Este glossário define termos de inteligência artificial.
A
ablação
Uma técnica para avaliar a importância de um atributo ou componente removendo temporariamente de um modelo. Em seguida, treine o modelo novamente sem esse atributo ou componente. Se o modelo retreinado tiver um desempenho significativamente pior, o atributo ou componente removido provavelmente era importante.
Por exemplo, suponha que você treine um modelo de classificação em 10 recursos e alcance 88% de precisão no conjunto de teste. Para verificar a importância do primeiro atributo, treine o modelo novamente usando apenas os outros nove atributos. Se o modelo retreinado tiver um desempenho significativamente pior (por exemplo, 55% de precisão), o atributo removido provavelmente era importante. Por outro lado, se o modelo retreinado tiver um desempenho igualmente bom, esse recurso provavelmente não era tão importante.
A ablação também pode ajudar a determinar a importância de:
- Componentes maiores, como um subsistema inteiro de um sistema de ML maior
- Processos ou técnicas, como uma etapa de pré-processamento de dados
Em ambos os casos, você vai observar como o desempenho do sistema muda (ou não) depois de remover o componente.
Teste A/B
Uma maneira estatística de comparar duas (ou mais) técnicas: A e B. Normalmente, A é uma técnica já existente, e B é uma técnica nova. O teste A/B não apenas determina qual técnica tem melhor performance, mas também se a diferença é estatisticamente significativa.
O teste A/B geralmente compara uma única métrica em duas técnicas. Por exemplo, como a acurácia do modelo se compara em duas técnicas? No entanto, o teste A/B também pode comparar qualquer número finito de métricas.
ícone de atalho
Uma categoria de componentes de hardware especializados projetados para realizar cálculos importantes necessários para algoritmos de aprendizado profundo.
Os chips aceleradores (ou apenas aceleradores, para abreviar) podem aumentar significativamente a velocidade e a eficiência das tarefas de treinamento e inferência em comparação com uma CPU de uso geral. Eles são ideais para treinar redes neurais e tarefas semelhantes que exigem muito poder de computação.
Exemplos de chips aceleradores:
- Unidades de Processamento de Tensor (TPUs) do Google com hardware dedicado para aprendizado profundo.
- As GPUs da NVIDIA, embora inicialmente projetadas para processamento gráfico, são projetadas para permitir o processamento paralelo, o que pode aumentar significativamente a velocidade de processamento.
precisão
O número de previsões de classificação corretas dividido pelo número total de previsões. Ou seja:
Por exemplo, um modelo que fez 40 previsões corretas e 10 incorretas teria uma acurácia de:
A classificação binária fornece nomes específicos para as diferentes categorias de previsões corretas e incorretas. Assim, a fórmula de acurácia para classificação binária é a seguinte:
em que:
- TP é o número de verdadeiros positivos (previsões corretas).
- TN é o número de verdadeiros negativos (previsões corretas).
- FP é o número de falsos positivos (previsões incorretas).
- FN é o número de falsos negativos (previsões incorretas).
Compare e contraste a acurácia com a precisão e o recall.
Consulte Classificação: acurácia, recall, precisão e métricas relacionadas no Curso intensivo de machine learning para mais informações.
ação
Na aprendizagem por reforço, o mecanismo pelo qual o agente faz a transição entre estados do ambiente. O agente escolhe a ação usando uma política.
função de ativação
Uma função que permite que as redes neurais aprendam relações não lineares (complexas) entre os recursos e o rótulo.
As funções de ativação mais usadas incluem:
Os gráficos das funções de ativação nunca são linhas retas únicas. Por exemplo, o gráfico da função de ativação ReLU consiste em duas linhas retas:

Um gráfico da função de ativação sigmoide tem esta aparência:

Clique no ícone para ver um exemplo.
Em uma rede neural, as funções de ativação manipulam a soma ponderada de todas as entradas para um neurônio. Para calcular uma soma ponderada, o neurônio adiciona os produtos dos valores e pesos relevantes. Por exemplo, suponha que a entrada relevante para um neurônio consista no seguinte:
| valor de entrada | peso de entrada |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
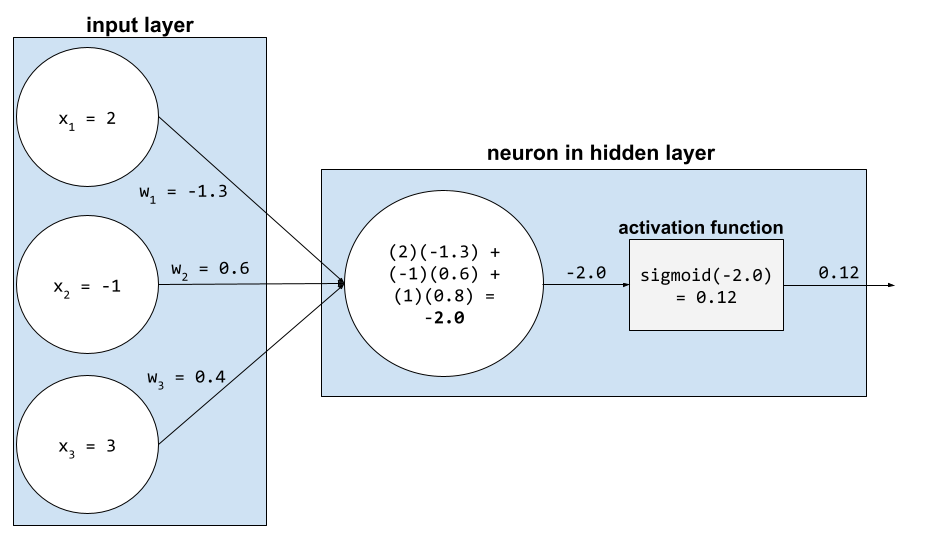
Consulte Redes neurais: funções de ativação no Curso intensivo de machine learning para mais informações.
aprendizagem ativa
Uma abordagem de treinamento em que o algoritmo escolhe alguns dos dados com que aprende. O aprendizado ativo é particularmente valioso quando os exemplos rotulados são escassos ou caros de obter. Em vez de buscar cegamente uma variedade de exemplos rotulados, um algoritmo de aprendizado ativo busca seletivamente o intervalo específico de exemplos necessários para o aprendizado.
