़न फ़ॉरेस्ट की ट्रेनिंग के लिए रणनीति, जिसमें हर डिसिज़न ट्री स्थिति को सीखते समय, संभावित सुविधाओं के किसी भी क्रम में लगाए गए सबसेट को ध्यान में रखता है. आम तौर पर, हर नोड के लिए सुविधाओं के एक अलग सबसेट का सैंपल लिया जाता है. इसके उलट, एट्रिब्यूट सैंपलिंग के बिना डिसिज़न ट्री को ट्रेनिंग देते समय, हर नोड के लिए सभी संभावित सुविधाओं पर विचार किया जाता है.
AUC (आरओसी कर्व के नीचे का क्षेत्र)
0.0 और 1.0 के बीच की कोई संख्या, जो बाइनरी क्लासिफ़िकेशन मॉडल की, पॉज़िटिव क्लास को नेगेटिव क्लास से अलग करने की उसकी क्षमता को दिखाती है. AUC, 1.0 के जितना करीब होगा, क्लास को एक-दूसरे से अलग करने की मॉडल की क्षमता उतनी ही बेहतर होगी.
उदाहरण के लिए, नीचे दिए गए इलस्ट्रेशन में क्लासिफ़ायर का मॉडल दिखाया गया है, जो पॉज़िटिव क्लास (हरे अंडाकार) और नेगेटिव क्लास (बैंगनी रेक्टैंगल) को पूरी तरह से अलग करता है. इस शानदार मॉडल का AUC 1.0 है:

इसके उलट, नीचे दिए गए इलस्ट्रेशन में क्लासिफ़ायर मॉडल के नतीजे दिखाए गए हैं, जिससे रैंडम नतीजे जनरेट किए गए हैं. इस मॉडल का AUC 0.5 है:

हां, पिछले मॉडल का AUC 0.5 है, न कि 0.0.
ज़्यादातर मॉडल दो चरम सीमाओं के बीच में होते हैं. उदाहरण के लिए, नीचे दिया गया मॉडल पॉज़िटिव को नेगेटिव से कुछ हद तक अलग करता है और इसलिए 0.5 और 1.0 के बीच का AUC है:

AUC, क्लासिफ़िकेशन थ्रेशोल्ड के लिए सेट की गई किसी भी वैल्यू को अनदेखा कर देता है. इसके बजाय, AUC कैटगरी तय करने के सभी संभावित थ्रेशोल्ड को ध्यान में रखता है.
AUC और ROC कर्व के बीच संबंध के बारे में जानने के लिए आइकॉन पर क्लिक करें.
AUC, आरओसी कर्व के तहत क्षेत्र को दिखाता है. उदाहरण के लिए, पॉज़िटिव को नेगेटिव से पूरी तरह अलग करने वाले मॉडल के लिए ROC कर्व ऐसा दिखता है:

ऊपर दिए गए इलस्ट्रेशन में, स्लेटी रंग के क्षेत्र का एरिया दिखाया गया है. इस असामान्य मामले में, क्षेत्रफल सिर्फ़ स्लेटी रंग के क्षेत्र (1.0) की लंबाई और ग्रे रंग के क्षेत्र की चौड़ाई (1.0) से गुणा करने पर मिलने वाली वैल्यू है. इसलिए, 1.0 और 1.0 के प्रॉडक्ट का AUC ठीक 1.0 होता है, जो कि सबसे ज़्यादा AUC स्कोर है.
इसके उलट, क्लासिफ़ायर के लिए आरओसी कर्व यहां दिया गया है, जो क्लास को अलग-अलग नहीं कर सकता. स्लेटी रंग के इस क्षेत्र का एरिया 0.5 है.

ज़्यादा सामान्य ROC कर्व करीब नीचे दिखाया गया है:

इस कर्व के नीचे के क्षेत्रफल की गणना मैन्युअल तरीके से करना एक मुश्किल काम होगा. इसलिए, आम तौर पर कोई प्रोग्राम ज़्यादातर एयूसी मानों की गणना करता है.
बढ़ी हुई वास्तविकता
एक ऐसी टेक्नोलॉजी जो कंप्यूटर से जनरेट की गई इमेज को असली दुनिया के व्यू पर लागू करती है और एक कंपोज़िट व्यू देती है.
ऑटोएन्कोडर
यह ऐसा सिस्टम है जो इनपुट से सबसे ज़रूरी जानकारी हासिल करना सीखता है. ऑटोएन्कोडर, एन्कोडर और डीकोडर का कॉम्बिनेशन होते हैं. ऑटोएन्कोडर, नीचे दी गई दो चरणों वाली प्रोसेस पर भरोसा करते हैं:
- एन्कोडर, इनपुट को (आम तौर पर) कम-डाइमेंशन वाले (इंटरमीडिएट) फ़ॉर्मैट में मैप करता है.
- डिकोडर, लोअर-डाइमेंशन वाले फ़ॉर्मैट को ओरिजनल हाई-डाइमेंशन वाले इनपुट फ़ॉर्मैट में मैप करके, ओरिजनल इनपुट का नुकसान पहुंचाने वाला वर्शन बनाता है.
एन्कोडर के इंटरमीडिएट फ़ॉर्मैट से ओरिजनल इनपुट को जितना हो सके उतना करीब से बनाने की कोशिश करके, ऑटोएन्कोडर को शुरू से आखिर तक ट्रेनिंग दी जाती है. इंटरमीडिएट फ़ॉर्मैट, ओरिजनल फ़ॉर्मैट से छोटा (लो-डाइमेंशन) होता है. इस वजह से, ऑटोएन्कोडर को यह जानना पड़ता है कि इनपुट में दी गई कौनसी जानकारी ज़रूरी है. इस वजह से, आउटपुट, इनपुट के मुताबिक नहीं होगा.
उदाहरण के लिए:
- अगर इनपुट डेटा एक ग्राफ़िक है, तो जो कॉपी पूरी नहीं होगी, वह मूल ग्राफ़िक की तरह होगी, लेकिन उसमें कुछ हद तक बदलाव किया गया होगा. ऐसा हो सकता है कि इस पूरी तरह से मेल न खाने वाली कॉपी से, ओरिजनल ग्राफ़िक से नॉइज़ हटा दिया जाए या उसमें कुछ पिक्सल आ जाएं.
- अगर इनपुट डेटा टेक्स्ट है, तो ऑटोएन्कोडर ऐसा नया टेक्स्ट जनरेट करेगा जो ओरिजनल टेक्स्ट की नकल करता है, लेकिन उससे मिलता-जुलता नहीं है.
अलग-अलग ऑटोएन्कोडर भी देखें.
ऑटोमेशन पर बायस
जब कोई व्यक्ति अपने-आप फ़ैसला लेने वाले सिस्टम के सुझावों को स्वीकार करता है, तो वह भी ऑटोमेशन के बिना दी गई जानकारी के बारे में. भले ही, अपने-आप फ़ैसला लेने वाले सिस्टम से कोई गड़बड़ी हुई हो.
AutoML
मशीन लर्निंग मॉडल बनाने के लिए, अपने-आप काम करने वाली कोई भी प्रोसेस. AutoML अपने-आप ये काम कर सकता है:
- सबसे सही मॉडल खोजें.
- हाइपर पैरामीटर ट्यून करें.
- डेटा तैयार करना (इसमें सुविधा इंजीनियरिंग करना भी शामिल है).
- इससे बनने वाले मॉडल को डिप्लॉय करें.
AutoML, डेटा साइंटिस्ट के लिए फ़ायदेमंद है, क्योंकि यह उनका समय बचा सकता है. साथ ही, यह मशीन लर्निंग पाइपलाइन को डेवलप करने में लगने वाला समय बचा सकता है और कॉन्टेंट का ज़्यादा सटीक अनुमान लगाने में भी मदद कर सकता है. मशीन लर्निंग के मुश्किल टास्क को ज़्यादा सुलभ बनाकर, यह ऐसे लोगों के लिए भी फ़ायदेमंद है जो विशेषज्ञ नहीं हैं.
ऑटो-रिग्रेसिव मॉडल
एक ऐसा model जो अपने पिछले अनुमानों के आधार पर अनुमान लगाता है. उदाहरण के लिए, ऑटो-रिग्रेसिव लैंग्वेज मॉडल, पहले से अनुमान लगाए गए टोकन के आधार पर, अगले टोकन का अनुमान लगाते हैं. ट्रांसफ़ॉर्मर पर आधारित सभी बड़े लैंग्वेज मॉडल अपने-आप रिग्रेटिव होते हैं.
इसके उलट, GAN पर आधारित इमेज मॉडल आम तौर पर ऑटो-रिग्रेसिव नहीं होते. इसकी वजह यह है कि ये मॉडल एक फ़ॉरवर्ड पास में इमेज जनरेट करते हैं, न कि अलग-अलग चरणों में. हालांकि, इमेज जनरेट करने वाले कुछ मॉडल ऑटो-रिग्रेसिव होते हैं, क्योंकि वे चरणों में इमेज जनरेट करते हैं.
सहायक नुकसान
लॉस फ़ंक्शन—इसका इस्तेमाल न्यूरल नेटवर्क मॉडल के मेन लॉस फ़ंक्शन के साथ किया जाता है. इससे शुरुआत में होने वाले महत्व के दौरान, ट्रेनिंग को तेज़ी से शुरू करने में मदद मिलती है.
सहायक लॉस फ़ंक्शन, पिछली लेयर में ग्रेडिएंट की भूमिका निभाते हैं. इससे ट्रेनिंग के दौरान, लुप्त होने वाले ग्रेडिएंट की समस्या का मुकाबला करके कैंसर में मदद मिलती है.
औसत सटीक
नतीजों के रैंक किए गए क्रम की परफ़ॉर्मेंस की खास जानकारी देने वाली मेट्रिक. हर काम के नतीजे के लिए, सटीक वैल्यू का औसत निकालकर, औसत सटीक वैल्यू को कैलकुलेट किया जाता है. हर नतीजा, रैंक की गई ऐसी सूची में मौजूद होता है जिसमें पिछले नतीजे के मुकाबले, प्रॉडक्ट को बाज़ार से हटाए जाने की संख्या बढ़ती है.
पीआर कर्व के दायरे में आने वाला क्षेत्र भी देखें.
ऐक्सिस से अलाइन की गई स्थिति
डिसिज़न ट्री में, एक स्थिति जिसमें सिर्फ़ एक सुविधा शामिल होती है. उदाहरण के लिए, अगर क्षेत्र एक सुविधा है, तो यह स्थिति ऐक्सिस से अलाइन की गई होगी:
area > 200
तिरछी स्थिति से कंट्रास्ट करें.
B
बैकप्रोपगेशन
ऐसा एल्गोरिदम जो न्यूरल नेटवर्क में ग्रेडिएंट डिसेंट को लागू करता है.
न्यूरल नेटवर्क को ट्रेनिंग देने के लिए, नीचे दिए दो-पास साइकल की कई दोहरावों की ज़रूरत होती है:
- फ़ॉरवर्ड पास के दौरान, सिस्टम अनुमान पाने के लिए उदाहरणों के बैच को प्रोसेस करता है. सिस्टम, हर अनुमान की तुलना, हर लेबल की वैल्यू से करता है. इस उदाहरण के लिए, अनुमान और लेबल की वैल्यू के बीच का अंतर, लॉस है. सिस्टम मौजूदा बैच के कुल नुकसान का हिसाब लगाने के लिए, सभी उदाहरणों के लॉस का डेटा एग्रीगेट करता है.
- बैकवर्ड पास (बैक प्रोपगेशन) के दौरान, सिस्टम सभी छिपी हुई लेयर में सभी न्यूरॉन के वेट को अडजस्ट करके नुकसान को कम करता है.
न्यूरल नेटवर्क में अक्सर कई छिपी हुई लेयर में कई न्यूरॉन होते हैं. उनमें से हर एक न्यूरॉन अलग-अलग तरीकों से कुल नुकसान में योगदान देता है. बैकप्रोपगेशन से तय होता है कि खास न्यूरॉन पर लागू होने वाले वज़न को बढ़ाना है या घटाना है.
लर्निंग रेट एक मल्टीप्लायर है. इससे यह कंट्रोल किया जाता है कि हर बैकवर्ड पास, हर वज़न को कितनी कम या ज़्यादा करता है. सीखने की ज़्यादा दर होने पर, सीखने की कम दर के मुकाबले, हर वज़न ज़्यादा या कम होता है.
कैलक्युलस के हिसाब से, बैकप्रोपगेशन प्रोसेस में चेन नियम को लागू किया जाता है. यह कैलक्युलस से लिया जाता है. इसका मतलब है कि बैकप्रोपगेशन, हर पैरामीटर के हिसाब से गड़बड़ी के पार्शियल डेरिवेटिव का हिसाब लगाता है.
कई साल पहले, मशीन लर्निंग इस्तेमाल करने वाले लोगों को बैकप्रॉपगेशन लागू करने के लिए कोड लिखना पड़ता था. TensorFlow जैसे मॉडर्न एमएल एपीआई, अब आपके लिए बैकप्रोपैगेशन की सुविधा को लागू करते हैं. वाह!
बैगिंग
किसी प्रशिक्षण को प्रशिक्षण देने का तरीका, जहां हर मॉडल का हिस्सा प्रशिक्षण के किसी रैंडम सबसेट के आधार पर ट्रेनिंग लेता है, जैसे कि बदलाव के साथ नमूने के तौर पर. उदाहरण के लिए, किसी भी क्रम में लगाए गए जंगल डिसिज़न ट्री का एक कलेक्शन है, जिसे बैगिंग की ट्रेनिंग दी जाती है.
बैगिंग शब्द बूटस्ट्रैप aggregateing के लिए छोटा है.
शब्दों का झोंका
वाक्य या पैसेज में शब्दों को इस तरह से दिखाया गया है चाहे वह क्रम कुछ भी हो. उदाहरण के लिए, शब्दों का बैग नीचे दिए गए तीन वाक्यांशों को एक जैसा दिखाता है:
- कुत्ता उछलता है
- जंप द डॉग
- कुत्ता उछलता है
हर शब्द को स्पार्स वेक्टर के इंडेक्स से मैप किया जाता है, जहां वेक्टर में शब्दावली के हर शब्द के लिए इंडेक्स होता है. उदाहरण के लिए, कुत्ते के कूदने वाले वाक्यांश को द, कुत्ते, और जंप शब्दों से जुड़े तीन इंडेक्स पर गैर-शून्य वैल्यू वाले फ़ीचर वेक्टर में मैप किया जाता है. शून्य के अलावा, इनमें से कोई भी वैल्यू हो सकती है:
- किसी शब्द की मौजूदगी को दिखाने के लिए 1.
- बैग में कोई शब्द कितनी बार दिखता है. उदाहरण के लिए, अगर वाक्यांश मरून डॉग है, मरून फ़र वाला कुत्ता, तो मरून और कुत्ते, दोनों को 2 और अन्य शब्दों को 1 से दिखाया जाएगा.
- कुछ अन्य वैल्यू, जैसे कि किसी शब्द के बैग में दिखने की संख्या का लॉगारिद्म.
आधारभूत
किसी model का इस्तेमाल, यह तुलना करने के लिए किया जाता है कि कोई दूसरा मॉडल (आम तौर पर, ज़्यादा जटिल मॉडल) कैसा परफ़ॉर्म कर रहा है. उदाहरण के लिए, लॉजिस्टिक रिग्रेशन मॉडल एक डीप मॉडल के लिए एक अच्छी बेसलाइन की तरह काम कर सकता है.
किसी खास समस्या के लिए, बेसलाइन से मॉडल डेवलपर उस न्यूनतम परफ़ॉर्मेंस का आकलन कर सकते हैं जिसे नए मॉडल को हासिल करने के बाद ही किया जाना चाहिए.
बैच
एक ट्रेनिंग में इस्तेमाल किए गए उदाहरणों का सेट दोहराव. बैच का साइज़, बैच में उदाहरणों की संख्या तय करता है.
बैच किसी epoch से किस तरह जुड़ा है, यह जानने के लिए epoch देखें.
बैच अनुमान
बिना लेबल वाले कई उदाहरणों के लिए, अनुमान लगाने की प्रोसेस, जिन्हें छोटे-छोटे सबसेट ("बैच") में बांटा गया है.
बैच अनुमान की सुविधा, ऐक्सेलरेटर चिप की पैरललाइज़ेशन सुविधाओं का फ़ायदा ले सकती है. इसका मतलब है कि एक से ज़्यादा ऐक्सेलरेटर, बिना लेबल वाले उदाहरणों के अलग-अलग बैच के लिए एक साथ अनुमान लगा सकते हैं. इससे हर सेकंड में अनुमान की संख्या बहुत ज़्यादा बढ़ जाती है.
बैच नॉर्मलाइज़ेशन
छिपी हुई लेयर में, ऐक्टिवेशन फ़ंक्शन के इनपुट या आउटपुट को नॉर्मलाइज़ करना. बैच नॉर्मलाइज़ेशन की सुविधा से ये फ़ायदे मिल सकते हैं:
- आउटलायर के वेट को सुरक्षित रखते हुए, न्यूरल नेटवर्क को ज़्यादा स्थिर बनाएं.
- ज़्यादा लर्निंग रेट चालू करें, जिससे स्पीड ट्रेनिंग हो सकती है.
- ओवरफ़िटिंग कम करें.
बैच का आकार
किसी बैच में उदाहरण की संख्या. उदाहरण के लिए, अगर बैच का साइज़ 100 है, तो मॉडल हर दोहराव में 100 उदाहरण प्रोसेस करता है.
बैच साइज़ की लोकप्रिय रणनीतियां इस तरह से हैं:
- स्टोकायस्टिक ग्रेडिएंट डिसेंट (एसजीडी), जिसमें बैच का साइज़ 1 है.
- पूरा बैच, जिसमें बैच का साइज़, पूरे ट्रेनिंग सेट के उदाहरणों की संख्या है. उदाहरण के लिए, अगर ट्रेनिंग सेट में लाखों उदाहरण शामिल हैं, तो बैच का साइज़ दस लाख उदाहरण होगा. आम तौर पर, एक साथ पूरी बैच बनाने की रणनीति, आम तौर पर गलत तरीके से काम करती है.
- मिनी-बैच, जिसमें बैच का साइज़ आम तौर पर 10 से 1,000 के बीच होता है. आम तौर पर, मिनी-बैच सबसे असरदार तरीका है.
बेज़ियन न्यूरल नेटवर्क
यह एक संभावित न्यूरल नेटवर्क है, जो वेट और आउटपुट में अनिश्चितता देता है. स्टैंडर्ड न्यूरल नेटवर्क रिग्रेशन मॉडल, आम तौर पर एक अदिश वैल्यू का अनुमान लगाता है. उदाहरण के लिए, एक स्टैंडर्ड मॉडल 8,53,000 घर की कीमत का अनुमान लगाता है. इसके उलट, बेज़ियन न्यूरल नेटवर्क, वैल्यू के डिस्ट्रिब्यूशन का अनुमान लगाता है. उदाहरण के लिए, बेज़ियन मॉडल 67,200 के स्टैंडर्ड डिविएशन के साथ, घर की कीमत 8,53,000 होने का अनुमान लगाता है.
बेज़ियन न्यूरल नेटवर्क, वेट और अनुमानों की अनिश्चितता का हिसाब लगाने के लिए, बेज़ थ्योरम पर निर्भर करता है. बेज़ियन न्यूरल नेटवर्क तब काम आ सकता है, जब अनिश्चितता का आकलन करना ज़रूरी हो. जैसे, दवाओं से जुड़े मॉडल. बेज़ियन न्यूरल नेटवर्क भी ओवरफ़िटिंग को रोकने में मदद कर सकते हैं.
बेज़ियन ऑप्टिमाइज़ेशन
यह एक प्रॉबेब्लिस्ट रिग्रेशन मॉडल का इस्तेमाल करके, कंप्यूटर की मदद से महंगे मकसद फ़ंक्शन को ऑप्टिमाइज़ करने की तकनीक है. इसके लिए, ऐसे सरोगेट को ऑप्टिमाइज़ किया जाता है जो बेज़ियन लर्निंग तकनीक का इस्तेमाल करके, अनिश्चितता को मापता है. बेज़ियन ऑप्टिमाइज़ेशन अपने-आप में बहुत महंगा होता है. इसलिए, आम तौर पर इसका इस्तेमाल ऐसे टास्क को ऑप्टिमाइज़ करने के लिए किया जाता है जिनमें काफ़ी कम पैरामीटर हों, जैसे कि हाइपर पैरामीटर चुनना.
बेलमैन इक्वेशन
रीइन्फ़ोर्समेंट लर्निंग में, यहां दी गई पहचान, सबसे सही Q-फ़ंक्शन की मदद से पूरी की जाती है:
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
रीइन्फ़ोर्समेंट लर्निंग एल्गोरिदम, इस पहचान को अपडेट करने के इस नियम के ज़रिए Q-लर्निंग बनाने के लिए लागू करते हैं:
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
रीइन्फ़ोर्समेंट लर्निंग के अलावा, बेलमैन इक्वेशन का इस्तेमाल डाइनैमिक प्रोग्रामिंग में भी किया जाता है. बेलमैन समीकरण के लिए Wikipedia की एंट्री देखें.
BERT (बाइडायरेक्शनल एन्कोडर ट्रांसफ़ॉर्मर का रिप्रज़ेंटेशन)
टेक्स्ट प्रज़ेंटेशन के लिए मॉडल आर्किटेक्चर. एक प्रशिक्षित BERT मॉडल, टेक्स्ट की कैटगरी तय करने या अन्य एमएल टास्क के लिए, एक बड़े मॉडल के हिस्से के तौर पर काम कर सकता है.
BERT की विशेषताएं ये हैं:
- ट्रांसफ़ॉर्मर आर्किटेक्चर का इस्तेमाल किया जाता है. इसलिए, यह खुद का ध्यान रखने पर निर्भर करता है.
- यह ट्रांसफ़ॉर्मर के एन्कोडर वाले हिस्से का इस्तेमाल करता है. एन्कोडर का काम कैटगरी तय करने जैसे खास काम को करने के बजाय, अच्छे से टेक्स्ट को दिखाना है.
- दोनों तरफ़ दो रास्ते हों.
- बिना निगरानी वाली ट्रेनिंग के लिए, मास्किंग का इस्तेमाल करता है.
BERT के वैरिएंट में ये शामिल हैं:
BERT की खास जानकारी के लिए, ओपन सोर्सिंग BERT: नैचुरल लैंग्वेज प्रोसेसिंग के लिए प्री-ट्रेनिंग की प्रोसेस देखें.
पक्षपात (नैतिक/निष्पक्षता)
1. कुछ चीज़ों, लोगों या समूहों के बारे में रूढ़िवादी सोच, पूर्वाग्रह या पक्षपात करना. ये पूर्वाग्रह डेटा को इकट्ठा करने और समझने के तरीके, सिस्टम के डिज़ाइन, और उपयोगकर्ताओं के सिस्टम के साथ इंटरैक्ट करने के तरीके पर असर डाल सकते हैं. इस तरह के पूर्वाग्रह में ये शामिल हैं:
- ऑटोमेशन बायस
- कन्फ़र्मेशन बायस
- एक्सपेरिमेंट करने वाले का पूर्वाग्रह
- ग्रुप एट्रिब्यूशन बायस
- इंप्लिसिट पूर्वाग्रह
- इन-ग्रुप बायस
- आउट-ग्रुप एक ही तरह का भेदभाव
2. सैंपलिंग या रिपोर्टिंग की प्रोसेस के दौरान सिस्टम में कोई गड़बड़ी हुई. इस तरह के पूर्वाग्रह में ये शामिल हैं:
इसे मशीन लर्निंग मॉडल में बायस टर्म या अनुमान बायस समझने की ज़रूरत नहीं है.
बायस (गणित) या बायस टर्म
किसी ऑरिजिन से कोई रुकावट या ऑफ़सेट. बायस, मशीन लर्निंग मॉडल में एक पैरामीटर होता है. इसे इनमें से किसी एक के तौर पर दिखाया जाता है:
- b
- w0
उदाहरण के लिए, इस फ़ॉर्मूला में पूर्वाग्रह b है:
एक सामान्य द्वि-आयामी रेखा में, पक्षपात का मतलब "y-इंटरसेप्ट" है. उदाहरण के लिए, इस इलस्ट्रेशन में लाइन का बायस 2 है.

पूर्वाग्रह मौजूद है क्योंकि सभी मॉडल ऑरिजिन (0,0) से शुरू नहीं होते. उदाहरण के लिए, मान लें कि किसी मनोरंजन पार्क में प्रवेश करने के लिए 2 यूरो और किसी ग्राहक के ठहरने के हर घंटे के लिए 0.5 यूरो और खर्च होते हैं. इसलिए, कुल लागत को मैप करने वाले मॉडल का बायस 2 होता है, क्योंकि सबसे कम लागत 2 यूरो होती है.
पूर्वाग्रह को नैतिकता और निष्पक्षता में पक्षपात या पूर्वाग्रह से नहीं समझा जाना चाहिए.
दोतरफ़ा
यह एक ऐसे सिस्टम के बारे में बताने वाला शब्द है जो टेक्स्ट के टारगेट सेक्शन से पहले और उसका बाद, दोनों तरह के टेक्स्ट का आकलन करता है. वहीं, एकतरफ़ा सिस्टम, सिर्फ़ उस टेक्स्ट का आकलन करता है जो टेक्स्ट के टारगेट सेक्शन से पहले से शुरू होता है.
उदाहरण के लिए, मास्क की गई भाषा का ऐसा मॉडल इस्तेमाल करें जिसे इस सवाल में अंडरलाइन किए गए शब्द या शब्दों के लिए संभावना तय करना ज़रूरी हो:
_____ आपके साथ क्या है?
एकतरफ़ा भाषा वाले मॉडल को अपनी संभावनाओं को सिर्फ़ "What", "is", और "the" शब्दों के संदर्भ के आधार पर तय करना होगा. वहीं दूसरी ओर, दो-तरफ़ा भाषा वाले मॉडल को "साथ" और "आप" से संदर्भ मिल सकता है. इससे मॉडल को बेहतर अनुमान लगाने में मदद मिल सकती है.
दो-तरफ़ा लैंग्वेज मॉडल
यह भाषा का ऐसा मॉडल है जो इस बात की संभावना तय करता है कि दिया गया टोकन, दी गई जगह पर मौजूद टेक्स्ट के एक छोटे हिस्से में मौजूद है या नहीं. ऐसा, पहले और पहले से मौजूद टेक्स्ट पर आधारित होता है.
बिगम
कोई N-ग्राम, जिसमें N=2 हो.
बाइनरी क्लासिफ़िकेशन
यह एक तरह का क्लासिफ़िकेशन टास्क है, जो इन दो में से किसी एक क्लास का अनुमान लगाता है:
उदाहरण के लिए, नीचे दिए गए दो मशीन लर्निंग मॉडल में से हर एक बाइनरी क्लासिफ़िकेशन मॉडल करता है:
- वह मॉडल जो तय करता है कि ईमेल मैसेज स्पैम (पॉज़िटिव क्लास) हैं या स्पैम नहीं हैं (नेगेटिव क्लास).
- एक मॉडल जो चिकित्सा के लक्षणों का आकलन करके यह पता लगाता है कि किसी व्यक्ति को कोई ख़ास बीमारी है या नहीं (नेगेटिव क्लास).
एक से ज़्यादा क्लास वाले क्लासिफ़िकेशन से अलग करें.
लॉजिस्टिक रिग्रेशन और क्लासिफ़िकेशन थ्रेशोल्ड भी देखें.
बाइनरी कंडीशन
डिसिज़न ट्री में, एक ऐसी स्थिति जिसमें सिर्फ़ दो संभावित नतीजे होते हैं, आम तौर पर हां या नहीं. उदाहरण के लिए, यह बाइनरी कंडिशन है:
temperature >= 100
नॉन-बाइनरी कंडिशन से कंट्रास्ट करें.
बिनिंग
बकेटिंग का समानार्थी शब्द.
BLEU (बाइलिंगुअल इवैलुएशन अंडरस्टडी)
0.0 और 1.0 के बीच का स्कोर, जो दो इंसानों की भाषाओं (उदाहरण के लिए, अंग्रेज़ी और रशियन) के बीच अनुवाद की क्वालिटी दिखाता है. BLEU स्कोर 1.0 होना चाहिए और इसका मतलब है कि अनुवाद सही है. वहीं, 0.0 का BLEU स्कोर तब काम का होता है, जब इसका बहुत इस्तेमाल होता है.
बूस्टिंग
यह एक ऐसी मशीन लर्निंग तकनीक है जो बहुत सटीक और बहुत सटीक क्लासिफ़ायर यानी "कमज़ोर" क्लासिफ़ायर के सेट को बार-बार मिला-जुलाकर इस्तेमाल करती है. इसे "कमज़ोर" कैटगरी तय करने वाला माना जाता है. यह क्लासिफ़ायर (एक "मज़बूत" कैटगरी तय करने वाला टूल) होता है. इसके लिए, मॉडल को उन उदाहरणों को बेहतर तरीके से मेज़र किया जाता है जिन्हें फ़िलहाल गलत कैटगरी में बांटा जा रहा है.
बाउंडिंग बॉक्स
किसी इमेज में, दिलचस्पी की जगह के आस-पास एक रेक्टैंगल के (x, y) कोऑर्डिनेट हैं, जैसे कि नीचे दी गई इमेज में कुत्ता.

ब्रॉडकास्ट किया जा रहा है
मैट्रिक्स गणित में किसी ऑपरेंड के आकार को उस ऑपरेशन के साथ काम करने वाले डाइमेंशन के हिसाब से बढ़ाना. उदाहरण के लिए, लीनियर बीजगणित के लिए ज़रूरी है कि मैट्रिक्स में जोड़ने की कार्रवाई में दो ऑपरेंड के डाइमेंशन एक जैसे हों. इस वजह से, n लंबाई वाले वेक्टर में साइज़ (m, n) का मैट्रिक्स नहीं जोड़ा जा सकता. ब्रॉडकास्ट करने की सुविधा की मदद से, इस कार्रवाई को चालू किया जा सकता है. इसके लिए, हर कॉलम में एक जैसी वैल्यू को कॉपी करके, n लंबाई के वेक्टर को वर्चुअल तौर पर साइज़ (m, n) के मैट्रिक्स तक बढ़ाया जाता है.
उदाहरण के लिए, नीचे दी गई परिभाषाओं के मुताबिक, लीनियर बीजगणित A+B को अनुमति नहीं देता है, क्योंकि A और B के डाइमेंशन अलग-अलग हैं:
A = [[7, 10, 4],
[13, 5, 9]]
B = [2]
हालांकि, ब्रॉडकास्टिंग B कार्रवाई को चालू करने पर A+B कार्रवाई करता है. इसके लिए, B को वर्चुअल तौर पर इस तरह बड़ा किया जाता है:
[[2, 2, 2],
[2, 2, 2]]
इसलिए, A+B अब एक मान्य कार्रवाई है:
[[7, 10, 4], + [[2, 2, 2], = [[ 9, 12, 6],
[13, 5, 9]] [2, 2, 2]] [15, 7, 11]]
ज़्यादा जानकारी के लिए, NumPy पर ब्रॉडकास्ट करने के बारे में नीचे दी गई जानकारी देखें.
बकेटिंग
किसी एक सुविधा को बकेट या बिन नाम की एक से ज़्यादा बाइनरी सुविधाओं में बदलना. आम तौर पर, यह सुविधा वैल्यू की सीमा के आधार पर तय होती है. कटी हुई सुविधा आम तौर पर, लगातार चलने वाली सुविधा होती है.
उदाहरण के लिए, तापमान को एक लगातार फ़्लोटिंग-पॉइंट सुविधा के रूप में दिखाने के बजाय, आप तापमान की रेंज को अलग-अलग बकेट में काट सकते हैं, जैसे:
- <= 10 डिग्री सेल्सियस "ठंडा" बकेट होगा.
- 11 से 24 डिग्री सेल्सियस के बीच तापमान "तापमान" बकेट रहेगा.
- >= 25 डिग्री सेल्सियस का तापमान "वॉर्म" बकेट होगा.
यह मॉडल, एक ही बकेट में मौजूद हर वैल्यू को एक जैसा मानेगा. उदाहरण के लिए, 13 और 22 वैल्यू, दोनों ही टेंपरेरेट बकेट में हैं. इसलिए, मॉडल दोनों वैल्यू को एक जैसा मानता है.
C
कैलिब्रेशन लेयर
अनुमान के बाद होने वाला अडजस्टमेंट. आम तौर पर, यह अनुमान के आधार पर होने वाले पूर्वाग्रह को ध्यान में रखकर किया जाता है. बदले गए अनुमानों और संभावनाओं का मिलान, मॉनिटर किए गए लेबल के सेट के डिस्ट्रिब्यूशन से होना चाहिए.
कैंडिडेट जनरेशन
सुझावों का शुरुआती सेट, जिसे सुझाव देने वाले सिस्टम ने चुना है. उदाहरण के लिए, एक ऐसा बुकस्टोर करें जिसमें 1,00,000 टाइटल उपलब्ध हों. कैंडिडेट जनरेशन वाले चरण में, किसी उपयोगकर्ता के लिए ज़रूरत के मुताबिक किताबों की एक छोटी सूची बनाई जाती है. जैसे, 500. हालांकि, किसी व्यक्ति को 500 किताबें देखने का सुझाव देना मुश्किल है. बाद में, ज़्यादा महंगा, सुझाव देने वाले सिस्टम के चरण (जैसे कि स्कोरिंग और री-रैंकिंग) उन 500 को घटाकर ज़्यादा काम के और ज़्यादा उपयोगी सेट कर देते हैं.
कैंडिडेट सैंपलिंग
ट्रेनिंग के समय का ऑप्टिमाइज़ेशन, जो सॉफ़्टमैक्स जैसे सभी पॉज़िटिव लेबल की संभावना का हिसाब लगाता है. हालांकि, यह सिर्फ़ नेगेटिव लेबल के किसी रैंडम सैंपल के लिए इस्तेमाल किया जाता है. उदाहरण के लिए, बीगल और कुत्ता लेबल वाले उदाहरण में, कैंडिडेट सैंपलिंग से इन चीज़ों के लिए, संभावित संभावनाओं और नुकसान से जुड़े शब्दों का पता लगाया जाता है:
- बीगल
- कुत्ता
- बाकी नेगेटिव क्लास का रैंडम सबसेट (उदाहरण के लिए, cat, lollipop, fence).
आइडिया यह है कि नेगेटिव क्लास को बहुत कम बार नेगेटिव रिस्पॉन्स से सीखा जा सकता है, जब पॉज़िटिव क्लास को हमेशा सही तरीके से लागू किया जाए. साथ ही, ऐसा होना भी सामान्य बात है.
ट्रेनिंग एल्गोरिदम की तुलना में, कैंडिडेट सैंपलिंग का तरीका ज़्यादा कारगर है. यह सुविधा, सभी नेगेटिव क्लास के लिए अनुमान लगाने वाले एल्गोरिदम की तुलना में ज़्यादा काम आती है. ऐसा खास तौर पर तब होता है, जब नेगेटिव क्लास की संख्या बहुत ज़्यादा हो.
कैटगरी से जुड़ा डेटा
सुविधाएं, जिनमें संभावित वैल्यू का एक खास सेट हो. उदाहरण के लिए, traffic-light-state नाम की ऐसी कैटगरी वाली सुविधा पर ध्यान दें जिसकी सिर्फ़ इन तीन संभावित वैल्यू में से कोई एक वैल्यू हो सकती है:
redyellowgreen
traffic-light-state को कैटगरी से जुड़ी सुविधा के तौर पर दिखाकर, मॉडल यह जान सकता है कि ड्राइवर के व्यवहार पर red, green, और yellow के अलग-अलग असर क्या हैं.
कैटगरी के हिसाब से मिलने वाली सुविधाओं को कभी-कभी अलग-अलग सुविधाएं कहा जाता है.
संख्या के हिसाब से डेटा से अलग होना चाहिए.
कॉज़ल लैंग्वेज मॉडल
एकतरफ़ा लैंग्वेज मॉडल का समानार्थी शब्द.
लैंग्वेज मॉडलिंग में, अलग-अलग दिशाओं के बारे में जानने के लिए, दो-तरफ़ा भाषा का मॉडल देखें.
सेंट्रोइड
k-means या k-median एल्गोरिदम की मदद से तय किए गए क्लस्टर का केंद्र. उदाहरण के लिए, अगर k 3 है, तो k-मीन या k-मीडियन एल्गोरिदम तीन सेंट्रोइड ढूंढता है.
सेंट्रोइड-बेस्ड क्लस्टरिंग
क्लस्टरिंग एल्गोरिदम की कैटगरी, जो डेटा को बिना हैरारकी वाले क्लस्टर में व्यवस्थित करती है. k-means सबसे ज़्यादा इस्तेमाल किया जाने वाला सेंट्रोइड-आधारित क्लस्टरिंग एल्गोरिदम है.
हैरारकल क्लस्टरिंग एल्गोरिदम से उलट.
चेन-ऑफ़-थॉट प्रॉम्प्ट
प्रॉम्प्ट इंजीनियरिंग तकनीक, जो बड़े लैंग्वेज मॉडल (एलएलएम) को बढ़ावा देती है. इसमें, एलएलएम को सिलसिलेवार तरीके से समझाया जाता है. उदाहरण के लिए, दूसरे वाक्य पर खास ध्यान देते हुए इस प्रॉम्प्ट पर विचार करें:
7 सेकंड में 0 से 60 मील प्रति घंटे की रफ़्तार वाली कार में, ड्राइवर को कितने g बल लगा सकते हैं? जवाब में, काम के सभी कैलकुलेशन दिखाएं.
एलएलएम से ये जवाब मिल सकते हैं:
- भौतिकी के फ़ॉर्मूलों का क्रम दिखाएं, वैल्यू को 0, 60, और 7 को सही जगहों पर प्लग-इन करें.
- बताएं कि इसने वे फ़ॉर्मूले क्यों चुने और अलग-अलग वैरिएबल का क्या मतलब है.
चेन-ऑफ़-थॉट प्रॉम्प्ट की मदद से, एलएलएम को हर कैलकुलेशन करने के लिए मजबूर किया जाता है. इससे ज़्यादा सही जवाब मिल सकता है. इसके अलावा, चेन-ऑफ़-थॉट प्रॉम्प्ट की मदद से, उपयोगकर्ता एलएलएम के चरणों की जांच करके यह तय कर सकता है कि वह जवाब सही है या नहीं.
चैट
मशीन लर्निंग सिस्टम (एमएल सिस्टम) की मदद से, लगातार होने वाली बातचीत का कॉन्टेंट. आम तौर पर, यह एक बड़ा लैंग्वेज मॉडल होता है. चैट में हुआ पिछला इंटरैक्शन (आपने क्या टाइप किया और बड़े लैंग्वेज मॉडल ने कैसे जवाब दिया), चैट के बाद के हिस्सों के लिए संदर्भ बन जाता है.
चैटबॉट, बड़े लैंग्वेज मॉडल का ऐप्लिकेशन है.
COVID-19 की जांच के लिए बनी चेकपोस्ट
ऐसा डेटा जो किसी खास ट्रेनिंग के दौरान मॉडल के पैरामीटर की स्थिति को कैप्चर करता है. चेकपॉइंट, वेट मॉडल को एक्सपोर्ट करने या कई सेशन में ट्रेनिंग करने की सुविधा चालू करते हैं. चेकपॉइंट की मदद से, ट्रेनिंग की सुविधा भी मिलती है. इससे पिछली गड़बड़ियों को जारी रखने में मदद मिलती है, जैसे कि नौकरी से पहले विज्ञापन देना.
फ़ाइन ट्यूनिंग होने पर, ट्रेनिंग के लिए नए मॉडल की शुरुआत, पहले से ट्रेन किए गए मॉडल के लिए खास चेकपॉइंट के तौर पर होगी.
क्लास
वह कैटगरी जो लेबल से जुड़ी हो सकती है. उदाहरण के लिए:
- बाइनरी क्लासिफ़िकेशन मॉडल में, जो स्पैम का पता लगाता है, उसमें दो क्लास स्पैम हो सकती हैं और स्पैम नहीं.
- कुत्तों की नस्लों की पहचान करने वाले कई कैटगरी वाले क्लासिफ़िकेशन मॉडल में, पूडल, बीगल, पग, वगैरह की क्लास हो सकती हैं.
क्लासिफ़िकेशन मॉडल, क्लास का अनुमान लगाता है. इसके उलट, रिग्रेशन मॉडल क्लास के बजाय किसी संख्या का अनुमान लगाता है.
क्लासिफ़िकेशन मॉडल
कोई model, जिसका अनुमान model के तौर पर होता है. उदाहरण के लिए, ये सभी क्लासिफ़िकेशन मॉडल नीचे दिए गए हैं:
- इनपुट वाक्य की भाषा का अनुमान लगाने वाला मॉडल (फ़्रेंच? स्पैनिश? इटैलियन?).
- ऐसा मॉडल जो पेड़ों की प्रजातियों का अनुमान लगाता है (मेपल? Oak? बेओबैब?).
- ऐसा मॉडल जो किसी खास मेडिकल स्थिति के लिए, पॉज़िटिव या नेगेटिव क्लास का अनुमान लगाता है.
इसके उलट, रिग्रेशन मॉडल क्लास के बजाय संख्याओं का अनुमान लगाते हैं.
क्लासिफ़िकेशन मॉडल आम तौर पर दो तरह के होते हैं:
श्रेणी में बाँटने की सीमा
बाइनरी क्लासिफ़िकेशन में, 0 और 1 के बीच की कोई संख्या, जो लॉजिस्टिक रिग्रेशन मॉडल के रॉ आउटपुट को पॉज़िटिव क्लास या नेगेटिव क्लास के अनुमान में बदलती है. ध्यान दें कि क्लासिफ़िकेशन थ्रेशोल्ड वह वैल्यू है जिसे कोई व्यक्ति चुनता है. न कि वह वैल्यू जिसे मॉडल ट्रेनिंग से चुना जाता है.
लॉजिस्टिक रिग्रेशन मॉडल, 0 और 1 के बीच का रॉ वैल्यू देता है. इसके बाद:
- अगर यह रॉ वैल्यू, क्लासिफ़िकेशन थ्रेशोल्ड से ज़्यादा है, तो पॉज़िटिव क्लास का अनुमान लगाया जाता है.
- अगर यह रॉ वैल्यू, क्लासिफ़िकेशन थ्रेशोल्ड से कम है, तो नेगेटिव क्लास का अनुमान लगाया जाता है.
उदाहरण के लिए, मान लीजिए कि क्लासिफ़िकेशन थ्रेशोल्ड 0.8 है. अगर रॉ वैल्यू 0.9 है, तो मॉडल पॉज़िटिव क्लास का अनुमान लगाता है. अगर रॉ वैल्यू 0.7 है, तो मॉडल नेगेटिव क्लास का अनुमान लगाता है.
क्लासिफ़िकेशन थ्रेशोल्ड चुनने से, फ़ॉल्स पॉज़िटिव और फ़ॉल्स नेगेटिव की संख्या पर काफ़ी असर पड़ता है.
वर्ग-असंतुलित डेटासेट
कैटगरी से जुड़ी समस्या का ऐसा डेटासेट जिसमें हर क्लास के लेबल की कुल संख्या काफ़ी अलग हो. उदाहरण के लिए, ऐसा बाइनरी क्लासिफ़िकेशन डेटासेट देखें जिसके दो लेबल इस तरह से बंटे हुए हैं:
- 10,00,000 नेगेटिव लेबल
- 10 पॉज़िटिव लेबल
नेगेटिव और पॉज़िटिव लेबल का अनुपात 1,00,000 से 1 है. इसलिए, यह क्लास-असंतुलित डेटासेट है.
इसके उलट, नीचे दिया गया डेटासेट क्लास के हिसाब से असंतुलित नहीं है, क्योंकि पॉज़िटिव लेबल और नेगेटिव लेबल का अनुपात एक के करीब है:
- 517 नेगेटिव लेबल
- 483 पॉज़िटिव लेबल
कई क्लास वाले डेटासेट को क्लास-असंतुलित भी माना जा सकता है. उदाहरण के लिए, नीचे दिया गया मल्टी-क्लास क्लासिफ़िकेशन डेटासेट भी क्लास असंतुलित है, क्योंकि एक लेबल में अन्य दो की तुलना में कहीं ज़्यादा उदाहरण हैं:
- "हरे रंग" क्लास वाले 10,00,000 लेबल
- "बैंगनी" क्लास वाले 200 लेबल
- "नारंगी" क्लास वाले 350 लेबल
एंट्रॉपी, मैजरिटी क्लास, और अल्पसंख्यक वर्ग भी देखें.
क्लिपिंग
इनमें से कोई एक या दोनों काम करके, आउटलायर को मैनेज करने की तकनीक:
- सुविधा की उन वैल्यू को कम करना जो तय की गई ज़्यादा से ज़्यादा सीमा से ज़्यादा हैं.
- सुविधा की ऐसी वैल्यू बढ़ाना जो उस सबसे कम थ्रेशोल्ड से भी कम हो.
उदाहरण के लिए, मान लें कि किसी सुविधा के लिए <0.5% वैल्यू 40–60 की रेंज से बाहर है. इस स्थिति में, ये काम किए जा सकते हैं:
- अगर सभी वैल्यू 60 (ज़्यादा से ज़्यादा थ्रेशोल्ड) से ज़्यादा हैं, तो उन्हें 60 करने के लिए क्लिप करें.
- अगर वैल्यू 40 (कम से कम थ्रेशोल्ड) से कम है, तो उसे 40 करने के लिए क्लिप करें.
आउटलायर की वजह से, मॉडल को नुकसान पहुंच सकता है. कभी-कभी इनकी वजह से, ट्रेनिंग के दौरान वेट बाहर आ सकते हैं. कुछ आउटलायर से सटीक होने जैसी मेट्रिक पर भी बुरा असर पड़ सकता है. नुकसान को सीमित करने के लिए क्लिपिंग एक आम तकनीक है.
ग्रेडिएंट क्लिपिंग, ट्रेनिंग के दौरान तय की गई रेंज में ग्रेडिएंट वैल्यू को लागू करती है.
Cloud TPU
एक खास हार्डवेयर ऐक्सेलरेटर जिसे Google Cloud पर मशीन लर्निंग के वर्कलोड को तेज़ी से बढ़ाने के लिए डिज़ाइन किया गया है.
क्लस्टरिंग
ग्रुप से जुड़े उदाहरण. खास तौर पर, बिना निगरानी के सीखना. सभी उदाहरणों को ग्रुप में शामिल करने के बाद, कोई व्यक्ति हर क्लस्टर का मतलब बता सकता है.
कई क्लस्टरिंग एल्गोरिदम मौजूद हैं. उदाहरण के लिए, k-means एल्गोरिदम क्लस्टर के उदाहरण दिए गए हैं. ये उदाहरण, सेंट्रोइड से उनकी दूरी के आधार पर दिए गए हैं, जैसा कि इस डायग्राम में दिखाया गया है:

इसके बाद, एक व्यक्ति इन क्लस्टर की समीक्षा कर सकता है और उदाहरण के लिए, क्लस्टर 1 को "ड्वॉर्फ़ ट्री" और क्लस्टर 2 को "फ़ुल साइज़ ट्री" के तौर पर लेबल कर सकता है.
दूसरे उदाहरण के तौर पर, किसी केंद्र बिंदु से उदाहरण की दूरी के आधार पर क्लस्टरिंग एल्गोरिदम पर विचार करें. यहां इसका उदाहरण दिया गया है:

को-अडैप्टेशन
जब न्यूरॉन नेटवर्क के व्यवहार पर निर्भर करने के बजाय, खास तरह के न्यूरॉन के आउटपुट पर भरोसा करते हैं और ट्रेनिंग डेटा के पैटर्न का अनुमान लगाते हैं. जब पुष्टि करने वाले डेटा में, को-अडैप्टेशन करने वाले पैटर्न मौजूद नहीं होते हैं, तो वैल्यू के साथ-साथ ज़रूरत के मुताबिक बदलाव होने की वजह से ओवरफ़िटिंग होती है. ड्रॉपआउट रेगुलराइज़ेशन, साथ मिलकर लागू करने की प्रोसेस को कम करता है, क्योंकि ड्रॉपआउट की वजह से यह पक्का होता है कि न्यूरॉन सिर्फ़ चुनिंदा न्यूरॉन पर निर्भर नहीं हो सकते.
मिलकर काम करने के लिए फ़िल्टर करना
कई उपयोगकर्ताओं की रुचियों के आधार पर, किसी एक उपयोगकर्ता की दिलचस्पियों के बारे में अनुमान लगाना. कोलैबोरेटिव फ़िल्टर का इस्तेमाल अक्सर सुझाव देने वाले सिस्टम में किया जाता है.
कॉन्सेप्ट ड्रिफ़्ट
सुविधाओं और लेबल के बीच के संबंध में बदलाव. समय के साथ, कॉन्सेप्ट ड्रिफ़्ट होने पर मॉडल की क्वालिटी खराब हो जाती है.
ट्रेनिंग के दौरान, मॉडल को ट्रेनिंग सेट की सुविधाओं और उनके लेबल के बीच के संबंध के बारे में पता चलता है. अगर ट्रेनिंग सेट के लेबल असल दुनिया के लिए अच्छे प्रॉक्सी हैं, तो मॉडल को असल दुनिया का अनुमान लगाने में मदद करनी चाहिए. हालांकि, कॉन्सेप्ट ड्रिफ़्ट होने की वजह से, समय के साथ मॉडल के अनुमानों में कमी आ जाती है.
उदाहरण के लिए, किसी बाइनरी क्लासिफ़िकेशन मॉडल को आज़माएं, जिससे यह अनुमान लगाया जा सके कि किसी कार का कोई मॉडल "ईंधन की बचत" वाला है या नहीं. इसका मतलब है कि ये सुविधाएं:
- कार का वज़न
- इंजन कंप्रेशन
- ट्रांसमिशन टाइप
जब लेबल इनमें से कोई एक हो:
- ईंधन की बचत
- ईंधन की खपत कम होती है
हालांकि, "ईंधन की बचत करने वाली कार" का सिद्धांत लगातार बदल रहा है. साल 1994 में ईंधन की बचत लेबल वाले कार मॉडल को 2024 में ईंधन की कम खपत नहीं वाला लेबल दिया जाएगा. कॉन्सेप्ट ड्रिफ़्ट से जूझ रहा मॉडल, समय के साथ कम और कम उपयोगी अनुमान लगाने लगता है.
नॉनस्टेशनरिटी की मदद से तुलना करें. साथ ही, इनके बीच अंतर बताएं.
शर्त
डिसिज़न ट्री में, एक्सप्रेशन का आकलन करने वाला कोई भी नोड. उदाहरण के लिए, डिसिज़न ट्री के नीचे दिए गए हिस्से में दो शर्तें होती हैं:

स्थिति को स्प्लिट या टेस्ट भी कहा जाता है.
पत्ती के साथ कंट्रास्ट की स्थिति.
यह भी देखें:
बातचीत
गलत जानकारी का पर्यायवाची.
हो सकता है कि कन्फ़ैब्युलेशन, गलत जानकारी के मुकाबले ज़्यादा सटीक शब्द हो. हालांकि, गलत जानकारी पहले लोकप्रिय हुई.
कॉन्फ़िगरेशन
किसी मॉडल को ट्रेनिंग देने के लिए, इस्तेमाल की जाने वाली शुरुआती प्रॉपर्टी वैल्यू को असाइन करने की प्रोसेस. इसमें ये शामिल हैं:
- मॉडल की कंपोज़िंग लेयर
- डेटा की लोकेशन
- हाइपर पैरामीटर, जैसे:
मशीन लर्निंग प्रोजेक्ट में, कॉन्फ़िगरेशन को एक खास कॉन्फ़िगरेशन फ़ाइल के ज़रिए या नीचे दी गई कॉन्फ़िगरेशन लाइब्रेरी का इस्तेमाल करके किया जा सकता है:
एक पक्ष की पुष्टि करना
किसी जानकारी को इस तरह से खोजने, उसकी व्याख्या करने, उसके पक्ष में होने, और उसे याद करने की आदत, जिससे उसकी पहले से मौजूद मान्यताओं या परिकल्पना की पुष्टि हो सके. मशीन लर्निंग डेवलपर अनजाने में डेटा को इस तरह इकट्ठा या लेबल कर सकते हैं जिससे उनकी मौजूदा मान्यताओं को पूरा करने वाले नतीजों पर असर पड़ता हो. कंफ़र्मेशन बायस, एक तरह का अनुमान है.
एक्सपेरिमेंट करने वाले का पूर्वाग्रह, पुष्टि करने से जुड़ा एक तरह का पूर्वाग्रह होता है. इसमें एक्सपेरिमेंट करने वाला व्यक्ति, पहले से मौजूद किसी अनुमान की पुष्टि होने तक मॉडल को ट्रेनिंग देना जारी रखता है.
भ्रम की स्थिति का मैट्रिक्स
इस NxN टेबल में, क्लासिफ़िकेशन मॉडल के सही और गलत सुझावों की जानकारी होती है. उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल के लिए, नीचे दिए गए भ्रम की स्थिति दिखाने वाले मैट्रिक्स पर विचार करें:
| कैंसर (अनुमानित) | नॉन-ट्यूमर (अनुमानित) | |
|---|---|---|
| टमर (ग्राउंड ट्रूथ) | 18 (टीपी) | 1 (FN) |
| नॉन-ट्यूमर (ग्राउंड ट्रूथ) | 6 (एफ़पी) | 452 (TN) |
पहले वाले भ्रम की मेट्रिक में ये चीज़ें दिखती हैं:
- जिन 19 अनुमानों में ट्यूमोर का तथ्यों की सच्चाई थी, उनमें से मॉडल को सही तरीके से 18 और 1 को गलत कैटगरी में रखा गया था.
- जिन 458 अनुमानों में नॉन-ट्यूमर कहा गया था, उनमें से इस मॉडल को सही तरीके से 452 और गलत तरीके से 6 की कैटगरी दी गई.
अलग-अलग कैटगरी के क्लासिफ़िकेशन वाले सवाल के लिए, भ्रम की स्थिति बताने वाले मैट्रिक्स की मदद से, गलतियों के पैटर्न को पहचाना जा सकता है. उदाहरण के लिए, तीन अलग-अलग कैटगरी के मल्टी-क्लास क्लासिफ़िकेशन मॉडल के लिए, नीचे दिए गए भ्रम मैट्रिक्स पर विचार करें. इसमें आइरिस के तीन अलग-अलग टाइप (वर्जिनिका, वर्सीकलर, और सेटोसा) को कैटगरी में बांटा गया है. जब वर्जिनिका की ज़मीनी सच्चाई थी, तो कन्फ़्यूजन मैट्रिक्स दिखाता है कि सेटोसा की तुलना में इस मॉडल ने गलती से वर्सीकलर का अनुमान लगाने की संभावना ज़्यादा है:
| Setosa (अनुमानित) | वर्सीकलर (अनुमानित) | वर्जिनिका (अनुमानित) | |
|---|---|---|---|
| सेटोसा (ग्राउंड ट्रूथ) | 88 | 12 | 0 |
| वर्सीकलर (ग्राउंड ट्रूथ) | 6 | 141 | 7 |
| वर्जिनिका (ग्राउंड ट्रूथ) | 2 | 27 | 109 |
एक और उदाहरण यह हो सकता है कि भ्रम की स्थिति दिखाने वाले मैट्रिक्स से यह पता चल सकता है कि हाथ से लिखे हुए अंकों की पहचान करने वाला मॉडल, गलती से 4 के बजाय 9 का अनुमान लगा लेता है या गलती से 7 के बजाय 1 का अनुमान लगा लेता है.
कन्फ़्यूजन मैट्रिक्स में सटीक और याद रखें सहित कई तरह की परफ़ॉर्मेंस मेट्रिक का हिसाब लगाने के लिए ज़रूरी जानकारी होती है.
चुनाव क्षेत्र की पार्सिंग
किसी वाक्य को व्याकरण के हिसाब से छोटे-छोटे स्ट्रक्चर में बांटना. एमएल सिस्टम का बाद का हिस्सा, जैसे कि सामान्य भाषा की समझ वाला मॉडल, मूल वाक्य की तुलना में अन्य चीज़ों को ज़्यादा आसानी से पार्स कर सकता है. उदाहरण के लिए, इस वाक्य पर विचार करें:
मेरे दोस्त ने दो बिल्लियों को गोद लिया है.
चुनावी क्षेत्र पार्सर इस वाक्य को इन दो कॉम्पोनेंट में बांट सकता है:
- मेरा दोस्त एक संज्ञा वाक्यांश है.
- optedtwo cats में क्रिया के रूप में लिखा जाता है.
इन उम्मीदवारों को छोटे-छोटे हिस्सों में बांटा जा सकता है. उदाहरण के लिए, क्रिया के वाक्यांश
दो बिल्लियों को गोद लिया
इन्हें इन ग्रुप में बांटा जा सकता है:
- adopt एक क्रिया है.
- two cats, एक और संज्ञा वाक्यांश है.
कॉन्टेक्स्ट के हिसाब से भाषा जोड़ना
एम्बेड करने की सुविधा, जिससे शब्दों और वाक्यांशों को इस तरह से "समझना" शुरू हो जाए कि लोग उन्हें आसानी से समझ सकें. कॉन्टेक्स्ट के हिसाब से भाषा जोड़ने की सुविधा, मुश्किल सिंटैक्स, सिमेंटिक्स, और संदर्भ को समझ सकती है.
उदाहरण के लिए, अंग्रेज़ी शब्द cow को एम्बेड करने के बारे में सोचें. word2vec जैसे पुराने एम्बेड करने से, अंग्रेज़ी शब्दों को इस तरह दिखाया जा सकता है कि एम्बेड करने की जगह गाय से बुल या भेड़ (महिला भेड़) से राम (पुरुष भेड़) या महिला से पुरुष की दूरी, एक जैसी है. कॉन्टेक्स्ट के हिसाब से भाषा में एम्बेड करने की सुविधा, इससे एक कदम आगे बढ़ सकती है. ऐसा करने के लिए, अंग्रेज़ी बोलने वाले लोगों को कभी-कभी गाय या बैल का मतलब समझने के लिए गाय का इस्तेमाल करना होता है.
कॉन्टेक्स्ट विंडो
किसी दिए गए प्रॉम्प्ट में, कोई मॉडल कितने टोकन प्रोसेस कर सकता है. कॉन्टेक्स्ट विंडो जितनी बड़ी होगी, मॉडल उतनी ज़्यादा जानकारी का इस्तेमाल करके, प्रॉम्प्ट के लिए आसान और एक जैसा जवाब दे पाएगा.
लगातार चलने वाली सुविधा
फ़्लोटिंग-पॉइंट सुविधा, जिसमें तापमान या वज़न जैसी संभावित वैल्यू की अनगिनत रेंज मौजूद है.
अलग-अलग सुविधा से कंट्रास्ट करें.
आसानी से इकट्ठा किया जाने वाला सैंपल
ऐसे डेटासेट का इस्तेमाल करना जिसे छोटे-छोटे प्रयोग चलाने के लिए वैज्ञानिक तरीके से इकट्ठा न किया गया हो. बाद में, यह ज़रूरी है कि वैज्ञानिक रूप से इकट्ठा किए गए डेटासेट का इस्तेमाल किया जाए.
कन्वर्जेंस
वह स्थिति, जब लॉस की वैल्यू में हर दोहराव के साथ बहुत कम या बिलकुल भी बदलाव नहीं होता है. उदाहरण के लिए, नीचे दिया गया लॉस कर्व करीब 700 बार दोहराया गया है:

कोई मॉडल तब कहता है, जब अतिरिक्त ट्रेनिंग से मॉडल बेहतर नहीं होता.
डीप लर्निंग में, नुकसान की वैल्यू कभी-कभी स्थिर या करीब-करीब तब तक बनी रहती हैं, जब तक कि आखिरी बार घटते क्रम में कई बार ऐसा होता है. अगर लंबे समय तक लगातार होने वाली वैल्यू में कमी होती है, तो कुछ समय के लिए आपको गलत जानकारी मिल सकती है.
शुरुआती स्टॉप भी देखें.
कॉनवैक्स फ़ंक्शन
यह ऐसा फ़ंक्शन होता है जिसमें फ़ंक्शन के ग्राफ़ के ऊपर मौजूद क्षेत्र को कन्वर्ज़न सेट कहा जाता है. प्रोटोटाइपिकल कन्वेक्स फ़ंक्शन का आकार U अक्षर की तरह होता है. उदाहरण के लिए, सभी कॉनवैक्स फ़ंक्शन नीचे दिए गए हैं:

इसके उलट, नीचे दिया गया फ़ंक्शन उत्तल नहीं है. ध्यान दें कि ग्राफ़ के ऊपर दिया गया क्षेत्र, उत्तल सेट नहीं है:

किसी स्ट्रिकली कन्वेक्स फ़ंक्शन में, सिर्फ़ एक स्थानीय कम से कम पॉइंट होता है. यह ग्लोबल सबसे कम पॉइंट भी होता है. क्लासिक U के आकार वाले फ़ंक्शन, कठिन रूप से उत्तल फ़ंक्शन होते हैं. हालांकि, कुछ उत्तल फ़ंक्शन (उदाहरण के लिए, सीधी रेखाएं) U के आकार के नहीं होते.
कन्वर्ज़न ऑप्टिमाइज़ेशन
किसी कन्वर्ज़न फ़ंक्शन की सबसे कम वैल्यू का पता लगाने के लिए, ग्रेडिएंट डिसेंट जैसी गणित की तकनीकों का इस्तेमाल करने की प्रक्रिया. मशीन लर्निंग में काफ़ी रिसर्च की गई है. इसमें कई तरह की समस्याओं को उत्तल ऑप्टिमाइज़ेशन की समस्याओं के तौर पर पेश करने और उन समस्याओं को बेहतर तरीके से हल करने पर ध्यान दिया गया है.
पूरी जानकारी के लिए, बॉयड और वंडेनबर्ग, कॉन्वैक्स ऑप्टिमाइज़ेशन देखें.
कॉनवैक्स सेट
यूक्लिडीन स्पेस का एक सबसेट, जैसे कि सबसेट में किसी भी दो पॉइंट के बीच बनाई गई लाइन, सबसेट में ही पूरी तरह से बनी रहती है. उदाहरण के लिए, नीचे दिए गए दो आकार कॉनवैक्स सेट हैं:

इसके उलट, नीचे दिए गए दो आकार उत्तल सेट नहीं होते हैं:

कन्वर्ज़न
गणित में, आम तौर पर दो फ़ंक्शन का मिक्स होता है. मशीन लर्निंग में, कॉन्वोल्यूशन कॉन्वोलूशनल फ़िल्टर और इनपुट मैट्रिक्स को मिलाता है, ताकि वेट को ट्रेनिंग दी जा सके.
मशीन लर्निंग में "कन्वोलूशन" शब्द का इस्तेमाल, अक्सर कन्वोलूशनल ऑपरेशन या कॉन्वोल्यूशन लेयर के बारे में बताने के लिए किया जाता है.
कॉन्वोलूशन के बिना, मशीन लर्निंग एल्गोरिदम को किसी बड़े टेंसर में हर सेल के लिए अलग-अलग वज़न जानना होगा. उदाहरण के लिए, 2K x 2K इमेज पर मशीन लर्निंग एल्गोरिदम की ट्रेनिंग को 40 लाख अलग-अलग वेट ढूंढने के लिए मजबूर किया जाएगा. कन्वर्ज़न की वजह से, मशीन लर्निंग एल्गोरिदम को कॉन्वोल्यूशन फ़िल्टर की हर सेल की वैल्यू का पता लगाना पड़ता है. इससे मॉडल को ट्रेनिंग देने के लिए, ज़रूरी मेमोरी बहुत कम हो जाती है. जब कॉन्वलूशनल फ़िल्टर को लागू किया जाता है, तो उसे सभी सेल में इस तरह कॉपी किया जाता है कि हर सेल को फ़िल्टर से गुणा किया जाता है.
कॉन्वोल्यूशन फ़िल्टर
कॉन्वोलेशन ऑपरेशन में शामिल दो अभिनेताओं में से एक. (दूसरा कलाकार इनपुट मैट्रिक्स का एक हिस्सा है.) कॉन्वोलूशनल फ़िल्टर एक ऐसा मैट्रिक्स होता है जिसकी रैंक इनपुट मैट्रिक्स के बराबर होती है, लेकिन उसका आकार छोटा होता है. उदाहरण के लिए, 28x28 इनपुट मैट्रिक्स के लिए, फ़िल्टर 28x28 से छोटा कोई भी 2D मैट्रिक्स हो सकता है.
फ़ोटोग्राफ़िक हेर-फेर में, कॉन्वोलूशनल फ़िल्टर में सभी सेल आम तौर पर एक और शून्य के स्थिर पैटर्न पर सेट होती हैं. मशीन लर्निंग में, कन्वोलूशनल फ़िल्टर को आम तौर पर किसी रैंडम नंबर के साथ लागू किया जाता है और फिर नेटवर्क, सही वैल्यू को ट्रेन करता है.
कॉन्वोलूशन लेयर
डीप न्यूरल नेटवर्क की एक लेयर, जिसमें कॉन्वोलूशनल फ़िल्टर इनपुट मैट्रिक्स से पास होता है. उदाहरण के लिए, नीचे दिए गए 3x3 कॉन्वोल्यूशन फ़िल्टर का इस्तेमाल करें:
![इन वैल्यू वाला 3x3 मैट्रिक्स: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=1&hl=hi)
नीचे दिया गया ऐनिमेशन, 5x5 इनपुट मैट्रिक्स से जुड़ी नौ कंवोलूशनल लेयर को दिखाता है. ध्यान दें कि हर कंवोलूशनल ऑपरेशन, इनपुट मैट्रिक्स के एक अलग 3x3 स्लाइस पर काम करता है. नतीजे के तौर पर मिलने वाले 3x3 मैट्रिक्स (दाईं ओर) में 9 कंवलेशन ऑपरेशन के नतीजे होते हैं:
![इस ऐनिमेशन में दो मैट्रिक्स दिखाए गए हैं. पहला मैट्रिक्स 5x5 मैट्रिक्स है: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195.10,9]
दूसरा मैट्रिक्स 3x3 मैट्रिक्स है:
[[181,303,618], [1,15,338,605], [1,69,351,560].
दूसरे मैट्रिक्स का हिसाब लगाने के लिए, 5x5 मैट्रिक्स के 3x3 के अलग-अलग सबसेट पर
कॉन्वोल्यूशन फ़िल्टर [[0, 1, 0], [1, 0, 1], [0, 1, 0]] का इस्तेमाल किया जाता है.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=1&hl=hi)
कॉन्वोलूशनल न्यूरल नेटवर्क
ऐसा न्यूरल नेटवर्क जिसमें कम से कम एक लेयर, कॉन्वोलूशन लेयर होती है. एक सामान्य कॉन्वलूशनल न्यूरल नेटवर्क में नीचे दी गई कुछ लेयर होती हैं:
कॉन्वोलूशनल न्यूरल नेटवर्क को इमेज पहचानने जैसी कुछ खास तरह की समस्याओं में बहुत सफलता मिली है.
कॉन्वलूशनल ऑपरेशन
नीचे दिया गया दो चरणों वाला गणितीय ऑपरेशन:
- कॉन्वोल्यूशन फ़िल्टर और इनपुट मैट्रिक्स के एक स्लाइस का एलिमेंट के हिसाब से गुणा. (इनपुट मैट्रिक्स के स्लाइस की रैंक और साइज़, कॉन्वलूशनल फ़िल्टर के बराबर है.)
- नतीजे के तौर पर मिले प्रॉडक्ट मैट्रिक्स में सभी वैल्यू का योग.
उदाहरण के लिए, यहां दिए गए 5x5 इनपुट मैट्रिक्स पर गौर करें:
![5x5 मैट्रिक्स: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,7,19.1]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=1&hl=hi)
अब 2x2 कॉन्वोल्यूशन फ़िल्टर का इस्तेमाल करें:
![2x2 मैट्रिक्स: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=1&hl=hi)
हर कॉन्वलूशनल ऑपरेशन में इनपुट मैट्रिक्स का एक 2x2 स्लाइस होता है. उदाहरण के लिए, मान लीजिए कि हम इनपुट मैट्रिक्स के सबसे ऊपर बाईं ओर मौजूद 2x2 स्लाइस का इस्तेमाल करते हैं. इसलिए, इस स्लाइस पर कॉन्वोल्यूशन ऑपरेशन इस तरह से दिखेगा:
![इनपुट मैट्रिक्स के सबसे ऊपर बाईं ओर 2x2 सेक्शन पर, कॉन्वोलूशनल फ़िल्टर [[1, 0], [0, 1]] को लागू किया जा रहा है, जो कि [[1,28,97], [35,22]] है.
कॉन्वोलूशनल फ़िल्टर, 128 और 22 को वैसे ही छोड़ देता है, लेकिन
97 और 35 को शून्य कर देता है. इस वजह से, कॉन्वोल्यूशन ऑपरेशन की वैल्यू
150 (128+22) मिलती है.](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=1&hl=hi)
कॉन्वोल्यूशन लेयर में कॉन्वोल्यूशनल ऑपरेशन की एक सीरीज़ होती है. हर ऑपरेशन, इनपुट मैट्रिक्स के अलग-अलग स्लाइस पर काम करता है.
लागत
लॉस का समानार्थी शब्द.
को-ट्रेनिंग
सेमी-सुपरवाइज़्ड लर्निंग का तरीका, खास तौर पर तब फ़ायदेमंद होता है, जब यहां दी गई सभी शर्तें पूरी होती हों:
- डेटासेट में, लेबल नहीं किए गए उदाहरणों और लेबल किए गए उदाहरणों की संख्या का अनुपात ज़्यादा है.
- यह एक कैटगरी से जुड़ी समस्या है (बाइनरी या मल्टी-क्लास).
- डेटासेट में, अनुमानित सुविधाओं के दो अलग-अलग सेट होते हैं. ये सुविधाएं, एक-दूसरे से अलग होती हैं और सहायक नहीं होती हैं.
को-ट्रेनिंग, अलग-अलग तरह के सिग्नल को बेहतर बनाती है. उदाहरण के लिए, क्लासिफ़िकेशन मॉडल इस्तेमाल करें. यह मॉडल, इस्तेमाल की गई अलग-अलग कारों को अच्छी या खराब कैटगरी में बांटता है. अनुमानित सुविधाओं का एक सेट, सभी चीज़ों पर फ़ोकस कर सकता है. जैसे, साल, कार का मॉडल, और साल
को-ट्रेनिंग के बारे में खास जानकारी देने वाला पेपर, को-ट्रेनिंग के साथ लेबल किए गए और बिना लेबल वाले डेटा को जोड़ना है. यह जानकारी ब्लूम और मिचेल ने दी है.
काउंटरफ़ैक्चुअल फ़ेयरनेस
यह फ़ेयरनेस मेट्रिक है. इससे यह पता लगाया जाता है कि क्लासिफ़ायर, पहले व्यक्ति से मेल खाने वाले दूसरे व्यक्ति के मामले में एक जैसा नतीजा दिखाता है या नहीं. इसमें एक या एक से ज़्यादा संवेदनशील विशेषताओं को शामिल नहीं किया जाता. काउंटरफ़ैक्चुअल फ़ेयरनेस के लिए कैटगरी तय करने वाले टूल का आकलन करना, किसी मॉडल में पक्षपात के संभावित सोर्स का पता लगाने का एक तरीका है.
काउंटरफ़ैक्चुअल फ़ेयरनेस के बारे में ज़्यादा जानकारी पाने के लिए, "जब दुनिया आपस में टकराती है: अलग-अलग काउंटरफ़ैक्चुअल आकलनों को निष्पक्षता से शामिल करना" देखें.
कवरेज बायस
चुनाव के मापदंड देखें.
क्रैश ब्लॉसम
ऐसा वाक्य या वाक्यांश जिसका मतलब साफ़ तौर पर न हो. क्रैश ब्लॉसम प्राकृतिक भाषा समझने में एक बड़ी समस्या पेश करते हैं. उदाहरण के लिए, हेडलाइन रेड टेप होल्ड्स अप स्काइस्क्रेपर एक क्रैश ब्लॉसम है, क्योंकि एक एनएलयू मॉडल हेडलाइन की व्याख्या या मतलब के तौर पर कर सकता है.
आलोचक
Deep Q-Network का समानार्थी शब्द.
क्रॉस-एंट्रॉपी
लॉग लॉस को कई कैटगरी में बांटी जाने वाली समस्याओं के बारे में सामान्य जानकारी. क्रॉस-एंट्रॉपी दो प्रॉबबिलिटी डिस्ट्रिब्यूशन के बीच के अंतर को गिनता है. परेशानी भी देखें.
क्रॉस-वैलिडेशन
यह अनुमान लगाने का एक तरीका है कि कोई model, model से रोके गए एक या उससे ज़्यादा डेटा के सबसेट के साथ मॉडल की जांच करके, नए डेटा के लिए कितना सामान्य होगा.
क्यूमुलेटिव डिस्ट्रीब्यूशन फ़ंक्शन (सीडीएफ़)
यह फ़ंक्शन, टारगेट वैल्यू से कम या उसके बराबर सैंपल की फ़्रीक्वेंसी तय करता है. उदाहरण के लिए, कंटिन्यूअस वैल्यू के सामान्य डिस्ट्रिब्यूशन पर विचार करें. CDF आपको बताता है कि करीब 50% सैंपल मीन से कम या उसके बराबर होने चाहिए. साथ ही, करीब 84% सैंपल मीन के ऊपर एक स्टैंडर्ड डीविएशन से कम या उसके बराबर होने चाहिए.
D
डेटा ऐनलिसिस
सैंपल, मेज़रमेंट, और विज़ुअलाइज़ेशन पर विचार करके डेटा को समझना. डेटा का विश्लेषण खास तौर पर तब फ़ायदेमंद हो सकता है, जब डेटासेट पहली बार मिल जाए, यानी पहले model को बनाया जाए. सिस्टम के प्रयोगों और डीबग करने की समस्याओं को समझना भी बहुत ज़रूरी है.
डेटा बढ़ाना
ज़्यादा उदाहरण बनाने के लिए, मौजूदा उदाहरणों को बदलकर, ट्रेनिंग के उदाहरणों की रेंज और उनकी संख्या को गलत तरीके से बढ़ाया जा सकता है. उदाहरण के लिए, मान लें कि इमेज आपकी सुविधाओं में से एक हैं, लेकिन आपके डेटासेट में इमेज के उतने उदाहरण नहीं हैं जितने इस मॉडल को दिखाने के लिए ज़रूरी हैं. आम तौर पर, आपको अपने डेटासेट में लेबल की गई इमेज जोड़नी होंगी. इससे आपके मॉडल को ट्रेनिंग देने में मदद मिलेगी. अगर ऐसा मुमकिन नहीं है, तो डेटा को बेहतर बनाने की सुविधा, ओरिजनल फ़ोटो के कई वैरिएंट बनाने के लिए, हर इमेज को घुमा सकती है, स्ट्रैच कर सकती है, और दिखा सकती है. इससे बेहतरीन ट्रेनिंग पाने के लिए, लेबल किया गया ज़रूरी डेटा मिल सकता है.
DataFrame
मेमोरी में डेटासेट दिखाने के लिए, एक लोकप्रिय पांडा का डेटा टाइप.
DataFrame, टेबल या स्प्रेडशीट से मिलता-जुलता होता है. DataFrame के हर कॉलम का एक नाम (हेडर) होता है और हर पंक्ति की पहचान एक यूनीक नंबर से की जाती है.
DataFrame में मौजूद हर कॉलम को 2D अरे की तरह बनाया जाता है. हालांकि, हर कॉलम को उसका अपना डेटा टाइप असाइन किया जा सकता है.
pandas.DataFrame का रेफ़रंस पेज भी देखें.
डेटा पैरलिज़्म
ट्रेनिंग या अनुमान को स्केल करने का एक तरीका, जो पूरे मॉडल को कई डिवाइसों पर कॉपी करता है और फिर हर डिवाइस में इनपुट डेटा का सबसेट पास करता है. डेटा के साथ काम करने की सुविधा की मदद से, बहुत बड़े बैच साइज़ पर ट्रेनिंग और अनुमान लगाए जा सकते हैं. हालांकि, डेटा के साथ काम करने के लिए यह ज़रूरी है कि मॉडल इतना छोटा हो कि वह सभी डिवाइसों पर फ़िट हो सके.
आम तौर पर, डेटा एक जैसा अनुभव देने से ट्रेनिंग और अनुमान को तेज़ी से बढ़ाया जा सकता है.
मॉडल समानता भी देखें.
डेटा सेट या डेटासेट
रॉ डेटा का कलेक्शन, जिसे आम तौर पर (लेकिन खास तौर पर नहीं) इनमें से किसी एक फ़ॉर्मैट में व्यवस्थित किया जाता है:
- स्प्रेडशीट
- CSV फ़ॉर्मैट वाली फ़ाइल (कॉमा लगाकर अलग की गई वैल्यू)
Dataset API (tf.data)
डेटा को पढ़ने और उसे मशीन लर्निंग एल्गोरिदम की ज़रूरत के हिसाब से बनाने के लिए, एक हाई-लेवल TensorFlow एपीआई.
tf.data.Dataset ऑब्जेक्ट, एलिमेंट का एक क्रम दिखाता है, जिसमें हर एलिमेंट में एक या एक से ज़्यादा टेंसर होते हैं. tf.data.Iterator ऑब्जेक्ट, Dataset के एलिमेंट का ऐक्सेस देता है.
Dataset API के बारे में जानकारी के लिए, TensorFlow प्रोग्रामर की गाइड में, tf.data: TensorFlow इनपुट पाइपलाइन बनाएं.
फ़ैसले की सीमा
बाइनरी क्लास या मल्टी-क्लास क्लासिफ़िकेशन में, मॉडल की मदद से सीखी गई क्लास के बीच सेपरेटर. उदाहरण के लिए, नीचे दी गई इमेज में बाइनरी क्लासिफ़िकेशन की समस्या को दिखाया गया है. डिसिज़न लिमिट नारंगी क्लास और नीली क्लास के बीच की सीमा है:

डिसिज़न फ़ॉरेस्ट
कई डिसिज़न ट्री से बनाया गया मॉडल. डिसिज़न फ़ॉरेस्ट अपने डिसिज़न ट्री के अनुमानों को एग्रीगेट करके अनुमान लगाता है. डिसिज़न फॉरेस्ट के लोकप्रिय प्रकार में रैंडम फ़ॉरेस्ट और ग्रेडिएंट बूस्टेड ट्री शामिल हैं.
फ़ैसले के लिए थ्रेशोल्ड
क्लासिफ़िकेशन थ्रेशोल्ड के लिए समानार्थी शब्द.
डिसिज़न ट्री
निगरानी में रखा गया लर्निंग मॉडल, जिसमें conditions और conditions के सेट को हैरारकी के हिसाब से व्यवस्थित किया गया है. उदाहरण के लिए, यह डिसिज़न ट्री है:

डिकोडर
आम तौर पर, ऐसा कोई भी एमएल सिस्टम जो प्रोसेस किए गए, सघन या अंदरूनी प्रतिनिधित्व को ज़्यादा रॉ, स्पार्स या एक्सटर्नल प्रज़ेंटेशन में बदल देता है.
डिकोडर अक्सर किसी बड़े मॉडल का हिस्सा होते हैं. इन्हें अक्सर किसी एन्कोडर के साथ जोड़ा जाता है.
क्रम से आने वाले टास्क में, डिकोडर उस अंदरूनी स्थिति से शुरू होता है जिसे एन्कोडर की मदद से जनरेट किया जाता है, ताकि अगले क्रम का अनुमान लगाया जा सके.
ट्रांसफ़ॉर्मर आर्किटेक्चर में डिकोडर की परिभाषा जानने के लिए, ट्रांसफ़ॉर्मर देखें.
डीप मॉडल
ऐसा न्यूरल नेटवर्क जिसमें एक से ज़्यादा छिपी हुई लेयर हों.
डीप मॉडल को डीप न्यूरल नेटवर्क भी कहा जाता है.
वाइड मॉडल से कंट्रास्ट अलग हो.
डीप न्यूरल नेटवर्क
डीप मॉडल के लिए समानार्थी शब्द.
डीप क्यू-नेटवर्क (डीक्यूएन)
Q-लर्निंग में, एक डीप न्यूरल नेटवर्क है जो Q-फ़ंक्शन का अनुमान लगाता है.
क्रिटिक, Deep Q-Network का एक समानार्थी शब्द है.
डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) समानता
यह एक फ़ेयरनेस मेट्रिक होती है. इसका मतलब है कि किसी मॉडल की कैटगरी के नतीजे, दिए गए संवेदनशील एट्रिब्यूट पर निर्भर नहीं करते हैं.
उदाहरण के लिए, अगर ग्लबडब्ड्रिब यूनिवर्सिटी में लिलिपुटियन और ब्रोबडिंगनैजियन, दोनों लागू होते हैं, तो डेमोग्राफ़िक समानता तभी मिलेगी, जब लिलीपूत के स्वीकार किए जाने वाले लोगों का प्रतिशत ब्रोबडिंगनाजियन के स्वीकार किए गए प्रतिशत के बराबर हो. भले ही, कोई एक ग्रुप दूसरे ग्रुप की तुलना में ज़्यादा बेहतर हो.
एक जैसी संभावना और अवसर की समानता से अलग. इस वजह से, संवेदनशील विशेषताओं के आधार पर कैटगरी तय करने के नतीजे एग्रीगेट किए जा सकते हैं. हालांकि, कुछ खास बुनियादी तथ्यों लेबल के लिए, संवेदनशील विशेषताओं के आधार पर कैटगरी तय करने के नतीजों की अनुमति नहीं दी जाती. एक विज़ुअलाइज़ेशन के लिए, डेमोग्राफ़िक समानता को ऑप्टिमाइज़ करने पर अहम फ़र्क़ के बारे में जानकारी देने के लिए, "स्मार्ट मशीन लर्निंग की मदद से भेदभाव करना" देखें.
ग़ैर-ज़रूरी आवाज़ें हटाना
सेल्फ़-सुपरवाइज़्ड लर्निंग का एक सामान्य तरीका, जिसमें:
ग़ैर-ज़रूरी आवाज़ें कम करने की सुविधा, बिना लेबल वाले उदाहरणों से सीखने में मदद करती है. ओरिजनल डेटासेट को टारगेट या लेबल और इनपुट के तौर पर शोर वाले डेटा के तौर पर इस्तेमाल किया जाता है.
मास्क किए गए लैंग्वेज मॉडल में, ग़ैर-ज़रूरी आवाज़ें कम करने की सुविधा का इस्तेमाल इस तरह किया जाता है:
- कुछ टोकन को मास्क करके, बिना लेबल वाले वाक्य में शोर को आर्टिफ़िशियल ढंग से जोड़ दिया जाता है.
- मॉडल, ओरिजनल टोकन का अनुमान लगाने की कोशिश करता है.
सघनता
ऐसी सुविधा जिसमें ज़्यादातर या सभी वैल्यू शून्य नहीं हैं. आम तौर पर, यह फ़्लोटिंग-पॉइंट वैल्यू का Tensor होता है. उदाहरण के लिए, नीचे दिया गया 10-एलिमेंट टेन्सर घना है, क्योंकि उसके नौ वैल्यू शून्य हैं:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
स्पार्स सुविधा से कंट्रास्ट अलग होना चाहिए.
सघन परत
पूरी तरह से कनेक्ट की गई लेयर का समानार्थी शब्द.
गहराई
न्यूरल नेटवर्क में इनका योग:
- छिपी हुई लेयर की संख्या
- आउटपुट लेयर की संख्या, जो आम तौर पर 1 होती है
- किसी भी एम्बेडिंग लेयर की संख्या
उदाहरण के लिए, पांच छिपी हुई लेयर और एक आउटपुट लेयर वाले न्यूरल नेटवर्क की डेप्थ 6 है.
ध्यान दें कि इनपुट लेयर, डेप्थ पर असर नहीं डालता.
डेप्थवाइस सेपरेबल कॉन्वलूशनल न्यूरल नेटवर्क (sepCNN)
कन्वोलूशनल न्यूरल नेटवर्क आर्किटेक्चर, इनसेप्शन पर आधारित होता है, लेकिन जहां इंसेप्शन मॉड्यूल को गहराई से अलग किए जा सकने वाले कन्वर्ज़न से बदल दिया जाता है. इसे एक्ससेप्शन भी कहा जाता है.
डेप्थ के हिसाब से अलग किया जा सकने वाला कन्वर्ज़न (इसे शॉर्ट फ़ॉर्म भी कहा जाता है) भी, स्टैंडर्ड 3D कन्वर्ज़न को दो अलग-अलग कॉन्वलूशन ऑपरेशन में बांटता है. पहला, डेप्थ के हिसाब से ऐसा कन्वर्ज़न होता है जो ज़्यादा बेहतर तरीके से काम करता है: पहला, डेप्थ के हिसाब से डेप्थ के साथ (n y n y × 1) और फिर दूसरे पॉइंट की लंबाई 1 और 1 पॉइंट की लंबाई के साथ.
ज़्यादा जानने के लिए, Xception: डीप लर्निंग विद डेप्थवाइज़ सेपरेबल कन्वर्ज़न देखें.
डिराइव्ड लेबल
प्रॉक्सी लेबल के लिए समानार्थी शब्द.
डिवाइस
इन दो संभावित परिभाषाओं के साथ कोई ओवरलोडेड टर्म:
- हार्डवेयर की एक ऐसी कैटगरी जो TensorFlow सेशन चला सकती है. इसमें सीपीयू, जीपीयू, और TPU शामिल हैं.
- एमएल मॉडल को ऐक्सेलरेटर चिप (जीपीयू या टीपीयू) पर ट्रेनिंग देते समय, यह सिस्टम का वह हिस्सा होता है जो टेंसर और एम्बेडिंग में बदलाव करता है. यह डिवाइस, ऐक्सेलरेटर चिप पर काम करता है. वहीं दूसरी ओर, होस्ट आम तौर पर सीपीयू पर चलता है.
डिफ़रेंशियल प्राइवसी
मशीन लर्निंग में, किसी मॉडल के ट्रेनिंग सेट में शामिल किसी भी संवेदनशील डेटा (जैसे कि किसी व्यक्ति की निजी जानकारी) को सार्वजनिक होने से बचाने के लिए, पहचान छिपाने का तरीका अपनाया जाता है. इस तरीके से यह पक्का होता है कि model किसी खास व्यक्ति के बारे में ज़्यादा नहीं सीखता या याद नहीं रखता. ऐसा करने के लिए, मॉडल ट्रेनिंग के दौरान अलग-अलग डेटा पॉइंट को धुंधला करने के लिए, सैंपलिंग और नॉइज़ जोड़कर किया जाता है. इससे, संवेदनशील ट्रेनिंग डेटा के सार्वजनिक होने का खतरा कम हो जाता है.
डिफ़रेंशियल प्राइवसी का इस्तेमाल, मशीन लर्निंग के अलावा अन्य प्लैटफ़ॉर्म पर भी किया जाता है. उदाहरण के लिए, डेटा साइंटिस्ट अलग-अलग डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) के लिए प्रॉडक्ट के इस्तेमाल के आंकड़ों का हिसाब लगाते समय, किसी व्यक्ति की निजता की सुरक्षा के लिए कभी-कभी डिफ़रेंशियल प्राइवसी का इस्तेमाल करते हैं.
डाइमेंशन कम करने की सुविधा
फ़ीचर वेक्टर में किसी सुविधा को दिखाने के लिए इस्तेमाल होने वाले डाइमेंशन की संख्या कम करने के लिए, आम तौर पर एम्बेडिंग वेक्टर का इस्तेमाल किया जाता है.
आयाम
ओवरलोडेड टर्म जिसका इनमें से कोई एक मतलब है:
किसी टेन्सर में निर्देशांक के लेवल की संख्या. जैसे:
- किसी अदिश का आयाम शून्य होता है; उदाहरण के लिए,
["Hello"]. - वेक्टर में एक डाइमेंशन होता है; उदाहरण के लिए,
[3, 5, 7, 11]. - किसी मैट्रिक्स में दो डाइमेंशन होते हैं. उदाहरण के लिए,
[[2, 4, 18], [5, 7, 14]].
किसी खास सेल को एक डाइमेंशन वाले वेक्टर में यूनीक तौर पर तय करने के लिए, एक कोऑर्डिनेट का इस्तेमाल किया जा सकता है. किसी 2-डाइमेंशन मैट्रिक्स में किसी खास सेल की जानकारी देने के लिए, आपको दो निर्देशांक की ज़रूरत होती है.
- किसी अदिश का आयाम शून्य होता है; उदाहरण के लिए,
फ़ीचर वेक्टर में एंट्री की संख्या.
एम्बेडिंग लेयर में एलिमेंट की संख्या.
सीधे तौर पर प्रॉम्प्ट
ज़ीरो-शॉट प्रॉम्प्ट का पर्यायवाची.
डिस्क्रीट सुविधा
एक ऐसी सुविधा जिसमें संभावित वैल्यू के सीमित सेट होते हैं. उदाहरण के लिए, ऐसी सुविधा जिसके मान सिर्फ़ जानवर, सब्ज़ियों या खनिज हो सकते हैं. यह एक अलग या खास तरह की सुविधा होती है.
लगातार सुविधा से तुलना करें.
भेदभाव वाला मॉडल
एक ऐसा model जो एक या उससे ज़्यादा model के सेट के लिए, model का अनुमान लगाता है. औपचारिक रूप से, भेदभाव वाले मॉडल, सुविधाओं और वज़न के आधार पर किसी आउटपुट की संभावित संभावना के बारे में बताते हैं. इसका मतलब है कि:
p(output | features, weights)
उदाहरण के लिए, ऐसा मॉडल जो यह अनुमान लगाता है कि सुविधाओं और वज़न से मिलने वाला कोई ईमेल, स्पैम है या नहीं.
क्लासिफ़िकेशन और रिग्रेशन मॉडल के साथ-साथ, निगरानी में रखे गए ज़्यादातर मॉडल, भेदभाव वाले मॉडल हैं.
जनरेटिव मॉडल में अंतर होना चाहिए.
डिस्क्रिमिनेटर
ऐसा सिस्टम जो यह तय करता है कि उदाहरण असली हैं या नकली.
इसके अलावा, जनरेटिव ऐडवर्सल नेटवर्क का एक सबसिस्टम भी होता है. इससे यह पता चलता है कि जनरेटर के बनाए गए उदाहरण असली हैं या नकली.
अलग-अलग असर
ऐसे लोगों के बारे में फ़ैसले लेना जो अलग-अलग सबग्रुप पर ज़रूरत से ज़्यादा असर डालते हैं. आम तौर पर, इसका मतलब है कि वे ऐसी स्थितियां हैं जिनमें एल्गोरिदम से लिए गए फ़ैसले लेने की प्रोसेस से कुछ सबग्रुप को नुकसान पहुंचता है या उन्हें किसी अन्य ग्रुप के मुकाबले ज़्यादा फ़ायदा होता है.
उदाहरण के लिए, मान लीजिए कि कोई ऐसा एल्गोरिदम जो यह तय करता है कि मिनिएचर होम लोन पाने के लिए लिलिपुटियन की ज़रूरी शर्तें पूरी हो रही हैं या नहीं, उस एल्गोरिदम के डाक पते में कोई पिन कोड होने पर, उस एल्गोरिदम को "अयोग्यता" की कैटगरी में रखने की संभावना ज़्यादा होती है. अगर लिटिल-एंडियन लिलिपुटियन की तुलना में, बिग-एंडियन लिलीपुटियन के इस पिन कोड वाले डाक पते होने की संभावना ज़्यादा है, तो इस एल्गोरिदम का असर अलग-अलग हो सकता है.
अलग-अलग ट्रीटमेंट से यह अलग है. इसमें उन असमानताओं पर फ़ोकस किया जाता है जिनकी वजह से सबग्रुप की विशेषताएं, एल्गोरिदम से तय करने की प्रोसेस के लिए साफ़ तौर पर तैयार किए गए इनपुट होती हैं.
अलग-अलग ट्रीटमेंट
किसी व्यक्ति के संवेदनशील विशेषताओं को एल्गोरिदम के आधार पर तय करने की प्रोसेस में शामिल करना. इस तरह से, लोगों के अलग-अलग सबग्रुप के साथ अलग-अलग व्यवहार करना.
उदाहरण के लिए, एक ऐसा एल्गोरिदम इस्तेमाल किया जा सकता है जो यह तय करता है कि लिलिपुट के लोग, क़र्ज़ के आवेदन में दिए गए डेटा के आधार पर मिनिएचर होम लोन ले सकते हैं या नहीं. अगर एल्गोरिदम, इनपुट के तौर पर बिग-एंडियन या लिटिल-एंडियन के तौर पर लिलिपुटियन के अफ़िलिएशन का इस्तेमाल करता है, तो उस डाइमेंशन के हिसाब से अलग-अलग ट्रीटमेंट लागू किया जा सकता है.
अलग-अलग असर से अंतर होता है. इसमें सबग्रुप पर एल्गोरिदम से जुड़े फ़ैसलों से समाज पर पड़ने वाले असर पर फ़ोकस किया गया है. इस बात से कोई फ़र्क़ नहीं पड़ता कि वे सबग्रुप, मॉडल के लिए इनपुट हैं या नहीं.
डिस्टिलेशन
एक model (जिसे model कहा जाता है) के साइज़ को एक छोटे मॉडल (model) में कम करने की प्रोसेस, जो ओरिजनल मॉडल के अनुमानों को जितना हो सके उतना बेहतर तरीके से सिम्युलेट करता है. अलग-अलग तरह के मॉडल का इस्तेमाल करना आसान है, क्योंकि बड़े मॉडल (शिक्षक) की तुलना में, छोटे मॉडल के दो मुख्य फ़ायदे हैं:
- अनुमान लगाने में कम समय लगेगा
- मेमोरी और ऊर्जा की खपत में कमी
हालांकि, छात्र-छात्राओं के सुझाव आम तौर पर उतने अच्छे नहीं होते जितने कि शिक्षक के अनुमान पर आधारित होते हैं.
इसके लिए, छात्र-छात्रा के मॉडल को ट्रेनिंग दी जाती है, ताकि वह लॉस फ़ंक्शन को कम से कम कर सके. यह ट्रेनिंग, छात्र-छात्राओं और शिक्षक के मॉडल के अनुमानों के आउटपुट के आउटपुट के बीच के अंतर के आधार पर की जाती है.
डिस्टिलेशन की तुलना करने के लिए, नीचे दिए गए शब्दों का इस्तेमाल करें:
डिस्ट्रिब्यूशन
किसी सुविधा या लेबल के लिए, अलग-अलग वैल्यू की फ़्रीक्वेंसी और रेंज. डिस्ट्रिब्यूशन से पता चलता है कि किसी खास वैल्यू के होने की कितनी संभावना है.
नीचे दी गई इमेज में दो अलग-अलग डिस्ट्रिब्यूशन के हिस्टोग्राम दिखाए गए हैं:
- बाईं ओर, ऊर्जा के पावर लॉ डिस्ट्रिब्यूशन की जगह दिख रही है.
- दाईं ओर, लंबाई के मुकाबले इस ऊंचाई वाले लोगों की संख्या का सामान्य डिस्ट्रिब्यूशन.

हर सुविधा और लेबल के डिस्ट्रिब्यूशन को समझने से, वैल्यू को नॉर्मलाइज़ करने और आउटलायर का पता लगाने का तरीका तय करने में मदद मिल सकती है.
डिस्ट्रिब्यूशन से बाहर वाक्यांश का मतलब ऐसी वैल्यू से है जो डेटासेट में नहीं दिखती या बहुत कम होती है. उदाहरण के लिए, ऐसे डेटासेट के लिए शनि ग्रह की इमेज को डिस्ट्रिब्यूशन से बाहर माना जाएगा जिसमें बिल्ली की इमेज हों.
डिवाइक्टिव क्लस्टरिंग
हैरारकल क्लस्टरिंग देखें.
डाउनसैंपलिंग
ओवरलोडेड टर्म, जिसका इनमें से कोई एक मतलब हो सकता है:
- किसी मॉडल को ज़्यादा बेहतर तरीके से ट्रेन करने के लिए, किसी सुविधा में जानकारी की संख्या कम करना. उदाहरण के लिए, इमेज पहचानने वाले मॉडल को ट्रेनिंग देने से पहले, हाई-रिज़ॉल्यूशन वाली इमेज को कम रिज़ॉल्यूशन वाले फ़ॉर्मैट में डाउनसैंपल करना.
- ऐसे क्लास के उदाहरणों पर ट्रेनिंग देना जो बेहतर प्रतिनिधित्व नहीं किए गए हैं. इससे उन क्लास के लिए मॉडल ट्रेनिंग को बेहतर बनाया जा सकेगा जिनके पास ज़्यादा प्रतिनिधित्व नहीं था. उदाहरण के लिए, क्लास-असंतुलित डेटासेट में, मॉडल को मैजरिटी क्लास के बारे में ज़्यादा जानकारी मिलती है और यह माइनरिटी क्लास के बारे में ज़्यादा नहीं है. डाउनसैंपलिंग की मदद से, ज़्यादातर और अल्पसंख्यक क्लास के लिए ट्रेनिंग को बैलेंस करने में मदद मिलती है.
डीक्यूएन
Deep Q-Network का शॉर्ट फ़ॉर्म.
सर्वे बीच में छोड़ने वाले लोगों के लिए रेगुलराइज़ेशन
यह एक तरह का सामान्य नेटवर्क है, जो न्यूरल नेटवर्क की ट्रेनिंग में काम आता है. ड्रॉप-आउट रेगुलर करने से, किसी एक ग्रेडिएंट चरण के लिए नेटवर्क लेयर में यूनिट की तय संख्या को किसी भी क्रम में हटा दिया जाता है. जितनी ज़्यादा यूनिट छोड़ी गईं, रेगुलराइज़ेशन उतना ही मज़बूत होगा. इस तरह की ट्रेनिंग, नेटवर्क को बड़े पैमाने पर छोटे नेटवर्क के ग्रुप को एम्युलेट करने की ट्रेनिंग देने जैसा है. पूरी जानकारी के लिए, ड्रॉपआउट: न्यूरल नेटवर्क को ओवरफ़िट होने से रोकने का एक आसान तरीका देखें.
डाइनैमिक
कोई ऐसा काम जो बार-बार किया जाता हो या लगातार किया जाता हो. मशीन लर्निंग में, डाइनैमिक और ऑनलाइन शब्दों का समानार्थी मतलब होता है. मशीन लर्निंग में डाइनैमिक और ऑनलाइन इस्तेमाल के कुछ सामान्य तरीके नीचे दिए गए हैं:
- डाइनैमिक मॉडल (या ऑनलाइन मॉडल) ऐसा मॉडल है जिसे बार-बार या लगातार ट्रेनिंग दी जाती है.
- डाइनैमिक ट्रेनिंग (या ऑनलाइन ट्रेनिंग), ट्रेनिंग की ऐसी प्रोसेस है जिसमें बहुत कम बार या लगातार ट्रेनिंग दी जाती है.
- डाइनैमिक अनुमान या ऑनलाइन अनुमान, ज़रूरत के हिसाब से अनुमान जनरेट करने की प्रोसेस है.
डाइनैमिक मॉडल
ऐसा model जिसे अक्सर (हो सकता है कि लगातार) ट्रेनिंग दी गई हो. डाइनैमिक मॉडल, "हमेशा सीखते रहने वाला" होता है. यह लगातार बदलते डेटा के हिसाब से बदलता रहता है. डाइनैमिक मॉडल को ऑनलाइन मॉडल भी कहा जाता है.
स्टैटिक मॉडल से कंट्रास्ट अलग हो.
E
ईगर एक्ज़ीक्यूशन
ऐसा TensorFlow प्रोग्रामिंग एनवायरमेंट है जिसमें operations तुरंत चलने लगते हैं. वहीं दूसरी ओर, ग्राफ़ एक्ज़ीक्यूशन वाली कार्रवाइयां तब तक नहीं चलती हैं, जब तक उनका साफ़ तौर पर आकलन नहीं किया जाता. जल्द से जल्द एक्ज़ीक्यूट करना एक ज़रूरी इंटरफ़ेस है, जो ज़्यादातर प्रोग्रामिंग भाषाओं में कोड की तरह होता है. आम तौर पर, ग्राफ़ एक्ज़ीक्यूशन प्रोग्राम के मुकाबले, जल्द से जल्द एक्ज़ीक्यूशन करने वाले प्रोग्राम को डीबग करना आसान होता है.
समय से पहले रुकने की जगह
नियमित करने का तरीका, जिसमें ट्रेनिंग में कमी होने से पहले ट्रेनिंग खत्म करना शामिल है. शुरुआत में बंद करने पर, पुष्टि करने वाले डेटासेट की लॉस बढ़ने पर, आपने जान-बूझकर मॉडल को ट्रेनिंग देना बंद कर दिया है. इसका मतलब है कि जब सामान्य जानकारी की परफ़ॉर्मेंस खराब हो जाती है.
पृथ्वी मूवर की दूरी (ईएमडी)
दो डिस्ट्रिब्यूशन की मिलती-जुलती समानता का पैमाना. पृथ्वी मूवर की दूरी जितनी कम होगी, डिस्ट्रिब्यूशन उतना ही ज़्यादा होगा.
दूरी में बदलाव करें
एक जैसी दो टेक्स्ट स्ट्रिंग एक-दूसरे से कितनी मिलती-जुलती हैं. मशीन लर्निंग में, दूरी में बदलाव करना फ़ायदेमंद होता है, क्योंकि इसकी गिनती करना आसान होता है. साथ ही, यह दो स्ट्रिंग की तुलना करने का एक असरदार तरीका है, जो मिलती-जुलती हैं या दी गई स्ट्रिंग से मिलती-जुलती स्ट्रिंग को ढूंढती हैं.
बदलाव की दूरी की कई परिभाषाएं होती हैं, जिनमें से हर एक के लिए अलग-अलग स्ट्रिंग ऑपरेशन का इस्तेमाल किया जाता है. उदाहरण के लिए, लेवेंशेन डिस्टेंस कम से कम डिलीट करने, इंसर्ट करने, और अन्य कार्रवाइयों को ध्यान में रखता है.
उदाहरण के लिए, "दिल" और "डार्ट" शब्दों के बीच लेवनस्टीन की दूरी तीन है, क्योंकि एक शब्द को दूसरे शब्द में बदलने के लिए, नीचे दिए गए तीन बदलावों को कम किया गया है:
- दिल → डीआर्ट ("h" को "d" से बदलें)
- डीआर्ट → डार्ट (मिटाएं "e")
- डार्ट → डार्ट ("s" डालें)
आइनसम नोटेशन
दो टेन्सर को जोड़ने का तरीका बताने के लिए, एक असरदार नोटेशन. टेंसर को जोड़ने के लिए, एक टेंसर के एलिमेंट को दूसरे टेंसर के एलिमेंट से गुणा करें और फिर गुणनफल को जोड़ें. आइनसम नोटेशन हर टेंसर के ऐक्सिस की पहचान करने के लिए, प्रतीकों का इस्तेमाल करता है. इन चिह्नों को फिर से क्रम में लगाकर, नए टेंसर का आकार तय किया जाता है.
NumPy एक सामान्य Einsum लागू करता है.
एम्बेडिंग लेयर
एक खास छिपी हुई लेयर जो अच्छी-डाइमेंशन वाली कैटगरिकल सुविधा का इस्तेमाल करके, लोअर डाइमेंशन एम्बेड करने वाले वेक्टर को धीरे-धीरे सीखती है. एम्बेड करने वाली लेयर की मदद से, न्यूरल नेटवर्क को सिर्फ़ हाई डाइमेंशन वाली कैटगरीकल सुविधा की ट्रेनिंग देने के बजाय, ज़्यादा कुशल तरीके से ट्रेनिंग मिलती है.
उदाहरण के लिए, फ़िलहाल Earth, पेड़ों की करीब 73,000 प्रजातियों का समर्थन करती है. मान लीजिए
पेड़ की किस्में आपके मॉडल में एक सुविधा है, तो आपके मॉडल की इनपुट लेयर में 73,000 एलिमेंट वाला वन-हॉट वेक्टर शामिल है.
उदाहरण के लिए, शायद baobab कुछ ऐसा दिखाया जाएगा:

73,000 एलिमेंट का अरे बहुत लंबा होता है. अगर मॉडल में एम्बेडिंग लेयर नहीं जोड़ी जाती, तो इस मॉडल में 72,999 शून्य से गुणा करने पर ट्रेनिंग में बहुत समय लगेगा. आप 12 डाइमेंशन के लिए एम्बेडिंग लेयर चुन सकते हैं. इससे धीरे-धीरे, एम्बेड करने वाली लेयर, पेड़ों की हर प्रजाति के लिए एक नया एम्बेडिंग वेक्टर सीखेगी.
कुछ मामलों में, एम्बेडिंग लेयर के लिए हैशिंग एक बेहतर विकल्प है.
एम्बेड करने की जगह
हाई-डाइमेंशन वाले वेक्टर स्पेस की सुविधाओं वाले डी-डाइमेंशन वाले वेक्टर स्पेस को मैप किया जाता है. आम तौर पर, एम्बेड करने की जगह में ऐसा स्ट्रक्चर होता है जिससे गणित के अच्छे नतीजे मिलते हैं. उदाहरण के लिए, अगर एम्बेड करने की सही जगह में, एम्बेड करने की जगह को जोड़ने और घटाने से, शब्दों से जुड़े टास्क हल किए जा सकते हैं, तो इसका इस्तेमाल किया जा सकता है.
दो एम्बेड किए गए बिंदु वाले प्रॉडक्ट से पता चलता है कि वे कितने मिलते-जुलते हैं.
एम्बेडिंग वेक्टर
आम तौर पर, किसी छिपी हुई लेयर से फ़्लोटिंग-पॉइंट नंबरों का कलेक्शन, जो उस छिपी हुई लेयर के इनपुट के बारे में बताता है. अक्सर, एम्बेड करने वाला वेक्टर, एम्बेडिंग लेयर में ट्रेन किए गए फ़्लोटिंग-पॉइंट नंबरों का कलेक्शन होता है. उदाहरण के लिए, मान लीजिए कि एक एम्बेडिंग लेयर को धरती पर मौजूद पेड़ों की 73,000 प्रजातियों में से हर एक के लिए, एक एम्बेडिंग वेक्टर का अनुभव होना ज़रूरी है. शायद नीचे दी गई अरे बेओबैब ट्री के लिए एम्बेडिंग वेक्टर है:

एम्बेडिंग वेक्टर, रैंडम नंबरों का ग्रुप नहीं होता. एक एम्बेडिंग लेयर, इन वैल्यू को ट्रेनिंग के ज़रिए तय करती है, ठीक उसी तरह जैसे न्यूरल नेटवर्क, ट्रेनिंग के दौरान अन्य वेट को समझता है. कैटगरी का हर एलिमेंट, पेड़ की प्रजाति की कुछ विशेषताओं के साथ दी जाने वाली रेटिंग है. कौनसा एलिमेंट, पेड़ की किस प्रजाति की विशेषता बताता है? इंसानों के लिए यह तय करना बहुत मुश्किल है.
एम्बेडिंग वेक्टर का गणितीय रूप से अहम हिस्सा यह है कि एक जैसे आइटम में फ़्लोटिंग-पॉइंट संख्याओं के एक जैसे सेट होते हैं. उदाहरण के लिए, पेड़ों की एक जैसी प्रजातियों में, अलग-अलग तरह के पेड़ों की तुलना में फ़्लोटिंग-पॉइंट नंबर के सेट, एक जैसे होते हैं. रेडवुड और सिकोया, एक-दूसरे से जुड़े पेड़ों की प्रजातियां हैं. इसलिए, रेडवुड और नारियल के ताड़ के मुकाबले, इनमें फ़्लोट करने वाले पॉइंट मिलते-जुलते होते हैं. मॉडल को फिर से ट्रेनिंग देने पर, एम्बेड करने वाले वेक्टर में संख्या बदल जाएगी. भले ही, आपने एक जैसे इनपुट वाले मॉडल को फिर से ट्रेनिंग दी हो.
एंपिरिकल क्यूमुलेटिव डिस्ट्रिब्यूशन फ़ंक्शन (eCDF या EDF)
यह किसी असल डेटासेट से लिया गया कुल डिस्ट्रिब्यूशन फ़ंक्शन है जो एंपिरिकल मेज़रमेंट पर आधारित होता है. x-ऐक्सिस पर किसी भी पॉइंट पर फ़ंक्शन की वैल्यू, डेटासेट में ऑब्ज़र्वेशन का वह हिस्सा है जो तय की गई वैल्यू से कम या उसके बराबर है.
इमपिरिकल रिस्क मिनिमाइज़ेशन (ईआरएम)
ऐसा फ़ंक्शन चुनना जो ट्रेनिंग सेट में होने वाले नुकसान को कम से कम करता हो. संरचना से होने वाले जोखिम को कम करने के बीच अंतर करें.
एन्कोडर
आम तौर पर, ऐसा कोई भी एमएल सिस्टम जो रॉ, स्पैर्स या एक्सटर्नल रिप्रज़ेंटेशन को ज़्यादा प्रोसेस, ज़्यादा या ज़्यादा अंदरूनी प्रतिनिधित्व में बदल देता है.
एन्कोडर अक्सर किसी बड़े मॉडल का हिस्सा होता है. इसमें इन्हें अक्सर डीकोडर के साथ जोड़ा जाता है. कुछ ट्रांसफ़ॉर्मर एन्कोडर को डिकोडर से जोड़ते हैं. हालांकि, दूसरे ट्रांसफ़ॉर्मर सिर्फ़ एन्कोडर या डीकोडर का इस्तेमाल करते हैं.
कुछ सिस्टम, किसी क्लासिफ़िकेशन या रिग्रेशन नेटवर्क के इनपुट के तौर पर एन्कोडर के आउटपुट का इस्तेमाल करते हैं.
क्रम से जुड़े टास्क में, एन्कोडर इनपुट का क्रम लेता है और अंदरूनी स्थिति (वेक्टर) दिखाता है. इसके बाद, डीकोडर उस अंदरूनी स्थिति का इस्तेमाल करके, अगले क्रम का अनुमान लगाता है.
ट्रांसफ़ॉर्मर आर्किटेक्चर में एन्कोडर की परिभाषा जानने के लिए, ट्रांसफ़ॉर्मर देखें.
एन्सेम्बल
अलग-अलग ट्रेनिंग वाले मॉडल का एक कलेक्शन, जिनके अनुमानों का औसत या एग्रीगेट किया जाता है. कई मामलों में, एन्सेंबल किसी मॉडल की तुलना में बेहतर अनुमान देता है. उदाहरण के लिए, रैंडम फ़ॉरेस्ट कई डिसिज़न ट्री से बनाया गया ग्रुप है. ध्यान दें कि फ़ैसले लेने के लिए तय सभी फ़ॉरेस्ट असेंबली नहीं हैं.
एन्ट्रॉपी
इन्फ़ॉर्मेशन थ्योरी में, प्रॉबबिलिटी के डिस्ट्रिब्यूशन की जानकारी दी जाती है. इसके अलावा, एंट्रॉपी का मतलब यह भी है कि हर उदाहरण में कितनी जानकारी मौजूद है. जब किसी रैंडम वैरिएबल की सभी वैल्यू बराबर हों, तो डिस्ट्रिब्यूशन की एंट्रॉपी सबसे ज़्यादा होती है.
किसी ऐसे सेट की एन्ट्रॉपी का फ़ॉर्मूला जिसका फ़ॉर्मूला है: "0" और "1" दो संभावित वैल्यू "0" और "1" (उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन वाले लेबल में लेबल):
H = -p लॉग p - q लॉग q = -p लॉग p - (1-p) * लॉग (1-p)
कहां:
- H एंट्रॉपी है.
- p, "1" उदाहरणों का अंश है.
- q, "0" उदाहरणों का हिस्सा है. ध्यान दें कि q = (1 - p)
- आम तौर पर, log फ़ंक्शन लॉग2 होता है. इस मामले में, एंट्रॉपी यूनिट थोड़ी-सी है.
उदाहरण के लिए, मान लें कि:
- 100 उदाहरणों में "1" वैल्यू शामिल है
- 300 उदाहरणों में "0" वैल्यू है
इसलिए, एंट्रॉपी की वैल्यू यह है:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = हर उदाहरण के लिए 0.81 बिट
पूरी तरह से संतुलित सेट (उदाहरण के लिए, 200 "0" और 200 "1") में, हर उदाहरण के लिए 1.0 बिट की एंट्रॉपी होगी. जैसे-जैसे कोई सेट ज़्यादा असंतुलित होता जाता है, उसकी एंट्रॉपी 0.0 की ओर बढ़ जाती है.
डिसिज़न ट्री में, एंट्रॉपी जानकारी पाने बनाने में मदद करता है. इससे स्प्लिटर को डेटा की कैटगरी तय करने वाले डिसिज़न ट्री में बढ़ोतरी के दौरान, शर्तें चुनने में मदद मिलती है.
एंट्रॉपी की तुलना इनसे करें:
- गिनी इंपरिटी
- क्रॉस-एंट्रॉपी लॉस फ़ंक्शन
एंट्रॉपी को अक्सर शैनन की एंट्रॉपी कहा जाता है.
वातावरण
रीइन्फ़ोर्समेंट लर्निंग में, ऐसी दुनिया जिसमें एजेंट होता है और एजेंट को उस दुनिया की स्थिति को ट्रैक करने की अनुमति मिलती है. उदाहरण के लिए, यहां शतरंज जैसे खेल या भूलभुलैया जैसी दुनिया को दिखाया जा सकता है. जब एजेंट एनवायरमेंट पर कोई कार्रवाई लागू करता है, तो एक स्थिति से दूसरी स्थिति में एनवायरमेंट बदल जाता है.
एपिसोड
रीइन्फ़ोर्समेंट लर्निंग में, हर एनवायरमेंट को सीखने के लिए एजेंट की बार-बार कोशिश की जाती है.
epoch
पूरे ट्रेनिंग सेट के लिए एक पूरा ट्रेनिंग पास, जैसे कि हर उदाहरण को एक बार प्रोसेस किया गया हो.
Epoch, N/बैच साइज़ ट्रेनिंग इटरेशन को दिखाता है, जहां N उदाहरणों की कुल संख्या है.
उदाहरण के लिए, मान लें कि:
- इस डेटासेट में 1,000 उदाहरण शामिल हैं.
- बैच का साइज़ 50 उदाहरण है.
इसलिए, एक epoch को 20 बार दोहराना ज़रूरी है:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
एप्सिलॉन लालची नीति
रीइन्फ़ोर्समेंट लर्निंग में, एक ऐसी नीति जो या तो रैंडम नीति का पालन करती है. इस नीति में एप्सिलॉन प्रॉबबिलिटी की संभावना होती है. इसके अलावा, यह नीति लालच के लिए बनाई गई नीति का इस्तेमाल नहीं करती. उदाहरण के लिए, अगर ऐपिलॉन 0.9 है, तो 90% मामलों में यह नीति किसी भी क्रम में और 10% बार लालची नीति का पालन करती है.
एल्गोरिदम, एक के बाद एक कई एपिसोड पर, एपसिलॉन की वैल्यू को कम कर देता है. ऐसा, लालची वाली नीति के बजाय किसी भी क्रम में की गई नीति के हिसाब से किया जाता है. नीति में बदलाव करके, एजेंट पहले बिना किसी तय क्रम के पर्यावरण को एक्सप्लोर करता है और फिर लालच में किसी भी तरीके से खोजे जाने वाले नतीजों का फ़ायदा उठाता है.
अवसर की समानता
इस मेट्रिक से पता चलता है कि कोई मॉडल, संवेदनशील एट्रिब्यूट की सभी वैल्यू के लिए मनमुताबिक नतीजे का समान रूप से अनुमान लगाता है या नहीं, यह आकलन करने के लिए फ़ेयरनेस मेट्रिक का इस्तेमाल किया जाता है. दूसरे शब्दों में, अगर किसी मॉडल के लिए मनचाहा नतीजा पॉज़िटिव क्लास है, तो लक्ष्य होगा कि सही पॉज़िटिव रेट सभी ग्रुप के लिए एक जैसा हो.
अवसरों की समानता एक जैसी संभावना से जुड़ी है. इसके लिए ज़रूरी है कि दोनों सही पॉज़िटिव रेट और फ़ॉल्स पॉज़िटिव रेट, सभी ग्रुप के लिए एक जैसे हों.
मान लीजिए कि ग्लबडुब्ड्रिब यूनिवर्सिटी लिलिपुटियन और ब्रोबडिंगनेगियन, दोनों को गणित के सख्त प्रोग्राम में शामिल करती है. लिलिपुटियन के सेकंडरी स्कूलों में गणित की क्लास का एक बेहतरीन पाठ्यक्रम दिया जाता है. इनमें से ज़्यादातर छात्र-छात्राएं, यूनिवर्सिटी प्रोग्राम में हिस्सा ले सकते हैं. ब्रोबडिंगनैजियन के सेकंडरी स्कूलों में गणित की कक्षाएं नहीं चलती हैं. इस वजह से, बहुत कम छात्र-छात्राएं ही क्वालिफ़ाई हो पाते हैं. राष्ट्रीयता (लिलिपुटियन या ब्रोबडिंगनाजियन) के लिए "मान्य" का पसंदीदा लेबल मिलने पर, सबको एक जैसा मौका मिलता है. हालांकि, इसके लिए ज़रूरी है कि योग्यता पूरी करने वाले छात्र-छात्राओं को भी एडमिशन मिलने की संभावना बराबर हो. भले ही, वे लिलिपुटियन हों या ब्रोबडिंगनाजियन.
उदाहरण के लिए, मान लें कि ग्लबडुब्ड्रिब यूनिवर्सिटी में 100 लिलिपुटियन और 100 ब्रोबडिंगनाजियन आवेदन करते हैं और एडमिशन के लिए फ़ैसले इस तरह लिए जाते हैं:
टेबल 1. लिलिपुटियन आवेदक (90% योग्य हैं)
| क्वालिफ़ाई किया है | अयोग्य | |
|---|---|---|
| अनुमति दी गई | 45 | 3 |
| अस्वीकार किया गया | 45 | 7 |
| कुल | 90 | 10 |
|
शामिल होने वाले योग्य छात्र-छात्राओं का प्रतिशत: 45/90 = 50% अस्वीकार किए गए काबिल छात्र-छात्राओं का प्रतिशत: 7/10 = 70% लिलिपुटियन छात्र-छात्राओं का कुल प्रतिशत: (45+3)/100 = 48% |
||
दूसरी टेबल. ब्रोबडिंगनाजियन आवेदक (10% योग्य हैं):
| क्वालिफ़ाई किया है | अयोग्य | |
|---|---|---|
| अनुमति दी गई | 5 | 9 |
| अस्वीकार किया गया | 5 | 81 |
| कुल | 10 | 90 |
|
स्वीकार किए जाने वाले छात्रों का प्रतिशत: 5/10 = 50% अस्वीकार किए गए काबिल छात्र-छात्राओं का प्रतिशत: 81/90 = 90% स्वीकार किए गए ब्रोबडिंगनागियन छात्र-छात्राओं का कुल प्रतिशत: (5+9)/100 = 14% |
||
ऊपर दिए गए उदाहरण, योग्यता पूरी करने वाले छात्र-छात्राओं को दिए जाने वाले अवसरों की समानता के बारे में बताते हैं. इसकी वजह यह है कि लिलिपुटियन और ब्रोबडिंगनेगियन, दोनों के पास दाखिले की संभावना 50% होती है.
सबको समान अवसर मिलते हैं, लेकिन निष्पक्षता से जुड़े ये दो मेट्रिक पूरे नहीं होते:
- डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) के बीच का अंतर: लिलीपुटियन और ब्रोबडिंगनाजियन को यूनिवर्सिटी में अलग-अलग दर से एडमिशन मिलता है. लिलीपुटियन के 48% छात्र-छात्राएं ही इसमें शामिल होते हैं, लेकिन ब्रोबडिंगनैजियन में सिर्फ़ 14% छात्र-छात्राओं को ही शामिल किया जाता है.
- एक जैसी संभावना: ज़रूरी शर्तें पूरी करने वाले लिलीपुटियन और ब्रोबडिंगनेगियन, दोनों के छात्र-छात्राओं में शामिल होने की संभावना एक जैसी होती है. हालांकि, एक अतिरिक्त शर्त है कि लिलीपुटियन और ब्रोबडिंगनेगियन, दोनों का आवेदन अस्वीकार होने का एक जैसा मौका होता है. हालांकि, इस शर्त को पूरा नहीं किया जा सकता. काबिल लिलीपुटियन के लिए, अस्वीकार किए जाने की दर 70% है, जबकि ब्रोबडिंगनेग में योग्यता हासिल न करने वाले लोगों के अस्वीकार किए जाने की दर 90% है.
समानता के अवसरों के बारे में ज़्यादा जानने के लिए, "सुपरवाइज़्ड लर्निंग में बराबरी" देखें. यह भी देखें कि कैसे बराबरी को ऑप्टिमाइज़ करने पर, कन्वर्ज़न की अहमियत के बारे में पता लगाया जा सकता है. इसके लिए, "स्मार्ट मशीन लर्निंग की मदद से अलग-अलग तरह के भेदभाव' का इस्तेमाल करना" लेख पढ़ें.
इक्वलाइज़्ड ऑड्स
यह आकलन करने के लिए निष्पक्ष मेट्रिक है कि क्या कोई मॉडल, किसी एक संवेदनशील एट्रिब्यूट की सभी वैल्यू के लिए एक जैसा अनुमान लगा रहा है. इसमें पॉज़िटिव क्लास और नेगेटिव क्लास, दोनों की वैल्यू शामिल हैं, न कि सिर्फ़ एक या दूसरी क्लास के लिए. दूसरे शब्दों में कहें, तो ट्रू पॉज़िटिव रेट और फ़ॉल्स नेगेटिव रेट, दोनों सभी ग्रुप के लिए एक जैसे होने चाहिए.
बराबर संभावना अवसर की समानता से जुड़ी है. इसमें सिर्फ़ एक क्लास (पॉज़िटिव या नेगेटिव) की गड़बड़ी की दर पर फ़ोकस किया जाता है.
उदाहरण के लिए, मान लें कि ग्लबडुब्ड्रिब यूनिवर्सिटी लिलिपुटियन और ब्रोबडिंगनैजियन, दोनों को गणित के कड़े गणित के कार्यक्रम में शामिल करती है. लिलिपुटियन के सेकंडरी स्कूलों में, गणित की क्लास का दमदार पाठ्यक्रम उपलब्ध कराया जाता है. साथ ही, ज़्यादातर छात्र-छात्राएं, यूनिवर्सिटी प्रोग्राम में हिस्सा ले सकते हैं. ब्रोबडिंगनैजियन के सेकंडरी स्कूलों में गणित की क्लास नहीं होती. इस वजह से, स्कूल में उनके बहुत कम छात्र-छात्राएं क्वालिफ़ाई हो पाते हैं. सभी नतीजे एक जैसे ही होते हैं. हालांकि, इस बात से कोई फ़र्क़ नहीं पड़ता कि आवेदन करने वाला व्यक्ति लिलिपुटियन है या ब्रोबडिंगनाजियन. अगर वह योग्य है, तो उसे प्रोग्राम में शामिल होने की संभावना उतनी ही ज़्यादा होती है. साथ ही, प्रोग्राम में शामिल होने की संभावना बराबर होने के बाद, आवेदन अस्वीकार कर दिया जाता है.
मान लें कि 100 लिलिपुटियन और 100 ब्रोबडिंगनाजियन, ग्लबडुब्ड्रिब यूनिवर्सिटी में आवेदन करते हैं और एडमिशन के लिए इस तरह के फ़ैसले लिए गए हैं:
तीसरी टेबल. लिलिपुटियन आवेदक (90% योग्य हैं)
| क्वालिफ़ाई किया है | अयोग्य | |
|---|---|---|
| अनुमति दी गई | 45 | 2 |
| अस्वीकार किया गया | 45 | 8 |
| कुल | 90 | 10 |
|
शामिल होने वाले योग्य छात्र-छात्राओं का प्रतिशत: 45/90 = 50% अस्वीकार किए गए काबिल छात्र-छात्राओं का प्रतिशत: 8/10 = 80% लिलिपुटियन छात्र-छात्राओं का कुल प्रतिशत: (45+2)/100 = 47% |
||
टेबल 4. ब्रोबडिंगनाजियन आवेदक (10% योग्य हैं):
| क्वालिफ़ाई किया है | अयोग्य | |
|---|---|---|
| अनुमति दी गई | 5 | 18 |
| अस्वीकार किया गया | 5 | 72 |
| कुल | 10 | 90 |
|
स्वीकार किए गए छात्र-छात्राओं का प्रतिशत: 5/10 = 50% अस्वीकार किए गए काबिल छात्र-छात्राओं का प्रतिशत: 72/90 = 80% स्वीकार किए गए ब्रोबडिंगनाजियन छात्र-छात्राओं का कुल प्रतिशत: (5+18)/100 = 23% |
||
सभी नतीजे एक जैसे हैं. इसकी वजह यह है कि क्वालिफ़ाइड लिलिपुटियन और ब्रोबडिंगनेगियन, दोनों छात्र-छात्राओं के पास होने की संभावना 50% होती है. साथ ही, काबिल लिलीपुटियन और ब्रोबडिंगनेगियन छात्र-छात्राओं के आवेदन अस्वीकार होने की संभावना 80% होती है.
बराबर ऑड्स को औपचारिक रूप से "सुपरवाइज़्ड लर्निंग में बराबरी से जुड़े अवसर" में इस तरह बताया गया है: "अनुमान लगाने वाला व्यक्ति, सुरक्षित एट्रिब्यूट A के हिसाब से संभावनाओं को बराबर करता है. अगर Y और A, दोनों अलग-अलग हैं, तो Y के नतीजे अलग-अलग हैं."
एस्टिमेटर
ऐसा TensorFlow एपीआई जो अब काम नहीं करता. एस्टिमेटर के बजाय tf.keras का इस्तेमाल करें.
आकलन
किसी मशीन लर्निंग मॉडल के अनुमानों की क्वालिटी मेज़र करने की प्रोसेस. मॉडल बनाते समय, आम तौर पर आकलन से जुड़ी मेट्रिक को सिर्फ़ ट्रेनिंग सेट पर ही नहीं, बल्कि पुष्टि करने के सेट और टेस्ट सेट पर भी लागू किया जाता है. आकलन वाली मेट्रिक का इस्तेमाल करके, अलग-अलग मॉडल की एक-दूसरे से तुलना भी की जा सकती है.
उदाहरण
सुविधाओं की एक पंक्ति और कभी-कभी लेबल की वैल्यू. सुपरवाइज़्ड लर्निंग के उदाहरणों को दो सामान्य कैटगरी में बांटा जा सकता है:
- लेबल किए गए उदाहरण में एक या एक से ज़्यादा सुविधाएं और एक लेबल होता है. ट्रेनिंग के दौरान लेबल किए गए उदाहरणों का इस्तेमाल किया जाता है.
- बिना लेबल वाले उदाहरण में एक या उससे ज़्यादा सुविधाएं होती हैं, लेकिन कोई लेबल नहीं होता. बिना लेबल वाले उदाहरणों का इस्तेमाल, अनुमान लगाने के लिए किया जाता है.
उदाहरण के लिए, मान लें कि आपको छात्र-छात्राओं के टेस्ट स्कोर पर मौसम की स्थितियों के असर का पता लगाने के लिए, किसी मॉडल को ट्रेनिंग देनी है. लेबल किए गए तीन उदाहरण यहां दिए गए हैं:
| सुविधाएं | लेबल | ||
|---|---|---|---|
| तापमान | नमी | दबाव | टेस्ट के स्कोर |
| 15 | 47 | 998 | पसंद आया |
| 19 | 34 | 1020 | बहुत बढ़िया |
| 18 | 92 | 1012 | खराब |
यहां बिना लेबल वाले तीन उदाहरण दिए गए हैं:
| तापमान | नमी | दबाव | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
उदाहरण के लिए, आम तौर पर डेटासेट की लाइन, रॉ सोर्स होती है. इसका मतलब है कि उदाहरण में, आम तौर पर डेटासेट में कॉलम के सबसेट शामिल होते हैं. इसके अलावा, उदाहरण में दी गई सुविधाओं में सिंथेटिक सुविधाएं भी शामिल हो सकती हैं, जैसे कि फ़ीचर क्रॉस.
एक्सपीरियंस रीप्ले
रीइन्फ़ोर्समेंट लर्निंग में, एक डीक्यूएन तकनीक का इस्तेमाल किया जाता है. इसकी मदद से ट्रेनिंग डेटा में समय के बीच के संबंध को कम किया जाता है. एजेंट, रीप्ले बफ़र में स्टेट ट्रांज़िशन को सेव करता है. इसके बाद, ट्रेनिंग डेटा बनाने के लिए, रीप्ले बफ़र से ट्रांज़िशन के सैंपल इकट्ठा करता है.
एक्सपेरिमेंट करने वाले का पक्षपात
पुष्टि करने से जुड़े मापदंड देखें.
एक्सप्लोडिंग ग्रेडिएंट से जुड़ी समस्या
डीप न्यूरल नेटवर्क (खास तौर पर, बार-बार होने वाले न्यूरल नेटवर्क) में ग्रेडिएंट का बहुत ज़्यादा (ज़्यादा) हो जाता है. डीप ग्रेडिएंट की वजह से अक्सर डीप न्यूरल नेटवर्क में हर नोड के वेट में बहुत बड़े अपडेट होते हैं.
विस्फोट होने के ग्रेडिएंट की समस्या से जूझ रहे मॉडल को ट्रेनिंग देना मुश्किल या नामुमकिन हो जाता है. ग्रेडिएंट क्लिपिंग की मदद से इस समस्या को कम किया जा सकता है.
खत्म हो रहे ग्रेडिएंट की समस्या से तुलना करें.
म॰
फ़ॉर्मूला1
"रोल-अप" बाइनरी क्लासिफ़िकेशन मेट्रिक, सटीक और फिर से याद करना, दोनों पर आधारित होती है. इसका फ़ॉर्मूला यहां दिया गया है:
उदाहरण के लिए, यहां दी गई जानकारी देखें:
- सटीक = 0.6
- रीकॉल = 0.4
जब पिछले उदाहरण की तरह, सटीक होने और रीकॉल करने की प्रोसेस काफ़ी मिलती-जुलती हो, तो F1 वैल्यू काफ़ी हद तक उनके मीन के करीब होती है. जब प्रिसिज़न और रीकॉल में काफ़ी अंतर हो, तो F1 कम वैल्यू के करीब होता है. उदाहरण के लिए:
- सटीक = 0.9
- रीकॉल = 0.1
निष्पक्षता का दायरा
एल्गोरिदम में कंस्ट्रेंट को लागू करके, यह पक्का किया जा सकता है कि निष्पक्षता की एक या एक से ज़्यादा परिभाषाएं सही हैं या नहीं. निष्पक्षता से जुड़ी शर्तों के उदाहरण:- अपने मॉडल के आउटपुट को प्रोसेस करने के बाद.
- फ़ेयरनेस मेट्रिक का उल्लंघन करने वाले जुर्माने को शामिल करने के लिए, लॉस फ़ंक्शन में बदलाव करना.
- ऑप्टिमाइज़ेशन के सवाल में सीधे तौर पर गणित का कोई कंस्ट्रेंट जोड़ना.
फ़ेयरनेस मेट्रिक
"फ़ेयरनेस" की गणित की परिभाषा, जिसका आकलन किया जा सकता है. आम तौर पर, निष्पक्षता से जुड़ी ये मेट्रिक इस्तेमाल की जाती हैं:
- एक जैसी संभावना वाले नतीजे
- अनुमानित समानता
- तथ्यों के हिसाब से निष्पक्षता
- डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) समानता
निष्पक्षता वाली कई मेट्रिक म्यूचुअली एक्सक्लूसिव होती हैं. फ़ेयरनेस मेट्रिक के साथ काम न करने वाली मेट्रिक देखें.
फ़ॉल्स नेगेटिव (एफ़एन)
एक उदाहरण, जिसमें मॉडल गलती से नेगेटिव क्लास का अनुमान लगाता है. उदाहरण के लिए, मॉडल अनुमान लगाता है कि कोई ईमेल मैसेज स्पैम नहीं है (नेगेटिव क्लास), लेकिन वह ईमेल असल में स्पैम है.
फ़ॉल्स नेगेटिव रेट
उन पॉज़िटिव उदाहरणों का अनुपात जिनके लिए मॉडल ने गलती से नेगेटिव क्लास का अनुमान लगाया है. यह फ़ॉर्मूला गलत नेगेटिव दर की गणना करता है:
फ़ॉल्स पॉज़िटिव (एफ़पी)
एक उदाहरण, जिसमें मॉडल गलती से पॉज़िटिव क्लास का अनुमान लगाता है. उदाहरण के लिए, यह मॉडल अनुमान लगाता है कि कोई ईमेल स्पैम (पॉज़िटिव क्लास) है, लेकिन वह ईमेल असल में स्पैम नहीं है.
फ़ॉल्स पॉज़िटिव रेट (एफ़पीआर)
उन असल नेगेटिव उदाहरणों का अनुपात जिनके लिए मॉडल ने गलती से पॉज़िटिव क्लास का अनुमान लगाया है. यह फ़ॉर्मूला फ़ॉल्स पॉज़िटिव रेट कैलकुलेट करता है:
फ़ॉल्स पॉज़िटिव रेट, आरओसी कर्व में x-ऐक्सिस होता है.
सुविधा
किसी मशीन लर्निंग मॉडल के लिए इनपुट वैरिएबल. एक उदाहरण में एक या एक से ज़्यादा सुविधाएं होती हैं. उदाहरण के लिए, मान लीजिए कि छात्र/छात्रा के टेस्ट स्कोर पर मौसम की स्थितियों के असर का पता लगाने के लिए, आपको किसी मॉडल को ट्रेनिंग दी जा रही है. नीचे दी गई टेबल में तीन उदाहरण दिए गए हैं. हर उदाहरण में तीन सुविधाएं और एक लेबल है:
| सुविधाएं | लेबल | ||
|---|---|---|---|
| तापमान | नमी | दबाव | टेस्ट के स्कोर |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
लेबल से अलग करें.
फ़ीचर क्रॉस
"क्रॉसिंग" कैटगरिकल या बकेट की गई सुविधाओं की मदद से बनाई गई सिंथेटिक सुविधा.
उदाहरण के लिए, "मूड का पूर्वानुमान" वाले मॉडल पर विचार करें, जो यहां दिए गए चार बकेट में से किसी एक में तापमान को दिखाता है:
freezingchillytemperatewarm
और यहां दी गई तीन बकेट में से किसी एक में हवा की रफ़्तार का पता लगाता है:
stilllightwindy
फ़ीचर क्रॉस के बिना, लीनियर मॉडल, पहले के सात अलग-अलग बकेट में से हर एक पर
अलग-अलग ट्रेनिंग लेता है. उदाहरण के लिए, मॉडल freezing को ट्रेनिंग देता है, लेकिन ट्रेनिंग नहीं देता, जैसे कि windy.
इसके अलावा, आपके पास तापमान और हवा की रफ़्तार का एक फ़ीचर क्रॉस बनाने का भी विकल्प है. इस सिंथेटिक सुविधा की ये 12 संभावित वैल्यू हो सकती हैं:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
क्रॉस फ़ीचर की मदद से मॉडल, freezing-windy दिन से freezing-still दिन के बीच के मूड के अंतर को समझ पाता है.
अगर दो सुविधाओं से कोई ऐसा सिंथेटिक फ़ीचर बनाया जाता है जिसमें हर सुविधा में अलग-अलग बकेट हैं, तो इससे बने फ़ीचर क्रॉस के कई संभावित कॉम्बिनेशन होंगे. उदाहरण के लिए, अगर एक सुविधा में 1,000 बकेट हैं और दूसरी सुविधा में 2,000 बकेट हैं, तो इससे बने फ़ीचर क्रॉस में 20,00,000 बकेट होंगे.
आम तौर पर, क्रॉस एक कार्टीज़न प्रॉडक्ट होता है.
फ़ीचर क्रॉस का इस्तेमाल ज़्यादातर लीनियर मॉडल के साथ किया जाता है और न्यूरल नेटवर्क के साथ कभी-कभार ही इसका इस्तेमाल किया जाता है.
फ़ीचर इंजीनियरिंग
इस प्रोसेस में, ये चरण शामिल होते हैं:
- यह तय करना कि मॉडल को ट्रेनिंग देने के लिए कौनसी सुविधाएं मददगार साबित हो सकती हैं.
- डेटासेट से रॉ डेटा को उन सुविधाओं के बेहतर वर्शन में बदलना.
उदाहरण के लिए, आपके पास यह तय करने का विकल्प है कि temperature आपके काम की सुविधा हो सकती है. इसके बाद, बकेटिंग का इस्तेमाल करके यह ऑप्टिमाइज़ किया जा सकता है कि मॉडल, अलग-अलग temperature रेंज से क्या सीख सकता है.
फ़ीचर इंजीनियरिंग को कभी-कभी फ़ीचर एक्सट्रैक्शन या फ़ीचराइज़ेशन कहा जाता है.
फ़ीचर एक्सट्रैक्शन
ओवरलोडेड टर्म की इनमें से कोई एक परिभाषाएं:
- बिना निगरानी वाले या पहले से ट्रेन किए गए मॉडल (उदाहरण के लिए, न्यूरल नेटवर्क में छिपी हुई लेयर की वैल्यू) की मदद से, किसी अन्य मॉडल में इनपुट के तौर पर इस्तेमाल करने के लिए, इंटरमीडिएट फ़ीचर रिप्रज़ेंटेशन को हासिल करना.
- फ़ीचर इंजीनियरिंग का समानार्थी शब्द.
किसी सुविधा की अहमियत
वैरिएबल की अहमियत के लिए समानार्थी शब्द.
सुविधाओं का सेट
उन सुविधाओं का ग्रुप जिनके आधार पर आपका मशीन लर्निंग मॉडल ट्रेनिंग देता है. उदाहरण के लिए, पिन कोड, प्रॉपर्टी का साइज़, और प्रॉपर्टी की स्थिति, ऐसे मॉडल के लिए आसान सुविधाओं के सेट का इस्तेमाल कर सकती है जो मकान की कीमतों का अनुमान लगाता है.
सुविधा की खास जानकारी
यह tf.Example प्रोटोकॉल बफ़र से सुविधाओं का डेटा एक्सट्रैक्ट करने के लिए ज़रूरी जानकारी बताता है. tf.Example प्रोटोकॉल बफ़र, डेटा का कंटेनर भर होता है, इसलिए आपको ये चीज़ें तय करनी होंगी:
- एक्सट्रैक्ट किया जाने वाला डेटा (यानी, सुविधाओं की कुंजियां)
- डेटा टाइप (उदाहरण के लिए, फ़्लोट या पूर्णांक)
- वीडियो की लंबाई (फ़िक्स्ड या वैरिएबल)
फ़ीचर वेक्टर
सुविधा की वैल्यू की कैटगरी में एक उदाहरण शामिल है. फ़ीचर वेक्टर, ट्रेनिंग और अनुमान के दौरान इनपुट किया जाता है. उदाहरण के लिए, दो अलग-अलग सुविधाओं वाले मॉडल के लिए फ़ीचर वेक्टर यह हो सकता है:
[0.92, 0.56]

हर उदाहरण, फ़ीचर वेक्टर के लिए अलग-अलग वैल्यू देता है. इसलिए, अगले उदाहरण के लिए फ़ीचर वेक्टर कुछ ऐसा हो सकता है:
[0.73, 0.49]
फ़ीचर इंजीनियरिंग यह तय करती है कि फ़ीचर वेक्टर में सुविधाएं कैसे दिखानी हैं. उदाहरण के लिए, पांच संभावित वैल्यू वाली बाइनरी कैटगरी वाली सुविधा को वन-हॉट एन्कोडिंग की मदद से दिखाया जा सकता है. इस मामले में, किसी खास उदाहरण के लिए फ़ीचर वेक्टर के हिस्से में, तीसरी पोज़िशन पर चार शून्य और एक 1.0 होगा, जैसा कि यहां बताया गया है:
[0.0, 0.0, 1.0, 0.0, 0.0]
एक अन्य उदाहरण के रूप में, मान लें कि आपके मॉडल में तीन सुविधाएं हैं:
- पांच संभावित वैल्यू वाली बाइनरी कैटगरी वाली सुविधा, जिसे एक-हॉट एन्कोडिंग की मदद से दिखाया जाता है. उदाहरण के लिए:
[0.0, 1.0, 0.0, 0.0, 0.0] - तीन संभावित वैल्यू वाली एक अन्य बाइनरी कैटगरी वाली सुविधा, जिसे वन-हॉट एन्कोडिंग के साथ दिखाया जाता है. उदाहरण के लिए:
[0.0, 0.0, 1.0] - कोई फ़्लोटिंग-पॉइंट सुविधा. उदाहरण के लिए:
8.3.
इस मामले में, हर उदाहरण के लिए फ़ीचर वेक्टर को नौ वैल्यू से दिखाया जाएगा. अगर पिछली सूची में वैल्यू के उदाहरण दिए गए हैं, तो फ़ीचर वेक्टर यह होगा:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
फ़ैचुराइज़ेशन
दस्तावेज़ या वीडियो जैसे इनपुट सोर्स से सुविधाएं निकालने और उन सुविधाओं को फ़ीचर वेक्टर में मैप करने की प्रोसेस.
एमएल (मशीन लर्निंग) के कुछ विशेषज्ञ, फ़ीचर इंजीनियरिंग या फ़ीचर एक्सट्रैक्शन के समानार्थी सुविधा के तौर पर सुविधा का इस्तेमाल करते हैं.
फ़ेडरेटेड लर्निंग
यह डिस्ट्रिब्यूटेड मशीन लर्निंग का एक तरीका है, जो स्मार्टफ़ोन जैसे डिवाइसों पर रहने वाले डीसेंट्रलाइज़्ड उदाहरण का इस्तेमाल करके, मशीन लर्निंग मॉडल को ट्रेन करता है. फ़ेडरेटेड लर्निंग में, डिवाइसों का एक सबसेट सेंट्रल कोऑर्डिनिंग सर्वर से मौजूदा मॉडल को डाउनलोड करता है. डिवाइस, मॉडल को बेहतर बनाने के लिए डिवाइस पर सेव किए गए उदाहरणों का इस्तेमाल करते हैं. इसके बाद डिवाइस, कोऑर्डिनेट करने वाले सर्वर पर मॉडल में किए गए सुधार (लेकिन ट्रेनिंग के उदाहरण नहीं) अपलोड करते हैं, जहां उन्हें दूसरे अपडेट के साथ एग्रीगेट किया जाता है, ताकि एक बेहतर वैश्विक मॉडल बनाया जा सके. एग्रीगेशन के बाद, डिवाइसों से कंप्यूट किए गए मॉडल अपडेट की ज़रूरत नहीं रहती और उन्हें खारिज किया जा सकता है.
ट्रेनिंग के उदाहरण कभी अपलोड नहीं किए जाते. इसलिए, फ़ेडरेटेड लर्निंग, डेटा इकट्ठा करने और डेटा इकट्ठा करने पर प्रतिबंध लगाने के निजता सिद्धांतों का पालन करती है.
फ़ेडरेटेड लर्निंग के बारे में ज़्यादा जानकारी के लिए, यह ट्यूटोरियल देखें.
फ़ीडबैक लूप
मशीन लर्निंग में, ऐसी स्थिति जिसमें मॉडल के अनुमान से उसी मॉडल या दूसरे मॉडल के ट्रेनिंग डेटा पर असर पड़ता है. उदाहरण के लिए, फ़िल्मों का सुझाव देने वाला मॉडल, लोगों को दिखने वाली फ़िल्मों पर असर डालेगा. इसके बाद, फ़िल्मों के सुझाव देने वाले बाद के मॉडल पर इसका असर पड़ेगा.
फ़ीडफ़ॉरवर्ड न्यूरल नेटवर्क (FFN)
ऐसा न्यूरल नेटवर्क जिसमें साइक्लिक या बार-बार होने वाले कनेक्शन नहीं होते. उदाहरण के लिए, ट्रेडिशनल डीप न्यूरल नेटवर्क फ़ीडफ़ॉरवर्ड न्यूरल नेटवर्क होते हैं. बार-बार होने वाले न्यूरल नेटवर्क से कंट्रास्ट अलग करें. ये नेटवर्क साइक्लिकल होते हैं.
कुछ समय के लिए वीडियो बनाना
एक मशीन लर्निंग अप्रोच, जिसका इस्तेमाल अक्सर ऑब्जेक्ट क्लासिफ़िकेशन के लिए किया जाता है. इसे ट्रेनिंग के कुछ ही उदाहरणों से, असरदार क्लासिफ़ायर को ट्रेनिंग देने के लिए डिज़ाइन किया जाता है.
वन-शॉट लर्निंग और ज़ीरो-शॉट लर्निंग के बारे में भी जानें.
कुछ शॉट के साथ प्रॉम्प्ट देना
ऐसा प्रॉम्प्ट जिसमें एक से ज़्यादा ("कुछ" उदाहरण) शामिल हों. इससे पता चलता है कि बड़े लैंग्वेज मॉडल का जवाब कैसे देना चाहिए. उदाहरण के लिए, नीचे दिए गए लंबे प्रॉम्प्ट में दो ऐसे उदाहरण शामिल हैं जिसमें किसी क्वेरी का जवाब देने का एक बड़ा लैंग्वेज मॉडल दिखाया गया है.
| एक प्रॉम्प्ट के हिस्से | ज़रूरी जानकारी |
|---|---|
| किसी चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब एलएलएम से देना है. |
| फ़्रांस: EUR | एक उदाहरण. |
| यूनाइटेड किंगडम: GBP | एक और उदाहरण. |
| भारत: | असल क्वेरी. |
आम तौर पर, वन-शॉट प्रॉम्प्ट और वन-शॉट प्रॉम्प्ट के मुकाबले, कुछ ही शॉट में प्रॉम्प्ट दिखाने से बेहतर नतीजे मिलते हैं. हालांकि, कुछ शॉट में प्रॉम्प्ट दिखाने के लिए, लंबे प्रॉम्प्ट की ज़रूरत होती है.
कुछ शॉट के लिए प्रॉम्प्ट देने की सुविधा, कुछ शॉट से सीखें है. यह प्रॉम्प्ट आधारित लर्निंग में इस्तेमाल किया जाता है.
वायलिन
Python-फ़र्स्ट कॉन्फ़िगरेशन वाली कॉन्फ़िगरेशन लाइब्रेरी, जो इनवेसिव कोड या इन्फ़्रास्ट्रक्चर के बिना फ़ंक्शन और क्लास की वैल्यू सेट करती है. Pax और अन्य एमएल कोडबेस के मामले में, ये फ़ंक्शन और क्लास मॉडल और ट्रेनिंग हाइपर पैरामीटर दिखाते हैं.
Fiddle यह मानता है कि मशीन लर्निंग कोड बेस आम तौर पर इन हिस्सों में बंटे होते हैं:
- लाइब्रेरी कोड, जो लेयर और ऑप्टिमाइज़र के बारे में बताता है.
- डेटासेट "glue" कोड, जो लाइब्रेरी और वायर को एक साथ कॉल करता है.
Fiddle, ग्लू कोड के कॉल स्ट्रक्चर को बिना आकलन वाले और बदले जा सकने वाले फ़ॉर्म में कैप्चर करता है.
फ़ाइन ट्यूनिंग
पहले से ट्रेन किए गए मॉडल पर, टास्क के लिए खास तौर पर बनाए गए ट्रेनिंग पास का इस्तेमाल किया जाता है, ताकि किसी खास इस्तेमाल के उदाहरण के लिए उसके पैरामीटर को बेहतर बनाया जा सके. उदाहरण के लिए, कुछ बड़े लैंग्वेज मॉडल के लिए पूरी ट्रेनिंग का क्रम यहां दिया गया है:
- प्री-ट्रेनिंग: किसी बड़े सामान्य डेटासेट की मदद से, किसी बड़े लैंग्वेज मॉडल को ट्रेनिंग दें. जैसे, अंग्रेज़ी भाषा के सभी Wikipedia पेजों की मदद से.
- फ़ाइन-ट्यूनिंग: पहले से ट्रेन किए गए मॉडल को कोई खास टास्क करने के लिए ट्रेनिंग दें, जैसे कि स्वास्थ्य से जुड़ी क्वेरी का जवाब देना. आम तौर पर, फ़ाइन ट्यूनिंग में किसी टास्क पर फ़ोकस करने वाले सैकड़ों या हज़ारों उदाहरण शामिल होते हैं.
दूसरे उदाहरण के तौर पर, एक बड़े इमेज मॉडल के लिए पूरी ट्रेनिंग का क्रम इस तरह है:
- प्री-ट्रेनिंग: एक बड़े सामान्य इमेज डेटासेट की मदद से, एक बड़े इमेज मॉडल को ट्रेनिंग दें. जैसे, Wikimedia Commons की सभी इमेज.
- फ़ाइन-ट्यूनिंग: पहले से ट्रेन किए गए मॉडल को कोई खास काम करने के लिए ट्रेनिंग दें, जैसे कि ओर्का की इमेज जनरेट करना.
ऐसेट को बेहतर बनाने के लिए, यहां दी गई रणनीतियों का कोई भी कॉम्बिनेशन इस्तेमाल किया जा सकता है:
- पहले से ट्रेन किए गए मॉडल के सभी मौजूदा पैरामीटर में बदलाव करना. इसे कभी-कभी फ़ुल फ़ाइन ट्यूनिंग भी कहा जाता है.
- पहले से ट्रेन किए गए मॉडल के मौजूदा पैरामीटर में से सिर्फ़ कुछ में बदलाव करना (आम तौर पर, आउटपुट लेयर की सबसे करीब की लेयर). हालांकि, अन्य मौजूदा पैरामीटर में कोई बदलाव नहीं करना पड़ता (आम तौर पर, इनपुट लेयर से जुड़ी लेयर. पैरामीटर की बेहतर ट्यूनिंग देखें.
- आम तौर पर, आउटपुट लेयर के सबसे करीब मौजूद लेयर के ऊपर ज़्यादा लेयर जोड़ना.
फ़ाइन ट्यूनिंग, ट्रांसफ़र लर्निंग का एक तरीका है. इसलिए, फ़ाइन ट्यूनिंग में किसी और लॉस फ़ंक्शन या मॉडल टाइप का इस्तेमाल किया जा सकता है, जो पहले से ट्रेन किए गए मॉडल को ट्रेनिंग देने वाले मॉडल टाइप से अलग होता है. उदाहरण के लिए, पहले से ट्रेन किए गए बड़े इमेज मॉडल को बेहतर बनाकर ऐसा रिग्रेशन मॉडल बनाया जा सकता है जो इनपुट इमेज में पक्षियों की संख्या दिखाता है.
फ़ाइन-ट्यूनिंग की तुलना, नीचे दिए गए शब्दों से करें:
फ़्लैक्स
JAX के आधार पर बनाई गई, डीप लर्निंग के लिए अच्छी परफ़ॉर्मेंस वाली ओपन सोर्स लाइब्रेरी. Flax, ट्रेनिंग न्यूरल नेटवर्क के लिए फ़ंक्शन देता है. साथ ही, यह उनकी परफ़ॉर्मेंस का आकलन करने के तरीके भी उपलब्ध कराता है.
फ़्लैक्सफ़ॉर्मर
यह ओपन सोर्स Transformer लाइब्रेरी है. इसे Flax पर बनाया गया है. इसे खास तौर पर, नैचुरल लैंग्वेज प्रोसेसिंग और मल्टीमोडल रिसर्च के लिए डिज़ाइन किया गया है.
गेट भूल जाओ
लंबे समय तक चलने वाली मेमोरी सेल का हिस्सा, जो सेल में होने वाली जानकारी के फ़्लो को कंट्रोल करता है. सेल की स्थिति से जुड़ी जानकारी हटाकर, दोनों फाटकों को संदर्भ के तौर पर रखने की ज़रूरत नहीं है.
फ़ुल सॉफ़्टमैक्स
softmax का समानार्थी शब्द.
उम्मीदवार के लिए सैंपलिंग से तुलना करें.
पूरी तरह से कनेक्ट की गई लेयर
छिपी हुई लेयर, जिसमें हर नोड अगली छिपी हुई लेयर के हर नोड से जुड़ा होता है.
पूरी तरह से कनेक्ट की गई लेयर को सघन लेयर भी कहा जाता है.
फ़ंक्शन ट्रांसफ़ॉर्मेशन
ऐसा फ़ंक्शन जो इनपुट के तौर पर फ़ंक्शन को लेता है और बदले गए फ़ंक्शन को आउटपुट के तौर पर दिखाता है. JAX, फ़ंक्शन ट्रांसफ़ॉर्मेशन का इस्तेमाल करता है.
G
जीएएन
जनरेटिव ऐडवर्सल नेटवर्क का शॉर्ट फ़ॉर्म.
सामान्यीकरण
मॉडल की, पहले न देखे गए नए डेटा पर सही अनुमान लगाने की सुविधा. जिस मॉडल को सामान्य बनाया जा सकता है वह ओवरफ़िटिंग वाले मॉडल से उलट होता है.
सामान्यीकरण कर्व
दोहरावों की संख्या के फ़ंक्शन के तौर पर, ट्रेनिंग में कमी और पुष्टि में कमी, दोनों का एक प्लॉट.
सामान्यीकरण कर्व की मदद से संभावित ओवरफ़िटिंग का पता लगाया जा सकता है. उदाहरण के लिए, नीचे दिया गया सामान्यीकरण कर्व, ओवरफ़िटिंग का सुझाव देता है. ऐसा इसलिए, क्योंकि पुष्टि न होने की वजह, ट्रेनिंग में नुकसान की तुलना में काफ़ी ज़्यादा हो जाती है.

सामान्य लीनियर मॉडल
गॉसियन नॉइज़ पर आधारित लीस्ट स्क्वेयर रिग्रेशन वाले मॉडल और अन्य तरह के शोर, जैसे कि पॉइसन नॉइज़ या कैटगरी वाले नॉइज़ के आधार पर अन्य तरह के मॉडल का सामान्यीकरण. सामान्य लीनियर मॉडल के उदाहरणों में ये शामिल हैं:
- लॉजिस्टिक रिग्रेशन
- मल्टी-क्लास रिग्रेशन
- कम से कम स्क्वेयर रिग्रेशन
सामान्य लीनियर मॉडल के पैरामीटर, कन्वर्ज़न वाले ऑप्टिमाइज़ेशन की मदद से ढूंढे जा सकते हैं.
सामान्य लीनियर मॉडल में ये प्रॉपर्टी दिखती हैं:
- सबसे कम स्क्वेयर वाले रिग्रेशन मॉडल का औसत अनुमान, ट्रेनिंग डेटा पर दिए गए औसत लेबल के बराबर होता है.
- इष्टतम लॉजिस्टिक रिग्रेशन मॉडल के ज़रिए अनुमानित औसत संभावना, ट्रेनिंग डेटा पर मौजूद औसत लेबल के बराबर होती है.
सामान्य लीनियर मॉडल की क्षमता, इसकी सुविधाओं के हिसाब से सीमित होती है. डीप मॉडल के उलट, सामान्य लीनियर मॉडल "नई सुविधाओं को नहीं सीख सकता" हो सकता है.
जनरेटिव ऐडवर्सल नेटवर्क (GAN)
नया डेटा बनाने वाला सिस्टम, जिसमें जनरेटर डेटा बनाता है और विविक्त करने वाला पता लगाता है कि बनाया गया डेटा मान्य है या अमान्य.
जनरेटिव एआई
बदलाव लाने वाला उभरता हुआ फ़ील्ड, जिसकी कोई औपचारिक परिभाषा नहीं है. हालांकि, ज़्यादातर विशेषज्ञ इस बात से सहमत हैं कि जनरेटिव एआई मॉडल ऐसा कॉन्टेंट बना ("जनरेट") कर सकते हैं जिसमें ये चीज़ें शामिल हों:
- जटिल
- आसानी से समझ में आने वाला
- मूल
उदाहरण के लिए, जनरेटिव एआई मॉडल की मदद से बेहतरीन निबंध या इमेज बनाई जा सकती हैं.
एलएसटीएम और आरएनएन जैसी कुछ पुरानी टेक्नोलॉजी भी ओरिजनल और आसान कॉन्टेंट जनरेट कर सकती हैं. कुछ विशेषज्ञों का मानना है कि ये पुरानी टेक्नोलॉजी जनरेटिव एआई हैं. वहीं कुछ को लगता है कि पिछली टेक्नोलॉजी की तुलना में, सही जनरेटिव एआई के लिए ज़्यादा मुश्किल आउटपुट की ज़रूरत होती है.
अनुमानित ML में अंतर करें.
जनरेटिव मॉडल
व्यावहारिक तौर पर, एक मॉडल जो इनमें से कोई एक काम करता है:
- ट्रेनिंग डेटासेट से नए उदाहरण बनाता है (जनरेट करता है). उदाहरण के लिए, कविताओं के एक डेटासेट की ट्रेनिंग देने के बाद, जनरेटिव मॉडल कविताएं बना सकता है. जनरेटिव एडवरसिरियल नेटवर्क का एक हिस्सा जनरेटर इस कैटगरी में आता है.
- इससे इस बात की संभावना तय की जाती है कि नया उदाहरण, ट्रेनिंग सेट से आया है या उसी तरीके से बनाया गया है जिससे ट्रेनिंग सेट बनाया गया था. उदाहरण के लिए, अंग्रेज़ी वाक्यों वाले डेटासेट की ट्रेनिंग के बाद, जनरेटिव मॉडल इस बात की संभावना तय कर सकता है कि नया इनपुट, अंग्रेज़ी का एक मान्य वाक्य है.
जनरेटिव मॉडल, डेटासेट में उदाहरणों या खास सुविधाओं के डिस्ट्रिब्यूशन को सैद्धांतिक तौर पर देख सकता है. यानी:
p(examples)
अनसुपरवाइज़्ड लर्निंग मॉडल जनरेटिव होते हैं.
भेदभाव वाले मॉडल से कंट्रास्ट अलग करें.
जेनरेटर
जनरेटिव ऐडवर्सल नेटवर्क का एक सबसिस्टम, जो नए उदाहरण बनाता है.
भेदभाव वाले मॉडल से कंट्रास्ट अलग करें.
जिनी इंप्यूरिटी
एंट्रॉपी से मिलती-जुलती मेट्रिक. स्प्लिटर डिसिज़न ट्री की कैटगरी तय करने के लिए, शर्तों को कंपोज़ करने के लिए, जिनी इंपरिटी या एंट्रॉपी से मिली वैल्यू का इस्तेमाल करते हैं. जानकारी पाने का तरीका एंट्रॉपी से लिया जाता है. जिनी इंप्योरिटी से बनाई गई मेट्रिक के लिए ऐसा कोई शब्द नहीं है जिसे दुनिया भर में स्वीकार किया जाता हो; हालांकि, यह बिना नाम वाली मेट्रिक भी जानकारी हासिल करने जितनी ही ज़रूरी है.
जिनी इंपरिटी को गिनी इंडेक्स या साधारण भाषा में गिनी भी कहा जाता है.
गोल्डन डेटासेट
मैन्युअल तरीके से चुने गए डेटा का सेट, जो ज़मीनी हकीकत को कैप्चर करता है. टीमें किसी मॉडल की क्वालिटी का आकलन करने के लिए, एक या उससे ज़्यादा गोल्डन डेटासेट का इस्तेमाल कर सकती हैं.
कुछ गोल्डन डेटासेट, ज़मीनी हकीकत के अलग-अलग सबडोमेन को कैप्चर करते हैं. उदाहरण के लिए, इमेज क्लासिफ़िकेशन के लिए एक गोल्डन डेटासेट, रोशनी की स्थितियों और इमेज रिज़ॉल्यूशन को कैप्चर कर सकता है.
GPT (जनरेटिव प्री-ट्रेन्ड ट्रांसफ़ॉर्मर)
Transformer पर आधारित बड़े लैंग्वेज मॉडल का एक फ़ैमिली ग्रुप, जिसे OpenAI ने बनाया है.
GPT के वैरिएंट कई मॉडलिंग पर लागू किए जा सकते हैं. इनमें ये शामिल हैं:
- इमेज जनरेट करना (उदाहरण के लिए, ImageGPT)
- टेक्स्ट-टू-इमेज जनरेट करना (उदाहरण के लिए, DALL-E).
ग्रेडिएंट
सभी इंडिपेंडेंट वैरिएबल के हिसाब से पार्शियल डेरिवेटिव का वेक्टर. मशीन लर्निंग में, ग्रेडिएंट, मॉडल फ़ंक्शन के पार्शियल डेरिवेटिव का वेक्टर होता है. सबसे खड़ी चढ़ाई की दिशा में ग्रेडिएंट पॉइंट.
ग्रेडिएंट अक्यूम्युलेशन
यह एक बैकप्रोपगेशन तकनीक है, जो पैरामीटर को एक बार दोहराने के बजाय, हर Epoch के लिए सिर्फ़ एक बार अपडेट करती है. हर मिनी-बैच को प्रोसेस करने के बाद, ग्रेडिएंट अक्यूमेशन बस कुल ग्रेडिएंट को अपडेट करता है. फिर, Epoch में आखिरी मिनी-बैच को प्रोसेस करने के बाद, सिस्टम सभी ग्रेडिएंट बदलावों के कुल योग के आधार पर पैरामीटर अपडेट करता है.
ग्रेडिएंट संग्रह तब फ़ायदेमंद होता है, जब ट्रेनिंग के लिए उपलब्ध मेमोरी के मुकाबले बैच का साइज़ बहुत ज़्यादा हो. जब मेमोरी में कोई समस्या होती है, तो अक्सर बैच का साइज़ कम कर दिया जाता है. हालांकि, सामान्य बैक-प्रॉपगेशन में बैच का साइज़ कम करने से, पैरामीटर में होने वाले अपडेट की संख्या बढ़ जाती है. ग्रेडिएंट अक्यूमेशन, मॉडल को मेमोरी की समस्याओं से बचने में मदद करता है, लेकिन यह अब भी बेहतर तरीके से ट्रेनिंग लेता है.
ग्रेडिएंट बूस्टेड (डिसिज़न) ट्री (GBT)
एक तरह का फ़ैसले फ़ॉरेस्ट, जिसमें:
- ट्रेनिंग, ग्रेडिएंट बूस्टिंग पर निर्भर करती है.
- कमज़ोर मॉडल, डिसिज़न ट्री है.
ग्रेडिएंट बूस्टिंग
एक ट्रेनिंग एल्गोरिदम, जिसमें कमज़ोर मॉडल को बार-बार ट्रेनिंग देने के लिए ट्रेनिंग दी जाती है. इससे मज़बूत मॉडल की क्वालिटी को सुधारा जा सकता है (नुकसान को कम किया जा सकता है). उदाहरण के लिए, कमज़ोर मॉडल, लीनियर या छोटा डिसिज़न ट्री मॉडल हो सकता है. मज़बूत मॉडल, पहले ट्रेन किए गए सभी कमज़ोर मॉडल का योग बन जाता है.
ग्रेडिएंट बूस्टिंग के सबसे आसान रूप में, हर बार इटरेशन के दौरान एक कमज़ोर मॉडल को ट्रेनिंग दी जाती है, ताकि वह मज़बूत मॉडल के लॉस ग्रेडिएंट का अनुमान लगा सके. इसके बाद, स्ट्रॉन्ग मॉडल का आउटपुट, अनुमानित ग्रेडिएंट को घटाकर अपडेट किया जाता है. यह ग्रेडिएंट डिसेंट की तरह ही होता है.
कहां:
- $F_{0}$ शुरुआती मज़बूत मॉडल है.
- $F_{i+1}$ दूसरा मज़बूत मॉडल है.
- $F_{i}$ फ़िलहाल एक मज़बूत मॉडल है.
- $\xi$, 0.0 और 1.0 के बीच की कोई वैल्यू है. इसे shrinkage कहा जाता है. इसकी वैल्यू, ग्रेडिएंट ढलान में लर्निंग रेट के बराबर होती है.
- $f_{i}$ एक कमज़ोर मॉडल है, जिसे $F_{i}$ के लॉस ग्रेडिएंट का अनुमान लगाने के लिए ट्रेन किया गया है.
ग्रेडिएंट बूस्टिंग की आधुनिक विविधताओं में उनकी गणना में लॉस का सेकंड डेरिवेटिव (हेसियन) भी शामिल है.
डिसिज़न ट्री का इस्तेमाल आम तौर पर, ग्रेडिएंट बूस्टिंग में कमज़ोर मॉडल के तौर पर किया जाता है. ग्रेडिएंट बूस्टेड (डिसिज़न) ट्री देखें.
ग्रेडिएंट क्लिपिंग
आम तौर पर, इस्तेमाल किया जाने वाला तरीका, किसी मॉडल को ग्रेडिएंट डिसेंट को ट्रेन करने के दौरान, ग्रेडिएंट की ज़्यादा से ज़्यादा वैल्यू को आर्टिफ़िशियल तरीके से सीमित (क्लिप करके) करके, विस्फोटक वाले ग्रेडिएंट की समस्या को कम करने का एक तरीका है.
ग्रेडिएंट डिसेंट
लॉस को कम करने के लिए, गणित की तकनीक. धीरे-धीरे घटता क्रम में, वेट और पूर्वाग्रह को अडजस्ट करता है. इसके बाद, नुकसान को कम करने के लिए, सबसे सही कॉम्बिनेशन ढूंढता है.
ग्रेडिएंट ढलान पुराना है—जो मशीन लर्निंग की तुलना में बहुत पुराना है.
ग्राफ़
TensorFlow में, एक कंप्यूटेशन स्पेसिफ़िकेशन है. ग्राफ़ में मौजूद नोड, संक्रियाओं को दिखाते हैं. किनारों को निर्देशित किया जाता है और ये किसी कार्रवाई (टेन्सर) के नतीजे को दूसरे ऑपरेशन के ऑपरेशन के रूप में पास करते हैं. ग्राफ़ को विज़ुअलाइज़ करने के लिए, TensorBoard का इस्तेमाल करें.
ग्राफ़ एक्ज़ीक्यूशन
ऐसा TensorFlow प्रोग्रामिंग एनवायरमेंट है जिसमें प्रोग्राम पहले एक ग्राफ़ बनाता है और फिर उस ग्राफ़ का पूरा या कुछ हिस्सा एक्ज़ीक्यूट करता है. ग्राफ़ एक्ज़ीक्यूशन, TensorFlow 1.x में डिफ़ॉल्ट एक्ज़ीक्यूशन मोड है.
eager का इस्तेमाल करने की सुविधा अलग-अलग हो.
लालची नीति
रीइन्फ़ोर्समेंट लर्निंग में, एक ऐसी नीति जो हमेशा ऐसी कार्रवाई चुनती है जिसकी रिटर्न की उम्मीद सबसे ज़्यादा हो.
ज़मीनी हकीकत
हकीकत.
यह असल में हुआ था.
उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल का इस्तेमाल करें. इससे यह अनुमान लगाया जा सकता है कि यूनिवर्सिटी में पढ़ने वाला कोई छात्र छह साल के अंदर ग्रैजुएशन करेगा या नहीं. इस मॉडल की वास्तविक सच्चाई यह है कि उस छात्र/छात्रा ने असल में छह साल के अंदर ग्रैजुएट हुआ या नहीं.
ग्रुप एट्रिब्यूशन बायस
यह मानकर कि किसी व्यक्ति पर जो भी सही है वह उस ग्रुप में शामिल सभी लोगों के लिए भी सही है. डेटा कलेक्शन के लिए सुविधा सैंपल का इस्तेमाल करने पर, ग्रुप एट्रिब्यूशन से जुड़े भेदभाव का असर बढ़ सकता है. प्रतिनिधित्व न करने वाले नमूने में, ऐसे एट्रिब्यूशन बनाए जा सकते हैं जो वास्तविकता से परे होते हैं.
ग्रुप में एक ही अंतर से जुड़े बायस और इन-ग्रुप बायस भी देखें.
H
गलत जानकारी
जनरेटिव एआई मॉडल का इस्तेमाल करके, भरोसेमंद लगने वाले, लेकिन तथ्यों के हिसाब से गलत आउटपुट जनरेट करना. ऐसा करने का मकसद, असल दुनिया के बारे में प्रामाणिकता ज़ाहिर करना होता है. उदाहरण के लिए, एक जनरेटिव एआई मॉडल है जिसमें दावा किया गया है कि 1865 में बराक ओबामा की मौत हो गई थी. यह मॉडल गलत जानकारी दे रहा है.
हैशिंग
मशीन लर्निंग में, कैटगरिकल डेटा को बकेट करने का एक तरीका है. खास तौर पर तब, जब कैटगरी की संख्या बड़ी हो, लेकिन डेटासेट में दिखने वाली कैटगरी की संख्या, बाकी डेटा की तुलना में कम हो.
उदाहरण के लिए, पृथ्वी पर पेड़ों की करीब 73,000 प्रजातियां हैं. पेड़ों की 73,000 प्रजातियों में से हर को 73,000 अलग-अलग कैटगरी के बकेट में दिखाया जा सकता है. इसके अलावा, अगर डेटासेट में पेड़ों की सिर्फ़ 200 प्रजातियां दिखती हैं, तो आप पेड़ों की प्रजातियों को करीब 500 बकेट में बांटने के लिए हैशिंग का इस्तेमाल कर सकते हैं.
एक बकेट में पेड़ों की कई प्रजातियां हो सकती हैं. उदाहरण के लिए, हैशिंग की मदद से बाओबैब और रेड मेपल को एक ही बकेट में रखा जा सकता है. आनुवंशिक रूप से अलग-अलग प्रजाति हैं. इसके बावजूद, हैशिंग अब भी बड़े कैटगरी वाले सेट को चुनी गई संख्या की बकेट में मैप करने का एक अच्छा तरीका है. हैशिंग, संभावित वैल्यू वाली किसी कैटगरी वाली सुविधा को तय करने के हिसाब से ग्रुप में बांटती है और वैल्यू को बहुत कम संख्या में बदल देती है.
अनुभव
किसी समस्या का आसान और तुरंत लागू किया गया समाधान. उदाहरण के लिए, "हमने 86% सटीक अनुमान लगाया है. जब हमने डीप न्यूरल नेटवर्क पर स्विच किया, तो यह 98% तक सटीक हो गया."
छिपी हुई लेयर
इनपुट लेयर (सुविधाओं) और आउटपुट लेयर (अनुमान) के बीच न्यूरल नेटवर्क में मौजूद एक लेयर. हर छिपी हुई लेयर में एक या एक से ज़्यादा न्यूरॉन होते हैं. उदाहरण के लिए, नीचे दिए गए न्यूरल नेटवर्क में दो छिपी हुई लेयर हैं. पहली लेयर में तीन न्यूरॉन और दूसरे में दो न्यूरॉन हैं:

डीप न्यूरल नेटवर्क में एक से ज़्यादा छिपे हुए लेयर होते हैं. उदाहरण के लिए, ऊपर दिया गया उदाहरण एक डीप न्यूरल नेटवर्क है, क्योंकि मॉडल में दो छिपी हुई लेयर हैं.
हैरारकी के हिसाब से क्लस्टरिंग
क्लस्टरिंग एल्गोरिदम की कैटगरी, जो क्लस्टर का ट्री बनाती है. हैरारकीकल क्लस्टरिंग, हैरारकी वाले डेटा के हिसाब से पूरी तरह काम करती है, जैसे कि बोटैनिकल टेक्सॉनमी. हैरारकी वाले क्लस्टरिंग एल्गोरिदम दो तरह के होते हैं:
- एगलोमेरेटिव क्लस्टरिंग, सबसे पहले हर उदाहरण को अपने क्लस्टर में असाइन करता है. साथ ही, हैरारकी ट्री बनाने के लिए, सबसे नज़दीकी क्लस्टर को बार-बार मर्ज करता है.
- डाइविज़िव क्लस्टरिंग, पहले सभी उदाहरणों को एक क्लस्टर में बांटता है और फिर क्लस्टर को हैरारकी वाले ट्री में बांटता है.
सेंट्रोइड-आधारित क्लस्टरिंग से कंट्रास्ट अलग है.
हिंज लॉस
क्लासिफ़िकेशन के लिए लॉस फ़ंक्शन को इस तरह डिज़ाइन किया गया है कि ट्रेनिंग के हर उदाहरण से, फ़ैसले की सीमा एक-दूसरे से ज़्यादा से ज़्यादा दूर की जा सके. इससे, उदाहरणों और सीमाओं के बीच का अंतर ज़्यादा से ज़्यादा बढ़ाया जा सकता है. KSVM, हिंज लॉस (या इससे जुड़े फ़ंक्शन, जैसे कि स्क्वेयर हिंज लॉस) का इस्तेमाल करते हैं. बाइनरी क्लासिफ़िकेशन के लिए, हिंज लॉस फ़ंक्शन इस तरह परिभाषित किया गया है:
जहां y सही लेबल है, या तो -1 या +1 है और y' क्लासिफ़ायर मॉडल का रॉ आउटपुट है:
इस वजह से, कब्ज़ लॉस बनाम (y * y') का प्लॉट इस तरह दिखता है:

ऐतिहासिक भेदभाव
एक तरह का पूर्वाग्रह जो दुनिया में पहले से मौजूद है और जिसकी जगह डेटा डेटासेट बन गया है. ये पूर्वाग्रह मौजूदा सांस्कृतिक रूढ़िवादी सोच, उम्र, लिंग, आय, शिक्षा वगैरह के असमानताओं और कुछ सामाजिक समूहों के ख़िलाफ़ पूर्वाग्रहों की ओर इशारा करते हैं.
उदाहरण के लिए, किसी क्लासिफ़िकेशन मॉडल से यह अनुमान लगाया जा सकता है कि क़र्ज़ लेने वाला व्यक्ति, डिफ़ॉल्ट तौर पर क़र्ज़ ले पाएगा या नहीं. इस मॉडल को 1980 के दशक में, दो अलग-अलग कम्यूनिटी में स्थानीय बैंकों से लिए गए, क़र्ज़ के लिए डिफ़ॉल्ट तौर पर लागू होने वाले पुराने डेटा की मदद से ट्रेनिंग दी गई थी. अगर समुदाय A के पिछले आवेदकों की, समुदाय B के आवेदकों की तुलना में छह गुना ज़्यादा लोन लेने की संभावना थी, तो मॉडल ऐतिहासिक पक्षपात को समझ सकता है और इस वजह से इस मॉडल से समुदाय A में क़र्ज़ लेने की संभावना कम हो जाएगी. भले ही, ऐसी पुरानी स्थितियां जिनकी वजह से उस समुदाय की ज़्यादा डिफ़ॉल्ट दरें लागू न हों.
होल्डआउट डेटा
उदाहरण उन्हें ट्रेनिंग के दौरान जान-बूझकर इस्तेमाल न किया गया हो ("होल्ड किया गया"). पुष्टि करने वाले डेटासेट और टेस्ट डेटासेट, होल्डआउट डेटा के उदाहरण हैं. होल्डआउट डेटा से, आपके मॉडल की उस डेटा के अलावा सामान्य बनाने की क्षमता का आकलन करने में मदद मिलती है जिस पर उसे ट्रेनिंग दी गई थी. होल्डआउट सेट में होने वाले नुकसान का अनुमान, ट्रेनिंग सेट से हुए नुकसान की तुलना में अनदेखे डेटासेट पर होने वाले नुकसान का बेहतर अनुमान देता है.
होस्ट
एमएल मॉडल को ऐक्सेलरेटर चिप (जीपीयू या TPU) पर ट्रेनिंग देते समय, सिस्टम का वह हिस्सा जो इन दोनों को कंट्रोल करता है:
- कोड का पूरा फ़्लो.
- इनपुट पाइपलाइन का एक्सट्रैक्शन और ट्रांसफ़ॉर्मेशन.
आम तौर पर, होस्ट किसी सीपीयू पर चलता है, न कि एक्स्लेरेटर चिप पर. डिवाइस, एक्सीलेरेटर चिप पर टेंसर में बदलाव करता है.
हाइपर पैरामीटर
वे वैरिएबल जिन्हें आपने या हाइपर पैरामीटर ट्यूनिंग सेवा के लिए सेट किया गया है किसी मॉडल को लगातार चलाने के दौरान अडजस्ट किया जाता है. उदाहरण के लिए, लर्निंग रेट हाइपर पैरामीटर है. एक ट्रेनिंग सेशन से पहले, लर्निंग रेट को 0.01 पर सेट किया जा सकता है. अगर आपको लगता है कि 0.01 बहुत ज़्यादा है, तो शायद आप अगले ट्रेनिंग सेशन के लिए लर्निंग रेट को 0.003 पर सेट करें.
वहीं दूसरी ओर, पैरामीटर ऐसे अलग-अलग वेट और बायस हैं जिन्हें मॉडल, ट्रेनिंग के दौरान सीखता है.
हाइपरप्लेन
वह सीमा जो किसी स्पेस को दो सबस्पेस में अलग करती है. उदाहरण के लिए, लाइन दो डाइमेंशन में एक हाइपरप्लेन है और तीन डाइमेंशन में प्लेन हाइपरप्लेन. आम तौर पर, मशीन लर्निंग में हाइपरप्लेन वह सीमा होती है जो हाई-डाइमेंशन वाले स्पेस को अलग करती है. केर्नेल सपोर्ट वेक्टर मशीन, पॉज़िटिव क्लास को नेगेटिव क्लास से अलग करने के लिए हाइपरप्लेन का इस्तेमाल करती हैं. ऐसा अक्सर बहुत ज़्यादा डाइमेंशन वाली जगह में किया जाता है.
I
आई॰आई॰डी॰
स्वतंत्र रूप से और एक जैसे वितरित के लिए संक्षिप्त नाम.
इमेज पहचानने की सुविधा
ऐसी प्रोसेस जो किसी इमेज में ऑब्जेक्ट, पैटर्न या कॉन्सेप्ट की कैटगरी तय करती है. इमेज की पहचान करने की सुविधा को इमेज क्लासिफ़िकेशन भी कहा जाता है.
ज़्यादा जानकारी के लिए, ML Practicum: Image क्लासिफ़िकेशन में यह लेख पढ़ें.
असंतुलित डेटासेट
क्लास-असंतुलित डेटासेट के लिए समानार्थी.
अनजाने में भेदभाव करना
किसी व्यक्ति के दिमाग के मॉडल और यादों के आधार पर, अपने-आप जुड़ाव या अनुमान लगाना. अनजाने में होने वाले भेदभाव से इन चीज़ों पर असर पड़ सकता है:
- डेटा को इकट्ठा करने और उसे कैटगरी में बांटने का तरीका.
- मशीन लर्निंग सिस्टम को कैसे डिज़ाइन और डेवलप किया जाता है.
उदाहरण के लिए, शादी की फ़ोटो की पहचान करने के लिए क्लासिफ़ायर का इस्तेमाल करते समय, इंजीनियर फ़ोटो में सफ़ेद ड्रेस को फ़ीचर के तौर पर इस्तेमाल कर सकता है. हालांकि, कुछ ज़माने में और कुछ संस्कृतियों में, सफे़द ड्रेस का पारंपरिक तौर पर इस्तेमाल किया जाता है.
पुष्टि से जुड़े मापदंड भी देखें.
इंप्यूटेशन
वैल्यू इंप्यूटेशन का छोटा फ़ॉर्मैट.
निष्पक्षता मेट्रिक के साथ काम नहीं करता
यह विचार कि निष्पक्षता की कुछ धारणाएं पारस्परिक रूप से असंगत हैं और एक साथ पूरी नहीं की जा सकती. इसलिए, निष्पक्षता का आकलन करने के लिए ऐसी कोई एक मेट्रिक नहीं है जो मशीन लर्निंग के सभी सवालों पर लागू की जा सके.
भले ही, यह आपको अच्छा न लगे, लेकिन निष्पक्षता वाली मेट्रिक के साथ काम न करने का यह मतलब नहीं है कि निष्पक्षता की कोशिशें बेकार हैं. इसके बजाय, हमारा सुझाव है कि मशीन लर्निंग से जुड़ी किसी समस्या के लिए, निष्पक्षता को साफ़ तौर पर समझना चाहिए. इसका मकसद, इस्तेमाल के उदाहरणों से होने वाले नुकसान को रोकना है.
इस विषय पर ज़्यादा जानकारी पाने के लिए, "निष्पक्षता की संभावना (इम्प्रेशन) के बारे में जानकारी" देखें.
इन-कॉन्टेक्स्ट लर्निंग
कुछ शॉट प्रॉम्प्ट के लिए समानार्थी शब्द.
अलग-अलग और एक समान रूप से डिस्ट्रिब्यूट किए गए (i.i.d)
ऐसे डिस्ट्रिब्यूशन से लिया गया डेटा जिसमें बदलाव नहीं होता है और जहां हर वैल्यू पहले से ड्रॉ की गई वैल्यू पर निर्भर नहीं होती है. i.i.d, मशीन लर्निंग की आदर्श गैस है. यह गणित के हिसाब से एक उपयोगी डिज़ाइन है. हालांकि, असल दुनिया में इसे शायद कभी नहीं मिला. उदाहरण के लिए, कुछ समय के लिए किसी वेब पेज पर वेबसाइट पर आने वालों के डिस्ट्रिब्यूशन में बदलाव हो सकता है. इसका मतलब है कि इस छोटी विंडो में वेबसाइट पर आने वाले लोगों के डिस्ट्रिब्यूशन में कोई बदलाव नहीं होता और एक व्यक्ति की विज़िट, आम तौर पर दूसरे की विज़िट पर निर्भर नहीं होती. हालांकि, अगर उस समयावधि को बढ़ाया जाता है, तो वेब पेज पर आने वाले लोगों में सीज़न के हिसाब से अंतर दिख सकता है.
नॉनस्टेशनरिटी भी देखें.
व्यक्तिगत निष्पक्षता
यह एक फ़ेयरनेस मेट्रिक है, जो यह जांच करती है कि मिलते-जुलते लोगों को उसी तरह से बांटा गया है या नहीं. उदाहरण के लिए, हो सकता है कि Brobdingnagian Academy यह पक्का करके व्यक्तिगत निष्पक्षता को संतुष्ट करना चाहे कि एक जैसी ग्रेड और स्टैंडर्ड टेस्ट स्कोर वाले दो छात्र-छात्राओं को दाखिला लेने की संभावना बराबर हो.
ध्यान दें कि व्यक्तिगत निष्पक्षता पूरी तरह इस बात पर निर्भर करती है कि आपने "समानता" को कैसे परिभाषित किया है. इस मामले में, ग्रेड और टेस्ट के स्कोर इस आधार पर तय होते हैं कि अगर समानता से जुड़ी मेट्रिक में अहम जानकारी छूट जाती है (जैसे, छात्र-छात्राओं के पाठ्यक्रम की सख्ती), तो आपके लिए निष्पक्षता से जुड़े नए सवाल पैदा हो सकते हैं.
व्यक्तिगत निष्पक्षता के बारे में ज़्यादा जानने के लिए, "फ़ेयरनेस थ्रू जागरूकता" देखें.
अनुमान
मशीन लर्निंग में, बिना लेबल वाले उदाहरणों पर एक प्रशिक्षित मॉडल को लागू करके, अनुमान लगाने की प्रोसेस.
आंकड़ों में अनुमान का कुछ अलग मतलब होता है. ज़्यादा जानकारी के लिए, आंकड़ों के अनुमान पर Wikipedia का लेख देखें.
अनुमान का पाथ
डिसिज़न ट्री में, अनुमान के दौरान, कोई खास उदाहरण रूट, रूट से अन्य स्थिति पर ले जाता है, जो लीफ़ के साथ खत्म होता है. उदाहरण के लिए, नीचे दिए गए डिसिज़न ट्री में, थिकर ऐरो, इन फ़ीचर वैल्यू के साथ उदाहरण के तौर पर अनुमान पाथ दिखाते हैं:
- x = 7
- y = 12
- z = -3
इस इलस्ट्रेशन में दिया गया अनुमान पाथ, लीफ़ (Zeta) तक पहुंचने से पहले तीन स्थितियों से होकर गुज़रता है.

तीन मोटे ऐरो अनुमान का पाथ दिखाते हैं.
Google News Initiative
डिसिज़न फ़ॉरेस्ट में, नोड की एंट्रॉपी और वेटेड (उदाहरणों की संख्या के आधार पर) योग के चाइल्ड नोड की एंट्रॉपी के बीच का अंतर. नोड की एंट्रॉपी उस नोड में मौजूद उदाहरणों की एंट्रॉपी होती है.
उदाहरण के लिए, इन एंट्रॉपी वैल्यू पर विचार करें:
- पैरंट नोड की एन्ट्रॉपी = 0.6
- 16 काम के उदाहरणों वाले एक चाइल्ड नोड की एन्ट्रॉपी = 0.2
- 24 काम के उदाहरणों = 0.1 वाले किसी अन्य चाइल्ड नोड की एंट्रॉपी
इसलिए, 40% उदाहरण एक चाइल्ड नोड में और 60% दूसरे चाइल्ड नोड में होते हैं. इसलिए:
- चाइल्ड नोड का वेटेड एंट्रॉपी योग = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
इस तरह, मुझे यह जानकारी मिलती है:
- जानकारी गेन = पैरंट नोड की एंट्रॉपी - चाइल्ड नोड के वेटेड एंट्रॉपी का योग
- हासिल की गई जानकारी = 0.6 - 0.14 = 0.46
ज़्यादातर स्प्लिटर शर्तें बनाने की कोशिश करते हैं, ताकि ज़्यादा से ज़्यादा जानकारी मिल सके.
इन-ग्रुप बायस
किसी व्यक्ति के ग्रुप या अपनी विशेषताओं में पक्षपात दिखाना. अगर टेस्टर या रेटिंग देने वाले लोगों में मशीन लर्निंग डेवलपर के दोस्त, परिवार के सदस्य या आपके साथ काम करने वाले लोग शामिल हैं, तो इन-ग्रुप बायस की वजह से, प्रॉडक्ट टेस्टिंग या डेटासेट को अमान्य किया जा सकता है.
इन-ग्रुप बायस, एक तरह का ग्रुप एट्रिब्यूशन बायस है. ग्रुप से बाहर के लोगों के लिए एक ही तरीके से होने वाले भेदभाव की जानकारी भी देखें.
इनपुट जनरेटर
यह एक ऐसा तरीका है जिससे न्यूरल नेटवर्क में डेटा को लोड किया जाता है.
इनपुट जनरेटर को एक ऐसा कॉम्पोनेंट माना जाता है जो रॉ डेटा को टेंसर में प्रोसेस करता है. इन टेंसर को दोहराया जाता है, ताकि ट्रेनिंग, आकलन, और अनुमान के लिए बैच जनरेट किए जा सकें.
इनपुट लेयर
न्यूरल नेटवर्क की लेयर, जो फ़ीचर वेक्टर को दबाकर रखती है. इसका मतलब है कि इनपुट लेयर, ट्रेनिंग या अनुमान के लिए उदाहरण देता है. उदाहरण के लिए, नीचे दिए गए न्यूरल नेटवर्क की इनपुट लेयर में दो सुविधाएं हैं:

इन-सेट स्थिति
डिसिज़न ट्री में, एक स्थिति, जो आइटम के सेट में एक आइटम की मौजूदगी की जांच करती है. उदाहरण के लिए, यहां दी गई शर्त इन-सेट में है:
house-style in [tudor, colonial, cape]
अनुमान के दौरान, अगर हाउस-स्टाइल सुविधा की वैल्यू tudor, colonial या cape है, तो इस शर्त की वैल्यू के तौर पर 'हां' किया जाता है. अगर
हाउस-स्टाइल सुविधा की वैल्यू कुछ और है (उदाहरण के लिए, ranch),
तो इस शर्त की वैल्यू 'नहीं' होती है.
वन-हॉट कोड में बदली गई सुविधाओं को टेस्ट करने वाली कंडीशन के मुकाबले, इन-सेट स्थितियों में आम तौर पर ज़्यादा बेहतर डिसिज़न ट्री बनते हैं.
इंस्टेंस
example के लिए समानार्थी शब्द.
निर्देश ट्यूनिंग
फ़ाइन-ट्यूनिंग का एक तरीका, जो जनरेटिव एआई मॉडल को निर्देशों का पालन करने की क्षमता को बेहतर बनाता है. इंस्ट्रक्शन को ट्यून करने में, मॉडल को निर्देशों की एक सीरीज़ की ट्रेनिंग दी जाती है. आम तौर पर, इसमें कई तरह के टास्क शामिल होते हैं. इसके बाद, निर्देशों के हिसाब से तैयार किया गया मॉडल, कई तरह के ज़ीरो-शॉट प्रॉम्प्ट के लिए मददगार जवाब देता है.
इनकी तुलना और इनके साथ अंतर करना:
इंटरप्रेटेडेबिलिटी
किसी इंसान को मशीन लर्निंग के मॉडल की रीज़निंग के बारे में समझाने या दिखाने की सुविधा.
उदाहरण के लिए, ज़्यादातर लीनियर रिग्रेशन मॉडल को आसानी से समझा जा सकता है. (आपको हर सुविधा के लिए सिर्फ़ ट्रेन किए गए वज़न को देखना है.) डिसिज़न फ़ॉरेस्ट भी आसानी से समझे जा सकते हैं. हालांकि, कुछ मॉडल को समझने में आसान बनाने के लिए, आसान विज़ुअलाइज़ेशन की ज़रूरत होती है.
एमएल मॉडल को समझने के लिए, लर्निंग इंटरप्रिटेबिलिटी टूल (एलआईटी) का इस्तेमाल किया जा सकता है.
इंटर-रेटर एग्रीमेंट
इससे पता चलता है कि कोई टास्क करते समय, रेटिंग देने वाले लोग कितनी बार सहमत होते हैं. अगर रेटिंग देने वाले लोग सहमत नहीं हैं, तो टास्क के निर्देशों को बेहतर बनाने की ज़रूरत हो सकती है. इसे कभी-कभी इंटर-एनोटेटर कानूनी समझौता या इंटर-रेटर विश्वसनीयता भी कहा जाता है. कोहेन के कप्पा को भी देखें. यह इंटर-रेटर एग्रीमेंट का सबसे लोकप्रिय मेज़रमेंट है.
इंटरसेक्शन ओवर यूनियन (आईओयू)
दो सेट के प्रतिच्छेदन को उनके यूनियन से भाग देने पर मिलने वाली संख्या. मशीन लर्निंग में इमेज की पहचान करने वाले टास्क में, IoU का इस्तेमाल ग्राउंड-ट्रूथ बाउंडिंग बॉक्स के हिसाब से, मॉडल के अनुमानित बाउंडिंग बॉक्स के सटीक होने का पता लगाने के लिए किया जाता है. इस मामले में, दो बॉक्स का IoU ओवरलैप वाले इलाके और कुल एरिया के बीच का अनुपात है और इसकी वैल्यू 0 (अनुमानित बाउंडिंग बॉक्स और ग्राउंड-ट्रूथ बाउंडिंग बॉक्स का कोई ओवरलैप नहीं) से 1 (अनुमानित बाउंडिंग बॉक्स और ग्राउंड-ट्रूथ बाउंडिंग बॉक्स में बिलकुल एक जैसे निर्देशांक होते हैं).
उदाहरण के लिए, नीचे दी गई इमेज में:
- अनुमानित बाउंडिंग बॉक्स (निर्देशांक यह तय करते हैं कि मॉडल, पेंटिंग में नाइट टेबल का अनुमान कहां लगाता है) को बैंगनी रंग में आउटलाइन किया गया है.
- ग्राउंड-ट्रूथ बाउंडिंग बॉक्स (पेंटिंग में नाइट टेबल होने की जगह को तय करने वाले निर्देशांक) हरे रंग में आउटलाइन किया गया है.

यहां, अनुमान और ज़मीनी सच्चाई के लिए बाउंडिंग बॉक्स का इंटरसेक्शन (नीचे बाईं ओर), 1 है, और अनुमान और ज़मीनी सच्चाई (नीचे दाईं ओर) के लिए, बाउंडिंग बॉक्स का योग 7 है, इसलिए IoU \(\frac{1}{7}\)है.


IoU
इंटरसेक्शन ओवर यूनियन का शॉर्ट फ़ॉर्म.
आइटम का मैट्रिक्स
सुझाव देने वाले सिस्टम में, मैट्रिक्स फ़ैक्टराइज़ेशन से जनरेट होने वाले एम्बेड करने वाले वेक्टर का एक मैट्रिक्स होता है. इसमें हर आइटम के बारे में अनचाही सिग्नल मिलते हैं. आइटम मैट्रिक्स की हर लाइन में सभी आइटम के लिए, एक लेटेंट सुविधा की वैल्यू होती है. उदाहरण के लिए, फ़िल्म का सुझाव देने वाले किसी सिस्टम का इस्तेमाल करें. आइटम मैट्रिक्स का हर कॉलम एक मूवी को दिखाता है. लेटेंट सिग्नल, अलग-अलग शैलियों के हो सकते हैं या ऐसे सिग्नल हो सकते हैं जिन्हें समझना मुश्किल हो सकता है. इन सिग्नल में शैली, स्टार, फ़िल्म की उम्र या अन्य चीज़ों के बीच मुश्किल इंटरैक्शन शामिल होते हैं.
आइटम मैट्रिक्स में कॉलम की संख्या, उस टारगेट मैट्रिक्स के बराबर होती है जिसे फ़ैक्टराइज़ किया जा रहा है. उदाहरण के लिए, फ़िल्म का सुझाव देने वाला जो सिस्टम 10,000 फ़िल्मों के टाइटल का आकलन करता है, उसमें आइटम मैट्रिक्स में 10,000 कॉलम होंगे.
items
सुझाव देने वाले सिस्टम में, वे इकाइयां जिन्हें सिस्टम सुझाव देता है. उदाहरण के लिए, वीडियो ऐसे आइटम हैं जिनका सुझाव किसी वीडियो स्टोर की ओर से दिया जाता है. जबकि, बुकस्टोर ऐसे आइटम का सुझाव देता है जिनका सुझाव किताब की दुकान में देता है.
फिर से करें
ट्रेनिंग के दौरान, किसी मॉडल के पैरामीटर—मॉडल के वेट और पक्षपात से जुड़ा एक अपडेट. बैच साइज़ से यह तय होता है कि मॉडल एक बार में कितने उदाहरण प्रोसेस करेगा. उदाहरण के लिए, अगर बैच का साइज़ 20 है, तो मॉडल, पैरामीटर में बदलाव करने से पहले 20 उदाहरणों को प्रोसेस करता है.
न्यूरल नेटवर्क को ट्रेनिंग देते समय, एक इटरेशन में ये दो पास शामिल होते हैं:
- एक बैच में नुकसान का आकलन करने के लिए फ़ॉरवर्ड पास.
- बैकवर्ड पास (बैकप्रोपगेशन) की मदद से, नुकसान और लर्निंग रेट के आधार पर मॉडल के पैरामीटर में बदलाव किया जा सकता है.
J
जैक्स
अरे कंप्यूटिंग लाइब्रेरी, जिसमें XLA (Accelerated लीनियर Algebra) और बेहतरीन परफ़ॉर्मेंस वाली न्यूमेरिक (संख्या वाली) कंप्यूटिंग के लिए अपने-आप अंतर करने की सुविधा मिलती है. JAX, कंपोज़ेबल ट्रांसफ़ॉर्मेशन के साथ तेज़ी से काम करने वाले न्यूमेरिक कोड को लिखने के लिए, आसान और बेहतर एपीआई उपलब्ध कराता है. JAX में ये सुविधाएं मिलती हैं:
grad(अपने-आप अलग होने की सुविधा)jit(खास तौर पर एक साथ कई शॉर्ट वीडियो का कंपाइलेशन)vmap(ऑटोमैटिक वेक्टराइज़ेशन या बैचिंग)pmap(साथ में प्रोसेस होना)
JAX, Python की NumPy लाइब्रेरी के न्यूमेरिक कोड के ट्रांसफ़ॉर्मेशन ऐक्शन को दिखाने और उन्हें कंपोज़ करने के लिए इस्तेमाल किया जाता है. यह सुविधा मिलती-जुलती है, लेकिन इसका दायरा काफ़ी बड़ा है. (असल में, JAX में मौजूद .numpy लाइब्रेरी काम करने की एक ही तरह की है, लेकिन Python NumPy लाइब्रेरी का पूरी तरह से दोबारा लिखा गया वर्शन है.)
खास तौर पर, JAX मॉडल और डेटा को जीपीयू और TPU ऐक्सेलरेटर चिप में, मॉडल और डेटा को समानता के हिसाब से बदलकर, मशीन लर्निंग के कई टास्क को तेज़ी से पूरा करता है.
Flax, Optax, Pax, और कई अन्य लाइब्रेरी को JAX इन्फ़्रास्ट्रक्चर पर बनाया गया है.
K
Keras
एक लोकप्रिय Python मशीन लर्निंग एपीआई. Keras चैनल, कई डीप लर्निंग फ़्रेमवर्क पर काम करता है. इनमें TensorFlow भी शामिल है, जहां इसे tf.keras के तौर पर उपलब्ध कराया जाता है.
कर्नेल सपोर्ट वेक्टर मशीन्स (KSVM)
एक क्लासिफ़िकेशन एल्गोरिदम, जो इनपुट डेटा वेक्टर को हाई डाइमेंशन वाले स्पेस पर मैप करके, पॉज़िटिव और नेगेटिव क्लास के बीच के मार्जिन को कम करता है. उदाहरण के लिए, कैटगरी से जुड़े किसी सवाल पर ध्यान दें जिसमें इनपुट डेटासेट में सौ सुविधाएँ हैं. पॉज़िटिव और नेगेटिव क्लास के बीच मार्जिन को बढ़ाने के लिए, KSVM उन सुविधाओं को अंदरूनी तौर पर लाखों डाइमेंशन वाले स्पेस में मैप कर सकता है. KSVM, हिंज लॉस नाम के लॉस फ़ंक्शन का इस्तेमाल करता है.
मुख्य बातें
किसी इमेज में खास सुविधाओं के निर्देशांक. उदाहरण के लिए, इमेज की पहचान करने वाले मॉडल के लिए, जो अलग-अलग तरह के फूलों की प्रजातियों में अंतर करता है. इसके लिए, हर पंखुड़ी, तना, स्टैमेन वगैरह के बीच के खास पॉइंट हो सकते हैं.
के-फ़ोल्ड क्रॉस वैलिडेशन
यह एक एल्गोरिदम है, जो नए डेटा के लिए किसी मॉडल की सामान्य जानकारी को सामान्य तौर पर इस्तेमाल करने का अनुमान लगाता है. k-फ़ोल्ड में मौजूद k, उन समान समूहों की संख्या होता है जिन्हें आप डेटासेट के उदाहरणों को बांटते हैं. इसका मतलब है कि आपके मॉडल को k बार प्रशिक्षण देना और टेस्ट करना है. ट्रेनिंग और टेस्टिंग के हर राउंड के लिए, एक अलग ग्रुप को टेस्ट सेट माना जाता है. बचे हुए सभी ग्रुप, ट्रेनिंग सेट बन जाते हैं. ट्रेनिंग और टेस्टिंग के कई हज़ार चरणों के बाद, चुनी गई टेस्ट मेट्रिक के मीन और स्टैंडर्ड डीविएशन का हिसाब लगाया जाता है.
उदाहरण के लिए, मान लें कि आपके डेटासेट में 120 उदाहरण हैं. मान लीजिए, आपने k को 4 पर सेट करने का फ़ैसला किया है. इसलिए, उदाहरणों को शफ़ल करने के बाद, आप डेटासेट को 30 उदाहरणों के चार बराबर ग्रुप में बांटते हैं और चार ट्रेनिंग/टेस्टिंग राउंड करते हैं:

उदाहरण के लिए, किसी लीनियर रिग्रेशन मॉडल के लिए, मीन स्क्वेयर्ड एरर (एमएसई) सबसे अहम मेट्रिक हो सकती है. इसलिए, आपको सभी चारों राउंड में MSE का माध्य और स्टैंडर्ड डीविएशन पता चल जाएगा.
के-मीन
यह एक लोकप्रिय क्लस्टरिंग एल्गोरिदम है, जो बिना निगरानी वाले मोड में लर्निंग के उदाहरणों को ग्रुप में बांटता है. k-मीन एल्गोरिदम मूल रूप से ये काम करता है:
- यह फिर से सबसे अच्छे k सेंटर पॉइंट की पहचान करता है (इसे सेंट्रोइड कहा जाता है).
- हर उदाहरण को सबसे पास के सेंट्रोइड पर असाइन करता है. एक ही केंद्रक के वे उदाहरण एक ही समूह से संबंधित हैं.
k-मीन एल्गोरिदम, सेंट्रोइड की जगह चुनता है, ताकि हर उदाहरण से उसके सबसे नज़दीकी सेंट्रोइड की दूरी के कुल स्क्वेयर को कम किया जा सके.
उदाहरण के लिए, कुत्ते की लंबाई और कुत्ते की चौड़ाई के हिसाब से जानकारी देने वाले ये प्लॉट देखें:

अगर k=3 है, तो k-मीन एल्गोरिदम, तीन सेंट्रोइड तय करेगा. हर उदाहरण को उसके सबसे पास के सेंट्रोइड से असाइन किया जाता है. इसमें तीन ग्रुप मिलते हैं:

मान लें कि एक निर्माता कुत्तों के लिए छोटे, मीडियम, और बड़े स्वेटर के लिए सही साइज़ तय करना चाहता है. तीन सेंट्रोइड उस समूह में हर कुत्ते की औसत ऊंचाई और औसत चौड़ाई की पहचान करते हैं. इसलिए, मैन्युफ़ैक्चरर को स्वेटर के साइज़ को उन तीन सेंट्रोइड के आधार पर तय करना चाहिए. ध्यान दें कि क्लस्टर का केंद्रक आम तौर पर क्लस्टर में एक उदाहरण नहीं होता है.
ऊपर दिए गए उदाहरण में सिर्फ़ दो सुविधाओं (ऊंचाई और चौड़ाई) वाले उदाहरणों के लिए, k-मीन दिखाया गया है. ध्यान दें कि k-मीन, कई सुविधाओं में उदाहरणों को ग्रुप कर सकते हैं.
के-मीडियन
क्लस्टरिंग एल्गोरिदम, जो k-means से काफ़ी मिलता-जुलता है. दोनों के बीच में यह अलग है कि:
- k-मीन में, सेंट्रोइड, किसी सेंट्रोइड कैंडिडेट और इसके हर उदाहरण के बीच की दूरी के स्क्वेयर के योग को कम करके तय किए जाते हैं.
- के-मीडियन में, सेंट्रोइड का पता लगाने के लिए, सेंट्रोइड कैंडिडेट और उसके हर उदाहरण के बीच की दूरी के योग को कम से कम किया जाता है.
ध्यान दें कि दूरी की परिभाषाएं भी अलग-अलग हैं:
- k-मीन, सेंट्रोइड से उदाहरण तक यूक्लिडियन दूरी पर निर्भर करता है. (दो डाइमेंशन में, यूक्लिडीन दूरी का मतलब, कर्ण की गणना करने के लिए पाइथागोरस प्रमेय का इस्तेमाल करना है.) उदाहरण के लिए, (2,2) और (5,-2) के बीच की k-मीन की दूरी यह होगी:
- k-median, सेंट्रोइड से उदाहरण तक के लिए, मैनहैटन की दूरी पर निर्भर करता है. यह दूरी हर डाइमेंशन के कुल डेल्टा का योग है. उदाहरण के लिए, (2,2) और (5,-2) के बीच k-मीडियन की दूरी इस तरह होगी:
L
L0 रेगुलराइज़ेशन
यह एक तरह का रेगुलर एक्सप्रेशन होता है, जो किसी मॉडल में शून्य के अलावा अन्य वेट की कुल संख्या को पेनल्टी कर देता है. उदाहरण के लिए, 11 नॉन-ज़ीरो वेट वाले किसी मॉडल को उसी तरह के मॉडल की तुलना में ज़्यादा दंड दिया जाएगा जिसका वज़न 10 नॉन ज़ीरो है.
L0 रेगुलराइज़ेशन को कभी-कभी L0-norm रेगुलराइज़ेशन भी कहा जाता है.
L1 की कमी
ऐसा लॉस फ़ंक्शन जो असल लेबल की वैल्यू और मॉडल की अनुमान लगाई गई वैल्यू के बीच के फ़र्क़ का हिसाब लगाता है. उदाहरण के लिए, यहां दिए गए पांच उदाहरणों के लिए, बैच के लिए L1 की लॉस का हिसाब यहां दिया गया है:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | डेल्टा का निरपेक्ष मान |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 नुकसान | ||
L2 नुकसान की तुलना में, अन्य वजहों के मुकाबले L1 नुकसान कम संवेदनशील होता है.
मीन ऐब्सॉल्यूट एरर औसत L1 नुकसान है.
L1 रेगुलराइज़ेशन
यह एक तरह का रेगुलराइज़ेशन होता है, जो वेट की कुल वैल्यू के योग के अनुपात में वेट को कम करता है. L1 को रेगुलर करने से, ग़ैर-ज़रूरी या काम की सुविधाओं की अहमियत को बिलकुल 0 पर बढ़ाने में मदद मिलती है. किसी ऐसी सुविधा को मॉडल से हटा दिया जाता है जिसका वज़न 0 है.
L2 रेगुलराइज़ेशन से अलग करें.
L2 की कमी
लॉस फ़ंक्शन, जो असली लेबल की वैल्यू और मॉडल की अनुमान लगाई गई वैल्यू के बीच के अंतर के स्क्वेयर का हिसाब लगाता है. उदाहरण के लिए, यहां बैच के पांच उदाहरण के लिए, L2 के मुनाफ़े का हिसाब दिया गया है:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | डेल्टा का वर्ग |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 नुकसान | ||
वर्ग की वजह से, L2 की कमी से आउटलायर का असर बढ़ जाता है. इसका मतलब है कि L1 नुकसान की तुलना में, L2 नुकसान, खराब अनुमानों पर ज़्यादा प्रतिक्रिया देता है. उदाहरण के लिए, पिछले बैच के लिए L1 की कमी 16 के बजाय 8 होगी. ध्यान दें कि एक आउटलायर, 16 में से 9 के लिए है.
रिग्रेशन मॉडल आम तौर पर, लॉस फ़ंक्शन के तौर पर L2 लॉस का इस्तेमाल करते हैं.
मीन स्क्वेयर्ड एरर हर उदाहरण में औसत L2 नुकसान होता है. L2 लॉस का दूसरा नाम स्क्वेयर लॉस भी है.
L2 रेगुलराइज़ेशन
एक तरह का रेगुलराइज़ेशन, जो वज़न के स्क्वेयर के योग के अनुपात में वेट को कम करता है. L2 रेगुलराइज़ेशन, आउटलायर वेट (ज़्यादा पॉज़िटिव या कम नेगेटिव वैल्यू वाले) को 0 के करीब लाने, लेकिन 0 के आस-पास नहीं करने में मदद करता है. ऐसी सुविधाएं मॉडल में मौजूद रहती हैं जिनकी वैल्यू 0 के करीब होती है. हालांकि, वे मॉडल के अनुमान पर बहुत ज़्यादा असर नहीं डालती हैं.
L2 रेगुलराइज़ेशन की सुविधा से, लीनियर मॉडल को सामान्य बनाने में हमेशा मदद मिलती है.
L1 रेगुलराइज़ेशन से अलग करें.
लेबल
सुपरवाइज़्ड मशीन लर्निंग में, किसी उदाहरण के "जवाब" या "नतीजे" वाला हिस्सा होता है.
लेबल किए गए उदाहरण में एक या इससे ज़्यादा सुविधाएं और एक लेबल होता है. उदाहरण के लिए, स्पैम की पहचान करने वाले डेटासेट में, लेबल "स्पैम" होगा या "स्पैम नहीं" होगा. बारिश के डेटासेट में, किसी खास समय के दौरान हुई बारिश की मात्रा का लेबल दिया जा सकता है.
लेबल किया गया उदाहरण
उदाहरण के लिए, एक या एक से ज़्यादा सुविधाएं और लेबल शामिल होना. उदाहरण के लिए, नीचे दी गई टेबल में घर के वैल्यूएशन मॉडल के लेबल वाले तीन उदाहरण दिए गए हैं. हर उदाहरण में तीन सुविधाएं और एक लेबल है:
| कमरों की संख्या | बाथरूम की संख्या | घर की उम्र | घर की कीमत (लेबल) |
|---|---|---|---|
| 3 | 2 | 15 | 3,45,000 डॉलर |
| 2 | 1 | 72 | 1,79,000 डॉलर |
| 4 | 2 | 34 | 3,92,000 डॉलर |
निगरानी में रखे गए मशीन लर्निंग में, मॉडल लेबल किए गए उदाहरणों के आधार पर ट्रेनिंग देते हैं और बिना लेबल वाले उदाहरणों के आधार पर अनुमान लगाते हैं.
बिना लेबल वाले उदाहरणों के साथ कंट्रास्ट लेबल किए गए उदाहरण.
लेबल लीकेज
मॉडल के डिज़ाइन से जुड़ी ऐसी गड़बड़ी जिसमें सुविधा, लेबल के लिए प्रॉक्सी होती है. उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल का इस्तेमाल करें, ताकि यह अनुमान लगाया जा सके कि संभावित ग्राहक कोई खास प्रॉडक्ट खरीदेगा या नहीं.
मान लें कि इस मॉडल की एक सुविधा, SpokeToCustomerAgent नाम की बूलियन है. इसका मतलब यह है कि किसी ग्राहक एजेंट को असल में प्रॉडक्ट खरीदने के बाद ही असाइन किया जाता है. ट्रेनिंग के दौरान, मॉडल को SpokeToCustomerAgent और लेबल के बीच संबंध के बारे में तुरंत पता चल जाएगा.
लैम्डा
रेगुलराइज़ेशन रेट का समानार्थी शब्द.
Lambda एक ओवरलोडेड टर्म है. यहां हम रेगुलराइज़ेशन में, शब्द की परिभाषा पर फ़ोकस कर रहे हैं.
LaMDA (बातचीत ऐप्लिकेशन के लिए भाषा का मॉडल)
Google ने ट्रांसफ़ॉर्मर पर आधारित बड़े लैंग्वेज मॉडल बनाया है. इस मॉडल को Google ने एक बड़े डायलॉग डेटासेट के साथ डेवलप किया है. इस डेटासेट की मदद से, बातचीत के असली जवाब जनरेट किए जा सकते हैं.
LaMDA: बातचीत वाली हमारी बेहतरीन टेक्नोलॉजी, इसके बारे में ख़ास जानकारी देती है.
लैंडमार्क
कीपॉइंट के लिए समानार्थी शब्द.
लैंग्वेज मॉडल
ऐसा model जो model या टोकन के लंबे सीक्वेंस में होने वाले टोकन की संभावना का अनुमान लगाता है.
लार्ज लैंग्वेज मॉडल
एक अनौपचारिक शब्द, जिसका कोई मतलब नहीं होता. आम तौर पर, इसका मतलब भाषा का ऐसा मॉडल होता है जिसमें कई पैरामीटर होते हैं. बड़े लैंग्वेज मॉडल में 100 अरब से ज़्यादा पैरामीटर होते हैं.
लैटेंट स्पेस
स्पेस एम्बेड करने का समानार्थी शब्द.
लेयर
न्यूरल नेटवर्क में न्यूरॉन का एक सेट. लेयर के तीन सामान्य टाइप यहां दिए गए हैं:
- इनपुट लेयर, जो सभी सुविधाओं के लिए वैल्यू देती है.
- एक या एक से ज़्यादा छिपी हुई लेयर, जो सुविधाओं और लेबल के बीच गैर-कानूनी संबंध दिखाती हैं.
- आउटपुट लेयर, जिससे अनुमान लगाया जाता है.
उदाहरण के लिए, नीचे दिए गए इलस्ट्रेशन में एक इनपुट लेयर, दो छिपी हुई लेयर, और एक आउटपुट लेयर वाला न्यूरल नेटवर्क दिखाया गया है:

TensorFlow में, layers ऐसे Python फ़ंक्शन भी हैं जो Tensor और कॉन्फ़िगरेशन के विकल्पों को इनपुट के तौर पर लेते हैं और अन्य टेंसर को आउटपुट के तौर पर बनाते हैं.
लेयर एपीआई (tf.layers)
लेयर के कंपोज़िशन के तौर पर डीप न्यूरल नेटवर्क बनाने के लिए, TensorFlow एपीआई. लेयर एपीआई से, आपको अलग-अलग तरह की लेयर बनाने की सुविधा मिलती है, जैसे कि:
- पूरी तरह कनेक्ट की गई लेयर के लिए,
tf.layers.Dense. - कॉन्वोलूशन लेयर के लिए
tf.layers.Conv2D.
लेयर एपीआई, Keras लेयर एपीआई के नियमों का पालन करता है. इसका मतलब है कि एक अलग प्रीफ़िक्स के अलावा, लेयर एपीआई में मौजूद सभी फ़ंक्शन के नाम और हस्ताक्षर, Keras लेयर एपीआई में, मिलते-जुलते नाम और हस्ताक्षर के होते हैं.
पत्ती
डिसिज़न ट्री में मौजूद कोई भी एंडपॉइंट. स्थिति के उलट, पत्ती जांच नहीं करती. इसके बजाय, लीफ़ देने का अनुमान लगाया जा सकता है. लीफ़, किसी अनुमान पाथ का टर्मिनल नोड भी होता है.
उदाहरण के लिए, नीचे दिए गए डिसिज़न ट्री में तीन पत्तियां हैं:

लर्निंग इंटरप्रिटेबिलिटी टूल (एलआईटी)
यह विज़ुअल, मॉडल को समझने और डेटा को आसानी से समझने में मदद करने वाला इंटरैक्टिव टूल है.
मॉडल को समझने या टेक्स्ट, इमेज, और टेबल फ़ॉर्मैट वाले डेटा को विज़ुअलाइज़ करने के लिए, ओपन सोर्स LIT का इस्तेमाल किया जा सकता है.
सीखने की दर
यह एक फ़्लोटिंग-पॉइंट नंबर होता है, जो ग्रेडिएंट डिसेंट एल्गोरिदम के बारे में बताता है कि हर इटरेशन पर, वेट और पक्षपात को कितना सख्ती से बदलना है. उदाहरण के लिए, 0.3 का लर्निंग रेट, सीखने की दर 0.1 की तुलना में तीन गुना ज़्यादा असरदार तरीके से वेट और बायस को अडजस्ट करेगा.
लर्निंग रेट, एक मुख्य हाइपर पैरामीटर है. अगर सीखने की दर बहुत कम पर सेट की जाती है, तो ट्रेनिंग में बहुत समय लगेगा. अगर लर्निंग रेट को बहुत ज़्यादा पर सेट किया जाता है, तो ग्रेडिएंट ढलान में अक्सर कन्वर्ज़न तक पहुंचने में समस्या होती है.
कम से कम स्क्वेयर रिग्रेशन
लीनियर रिग्रेशन मॉडल को L2 लॉस को कम से कम करके ट्रेनिंग दी गई है.
रेखीय
दो या ज़्यादा वैरिएबल के बीच का संबंध, जिसे सिर्फ़ जोड़ और गुणा करके दिखाया जा सकता है.
लीनियर रिलेशनशिप का प्लॉट एक लाइन होता है.
nonlinear से कंट्रास्ट करें.
लीनियर मॉडल
ऐसा model जो model लगाने के लिए, हर model के लिए एक model असाइन करता है. (लीनियर मॉडल में पूर्वाग्रह भी शामिल होता है.) वहीं दूसरी ओर, डीप मॉडल में दी गई सुविधाओं और सुविधाओं के बीच का संबंध आम तौर पर नॉनलाइन होता है.
आम तौर पर, लीनियर मॉडल को ट्रेनिंग देना आसान होता है. साथ ही, डीप मॉडल की तुलना में इन्हें समझा जा सकता है. हालांकि, डीप मॉडल, सुविधाओं के बीच जटिल संबंध सीख सकते हैं.
लीनियर रिग्रेशन और लॉजिस्टिक रिग्रेशन दो तरह के लीनियर मॉडल हैं.
लीनियर रिग्रेशन
एक तरह का मशीन लर्निंग मॉडल, जिसमें नीचे दी गई दोनों बातें सही होती हैं:
- यह मॉडल एक लीनियर मॉडल है.
- अनुमान, फ़्लोटिंग-पॉइंट की एक वैल्यू होती है. (यह लीनियर रिग्रेशन का रिग्रेशन वाला हिस्सा है.)
लॉजिस्टिक रिग्रेशन की मदद से, लीनियर रिग्रेशन के बीच का अंतर बताएं. इसके अलावा, क्लासिफ़िकेशन के साथ रिग्रेशन के कंट्रास्ट का इस्तेमाल करें.
एलआईटी
लर्निंग इंटरप्रिटेबिलिटी टूल (LIT) का छोटा नाम. इसे पहले लैंग्वेज इंटरप्रिटेबिलिटी टूल के नाम से जाना जाता था.
एलएलएम
बड़े लैंग्वेज मॉडल के लिए छोटा नाम.
लॉजिस्टिक रिग्रेशन
यह एक तरह का रिग्रेशन मॉडल है, जो प्रॉबबिलिटी का अनुमान लगाता है. लॉजिस्टिक रिग्रेशन मॉडल की विशेषताएं:
- लेबल कैटगरिकल है. आम तौर पर, लॉजिस्टिक रिग्रेशन शब्द का मतलब बाइनरी लॉजिस्टिक रिग्रेशन होता है. इसका मतलब ऐसे मॉडल के लिए है जो दो संभावित वैल्यू वाले लेबल के लिए, प्रॉबबिलिटी का हिसाब लगाता है. एक कम सामान्य वैरिएंट, मल्टीनोमियल लॉजिस्टिक रिग्रेशन, दो से ज़्यादा संभावित वैल्यू वाले लेबल के लिए प्रायिकताओं की गणना करता है.
- ट्रेनिंग के दौरान होने वाले नुकसान का फ़ंक्शन, लॉग लॉस है. (एक से ज़्यादा लॉग लॉस यूनिट को लेबल के लिए दो से ज़्यादा संभावित वैल्यू के साथ एक साथ रखा जा सकता है.)
- इस मॉडल में लीनियर आर्किटेक्चर का इस्तेमाल किया गया है, न कि डीप न्यूरल नेटवर्क. हालांकि, इस परिभाषा का बाकी हिस्सा, डीप मॉडल पर भी लागू होता है जो कैटगरीकल लेबल की संभावनाओं का अनुमान लगाते हैं.
उदाहरण के लिए, एक लॉजिस्टिक रिग्रेशन मॉडल इस्तेमाल करें. यह मॉडल, इनपुट ईमेल के स्पैम या स्पैम न होने की संभावना का हिसाब लगाता है. अनुमान के दौरान, मान लें कि मॉडल 0.72 का अनुमान लगाता है. इसलिए, मॉडल से यह अनुमान लगाया जा रहा है:
- ईमेल के स्पैम होने की 72% संभावना.
- इस बात की 28% संभावना होती है कि ईमेल स्पैम न हो.
लॉजिस्टिक रिग्रेशन मॉडल में, दो चरणों वाले इन आर्किटेक्चर का इस्तेमाल किया जाता है:
- यह मॉडल इनपुट सुविधाओं का लीनियर फ़ंक्शन लागू करके, रॉ अनुमान (y') जनरेट करता है.
- यह मॉडल, इसी अनुमान को sigmoid फ़ंक्शन के इनपुट के तौर पर इस्तेमाल करता है. यह अनुमान को 0 से 1 के बीच की वैल्यू में बदल देता है.
किसी भी रिग्रेशन मॉडल की तरह, लॉजिस्टिक रिग्रेशन मॉडल किसी संख्या का अनुमान लगाता है. हालांकि, यह नंबर आम तौर पर बाइनरी क्लासिफ़िकेशन मॉडल का हिस्सा बन जाता है, जैसे कि:
- अगर अनुमानित संख्या, क्लासिफ़िकेशन थ्रेशोल्ड से ज़्यादा है, तो बाइनरी क्लासिफ़िकेशन मॉडल पॉज़िटिव क्लास का अनुमान लगाता है.
- अगर अनुमानित संख्या, क्लासिफ़िकेशन थ्रेशोल्ड से कम है, तो बाइनरी क्लासिफ़िकेशन मॉडल नेगेटिव क्लास का अनुमान लगाता है.
लॉगिट
रॉ (नॉन-नॉर्मलाइज़्ड) ऐसे अनुमानों का वेक्टर जो किसी क्लासिफ़िकेशन मॉडल को जनरेट करता है, जिसे आम तौर पर नॉर्मलाइज़ेशन फ़ंक्शन में पास किया जाता है. अगर मॉडल मल्टी-क्लास क्लासिफ़िकेशन की समस्या को हल कर रहा है, तो लॉजिट आम तौर पर softmax फ़ंक्शन के लिए इनपुट बन जाता है. इसके बाद, सॉफ़्टमैक्स फ़ंक्शन हर संभावित क्लास के लिए एक वैल्यू के साथ (सामान्य) प्रॉबबिलिटी का वेक्टर जनरेट करता है.
लॉग लॉस
बाइनरी लॉजिस्टिक रिग्रेशन में इस्तेमाल किया जाने वाला लॉस फ़ंक्शन.
लॉग-ऑड
किसी इवेंट की संख्याओं का लॉगरिद्म.
लंबी अवधि के लिए मेमोरी (एलएसटीएम)
बार-बार होने वाले न्यूरल नेटवर्क में मौजूद एक तरह की सेल. इसका इस्तेमाल हैंडराइटिंग की पहचान, मशीन से अनुवाद, और इमेज के कैप्शन जैसे ऐप्लिकेशन में डेटा के क्रम को प्रोसेस करने के लिए किया जाता है. एलएसटीएम, लुप्त होने वाले ग्रेडिएंट की समस्या को ठीक करते हैं. यह समस्या तब होती है, जब आरएएनएन की पुरानी सेल के नए इनपुट और कॉन्टेक्स्ट के आधार पर इंटरनल मेमोरी स्टेट में लंबे डेटा क्रम की वजह से आरएनएन को ट्रेनिंग दी जाती है.
LoRA
कम रैंक के हिसाब से ढल जाने की क्षमता का छोटा नाम.
हार
निगरानी में रखे गए मॉडल की ट्रेनिंग के दौरान, यह पता लगाया जाता है कि कोई मॉडल, उसके अनुमान के लेबल से कितनी दूर है.
लॉस फ़ंक्शन, नुकसान का हिसाब लगाता है.
लॉस एग्रीगेटर
एक तरह का मशीन लर्निंग एल्गोरिदम, जो मॉडल की परफ़ॉर्मेंस को बेहतर बनाता है. इसके लिए, यह कई मॉडल के अनुमानों को जोड़ता है और उन अनुमानों का इस्तेमाल करके एक अनुमान लगाता है. इस वजह से, लॉस एग्रीगेटर, अनुमानों में फ़र्क़ को कम कर सकता है और सटीक होने को बेहतर बना सकता है.
लॉस कर्व
ट्रेनिंग की दोहरावों की संख्या के फ़ंक्शन के तौर पर, लॉस का प्लॉट. नीचे दिए गए प्लॉट में, आम तौर पर होने वाले लॉस कर्व को दिखाया गया है:

लॉस कर्व की मदद से यह तय किया जा सकता है कि आपका मॉडल कब कन्वर्ज़न या ओवरफ़िट हो रहा है.
लॉस कर्व इस तरह की सभी नुकसान को प्लॉट कर सकते हैं:
सामान्य तरीके से बताने वाला कर्व भी देखें.
लॉस फ़ंक्शन
ट्रेनिंग या टेस्टिंग के दौरान, यह गणित का एक ऐसा फ़ंक्शन है जो उदाहरणों के बैच में नुकसान का हिसाब लगाता है. लॉस फ़ंक्शन, उन मॉडल के लिए कम लॉस दिखाता है जो खराब अनुमान लगाने वाले मॉडल की तुलना में अच्छे अनुमान लगाते हैं.
आम तौर पर, ट्रेनिंग का मकसद लॉस फ़ंक्शन के वापस होने वाले नुकसान को कम करना होता है.
लॉस फ़ंक्शन कई तरह के होते हैं. जिस तरह का मॉडल बनाया जा रहा है उसके लिए, सही लॉस फ़ंक्शन चुनें. उदाहरण के लिए:
- L2 लॉस (या मीन स्क्वेयर्ड एरर) लीनियर रिग्रेशन का लॉस फ़ंक्शन है.
- लॉग लॉस का मतलब है, लॉजिस्टिक रिग्रेशन के लिए लॉस फ़ंक्शन इस्तेमाल करना.
लॉस सरफ़ेस
वज़न बनाम कम का ग्राफ़. ग्रेडिएंट डिसेंट का मकसद, ऐसे वज़न का पता लगाना है जिसके लिए कम से कम एक स्थानीय वैल्यू मिल रही है.
कम रैंक के हिसाब से ढलने की क्षमता (LoRA)
पैरामीटर की बेहतर ट्यूनिंग करने वाला एल्गोरिदम, जो बड़े भाषा के मॉडल के पैरामीटर के सिर्फ़ एक सबसेट को फ़ाइन-ट्यून करता है. LoRA से ये फ़ायदे मिलते हैं:
- इन तकनीकों को उन तकनीकों से ज़्यादा तेज़ी से फ़ाइन-ट्यून करता है, जिनके लिए किसी मॉडल के सभी पैरामीटर को बेहतर बनाने की ज़रूरत होती है.
- फ़ाइन-ट्यून किए गए मॉडल में, अनुमान की कंप्यूटेशनल लागत कम करता है.
LoRA के साथ तैयार किया गया मॉडल अपने अनुमानों की क्वालिटी को बनाए रखता है या उसे बेहतर बनाता है.
LoRA किसी मॉडल के कई खास वर्शन को चालू करता है.
एलएसटीएम
लॉन्ग शॉर्ट-टर्म मेमोरी का छोटा नाम.
सोम
मशीन लर्निंग
वह प्रोग्राम या सिस्टम जो इनपुट डेटा से मॉडल को ट्रेन करता है. ट्रेन किया गया मॉडल, मॉडल को ट्रेनिंग देने के लिए इस्तेमाल किए गए डिस्ट्रिब्यूशन से लिए गए नए (पहले कभी नहीं देखे गए) डेटा से काम का अनुमान लगा सकता है.
मशीन लर्निंग का मतलब ऐसे प्रोग्राम या सिस्टम से जुड़े अध्ययन के क्षेत्र से है जो इन प्रोग्राम या सिस्टम से जुड़े हों.
बहुमत श्रेणी
क्लास असंतुलित डेटासेट में ज़्यादा सामान्य लेबल. उदाहरण के लिए, 99% नेगेटिव लेबल और 1% पॉज़िटिव लेबल वाले डेटासेट के लिए, नेगेटिव लेबल ज़्यादातर क्लास हैं.
माइनरिटी क्लास से अलग करें.
मार्कोव के फ़ैसले की प्रोसेस (एमडीपी)
फ़ैसले लेने वाला मॉडल दिखाने वाला ग्राफ़, जिसमें राज्यों के क्रम को नेविगेट करने के लिए फ़ैसले लिए जाते हैं. ऐसा मार्कोव प्रॉपर्टी के हिसाब से किया जाता है. रीइन्फ़ोर्समेंट लर्निंग में, राज्यों के बीच होने वाले ट्रांज़िशन से संख्या में इनाम मिलता है.
मार्कोव प्रॉपर्टी
कुछ खास एनवायरमेंट की प्रॉपर्टी, जहां स्थिति के ट्रांज़िशन को पूरी तरह से, मौजूदा स्टेट और एजेंट की कार्रवाई में दी गई जानकारी से तय किया जाता है.
मास्क्ड लैंग्वेज मॉडल
यह भाषा का ऐसा मॉडल है जो किसी क्रम में खाली जगह को भरने के लिए, कैंडिडेट टोकन की संभावना का अनुमान लगाता है. उदाहरण के लिए, मास्क किए गए लैंग्वेज मॉडल से, यहां दिए गए वाक्य की अंडरलाइन को बदलने के लिए, उम्मीदवारों के शब्दों की संभावना का हिसाब लगाया जा सकता है:
टोपी में ____ वापस आ गया.
साहित्य में आम तौर पर अंडरलाइन के बजाय "MASK" स्ट्रिंग का इस्तेमाल किया जाता है. उदाहरण के लिए:
टोपी में "MASK" भी वापस आ गया.
ज़्यादातर आधुनिक मास्क वाले लैंग्वेज मॉडल दो-तरफ़ा हैं.
मैटप्लोटलिब
एक ओपन सोर्स Python 2D प्लॉटिंग लाइब्रेरी. matplotlib की मदद से मशीन लर्निंग के अलग-अलग पहलुओं को विज़ुअलाइज़ किया जा सकता है.
मैट्रिक्स फ़ैक्टराइज़ेशन
गणित में, यह ऐसे मैट्रिक्स को खोजने का एक तरीका है जिनके डॉट प्रॉडक्ट, टारगेट मैट्रिक्स का अनुमान लगाते हैं.
सुझाव देने वाले सिस्टम में, टारगेट मैट्रिक्स अक्सर आइटम पर उपयोगकर्ताओं की रेटिंग तय करता है. उदाहरण के लिए, फ़िल्म के सुझाव देने वाले सिस्टम के लिए टारगेट मैट्रिक्स कुछ इस तरह दिख सकता है, जहां सकारात्मक पूर्णांक उपयोगकर्ता रेटिंग होते हैं और 0 का मतलब है कि उपयोगकर्ता ने फ़िल्म को रेटिंग नहीं दी है:
| कैसाब्लांका | द फ़िलाडेल्फ़िया स्टोरी | Black Panther | वंडर वुमन | दिल से | |
|---|---|---|---|---|---|
| यूज़र 1 | 5.0 | 3.0 | 0.0 | 2.0 | 0.0 |
| यूज़र 2 | 4.0 | 0.0 | 0.0 | 1.0 | 5.0 |
| यूज़र 3 | 3.0 | 1.0 | 4.0 | 5.0 | 0.0 |
फ़िल्मों के सुझाव देने वाले सिस्टम का काम, रेट नहीं की गई फ़िल्मों के लिए उपयोगकर्ता रेटिंग का अनुमान लगाना है. उदाहरण के लिए, क्या उपयोगकर्ता 1 को ब्लैक पैंथर पसंद आएगा?
सुझाव देने वाले सिस्टम का एक तरीका है मैट्रिक्स फ़ैक्टर का इस्तेमाल करके, इन दो मैट्रिक्स को जनरेट करना:
- उपयोगकर्ता मैट्रिक्स, जो उपयोगकर्ताओं की संख्या X होता है. इसका मतलब है कि एम्बेड किए जाने वाले डाइमेंशन की संख्या.
- एक आइटम मैट्रिक्स, एम्बेड किए जा रहे डाइमेंशन की संख्या X और आइटम की संख्या के तौर पर बनाया जाता है.
उदाहरण के लिए, हमारे तीन उपयोगकर्ताओं और पांच आइटम पर मैट्रिक्स का फ़ैक्टराइज़ेशन का इस्तेमाल करने से, यह यूज़र मैट्रिक्स और आइटम मैट्रिक्स मिल सकता है:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
उपयोगकर्ता मैट्रिक्स और आइटम मैट्रिक्स के डॉट प्रॉडक्ट से एक सुझाव मैट्रिक्स मिलता है, जिसमें सिर्फ़ मूल उपयोगकर्ता रेटिंग ही नहीं, बल्कि फ़िल्मों के लिए ऐसे सुझाव भी शामिल होते हैं जिन्हें हर व्यक्ति ने नहीं देखा है. उदाहरण के लिए, उपयोगकर्ता 1 की कैसाब्लांका की रेटिंग देखें, जो 5.0 थी. सुझाव मैट्रिक्स में उस सेल से जुड़ा डॉट प्रॉडक्ट उम्मीद है कि 5.0 के आस-पास होगा और यह है:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9
सबसे अहम बात यह है कि क्या उपयोगकर्ता 1 को ब्लैक पैंथर, पसंद आएगा? पहली पंक्ति और तीसरे कॉलम से जुड़े डॉट प्रॉडक्ट को लेने पर, अनुमानित रेटिंग 4.3 मिलती है:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3
आम तौर पर, मैट्रिक्स के फ़ैक्टराइज़ेशन से, यूज़र मैट्रिक्स और आइटम मैट्रिक्स मिलता है. ये दोनों, टारगेट मैट्रिक्स की तुलना में ज़्यादा संक्षिप्त होते हैं.
मीन ऐब्सॉल्यूट एरर (एमएई)
L1 नुकसान का इस्तेमाल करने पर, हर उदाहरण के हिसाब से औसत नुकसान. औसत पूर्ण गड़बड़ी की गणना इस तरह करें:
- बैच के लिए, L1 लॉस का हिसाब लगाएं.
- L1 लॉस को बैच में उदाहरणों की संख्या से भाग दें.
उदाहरण के लिए, पांच उदाहरणों के यहां दिए गए बैच के लिए, L1 लॉस का हिसाब लगाएं:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | नुकसान (असल और अनुमानित के बीच में अंतर) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 नुकसान | ||
इसलिए, L1 की वैल्यू 8 है और उदाहरणों की संख्या पांच है. इसलिए, मीन ऐब्सॉल्यूट एरर (औसतन गड़बड़ी) यह होता है:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
मीन स्क्वेयर्ड एरर और रूट मीन स्क्वेयर्ड एरर के साथ कंट्रास्ट मीन ऐब्सलूट एरर.
मीन स्क्वेयर्ड एरर (MSE)
L2 नुकसान का इस्तेमाल करने पर, हर उदाहरण के हिसाब से औसत नुकसान. माध्य वर्ग गड़बड़ी की गणना इस तरह करें:
- बैच के लिए, L2 लॉस का हिसाब लगाएं.
- L2 लॉस को बैच में उदाहरणों की संख्या से भाग दें.
उदाहरण के लिए, पांच उदाहरणों के नीचे दिए गए बैच में नुकसान के बारे में सोचें:
| वास्तविक मान | मॉडल का अनुमान | हार मिली | स्क्वेयर लॉस |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 नुकसान | |||
इसलिए, मीन स्क्वेयर्ड एरर यह होता है:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
मीन स्क्वेयर्ड एरर एक लोकप्रिय ट्रेनिंग ऑप्टिमाइज़र है, खास तौर पर, लीनियर रिग्रेशन के लिए.
मीन स्क्वेयर्ड एरर और रूट मीन स्क्वेयर्ड एरर की मदद से कंट्रास्ट मीन स्क्वेयर्ड एरर.
TensorFlow Playground, नुकसान की वैल्यू कैलकुलेट करने के लिए, मीन स्क्वेयर्ड एरर का इस्तेमाल करता है.
मेश
एमएल पैरलल प्रोग्रामिंग में, यह एक टर्म है जो TPU चिप को डेटा और मॉडल असाइन करता है. साथ ही, इन वैल्यू को शार्ड करने या दोहराए जाने का तरीका तय करता है.
मेश एक ओवरलोडेड टर्म है, जिसका इनमें से कोई एक मतलब हो सकता है:
- TPU चिप का फ़िज़िकल लेआउट.
- TPU चिप के साथ डेटा और मॉडल को मैप करने के लिए, एक ऐब्स्ट्रैक्ट लॉजिकल कंस्ट्रक्ट.
दोनों ही मामलों में, मेश को आकार के तौर पर दिखाया जाता है.
मेटा-लर्निंग
मशीन लर्निंग का एक सबसेट जो लर्निंग एल्गोरिदम को खोजता है या उसे बेहतर बनाता है. मेटा-लर्निंग सिस्टम का लक्ष्य, किसी मॉडल को ट्रेनिंग देना भी हो सकता है, ताकि वह छोटे से डेटा का इस्तेमाल करके या पिछले टास्क में मिले अनुभव से नया टास्क तुरंत सीख सके. मेटा-लर्निंग एल्गोरिदम आम तौर पर इन कामों को करने की कोशिश करते हैं:
- हाथ से तैयार की गई सुविधाओं (जैसे, शुरू करने वाला टूल या ऑप्टिमाइज़र) को बेहतर बनाएं या सीखें.
- डेटा की कम खपत और गणना करने की क्षमता होनी चाहिए.
- सामान्य जानकारी को बेहतर बनाएं.
मेटा-लर्निंग, कुछ शॉट के साथ सीखना से जुड़ा है.
मीट्रिक
वह आंकड़ा जो आपके लिए मायने रखता है.
मकसद वह मेट्रिक होती है जिसे मशीन लर्निंग सिस्टम, ऑप्टिमाइज़ करने की कोशिश करता है.
Metrics API (tf.metric)
मॉडल का आकलन करने के लिए, TensorFlow एपीआई. उदाहरण के लिए, tf.metrics.accuracy
यह तय करता है कि किसी मॉडल के अनुमान, लेबल से कितनी बार मेल खाते हैं.
मिनी-बैच
किसी बैच का एक छोटा, बिना किसी क्रम के चुना गया सबसेट, जिसे एक दोहराव में प्रोसेस किया जाता है. आम तौर पर, मिनी बैच का बैच साइज़ 10 से 1,000 उदाहरणों के बीच होता है.
उदाहरण के लिए, मान लें कि पूरे ट्रेनिंग सेट (पूरे बैच) में 1,000 उदाहरण हैं. इसके अलावा, मान लें कि आपने हर मिनी-बैच के बैच साइज़ को 20 पर सेट किया है. इसलिए, हर दोहराव से 1,000 उदाहरणों में से किसी 20 के क्रम में नुकसान का पता लगाया जाता है और इसके बाद, वेट और पक्षपातों को उसके हिसाब से अडजस्ट किया जाता है.
पूरे बैच के सभी उदाहरणों के नुकसान की तुलना में, मिनी-बैच पर हुए नुकसान का हिसाब लगाना ज़्यादा आसान है.
मिनी-बैच स्टोकैस्टिक ग्रेडिएंट ढलान
एक ग्रेडिएंट डिसेंट एल्गोरिदम, जो मिनी-बैच का इस्तेमाल करता है. दूसरे शब्दों में, मिनी-बैच स्टोहैस्टिक ग्रेडियंट ढलान, ट्रेनिंग डेटा के एक छोटे सबसेट के आधार पर ग्रेडिएंट का अनुमान लगाता है. सामान्य स्टोकैस्टिक ग्रेडिएंट डिसेंट, साइज़ 1 के मिनी-बैच का इस्तेमाल करता है.
कम से कम नुकसान
जनरेट किए गए डेटा और रीयल डेटा के डिस्ट्रिब्यूशन के बीच की क्रॉस-एंट्रॉपी के आधार पर, जनरेटिव ऐडवर्सल नेटवर्क की लॉस फ़ंक्शन.
पहले पेपर में Minimax के लॉस का इस्तेमाल किया गया है, ताकि जनरेटिव एआई की मदद से मुश्किल नेटवर्क के बारे में जानकारी दी गई हो.
अल्पसंख्यक वर्ग
क्लास असंतुलित डेटासेट में कम इस्तेमाल होने वाला लेबल. उदाहरण के लिए, जिस डेटासेट में 99% नेगेटिव लेबल और 1% पॉज़िटिव लेबल हों उसके लिए पॉज़िटिव लेबल, अल्पसंख्यक वर्ग होते हैं.
ज़्यादातर वर्ग से अलग करें.
माली (ML)
मशीन लर्निंग का छोटा नाम.
एमएनआईएसटी
LeCun, Cortes, और बर्ज का इकट्ठा किया गया एक सार्वजनिक डोमेन का डेटासेट, जिसमें 60,000 इमेज हैं. हर इमेज में दिखाया गया है कि किसी इंसान ने 0 से 9 तक, किसी अंक को मैन्युअल तरीके से कैसे लिखा है. हर इमेज को पूर्णांक के 28x28 कलेक्शन के तौर पर सेव किया जाता है. यहां हर पूर्णांक की ग्रेस्केल वैल्यू, 0 से 255 के बीच होती है.
एमएनआईएसटी, मशीन लर्निंग के लिए एक कैननिकल डेटासेट है. इसका इस्तेमाल, अक्सर मशीन लर्निंग के नए तरीकों को टेस्ट करने के लिए किया जाता है. ज़्यादा जानकारी के लिए, हाथ से लिखे गए अंकों का एमएनआईएसटी डेटाबेस देखें.
मोडलिटी
डेटा की बेहतर कैटगरी. उदाहरण के लिए, संख्या, टेक्स्ट, इमेज, वीडियो, और ऑडियो पांच अलग-अलग तरीके हैं.
model
आम तौर पर, यह गणित के किसी भी ऐसे तरीके का इस्तेमाल करता है जो इनपुट डेटा को प्रोसेस करता है और आउटपुट दिखाता है. इसे अलग तरीके से लिखा गया हो. मॉडल, ऐसे पैरामीटर और स्ट्रक्चर का सेट होता है जिनकी किसी सिस्टम को अनुमान लगाने की ज़रूरत होती है. सुपरवाइज़्ड मशीन लर्निंग में, मॉडल इनपुट के तौर पर उदाहरण का इस्तेमाल करता है और आउटपुट के तौर पर अनुमान दिखाता है. सुपरवाइज़्ड मशीन लर्निंग में, मॉडल कुछ हद तक अलग होते हैं. उदाहरण के लिए:
- लीनियर रिग्रेशन मॉडल में वेट और बायस का एक सेट होता है.
- न्यूरल नेटवर्क मॉडल में ये चीज़ें शामिल हैं:
- छिपी हुई लेयर का सेट. हर लेयर में एक या उससे ज़्यादा न्यूरॉन होते हैं.
- हर न्यूरॉन का वेट और बायस.
- डिसिज़न ट्री मॉडल में ये चीज़ें शामिल होती हैं:
- पेड़ का आकार यानी एक ऐसा पैटर्न जिसमें पत्तियां और स्थितियां आपस में जुड़ी होती हैं.
- शर्तें और पत्तियां.
आपके पास किसी मॉडल को सेव करने, उसे वापस लाने या उसकी कॉपी बनाने का विकल्प होता है.
बिना निगरानी वाली मशीन लर्निंग, मॉडल भी जनरेट करती है. आम तौर पर, यह ऐसा फ़ंक्शन होता है जो इनपुट के उदाहरण को सबसे सही क्लस्टर के साथ मैप कर सकता है.
मॉडल की कपैसिटी
समस्याओं की जटिलता, जिन्हें मॉडल सीख सकता है. कोई मॉडल जितनी समस्याएँ सीख सकता है, मॉडल की क्षमता उतनी ही ज़्यादा होगी. आम तौर पर, मॉडल पैरामीटर की संख्या बढ़ने पर किसी मॉडल की क्षमता बढ़ जाती है. क्लासिफ़ायर की क्षमता की औपचारिक परिभाषा के लिए, वीसी डाइमेंशन देखें.
मॉडल कैस्केडिंग
एक सिस्टम जो किसी खास अनुमान से जुड़ी क्वेरी के लिए सबसे सही model चुनता है.
मान लें कि मॉडल का एक ग्रुप है, जिसमें बहुत बड़े (बहुत सारे पैरामीटर) से लेकर बहुत छोटे (बहुत कम पैरामीटर) शामिल हैं. बहुत बड़े मॉडल, छोटे मॉडल के मुकाबले अनुमान में ज़्यादा कंप्यूटेशनल संसाधन इस्तेमाल करते हैं. हालांकि, छोटे मॉडल की तुलना में बहुत बड़े मॉडल को ज़्यादा जटिल अनुरोध मिल सकते हैं. मॉडल कैस्केडिंग, अनुमान से जुड़ी क्वेरी की जटिलता तय करता है और फिर अनुमान लगाने के लिए, सही मॉडल चुनता है. मॉडल कैस्केडिंग का मुख्य मकसद, अनुमान की लागत को कम करना है. इसके लिए, आम तौर पर छोटे मॉडल चुने जाते हैं और मुश्किल क्वेरी के लिए सिर्फ़ बड़े मॉडल को चुना जाता है.
मान लें कि एक छोटा मॉडल किसी फ़ोन पर चलता है और उस मॉडल का बड़ा वर्शन रिमोट सर्वर पर चलता है. अच्छे मॉडल के कैस्केडिंग की मदद से लागत और इंतज़ार का समय कम हो जाता है. इससे छोटे मॉडल को सामान्य अनुरोधों को हैंडल करने में मदद मिलती है. साथ ही, जटिल अनुरोधों को मैनेज करने के लिए सिर्फ़ रिमोट मॉडल को कॉल किया जा सकता है.
मॉडल राऊटर भी देखें.
मॉडल पैरलिज़्म
यह ट्रेनिंग या अनुमान को स्केल करने का एक ऐसा तरीका है जो अलग-अलग model पर किसी model के अलग-अलग हिस्सों को शामिल करता है. मॉडल समानता ऐसे मॉडल को चालू करती है जो एक डिवाइस पर फ़िट होने के लिए बहुत बड़े होते हैं.
मॉडल समानता को लागू करने के लिए, सिस्टम आम तौर पर ये काम करता है:
- शार्ड, मॉडल को छोटे-छोटे हिस्सों में बांटते हैं.
- उन छोटे पार्ट को बनाने की ट्रेनिंग, एक से ज़्यादा प्रोसेसर के बीच बांटती है. हर प्रोसेसर, मॉडल का अपना हिस्सा खुद ही तैयार करता है.
- नतीजों को जोड़कर एक मॉडल बनाता है.
मॉडल पैरलिज़्म ट्रेनिंग को धीमा कर देता है.
डेटा समानता भी देखें.
मॉडल राऊटर
वह एल्गोरिदम जो model में model के लिए सबसे सही model तय करता है. मॉडल राऊटर अपने-आप में एक मशीन लर्निंग मॉडल होता है. यह किसी दिए गए इनपुट के लिए, धीरे-धीरे सबसे अच्छा मॉडल चुनने का तरीका सीखता है. हालांकि, मॉडल राऊटर को कभी-कभी ज़्यादा आसान, नॉन-मशीन लर्निंग एल्गोरिदम हो सकता है.
मॉडल ट्रेनिंग
सबसे अच्छा model तय करने की प्रोसेस.
दिलचस्पी बढ़ाना
यह एक बेहतरीन ग्रेडिएंट डिसेंट एल्गोरिदम है जिसमें लर्निंग कदम, न सिर्फ़ मौजूदा चरण के डेरिवेटिव पर निर्भर करता है, बल्कि चरण से ठीक पहले के डेरिवेटिव पर भी निर्भर करता है. मोमेंटम में समय के साथ ग्रेडिएंट के तेज़ी से भारित घटने-बढ़ने वाले औसत की गणना करना शामिल है, जो भौतिकी में संवेग के समान है. मोमेंटम, कभी-कभी स्थानीय मिनिमा में सीखने बात करने से रोकता है.
कई क्लास की कैटगरी
सुपरवाइज़्ड लर्निंग में, क्लासिफ़िकेशन से जुड़ी एक समस्या, जिसके डेटासेट में लेबल की दो से ज़्यादा क्लास हैं. जैसे, Iris डेटासेट में मौजूद लेबल, इन तीन क्लास में से कोई एक होना चाहिए:
- आइरिस सेटोसा
- आइरिस वर्जिनिका
- आइरिस वर्सीकलर
Iris डेटासेट पर ट्रेनिंग किया गया एक मॉडल, जो नए उदाहरणों में Iris टाइप का अनुमान लगाता है, वह कई क्लास की कैटगरी तय कर रहा है.
इसके उलट, दो क्लास के बीच अंतर करने वाले क्लासिफ़िकेशन से जुड़े सवाल बाइनरी क्लासिफ़िकेशन मॉडल हैं. उदाहरण के लिए, स्पैम या स्पैम नहीं का अनुमान लगाने वाला ईमेल मॉडल, बाइनरी क्लासिफ़िकेशन मॉडल होता है.
क्लस्टरिंग से जुड़ी समस्याओं में, मल्टी-क्लास क्लासिफ़िकेशन का मतलब दो से ज़्यादा क्लस्टर से है.
मल्टी-क्लास लॉजिस्टिक रिग्रेशन
मल्टी-क्लास क्लासिफ़िकेशन में लॉजिस्टिक रिग्रेशन का इस्तेमाल करना.
मल्टी-हेड सेल्फ़-अटेंशन
सेल्फ़-अटेंशन का एक एक्सटेंशन, जो इनपुट क्रम में हर पोज़िशन के लिए, खुद पर ध्यान देने की सुविधा को कई बार लागू करता है.
ट्रांसफ़ॉर्मर ने मल्टी-हेड सेल्फ़-अटेंशन पेश किया.
मल्टीमोडल मॉडल
ऐसा मॉडल जिसके इनपुट और/या आउटपुट में एक से ज़्यादा मॉडलिटी शामिल हों. उदाहरण के लिए, एक ऐसा मॉडल देखें जो एक इमेज और एक टेक्स्ट कैप्शन (दो मोडलिटी) को सुविधाओं के रूप में लेता है. इससे यह पता चलता है कि इमेज के लिए टेक्स्ट कैप्शन कितना सही है. इसलिए, इस मॉडल के इनपुट मल्टीमोडल होते हैं और आउटपुट यूनिमोडल होता है.
बहुपद वर्गीकरण
मल्टी-क्लास क्लासिफ़िकेशन के लिए समानार्थी शब्द.
मल्टीनोमियल रिग्रेशन
मल्टी-क्लास लॉजिस्टिक रिग्रेशन का समानार्थी शब्द.
मल्टीटास्क
एक मशीन लर्निंग तकनीक, जिसमें किसी एक model को कई model करने के लिए ट्रेनिंग दी जाती है.
मल्टीटास्किंग मॉडल को उस डेटा पर ट्रेनिंग देकर बनाया जाता है जो अलग-अलग टास्क के लिए सही होता है. इससे मॉडल को टास्क के बीच जानकारी शेयर करने में मदद मिलती है, जिससे मॉडल को ज़्यादा असरदार तरीके से सीखने में मदद मिलती है.
कई कामों के लिए ट्रेन किए गए मॉडल में, सामान्य बनाने की क्षमता बेहतर होती है. साथ ही, यह अलग-अलग तरह के डेटा को हैंडल करने में ज़्यादा मज़बूत हो सकता है.
नहीं
नेएन ट्रैप
जब ट्रेनिंग के दौरान आपके मॉडल का एक नंबर, NaN बन जाता है, तो आपके मॉडल के कई या दूसरे सभी नंबर, आखिर में NaN बन जाते हैं.
NaN, Not a Number का छोटा रूप होता है.
नैचुरल लैंग्वेज अंडरस्टैंडिंग
उपयोगकर्ता ने क्या टाइप किया है या क्या कहा है, इस आधार पर उपयोगकर्ता का इरादा तय करना. उदाहरण के लिए, सर्च इंजन, आम भाषा की समझ का इस्तेमाल करके यह तय करता है कि उपयोगकर्ता क्या टाइप कर रहा है या उसने क्या खोजा है.
नेगेटिव क्लास
बाइनरी क्लासिफ़िकेशन में, एक क्लास को पॉज़िटिव और दूसरी क्लास को नेगेटिव कहा जाता है. पॉज़िटिव क्लास वह चीज़ या इवेंट है जिसके लिए मॉडल टेस्ट कर रहा है और नेगेटिव क्लास, इसकी दूसरी संभावना होती है. उदाहरण के लिए:
- किसी मेडिकल टेस्ट में नेगेटिव क्लास "ट्यूमर नहीं" हो सकती है.
- ईमेल की कैटगरी तय करने वाली सुविधा में, नेगेटिव क्लास "स्पैम नहीं" हो सकती है.
पॉज़िटिव क्लास से अलग करें.
नेगेटिव सैंपलिंग
उम्मीदवार के सैंपलिंग के लिए समानार्थी शब्द.
न्यूरल आर्किटेक्चर सर्च (एनएएस)
न्यूरल नेटवर्क के आर्किटेक्चर को अपने-आप डिज़ाइन करने की तकनीक. एनएएस एल्गोरिदम, न्यूरल नेटवर्क को ट्रेनिंग देने में लगने वाले समय और रिसॉर्स को कम कर सकते हैं.
NAS आम तौर पर इनका इस्तेमाल करता है:
- सर्च स्पेस, जो संभावित आर्किटेक्चर का सेट होता है.
- एक फ़िटनेस फ़ंक्शन, जो यह मापता है कि कोई खास आर्किटेक्चर किसी दिए गए टास्क पर कितना अच्छा परफ़ॉर्म करता है.
एनएएस एल्गोरिदम अक्सर संभावित आर्किटेक्चर के एक छोटे सेट के साथ शुरू होते हैं. साथ ही, जैसे-जैसे एल्गोरिदम को इस बारे में ज़्यादा जानकारी मिलती है कि कौनसे आर्किटेक्चर असरदार हैं, खोज की जगह धीरे-धीरे बढ़ती जाती है. आम तौर पर, फ़िटनेस फ़ंक्शन किसी ट्रेनिंग सेट के आर्किटेक्चर की परफ़ॉर्मेंस पर आधारित होता है. आम तौर पर, एल्गोरिदम को रीइन्फ़ोर्समेंट लर्निंग तकनीक का इस्तेमाल करके ट्रेनिंग दी जाती है.
एनएएस एल्गोरिदम की मदद से, कई तरह के कामों के लिए अच्छी परफ़ॉर्मेंस वाली आर्किटेक्चर की खोज की जा सकती है. इनमें इमेज क्लासिफ़िकेशन, टेक्स्ट की कैटगरी तय करना, और मशीन से अनुवाद करना शामिल है.
न्यूरल नेटवर्क
कोई model, जिसमें कम से कम एक model हो. डीप न्यूरल नेटवर्क एक तरह का न्यूरल नेटवर्क है, जिसमें एक से ज़्यादा छिपी हुई लेयर होती हैं. उदाहरण के लिए, नीचे दिया गया डायग्राम, दो छिपी हुई लेयर वाला डीप न्यूरल नेटवर्क दिखाता है.

किसी न्यूरल नेटवर्क में मौजूद हर न्यूरॉन, अगली लेयर के सभी नोड से जुड़ा होता है. उदाहरण के लिए, पिछले डायग्राम में देखें कि पहली छिपी हुई लेयर में मौजूद तीन न्यूरॉन, दूसरी छिपी हुई लेयर में मौजूद दोनों न्यूरॉन से अलग-अलग कनेक्ट करते हैं.
कंप्यूटर पर लागू किए गए न्यूरल नेटवर्क को कभी-कभी आर्टिफ़िशियल न्यूरल नेटवर्क कहा जाता है, ताकि इन्हें दिमाग और दूसरे नर्वस सिस्टम में पाए जाने वाले न्यूरल नेटवर्क से अलग किया जा सके.
कुछ न्यूरल नेटवर्क अलग-अलग सुविधाओं और लेबल के बीच बहुत जटिल नॉनलीनियर नेटवर्क की नकल कर सकते हैं.
कॉन्वोलूशनल न्यूरल नेटवर्क और बार-बार होने वाला न्यूरल नेटवर्क भी देखें.
न्यूरॉन
मशीन लर्निंग में, किसी न्यूरल नेटवर्क की छिपी हुई लेयर में एक अलग यूनिट. हर न्यूरॉन, ये दो चरणों वाली कार्रवाई करता है:
- यह फ़ंक्शन, इनपुट वैल्यू के वेट किए गए योग को उनसे जुड़े भार से गुणा करके निकाला जाता है.
- किसी ऐक्टिवेशन फ़ंक्शन के इनपुट के तौर पर वेटेड योग को पास करता है.
पहली छिपी हुई लेयर में मौजूद न्यूरॉन, इनपुट लेयर में मौजूद सुविधा की वैल्यू से इनपुट स्वीकार करता है. पहली छिपी हुई लेयर के अलावा, किसी छिपी हुई लेयर में मौजूद न्यूरॉन, पिछली छिपी हुई लेयर में मौजूद न्यूरॉन के इनपुट स्वीकार करता है. उदाहरण के लिए, दूसरी छिपी हुई लेयर में मौजूद न्यूरॉन, पहली छिपी हुई लेयर में मौजूद न्यूरॉन के इनपुट स्वीकार करता है.
नीचे दिए गए उदाहरण में दो न्यूरॉन और उनके इनपुट को हाइलाइट किया गया है.

एक तंत्रिका नेटवर्क में मौजूद न्यूरॉन, दिमाग और नर्वस सिस्टम के अन्य भागों में न्यूरॉन के व्यवहार की नकल करता है.
एन-ग्राम
N शब्दों का ऑर्डर किया गया क्रम. उदाहरण के लिए, पूरी तरह से पागलपन में 2-ग्राम होता है. क्योंकि ऑर्डर प्रासंगिक होता है, इसलिए पागलों की तरह शब्दों की दो ग्रामर सच में पागलपन से अलग होती हैं.
| नहीं | इस तरह के एन-ग्राम के लिए नाम | उदाहरण |
|---|---|---|
| 2 | बड़ाम या 2-ग्राम | जाना, जाना, दोपहर का खाना, खाना |
| 3 | ट्राइग्राम या 3-ग्राम | बहुत ज़्यादा खाया, तीन अंधे चूहे, बेल टोल |
| 4 | 4 ग्राम | पार्क में टहलना, हवा में धूल भरी आंधी, बच्चे ने दाल खा ली |
भाषा की स्वाभाविक समझ वाले कई मॉडल, N-ग्राम की मदद से यह अनुमान लगाते हैं कि उपयोगकर्ता कौनसा शब्द टाइप करेगा या कौनसा बोलेगा. उदाहरण के लिए, मान लें कि किसी उपयोगकर्ता ने तीन ब्लाइंड टाइप किया. त्रिकोणमिति पर आधारित एनएलयू मॉडल यह अनुमान लगा सकता है कि उपयोगकर्ता को अगली बार माइस टाइप करना होगा.
शब्दों के बैग, जो शब्दों के क्रम में नहीं होते हैं, उन्हें N-ग्राम से अलग करें.
एनएलयू
प्राकृतिक भाषा समझने की सुविधा के लिए छोटा नाम.
नोड (डिसिज़न ट्री)
डिसिज़न ट्री में, किसी भी स्थिति या लीफ़ के बारे में जानकारी शामिल होती है.

नोड (न्यूरल नेटवर्क)
छिपी हुई लेयर में एक न्यूरॉन.
नोड (TensorFlow ग्राफ़)
TensorFlow के ग्राफ़ में की गई कार्रवाई.
शोर
मोटे तौर पर, ऐसी कोई भी चीज़ जो डेटासेट में सिग्नल को छिपा देती है. शोर को कई तरीकों से डेटा में शामिल किया जा सकता है. उदाहरण के लिए:
- रेटिंग देने वाले लोग, वीडियो को लेबल करने में गलती करते हैं.
- इंसान और इंस्ट्रुमेंट, सुविधाओं की वैल्यू को गलत तरीके से रिकॉर्ड या मिटा देते हैं.
नॉन-बाइनरी शर्त
एक ऐसी स्थिति जिसमें दो से ज़्यादा संभावित नतीजे हो सकते हैं. उदाहरण के लिए, नीचे दी गई नॉन-बाइनरी शर्त के तीन संभावित नतीजे होते हैं:

नॉनलीनियर
दो या ज़्यादा वैरिएबल के बीच का ऐसा संबंध जिसे सिर्फ़ जोड़ और गुणा करके नहीं दिखाया जा सकता. लीनियर रिलेशनशिप को लाइन के तौर पर दिखाया जा सकता है. लीनियर रिलेशनशिप को लाइन के तौर पर नहीं दिखाया जा सकता. उदाहरण के लिए, ऐसे दो मॉडल पर विचार करें जिनमें से हर एक एक सुविधा को एक लेबल से जोड़ता है. बाईं ओर वाला मॉडल लीनियर है और दाईं ओर मौजूद मॉडल नॉनलीनियर है:

नॉन-रिस्पॉन्स बायस
चुनाव के मापदंड देखें.
नॉनस्टेशनरिटी
ऐसी सुविधा जिसकी वैल्यू एक या उससे ज़्यादा डाइमेंशन में बदलती हैं. आम तौर पर, यह वैल्यू समय के हिसाब से बदल जाती है. उदाहरण के लिए, नॉनस्टेशनरिटी के इन उदाहरणों पर गौर करें:
- किसी स्टोर में बेचे जाने वाले स्विमसूट की संख्या मौसम के हिसाब से अलग-अलग होती है.
- किसी इलाके में उगाए गए किसी खास फल की संख्या, साल के ज़्यादातर समय शून्य होती है. हालांकि, थोड़े समय के लिए यह काफ़ी ज़्यादा होती है.
- जलवायु परिवर्तन की वजह से, सालाना औसत तापमान में बदलाव हो रहा है.
स्टेशनेरिटी के कंट्रास्ट से.
नॉर्मलाइज़ेशन
मोटे तौर पर, किसी वैरिएबल की असल वैल्यू की रेंज को वैल्यू की स्टैंडर्ड रेंज में बदलने की प्रोसेस, जैसे कि:
- -1 से +1
- 0 से 1
- सामान्य डिस्ट्रिब्यूशन
उदाहरण के लिए, मान लें कि किसी सुविधा की वैल्यू की असल रेंज 800 से 2,400 है. फ़ीचर इंजीनियरिंग के हिस्से के तौर पर, आपके पास वास्तविक वैल्यू को सामान्य रेंज तक सामान्य करने का विकल्प होता है, जैसे कि -1 से +1.
फ़ीचर इंजीनियरिंग में, सामान्य बनाना एक सामान्य टास्क है. फ़ीचर वेक्टर की हर संख्या वाली सुविधा की रेंज एक जैसी होने पर, मॉडल आम तौर पर तेज़ी से ट्रेनिंग देते हैं (और बेहतर अनुमान लगाते हैं).
नॉवल्टी डिटेक्शन
यह तय करने की प्रोसेस कि नया (नॉवल) उदाहरण उसी डिस्ट्रिब्यूशन से मिला है जिससे ट्रेनिंग सेट मिला है. दूसरे शब्दों में, ट्रेनिंग सेट पर ट्रेनिंग के बाद, नॉवल्टी डिटेक्शन की मदद से यह पता चलता है कि कोई नया उदाहरण (अनुमान के दौरान या अतिरिक्त ट्रेनिंग के दौरान) क्या कोई आउटलायर है.
आउटलायर डिटेक्शन के साथ कंट्रास्ट.
संख्या वाला डेटा
सुविधाएं को पूर्णांक या असल वैल्यू वाली संख्याओं के तौर पर दिखाया जाता है. उदाहरण के लिए, घर के मूल्यांकन वाला मॉडल शायद घर के साइज़ (वर्ग फ़ीट या वर्ग मीटर में) को संख्या वाले डेटा के तौर पर दिखाएगा. किसी सुविधा को संख्या वाले डेटा के तौर पर दिखाने से यह पता चलता है कि सुविधा की वैल्यू का लेबल से गणितीय संबंध है. इसका मतलब है कि किसी घर में मौजूद वर्ग मीटर की संख्या का इस घर की वैल्यू से कुछ हद तक गणितीय संबंध हो सकता है.
सभी पूर्णांक डेटा को संख्या वाले डेटा के तौर पर नहीं दिखाया जाना चाहिए. उदाहरण के लिए, दुनिया के कुछ हिस्सों में पिन कोड पूर्णांक होते हैं. हालांकि, मॉडल में पूर्णांक पिन कोड को न्यूमेरिक डेटा के तौर पर नहीं दिखाया जाना चाहिए. ऐसा इसलिए, क्योंकि 20000 का पिन कोड 10,000 पिन कोड के मुकाबले दो बार (या आधा) नहीं है. इसके अलावा, हालांकि अलग-अलग पिन कोड रीयल एस्टेट की अलग-अलग वैल्यू से जुड़े होते हैं, फिर भी हम यह नहीं मान सकते कि पिन कोड 20000 पर रीयल एस्टेट की वैल्यू, पिन कोड 10000 में रीयल एस्टेट की वैल्यू के मुकाबले दोगुनी है.
पिन कोड को कैटगरिकल डेटा के तौर पर दिखाया जाना चाहिए.
संख्या वाली सुविधाओं को कभी-कभी लगातार सुविधाएं कहा जाता है.
NumPy
यह एक ओपन सोर्स मैथ लाइब्रेरी है, जो Python में बेहतर अरे ऑपरेशन की सुविधा देती है. pandas को NumPy पर बनाया गया है.
O
कैंपेन का मकसद
वह मेट्रिक जिसे आपका एल्गोरिदम ऑप्टिमाइज़ करने की कोशिश कर रहा है.
मकसद फ़ंक्शन
गणित का वह फ़ॉर्मूला या मेट्रिक जिसे मॉडल ऑप्टिमाइज़ करना है. उदाहरण के लिए, लीनियर रिग्रेशन का मकसद फ़ंक्शन आम तौर पर, मीन स्क्वेयर्ड लॉस होता है. इसलिए, लीनियर रिग्रेशन मॉडल को ट्रेनिंग देते समय, ट्रेनिंग का मकसद मीन स्क्वेयर लॉस को कम करना होता है.
कुछ मामलों में, लक्ष्य मकसद फ़ंक्शन को बढ़ाना होता है. उदाहरण के लिए, अगर ऑब्जेक्ट का मकसद फ़ंक्शन सटीक है, तो उसका लक्ष्य ज़्यादा से ज़्यादा सटीक काम करना होता है.
नुकसान भी देखें.
तिरछी स्थिति
डिसिज़न ट्री में, एक ऐसी स्थिति होती है जिसमें एक से ज़्यादा सुविधा शामिल होती है. उदाहरण के लिए, अगर ऊंचाई और चौड़ाई दोनों विशेषताएं हैं, तो यहां एक तिरछी शर्त है:
height > width
ऐक्सिस की अलाइन स्थिति के बीच कंट्रास्ट.
अॉफ़लाइन
स्टैटिक के लिए समानार्थी.
ऑफ़लाइन अनुमान
ऐसे मॉडल की प्रोसेस जो सुझावों का बैच जनरेट करती है और फिर उन अनुमानों को कैश मेमोरी (सेव) करती है. इसके बाद, ऐप्लिकेशन मॉडल को फिर से चलाने के बजाय, कैश मेमोरी से अनुमान को ऐक्सेस कर सकते हैं.
उदाहरण के लिए, ऐसा मॉडल इस्तेमाल करें जो हर चार घंटे में एक बार स्थानीय मौसम के पूर्वानुमान (अनुमान) जनरेट करता हो. हर मॉडल के चलने के बाद, सिस्टम स्थानीय मौसम के सभी पूर्वानुमान को कैश मेमोरी में सेव कर लेता है. मौसम की जानकारी देने वाले ऐप्लिकेशन, कैश मेमोरी से अनुमान लगवाते हैं.
ऑफ़लाइन अनुमान को स्टैटिक अनुमान भी कहा जाता है.
ऑनलाइन अनुमान से अंतर होना चाहिए.
वन-हॉट एन्कोडिंग
कैटगरी वाले डेटा को वेक्टर के तौर पर दिखाना, जिसमें:
- एक एलिमेंट 1 पर सेट है.
- अन्य सभी एलिमेंट 0 पर सेट हैं.
वन-हॉट एन्कोडिंग का इस्तेमाल आम तौर पर, उन स्ट्रिंग या आइडेंटिफ़ायर को दिखाने के लिए किया जाता है जिनमें संभावित वैल्यू का सीमित सेट होता है.
उदाहरण के लिए, मान लें कि Scandinavia नाम की किसी कैटगरी वाली सुविधा के पांच संभावित वैल्यू हो सकती हैं:
- "डेनमार्क"
- "स्वीडन"
- "नॉर्वे"
- "फ़िनलैंड"
- "आइसलैंड"
वन-हॉट एन्कोडिंग में इन दोनों वैल्यू को इस तरह दिखाया जा सकता है:
| country | वेक्टर | ||||
|---|---|---|---|---|---|
| "डेनमार्क" | 1 | 0 | 0 | 0 | 0 |
| "स्वीडन" | 0 | 1 | 0 | 0 | 0 |
| "नॉर्वे" | 0 | 0 | 1 | 0 | 0 |
| "फ़िनलैंड" | 0 | 0 | 0 | 1 | 0 |
| "आइसलैंड" | 0 | 0 | 0 | 0 | 1 |
वन-हॉट एन्कोडिंग की मदद से, कोई मॉडल पांच देशों में से हर एक के आधार पर अलग-अलग कनेक्शन सीख सकता है.
किसी सुविधा को संख्यात्मक डेटा के तौर पर दिखाना, वन-हॉट एन्कोडिंग का विकल्प है. माफ़ करें, स्कैंडिनेवियन देशों को अंकों में दिखाना सही नहीं है. उदाहरण के लिए, इस संख्या को देखें:
- "डेनमार्क" 0 है
- "स्वीडन" एक है
- "नॉर्वे" दो है
- "फ़िनलैंड" 3 है
- "आइसलैंड" चार है
न्यूमेरिक एन्कोडिंग की मदद से, मॉडल रॉ संख्याओं को गणितीय तरीके से समझेगा और उनके आधार पर ट्रेनिंग करने की कोशिश करेगा. हालांकि, नॉर्वे की तुलना में आइसलैंड असल में किसी चीज़ से दोगुना (या आधा) नहीं है, इसलिए यह मॉडल कुछ अजीब निष्कर्षों पर पहुंचेगा.
वन-शॉट लर्निंग
एक मशीन लर्निंग अप्रोच, जिसका इस्तेमाल अक्सर ऑब्जेक्ट क्लासिफ़िकेशन के लिए किया जाता है. इसे ट्रेनिंग के एक ही उदाहरण से, कैटगरी तय करने वाले असरदार तरीकों को सीखने के लिए डिज़ाइन किया गया है.
कुछ समय के लिए आसानी से सीखें और पहले से तैयार मशीन लर्निंग के बारे में भी जानें.
वन-शॉट प्रॉम्प्ट
एक ऐसा प्रॉम्प्ट जिसमें एक उदाहरण शामिल हो. इसमें बताया गया है कि बड़े लैंग्वेज मॉडल को जवाब कैसे देना चाहिए. उदाहरण के लिए, इस प्रॉम्प्ट में एक उदाहरण दिया गया है. इसमें बड़े लैंग्वेज मॉडल को दिखाया गया है कि इसे किसी क्वेरी का जवाब कैसे देना चाहिए.
| एक प्रॉम्प्ट के हिस्से | ज़रूरी जानकारी |
|---|---|
| किसी चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब एलएलएम से देना है. |
| फ़्रांस: EUR | एक उदाहरण. |
| भारत: | असल क्वेरी. |
वन-शॉट प्रॉम्प्ट की तुलना नीचे दिए गए शब्दों से करें:
एक-बनाम-सभी
N क्लास की कैटगरी तय करने में हुई समस्या को देखते हुए, ऐसा समाधान जिसमें N अलग बाइनरी क्लासिफ़ायर शामिल हैं—हर संभावित नतीजे के लिए एक बाइनरी क्लासिफ़ायर. उदाहरण के लिए, अगर मॉडल को जानवर, सब्ज़ी या खनिज के रूप में अलग-अलग कैटगरी में बांटा गया है, तो एक-बनाम सभी समाधान देने पर तीन अलग-अलग बाइनरी क्लासिफ़ायर दिए जाएंगे:
- जानवर है बनाम जानवर नहीं
- सब्ज़ी बनाम सब्ज़ी नहीं
- मिनरल बनाम मिनरल नहीं
online
डाइनैमिक का समानार्थी शब्द.
ऑनलाइन अनुमान
मांग पर अनुमान जनरेट करना. उदाहरण के लिए, मान लें कि कोई ऐप्लिकेशन किसी मॉडल के लिए इनपुट पास करता है और अनुमान के लिए अनुरोध जारी करता है. ऑनलाइन अनुमान का इस्तेमाल करने वाला सिस्टम, अनुरोध का जवाब देता है. इसके लिए, मॉडल को रन किया जाता है और ऐप्लिकेशन को सुझाव के तौर पर दिखाया जाता है.
ऑफ़लाइन अनुमान से तुलना करें.
कार्रवाई (ऑप)
TensorFlow में, ऐसी कोई भी प्रोसेस जो Tensor बनाता है, उसमें बदलाव करता है या उसे बंद करता है. उदाहरण के लिए, मैट्रिक्स गुणा एक ऐसी कार्रवाई है जिसमें दो टेन्सर को इनपुट के तौर पर लिया जाता है और आउटपुट के तौर पर एक टेन्सर जनरेट होता है.
ओटैक्स
JAX के लिए, ग्रेडिएंट प्रोसेसिंग और ऑप्टिमाइज़ेशन लाइब्रेरी. Optax, रिसर्च में मदद करने के लिए ऐसे बिल्डिंग ब्लॉक मुहैया कराता है जिन्हें कस्टम तरीके से जोड़ा जा सके. इससे, डीप न्यूरल नेटवर्क जैसे पैरामेट्रिक मॉडल को ऑप्टिमाइज़ करने में मदद मिलती है. अन्य लक्ष्यों में ये शामिल हैं:
- यह मुख्य कॉम्पोनेंट को पढ़ने लायक, जांचा-परखा, और बेहतर तरीके से लागू करने की सुविधा देता है.
- कम लेवल की सामग्री को कस्टम ऑप्टिमाइज़र (या दूसरे ग्रेडिएंट प्रोसेसिंग कॉम्पोनेंट) में जोड़ना संभव बनाकर उत्पादकता को बेहतर बनाना.
- सभी के लिए योगदान करना आसान बनाकर नए विचारों को अपनाने में तेज़ी लाना.
ऑप्टिमाइज़र
ग्रेडिएंट डिसेंट एल्गोरिदम को खास तौर पर लागू करना. लोकप्रिय ऑप्टिमाइज़र में ये शामिल हैं:
- AdaGrad, जिसका मतलब है, ADAptive GRADient ढलान.
- एडम, जिसका पूरा नाम ADAptive with Momentum है.
आउट-ग्रुप एक ही तरह का भेदभाव
उनके नज़रिए, मान्यताओं, व्यक्तित्व, और अन्य विशेषताओं की तुलना करते समय, ग्रुप के सदस्यों को ग्रुप में शामिल सदस्यों के मुकाबले ज़्यादा एक जैसा दिखने लगता है. इन-ग्रुप का मतलब है, वे लोग जिनके साथ अक्सर इंटरैक्ट किया जाता है; आउट-ग्रुप का मतलब उन लोगों से है जिनके साथ आम तौर पर इंटरैक्ट नहीं किया जाता. अगर लोगों से ग्रुप के बाहर के एट्रिब्यूट की वैल्यू देकर डेटासेट बनाया जाता है, तो हो सकता है कि उनमें शामिल जानकारी को समझना मुश्किल हो. साथ ही, वे उन एट्रिब्यूट की तुलना में ज़्यादा स्टीरियोटाइप हो सकते हैं जिन्हें मीटिंग में शामिल लोगों ने अपने ग्रुप के लोगों के लिए सूची में शामिल किया है.
उदाहरण के लिए, लिलिपुटियन लोगों के घरों के बारे में ज़्यादा बारीकी से जानकारी दे सकते हैं. इसके लिए वे वास्तुकला की स्टाइल, खिड़कियों, दरवाज़े, और साइज़ में छोटे-छोटे अंतर दिखाते हैं. हालांकि, यही लिलीपुटियन सिर्फ़ यह एलान कर सकता है कि ब्रोबडिंगनाजियन सभी एक जैसे घरों में रहते हैं.
आउट-ग्रुप एक ही तरह का भेदभाव, एक तरह का ग्रुप एट्रिब्यूशन बायस है.
इन-ग्रुप बायस भी देखें.
आउटलायर डिटेक्शन
किसी ट्रेनिंग सेट में, आउटलायर की पहचान करने की प्रोसेस.
नई सुविधाओं की पहचान से कंट्रास्ट अलग होना चाहिए.
जिसकी परफ़ॉर्मेंस सामान्य से अलग रही
मान ज़्यादातर अन्य मानों से दूर हैं. मशीन लर्निंग में, इनमें से कोई भी आउटलायर:
- वह डेटा डालें जिसके मान मीन से करीब 3 मानक विचलनों से ज़्यादा हैं.
- उच्च निरपेक्ष मान वाले भार.
- अनुमानित वैल्यू, असल वैल्यू से ज़्यादा दूर होती हैं.
उदाहरण के लिए, मान लें कि widget-price किसी खास मॉडल की एक सुविधा है.
मान लें कि औसत widget-price, 7 यूरो है और मानक विचलन 1 यूरो है. उदाहरण के लिए, 12 यूरो या 2 यूरो के widget-price को आउटलायर माना जाएगा, क्योंकि उनमें से हर एक कीमत, मीन से पांच मानक विचलन है.
आउटलायर अक्सर टाइपिंग की गलतियां या इनपुट से जुड़ी अन्य गलतियों की वजह से होते हैं. दूसरे मामलों में, अलग-अलग वजहों से गलतियां नहीं होतीं. ऐसा इसलिए है, क्योंकि मीन से पांच मानक विचलन बहुत कम देखने को मिलते हैं, लेकिन नामुमकिन नहीं हैं.
आउटलायर की वजह से, मॉडल ट्रेनिंग में अक्सर समस्याएं आती हैं. क्लिपिंग, आउटलायर को मैनेज करने का एक तरीका है.
आउट-ऑफ़-बैग इवैलुएशन (ओओबी इवैलुएशन)
एक ऐसा तरीका जिससे डिसिज़न ट्री की क्वालिटी का आकलन किया जा सकता है. इसके लिए, हर डिसिज़न ट्री की जांच उन उदाहरणों से करें जो डिसिज़न ट्री के ट्रेनिंग के दौरान इस्तेमाल नहीं किए गए थे. उदाहरण के लिए, यहां दिए गए डायग्राम में ध्यान दें कि सिस्टम, हर डिसिज़न ट्री को करीब दो-तिहाई उदाहरणों पर ट्रेनिंग देता है और फिर बचे हुए एक तिहाई उदाहरणों का आकलन करता है.