AdaGrad
Um algoritmo sofisticado de gradiente descendente que redimensiona os gradientes de cada parâmetro, a cada um deles uma taxa de aprendizado independente. Para uma explicação completa, consulte Adaptive Subgradient Methods for Online Learning and Stochastic Optimization (em inglês).
adaptação
Sinônimo de ajuste ou ajuste fino.
agente
Software que pode raciocinar sobre entradas multimodais do usuário para planejar e executar ações em nome dele.
No aprendizado por reforço, um agente é a entidade que usa uma política para maximizar o retorno esperado obtido com a transição entre estados do ambiente.
agêntico / agêntica
A forma adjetiva de agente. Agêntico se refere às qualidades que os agentes têm, como autonomia.
fluxo de trabalho com agentes
Um processo dinâmico em que um agente planeja e executa ações de forma autônoma para alcançar uma meta. O processo pode envolver raciocínio, invocação de ferramentas externas e autocorreção do plano.
clustering aglomerativo
Consulte clustering hierárquico.
AI slop
Saída de um sistema de IA generativa que prioriza a quantidade em vez da qualidade. Por exemplo, uma página da Web com slop de IA é preenchida com conteúdo de baixa qualidade, gerado por IA e produzido de forma barata.
detecção de anomalias
O processo de identificar outliers. Por exemplo, se a média de um determinado recurso for 100 com um desvio padrão de 10, a detecção de anomalias vai sinalizar um valor de 200 como suspeito.
AR
Abreviação de realidade aumentada.
área sob a curva PR
Consulte AUC PR (área sob a curva PR).
área sob a curva ROC
Consulte AUC (área sob a curva ROC).
inteligência artificial geral
Um mecanismo não humano que demonstra uma ampla gama de resolução de problemas, criatividade e adaptabilidade. Por exemplo, um programa que demonstre inteligência artificial geral pode traduzir texto, compor sinfonias e se destacar em jogos que ainda não foram inventados.
inteligência artificial
Um programa ou modelo não humano que pode resolver tarefas sofisticadas. Por exemplo, programas ou modelos que traduzem texto ou que identificam doenças usando imagens radiológicas usam inteligência artificial.
Formalmente, o aprendizado de máquina é um subcampo da inteligência artificial. Mas, nos últimos anos, algumas organizações começaram a usar os termos inteligência artificial e aprendizado de máquina como sinônimos.
atenção
Um mecanismo usado em uma rede neural que indica a importância de uma palavra ou parte dela. A atenção comprime a quantidade de informações que um modelo precisa para prever o próximo token/palavra. Um mecanismo de atenção típico pode consistir em uma soma ponderada em um conjunto de entradas, em que o peso de cada entrada é calculado por outra parte da rede neural.
Consulte também autoatenção e autoatenção de várias cabeças, que são os blocos de construção dos Transformadores.
Consulte LLMs: o que é um modelo de linguagem grande? no Curso intensivo de machine learning para mais informações sobre autoatenção.
atributo
Sinônimo de recurso.
Na imparcialidade do aprendizado de máquina, os atributos geralmente se referem a características relacionadas a indivíduos.
amostragem de atributos
Uma tática para treinar uma floresta de decisão em que cada árvore de decisão considera apenas um subconjunto aleatório de possíveis atributos ao aprender a condição. Em geral, um subconjunto diferente de recursos é amostrado para cada nó. Por outro lado, ao treinar uma árvore de decisão sem amostragem de atributos, todos os recursos possíveis são considerados para cada nó.
AUC (área sob a curva ROC)
Um número entre 0,0 e 1,0 que representa a capacidade de um modelo de classificação binária separar classes positivas de classes negativas. Quanto mais perto de 1,0 a AUC estiver, melhor será a capacidade do modelo de distinguir as classes.
Por exemplo, a ilustração a seguir mostra um modelo de classificação que separa perfeitamente as classes positivas (ovais verdes) das negativas (retângulos roxos). Esse modelo irrealisticamente perfeito tem uma AUC de 1,0:

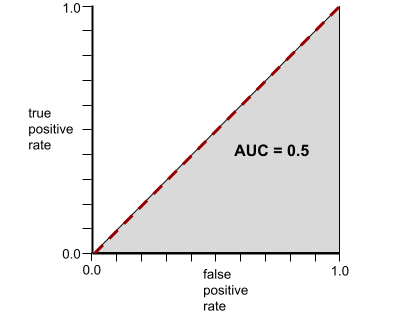
Por outro lado, a ilustração a seguir mostra os resultados de um modelo de classificação que gerou resultados aleatórios. Esse modelo tem uma AUC de 0,5:

Sim, o modelo anterior tem uma AUC de 0,5, não de 0,0.
A maioria dos modelos está em algum lugar entre os dois extremos. Por exemplo, o modelo a seguir separa um pouco os positivos dos negativos e, portanto, tem uma AUC entre 0,5 e 1,0:

A AUC ignora qualquer valor definido para o limite de classificação. Em vez disso, a AUC considera todos os limiares de classificação possíveis.
Clique no ícone para saber mais sobre a relação entre AUC e curvas ROC.
A AUC representa a área sob uma curva ROC. Por exemplo, a curva ROC de um modelo que separa perfeitamente positivos de negativos tem esta aparência:
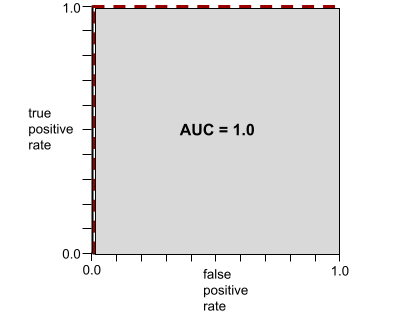
A AUC é a área da região cinza na ilustração anterior. Nesse caso incomum, a área é simplesmente o comprimento da região cinza (1,0) multiplicado pela largura da região cinza (1,0). Portanto, o produto de 1,0 e 1,0 gera uma AUC de exatamente 1,0, que é a pontuação mais alta possível.
Por outro lado, a curva ROC de um modelo de classificação que não consegue separar classes é assim: A área dessa região cinza é 0,5.
Uma curva ROC mais típica tem aproximadamente esta aparência:
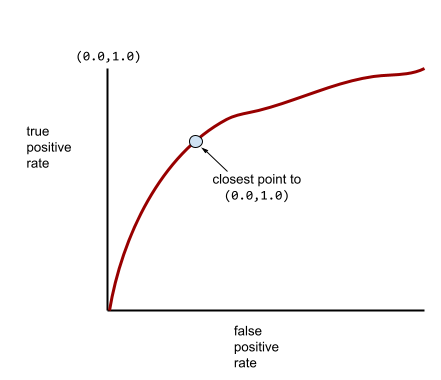
Calcular a área abaixo dessa curva manualmente seria trabalhoso. Por isso, um programa geralmente calcula a maioria dos valores de AUC.
Consulte Classificação: ROC e AUC no Curso intensivo de machine learning para mais informações.
realidade aumentada
Uma tecnologia que sobrepõe uma imagem gerada por computador à visão do usuário do mundo real, fornecendo assim uma visão composta.
codificador automático
Um sistema que aprende a extrair as informações mais importantes da entrada. Os codificadores automáticos são uma combinação de um codificador e um decodificador. Os codificadores automáticos dependem do seguinte processo de duas etapas:
- O codificador mapeia a entrada para um formato (intermediário) de baixa dimensão (normalmente) com perda.
- O decodificador cria uma versão com perda da entrada original mapeando o formato de dimensão inferior para o formato de entrada original de dimensão superior.
Os codificadores automáticos são treinados de ponta a ponta fazendo com que o decodificador tente reconstruir a entrada original do formato intermediário do codificador da maneira mais fiel possível. Como o formato intermediário é menor (de dimensão inferior) do que o original, o codificador automático é forçado a aprender quais informações na entrada são essenciais, e a saída não será perfeitamente idêntica à entrada.
Exemplo:
- Se os dados de entrada forem um gráfico, a cópia não exata será semelhante ao gráfico original, mas um pouco modificada. Talvez a cópia não exata remova ruídos do gráfico original ou preencha alguns pixels ausentes.
- Se os dados de entrada forem texto, um codificador automático vai gerar um novo texto que imita (mas não é idêntico) o texto original.
Consulte também autocodificadores variacionais.
avaliação automática
Usar software para julgar a qualidade da saída de um modelo.
Quando a saída do modelo é relativamente simples, um script ou programa pode comparar a saída do modelo com uma resposta ideal. Esse tipo de avaliação automática às vezes é chamado de avaliação programática. Métricas como ROUGE ou BLEU costumam ser úteis para avaliação programática.
Quando a saída do modelo é complexa ou não tem uma resposta certa, um programa de ML separado chamado autorrater às vezes realiza a avaliação automática.
Contraste com a avaliação humana.
viés de automação
Quando um responsável pela tomada de decisões humanas favorece as recomendações feitas por um sistema automatizado de tomada de decisões em vez de informações feitas sem automação, mesmo quando o sistema automatizado de tomada de decisões comete erros.
Consulte Imparcialidade: tipos de viés no Curso intensivo de machine learning para mais informações.
AutoML
Qualquer processo automatizado para criar modelos de machine learning . O AutoML pode realizar tarefas automaticamente, como:
- Pesquise o modelo mais adequado.
- Ajuste os hiperparâmetros.
- Prepare os dados (incluindo a realização da engenharia de atributos).
- Implante o modelo resultante.
O AutoML é útil para cientistas de dados porque economiza tempo e esforço no desenvolvimento de pipelines de machine learning e melhora a precisão da previsão. Também é útil para pessoas sem experiência, tornando tarefas complicadas de machine learning mais acessíveis.
Consulte Machine learning automatizado (AutoML) no Curso intensivo de machine learning para mais informações.
avaliação do avaliador automático
Um mecanismo híbrido para julgar a qualidade da saída de um modelo de IA generativa que combina avaliação humana com avaliação automática. Um autoavaliador é um modelo de ML treinado com dados criados por avaliação humana. O ideal é que um avaliador automático aprenda a imitar um avaliador humano.Há avaliadores automáticos pré-criados, mas os melhores são ajustados especificamente para a tarefa que você está avaliando.
modelo autorregressivo
Um modelo que infere uma previsão com base nas próprias previsões anteriores. Por exemplo, os modelos de linguagem autorregressivos preveem o próximo token com base nos tokens previstos anteriormente. Todos os modelos de linguagem grande baseados em Transformer são autorregressivos.
Em contraste, os modelos de imagem baseados em GAN geralmente não são autorregressivos, já que geram uma imagem em uma única passagem direta e não de forma iterativa em etapas. No entanto, alguns modelos de geração de imagens são autorregressivos porque geram uma imagem em etapas.
perda auxiliar
Uma função de perda, usada em conjunto com uma rede neural, função de perda principal do modelo, que ajuda a acelerar o treinamento durante as primeiras iterações, quando os pesos são inicializados aleatoriamente.
As funções de perda auxiliares enviam gradientes eficazes para as camadas anteriores. Isso facilita a convergência durante o treinamento, combatendo o problema de desaparecimento de gradiente.
Precisão média em k
Uma métrica para resumir a performance de um modelo em um único comando que gera resultados classificados, como uma lista numerada de recomendações de livros. A precisão média em k é, bem, a média dos valores de precisão em k para cada resultado relevante. Portanto, a fórmula para a precisão média em k é:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
em que:
- \(n\) é o número de itens relevantes na lista.
Contraste com o recall em k.
condição alinhada ao eixo
Em uma árvore de decisão, uma condição que envolve apenas um único recurso. Por exemplo, se area for um recurso, a condição a seguir será alinhada ao eixo:
area > 200
Contraste com a condição oblíqua.
B
retropropagação
O algoritmo que implementa o gradiente descendente em redes neurais.
O treinamento de uma rede neural envolve muitas iterações do seguinte ciclo de duas passagens:
- Durante a transmissão direta, o sistema processa um lote de exemplos para gerar previsões. O sistema compara cada previsão com cada valor de rótulo. A diferença entre a previsão e o valor do rótulo é a perda desse exemplo. O sistema agrega as perdas de todos os exemplos para calcular a perda total do lote atual.