आउट-ऑफ़-बैग इवैलुएशन, क्रॉस-वैलिडेशन तकनीक का एक कंप्यूटेशनल (सही तरीके से) और पुराने अनुमान है. क्रॉस-वैलिडेशन के दौरान, क्रॉस-वैलिडेशन के हर राउंड के लिए एक मॉडल को ट्रेनिंग दी जाती है (उदाहरण के लिए, 10 मॉडल को 10-फ़ोल्ड क्रॉस-वैलिडेशन में ट्रेनिंग दी गई है). OOB के आकलन से एक मॉडल को ट्रेन किया जाता है. बैगिंग, ट्रेनिंग के दौरान हर ट्री का कुछ डेटा रोक देती है. इसलिए, OOB इवैलुएशन इस डेटा का इस्तेमाल क्रॉस-वैलिडेशन का अनुमान लगाने के लिए कर सकता है.
आउटपुट लेयर
न्यूरल नेटवर्क की "फ़ाइनल" लेयर. आउटपुट लेयर में अनुमान होता है.
नीचे दिए गए उदाहरण में, इनपुट लेयर, दो छिपी हुई लेयर, और एक आउटपुट लेयर वाला एक छोटा डीप न्यूरल नेटवर्क दिखाया गया है:

ओवरफ़िटिंग
model से मेल खाने वाला model बनाना, ताकि मॉडल नए डेटा के लिए सही अनुमान न लगा पाए.
रेगुलराइज़ेशन की मदद से, ज़रूरत से ज़्यादा फ़िट बैठना कम हो सकता है. बड़े और अलग-अलग तरह के ट्रेनिंग सेट पर ट्रेनिंग से भी ओवरफ़िटिंग को कम किया जा सकता है.
ओवरसैंपलिंग
क्लास असंतुलित डेटासेट में, माइनरिटी क्लास के उदाहरण फिर से इस्तेमाल करें. इससे ट्रेनिंग सेट बेहतर तरीके से बनाया जा सकेगा.
उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन से जुड़ी ऐसी समस्या पर विचार करें जिसमें ज़्यादातर क्लास और अल्पसंख्यक क्लास का अनुपात 5,000:1 है. अगर डेटासेट में दस लाख उदाहरण शामिल हैं, तो उस डेटासेट में अल्पसंख्यक वर्ग के सिर्फ़ 200 उदाहरण शामिल हैं. हो सकता है कि असरदार ट्रेनिंग के लिए ये बहुत कम उदाहरण हों. इस कमी से निपटने के लिए, आपको उन 200 उदाहरणों को कई बार ओवरसैंपल (फिर से इस्तेमाल) करना पड़ सकता है. इससे, काम की ट्रेनिंग के लिए ज़रूरत के मुताबिक उदाहरण मिल सकते हैं.
ओवरलैप करते समय, आपको ओवरफ़िटिंग को लेकर सावधान रहना होगा.
अंडरसैंपलिंग से कंट्रास्ट अलग करें.
P
पैक किया गया डेटा
डेटा को ज़्यादा बेहतर तरीके से सेव करने का तरीका.
पैक किया गया डेटा, कंप्रेस किए गए फ़ॉर्मैट का इस्तेमाल करके या किसी ऐसे तरीके से डेटा सेव करता है जिससे डेटा को बेहतर तरीके से ऐक्सेस किया जा सकता है. पैक किया गया डेटा, इसे ऐक्सेस करने के लिए ज़रूरी मेमोरी और कंप्यूटेशन की संख्या को कम करता है. इससे, तेज़ ट्रेनिंग और मॉडल का अनुमान लगाने में आसानी होती है.
पैक किए गए डेटा का इस्तेमाल अक्सर अन्य तकनीकों के साथ किया जाता है. जैसे, डेटा को बेहतर बनाने की सुविधा और रेगुलराइज़ेशन. इससे मॉडल की परफ़ॉर्मेंस बेहतर हो सकती है.
पांडा
numpy पर ऊपर बना कॉलम-ओरिएंटेड डेटा विश्लेषण एपीआई. TensorFlow समेत कई मशीन लर्निंग फ़्रेमवर्क, पांडा के डेटा स्ट्रक्चर को इनपुट के तौर पर इस्तेमाल करते हैं. ज़्यादा जानकारी के लिए, pandas के दस्तावेज़ पढ़ें.
पैरामीटर
ऐसे वेट और पूर्वाग्रह जो मॉडल को ट्रेनिंग के दौरान सीखते हैं. उदाहरण के लिए, लीनियर रिग्रेशन मॉडल के पैरामीटर में, इस फ़ॉर्मूला में बायस (b) और सभी वेट (w1, w2 वगैरह) शामिल होते हैं:
वहीं दूसरी ओर, हाइपर पैरामीटर वे वैल्यू हैं जो मॉडल को आप (या हाइपर पैरामीटर ट्यूनिंग सेवा) दी जाती हैं. उदाहरण के लिए, लर्निंग रेट हाइपर पैरामीटर है.
पैरामीटर-कुशल ट्यूनिंग
एक बड़े नेटवर्क को फ़ाइन-ट्यून करने की तकनीकों का सेट फ़ाइन-ट्यूनिंग की तुलना में, पहले से ट्रेन की गई भाषा के मॉडल (पीएलएम) को ज़्यादा बेहतर तरीके से इस्तेमाल करना. आम तौर पर, पैरामीटर के हिसाब से ट्यून करने की सुविधा, फ़ुल-ट्यूनिंग के मुकाबले काफ़ी कम पैरामीटर दिखाती है. हालांकि, आम तौर पर यह बड़े लैंग्वेज मॉडल की तरह काम करती है, जो फ़ुल ट्यूनिंग से बने बड़े लैंग्वेज मॉडल की तरह ही काम करती है.
पैरामीटर-कुशल ट्यूनिंग की इनके साथ तुलना करें:
पैरामीटर-कुशल ट्यूनिंग को पैरामीटर-कुशल फ़ाइन-ट्यूनिंग भी कहा जाता है.
पैरामीटर सर्वर (PS)
ऐसा जॉब जो किसी डिस्ट्रिब्यूटेड सेटिंग में, मॉडल के पैरामीटर को ट्रैक करता है.
पैरामीटर में अपडेट
ट्रेनिंग के दौरान, किसी मॉडल के पैरामीटर में बदलाव करने की प्रोसेस. आम तौर पर, यह ग्रेडिएंट डिसेंट के एक बार में किया जाता है.
आंशिक तौर पर डेरिवेटिव
ऐसा डेरिवेटिव, जिसमें एक वैरिएबल को छोड़कर बाकी सभी वैरिएबल को कॉन्स्टेंट माना जाता है. उदाहरण के लिए, x के हिसाब से f(x, y) का पार्शियल डेरिवेटिव, f का व्युत्पन्न है. इसे अकेले x का फ़ंक्शन माना जाता है (इसका मतलब है कि y कॉन्सटेंट है). x के हिसाब से f का आंशिक डेरिवेटिव सिर्फ़ इस बात पर ध्यान देता है कि x कैसे बदल रहा है और समीकरण के दूसरे सभी वैरिएबल को अनदेखा कर देता है.
पार्टिसिपेशन बायस
गैर-प्रतिक्रिया पूर्वाग्रह के लिए समानार्थी. चुनाव के मापदंड देखें.
बंटवारे की रणनीति
वह एल्गोरिदम जिससे वैरिएबल को पैरामीटर सर्वर में बांटा जाता है.
पैक्स
यह एक प्रोग्रामिंग फ़्रेमवर्क है, जिसे बड़े पैमाने पर न्यूरल नेटवर्क मॉडल की ट्रेनिंग देने के लिए डिज़ाइन किया गया है. इसमें कई TPU ऐक्सेलरेटर चिप स्लाइस या पॉड शामिल हैं.
Pax को Flax पर बनाया गया है. इसे JAX पर बनाया गया है.

पर्सेप्ट्रॉन
ऐसा सिस्टम (हार्डवेयर या सॉफ़्टवेयर) जो एक या उससे ज़्यादा इनपुट वैल्यू लेता है, इनपुट के वेटेड योग पर फ़ंक्शन चलाता है और सिंगल आउटपुट वैल्यू को कंप्यूट करता है. मशीन लर्निंग में, यह फ़ंक्शन आम तौर पर नॉनलीनियर होता है, जैसे कि ReLU, sigmoid या tanh. उदाहरण के लिए, नीचे दिया गया पर्सेप्ट्रॉन, तीन इनपुट वैल्यू को प्रोसेस करने के लिए सिग्मॉइड फ़ंक्शन का इस्तेमाल करता है:
नीचे दिए गए उदाहरण में, पर्सेप्ट्रॉन को तीन इनपुट के बारे में बताया गया है. पर्सेप्ट्रॉन के अंदर जाने से पहले, हर इनपुट में वज़न के हिसाब से बदलाव किया जाता है:

न्यूरल नेटवर्क में पर्सेप्ट्रॉन, न्यूरॉन होते हैं.
प्रदर्शन
ओवरलोडेड टर्म जिसका ये मतलब है:
- सॉफ़्टवेयर इंजीनियरिंग में स्टैंडर्ड का मतलब. नाम: यह सॉफ़्टवेयर कितनी तेज़ी से (या बेहतर तरीके से) काम करता है?
- मशीन लर्निंग का मतलब. यहां परफ़ॉर्मेंस से इस सवाल का जवाब मिलता है: यह model कितना सही है? इसका मतलब है कि मॉडल के अनुमान कितने अच्छे हैं?
परम्यूटेशन वैरिएबल का महत्व
यह एक तरह का वैरिएबल अहमियत है, जो सुविधा की वैल्यू को लागू करने के बाद, मॉडल के अनुमान की गड़बड़ी में होने वाली बढ़ोतरी का आकलन करता है. क्रम में होने वाले वैरिएबल का महत्व, मॉडल-इंडिपेंडेंट मेट्रिक है.
हैरानी
एक तरीका, जिससे पता चलता है कि कोई model अपना टास्क कितनी अच्छी तरह पूरा कर रहा है. उदाहरण के लिए, मान लीजिए कि आपका टास्क किसी ऐसे शब्द के पहले कुछ अक्षर पढ़ना है जिसे कोई उपयोगकर्ता फ़ोन के कीबोर्ड पर टाइप कर रहा है. साथ ही, आपको पूरे होने वाले संभावित शब्दों की सूची देनी है. हैरानी के तौर पर, P. इस टास्क में, अनुमान लगाने की संख्या के बारे में बताया जाना चाहिए. इससे आपकी सूची में वह असल शब्द शामिल हो सकेगा जिसे उपयोगकर्ता टाइप करना चाहता है.
किसी समस्या को क्रॉस-एंट्रॉपी से इस तरह से जोड़ा जा सकता है:
पाइपलाइन
मशीन लर्निंग एल्गोरिदम से जुड़ा इंफ़्रास्ट्रक्चर. पाइपलाइन में, डेटा इकट्ठा करना, डेटा को ट्रेनिंग डेटा फ़ाइलों में डालना, एक या उससे ज़्यादा मॉडल को ट्रेनिंग देना, और मॉडल को प्रोडक्शन में एक्सपोर्ट करना शामिल है.
पाइपलाइनिंग
मॉडल समानता का एक रूप, जिसमें मॉडल की प्रोसेसिंग को लगातार चरणों में बांटा जाता है और हर चरण को एक अलग डिवाइस पर चलाया जाता है. जब कोई चरण एक बैच को प्रोसेस करता है, तब पिछला चरण अगले बैच पर काम कर सकता है.
स्टेज की गई ट्रेनिंग भी देखें.
पिजित
एक JAX फ़ंक्शन, जो कई ऐक्सेलरेटर चिप में चलाने के लिए कोड को बांटता है. उपयोगकर्ता, pjit को एक फ़ंक्शन पास करता है, जो एक जैसे सिमैंटिक वाले फ़ंक्शन दिखाता है. हालांकि, उसे XLA कंप्यूटेशन के तौर पर कंपाइल किया जाता है. यह कंप्यूटेशन कई डिवाइसों (जैसे कि जीपीयू या TPU कोर) पर चलता है.
pjit की मदद से लोग, SPMD पार्टीशनर का इस्तेमाल करके, कंप्यूटेशन को फिर से लिखे बिना ही शार्ड कर सकते हैं.
मार्च 2023 तक, pjit को jit के साथ मर्ज कर दिया गया है. ज़्यादा जानकारी के लिए,
डिस्ट्रिब्यूटेड अरे और अपने-आप
पैरललाइज़ेशन
देखें.
पीएलएम
पहले से ट्रेन की गई भाषा के मॉडल का छोटा नाम.
पीमैप
एक JAX फ़ंक्शन, जो अलग-अलग इनपुट वैल्यू वाले कई मौजूदा हार्डवेयर डिवाइसों (सीपीयू, जीपीयू या TPU) पर इनपुट फ़ंक्शन की कॉपी चलाता है. pmap, SPMD पर निर्भर करता है.
policy
रीइन्फ़ोर्समेंट लर्निंग में, एजेंट की प्रॉबेब्लिस्टिक मैपिंग राज्यों से कार्रवाई तक.
पूल करना
किसी शुरुआती कॉन्वोल्यूशन लेयर से बने मैट्रिक्स (या मैट्रिक्स) को किसी छोटे मैट्रिक्स में कम करना. आम तौर पर, पूल किए गए हिस्से के लिए ज़्यादा से ज़्यादा या औसत वैल्यू का इस्तेमाल किया जाता है. उदाहरण के लिए, मान लें कि हमारे पास नीचे दिया गया 3x3 मैट्रिक्स है:
![3x3 मैट्रिक्स [[5,3,1], [8,2,5], [9,4,3].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=1&hl=hi)
कॉन्वोलूशनल ऑपरेशन की तरह ही, पूल करने की प्रक्रिया भी उस मैट्रिक्स को स्लाइस में बांटती है. इसके बाद, इस ऑपरेशन को स्ट्राइड की मदद से स्लाइड करती है. उदाहरण के लिए, मान लें कि पूलिंग ऑपरेशन कॉन्वलूशनल मैट्रिक्स को 1x1 स्ट्राइड के साथ 2x2 स्लाइस में विभाजित करता है. जैसा कि नीचे दिया गया डायग्राम दिखाया गया है, पूलिंग के चार ऑपरेशन होते हैं. मान लें कि पूलिंग की हर कार्रवाई में, उस स्लाइस में मौजूद चार की सबसे ज़्यादा वैल्यू चुनी जा सकती है:
![इनपुट मैट्रिक्स 3x3 है, जिसमें ये वैल्यू हैं: [[5,3,1], [8,2,5], [9,4,3]].
इनपुट मैट्रिक्स का सबसे ऊपर बाईं ओर मौजूद 2x2 सबमैट्रिक्स [[5,3], [8,2]] है. इसलिए,
सबसे ऊपर बाईं ओर मौजूद पूलिंग कार्रवाई की वैल्यू 8 होती है. यह वैल्यू 8, 3, 8, और 2 तक हो सकती है. इनपुट मैट्रिक्स का सबसे ऊपर दाईं ओर मौजूद 2x2 सबमैट्रिक्स [[3,1], [2,5]] है. इसलिए, सबसे ऊपर दाईं ओर मौजूद पूलिंग कार्रवाई की वैल्यू
5 है. इनपुट मैट्रिक्स का सबसे नीचे बाईं ओर मौजूद 2x2 सबमैट्रिक्स
[[8,2], [9,4]] है. इसलिए, सबसे नीचे बाईं ओर वाली पूलिंग कार्रवाई की वैल्यू
9 होती है. इनपुट मैट्रिक्स का सबसे नीचे दाईं ओर मौजूद 2x2 सबमैट्रिक्स
[[2,5], [4,3]] है. इसलिए, सबसे नीचे दाईं ओर वाली पूलिंग कार्रवाई की वैल्यू
5 होती है. कुल मिलाकर, पूलिंग की कार्रवाई से 2x2 मैट्रिक्स मिलता है
[[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=1&hl=hi)
पूल करने की सुविधा से, इनपुट मैट्रिक्स में अनुवादक इनवैरियंस को लागू करने में मदद मिलती है.
दृष्टि ऐप्लिकेशन के लिए पूलिंग को औपचारिक तौर पर स्पेशल पूलिंग कहा जाता है. टाइम सीरीज़ वाले ऐप्लिकेशन में, पूलिंग को टेंपोरल पूलिंग कहा जाता है. पूलिंग को अक्सर सबसैंपलिंग या डाउनसैंपलिंग कहा जाता है.
पोज़िशनल एन्कोडिंग
टोकन को एम्बेड करने के क्रम में, टोकन की जगह के बारे में जानकारी जोड़ने की तकनीक. ट्रांसफ़ॉर्मर मॉडल, क्रम के अलग-अलग हिस्सों के बीच के संबंध को बेहतर तरीके से समझने के लिए पोज़िशनल एन्कोडिंग का इस्तेमाल करते हैं.
पोज़िशनल एन्कोडिंग को आम तौर पर लागू करने के लिए, साइनसोइडल फ़ंक्शन का इस्तेमाल किया जाता है. (खास तौर पर, साइनसोइडल फ़ंक्शन की फ़्रीक्वेंसी और एम्प्लिट्यूड, क्रम में टोकन की स्थिति से तय किए जाते हैं.) इस तकनीक से, ट्रांसफ़ॉर्मर मॉडल उसकी पोज़िशन के आधार पर, क्रम के अलग-अलग हिस्सों में शामिल होना सीख पाता है.
पॉज़िटिव क्लास
वह क्लास जिसकी जांच की जा रही है.
उदाहरण के लिए, कैंसर मॉडल में पॉज़िटिव क्लास "ट्यूमर" हो सकती है. ईमेल की कैटगरी तय करने वाली सुविधा का पॉज़िटिव क्लास "स्पैम" हो सकता है.
नेगेटिव क्लास से उलट जानकारी दें.
पोस्ट-प्रोसेस
मॉडल चलने के बाद, मॉडल के आउटपुट में बदलाव करना. पोस्ट-प्रोसेसिंग का इस्तेमाल, मॉडल में बदलाव किए बिना निष्पक्षता से जुड़ी पाबंदियों को लागू करने के लिए किया जा सकता है.
उदाहरण के लिए, कोई भी क्लासिफ़िकेशन थ्रेशोल्ड सेट करके बाइनरी क्लासिफ़ायर में पोस्ट-प्रोसेसिंग लागू कर सकता है. ऐसा करके, कुछ एट्रिब्यूट के लिए ऑपर्च्यूनिटी के बराबर को बनाए रखा जा सकता है. इसके लिए, यह जांच की जा सकती है कि उस एट्रिब्यूट की सभी वैल्यू के लिए, सही पॉज़िटिव रेट एक जैसा है या नहीं.
PR AUC (पीआर कर्व के तहत का क्षेत्र)
इंटरपोलेट किए गए प्रीसिज़न-रीकॉल कर्व के तहत आने वाला एरिया, जो क्लासिफ़िकेशन थ्रेशोल्ड की अलग-अलग वैल्यू के लिए पॉइंट (रीकॉल, सटीक) को प्लॉट करके मिलता है. इसका हिसाब लगाने के तरीके के आधार पर, पीआर एयूसी, मॉडल की औसत सटीक वैल्यू के बराबर हो सकता है.
प्रक्सिस
Pax की मुख्य और बेहतर परफ़ॉर्मेंस वाली एमएल लाइब्रेरी. प्रेक्सिस को अक्सर "लेयर लाइब्रेरी" कहा जाता है.
प्रैक्टिस में सिर्फ़ लेयर क्लास की परिभाषाएं ही नहीं, बल्कि इसके साथ काम करने वाले ज़्यादातर कॉम्पोनेंट भी शामिल हैं, जैसे:
- डेटा इनपुट
- कॉन्फ़िगरेशन लाइब्रेरी (HParam और Fiddle)
- ऑप्टिमाइज़र
Praxis से मॉडल क्लास की परिभाषाएं मिलती हैं.
प्रीसिज़न
क्लासिफ़िकेशन मॉडल के लिए एक मेट्रिक, जो यहां दिए गए सवाल का जवाब देती है:
जब मॉडल ने पॉज़िटिव क्लास का अनुमान लगाया था, तो कितने प्रतिशत अनुमान सही थे?
इसका फ़ॉर्मूला यहां दिया गया है:
कहां:
- सही पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का सही अनुमान लगाया है.
- फ़ॉल्स पॉज़िटिव का मतलब है कि मॉडल ने गलती से पॉज़िटिव क्लास का अनुमान लगाया था.
उदाहरण के लिए, मान लें कि किसी मॉडल ने 200 सकारात्मक अनुमान लगाए हैं. इन 200 सकारात्मक अनुमानों में से:
- 150 ट्रू पॉज़िटिव थे.
- 50 जवाब फ़ॉल्स पॉज़िटिव थे.
इस मामले में:
सटीक होने और याद रखने के बीच अंतर करें.
प्रिसिज़न-रीकॉल कर्व
क्लासिफ़िकेशन के अलग-अलग थ्रेशोल्ड पर, सटीक बनाम रीकॉल का कर्व.
अनुमान
किसी मॉडल का आउटपुट. उदाहरण के लिए:
- बाइनरी क्लासिफ़िकेशन मॉडल का अनुमान, पॉज़िटिव क्लास या नेगेटिव क्लास हो सकता है.
- मल्टी-क्लास क्लासिफ़िकेशन मॉडल का अनुमान एक क्लास है.
- लीनियर रिग्रेशन मॉडल का अनुमान एक संख्या होती है.
प्रिडिक्शन बायस
वह वैल्यू जो यह बताती है कि डेटासेट में मौजूद अनुमानों के औसत और लेबल के औसत की दूरी कितनी है.
इसे मशीन लर्निंग मॉडल में बायस टर्म या नैतिकता और निष्पक्षता में पक्षपात के तौर पर नहीं समझा जा सकता.
अनुमानित एमएल
कोई भी स्टैंडर्ड ("क्लासिक") मशीन लर्निंग सिस्टम.
अनुमानित ML शब्द की कोई औपचारिक परिभाषा नहीं है. यह शब्द, मशीन लर्निंग सिस्टम की ऐसी कैटगरी को अलग करता है जो जनरेटिव एआई पर आधारित नहीं है.
अनुमानित समानता
इस फ़ेयरनेस मेट्रिक से यह पता चलता है कि डेटा की कैटगरी तय करने वाले किसी दिए गए टूल के लिए, सटीक दरें, उन सबग्रुप के लिए लागू हैं या नहीं.
उदाहरण के लिए, अगर किसी मॉडल में यह अनुमान लगाया जाता है कि कॉलेज में उसे स्वीकार कर लिया जाएगा, तो वह राष्ट्रीयता के बीच समानता का अनुमान लगा सकता. ऐसा तब होता है, जब लिलीपुटियन और ब्रोबडिंगनाजियन के लिए डेटा के सटीक होने की दर एक जैसी हो.
अनुमानित समानता को कभी-कभी अनुमानित दर की समानता भी कहा जाता है.
अनुमानित समानता के बारे में ज़्यादा जानने के लिए, "फ़ेयरनेस डेफ़िनिशन की पूरी जानकारी" (सेक्शन 3.2.1) देखें.
अनुमानित दर की समानता
अनुमानित समानता का एक और नाम.
प्री-प्रोसेसिंग
मॉडल को ट्रेनिंग देने के लिए, डेटा का इस्तेमाल किए जाने से पहले उसे प्रोसेस करना. प्री-प्रोसेसिंग, अंग्रेज़ी टेक्स्ट के एक कलेक्शन से ऐसे शब्दों को हटाने जितना आसान हो सकती है जो अंग्रेज़ी शब्दकोश में नहीं आते. इसके अलावा, यह डेटा पॉइंट को फिर से दिखाने जितना मुश्किल भी हो सकता है. इससे संवेदनशील एट्रिब्यूट से जुड़े ज़्यादा से ज़्यादा एट्रिब्यूट हट जाते हैं. प्री-प्रोसेसिंग से, फ़ेयरनेस कंस्ट्रेंट को पूरा करने में मदद मिल सकती है.पहले से ट्रेन किया गया मॉडल
मॉडल या मॉडल कॉम्पोनेंट, जैसे कि एम्बेडिंग वेक्टर जिन्हें पहले ही ट्रेनिंग दी जा चुकी है. कभी-कभी, आप पहले से ट्रेन किए गए एम्बेडिंग वेक्टर को न्यूरल नेटवर्क में फ़ीड कर सकते हैं. वहीं, कभी-कभी आपका मॉडल, पहले से ट्रेन की गई एम्बेडिंग पर निर्भर रहने के बजाय, एम्बेड करने वाले वेक्टर को खुद ट्रेनिंग देगा.
पहले से ट्रेन की गई भाषा का मॉडल शब्द का मतलब बड़े लैंग्वेज मॉडल से है, जो प्री-ट्रेनिंग से गुज़र चुका है.
प्री-ट्रेनिंग
एक बड़े डेटासेट पर मॉडल की शुरुआती ट्रेनिंग. पहले से ट्रेनिंग पा चुके कुछ मॉडल, अनाड़ी विशाल होते हैं और उन्हें आम तौर पर अतिरिक्त ट्रेनिंग की मदद से बेहतर बनाना होगा. उदाहरण के लिए, मशीन लर्निंग के विशेषज्ञ बड़े टेक्स्ट डेटासेट, जैसे कि विकिपीडिया में मौजूद अंग्रेज़ी के सभी पेजों पर बड़े लैंग्वेज मॉडल को पहले से ट्रेनिंग दे सकते हैं. प्री-ट्रेनिंग के बाद, नतीजे वाले मॉडल को इनमें से किसी भी तकनीक की मदद से और ज़्यादा बेहतर बनाया जा सकता है:
पहले से मौजूद भरोसा
डेटा की ट्रेनिंग शुरू करने से पहले, उसके बारे में आपकी क्या राय है. उदाहरण के लिए, L2 रेगुलराइज़ेशन इस शर्त पर निर्भर करता है कि वेट छोटा होना चाहिए और आम तौर पर, शून्य के आस-पास रखा जाना चाहिए.
प्रॉबेब्लिस्टिक रिग्रेशन मॉडल
ऐसा रिग्रेशन मॉडल जो हर सुविधा के लिए न सिर्फ़ वेट का इस्तेमाल करता है, बल्कि उन वेट की अनिश्चितता का भी इस्तेमाल करता है. प्रॉबेब्लिस्टिक रिग्रेशन मॉडल से, एक अनुमान मिलता है और उस अनुमान की अनिश्चितता होती है. उदाहरण के लिए, संभावित रिग्रेशन मॉडल, 12 के स्टैंडर्ड डिविएशन के साथ, 325 का अनुमान लगा सकता है. प्रॉबेब्लिस्टिक रिग्रेशन मॉडल के बारे में ज़्यादा जानकारी के लिए, tensorflow.org पर Colab देखें.
प्रोबैबिलिटी डेंसिटी फ़ंक्शन
यह फ़ंक्शन, डेटा के ऐसे सैंपल की फ़्रीक्वेंसी की पहचान करता है जिनमें बिलकुल एक वैल्यू होती है. जब किसी डेटासेट की वैल्यू, लगातार फ़्लोटिंग-पॉइंट नंबर होती हैं, तो एग्ज़ैक्ट मैच शायद ही कभी हों. हालांकि, x वैल्यू से y की वैल्यू पर प्रॉबबिलिटी डेंसिटी फ़ंक्शन को integrating से, x और y के बीच डेटा के सैंपल की अनुमानित फ़्रीक्वेंसी मिलती है.
उदाहरण के लिए, एक ऐसा सामान्य डिस्ट्रिब्यूशन देखें जिसका माध्य 200 और स्टैंडर्ड डिविएशन 30 है. 211.4 से 218.7 की रेंज में आने वाले डेटा के सैंपल की अनुमानित फ़्रीक्वेंसी तय करने के लिए, 211.4 से 218.7 के बीच के सामान्य डिस्ट्रिब्यूशन के लिए, प्रॉबेबिलिटी फ़ंक्शन को इंटिग्रेट किया जा सकता है.
मैसेज
किसी बड़े लैंग्वेज मॉडल में इनपुट के तौर पर डाला गया कोई भी टेक्स्ट, ताकि मॉडल को यह तय करने में मदद मिल सके कि वह किस तरह से काम करे. प्रॉम्प्ट, किसी वाक्यांश की तरह छोटे हो सकते हैं या फिर मनचाहे तरीके से लंबे हो सकते हैं. उदाहरण के लिए, किसी उपन्यास का पूरा टेक्स्ट. प्रॉम्प्ट कई कैटगरी में आते हैं. इनमें नीचे दी गई टेबल में दी गई कैटगरी भी शामिल हैं:
| प्रॉम्प्ट की कैटगरी | उदाहरण | ज़रूरी जानकारी |
|---|---|---|
| सवाल | कबूतर कितनी तेज़ी से उड़ सकता है? | |
| निर्देश | आर्बिट्रेज के बारे में एक मज़ेदार कविता लिखें. | ऐसा प्रॉम्प्ट जिसमें बड़े लैंग्वेज मॉडल को कुछ करने के लिए कहा जाता है. |
| उदाहरण | मार्कडाउन कोड का अनुवाद एचटीएमएल में करें. उदाहरण के लिए:
मार्कडाउन: * सूची आइटम एचटीएमएल: <ul> <li>सूची में दिया गया आइटम</li> </ul> |
इस उदाहरण में पहला वाक्य एक निर्देश है. प्रॉम्प्ट का बाकी हिस्सा, उदाहरण के तौर पर दिया गया है. |
| भूमिका | यह बताओ कि फ़िज़िक्स में पीएचडी के लिए, मशीन लर्निंग ट्रेनिंग में ग्रेडिएंट डिसेंट का इस्तेमाल क्यों होता है. | वाक्य का पहला हिस्सा एक निर्देश है. वाक्यांश "फ़िज़िक्स में पीएचडी के लिए" भूमिका वाला हिस्सा है. |
| मॉडल को पूरा करने के लिए इनपुट का कुछ हिस्सा | यूनाइटेड किंगडम के प्रधानमंत्री यहां रहते हैं | पार्शियल इनपुट प्रॉम्प्ट या तो अचानक खत्म हो सकता है (जैसा कि इस उदाहरण में दिखाया गया है) या अंडरस्कोर पर खत्म हो सकता है. |
जनरेटिव एआई मॉडल किसी प्रॉम्प्ट का जवाब देने के लिए, टेक्स्ट, कोड, इमेज, एम्बेड करने की सुविधा, और वीडियो वगैरह का इस्तेमाल करता है.
प्रॉम्प्ट के आधार पर सीखने की सुविधा
कुछ खास मॉडल की क्षमता, जो आर्बिट्रेरी टेक्स्ट इनपुट (प्रॉम्प्ट) के हिसाब से, अपने व्यवहार के मुताबिक बदलाव करने की सुविधा देती है. प्रॉम्प्ट पर आधारित सीखने के एक आम मॉडल में, बड़े लैंग्वेज मॉडल में टेक्स्ट जनरेट करके प्रॉम्प्ट का जवाब दिया जाता है. उदाहरण के लिए, मान लें कि कोई उपयोगकर्ता यह प्रॉम्प्ट डालता है:
न्यूटन के गति के तीसरे नियम का सारांश लिखें.
प्रॉम्प्ट पर आधारित लर्निंग वाले मॉडल को पिछले प्रॉम्प्ट का जवाब देने के लिए, ख़ास तौर पर ट्रेनिंग नहीं दी गई है. इसके बजाय, यह मॉडल भौतिकी के बारे में बहुत सारे तथ्यों, भाषा के सामान्य नियमों और कारगर जवाबों के बारे में बहुत कुछ जानता है. यह जानकारी, काम का (उम्मीद है) जवाब देने के लिए काफ़ी है. लोगों से मिले दूसरे सुझावों ("यह जवाब काफ़ी मुश्किल था." या "यह प्रतिक्रिया क्या है?") की मदद से, तुरंत जानकारी देने वाले कुछ सिस्टम धीरे-धीरे अपने जवाबों को ज़्यादा मददगार बना सकते हैं.
प्रॉम्प्ट डिज़ाइन
प्रॉम्प्ट इंजीनियरिंग का समानार्थी शब्द.
प्रॉम्प्ट इंजीनियरिंग
एक बड़े लैंग्वेज मॉडल से सही जवाब पाने के लिए, प्रॉम्प्ट बनाने की कला. लोग प्रॉम्प्ट इंजीनियरिंग करते हैं. अच्छी तरह से स्ट्रक्चर किए गए प्रॉम्प्ट लिखना, किसी लार्ज लैंग्वेज मॉडल से मददगार जवाब पाने का एक अहम हिस्सा है. प्रॉम्प्ट इंजीनियरिंग कई फ़ैक्टर पर निर्भर करती है. जैसे:
- इस डेटासेट का इस्तेमाल, बड़े लैंग्वेज मॉडल को पहले से ट्रेनिंग देने और इसे बेहतर बनाने के लिए किया जाता है.
- तापमान और डिकोड करने वाले दूसरे पैरामीटर जिनका इस्तेमाल मॉडल, रिस्पॉन्स जनरेट करने के लिए करता है.
मददगार प्रॉम्प्ट लिखने के बारे में ज़्यादा जानने के लिए, प्रॉम्प्ट के डिज़ाइन के बारे में जानकारी देखें.
प्रॉम्प्ट डिज़ाइन, प्रॉम्प्ट इंजीनियरिंग का एक समानार्थी शब्द है.
प्रॉम्प्ट ट्यूनिंग
पैरामीटर की बेहतर ट्यूनिंग का एक तरीका, जो उस "प्रीफ़िक्स" को सीखता है जिसे सिस्टम, असली प्रॉम्प्ट से पहले जोड़ता है.
प्रॉम्प्ट ट्यूनिंग का एक वैरिएशन हर लेयर पर प्रीफ़िक्स जोड़ना है. इसे कभी-कभी प्रीफ़िक्स ट्यूनिंग भी कहा जाता है. इसके उलट, ज़्यादातर प्रॉम्प्ट ट्यूनिंग इनपुट लेयर में सिर्फ़ प्रीफ़िक्स जोड़ता है.
प्रॉक्सी लेबल
ऐसे लेबल का अनुमान लगाने के लिए इस्तेमाल किया जाने वाला डेटा जो डेटासेट में सीधे तौर पर उपलब्ध नहीं हैं.
उदाहरण के लिए, मान लें कि आपको कर्मचारी के तनाव के स्तर का अनुमान लगाने के लिए एक मॉडल को ट्रेनिंग देनी होगी. आपके डेटासेट में बहुत सी अनुमानित सुविधाएँ हैं, लेकिन तनाव का स्तर नाम का कोई लेबल नहीं है. इस चिंता की कोई बात नहीं है. तनाव का स्तर मापने के लिए, "ऑफ़िस में होने वाली दुर्घटनाएं" को प्रॉक्सी लेबल के तौर पर चुना जाता है. ऐसा नहीं है कि शांत कर्मचारियों की तुलना में, ज़्यादा तनाव में रहने वाले कर्मचारियों के साथ ज़्यादा दुर्घटनाएं होती हैं. या वे ऐसा करते हैं? ऐसा हो सकता है कि ऑफ़िस में होने वाली दुर्घटनाएं कई वजहों से गिरती हों.
दूसरे उदाहरण के तौर पर, मान लें कि आपको अपने डेटासेट के लिए क्या बारिश हो रही है? को बूलियन लेबल बनाना है, लेकिन आपके डेटासेट में बारिश का डेटा नहीं है. अगर फ़ोटो उपलब्ध हैं, तो इमेज में लोगों को छतियां पकड़े हुए एक इमेज लेबल के तौर पर दिखाया जा सकता है. इससे पता चलेगा कि क्या बारिश हो रही है? क्या यह एक अच्छा प्रॉक्सी लेबल है? शायद, लेकिन कुछ संस्कृतियों में लोग बारिश के मुकाबले धूप से सुरक्षा के लिए छाते ले जाना ज़्यादा पसंद करते हैं.
प्रॉक्सी लेबल अक्सर सटीक नहीं होते हैं. जब भी हो सके, प्रॉक्सी लेबल के बजाय असल लेबल चुनें. इसलिए, जब कोई असल लेबल मौजूद न हो, तो प्रॉक्सी लेबल को सावधानी से चुनें और सबसे कम नुकसान पहुंचाने वाला प्रॉक्सी लेबल चुनें.
प्रॉक्सी (संवेदनशील एट्रिब्यूट)
ऐसा एट्रिब्यूट जिसे संवेदनशील एट्रिब्यूट के लिए स्टैंड-इन के तौर पर इस्तेमाल किया जाता है. उदाहरण के लिए, किसी व्यक्ति के पिन कोड का इस्तेमाल उसकी आय, नस्ल या जातीयता के लिए प्रॉक्सी के रूप में किया जा सकता है.प्योर फ़ंक्शन
ऐसा फ़ंक्शन जिसके आउटपुट सिर्फ़ इसके इनपुट पर आधारित होते हैं और जिसका कोई खराब इफ़ेक्ट नहीं होता. खास तौर पर, प्योर फ़ंक्शन किसी ग्लोबल स्थिति का इस्तेमाल नहीं करता या उसमें बदलाव नहीं करता. जैसे, किसी फ़ाइल का कॉन्टेंट या फ़ंक्शन के बाहर के किसी वैरिएबल की वैल्यू.
प्योर फ़ंक्शन का इस्तेमाल करके थ्रेड-सुरक्षित कोड बनाया जा सकता है. यह model कोड को एक से ज़्यादा ऐक्सेलरेटर चिप में शेयर करते समय फ़ायदेमंद होता है.
JAX के फ़ंक्शन में बदलाव करने के तरीकों के लिए ज़रूरी है कि इनपुट फ़ंक्शन प्योर फ़ंक्शन हों.
सवाल
क्यू-फ़ंक्शन
रीइन्फ़ोर्समेंट लर्निंग में, वह फ़ंक्शन जो किसी स्टेट में कार्रवाई करने के बाद, लौटाने के अनुमान का अनुमान लगाता है. इसके बाद, वह नीति का पालन करता है.
क्यू-फ़ंक्शन को स्टेट-ऐक्शन वैल्यू फ़ंक्शन भी कहा जाता है.
क्यू-लर्निंग
रीइन्फ़ोर्समेंट लर्निंग में एक एल्गोरिदम है जो बेलमैन इक्वेशन को लागू करके, एजेंट को मार्कोव के फ़ैसले लेने की प्रोसेस के सबसे बेहतर Q-फ़ंक्शन के बारे में बताता है. मार्कोव का फ़ैसला प्रोसेस एक एनवायरमेंट मॉडल है.
क्वेनटाइल
क्वांटाइल बकेटिंग में हर बकेट.
क्वानटाइल बकेटिंग
किसी सुविधा की वैल्यू को बकेट में बांटा जा रहा है, ताकि हर बकेट में एक जैसे (या करीब-करीब बराबर) उदाहरण मौजूद हों. उदाहरण के लिए, नीचे दिया गया डायग्राम 44 पॉइंट को 4 बकेट में बांटता है, जिनमें से हर एक में 11 पॉइंट होते हैं. आकृति में मौजूद हर बकेट में समान संख्या में पॉइंट रखने के लिए, कुछ बकेट x-वैल्यू की अलग-अलग चौड़ाई में फैली होती हैं.

क्वांटाइज़ेशन
ओवरलोडेड टर्म, जिसका इस्तेमाल इनमें से किसी भी तरीके से किया जा सकता है:
- किसी खास सुविधा पर क्वांटाइल बकेटिंग लागू करना.
- तेज़ी से स्टोर करने, ट्रेनिंग देने, और अनुमान लगाने के लिए, डेटा को शून्य और एक में बदलना. बूलियन डेटा अन्य फ़ॉर्मैट की तुलना में नॉइज़ और गड़बड़ियों के मामले में ज़्यादा कारगर है इसलिए, क्वांटाइज़ेशन से मॉडल को सटीक बनाने में मदद मिल सकती है. क्वांटाइज़ेशन की तकनीकों में राउंडिंग, काट-छांट करना, और बाइनिंग शामिल हैं.
किसी मॉडल के पैरामीटर को स्टोर करने के लिए, इस्तेमाल होने वाले बिट की संख्या कम करना. उदाहरण के लिए, मान लें कि किसी मॉडल के पैरामीटर 32-बिट फ़्लोटिंग-पॉइंट नंबर के रूप में स्टोर किए जाते हैं. क्वांटाइज़ेशन की सुविधा, उन पैरामीटर को 32 बिट से कम करके 4, 8 या 16 बिट में बदल देती है. क्वांटाइज़ेशन से इन चीज़ों को कम किया जा सकता है:
- कंप्यूट, मेमोरी, डिस्क, और नेटवर्क के इस्तेमाल की जानकारी
- पूर्वानुमान का पता लगाने का समय
- ऊर्जा की खपत
हालांकि, कभी-कभी क्वांटाइज़ेशन से मॉडल के अनुमानों की सटीक जानकारी कम हो जाती है.
सूची
ऐसा TensorFlow ऑपरेशन है, जो सूची के डेटा स्ट्रक्चर को लागू करता है. आम तौर पर, I/O में इस्तेमाल किया जाता है.
R
आरएजी
रिकवरी-एगमेंटेड जनरेशन का छोटा नाम.
रैंडम फ़ॉरेस्ट
डिसिज़न ट्री का एक कलेक्शन, जिसमें हर डिसिज़न ट्री को किसी खास नियम के साथ ट्रेनिंग दी जाती है, जैसे कि बैगिंग.
रैंडम फ़ॉरेस्ट एक तरह के फ़ैसले फ़ॉरेस्ट हैं.
रैंडम पॉलिसी
इन्फ़ोर्समेंट लर्निंग में एक ऐसी नीति है जो बिना किसी क्रम के कार्रवाई चुनती है.
रैंकिंग
एक तरह की सुपरवाइज़्ड लर्निंग, जिसका मकसद आइटम की सूची ऑर्डर करना होता है.
रैंक (सामान्य)
मशीन लर्निंग की समस्या में क्लास का क्रम, जो क्लास को सबसे अच्छी से लेकर सबसे नीचे वाली कैटगरी में बांटता है. उदाहरण के लिए, व्यवहार की रैंकिंग करने वाला सिस्टम, कुत्ते के लिए इनाम को सबसे बढ़िया (स्टीक) से लेकर सबसे कम (मुंझाया हुआ केल) तक रैंक कर सकता है.
रैंक (टेन्सर)
किसी टेन्सर में डाइमेंशन की संख्या. उदाहरण के लिए, किसी अदिश की रैंक 0 होती है, सदिश का रैंक 1 होता है, और आव्यूह की रैंक 2 होती है.
रैंक (सामान्य) से अलग है.
रेटिंग देने वाला
ऐसा व्यक्ति जो उदाहरणों के लिए लेबल देता है. रेटिंग देने वालों का एक और नाम "एनोटेटर" भी है.
रीकॉल
क्लासिफ़िकेशन मॉडल के लिए एक मेट्रिक, जो यहां दिए गए सवाल का जवाब देती है:
जब असल डेटा पॉज़िटिव क्लास था, तो मॉडल ने कितने प्रतिशत अनुमानों को पॉज़िटिव क्लास के तौर पर सही तरीके से पहचाना?
इसका फ़ॉर्मूला यहां दिया गया है:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
कहां:
- सही पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का सही अनुमान लगाया है.
- गलत नेगेटिव का मतलब है कि मॉडल ने गलती से, नेगेटिव क्लास का अनुमान लगाया था.
उदाहरण के लिए, मान लें कि आपके मॉडल ने ऐसे उदाहरणों पर 200 अनुमान लगाए जिनके लिए ज़मीनी सच्चाई एक पॉज़िटिव क्लास थी. इन 200 अनुमानों में से:
- 180 ट्रू पॉज़िटिव थे.
- 20 नतीजे फ़ॉल्स नेगेटिव थे.
इस मामले में:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
सुझाव देने वाला सिस्टम
यह ऐसा सिस्टम है जो हर उपयोगकर्ता के लिए, अपनी पसंद के आइटम के एक बड़े सेट को चुनता है. उदाहरण के लिए, वीडियो का सुझाव देने वाला कोई सिस्टम 1,00, 000 वीडियो के संग्रह से दो वीडियो का सुझाव दे सकता है. इसमें किसी एक उपयोगकर्ता के लिए कैसाब्लांका और फ़िलाडेल्फ़िया स्टोरी चुनकर, दूसरे को वंडर वुमन और ब्लैक पैंथर जैसे वीडियो का सुझाव दिया जा सकता है. वीडियो के सुझाव देने वाला सिस्टम, इन बातों के आधार पर सुझाव दे सकता है:
- ऐसी फ़िल्में जिन्हें इसी तरह के दूसरे उपयोगकर्ताओं ने रेटिंग दी है या देखा है.
- शैली, डायरेक्टर, अभिनेता, टारगेट की गई डेमोग्राफ़िक...
रेक्टिफ़ाइड लीनियर यूनिट (ReLU)
ये ऐक्टिवेशन फ़ंक्शन होते हैं:
- अगर इनपुट नेगेटिव या शून्य है, तो आउटपुट शून्य होता है.
- अगर इनपुट पॉज़िटिव है, तो आउटपुट, इनपुट के बराबर होता है.
उदाहरण के लिए:
- अगर इनपुट -3 है, तो आउटपुट 0 होगा.
- अगर इनपुट में +3 है, तो आउटपुट 3.0 होगा.
यहां ReLU का प्लॉट दिया गया है:

ReLU एक काफ़ी लोकप्रिय ऐक्टिवेशन फ़ंक्शन है. आसान तरीका होने के बावजूद, ReLU अब भी न्यूरल नेटवर्क को सुविधाओं और लेबल के बीच के ऑनलाइन संबंध जानने की सुविधा देता है.
बार-बार होने वाला न्यूरल नेटवर्क
एक न्यूरल नेटवर्क जिसे जान-बूझकर कई बार चलाया जाता है. इसमें हर बार का कुछ हिस्सा, अगली बार चलाया जाता है. खास तौर पर, पिछली बार चलाई गई छिपी हुई लेयर, अगली बार रन करने के दौरान उसी छिपी हुई लेयर के लिए इनपुट का कुछ हिस्सा उपलब्ध कराती हैं. बार-बार होने वाले न्यूरल नेटवर्क, क्रम का आकलन करने में खास तौर पर मददगार होते हैं. इससे छिपी हुई लेयर, क्रम के शुरुआती हिस्सों में न्यूरल नेटवर्क के पिछले हिस्सों से सीख सकती हैं.
उदाहरण के लिए, नीचे दिए गए डायग्राम में बार-बार न्यूरल नेटवर्क दिखता है, जो चार बार चलता है. ध्यान दें कि पहली बार रन करने पर छिपी हुई लेयर में सीखी गई वैल्यू, दूसरी बार रन करने पर उन्हीं छिपी हुई लेयर के इनपुट का हिस्सा बन जाती हैं. इसी तरह, दूसरी बार रन करने पर, छिपी हुई लेयर में सीखी गई वैल्यू, तीसरी बार चलाने पर उसी छिपी हुई लेयर के इनपुट का हिस्सा बन जाती हैं. इस तरह, बार-बार होने वाला न्यूरल नेटवर्क धीरे-धीरे अलग-अलग शब्दों के मतलब के बजाय पूरे क्रम को समझेगा और उसके मतलब का अनुमान लगाता है.