- Durante a passagem para trás (backpropagation), o sistema reduz a perda ajustando os pesos de todos os neurônios em todas as camadas ocultas.
As redes neurais geralmente contêm muitos neurônios em várias camadas ocultas. Cada um desses neurônios contribui para a perda geral de maneiras diferentes. A retropropagação determina se é necessário aumentar ou diminuir os pesos aplicados a neurônios específicos.
A taxa de aprendizado é um multiplicador que controla o grau em que cada transmissão para trás aumenta ou diminui cada peso. Uma taxa de aprendizado grande aumenta ou diminui cada peso mais do que uma taxa pequena.
Em termos de cálculo, a retropropagação implementa a regra da cadeia do cálculo. Ou seja, a retropropagação calcula a derivada parcial do erro em relação a cada parâmetro.
Há anos, os profissionais de ML precisavam escrever código para implementar a retropropagação. As APIs de ML modernas, como o Keras, implementam a retropropagação para você. Ufa.
Consulte Redes neurais no Curso intensivo de machine learning para mais informações.
ensacamento
Um método para treinar um conjunto em que cada modelo constituinte é treinado em um subconjunto aleatório de exemplos de treinamento amostrados com substituição. Por exemplo, uma floresta aleatória é um conjunto de árvores de decisão treinadas com bagging.
O termo bagging é uma abreviação de bootstrap aggregating.
Consulte Florestas aleatórias no curso "Florestas de decisão" para mais informações.
Saco de palavras
Uma representação das palavras em uma frase ou passagem, independente da ordem. Por exemplo, o modelo de bolsa de palavras representa as três frases a seguir de forma idêntica:
- o cachorro pula
- pula o cachorro
- o cachorro pula o
Cada palavra é mapeada para um índice em um vetor esparso, em que o vetor tem um índice para cada palavra no vocabulário. Por exemplo, a frase o cachorro pula é mapeada em um vetor de recursos com valores diferentes de zero nos três índices correspondentes às palavras o, cachorro e pula. O valor diferente de zero pode ser qualquer um dos seguintes:
- Um "1" para indicar a presença de uma palavra.
- Uma contagem do número de vezes que uma palavra aparece na bolsa. Por exemplo, se a frase fosse o cachorro marrom é um cachorro com pelo marrom, marrom e cachorro seriam representados como 2, enquanto as outras palavras seriam representadas como 1.
- Algum outro valor, como o logaritmo da contagem do número de vezes que uma palavra aparece na bolsa.
baseline
Um modelo usado como ponto de referência para comparar o desempenho de outro modelo (normalmente, um mais complexo). Por exemplo, um modelo de regressão logística pode servir como uma boa base para um modelo de aprendizado profundo.
Para um problema específico, a referência ajuda os desenvolvedores de modelos a quantificar o desempenho mínimo esperado que um novo modelo precisa alcançar para ser útil.
modelo de base
Um modelo pré-treinado que pode servir como ponto de partida para ajustes para lidar com tarefas ou aplicativos específicos.
Consulte também modelo pré-treinado e modelo de fundação.
lote
O conjunto de exemplos usados em uma iteração de treinamento. O tamanho do lote determina o número de exemplos em um lote.
Consulte época para uma explicação de como um lote se relaciona a uma época.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
inferência em lote
O processo de inferir previsões em vários exemplos sem rótulo divididos em subconjuntos menores ("lotes").
A inferência em lote pode aproveitar os recursos de paralelização dos chips aceleradores. Ou seja, vários aceleradores podem inferir previsões simultaneamente em diferentes lotes de exemplos sem rótulo, aumentando muito o número de inferências por segundo.
Consulte Sistemas de ML de produção: inferência estática x dinâmica no Curso intensivo de machine learning para mais informações.
normalização em lote
Normalizar a entrada ou saída das funções de ativação em uma camada oculta. A normalização em lote pode oferecer os seguintes benefícios:
- Tornar as redes neurais mais estáveis protegendo contra pesos outlier.
- Ative taxas de aprendizado mais altas, o que pode acelerar o treinamento.
- Reduza o overfitting.
tamanho do lote
O número de exemplos em um lote. Por exemplo, se o tamanho do lote for 100, o modelo vai processar 100 exemplos por iteração.
Confira a seguir algumas estratégias de tamanho de lote conhecidas:
- Gradiente descendente estocástico (GDE), em que o tamanho do lote é 1.
- Lote completo, em que o tamanho do lote é o número de exemplos em todo o conjunto de treinamento. Por exemplo, se o conjunto de treinamento tiver um milhão de exemplos, o tamanho do lote será um milhão de exemplos. O lote completo geralmente é uma estratégia ineficiente.
- minilote, em que o tamanho do lote geralmente fica entre 10 e 1.000. O mini-batch geralmente é a estratégia mais eficiente.
Para saber mais, consulte os seguintes artigos:
- Sistemas de ML de produção: inferência estática x dinâmica no Curso intensivo de machine learning.
- Manual de ajuste do aprendizado profundo.
Rede neural bayesiana
Uma rede neural probabilística que considera a incerteza nos pesos e nas saídas. Um modelo de regressão de rede neural padrão geralmente prevê um valor escalar. Por exemplo, um modelo padrão prevê o preço de uma casa de 853.000. Em contraste, uma rede neural bayesiana prevê uma distribuição de valores. Por exemplo, um modelo bayesiano prevê um preço de imóvel de US$ 853.000 com um desvio padrão de US$ 67.200.
Uma rede neural bayesiana usa o teorema de Bayes para calcular incertezas em pesos e previsões. Uma rede neural bayesiana pode ser útil quando é importante quantificar a incerteza, como em modelos relacionados a produtos farmacêuticos. As redes neurais bayesianas também podem ajudar a evitar o overfitting.
Otimização bayesiana
Uma técnica de modelo de regressão probabilística para otimizar funções objetivas computacionalmente caras. Em vez disso, ela otimiza um substituto que quantifica a incerteza usando uma técnica de aprendizado bayesiano. Como a otimização bayesiana é muito cara, ela geralmente é usada para otimizar tarefas caras de avaliar que têm um pequeno número de parâmetros, como a seleção de hiperparâmetros.
Equação de Bellman
No aprendizado por reforço, a seguinte identidade é satisfeita pela função Q ideal:
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
Os algoritmos de aprendizagem por reforço aplicam essa identidade para criar aprendizagem Q usando a seguinte regra de atualização:
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
Além da aprendizagem por reforço, a equação de Bellman tem aplicações na programação dinâmica. Consulte a entrada da Wikipédia para a equação de Bellman.
BERT (Bidirectional Encoder Representations from Transformers)
Uma arquitetura de modelo para representação de texto. Um modelo BERT treinado pode atuar como parte de um modelo maior para classificação de texto ou outras tarefas de ML.
O BERT tem as seguintes características:
- Usa a arquitetura Transformer e, portanto, depende da autoatenção.
- Usa a parte codificadora do Transformer. O trabalho do codificador é produzir boas representações de texto, em vez de realizar uma tarefa específica, como classificação.
- É bidirecional.
- Usa mascaramento para treinamento não supervisionado.
As variantes do BERT incluem:
Consulte Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing para uma visão geral do BERT.
viés (ética/justiça)
1. Estereótipos, preconceito ou favoritismo em relação a algumas coisas, pessoas ou grupos. Esses vieses podem afetar a coleta e a interpretação de dados, o design de um sistema e a forma como os usuários interagem com ele. Algumas formas desse tipo de viés incluem:
- Viés de automação
- viés de confirmação
- Viés do experimentador
- viés de atribuição a grupos
- viés implícito
- viés de grupo
- viés de homogeneidade externa ao grupo
2. Erro sistemático introduzido por um procedimento de amostragem ou relatório. Algumas formas desse tipo de viés incluem:
- viés de cobertura
- viés de não resposta
- viés de participação
- viés de relatório
- vício de amostragem
- viés de seleção
Não confundir com o termo de viés em modelos de machine learning ou o viés de previsão.
Consulte Imparcialidade: tipos de viés no Curso intensivo de machine learning para mais informações.
viés (matemática) ou termo de viés
Uma interceptação ou um deslocamento de uma origem. O viés é um parâmetro nos modelos de machine learning, simbolizado por um dos seguintes elementos:
- b
- w0
Por exemplo, o viés é o b na seguinte fórmula:
Em uma linha bidimensional simples, a polarização significa apenas "intercepto y". Por exemplo, o viés da linha na ilustração a seguir é 2.
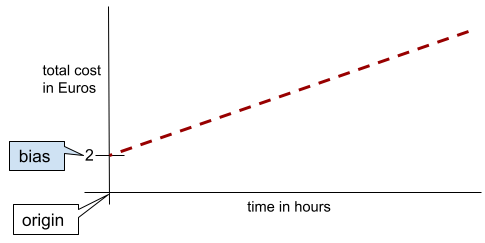
O viés existe porque nem todos os modelos começam na origem (0,0). Por exemplo, suponha que um parque de diversões custe 2 euros para entrar e mais 0,5 euro por hora de permanência de um cliente. Portanto, um modelo que mapeia o custo total tem um viés de 2, porque o menor custo é de 2 euros.
Não confunda viés com viés em ética e justiça ou viés de previsão.
Consulte Regressão linear no Curso intensivo de machine learning para mais informações.
bidirecional
Um termo usado para descrever um sistema que avalia o texto que precede e segue uma seção de texto de destino. Por outro lado, um sistema unidirecional avalia apenas o texto que precede uma seção de texto de destino.
Por exemplo, considere um modelo de linguagem mascarado que precisa determinar as probabilidades da palavra ou palavras que representam o sublinhado na seguinte pergunta:
Qual é o _____ com você?
Um modelo de linguagem unidirecional teria que basear suas probabilidades apenas no contexto fornecido pelas palavras "What", "is" e "the". Em contraste, um modelo de linguagem bidirecional também pode ganhar contexto com "com" e "você", o que pode ajudar o modelo a gerar previsões melhores.
modelo de linguagem bidirecional
Um modelo de linguagem que determina a probabilidade de um determinado token estar presente em um determinado local em um trecho de texto com base no texto anterior e posterior.
bigrama
Um bigrama.
classificação binária
Um tipo de tarefa de classificação que prevê uma de duas classes mutuamente exclusivas:
Por exemplo, os dois modelos de aprendizado de máquina a seguir realizam classificação binária:
- Um modelo que determina se as mensagens de e-mail são spam (a classe positiva) ou não spam (a classe negativa).
- Um modelo que avalia sintomas médicos para determinar se uma pessoa tem uma doença específica (a classe positiva) ou não (a classe negativa).
Contraste com a classificação multiclasse.
Consulte também regressão logística e limiar de classificação.
Consulte Classificação no Curso intensivo de machine learning para mais informações.
condição binária
Em uma árvore de decisão, uma condição que tem apenas dois resultados possíveis, geralmente sim ou não. Por exemplo, esta é uma condição binária:
temperature >= 100
Contraste com a condição não binária.
Consulte Tipos de condições no curso "Florestas de decisão" para mais informações.
agrupamento por classes
Sinônimo de agrupamento em intervalos.
modelo de caixa preta
Um modelo cujo "raciocínio" é impossível ou difícil de entender para os humanos. Ou seja, embora as pessoas possam ver como os comandos afetam as respostas, não é possível determinar exatamente como um modelo de caixa preta determina a resposta. Em outras palavras, um modelo de caixa preta não tem interpretabilidade.
A maioria dos modelos de aprendizado profundo e modelos de linguagem grandes são caixas pretas.
BLEU (Bilingual Evaluation Understudy)
Uma métrica entre 0,0 e 1,0 para avaliar traduções automáticas, por exemplo, de espanhol para japonês.
Para calcular uma pontuação, o BLEU geralmente compara a tradução de um modelo de ML (texto gerado) com a tradução de um especialista humano (texto de referência). O grau de correspondência entre os n-gramas no texto gerado e no texto de referência determina a pontuação BLEU.
O artigo original sobre essa métrica é BLEU: a Method for Automatic Evaluation of Machine Translation (em inglês).
Consulte também BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
Uma métrica para avaliar traduções automáticas de um idioma para outro, principalmente para e do inglês.