रिग्रेशन मॉडल
अनौपचारिक रूप से, यह एक मॉडल है जो संख्या के तौर पर अनुमान लगाता है. (वहीं दूसरी ओर, क्लासिफ़िकेशन मॉडल एक क्लास अनुमान जनरेट करता है.) उदाहरण के लिए, नीचे दिए गए सभी रिग्रेशन मॉडल के उदाहरण हैं:
- ऐसा मॉडल जो किसी खास घर की वैल्यू का अनुमान लगाता है, जैसे कि 4,23,000 यूरो.
- ऐसा मॉडल जो किसी खास पेड़ के जीवन की अनुमानित अवधि का अनुमान लगाता है, जैसे कि 23.2 साल.
- ऐसा मॉडल जो यह अनुमान लगाता है कि किसी शहर में अगले छह घंटों में कितनी बारिश होगी, जैसे कि 0.18 इंच.
आम तौर पर, रिग्रेशन मॉडल दो तरह के होते हैं:
- लीनियर रिग्रेशन: इसमें, उस लाइन का पता चलता है जो लेबल की वैल्यू के हिसाब से, सुविधाओं के हिसाब से सबसे सही होती है.
- लॉजिस्टिक रिग्रेशन, जो 0.0 और 1.0 के बीच की संभावना जनरेट करता है. इसके बाद, सिस्टम आम तौर पर क्लास के अनुमान को मैप करता है.
अंकों वाला अनुमान दिखाने वाला हर मॉडल, रिग्रेशन मॉडल नहीं होता. कुछ मामलों में, संख्यात्मक अनुमान असल में सिर्फ़ एक क्लासिफ़िकेशन मॉडल होता है जिसमें संख्या वाले क्लास के नाम होते हैं. उदाहरण के लिए, जो मॉडल यह अनुमान लगाता है कि अंकों वाला पिन कोड एक क्लासिफ़िकेशन मॉडल है, न कि रिग्रेशन मॉडल.
रेगुलराइज़ेशन
ऐसा कोई भी तरीका जो ओवरफ़िटिंग को कम करता हो. रेगुलराइज़ेशन के ये तरीके लोकप्रिय हैं:
- L1 रेगुलराइज़ेशन
- L2 रेगुलराइज़ेशन
- ड्रॉपआउट रेगुलराइज़ेशन
- रिलीज़ होने से पहले रोकना (यह औपचारिक तौर पर नियमित करने का तरीका नहीं है, लेकिन यह ओवरफ़िटिंग को कम कर सकता है)
रेगुलराइज़ेशन को मॉडल की जटिलता की वजह से लगने वाला जुर्माना भी कहा जा सकता है.
रेगुलराइज़ेशन रेट
यह संख्या बताती है कि ट्रेनिंग के दौरान नियमित तौर पर नियमित करने की अहमियत क्या है. रेगुलराइज़ेशन रेट को बढ़ाने से, ओवरफ़िटिंग कम हो जाती है. हालांकि, इससे मॉडल की अनुमानित क्षमता कम हो जाती है. इसके उलट, रेगुलराइज़ेशन दर को कम करने या छोड़ने से ओवरफ़िटिंग में बढ़ोतरी होती है.
रीइन्फ़ोर्समेंट लर्निंग (आरएल)
ऐसे एल्गोरिदम का फ़ैमिली ग्रुप जो सबसे सही नीति के बारे में सीखते हैं. इसका लक्ष्य, किसी एनवायरमेंट के साथ इंटरैक्ट करते समय रिटर्न को ज़्यादा से ज़्यादा बढ़ाना होता है. जैसे, ज़्यादातर गेम का सबसे अहम इनाम जीत होता है. रीइन्फ़ोर्समेंट लर्निंग सिस्टम, मुश्किल गेम खेलने में विशेषज्ञ बन सकते हैं. इसके लिए, पिछले गेम के मूव के सीक्वेंस का आकलन किया जाता है. इस वजह से ही गेम में जीत और सीक्वेंस की वजह से हारने का खतरा होता है.
लोगों के सुझाव, शिकायत या राय की मदद से रीइन्फ़ोर्समेंट लर्निंग (आरएलएचएफ़)
रेटिंग देने वाले लोगों के सुझाव, शिकायत या राय का इस्तेमाल करके, किसी मॉडल के जवाबों की क्वालिटी को बेहतर बनाना. उदाहरण के लिए, आरएलएचएफ़ तरीकों में उपयोगकर्ताओं से 👍 या 🇺 इमोजी का इस्तेमाल करके, किसी मॉडल के जवाब की क्वालिटी को रेटिंग देने के लिए कहा जा सकता है. इसके बाद, सिस्टम इस सुझाव के आधार पर आने वाले जवाबों में बदलाव कर सकता है.
ReLU
रेक्टिफ़ाइड लीनियर यूनिट का छोटा नाम.
बफ़र को फिर से चलाएं
DQN जैसे एल्गोरिदम में, वह मेमोरी जिसका इस्तेमाल एजेंट करता है, ताकि अनुभव को फिर से चलाने के लिए, स्थिति के ट्रांज़िशन को सेव किया जा सके.
प्रतिरूप
ट्रेनिंग सेट या मॉडल की कॉपी, आम तौर पर किसी दूसरी मशीन पर की जाती है. उदाहरण के लिए, डेटा के साथ काम करने को लागू करने के लिए, कोई सिस्टम इस रणनीति का इस्तेमाल कर सकता है:
- किसी मौजूदा मॉडल की प्रतिकृतियों को एक से ज़्यादा मशीनों पर रखें.
- हर एक प्रतिकृति पर ट्रेनिंग सेट के अलग-अलग सबसेट भेजें.
- पैरामीटर के अपडेट को एग्रीगेट करें.
रिपोर्टिंग में भेदभाव
लोग कार्रवाइयों, नतीजों या प्रॉपर्टी के बारे में कितनी बार लिखते हैं, यह उनकी असल दुनिया की फ़्रीक्वेंसी या किसी व्यक्ति के एक वर्ग की विशेषता का पता नहीं दिखाता. रिपोर्टिंग में होने वाले पक्षपात से उस डेटा की कंपोज़िशन पर असर पड़ सकता है जिससे मशीन लर्निंग सिस्टम सीखते हैं.
उदाहरण के लिए, किताबों में, सांस लेने में मदद करने वाले शब्द के मुकाबले हंसी हुई शब्द ज़्यादा इस्तेमाल किया जाता है. एक मशीन लर्निंग मॉडल जो किताब के संग्रह से हंसने और सांस लेने की फ़्रीक्वेंसी का अनुमान लगाता है. इससे शायद यह पता चल सकता है कि हंसना, सांस लेने से ज़्यादा सामान्य है.
प्रतिनिधित्व
काम की सुविधाओं के साथ डेटा को मैप करने की प्रोसेस.
री-रैंकिंग
सुझाव देने वाले सिस्टम का आखिरी चरण. इस दौरान, स्कोर किए गए आइटम को किसी दूसरे एल्गोरिदम (आम तौर पर, मशीन लर्निंग नहीं) के हिसाब से फिर से ग्रेड किया जा सकता है. फिर से रैंक करने की सुविधा, स्कोरिंग फ़ेज़ के हिसाब से जनरेट हुए आइटम की सूची का आकलन करती है. इसके लिए, ये कार्रवाइयां की जाती हैं:
- ऐसे आइटम हटाना जिन्हें उपयोगकर्ता पहले ही खरीद चुका है.
- इसके अलावा, ज़्यादा से ज़्यादा नए प्रॉडक्ट की संख्या बढ़ाई जा रही है.
रिकवरी-एग्मेंटेड जनरेशन (आरएजी)
यह एक ऐसी तकनीक है जिसकी मदद से बड़े लैंग्वेज मॉडल (एलएलएम) आउटपुट की क्वालिटी को बेहतर बनाया जा सकता है. इसके लिए, मॉडल को ट्रेनिंग देने के बाद इकट्ठा किए गए ज्ञान के सोर्स का इस्तेमाल किया जाता है. RAG एलएलएम के जवाबों को ज़्यादा सटीक बनाता है. इसके लिए, वह ट्रेन किए गए एलएलएम को भरोसेमंद नॉलेज बेस या दस्तावेज़ों से मिली जानकारी का ऐक्सेस देता है.
रिकवर करने में मदद करने वाली जनरेशन को इस्तेमाल करने की कुछ सामान्य वजहें ये हैं:
- किसी मॉडल के जनरेट किए गए जवाबों के तथ्यों को ज़्यादा सटीक बनाना.
- मॉडल को उस जानकारी का ऐक्सेस देना जिसके लिए उसे ट्रेनिंग नहीं दी गई थी.
- मॉडल में इस्तेमाल की जाने वाली जानकारी बदलना.
- सोर्स को उद्धरण देने के लिए मॉडल को चालू करना.
उदाहरण के लिए, मान लीजिए कि कोई केमिकल ऐप्लिकेशन, उपयोगकर्ता की क्वेरी से जुड़ी खास जानकारी जनरेट करने के लिए PaLM API का इस्तेमाल करता है. ऐप्लिकेशन के बैकएंड से कोई क्वेरी मिलने पर, बैकएंड:
- उपयोगकर्ता की क्वेरी के हिसाब से काम के डेटा को खोजता है ("वापस लाया जाता है").
- उपयोगकर्ता की क्वेरी में काम के केमिकल के डेटा को जोड़ता है ("बढ़ाएं").
- यह एलएलएम को, जोड़े गए डेटा के आधार पर जवाब बनाने का निर्देश देता है.
return
किसी नीति और खास स्थिति के हिसाब से, रीइन्फ़ोर्समेंट लर्निंग में यह रिटर्न, उन सभी इनाम का योग होता है जो एजेंट, राज्य से एपिसोड के आखिर तक नीति का पालन करने पर मिलने की उम्मीद करता है. एजेंट, संभावित इनामों में होने वाली देरी का हिसाब लगाता है. ऐसा इनाम पाने के लिए ज़रूरी राज्यों के हिसाब से छूट देकर किया जाता है.
इसलिए, अगर छूट का फ़ैक्टर \(\gamma\)है और \(r_0, \ldots, r_{N}\) एपिसोड के आखिर तक इनामों को दिखाता है, तो ऐसे में रिटर्न का हिसाब इस तरह से दिखेगा:
इनाम
रीइन्फ़ोर्समेंट लर्निंग में, किसी स्टेट में की गई कार्रवाई का संख्यात्मक नतीजा होता है. इसकी परिभाषा एनवायरमेंट के तहत दी जाती है.
रिज रेगुलराइज़ेशन
L2 रेगुलराइज़ेशन का समानार्थी शब्द. रिज रेगुलराइज़ेशन शब्द का इस्तेमाल ज़्यादातर, आंकड़ों के हिसाब से किया जाता है. वहीं, मशीन लर्निंग में L2 रेगुलराइज़ेशन का ज़्यादा इस्तेमाल किया जाता है.
आरएनएन
बार-बार होने वाले न्यूरल नेटवर्क का शॉर्ट फ़ॉर्म.
आरओसी (रिसीवर ऑपरेटिंग एट्रिब्यूट) कर्व
बाइनरी कैटगरी में क्लासिफ़िकेशन के थ्रेशोल्ड के लिए ट्रू पॉज़िटिव रेट बनाम फ़ॉल्स पॉज़िटिव रेट का ग्राफ़.
आरओसी कर्व का आकार यह बताता है कि बाइनरी क्लासिफ़िकेशन मॉडल में पॉज़िटिव क्लास को नेगेटिव क्लास से अलग किया जा सकता है. उदाहरण के लिए, मान लीजिए कि एक बाइनरी क्लासिफ़िकेशन मॉडल, सभी नेगेटिव क्लास को सभी पॉज़िटिव क्लास से पूरी तरह अलग करता है:

पिछले मॉडल के लिए आरओसी कर्व इस तरह दिखता है:

इसके उलट, नीचे दिया गया इलस्ट्रेशन बहुत मुश्किल मॉडल के लिए रॉ लॉजिस्टिक रिग्रेशन वैल्यू को ग्राफ़ में दिखाता है. यह मॉडल, नेगेटिव क्लास को पॉज़िटिव क्लास से बिलकुल अलग नहीं कर सकता:

इस मॉडल के लिए आरओसी कर्व इस तरह दिखता है:

हालांकि, असल दुनिया में वापस आते हैं. ज़्यादातर बाइनरी क्लासिफ़िकेशन मॉडल, कुछ हद तक पॉज़िटिव और नेगेटिव क्लास को अलग करते हैं, लेकिन आम तौर पर बिलकुल अच्छे से नहीं होते. इसलिए, एक सामान्य आरओसी कर्व इन दोनों चरम सीमाओं के बीच में होता है:
(0.0,1.0) के सबसे करीब वाले ROC कर्व पर मौजूद पॉइंट, सैद्धांतिक रूप से आदर्श वर्गीकरण थ्रेशोल्ड की पहचान करता है. हालांकि, वास्तविक दुनिया की कई दूसरी समस्याएं आदर्श क्लासिफ़िकेशन के थ्रेशोल्ड को चुनने पर असर डालती हैं. उदाहरण के लिए, शायद फ़ॉल्स नेगेटिव की वजह से फ़ॉल्स पॉज़िटिव के मुकाबले कहीं ज़्यादा नुकसान पहुंचता है.
AUC नाम की मेट्रिक, आरओसी कर्व को एक ही फ़्लोटिंग-पॉइंट वैल्यू में बदल सकती है.
भूमिका के लिए प्रॉम्प्ट
यह प्रॉम्प्ट का एक वैकल्पिक हिस्सा होता है, जो जनरेटिव एआई मॉडल के रिस्पॉन्स के लिए, टारगेट ऑडियंस की पहचान करता है. रोल प्रॉम्प्ट के बिना, बड़ा लैंग्वेज मॉडल ऐसा जवाब देता है जो सवाल पूछने वाले व्यक्ति के लिए काम का हो सकता है और नहीं भी. रोल प्रॉम्प्ट के साथ, एक लार्ज लैंग्वेज मॉडल इस तरह से जवाब दे सकता है कि वह किसी ख़ास टारगेट ऑडियंस के लिए ज़्यादा सही और मददगार हो. उदाहरण के लिए, इन प्रॉम्प्ट का रोल प्रॉम्प्ट वाला हिस्सा बोल्डफ़ेस में दिया गया है:
- अर्थशास्त्र में पीएचडी के लिए इस लेख का सारांश बनाओ.
- बताओ कि 10 साल के बच्चे के लिए ज्वार कैसे काम करता है.
- 2008 की वित्तीय संकट के बारे में बताओ. जैसे कि छोटे बच्चे या गोल्डन रिट्रीवर नस्ल के कुत्ते से बात करें.
रूट
डिसिज़न ट्री में शुरुआती नोड (पहली स्थिति). तरीके के हिसाब से, डायग्राम रूट को डिसिज़न ट्री के सबसे ऊपर दिखाता है. उदाहरण के लिए:

रूट डायरेक्ट्री
वह डायरेक्ट्री जिसे TensorFlow चेकपॉइंट की सबडायरेक्ट्री होस्ट करने के लिए तय किया जाता है. साथ ही, एक से ज़्यादा मॉडल की इवेंट फ़ाइलों को भी होस्ट किया जाता है.
रूट मीन स्क्वेयर्ड एरर (RMSE)
मीन स्क्वेयर्ड एरर का वर्गमूल.
रोटेशनल इन्वैरियंस
इमेज की कैटगरी तय करने से जुड़ी समस्या में, इमेज का ओरिएंटेशन बदलने पर भी एल्गोरिदम की, इमेज को सही तरीके से अलग-अलग कैटगरी में बांटने की क्षमता. उदाहरण के लिए, एल्गोरिदम अभी भी किसी टेनिस रैकेट की पहचान कर सकता है, चाहे वह ऊपर की ओर हो, तिरछा हो या नीचे. ध्यान दें कि रोटेशनल इन्वैरियंस हमेशा ज़रूरी नहीं होता है; उदाहरण के लिए, रिवर्स-डाउन 9 को 9 की कैटगरी में नहीं रखा जाना चाहिए.
अनुवादक इनवैरियंस और साइज़ इनवैरियंस भी देखें.
R-squared
इस रिग्रेशन की मेट्रिक से पता चलता है कि किसी सुविधा या सुविधा के सेट की वजह से, लेबल के कितने वैरिएशन हैं. आर-स्क्वेयर, 0 और 1 के बीच की कोई वैल्यू होती है, जिसे इस तरह समझा जा सकता है:
- 0 के R-वर्ग का मतलब है कि लेबल की कोई भी विविधता सुविधा सेट की वजह से नहीं है.
- 1 के R-वर्ग का मतलब है कि किसी लेबल के सभी वैरिएशन, सुविधा सेट की वजह से हैं.
- 0 और 1 के बीच का आर-स्क्वेयर, किसी खास सुविधा या सुविधा सेट से लेबल के वैरिएशन का अनुमान किस सीमा तक लगाता है. उदाहरण के लिए, 0.10 के R-वर्ग का मतलब है कि लेबल के वैरिएंस का 10 प्रतिशत फ़ीचर सेट की वजह से है, 0.20 के R-स्क्वेयर का मतलब है 20 प्रतिशत सुविधा सेट का कारण है, और यह इसी तरह जारी रहता है.
आर-स्क्वेयर, किसी मॉडल की अनुमानित वैल्यू और ग्राउंड ट्रूथ के बीच पीयर्सन कोरिलेशन गुणांक का स्क्वेयर होता है.
S
सैंपलिंग बायस
चुनाव के मापदंड देखें.
रिप्लेसमेंट की मदद से सैंपलिंग
उम्मीदवार के आइटम के सेट में से आइटम चुनने का तरीका, जिसमें एक ही आइटम को एक से ज़्यादा बार चुना जा सकता है. "बदलाव के साथ" वाक्यांश का मतलब है कि हर बार चुने जाने के बाद, चुना गया आइटम सही आइटम के पूल में चला जाता है. बिना किसी बदले सैंपल करने के इन्वर्स तरीके का मतलब है कि किसी उम्मीदवार के आइटम को सिर्फ़ एक बार चुना जा सकता है.
उदाहरण के लिए, फलों के इस सेट पर विचार करें:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
मान लें कि सिस्टम किसी भी क्रम में, fig को पहले आइटम के तौर पर चुनता है.
रिप्लेसमेंट के साथ सैंपलिंग का इस्तेमाल करने पर, सिस्टम
नीचे दिए गए सेट में से दूसरा आइटम चुनता है:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
हां, यह पहले की तरह ही सेट है. इसलिए, सिस्टम फिर से
fig को चुन सकता है.
अगर किसी सैंपल को चुने जाने के बाद उसका इस्तेमाल किया जा रहा है, तो उसे फिर से
नहीं चुना जा सकता. उदाहरण के लिए, अगर सिस्टम किसी भी क्रम में fig को पहले सैंपल के तौर पर चुनता है, तो fig को फिर से नहीं चुना जा सकता. इसलिए, सिस्टम
नीचे दिए गए (कम किए गए) सेट में से दूसरा सैंपल चुनता है:
fruit = {kiwi, apple, pear, cherry, lime, mango}
SavedModel
TensorFlow के मॉडल को सेव और वापस पाने के लिए सुझाया गया फ़ॉर्मैट. सेव किए गए मॉडल, किसी लैंग्वेज न्यूट्रल और रिकवर किए जा सकने वाले सीरियलाइज़ेशन फ़ॉर्मैट है. इसकी मदद से, हाई-लेवल सिस्टम और टूल, TensorFlow के मॉडल बना सकते हैं, उनका इस्तेमाल कर सकते हैं, और उनमें बदलाव कर सकते हैं.
पूरी जानकारी के लिए, TensorFlow प्रोग्रामर की गाइड में मौजूद सेव करना और वापस पाना चैप्टर देखें.
सेवर
TensorFlow ऑब्जेक्ट, मॉडल चेकपॉइंट को सेव करने की ज़िम्मेदारी लेता है.
स्केलर
एक संख्या या एक स्ट्रिंग, जिसे रैंक 0 के टेंसर के तौर पर दिखाया जा सकता है. उदाहरण के लिए, कोड की नीचे दी गई लाइनें, TensorFlow में एक स्केलर बनाती हैं:
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)
स्केलिंग
ऐसा कोई भी गणितीय बदलाव या तकनीक जो किसी लेबल और/या सुविधा की वैल्यू की रेंज में बदलाव करता है. स्केलिंग के कुछ तरीके, नॉर्मलाइज़ेशन जैसे बदलावों के लिए बहुत काम के हैं.
मशीन लर्निंग में स्केलिंग के उपयोगी तरीके ये हैं:
- लीनियर स्केलिंग, जिसमें आम तौर पर घटाव और डिवीज़न के कॉम्बिनेशन का इस्तेमाल किया जाता है. इस सुविधा में, ओरिजनल वैल्यू को -1 और +1 के बीच या 0 से 1 के बीच की किसी संख्या से बदला जाता है.
- लॉगारिद्मिक स्केलिंग, जो ओरिजनल वैल्यू को लॉगारिद्म से बदल देता है.
- Z-स्कोर नॉर्मलाइज़ेशन, जिसमें ओरिजनल वैल्यू को फ़्लोटिंग-पॉइंट वैल्यू से बदल दिया जाता है. यह वैल्यू, सुविधा के मीन से स्टैंडर्ड डिविएशन की संख्या दिखाती है.
विज्ञान-सीखने के लिए
एक लोकप्रिय ओपन सोर्स मशीन लर्निंग प्लैटफ़ॉर्म. scikit-learn.org पर जाएं.
स्कोरिंग
यह सुझाव देने वाले सिस्टम का हिस्सा है, जो उम्मीदवार को जनरेट करने के चरण में बनाए गए हर आइटम की वैल्यू या रैंकिंग देता है.
चुनने से जुड़ा मापदंड
चुनने की प्रोसेस की वजह से सैंपल डेटा से लिए गए नतीजों में गड़बड़ियां होती हैं. इस प्रोसेस की वजह से, डेटा में देखे गए सैंपल और मॉनिटर नहीं किए गए सैंपल के बीच सिस्टम में अंतर जनरेट होता है. ये पूर्वाग्रह हैं:
- कवरेज बायस: डेटासेट में दिखाई गई जनसंख्या, उस जनसंख्या से मेल नहीं खाती जिसके बारे में मशीन लर्निंग मॉडल अनुमान लगा रहा है.
- सैंपलिंग बायस: टारगेट ग्रुप से रैंडम तरीके से डेटा इकट्ठा नहीं किया जाता.
- नॉन-रिस्पॉन्स बायस (इसे पार्टिसिपेशन बायस भी कहा जाता है): कुछ खास ग्रुप के उपयोगकर्ता, दूसरे ग्रुप के उपयोगकर्ताओं की तुलना में अलग-अलग दरों पर सर्वे से ऑप्ट-आउट करते हैं.
उदाहरण के लिए, मान लीजिए कि एक ऐसा मशीन लर्निंग मॉडल बनाया जा रहा है जो यह अनुमान लगाता है कि लोगों को कोई फ़िल्म पसंद आएगी या नहीं. ट्रेनिंग डेटा इकट्ठा करने के लिए, आपको थिएटर में सबसे पहली लाइन में, फ़िल्म दिखाने वाले सभी लोगों को एक सर्वे भेजने का मौका मिलता है. ऐसा लग सकता है कि यह डेटासेट इकट्ठा करने का सही तरीका है. हालांकि, डेटा इकट्ठा करने के इस तरीके से, इन चीज़ों में होने वाले भेदभाव से जुड़ी जानकारी मिल सकती है:
- कवरेज बायस: मूवी देखने का विकल्प चुनने वाले लोगों के सैंपल से, हो सकता है कि आपके मॉडल के अनुमान उन लोगों के लिए सामान्य न हों जिन्होंने फ़िल्म के लिए अपनी दिलचस्पी के बारे में पहले से नहीं बताया हो.
- सैंपल के तौर पर मौजूद बायस: सैंपल के तौर पर लिए गए लोगों (फ़िल्म में मौजूद सभी लोगों) के आधार पर, रैंडम तरीके से सैंपलिंग के बजाय सिर्फ़ पहली लाइन में मौजूद लोगों के सैंपल लिए गए. ऐसा हो सकता है कि अगली पंक्ति में बैठे लोगों को दूसरी पंक्तियों के मुकाबले फ़िल्म में ज़्यादा दिलचस्पी हो.
- गैर-प्रतिक्रिया पूर्वाग्रह: आमतौर पर, कम राय रखने वाले लोगों की तुलना में बेहतर राय वाले लोग वैकल्पिक सर्वे का जवाब ज़्यादा देते हैं. इस सर्वे में हिस्सा लेना ज़रूरी नहीं है. इसलिए, इस सर्वे से मिलने वाले जवाबों की तुलना में, सामान्य (घंटी के आकार में) डिस्ट्रिब्यूशन की तुलना में बायमॉडल डिस्ट्रिब्यूशन बनने की संभावना ज़्यादा होती है.
खुद का ध्यान रखना (इसे सेल्फ़-अटेंशन लेयर भी कहा जाता है)
यह एक न्यूरल नेटवर्क लेयर है, जो एम्बेड करने के क्रम (उदाहरण के लिए, टोकन एम्बेड) को एम्बेड करने के दूसरे क्रम में बदल देती है. आउटपुट सीक्वेंस में हर एम्बेड करने के लिए ध्यान देने के तरीके के ज़रिए, इनपुट क्रम के एलिमेंट से जानकारी को जोड़ा जाता है.
खुद का ध्यान रखना का मतलब है, किसी दूसरे संदर्भ के बजाय, खुद से रूबरू होना. खुद का ध्यान रखना, ट्रांसफ़ॉर्मर के लिए सबसे ज़रूरी बातों में से एक है. इसमें "query", "key", और "value" जैसी डिक्शनरी लुकअप शब्दावली का इस्तेमाल किया जाता है.
खुद पर ध्यान देने वाली लेयर की शुरुआत, इनपुट के क्रम से होती है. हर शब्द के लिए एक का इस्तेमाल किया जाता है. किसी शब्द के लिए इनपुट देना, उसे एम्बेड करना आसान हो सकता है. इनपुट के क्रम में मौजूद हर शब्द के लिए नेटवर्क, शब्दों के पूरे क्रम के हर एलिमेंट के लिए शब्द के हिसाब से स्कोर तय करता है. प्रासंगिकता से जुड़े स्कोर से यह तय होता है कि शब्द के आखिरी हिस्से में, दूसरे शब्दों के कितने शब्दों को शामिल किया गया है.
उदाहरण के लिए, इस वाक्य पर गौर करें:
जानवर बहुत थका हुआ था, इसलिए वह सड़क पार नहीं किया.
नीचे दिए गए इलस्ट्रेशन में, Transformer: A Novel Neral Network लगाती फ़ॉर लैंग्वेज अंडरस्टैंडिंग का उदाहरण दिया गया है. सर्वनाम it के लिए, खुद पर ध्यान देने वाली लेयर का पैटर्न दिखाया गया है. हर लाइन में अंधेरा होने से पता चलता है कि प्रज़ेंटेशन में हर शब्द का कितना योगदान है:

खुद पर ध्यान देने वाली लेयर, "इससे" काम के शब्दों को हाइलाइट करती है. इस मामले में, अटेंशन लेयर ने ऐनिमल को सबसे ज़्यादा प्राथमिकता देते हुए उन शब्दों को हाइलाइट किया है जो
n टोकन के क्रम के लिए, खुद पर ध्यान देने की सुविधा की मदद से, एम्बेड करने के क्रम में n बार बदलाव किया जाता है. ऐसा क्रम में हर पोज़िशन पर एक बार किया जाता है.
ध्यान देने की सुविधा और एक से ज़्यादा लोगों का ध्यान खींचने के मामले में जाएं.
सेल्फ़-सुपरवाइज़्ड लर्निंग
बिना निगरानी वाली मशीन लर्निंग की समस्या को निगरानी में रखे गए मशीन लर्निंग की समस्या में बदलने की तकनीकों का एक ग्रुप. इसके लिए, बिना लेबल वाले उदाहरणों के सरोगेट लेबल बनाएं.
ट्रांसफ़ॉर्मर पर आधारित कुछ मॉडल, जैसे कि BERT, सेल्फ़-सुपरवाइज़्ड लर्निंग का इस्तेमाल करते हैं.
सेल्फ़-सुपरवाइज़्ड ट्रेनिंग, सेमी-सुपरवाइज़्ड लर्निंग का तरीका है.
सेल्फ़-ट्रेनिंग
सेल्फ़-सुपरवाइज़्ड लर्निंग का एक वैरिएंट, जो खास तौर पर तब मददगार होता है, जब यहां बताई गई सभी स्थितियों में ज़रूरी हो:
- डेटासेट में, लेबल नहीं किए गए उदाहरणों और लेबल किए गए उदाहरणों की संख्या का अनुपात ज़्यादा है.
- यह एक क्लासिफ़िकेशन से जुड़ी समस्या है.
सेल्फ़-ट्रेनिंग, इन दो चरणों में तब तक होती है, जब तक मॉडल बेहतर बनाना बंद नहीं कर देता:
- लेबल किए गए उदाहरणों के हिसाब से मॉडल को ट्रेनिंग देने के लिए, निगरानी में रखे गए मशीन लर्निंग का इस्तेमाल करें.
- पहले चरण में बनाए गए मॉडल का इस्तेमाल करके, बिना लेबल वाले उदाहरणों के लिए अनुमान (लेबल) जनरेट करें. इस मॉडल का इस्तेमाल, ऐसे उदाहरणों के लिए करें जिनमें अनुमानित लेबल वाले लेबल के बारे में ज़्यादा भरोसा हो.
ध्यान दें कि चरण 2 की हर गतिविधि में, पहले चरण के लिए ट्रेनिंग के लिए लेबल किए गए ज़्यादा उदाहरण जोड़े जाते हैं.
सेमी-सुपरवाइज़्ड लर्निंग
ऐसे डेटा के लिए मॉडल को ट्रेनिंग देना जिसमें ट्रेनिंग के कुछ उदाहरणों में लेबल हों, लेकिन अन्य में नहीं. सेमी-सुपरवाइज़्ड लर्निंग की एक तकनीक, बिना लेबल वाले उदाहरणों के लिए लेबल का अनुमान लगाना है. इसके बाद, अनुमानित लेबल के आधार पर नया मॉडल बनाना है. सेमी-सुपरवाइज़्ड लर्निंग तब काम आ सकती है, जब लेबल पाना महंगा हो, लेकिन बिना लेबल वाले उदाहरण बहुत ज़्यादा हों.
सेल्फ़-ट्रेनिंग, सेमी-सुपरवाइज़्ड लर्निंग की एक तकनीक है.
संवेदनशील एट्रिब्यूट
एक ऐसा एट्रिब्यूट जिसे कानूनी, नैतिक, सामाजिक या निजी वजहों से खास तौर पर ध्यान में रखा जा सकता है.भावनाओं का विश्लेषण
आंकड़ों या मशीन लर्निंग के एल्गोरिदम का इस्तेमाल करके, यह तय किया जाता है कि किसी सेवा, प्रॉडक्ट, संगठन या विषय के बारे में किसी ग्रुप का नज़रिया अच्छा है या नहीं. उदाहरण के लिए, सामान्य भाषा की समझ का इस्तेमाल करके, एक एल्गोरिदम यूनिवर्सिटी के किसी कोर्स के टेक्स्ट के ज़रिए दिए गए सुझाव, शिकायत या राय का विश्लेषण कर सकता है. इससे यह पता लगाया जा सकता है कि छात्र-छात्राओं को आम तौर पर किस कोर्स को पसंद या नापसंद किया गया है.
सीक्वेंस मॉडल
ऐसा मॉडल जिसके इनपुट क्रम पर निर्भर होते हैं. उदाहरण के लिए, पहले देखे गए वीडियो के क्रम से अगले वीडियो का अनुमान लगाना.
टास्क को क्रम से लगाने के लिए इस्तेमाल किया जाने वाला टास्क
ऐसा टास्क जो टोकन के इनपुट क्रम को, टोकन के आउटपुट सीक्वेंस में बदलता है. उदाहरण के लिए, क्रम से क्रम के हिसाब से किए जाने वाले दो लोकप्रिय टास्क हैं:
- अनुवादक:
- इनपुट का क्रम: "मुझे तुमसे प्यार है".
- आउटपुट सीक्वेंस का सैंपल: "Je t'aime."
- सवाल का जवाब दें:
- इनपुट का क्रम: "क्या मुझे न्यूयॉर्क में अपनी कार चाहिए?"
- आउटपुट का क्रम: "नहीं, कृपया अपनी कार घर पर रखें."
व्यक्ति खा सकता है
ऑनलाइन अनुमान या ऑफ़लाइन अनुमान की मदद से, अनुमान लगाने के लिए, ट्रेन किए गए मॉडल को उपलब्ध कराने की प्रोसेस.
आकार (टेन्सर)
किसी टेंसर के हर डाइमेंशन में एलिमेंट की संख्या. आकार को पूर्णांकों की सूची के तौर पर दिखाया जाता है. उदाहरण के लिए, नीचे दिए गए द्वि-आयामी टेंसर का आकार [3,4] है:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
TensorFlow, डाइमेंशन का ऑर्डर दिखाने के लिए पंक्ति-मेजर (C-स्टाइल) फ़ॉर्मैट का इस्तेमाल करता है.
इसलिए, TensorFlow में मौजूद आकार [4,3] के बजाय [3,4] है. दूसरे शब्दों में, दो-डाइमेंशन वाले TensorFlow Tensor में, आकार [पंक्तियों की संख्या, कॉलम की संख्या] है.
शार्ड
ट्रेनिंग सेट या मॉडल का लॉजिकल डिवीज़न. आम तौर पर, कुछ प्रोसेस में उदाहरण या पैरामीटर को (आम तौर पर) बराबर साइज़ में बांटकर शार्ड बनाए जाते हैं. फिर प्रत्येक शार्ड को एक अलग मशीन को असाइन कर दिया जाता है.
किसी मॉडल को शार्ड करना मॉडल पैरललिज़्म कहा जाता है; शार्डिंग डेटा को डेटा पैरलिज़्म कहा जाता है.
सिकुड़ना
ग्रेडिएंट बूस्टिंग में हाइपर पैरामीटर, जो ओवरफ़िटिंग को कंट्रोल करता है. ग्रेडिएंट बूस्टिंग में होने वाली कमी, ग्रेडिएंट डिसेंट लर्निंग रेट के बराबर है. श्रिंकेज, 0.0 और 1.0 के बीच का दशमलव मान होता है. कम श्रिंकेज वैल्यू, ज़्यादा श्रिंकेज वैल्यू की तुलना में ओवरफ़िटिंग को कम करती है.
सिगमॉइड फ़ंक्शन
यह गणित का एक फ़ंक्शन है, जो इनपुट वैल्यू को सीमित रेंज में "स्क्विज़" करता है. आम तौर पर, यह 0 से 1 या -1 से +1 तक होता है. इसका मतलब है कि आपके पास किसी भी संख्या (दो, 10 लाख, नेगेटिव अरब को जो भी हो) को सिग्मॉइड पर पास करने का विकल्प होता है और तब भी आउटपुट, सीमित सीमा में ही रहेगा. सिगमॉइड ऐक्टिवेशन फ़ंक्शन का प्लॉट इस तरह दिखता है:
सिगमॉइड फ़ंक्शन को मशीन लर्निंग में कई चीज़ों के लिए इस्तेमाल किया जाता है. इनमें ये शामिल हैं:
- लॉजिस्टिक रिग्रेशन या मल्टीनोमियल रिग्रेशन मॉडल के रॉ आउटपुट को प्रॉबबिलिटी में बदलना.
- कुछ न्यूरल नेटवर्क में, ऐक्टिवेशन फ़ंक्शन के तौर पर काम करना.
समानता का माप
क्लस्टरिंग एल्गोरिदम में, इस मेट्रिक का इस्तेमाल यह तय करने के लिए किया जाता है कि दोनों उदाहरण कितने मिलते-जुलते हैं (कितने मिलते-जुलते हैं).
एक प्रोग्राम / एक से ज़्यादा डेटा (एसपीएमडी)
यह पैरललिज़्म की ऐसी तकनीक है जिसमें अलग-अलग डिवाइसों पर अलग-अलग इनपुट डेटा पर एक ही कंप्यूटेशन की मदद से कंप्यूट किया जाता है. एसपीडीएम का मकसद तेज़ी से नतीजे पाना है. यह पैरलल प्रोग्रामिंग का सबसे आम तरीका है.
साइज़ इन्वैरियंस
इमेज की कैटगरी तय करने से जुड़ी समस्या में, इमेज का साइज़ बदलने पर भी एल्गोरिदम की, इमेज को सही कैटगरी में बांटने की क्षमता. उदाहरण के लिए, एल्गोरिदम अभी भी किसी बिल्ली की पहचान कर सकता है, चाहे वह 2M पिक्सल का इस्तेमाल करे या 200K पिक्सल का. ध्यान दें कि सबसे अच्छे इमेज क्लासिफ़िकेशन एल्गोरिदम में भी साइज़ इन्वैरियंस की कुछ सीमाएं होती हैं. उदाहरण के लिए, हो सकता है कि कोई एल्गोरिदम (या इंसान) सिर्फ़ 20 पिक्सल इस्तेमाल करने वाली बिल्ली की इमेज को सही तरीके से अलग-अलग कैटगरी में नहीं डालता.
ट्रांसलेशनल इनवैरियंस और रोटेशनल इनवैरियंस भी देखें.
स्केचिंग
बिना निगरानी वाली मशीन लर्निंग में, एल्गोरिदम की एक कैटगरी है. यह ऐसे एल्गोरिदम की कैटगरी का इस्तेमाल करती है जो उदाहरणों की मिलती-जुलती जानकारी का शुरुआती विश्लेषण करते हैं. स्केचिंग एल्गोरिदम, इलाके के हिसाब से संवेदनशील हैश फ़ंक्शन का इस्तेमाल करते हैं. इससे उन पॉइंट की पहचान की जाती है जो एक जैसे हो सकते हैं. इसके बाद, उन्हें बकेट में ग्रुप कर देते हैं.
स्केचिंग से, बड़े डेटासेट में समानता की गिनती करने के लिए, ज़रूरी कंप्यूटेशन (कंप्यूटेशन) को कम कर दिया जाता है. डेटासेट में उदाहरणों के हर एक जोड़े के लिए समानता का पता लगाने के बजाय, हम हर बकेट में पॉइंट के हर जोड़े के लिए समानता का हिसाब लगाते हैं.
स्किप-ग्राम
एक n-gram, जो मूल संदर्भ से शब्दों को हटा सकता है (या "अभी नहीं") हो सकता है. इसका मतलब है कि N शब्द मूल रूप से उनके आस-पास नहीं हैं. इसका मतलब है कि "k-skip-n-gram" एक n-ग्राम है, जिसके लिए ज़्यादा से ज़्यादा k शब्द स्किप किए जा सकते हैं.
उदाहरण के लिए, "द क्विक ब्राउन फ़ॉक्स" के ये दो ग्राम हो सकते हैं:
- "तेज़"
- "क्विक ब्राउन"
- "भूरी लोमड़ी"
"1-स्किप-2-ग्राम" ऐसे शब्दों का जोड़ा होता है जिनमें ज़्यादा से ज़्यादा एक शब्द हो. इसलिए, "The Quick Brown fox" के पास ये 1 स्किप 2 ग्राम होते हैं:
- "द ब्राउन"
- "झटपट लोमड़ी"
इसके अलावा, सभी 2-ग्राम 1-स्किप-2-ग्राम भी होते हैं, क्योंकि एक से कम शब्द स्किप किया जा सकता है.
स्किप-ग्राम की मदद से, किसी शब्द से जुड़े कॉन्टेक्स्ट को बेहतर तरीके से समझा जा सकता है. उदाहरण में, "लोमड़ी" को 1-skip-2-grams के सेट में सीधे "Quick" से जोड़ा गया था, लेकिन 2-ग्राम के सेट से नहीं.
स्किप-ग्राम की सुविधा का इस्तेमाल करके, शब्द एम्बेड करने वाले मॉडल को ट्रेनिंग दी जाती है.
सॉफ़्टमैक्स
यह ऐसा फ़ंक्शन है जो मल्टी-क्लास क्लासिफ़िकेशन मॉडल में, हर संभावित क्लास के लिए प्रायिकता तय करता है. प्रायिकता का योग 1.0 होता है. उदाहरण के लिए, नीचे दी गई टेबल से पता चलता है कि सॉफ़्टमैक्स अलग-अलग तरह की संभावनाओं को कैसे बांटता है:
| इमेज है... | प्रॉबेबिलिटी |
|---|---|
| कुत्ता | 0.85 |
| cat | 0.13 |
| घोड़ा | .02 |
सॉफ़्टमैक्स को फ़ुल सॉफ़्टमैक्स भी कहा जाता है.
उम्मीदवार के लिए सैंपलिंग से तुलना करें.
सॉफ़्ट प्रॉम्प्ट ट्यूनिंग
किसी खास टास्क के लिए, बड़े लैंग्वेज मॉडल को ट्यून करने की तकनीक. इस तकनीक में बहुत ज़्यादा संसाधनों वाली बेहतर ट्यूनिंग नहीं होती. मॉडल में सभी वेट को फिर से ट्रेनिंग देने के बजाय, सॉफ़्ट प्रॉम्प्ट ट्यूनिंग से प्रॉम्प्ट में अपने-आप बदलाव होता है. इससे उसी लक्ष्य को हासिल किया जा सकता है.
टेक्स्ट वाले प्रॉम्प्ट को देखते हुए, सॉफ़्ट प्रॉम्प्ट ट्यूनिंग आम तौर पर प्रॉम्प्ट में अतिरिक्त टोकन एम्बेड करता है. साथ ही, इनपुट को ऑप्टिमाइज़ करने के लिए बैकप्रोपैगेशन का इस्तेमाल करता है.
"हार्ड" प्रॉम्प्ट में टोकन एम्बेड करने के बजाय, असल टोकन शामिल होते हैं.
विरल सुविधा
ऐसी सुविधा जिसकी वैल्यू शून्य या खाली है. उदाहरण के लिए, जिस सुविधा में एक वैल्यू और 00 लाख वैल्यू होती है उसे स्पार्स माना जाता है. वहीं दूसरी ओर, गंभीर सुविधा में ऐसी वैल्यू होती हैं जो मुख्य रूप से शून्य या खाली नहीं होती हैं.
मशीन लर्निंग में, बहुत सारी सुविधाएं कम काम की होती हैं. कैटगरी के हिसाब से मिलने वाली सुविधाएं, आम तौर पर कम जानकारी वाली होती हैं. उदाहरण के लिए, जंगल में मौजूद पेड़ों की 300 संभावित प्रजातियों में से, एक उदाहरण से सिर्फ़ मैपल ट्री की पहचान हो सकती है. वीडियो लाइब्रेरी में मौजूद लाखों वीडियो में से, एक उदाहरण से सिर्फ़ "कैसाब्लांका" की पहचान हो सकती है.
आम तौर पर, किसी मॉडल में वन-हॉट एन्कोडिंग की मदद से कम सुविधाओं को दिखाया जाता है. अगर वन-हॉट एन्कोडिंग बड़ी है, तो बेहतर परफ़ॉर्मेंस के लिए, वन-हॉट एन्कोडिंग के ऊपर एम्बेडिंग लेयर का इस्तेमाल किया जा सकता है.
स्पैर्स रिप्रज़ेंटेशन
स्पार्स सुविधा में, शून्य के अलावा अन्य एलिमेंट की सिर्फ़ पोज़िशन को स्टोर करना.
उदाहरण के लिए, मान लीजिए कि species नाम की एक कैटगरी वाली सुविधा किसी खास जंगल में
पेड़ की 36 प्रजातियों की पहचान करती है. मान लें कि हर उदाहरण सिर्फ़ एक प्रजाति की पहचान करता है.
हर उदाहरण में पेड़ की प्रजाति को दिखाने के लिए, वन-हॉट वेक्टर का इस्तेमाल किया जा सकता है.
वन-हॉट वेक्टर में एक 1 (उस उदाहरण में पेड़ की खास प्रजातियों को दिखाने के लिए) और 35 0 (पेड़ की 35 प्रजातियों को दिखाने के लिए) (उस उदाहरण में शामिल नहीं) होंगे. इसलिए, maple का एक बार में ही इस्तेमाल
कुछ ऐसा दिख सकता है:

इसके अलावा, कम दिखने से सिर्फ़ खास प्रजातियों की
स्थिति की पहचान हो जाएगी. अगर maple, रैंक 24 पर है, तो maple का स्पैर्स रिप्रज़ेंटेशन बस यह होगा:
24
ध्यान दें कि एक-हॉट रिप्रज़ेंटेशन की तुलना में, स्पार्स रिप्रज़ेंटेशन ज़्यादा छोटा होता है.
थोड़ा और जटिल उदाहरण देखने के लिए आइकॉन पर क्लिक करें.
मान लीजिए कि आपके मॉडल के हर उदाहरण को एक अंग्रेज़ी वाक्य में शब्दों का प्रतिनिधित्व करना होगा, लेकिन उन शब्दों का क्रम नहीं. अंग्रेज़ी में करीब 1,70,000 शब्द हैं, इसलिए अंग्रेज़ी एक कैटगरी वाली सुविधा है जिसमें करीब 1,70,000 एलिमेंट हैं. अंग्रेज़ी के ज़्यादातर वाक्यों में इन 1,70,000 शब्दों के बहुत ही छोटे से हिस्से का इस्तेमाल किया गया है. इसलिए, किसी एक उदाहरण में शब्दों का सेट, काफ़ी हद तक कम डेटा वाला होगा.
इस वाक्य पर गौर करें:
My dog is a great dog
इस वाक्य में शब्दों को दिखाने के लिए, वन-हॉट वेक्टर के वैरिएंट का इस्तेमाल किया जा सकता है. इस वैरिएंट के मामले में, वेक्टर की एक से ज़्यादा सेल में शून्य के अलावा कोई अन्य वैल्यू हो सकती है. इसके अलावा, इस वैरिएंट में, एक सेल में एक के बजाय एक पूर्णांक हो सकता है. हालांकि, वाक्य में "मेरा", "है", "a", और "बहुत अच्छा" जैसे शब्द सिर्फ़ एक बार दिखते हैं, लेकिन "कुत्ता" शब्द दो बार दिखता है. इस वाक्य में शब्दों को दर्शाने के लिए, वन-हॉट वेक्टर के इस वैरिएंट का इस्तेमाल करने से यह 1,70,000 एलिमेंट वेक्टर हासिल होता है:

एक ही वाक्य को कम शब्दों में इस तरह पेश किया जाएगा:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
स्पार्स वेक्टर
ऐसा वेक्टर जिसकी वैल्यू ज़्यादातर शून्य होती है. इसके अलावा, स्पार्स सुविधा और स्पैर्सिटी के बारे में भी जानें.
कम जानकारी होना
किसी वेक्टर या मैट्रिक्स में शून्य (या शून्य) पर सेट किए गए एलिमेंट की संख्या को उस वेक्टर या मैट्रिक्स में मौजूद एंट्री की कुल संख्या से भाग देने पर मिलने वाली संख्या. उदाहरण के लिए, 100-एलिमेंट वाले ऐसे मैट्रिक्स पर ध्यान दें जिसमें 98 सेल में शून्य हो. स्पार्सिटी का हिसाब लगाने के लिए, यह तरीका अपनाएं:
सुविधा की विरलता का मतलब फ़ीचर वेक्टर की विरलता से है; मॉडल की विरलता का मतलब मॉडल के वेट की विरलता से है.
स्पेशल पूलिंग
पूलिंग देखें.
बांटें
डिसिज़न ट्री में, स्थिति के लिए एक और नाम दिया जाता है.
स्प्लिटर
डिसिज़न ट्री की ट्रेनिंग के दौरान, एक रूटीन और एल्गोरिदम की मदद से, हर नोड के लिए सबसे सही स्थिति का पता लगाया जाता है.
एसपीएमडी
सिंगल प्रोग्राम / एक से ज़्यादा डेटा का छोटा नाम.
वर्गाकार हिंज लॉस
हिंज लॉस का स्क्वेयर. चौकोर हिंज लॉस सामान्य रूप से कब्ज़ों की तुलना में अंतर से ज़्यादा नुकसान पहुंचाता है.
वर्ग लॉस
L2 नुकसान का पर्यायवाची.
कुछ लोगों के लिए ट्रेनिंग
अलग-अलग स्टेज के हिसाब से किसी मॉडल को ट्रेनिंग देने की रणनीति. इसका मकसद, ट्रेनिंग की प्रोसेस को तेज़ करना या मॉडल की क्वालिटी को बेहतर बनाना हो सकता है.
प्रोग्रेसिव स्टैकिंग अप्रोच का इलस्ट्रेशन नीचे दिखाया गया है:
- पहले चरण में तीन छिपी हुई लेयर होती हैं, दूसरे चरण में छह छिपी हुई लेयर, और तीसरे चरण में 12 छिपी हुई लेयर होती हैं.
- दूसरे चरण में, पहले चरण की तीन छिपी हुई लेयर में सीखे गए वज़न के साथ ट्रेनिंग शुरू की जाती है. स्टेज 3, स्टेज 2 की छिपी छह लेयर में सीखे गए वज़न के साथ ट्रेनिंग शुरू करती है.
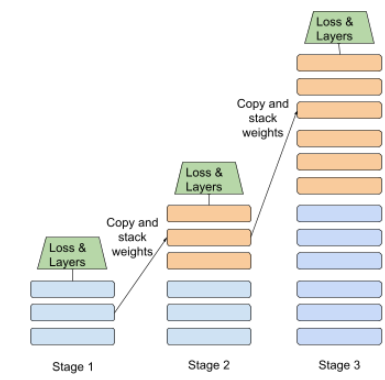
पाइपलाइनिंग भी देखें.
state
रीइन्फ़ोर्समेंट लर्निंग में, पैरामीटर की वे वैल्यू होती हैं जो एनवायरमेंट के मौजूदा कॉन्फ़िगरेशन के बारे में बताती हैं. इनका इस्तेमाल एजेंट, कोई कार्रवाई चुनने के लिए करता है.
स्टेट-ऐक्शन वैल्यू फ़ंक्शन
Q-फ़ंक्शन का समानार्थी शब्द.
स्टैटिक
लगातार करने के बजाय एक बार किया गया. स्टैटिक और ऑफ़लाइन शब्दों के समानार्थी शब्द हैं. मशीन लर्निंग में स्टैटिक और ऑफ़लाइन इस्तेमाल के सामान्य तरीके नीचे दिए गए हैं:
- स्टैटिक मॉडल (या ऑफ़लाइन मॉडल) ऐसा मॉडल है जिसे एक बार ट्रेनिंग दी गई है और फिर इसे कुछ समय तक इस्तेमाल किया जाता है.
- स्टैटिक ट्रेनिंग (या ऑफ़लाइन ट्रेनिंग), स्टैटिक मॉडल को ट्रेनिंग देने की प्रोसेस है.
- स्टैटिक अनुमान (या ऑफ़लाइन अनुमान) ऐसी प्रोसेस है जिसमें मॉडल एक समय पर अनुमानों का बैच जनरेट करता है.
डाइनैमिक से कंट्रास्ट करें.
स्टैटिक अनुमान
ऑफ़लाइन अनुमान के लिए समानार्थी शब्द.
स्टेशनरिटी
ऐसी सुविधा जिसकी वैल्यू एक या उससे ज़्यादा डाइमेंशन में नहीं बदलती. ऐसा आम तौर पर, समय के साथ होता है. उदाहरण के लिए, किसी सुविधा की वैल्यू, 2021 और 2023 में एक जैसी दिखती है.
असल दुनिया में, बहुत कम सुविधाएं स्टेशनरिटी दिखाती हैं. यहां तक कि स्थिरता के साथ पर्यायवाची सुविधाएं (जैसे, समुद्र का स्तर) समय के साथ बदलती रहती हैं.
नॉनस्टेशनरिटी से कंट्रास्ट करें.
चरण
एक बैच का फ़ॉरवर्ड पास और बैकवर्ड पास.
फ़ॉरवर्ड पास और बैकवर्ड पास के बारे में ज़्यादा जानकारी के लिए, बैकप्रोपगेशन देखें.
स्टेप साइज़
सीखने की दर का समानार्थी शब्द.
स्टोकेस्टिक ग्रेडिएंट डिसेंट (एसजीडी)
एक ग्रेडिएंट डिसेंट एल्गोरिदम, जिसमें बैच साइज़ एक है. दूसरे शब्दों में कहें, तो SGD किसी ट्रेनिंग सेट से, किसी भी क्रम में चुने गए एक उदाहरण के आधार पर ट्रेनिंग लेता है.
स्ट्राइड
कॉन्वलूशनल ऑपरेशन या पूलिंग में, इनपुट स्लाइस की अगली सीरीज़ के हर डाइमेंशन में मौजूद डेल्टा. उदाहरण के लिए, नीचे दिया गया ऐनिमेशन, कॉन्वलूशनल ऑपरेशन के दौरान स्ट्राड (1,1) दिखाता है. इसलिए, अगला इनपुट स्लाइस, पिछले इनपुट स्लाइस की दाईं ओर एक पोज़िशन से शुरू करता है. जब कार्रवाई दाएँ किनारे पर पहुंचती है, तो अगला टुकड़ा पूरी तरह से बाईं ओर लेकिन एक स्थिति नीचे होता है.
पहले का उदाहरण दो-डाइमेंशन वाले मूव को दिखाता है. अगर इनपुट मैट्रिक्स थ्री-डाइमेंशन वाला है, तो स्ट्राड भी तीन-डाइमेंशन में होगा.
स्ट्रक्चरल रिस्क मिनिमाइज़ेशन (एसआरएम)
एक ऐसा एल्गोरिदम जो दो लक्ष्यों को संतुलित करता है:
- सबसे अनुमानित मॉडल बनाने की ज़रूरत. उदाहरण के लिए, सबसे कम नुकसान.
- मॉडल को जितना हो सके उतना आसान बनाए रखने की ज़रूरत होना. उदाहरण के लिए, रेगुलर एक्सप्रेशन का इस्तेमाल करना.
उदाहरण के लिए, जो फ़ंक्शन ट्रेनिंग सेट पर लॉस+रेगुलराइज़ेशन को कम करता है, वह स्ट्रक्चरल रिस्क कम करने का एल्गोरिदम है.
empirical जोखिम को कम करने से अलग करें.
सबसैंपलिंग
पूलिंग देखें.
सबवर्ड टोकन
भाषा के मॉडल में, एक टोकन होता है. यह किसी शब्द की सबस्ट्रिंग होता है. इसमें पूरा शब्द हो सकता है.
उदाहरण के लिए, "itemize" जैसे किसी शब्द को "आइटम" (रूट शब्द) और "ize" (एक सफ़िक्स) अलग-अलग हिस्सों में बांटा जा सकता है. हर एक हिस्से को उसके टोकन से दिखाया जाता है. आम तौर पर इस्तेमाल न होने वाले शब्दों को सब-वर्ड (सबवर्ड) में बांटा जाता है. इससे भाषा के मॉडल, शब्द के सामान्य हिस्सों, जैसे कि प्रीफ़िक्स और सफ़िक्स के हिसाब से काम करते हैं.
वहीं, "जा रहे हैं" जैसे सामान्य शब्दों को अलग-अलग नहीं किया जा सकता और उन्हें एक ही टोकन से दिखाया जा सकता है.
खास जानकारी
TensorFlow में, किसी खास कदम के हिसाब से तय की गई वैल्यू या वैल्यू का सेट. आम तौर पर, इसका इस्तेमाल ट्रेनिंग के दौरान मॉडल मेट्रिक को ट्रैक करने के लिए किया जाता है.
सुपरवाइज़्ड मशीन लर्निंग
model और उनके model की मदद से किसी model को ट्रेनिंग देना. सुपरवाइज़्ड मशीन लर्निंग, किसी विषय को सीखने जैसा ही है. इसमें सवालों के सेट और उनसे जुड़े जवाबों को पढ़ा जाता है. सवालों और जवाबों के बीच मैपिंग करने में महारत हासिल करने के बाद, छात्र-छात्राएं उसी विषय से जुड़े नए (पहले कभी नहीं देखे गए) सवालों के जवाब दे सकते हैं.
बिना निगरानी वाली मशीन लर्निंग से तुलना करें.
एआई की मदद से जनरेट की गई सुविधा
ऐसी सुविधा जो इनपुट सुविधाओं में मौजूद नहीं होती, बल्कि उन्हें एक या एक से ज़्यादा सुविधाओं से तैयार की जाती है. सिंथेटिक सुविधाएं बनाने के तरीकों में ये शामिल हैं:
- रेंज बिन में लगातार चलने वाली सुविधा बकेट करना.
- सुविधा क्रॉस बनाना.
- एक सुविधा की वैल्यू को अन्य सुविधा की वैल्यू से या उसी से गुणा करना (या भाग देना). उदाहरण के लिए, अगर
aऔरbइनपुट सुविधाएं हैं, तो यहां एआई की मदद से बनाए गए फ़ीचर के उदाहरण दिए गए हैं:- ab
- ए2
- किसी सुविधा की वैल्यू में ट्रांसेंडेंटल फ़ंक्शन लागू करना. उदाहरण के लिए, अगर
cकोई इनपुट सुविधा है, तो सिंथेटिक सुविधाओं के उदाहरण यहां दिए गए हैं:- sin(c)
- ln(c)
सिर्फ़ नॉर्मलाइज़ या स्केलिंग करके बनाई गई सुविधाओं को सिंथेटिक फ़ीचर नहीं माना जाता.
T
T5
टेक्स्ट-टू-टेक्स्ट ट्रांसफ़र लर्निंग मॉडल की शुरुआत Google के एआई (AI) ने 2020 में की थी. T5 एक एन्कोडर-डीकोडर मॉडल है, जो ट्रांसफ़ॉर्मर आर्किटेक्चर पर आधारित है और जिसे बहुत बड़े डेटासेट पर ट्रेनिंग दी गई है. यह नैचुरल लैंग्वेज में प्रोसेसिंग के कई कामों में कारगर है. जैसे, टेक्स्ट जनरेट करना, भाषाओं का अनुवाद करना, और बातचीत के ज़रिए सवालों के जवाब देना.
"टेक्स्ट-टू-टेक्स्ट ट्रांसफ़र ट्रांसफ़ॉर्मर" में पांच T5 गेम का नाम T5 है.
टी5एक्स
यह एक ओपन सोर्स मशीन लर्निंग फ़्रेमवर्क है. इसे बड़े पैमाने पर नैचुरल लैंग्वेज प्रोसेसिंग (एनएलपी) मॉडल बनाने और ट्रेन करने के लिए डिज़ाइन किया गया है. T5 को T5X कोड बेस पर लागू किया गया है. इसे JAX और Flax पर बनाया गया है.
टेबल में क्यू-लर्निंग
इन्फ़ोर्समेंट लर्निंग में, क्यू-लर्निंग को लागू करने के लिए एक टेबल का इस्तेमाल करें. इसमें स्टेट और ऐक्शन के हर कॉम्बिनेशन के लिए, Q-फ़ंक्शन सेव किए जाते हैं.
टारगेट
label का समानार्थी शब्द.
टारगेट नेटवर्क
डीप क्यू-लर्निंग में, एक ऐसा न्यूरल नेटवर्क है जो मुख्य न्यूरल नेटवर्क का एक स्थायी अनुमान होता है. इसमें मुख्य न्यूरल नेटवर्क, क्यू-फ़ंक्शन या नीति लागू करता है. इसके बाद, टारगेट नेटवर्क की अनुमान लगाई गई Q-वैल्यू के आधार पर, मुख्य नेटवर्क को ट्रेनिंग दी जा सकती है. इसलिए, जब मुख्य नेटवर्क खुद अनुमानित Q-वैल्यू के आधार पर ट्रेनिंग लेता है, तब ऐसा फ़ीडबैक लूप को रोका जाता है. इस सुझाव से बचने से, ट्रेनिंग की स्थिरता बढ़ जाती है.
टास्क
एक ऐसी समस्या जिसे मशीन लर्निंग की तकनीकों की मदद से हल किया जा सकता है, जैसे:
तापमान
ऐसा हाइपर पैरामीटर, जो किसी मॉडल के आउटपुट की रैंडमनेस को कंट्रोल करता है. ज़्यादा तापमान से ज़्यादा आउटपुट मिलता है, वहीं कम तापमान से आउटपुट कम मिलता है.
सबसे अच्छा तापमान चुनना, मॉडल के आउटपुट के खास ऐप्लिकेशन और पसंदीदा प्रॉपर्टी पर निर्भर करता है. उदाहरण के लिए, क्रिएटिव आउटपुट जनरेट करने वाला ऐप्लिकेशन बनाते समय, शायद आपको तापमान बढ़ाना चाहिए. इसके ठीक उलट, इमेज और टेक्स्ट की कैटगरी तय करने वाला मॉडल बनाते समय आपको तापमान कम करना चाहिए. इससे मॉडल को ज़्यादा सटीक और एक जैसा अनुभव मिलेगा.
तापमान का इस्तेमाल अक्सर softmax के साथ किया जाता है.
टेम्पोरल डेटा
अलग-अलग समय पर रिकॉर्ड किया गया डेटा. उदाहरण के लिए, साल के हर दिन के लिए रिकॉर्ड की गई गर्मी के कोट की बिक्री का डेटा, अस्थायी डेटा होगा.
टेन्सर
TensorFlow प्रोग्राम में प्राइमरी डेटा स्ट्रक्चर. टेन्सर, N-डाइमेंशन वाले डेटा स्ट्रक्चर होते हैं (जहां N बहुत बड़ा हो सकता है) डेटा स्ट्रक्चर, आम तौर पर स्केलर, वेक्टर या मैट्रिक्स. टेन्सर के एलिमेंट में पूर्णांक, फ़्लोटिंग-पॉइंट या स्ट्रिंग वैल्यू हो सकती हैं.
TensorBoard
यह डैशबोर्ड, TensorFlow के एक या उससे ज़्यादा प्रोग्राम चलाने के दौरान सेव की गई जानकारी दिखाता है.
TensorFlow
एक बड़ा, डिस्ट्रिब्यूटेड, मशीन लर्निंग प्लैटफ़ॉर्म. इस टर्म का मतलब TensorFlow स्टैक में बेस एपीआई लेयर से भी है, जो डेटाफ़्लो ग्राफ़ पर सामान्य कंप्यूटेशन
हालांकि, TensorFlow का इस्तेमाल मुख्य रूप से मशीन लर्निंग के लिए किया जाता है, लेकिन TensorFlow का इस्तेमाल गैर-एमएल टास्क के लिए भी किया जा सकता है. इसके लिए डेटाफ़्लो ग्राफ़ का इस्तेमाल करके संख्यात्मक गणना करना ज़रूरी होता है.
TensorFlow प्लेग्राउंड
ऐसा प्रोग्राम जो यह दिखाता है कि अलग-अलग हाइपर पैरामीटर, मॉडल (मुख्य तौर पर न्यूरल नेटवर्क) की ट्रेनिंग पर कैसे असर डालते हैं. TensorFlow Playground के साथ एक्सपेरिमेंट करने के लिए, http://playground.tensorflow.org पर जाएं.
TensorFlow सर्विंग
प्रोडक्शन में प्रशिक्षित मॉडल को डिप्लॉय करने का प्लैटफ़ॉर्म.
टेन्सर प्रोसेसिंग यूनिट (टीपीयू)
यह ऐप्लिकेशन के हिसाब से इंटिग्रेट किया गया सर्किट (एएसआईसी) होता है. यह मशीन लर्निंग के वर्कलोड की परफ़ॉर्मेंस को ऑप्टिमाइज़ करता है. इन एएसआईसी को, TPU डिवाइस पर कई TPU चिप के तौर पर डिप्लॉय किया जाता है.
Tensor की रैंक
रैंक (टेन्सर) देखें.
टेन्सर का आकार
अलग-अलग डाइमेंशन में मौजूद टेन्सर के एलिमेंट की संख्या.
उदाहरण के लिए, [5, 10] टेन्सर का एक डाइमेंशन में 5 और दूसरे डाइमेंशन में 10 का साइज़ है.
टेन्सर का साइज़
किसी टेन्सर में मौजूद स्केलर की कुल संख्या. उदाहरण के लिए, [5, 10] Tensor का साइज़ 50 है.
TensorStore
बड़ी बहु-आयामी अरे को बेहतर तरीके से पढ़ने और लिखने के लिए, एक लाइब्रेरी.
समझौता खत्म करने की स्थिति
इन्फ़ोर्समेंट लर्निंग में, वे शर्तें तय होती हैं जो किसी एपिसोड के खत्म होने के बाद तय होती हैं. जैसे, जब एजेंट किसी खास स्थिति में पहुंच जाए या उसकी सीमा पार हो जाए. उदाहरण के लिए, tic-tac-toe में (जिसे नॉट्स और क्रॉस भी कहा जाता है), खिलाड़ी या तो लगातार तीन स्पेस मार्क करने या सभी स्पेस मार्क होने पर एपिसोड खत्म हो जाता है.
जांच
डिसिज़न ट्री में, स्थिति के लिए एक और नाम दिया जाता है.
टेस्ट में नुकसान
टेस्ट सेट के मुकाबले, मॉडल की लॉस दिखाने वाली मेट्रिक. model बनाते समय, आम तौर पर टेस्ट में होने वाले नुकसान को कम करने की कोशिश की जाती है. ऐसा इसलिए होता है, क्योंकि टेस्ट में कम नुकसान होने का मतलब है कि ट्रेनिंग में कमी या पुष्टि में कमी के मुकाबले, इसकी क्वालिटी अच्छी है.
टेस्ट में नुकसान होने और ट्रेनिंग न मिलने या पुष्टि न होने की वजह से, कभी-कभी आपको रेगुलराइज़ेशन रेट बढ़ाने की ज़रूरत पड़ सकती है.
टेस्ट सेट
डेटासेट का एक सबसेट, जो ट्रेन किए गए मॉडल की जांच के लिए रिज़र्व है.
परंपरागत तौर पर, डेटासेट में दिए गए उदाहरणों को, इन तीन अलग-अलग सबसेट में बांटा गया है:
- ट्रेनिंग सेट
- पुष्टि करने का सेट
- टेस्ट सेट
डेटासेट में दिया गया हर उदाहरण, पहले के किसी एक सबसेट से ही जुड़ा होना चाहिए. उदाहरण के लिए, कोई एक उदाहरण ट्रेनिंग सेट और टेस्ट सेट, दोनों से जुड़े नहीं होने चाहिए.
ट्रेनिंग सेट और पुष्टि करने वाले सेट, दोनों किसी मॉडल को ट्रेनिंग देने से जुड़े होते हैं. टेस्ट का सेट, सिर्फ़ ट्रेनिंग से जुड़ा है. इसलिए, ट्रेनिंग में कमी या पुष्टि में कमी की तुलना में, टेस्ट लॉस कम पक्षपातपूर्ण और ज़्यादा क्वालिटी वाली मेट्रिक है.
टेक्स्ट स्पैन
यह अरे इंडेक्स स्पैन, जो किसी टेक्स्ट स्ट्रिंग के किसी खास सब-सेक्शन से जुड़ा होता है.
उदाहरण के लिए, Python स्ट्रिंग s="Be good now" में good शब्द,
3 से 6 तक के टेक्स्ट स्पैन का इस्तेमाल करता है.
tf.Example
मशीन लर्निंग मॉडल ट्रेनिंग या अनुमान के लिए, इनपुट डेटा की जानकारी देने के लिए एक स्टैंडर्ड प्रोटोकॉल बफ़र.
tf.keras
TensorFlow में इंटिग्रेट किए गए Keras को लागू करना.
थ्रेशोल्ड (डिसिज़न ट्री के लिए)
ऐक्सिस की अलाइन स्थिति में, वह वैल्यू जिसके साथ सुविधा की तुलना की जा रही है. उदाहरण के लिए, नीचे दी गई स्थिति में थ्रेशोल्ड वैल्यू 75 है:
grade >= 75
टाइम सीरीज़ का विश्लेषण
मशीन लर्निंग और आंकड़ों का एक सबफ़ील्ड जो टेम्परल डेटा का विश्लेषण करता है. मशीन लर्निंग से जुड़ी कई तरह की समस्याओं के लिए टाइम सीरीज़ का विश्लेषण करना पड़ता है. इसमें किसी डेटा को अलग-अलग कैटगरी में बांटना, क्लस्टरिंग, पूर्वानुमान, और गड़बड़ी की पहचान करना शामिल है. उदाहरण के लिए, पुरानी बिक्री के डेटा के आधार पर, महीने के हिसाब से सर्दियों वाले कोट की बिक्री का अनुमान लगाने के लिए, टाइम सीरीज़ विश्लेषण का इस्तेमाल किया जा सकता है.
टाइमस्टेप
बार-बार होने वाले न्यूरल नेटवर्क में एक "अनरोल किया गया" सेल. उदाहरण के लिए, नीचे दिए गए डायग्राम में तीन टाइम स्टेप दिखाए गए हैं (इन्हें सबस्क्रिप्ट t-1, t, और t+1 के साथ लेबल किया गया है):

टोकन
भाषा के मॉडल में, वह एटॉमिक यूनिट जिस पर मॉडल ट्रेनिंग दे रहा है और अनुमान लगा रहा है. टोकन आम तौर पर इनमें से एक होता है:
- कोई शब्द—उदाहरण के लिए, "कुत्तों जैसे बिल्लियों" वाक्यांश के तीन शब्द टोकन होते हैं: "कुत्ते", "पसंद", और "बिल्लियां".
- एक वर्ण—उदाहरण के लिए, वाक्यांश "बाइक मछली" में नौ वर्ण के टोकन होते हैं. (ध्यान दें कि खाली जगह को एक टोकन के तौर पर गिना जाता है.)
- सबवर्ड—जिसमें एक शब्द एक टोकन या एक से ज़्यादा टोकन हो सकता है. सबवर्ड में रूट शब्द, प्रीफ़िक्स या सफ़िक्स होता है. उदाहरण के लिए, अगर किसी भाषा मॉडल में टोकन के तौर पर सबवर्ड का इस्तेमाल किया जाता है, तो हो सकता है कि उसे "कुत्ते" शब्द को दो टोकन (मूल शब्द "डॉग" और बहुवचन सफ़िक्स "s") के तौर पर दिखाया जाए. भाषा का यही मॉडल, "लंबा" शब्द को दो सबवर्ड (मूल शब्द "tall" और सफ़िक्स "er") के तौर पर देख सकता है.
भाषा मॉडल के बाहर के डोमेन के टोकन, दूसरी तरह की ऐटॉमिक यूनिट हो सकते हैं. उदाहरण के लिए, कंप्यूटर विज़न में, टोकन किसी इमेज का सबसेट हो सकता है.
Tower
डीप न्यूरल नेटवर्क का एक कॉम्पोनेंट, जो डीप न्यूरल नेटवर्क है. कुछ मामलों में, हर टावर एक स्वतंत्र डेटा सोर्स से पढ़ता है और वे टावर तब तक स्वतंत्र रहते हैं, जब तक उनका आउटपुट एक फ़ाइनल लेयर में नहीं जुड़ जाता. दूसरे मामलों में, (उदाहरण के लिए, कई ट्रांसफ़ॉर्मर के एन्कोडर और डीकोडर स्टैक/टावर में) टावर के एक-दूसरे से क्रॉस-कनेक्शन होते हैं.
TPU
टेनसर प्रोसेसिंग यूनिट का छोटा नाम.
TPU चिप
ऑन-चिप हाई बैंडविथ मेमोरी वाला प्रोग्राम करने लायक लीनियर अलजेब्रा ऐक्सेलरेटर, जिसे मशीन लर्निंग के वर्कलोड के लिए ऑप्टिमाइज़ किया गया है. TPU डिवाइस पर कई TPU चिप डिप्लॉय किए गए हैं.
TPU डिवाइस
कई TPU चिप, ज़्यादा बैंडविथ वाले नेटवर्क इंटरफ़ेस, और सिस्टम कूलिंग हार्डवेयर वाला प्रिंट किया गया सर्किट बोर्ड (पीसीबी).
TPU मास्टर
यह एक होस्ट मशीन पर चलने वाली सेंट्रल कोऑर्डिनेशन प्रोसेस है, जो TPU वर्कर को डेटा, नतीजे, प्रोग्राम, परफ़ॉर्मेंस, और सिस्टम की परफ़ॉर्मेंस की जानकारी भेजती और हासिल करती है. TPU मास्टर, TPU डिवाइसों के सेट अप और शटडाउन को भी मैनेज करता है.
TPU नोड
Google Cloud पर एक खास TPU टाइप वाला TPU संसाधन. TPU नोड, किसी मिलते-जुलते VPC नेटवर्क की मदद से, आपके VPC नेटवर्क से कनेक्ट होता है. TPU नोड, Cloud TPU API में बताए गए संसाधन होते हैं.
टीपीयू (TPU) पॉड
Google के डेटा सेंटर में, TPU डिवाइसों का खास कॉन्फ़िगरेशन. TPU पॉड में मौजूद सभी डिवाइस, एक खास हाई-स्पीड नेटवर्क के ज़रिए एक-दूसरे से कनेक्ट होते हैं. TPU पॉड, TPU डिवाइसों का सबसे बड़ा कॉन्फ़िगरेशन है. यह किसी खास TPU वर्शन के लिए उपलब्ध होता है.
TPU संसाधन
Google Cloud पर मौजूद ऐसी TPU इकाई जिसे आप बनाया जाता है, मैनेज किया जाता है या इस्तेमाल किया जाता है. उदाहरण के लिए, TPU नोड और TPU टाइप, TPU रिसॉर्स होते हैं.
TPU स्लाइस
TPU स्लाइस, TPU पॉड में मौजूद TPU डिवाइसों का फ़्रैक्शनल हिस्सा होता है. TPU स्लाइस में मौजूद सभी डिवाइस, एक खास हाई-स्पीड नेटवर्क के ज़रिए एक-दूसरे से कनेक्ट होते हैं.
TPU टाइप
किसी खास TPU हार्डवेयर वर्शन वाले एक या इससे ज़्यादा TPU डिवाइसों का कॉन्फ़िगरेशन. Google Cloud पर TPU नोड बनाते समय, TPU टाइप चुना जाता है. उदाहरण के लिए, v2-8
TPU टाइप, 8 कोर वाला एक TPU v2 डिवाइस है. v3-2048 TPU टाइप में 256 नेटवर्क वाले TPU v3 डिवाइस और कुल 2048 कोर होते हैं. TPU के टाइप, ऐसे संसाधन होते हैं जिनके बारे में Cloud TPU API में बताया गया है.
TPU वर्कर
यह ऐसी प्रोसेस है जो होस्ट मशीन पर चलती है और TPU डिवाइसों पर मशीन लर्निंग प्रोग्राम एक्ज़ीक्यूट करती है.
ट्रेनिंग
सबसे सही पैरामीटर (वेट और पूर्वाग्रह) तय करने की प्रोसेस में, एक मॉडल शामिल होता है. ट्रेनिंग के दौरान, सिस्टम उदाहरण पढ़ता है और धीरे-धीरे पैरामीटर में बदलाव करता है. ट्रेनिंग में हर उदाहरण का इस्तेमाल कभी-कभी से लेकर अरबों बार किया जाता है.
ट्रेनिंग नहीं मिली
यह एक मेट्रिक है, जो खास तौर पर ट्रेनिंग के दौरान मॉडल को हुए लॉस के बारे में बताती है. उदाहरण के लिए, मान लें कि लॉस फ़ंक्शन मीन स्क्वेयर्ड एरर है. ऐसा हो सकता है कि 10वीं क्वेरी के दौरान, ट्रेनिंग लॉस (मीन स्क्वेयर्ड एरर) 2.2 हो और 100वें चरण के दौरान ट्रेनिंग में नुकसान 1.9 हो.
लॉस कर्व में, ट्रेनिंग में हुए नुकसान की तुलना में बार-बार होने वाले दोहराव की तुलना की जाती है. लॉस कर्व से ट्रेनिंग के बारे में ये संकेत मिलते हैं:
- नीचे की ओर वाले स्लोप का मतलब है कि मॉडल में सुधार हो रहा है.
- ऊपर की ओर वाले स्लोप का मतलब है कि मॉडल बदतर हो रहा है.
- सपाट ढलान का मतलब है कि मॉडल कन्वर्ज़न तक पहुंच गया है.
उदाहरण के लिए, नीचे दिए गए कुछ आदर्श फ़ॉर्मैट में लॉस कर्व दिखाता है:
- शुरुआती दौर में इसका नीचे की ओर का स्लोप बहुत ज़्यादा था. इसका मतलब है कि मॉडल ने तेज़ी से मॉडल में सुधार किया.
- ट्रेनिंग के खत्म होने तक, धीरे-धीरे सपाट (लेकिन नीचे की ओर) होने वाला स्लोप होता है. इसका मतलब है कि शुरुआती दौर में मॉडल को बेहतर बनाने की प्रक्रिया कुछ धीमी रफ़्तार से होती है.
- ट्रेनिंग के खत्म होने की तरफ़ का सपाट ढलान, जिससे दर्शकों को एक ही जगह के खिलाड़ी में शामिल होने का सुझाव मिलता है.

हालांकि, ट्रेनिंग खत्म करना ज़रूरी है, लेकिन सामान्य जानकारी भी देखें.
ट्रेनिंग और ब्राउज़र में वेब पेज खोलने के दौरान परफ़ॉर्मेंस में अंतर
ट्रेनिंग के दौरान किसी मॉडल की परफ़ॉर्मेंस और सर्विंग के दौरान उसी मॉडल की परफ़ॉर्मेंस के बीच का अंतर.
ट्रेनिंग सेट
किसी मॉडल को ट्रेनिंग देने के लिए इस्तेमाल किए गए डेटासेट का सबसेट.
पारंपरिक तौर पर, डेटासेट में दिए गए उदाहरणों को इन तीन अलग-अलग सबसेट में बांटा गया है:
- ट्रेनिंग सेट
- पुष्टि करने का सेट
- टेस्ट सेट
आम तौर पर, डेटासेट में दिया गया हर उदाहरण, पहले के सबसेट में से किसी एक से जुड़ा होना चाहिए. उदाहरण के लिए, कोई एक उदाहरण ट्रेनिंग सेट और पुष्टि सेट, दोनों से नहीं जुड़ा होना चाहिए.
ट्रजेक्टरी
रीइन्फ़ोर्समेंट लर्निंग में, टपल का एक क्रम होता है. यह एजेंट के स्टेट ट्रांज़िशन का क्रम दिखाता है. इसमें हर टपल, स्थिति, ऐक्शन, इनाम, और किसी स्थिति के ट्रांज़िशन के लिए अगली स्थिति से जुड़ा होता है.
ट्रांसफ़र लर्निंग
एक मशीन लर्निंग टास्क से दूसरे टास्क में जानकारी ट्रांसफ़र करना. उदाहरण के लिए, मल्टी-टास्क लर्निंग में, एक मॉडल कई टास्क हल करता है. उदाहरण के लिए, डीप मॉडल जिसमें अलग-अलग टास्क के लिए अलग-अलग आउटपुट नोड होते हैं. ट्रांसफ़र लर्निंग में, किसी आसान टास्क से मुश्किल काम में जानकारी को ट्रांसफ़र करना या किसी ऐसे टास्क से जानकारी को ट्रांसफ़र करना शामिल हो सकता है जिसमें कम डेटा हो.
ज़्यादातर मशीन लर्निंग सिस्टम से एक टास्क ही हल होता है. ट्रांसफ़र लर्निंग, आर्टिफ़िशियल इंटेलिजेंस की ओर कदम है. इसमें एक ही प्रोग्राम से कई टास्क पूरे किए जा सकते हैं.
ट्रांसफ़र्मर
यह Google का एक न्यूरल नेटवर्क आर्किटेक्चर है. यह सेल्फ़-अटेंशन मैकेनिज़्म पर निर्भर होता है. इसकी मदद से, इनपुट एम्बेड करने के क्रम को आउटपुट एम्बेड करने के क्रम में बदला जाता है. इसके लिए, कन्वोलूशन या बार-बार न्यूरल नेटवर्क पर निर्भर नहीं रहना पड़ता. ट्रांसफ़ॉर्मर को खुद का ध्यान रखने वाली लेयर के स्टैक के तौर पर देखा जा सकता है.
ट्रांसफ़ॉर्मर में इनमें से कुछ भी शामिल किया जा सकता है:
एन्कोडर, एम्बेड करने के क्रम को समान लंबाई के नए क्रम में बदल देता है. किसी एन्कोडर में N एक जैसी लेयर होती हैं और हर लेयर में दो सब-लेयर होते हैं. ये दो सब-लेयर, इनपुट एम्बेड करने वाले सीक्वेंस की हर पोज़िशन पर लागू होते हैं. इससे सीक्वेंस का हर एलिमेंट एक नए एम्बेडिंग में बदल जाता है. पहला एन्कोडर सब-लेयर, इनपुट के क्रम में मौजूद जानकारी को इकट्ठा करता है. एन्कोडर की दूसरी सब-लेयर, इकट्ठा की गई जानकारी को आउटपुट एम्बेड करने में बदल देती है.
डीकोडर, इनपुट एम्बेड करने के क्रम को आउटपुट एम्बेडिंग के क्रम में बदल देता है. यह वीडियो की लंबाई अलग हो सकती है. डिकोडर में तीन सब-लेयर वाली N एक जैसी लेयर भी शामिल होती हैं. इनमें से दो लेयर, एन्कोडर सब-लेयर की तरह होती हैं. तीसरा डिकोडर सब-लेयर, एन्कोडर का आउटपुट लेता है और उससे जानकारी इकट्ठा करने के लिए, सेल्फ़-अटेंशन का इस्तेमाल करता है.
Transformer: A Novel Neural Network लगाती फ़ॉर लैंग्वेज समझ वाली ब्लॉग पोस्ट, ट्रांसफ़ॉर्मर के बारे में अच्छे से बताती है.
ट्रांसलेशनल इन्वैरियंस
इमेज क्लासिफ़िकेशन की समस्या में, इमेज के अंदर ऑब्जेक्ट की जगह बदलने पर भी, एल्गोरिदम की इमेज को सही तरीके से अलग-अलग कैटगरी में बांटने की क्षमता. उदाहरण के लिए, एल्गोरिदम अब भी कुत्ते की पहचान कर सकता है. भले ही, वह फ़्रेम के बीच में हो या फ़्रेम के बाईं ओर.
साइज़ इनवैरियंस और रोटेशनल इनवैरियंस भी देखें.
ट्राइग्राम
ऐसा N-ग्राम जिसमें N=3 हो.
वास्तविक नकारात्मक (TN)
एक उदाहरण, जिसमें मॉडल नेगेटिव क्लास का सही अनुमान लगाता है. उदाहरण के लिए, मॉडल अनुमान लगाता है कि कोई खास ईमेल मैसेज स्पैम नहीं है और वह ईमेल मैसेज वाकई स्पैम नहीं है.
ट्रू पॉज़िटिव (टीपी)
एक उदाहरण, जिसमें मॉडल पॉज़िटिव क्लास का सही अनुमान लगाता है. उदाहरण के लिए, मॉडल अनुमान लगाता है कि कोई खास ईमेल मैसेज स्पैम है और वह ईमेल मैसेज वाकई स्पैम है.
ट्रू पॉज़िटिव रेट (टीपीआर)
recall का समानार्थी शब्द. यानी:
ट्रू पॉज़िटिव रेट, आरओसी कर्व में y-ऐक्सिस होता है.
U
अनजाने में हुई जानकारी (किसी संवेदनशील एट्रिब्यूट के बारे में)
ऐसी स्थिति जिसमें संवेदनशील एट्रिब्यूट मौजूद होते हैं, लेकिन ट्रेनिंग डेटा में शामिल नहीं किए जाते. संवेदनशील एट्रिब्यूट को अक्सर किसी व्यक्ति के डेटा के अन्य एट्रिब्यूट के साथ जोड़ा जाता है. इसलिए, अगर किसी मॉडल को संवेदनशील एट्रिब्यूट के बारे में जानकारी न होने की वजह से ट्रेनिंग दी गई है, तो इसका असर अब भी उस एट्रिब्यूट पर अलग-अलग असर हो सकता है. इसके अलावा, यह भी हो सकता है कि वह अन्य फ़ेयरनेस कंस्ट्रेंट का उल्लंघन करता हो.
अंडरफ़िटिंग
ऐसा model बनाना जिसमें अनुमान लगाने की क्षमता कम हो, क्योंकि मॉडल ने ट्रेनिंग डेटा की जटिलता को पूरी तरह से कैप्चर नहीं किया है. कई समस्याओं की वजह से कम फ़िटिंग हो सकती है, जिनमें ये शामिल हैं:
- गलत सुविधाओं के सेट के लिए ट्रेनिंग देना.
- बहुत कम epoch या बहुत कम लर्निंग रेट के लिए ट्रेनिंग.
- बहुत ज़्यादा रेगुलराइज़ेशन रेट वाला ट्रेनिंग.
- डीप न्यूरल नेटवर्क में बहुत कम छिपी हुई लेयर उपलब्ध कराना.
अंडरसैंपलिंग
क्लास असंतुलित डेटासेट में से मैजरिटी क्लास से उदाहरण हटाएं, ताकि ज़्यादा सटीक ट्रेनिंग सेट बनाया जा सके.
उदाहरण के लिए, ऐसे डेटासेट पर विचार करें जिसमें ज़्यादातर क्लास और माइनरिटी क्लास का अनुपात 20:1 है. क्लास के इस असंतुलन को दूर करने के लिए, एक ट्रेनिंग सेट बनाया जा सकता है. इसमें अल्पसंख्यक क्लास के सभी उदाहरण शामिल होंगे, लेकिन ज़्यादातर क्लास के दसवें उदाहरण ही इस सेट में शामिल होंगे. इससे ट्रेनिंग सेट, क्लास का अनुपात 2:1 बनेगा. कम सैंपलिंग की वजह से, ज़्यादा संतुलित ट्रेनिंग सेट बेहतर मॉडल बना सकता है. इसके अलावा, इस ज़्यादा संतुलित ट्रेनिंग सेट में शायद कम उदाहरण मौजूद हों कि एक असरदार मॉडल को ट्रेनिंग दी जा सके.
ओवरसैंपलिंग से कंट्रास्ट बढ़ाएं.
एकतरफ़ा
एक सिस्टम जो सिर्फ़ टेक्स्ट के टारगेट सेक्शन से पहले उस टेक्स्ट का आकलन करता है. इसके उलट, बाय-डायरेक्शनल सिस्टम, टेक्स्ट के टारगेट सेक्शन से पहले और पहले, दोनों टेक्स्ट का आकलन करता है. ज़्यादा जानकारी के लिए, दो रास्ते पर जाएं.
एकतरफ़ा लैंग्वेज मॉडल
भाषा का ऐसा मॉडल जो टारगेट टोकन के बाद दिखने के बाद के बजाय, सिर्फ़ टोकन के आधार पर अपनी क्षमताओं को तय करता है. दो-तरफ़ा भाषा के मॉडल से कंट्रास्ट अलग होना चाहिए.
बिना लेबल वाले मैसेज का उदाहरण
उदाहरण के लिए, जिसमें सुविधाएं हों, लेकिन लेबल न हो. उदाहरण के लिए, नीचे दी गई टेबल में घर के वैल्यूएशन मॉडल के बिना लेबल वाले तीन उदाहरण दिखाए गए हैं. हर एक में तीन सुविधाएं हैं, लेकिन कोई हाउस वैल्यू नहीं है:
| कमरों की संख्या | बाथरूम की संख्या | घर की उम्र |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
निगरानी में रखे गए मशीन लर्निंग में, मॉडल लेबल किए गए उदाहरणों के आधार पर ट्रेनिंग देते हैं और बिना लेबल वाले उदाहरणों के आधार पर अनुमान लगाते हैं.
सेमी की निगरानी में और बिना निगरानी वाली लर्निंग में, बिना लेबल वाले उदाहरण का इस्तेमाल ट्रेनिंग के दौरान किया जाता है.
बिना लेबल वाले उदाहरण को लेबल किए गए उदाहरण से अलग करें.
अनसुपरवाइज़्ड मशीन लर्निंग
किसी डेटासेट में पैटर्न ढूंढने के लिए, model को ट्रेनिंग देना. आम तौर पर, इस डेटासेट को लेबल नहीं किया जाता है.
बिना निगरानी वाली मशीन लर्निंग का सबसे ज़्यादा इस्तेमाल, डेटा को क्लस्टर के तौर पर, मिलते-जुलते उदाहरणों के ग्रुप में देना है. उदाहरण के लिए, बिना निगरानी वाला मशीन लर्निंग एल्गोरिदम, संगीत की अलग-अलग प्रॉपर्टी के हिसाब से गानों को इकट्ठा कर सकता है. नतीजे के तौर पर बने क्लस्टर, दूसरे मशीन लर्निंग एल्गोरिदम के लिए इनपुट बन सकते हैं. उदाहरण के लिए, संगीत का सुझाव देने वाली सेवा के लिए. उपयोगी लेबल कम या मौजूद न होने पर, क्लस्टरिंग से मदद मिल सकती है. उदाहरण के लिए, गलत इस्तेमाल और धोखाधड़ी जैसे मामलों में क्लस्टर की मदद से इंसान डेटा को बेहतर ढंग से समझ सकते हैं.
निगरानी वाली मशीन लर्निंग से अलग हैं.
अपलिफ़्ट मॉडलिंग
मॉडलिंग की एक तकनीक, जो आम तौर पर मार्केटिंग में इस्तेमाल की जाती है. यह किसी "ट्रीटमेंट" के "आकर्षक असर" (जिसे "इंक्रीमेंटल असर" भी कहा जाता है) को मॉडल करती है. ऐसा करने के दो उदाहरण यहां दिए गए हैं:
- डॉक्टर, मरीज़ों की उम्र और स्वास्थ्य के इतिहास के आधार पर किसी मेडिकल प्रोसेस (ट्रीटमेंट) में होने वाली
- मार्केटर, खरीदारी की संभावना में बढ़ोतरी का अनुमान लगाने के लिए, अपलिफ़्ट मॉडलिंग का इस्तेमाल कर सकते हैं. ऐसा किसी व्यक्ति (एक व्यक्ति) पर दिखाए गए विज्ञापन (ट्रीटमेंट) की वजह से (कारण पर होने वाला असर) होने की संभावना का अनुमान लगाने के लिए किया जाता है.
अपलिफ़्ट मॉडलिंग, क्लासिफ़िकेशन या रिग्रेशन से अलग है. ऐसा इसलिए है, क्योंकि कुछ लेबल (उदाहरण के लिए, बाइनरी ट्रीटमेंट में आधे लेबल) में, प्रमोशनल कॉन्टेंट की परफ़ॉर्मेंस को बेहतर बनाने वाले मॉडल में हमेशा मौजूद नहीं होता. उदाहरण के लिए, मरीज़ को इलाज मिल सकता है या नहीं भी हो सकता है. इसलिए, हम सिर्फ़ इन दो स्थितियों में से यह पता लगा सकते हैं कि मरीज़ ठीक हो जाएगा या नहीं (लेकिन दोनों स्थितियों में ही यह ठीक नहीं होगा). अपलिफ़्ट मॉडल का मुख्य फ़ायदा यह है कि यह बिना निगरानी वाली स्थिति (काउंटरफ़ैक्चुअल) के लिए अनुमान जनरेट कर सकता है और इसका इस्तेमाल वजह से होने वाले असर का पता लगाने के लिए कर सकता है.
ज़्यादा वज़न हासिल करना
डाउनसैंपल किया गया क्लास में वेट लागू करना. यह उस फ़ैक्टर के बराबर होना चाहिए जिससे आपने डाउनसैंपल किया है.
उपयोगकर्ता मैट्रिक्स
सुझाव देने वाले सिस्टम में, मैट्रिक्स फ़ैक्टराइज़ेशन से जनरेट किया गया एम्बेड करने वाला वेक्टर होता है. इसमें, उपयोगकर्ता की प्राथमिकताओं के बारे में छुपे हुए सिग्नल होते हैं. यूज़र मैट्रिक्स की हर लाइन में किसी एक उपयोगकर्ता के लिए, अलग-अलग लेटेंट सिग्नल की तुलनात्मक क्षमता के बारे में जानकारी होती है. उदाहरण के लिए, फ़िल्म का सुझाव देने वाले किसी सिस्टम का इस्तेमाल करें. इस सिस्टम में, यूज़र मैट्रिक्स में मौजूद लेटेंट सिग्नल, किसी खास शैली में हर उपयोगकर्ता की दिलचस्पी दिखा सकते हैं. इसके अलावा, हो सकता है कि ऐसे सिग्नल को समझना मुश्किल हो जिनमें कई चीज़ों के आधार पर इंटरैक्शन करना मुश्किल होता है.
यूज़र मैट्रिक्स में हर लेटेंट सुविधा के लिए एक कॉलम और हर उपयोगकर्ता के लिए एक लाइन होती है. इसका मतलब है कि यूज़र मैट्रिक्स में पंक्तियों की संख्या, टारगेट मैट्रिक्स के बराबर है, जिसे फ़ैक्टराइज़ किया जा रहा है. उदाहरण के लिए, 10,00,000 उपयोगकर्ताओं के लिए फ़िल्म के सुझाव देने वाले सिस्टम में, उपयोगकर्ता मैट्रिक्स में 10,00,000 लाइनें होंगी.
V
पुष्टि करना
किसी मॉडल की क्वालिटी का शुरुआती आकलन. पुष्टि, पुष्टि करने के सेट के लिए किसी मॉडल के अनुमान की क्वालिटी की जांच करती है.
पुष्टि करने वाला सेट, ट्रेनिंग सेट से अलग होता है. इसलिए, पुष्टि करने की सुविधा से, ओवरफ़िट होने से बचा जा सकता है.
आपको जांच के पहले राउंड के तौर पर, पुष्टि करने के सेट के साथ मॉडल का आकलन करने के बारे में सोचना पड़ सकता है. इसके बाद, टेस्टिंग के दूसरे चरण के तौर पर, टेस्ट सेट के साथ इस मॉडल का आकलन किया जा सकता है.
पुष्टि नहीं हो पाने की समस्या
एक मेट्रिक, जो ट्रेनिंग के किसी खास दोहराव के दौरान, पुष्टि करने के सेट पर मॉडल की लॉस दिखाती है.
सामान्य तरीके से बताने वाला कर्व भी देखें.
पुष्टि करने का सेट
यह डेटासेट का सबसेट है, जो किसी प्रशिक्षित मॉडल की मदद से शुरुआती आकलन करता है. आम तौर पर, टेस्ट सेट के हिसाब से मॉडल का आकलन करने से पहले, कई बार पुष्टि करने के सेट के हिसाब से मॉडल का आकलन किया जाता है.
परंपरागत तौर पर, डेटासेट में दिए गए उदाहरणों को, इन तीन अलग-अलग सबसेट में बांटा गया है:
- ट्रेनिंग सेट
- पुष्टि करने का सेट
- टेस्ट सेट
आम तौर पर, डेटासेट में दिया गया हर उदाहरण, पहले के सबसेट में से किसी एक से जुड़ा होना चाहिए. उदाहरण के लिए, कोई एक उदाहरण ट्रेनिंग सेट और पुष्टि सेट, दोनों से नहीं जुड़ा होना चाहिए.
वैल्यू इंप्यूटेशन
किसी छूटी हुई वैल्यू को स्वीकार किए जा सकने वाले विकल्प से बदलने की प्रोसेस. अगर कोई वैल्यू मौजूद नहीं है, तो या तो पूरे उदाहरण को खारिज किया जा सकता है या उदाहरण को बचाने के लिए, वैल्यू इंप्युटेशन का इस्तेमाल किया जा सकता है.
उदाहरण के लिए, ऐसे डेटासेट पर विचार करें जिसमें temperature सुविधा हो और जिसे हर घंटे रिकॉर्ड किया जाना चाहिए. हालांकि, किसी एक घंटे के लिए
तापमान की रीडिंग नहीं मिल सकी. यहां डेटासेट का एक सेक्शन दिया गया है:
| टाइमस्टैंप | तापमान |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | मौजूद नहीं |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
कोई सिस्टम या तो इस उदाहरण को मिटा सकता है या एंप्यूटेशन एल्गोरिदम के आधार पर, उस तापमान को 12, 16, 18 या 20 के तौर पर दिखा सकता है जो मौजूद नहीं है.
गायब होने वाले ग्रेडिएंट से जुड़ी समस्या
कुछ डीप न्यूरल नेटवर्क की शुरुआती छिपी हुई लेयर के ग्रेडिएंट, बहुत सपाट (कम) हो जाते हैं. ग्रेडिएंट में तेज़ी से होने वाली कमी की वजह से डीप न्यूरल नेटवर्क में नोड पर वज़न में छोटे-मोटे बदलाव होते हैं. इस वजह से सीखना-सिखाना या बिलकुल नहीं बनाना पड़ता है. गायब होने वाले ग्रेडिएंट की समस्या से जूझ रहे मॉडल को ट्रेनिंग देना मुश्किल या नामुमकिन हो जाता है. लॉन्ग शॉर्ट टर्म मेमोरी सेल इस समस्या को हल करती हैं.
एक्सप्लोडिंग ग्रेडिएंट समस्या से तुलना करें.
वैरिएबल की अहमियत
स्कोर का एक सेट, जो मॉडल के लिए हर सुविधा की अहमियत दिखाता है.
उदाहरण के लिए, घर की कीमतों का अनुमान लगाने वाले डिसिज़न ट्री पर विचार करें. मान लीजिए कि इस डिसिज़न ट्री में तीन सुविधाओं का इस्तेमाल किया जाता है: साइज़, उम्र, और स्टाइल. अगर तीन सुविधाओं के लिए अलग-अलग अहमियत वाले सेट को {size=5.8, age=2.5, style=4.7} के हिसाब से कैलकुलेट किया जाता है, तो फ़ैसले ट्री के लिए साइज़, उम्र या स्टाइल से ज़्यादा ज़रूरी होता है.
वैरिएबल की अहमियत बताने वाली अलग-अलग मेट्रिक मौजूद हैं. इनसे मशीन लर्निंग के विशेषज्ञों को मॉडल के अलग-अलग पहलुओं के बारे में जानकारी मिल सकती है.
वैरिएशनल ऑटोएन्कोडर (VAE)
यह एक तरह का ऑटोएन्कोडर है, जो इनपुट के बदले हुए वर्शन जनरेट करने के लिए, इनपुट और आउटपुट के बीच अंतर का इस्तेमाल करता है. वैरिएशनल ऑटोएन्कोडर, जनरेटिव एआई के लिए मददगार हैं.
वीएई, वैरिएशनल अनुमान पर आधारित होते हैं: यह प्रॉबबिलिटी मॉडल के पैरामीटर का अनुमान लगाने की तकनीक है.
वेक्टर
बहुत ज़्यादा लोड हुआ शब्द, जिसका मतलब अलग-अलग गणितीय और वैज्ञानिक क्षेत्रों में अलग-अलग होता है. मशीन लर्निंग में, वेक्टर में दो प्रॉपर्टी होती हैं:
- डेटा टाइप: मशीन लर्निंग में वेक्टर में आम तौर पर फ़्लोटिंग-पॉइंट नंबर होते हैं.
- एलिमेंट की संख्या: वेक्टर की लंबाई या उसका डाइमेंशन.
उदाहरण के लिए, ऐसे फ़ीचर वेक्टर का इस्तेमाल करें जिसमें आठ फ़्लोटिंग-पॉइंट नंबर हों. इस फ़ीचर वेक्टर की लंबाई या डाइमेंशन आठ है. ध्यान दें कि मशीन लर्निंग वेक्टर में अक्सर बहुत ज़्यादा डाइमेंशन होते हैं.
कई तरह की जानकारी को वेक्टर के तौर पर दिखाया जा सकता है. उदाहरण के लिए:
- पृथ्वी की सतह पर किसी भी जगह को दो डाइमेंशन वाले वेक्टर के तौर पर दिखाया जा सकता है. इसमें एक डाइमेंशन का अक्षांश और दूसरा देशांतर होता है.
- 500 स्टॉक में से हर एक की मौजूदा कीमतों को 500-डाइमेंशन वाले वेक्टर के तौर पर दिखाया जा सकता है.
- क्लास की सीमित संख्या में प्रॉबबिलिटी डिस्ट्रिब्यूशन को वेक्टर के तौर पर दिखाया जा सकता है. उदाहरण के लिए, मल्टीक्लास क्लासिफ़िकेशन सिस्टम, जो तीन आउटपुट कलर (लाल, हरा या पीला) में से किसी एक का अनुमान लगाता है, तो इससे वेक्टर
(0.3, 0.2, 0.5)को आउटपुट के तौर परP[red]=0.3, P[green]=0.2, P[yellow]=0.5माना जा सकता है.
वेक्टर को जोड़ा जा सकता है. इसलिए, कई तरह के मीडिया को एक वेक्टर के तौर पर दिखाया जा सकता है. कुछ मॉडल, कई वन-हॉट एन्कोडिंग के साथ सीधे काम करते हैं.
वेक्टर पर गणित के सवाल हल करने के लिए, TPU जैसे खास प्रोसेसर को ऑप्टिमाइज़ किया जाता है.
वेक्टर, रैंक 1 का टेंसर होता है.
W
वासरस्टाइन लॉस
जनरेटिव पर बुरा असर डालने वाले नेटवर्क में आम तौर पर, नुकसान पहुंचाने वाले फ़ंक्शन का इस्तेमाल किया जाता है. यह डेटा, जनरेट किए गए डेटा और असल डेटा के डिस्ट्रिब्यूशन के बीच की पृथ्वी मूवर की दूरी पर आधारित होता है.
वज़न का डेटा
वह वैल्यू जिसे मॉडल, किसी दूसरी वैल्यू से गुणा करता है. ट्रेनिंग, किसी मॉडल के लिए उसका सही वेट तय करने की प्रोसेस है. अनुमान, वह प्रोसेस है जिसमें सीखे गए वज़न का इस्तेमाल करके अनुमान लगाया जाता है.
वेटेड ऑल्टरनेटिंग लीस्ट स्क्वेयर (WALS)
सुझाव देने वाले सिस्टम में मैट्रिक्स फ़ैक्टराइज़ेशन के दौरान मकसद फ़ंक्शन को कम करने के लिए, एक एल्गोरिदम. इससे, उन उदाहरणों को कम अहमियत दी जाती है जो मौजूद नहीं हैं. WALS, पंक्ति के फ़ैक्टराइज़ेशन और कॉलम के फ़ैक्टराइज़ेशन को ठीक करके, ओरिजनल मैट्रिक्स और रीकंस्ट्रक्शन के बीच वेटेड स्क्वेयर गड़बड़ी को कम करता है. इनमें से हर ऑप्टिमाइज़ेशन को कम से कम स्क्वेयर कन्वर्ज़न ऑप्टिमाइज़ेशन की मदद से हल किया जा सकता है. ज़्यादा जानकारी के लिए, सुझाव देने वाले सिस्टम का कोर्स देखें.
भारित योग
सभी ज़रूरी इनपुट वैल्यू का योग, उनके भार से गुणा किया जाता है. उदाहरण के लिए, मान लें कि काम के इनपुट में ये शामिल हैं:
| इनपुट वैल्यू | इनपुट वज़न |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
इसलिए, भारित योग यह होता है:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
वेटेड योग, किसी ऐक्टिवेशन फ़ंक्शन का इनपुट आर्ग्युमेंट है.
चौड़ा मॉडल
एक लीनियर मॉडल, जिसमें आम तौर पर कई स्पार्स इनपुट सुविधाएं होती हैं. हम इसे "वाइड" कहते हैं, क्योंकि यह एक खास तरह का न्यूरल नेटवर्क होता है. इसमें बड़ी संख्या में ऐसे इनपुट होते हैं जो सीधे आउटपुट नोड से कनेक्ट होते हैं. डीप मॉडल की तुलना में, वाइड मॉडल को डीबग करना और उनकी जांच करना अक्सर आसान होता है. हालांकि, वाइड मॉडल छिपी हुई लेयर के ज़रिए नॉन-लीनियरिटी को ज़ाहिर नहीं कर सकते. हालांकि, वाइड मॉडल फ़ीचर क्रॉसिंग और बकेटाइज़ेशन जैसे ट्रांसफ़ॉर्मेशन का इस्तेमाल अलग-अलग तरीकों से कर सकते हैं.
डीप मॉडल से कंट्रास्ट अलग करें.
चौड़ाई
किसी न्यूरल नेटवर्क की किसी खास लेयर में न्यूरॉन की संख्या.
लोगों की सूझ-बूझ
यह विचार कि लोगों के एक बड़े समूह ("भीड़") के विचारों या अनुमानों का औसतन करने से अक्सर बहुत ही अच्छे नतीजे मिलते हैं. उदाहरण के लिए, एक ऐसे गेम पर विचार करें जिसमें लोग एक बड़े जार में पैक किए गए जेली बीन की संख्या का अनुमान लगाते हैं. हालांकि, ज़्यादातर अलग-अलग अनुमान गलत होंगे, लेकिन सभी अनुमानों का औसत जार में मौजूद जेली बीन की असल संख्या के काफ़ी करीब दिखाया गया है.
Ensembles, लोगों की सूझ-बूझ का सॉफ़्टवेयर होता है. भले ही, अलग-अलग मॉडल बहुत ही गलत अनुमान लगा देते हैं, लेकिन कई मॉडल के अनुमानों का औसतन अक्सर बहुत से अच्छे अनुमान लगा देता है. उदाहरण के लिए, हो सकता है कि किसी फ़ैसले ट्री का इस्तेमाल करने पर लोग गलत अनुमान लगा पाएं, लेकिन डिसिज़न ट्री से अक्सर बहुत अच्छे अनुमान मिलते हैं.
शब्द एम्बेड करना
एम्बेडिंग वेक्टर में मौजूद किसी शब्द के सेट के हर शब्द को दिखाएं. इसका मतलब है कि हर शब्द को 0.0 और 1.0 के बीच की फ़्लोटिंग-पॉइंट वैल्यू के वेक्टर के तौर पर दिखाना. एक जैसे मतलब वाले शब्दों के मतलब, अलग-अलग मतलब वाले शब्दों के मुकाबले ज़्यादा मिलते-जुलते होते हैं. उदाहरण के लिए, गाजर, अजवाइन, और खीरे की जानकारी करीब-करीब एक जैसी होगी. यह हवाई जहाज़, धूप के चश्मे, और टूथपेस्ट के तरीकों से बहुत अलग होगा.
X
XLA (एक्सीरेटेड लीनियर अलजेब्रा)
जीपीयू, सीपीयू, और एमएल एक्सेलरेटर के लिए ओपन सोर्स मशीन लर्निंग कंपाइलर.
XLA कंपाइलर, PyTorch, TensorFlow, और JAX जैसे लोकप्रिय एमएल फ़्रेमवर्क के मॉडल लेता है. साथ ही, उन्हें अलग-अलग हार्डवेयर प्लैटफ़ॉर्म पर अच्छी परफ़ॉर्मेंस के लिए ऑप्टिमाइज़ करता है. इन हार्डवेयर प्लैटफ़ॉर्म में, GPU, सीपीयू, और एमएल ऐक्सेलरेटर शामिल हैं.
Z
ज़ीरो-शॉट लर्निंग
यह एक तरह की ट्रेनिंग होती है, जिसमें मॉडल किसी ऐसे टास्क के लिए अनुमान का अनुमान लगाता है जिसके लिए उसे पहले से ट्रेनिंग नहीं दी गई थी. दूसरे शब्दों में, मॉडल को किसी टास्क के लिए कोई ट्रेनिंग नहीं दी गई है. उदाहरण उसे दिए गए हैं, लेकिन उसे उस टास्क के लिए अनुमान लगाने के लिए कहा गया है.
ज़ीरो-शॉट प्रॉम्प्ट
एक प्रॉम्प्ट, जिसमें इस बात का उदाहरण नहीं होता कि आपको किस तरह लार्ज लैंग्वेज मॉडल से जवाब देना है. उदाहरण के लिए:
| एक प्रॉम्प्ट के हिस्से | ज़रूरी जानकारी |
|---|---|
| किसी चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब एलएलएम से देना है. |
| भारत: | असल क्वेरी. |
बड़ा लैंग्वेज मॉडल इनमें से किसी का भी जवाब दे सकता है:
- रुपया
- INR
- ₹
- भारतीय रुपया
- रुपया
- भारतीय रुपया
सभी जवाब सही हैं, लेकिन हो सकता है कि आपको कोई खास फ़ॉर्मैट इस्तेमाल करना पड़े.
ज़ीरो-शॉट प्रॉम्प्ट की तुलना नीचे दिए गए शब्दों से करें:
ज़ेड-स्कोर नॉर्मलाइज़ेशन
स्केलिंग की तकनीक, जो रॉ सुविधा की वैल्यू को फ़्लोटिंग-पॉइंट वैल्यू से बदल देती है. यह वैल्यू, उस सुविधा के मीन से स्टैंडर्ड डीविएशन की संख्या दिखाती है. उदाहरण के लिए, ऐसी सुविधा पर विचार करें जिसका माध्य 800 है और जिसका मानक विचलन 100 है. इस टेबल में बताया गया है कि Z-स्कोर नॉर्मलाइज़ेशन की मदद से, रॉ वैल्यू को Z-स्कोर पर कैसे मैप किया जाएगा:
| असल वैल्यू | ज़ेड-स्कोर |
|---|---|
| 800 | 0 |
| 950 | 1.5 से ज़्यादा |
| 575 | से 2.25 |
इसके बाद, मशीन लर्निंग मॉडल उस सुविधा के लिए, रॉ वैल्यू के बजाय Z-स्कोर के आधार पर ट्रेनिंग लेता है.