Para traduções de e para inglês, o BLEURT se alinha mais às classificações humanas do que o BLEU. Ao contrário do BLEU, o BLEURT enfatiza as similaridades semânticas (significado) e pode acomodar paráfrases.
O BLEURT usa um modelo de linguagem grande pré-treinado (o BERT, para ser exato) que é ajustado em textos de tradutores humanos.
O artigo original sobre essa métrica é BLEURT: Learning Robust Metrics for Text Generation (em inglês).
Perguntas booleanas (BoolQ)
Um conjunto de dados para avaliar a capacidade de um LLM de responder a perguntas de sim ou não. Cada um dos desafios no conjunto de dados tem três componentes:
- Uma consulta
- Uma passagem que implica a resposta à consulta.
- A resposta correta, que é sim ou não.
Exemplo:
- Consulta: há usinas nucleares em Michigan?
- Trecho: ...três usinas nucleares fornecem a Michigan cerca de 30% da eletricidade.
- Resposta correta: sim
Os pesquisadores coletaram as perguntas de consultas anônimas e agregadas da Pesquisa Google e usaram páginas da Wikipédia para fundamentar as informações.
Para mais informações, consulte BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions.
O BoolQ é um componente do conjunto SuperGLUE.
BoolQ
Abreviação de Perguntas booleanas.
incentivo
Uma técnica de machine learning que combina de forma iterativa um conjunto de modelos de classificação simples e não muito precisos (chamados de "classificadores fracos") em um modelo de classificação com alta precisão (um "classificador forte") ao aumentar a ponderação dos exemplos que o modelo está classificando incorretamente.
Consulte Árvores de decisão com aumento de gradiente? no curso "Florestas de decisão" para mais informações.
caixa delimitadora
Em uma imagem, as coordenadas (x, y) de um retângulo ao redor de uma área de interesse, como o cachorro na imagem abaixo.

transmissão
Expandir a forma de um operando em uma operação matemática de matriz para dimensões compatíveis com essa operação. Por exemplo, a álgebra linear exige que os dois operandos em uma operação de adição de matrizes tenham as mesmas dimensões. Consequentemente, não é possível adicionar uma matriz de forma (m, n) a um vetor de comprimento n. A transmissão permite essa operação expandindo virtualmente o vetor de comprimento n para uma matriz de forma (m, n) replicando os mesmos valores em cada coluna.
Consulte a descrição a seguir de transmissão em NumPy para mais detalhes.
agrupamento por classes
Converter um único atributo em vários atributos binários chamados de buckets ou classes, normalmente com base em um intervalo de valores. O atributo cortado geralmente é um atributo contínuo.
Por exemplo, em vez de representar a temperatura como um único atributo de ponto flutuante contínuo, você pode dividir intervalos de temperatura em intervalos discretos, como:
- <= 10 graus Celsius seria o grupo "frio".
- 11 a 24 graus Celsius seria o intervalo "temperado".
- >= 25 graus Celsius seria o grupo "quente".
O modelo vai tratar todos os valores no mesmo bucket de forma idêntica. Por exemplo, os valores 13 e 22 estão no bucket "temperado", então o modelo trata os dois valores de forma idêntica.
Consulte Dados numéricos: discretização no Curso intensivo de machine learning para mais informações.
C
camada de calibragem
Um ajuste pós-previsão, geralmente para explicar o vício de previsão. As previsões e probabilidades ajustadas precisam corresponder à distribuição de um conjunto de rótulos observados.
geração de candidatos
O conjunto inicial de recomendações escolhido por um sistema de recomendação. Por exemplo, considere uma livraria que oferece 100.000 títulos. A fase de geração de candidatos cria uma lista muito menor de livros adequados para um determinado usuário, digamos, 500. Mas mesmo 500 livros são muitos para recomendar a um usuário. As fases subsequentes e mais caras de um sistema de recomendação (como pontuação e reclassificação) reduzem esses 500 para um conjunto muito menor e mais útil de recomendações.
Consulte a Visão geral da geração de candidatos no curso de sistemas de recomendação para mais informações.
amostragem de candidatos
Uma otimização no momento do treinamento que calcula uma probabilidade para todos os rótulos positivos, usando, por exemplo, softmax, mas apenas para uma amostra aleatória de rótulos negativos. Por exemplo, considerando um exemplo rotulado como beagle e dog, a amostragem de candidatos calcula as probabilidades previstas e os termos de perda correspondentes para:
- beagle
- cachorro
- um subconjunto aleatório das classes negativas restantes (por exemplo, gato, pirulito, cerca).
A ideia é que as classes negativas aprendam com o reforço negativo menos frequente, desde que as classes positivas sempre recebam o reforço positivo adequado, e isso é observado empiricamente.
A amostragem candidata é mais eficiente em termos computacionais do que os algoritmos de treinamento que calculam previsões para todas as classes negativas, principalmente quando o número de classes negativas é muito grande.
dados categóricos
Atributos com um conjunto específico de valores possíveis. Por exemplo, considere um recurso categórico chamado traffic-light-state, que só pode ter um dos três valores possíveis a seguir:
redyellowgreen
Ao representar traffic-light-state como um atributo categórico, um modelo pode aprender os diferentes impactos de red, green e yellow no comportamento do motorista.
Às vezes, os recursos categóricos são chamados de recursos discretos.
Contraste com dados numéricos.
Consulte Como trabalhar com dados categóricos no Curso intensivo de machine learning para mais informações.
modelo de linguagem causal
Sinônimo de modelo de linguagem unidirecional.
Consulte modelo de linguagem bidirecional para comparar diferentes abordagens direcionais na modelagem de linguagem.
CB
Abreviação de CommitmentBank.
centroid
O centro de um cluster, determinado por um algoritmo k-means ou k-median. Por exemplo, se k for 3, o algoritmo k-means ou k-median vai encontrar três centróides.
Consulte Algoritmos de clustering no curso de clustering para mais informações.
clustering baseado em centroide
Uma categoria de algoritmos de agrupamento que organiza dados em clusters não hierárquicos. O k-means é o algoritmo de agrupamento baseado em centroide mais usado.
Contraste com algoritmos de clustering hierárquico.
Consulte Algoritmos de clustering no curso de clustering para mais informações.
Comandos com linha de raciocínio
Uma técnica de engenharia de comando que incentiva um modelo de linguagem grande (LLM) a explicar o raciocínio dele, etapa por etapa. Por exemplo, considere o seguinte comando, prestando atenção especial à segunda frase:
Quantas forças G um motorista sentiria em um carro que vai de 0 a 100 km/h em 7 segundos? Na resposta, mostre todos os cálculos relevantes.
A resposta do LLM provavelmente:
- Mostre uma sequência de fórmulas de física, inserindo os valores 0, 60 e 7 nos lugares apropriados.
- Explique por que ele escolheu essas fórmulas e o que significam as várias variáveis.
O comando de fluxo de consciência força o LLM a realizar todos os cálculos, o que pode levar a uma resposta mais correta. Além disso, o comando de cadeia de pensamento permite que o usuário examine as etapas do LLM para determinar se a resposta faz sentido.
Pontuação F de n-gramas de caracteres (ChrF)
Uma métrica para avaliar modelos de tradução automática. A pontuação F de n-gramas de caracteres determina o grau em que os n-gramas no texto de referência se sobrepõem aos n-gramas no texto gerado de um modelo de ML.
A pontuação F de n-gramas de caracteres é semelhante às métricas das famílias ROUGE e BLEU, exceto que:
- A pontuação F de N-gramas de caracteres opera em N-gramas de caracteres.
- ROUGE e BLEU operam em N-gramas de palavras ou tokens.
chat
O conteúdo de um diálogo entre duas pessoas com um sistema de ML, geralmente um modelo de linguagem grande. A interação anterior em uma conversa (o que você digitou e como o modelo de linguagem grande respondeu) se torna o contexto para as partes subsequentes da conversa.
Um chatbot é um aplicativo de um modelo de linguagem grande.
checkpoint
Dados que capturam o estado dos parâmetros de um modelo durante ou após o treinamento. Por exemplo, durante o treinamento, você pode:
- Interromper o treinamento, talvez intencionalmente ou como resultado de determinados erros.
- Capture o checkpoint.
- Depois, recarregue o ponto de verificação, possivelmente em um hardware diferente.
- Reinicie o treinamento.
Escolha de alternativas plausíveis (COPA, na sigla em inglês)
Um conjunto de dados para avaliar a capacidade de um LLM de identificar a melhor entre duas respostas alternativas para uma premissa. Cada um dos desafios no conjunto de dados consiste em três componentes:
- Uma premissa, que normalmente é uma declaração seguida de uma pergunta
- Duas respostas possíveis para a pergunta feita na premissa, uma correta e outra incorreta
- A resposta correta
Exemplo:
- Premissa:o homem quebrou o dedo do pé. Qual foi a CAUSA disso?
- Possíveis respostas:
- Ele fez um buraco na meia.
- Ele deixou cair um martelo no pé.
- Resposta correta:2
O COPA é um componente do conjunto SuperGLUE.
classe
Uma categoria a que um rótulo pode pertencer. Exemplo:
- Em um modelo de classificação binária que detecta spam, as duas classes podem ser spam e não spam.
- Em um modelo de classificação multiclasse que identifica raças de cachorros, as classes podem ser poodle, beagle, pug, e assim por diante.
Um modelo de classificação prevê uma classe. Já um modelo de regressão prevê um número, não uma classe.
Consulte Classificação no Curso intensivo de machine learning para mais informações.
conjunto de dados balanceado
Um conjunto de dados que contém rótulos categóricos em que o número de instâncias de cada categoria é aproximadamente igual. Por exemplo, considere um conjunto de dados botânicos cujo rótulo binário pode ser planta nativa ou planta não nativa:
- Um conjunto de dados com 515 plantas nativas e 485 plantas não nativas é um conjunto de dados com classes balanceadas.
- Um conjunto de dados com 875 plantas nativas e 125 plantas não nativas é um conjunto de dados com desequilíbrio de classes.
Não há uma linha divisória formal entre conjuntos de dados balanceados e desbalanceados. A distinção só se torna importante quando um modelo treinado em um conjunto de dados altamente desequilibrado não consegue convergir. Consulte Conjuntos de dados: conjuntos de dados desequilibrados no Curso intensivo de machine learning para mais detalhes.
modelo de classificação
Um modelo cuja previsão é uma classe. Por exemplo, todos os modelos a seguir são de classificação:
- Um modelo que prevê o idioma de uma frase de entrada (francês? Espanhol? Italiano?).
- Um modelo que prevê espécies de árvores (bordo? Carvalho? Baobá?).
- Um modelo que prevê a classe positiva ou negativa para uma condição médica específica.
Já os modelos de regressão preveem números, não classes.
Dois tipos comuns de modelos de classificação são:
limiar de classificação
Em uma classificação binária, um número entre 0 e 1 que converte a saída bruta de um modelo de regressão logística em uma previsão da classe positiva ou da classe negativa. O limite de classificação é um valor escolhido por um humano, não pelo treinamento do modelo.
Um modelo de regressão logística gera um valor bruto entre 0 e 1. Em seguida:
- Se esse valor bruto for maior que o limite de classificação, a classe positiva será prevista.
- Se esse valor bruto for menor que o limiar de classificação, a classe negativa será prevista.
Por exemplo, suponha que o limite de classificação seja 0,8. Se o valor bruto for 0,9, o modelo vai prever a classe positiva. Se o valor bruto for 0,7, o modelo vai prever a classe negativa.
A escolha do limite de classificação influencia muito o número de falsos positivos e falsos negativos.
Consulte Limiares e a matriz de confusão no Curso intensivo de machine learning para mais informações.
classificador
Um termo informal para um modelo de classificação.
conjunto de dados não balanceado
Um conjunto de dados para uma classificação em que o número total de rótulos de cada classe é significativamente diferente. Por exemplo, considere um conjunto de dados de classificação binária cujos dois rótulos são divididos da seguinte maneira:
- 1.000.000 de rótulos negativos
- 10 marcadores positivos
A proporção de rótulos negativos para positivos é de 100.000 para 1. Portanto, esse é um conjunto de dados com desequilíbrio de classes.
Em contraste, o conjunto de dados a seguir é equilibrado por classe porque a proporção de rótulos negativos para positivos é relativamente próxima de 1:
- 517 rótulos negativos
- 483 rótulos positivos
Os conjuntos de dados de várias classes também podem ser desbalanceados. Por exemplo, o seguinte conjunto de dados de classificação multiclasse também é desbalanceado porque um rótulo tem muito mais exemplos do que os outros dois:
- 1.000.000 de rótulos com a classe "verde"
- 200 rótulos com a classe "roxo"
- 350 rótulos com a classe "orange"
O treinamento de conjuntos de dados não balanceados pode apresentar desafios especiais. Consulte Conjuntos de dados desequilibrados no Curso intensivo de machine learning para mais detalhes.
Consulte também entropia, classe majoritária e classe minoritária.
corte
Uma técnica para processar outliers fazendo uma ou ambas as ações a seguir:
- Reduzir os valores de recursos que são maiores que um limite máximo até esse limite.
- Aumentar os valores de recursos que estão abaixo de um limite mínimo até esse limite.
Por exemplo, suponha que menos de 0,5% dos valores de um determinado atributo estejam fora do intervalo de 40 a 60. Nesse caso, faça o seguinte:
- Corte todos os valores acima de 60 (o limite máximo) para que sejam exatamente 60.
- Corte todos os valores abaixo de 40 (o limite mínimo) para que sejam exatamente 40.
Os outliers podem danificar os modelos, às vezes causando um estouro de pesos durante o treinamento. Alguns outliers também podem prejudicar muito métricas como acurácia. O corte é uma técnica comum para limitar o dano.
O ajuste de gradiente força os valores de gradiente dentro de um intervalo designado durante o treinamento.
Consulte Dados numéricos: normalização no Curso intensivo de machine learning para mais informações.
Cloud TPU
Um acelerador de hardware especializado projetado para acelerar cargas de trabalho de machine learning no Google Cloud.
clustering
Agrupar exemplos relacionados, principalmente durante o aprendizado não supervisionado. Depois que todos os exemplos são agrupados, um humano pode fornecer um significado a cada cluster.
Existem muitos algoritmos de clustering. Por exemplo, o algoritmo k-means agrupa exemplos com base na proximidade a um centroide, como no diagrama a seguir:

Um pesquisador humano pode analisar os clusters e, por exemplo, rotular o cluster 1 como "árvores anãs" e o cluster 2 como "árvores de tamanho normal".
Como outro exemplo, considere um algoritmo de clusterização com base na distância de um exemplo de um ponto central, ilustrado da seguinte maneira:

Consulte o curso sobre clustering para mais informações.
coadaptação
Um comportamento indesejável em que neurônios preveem padrões em dados de treinamento confiando quase exclusivamente nas saídas de outros neurônios específicos, em vez de confiar no comportamento da rede como um todo. Quando os padrões que causam a coadaptação não estão presentes nos dados de validação, a coadaptação causa overfitting. A regularização de dropout reduz a coadaptação porque o dropout garante que os neurônios não possam depender apenas de outros neurônios específicos.
filtragem colaborativa
Fazer previsões sobre os interesses de um usuário com base nos interesses de muitos outros usuários. A filtragem colaborativa é usada com frequência em sistemas de recomendação.
Consulte Filtragem colaborativa no curso de sistemas de recomendação para mais informações.
CommitmentBank (CB)
Um conjunto de dados para avaliar a proficiência de um LLM em determinar se o autor de uma passagem acredita em uma cláusula de destino dentro dessa passagem. Cada entrada no conjunto de dados contém:
- Um trecho
- Uma cláusula de destino dentro dessa passagem
- Um valor booleano que indica se o autor da passagem acredita que a cláusula de destino
Exemplo:
- Trecho:Que divertido ouvir Artemis rir. Ela é uma criança muito séria. Não sabia que ela tinha senso de humor.
- Cláusula de destino:ela tinha senso de humor
- Booleano: "True", o que significa que o autor acredita que a cláusula de destino
O CommitmentBank é um componente do conjunto SuperGLUE.
modelo compacto
Qualquer modelo pequeno projetado para ser executado em dispositivos pequenos com recursos computacionais limitados. Por exemplo, modelos compactos podem ser executados em smartphones, tablets ou sistemas incorporados.
compute
(Substantivo) Os recursos computacionais usados por um modelo ou sistema, como capacidade de processamento, memória e armazenamento.
Consulte chips aceleradores.
desvio de conceito
Uma mudança na relação entre atributos e o rótulo. Com o tempo, a degradação de conceitos reduz a qualidade de um modelo.
Durante o treinamento, o modelo aprende a relação entre os atributos e os rótulos no conjunto de treinamento. Se os rótulos no conjunto de treinamento forem bons indicadores do mundo real, o modelo deverá fazer boas previsões do mundo real. No entanto, devido ao deslocamento de conceito, as previsões do modelo tendem a piorar com o tempo.
Por exemplo, considere um modelo de classificação binária que prevê se um determinado modelo de carro é "eficiente em termos de consumo de combustível" ou não. Ou seja, os recursos podem ser:
- peso do carro
- compressão do motor
- transmission type
enquanto o rótulo for:
- econômico
- não é eficiente em termos de combustível
No entanto, o conceito de "carro econômico" está sempre mudando. Um modelo de carro rotulado como eficiente em termos de consumo de combustível em 1994 quase certamente seria rotulado como não eficiente em termos de consumo de combustível em 2024. Um modelo que sofre de desvio de conceito tende a fazer previsões cada vez menos úteis ao longo do tempo.
Compare e contraste com não estacionariedade.
condição
Em uma árvore de decisão, qualquer nó que realiza um teste. Por exemplo, a árvore de decisão a seguir contém duas condições:

Uma condição também é chamada de divisão ou teste.
Contraste a condição com o nó.
Consulte também:
Consulte Tipos de condições no curso "Florestas de decisão" para mais informações.
confabulação
Sinônimo de alucinação.
Confabulação é provavelmente um termo mais preciso tecnicamente do que alucinação. No entanto, a alucinação se tornou popular primeiro.
configuração
O processo de atribuição dos valores de propriedade iniciais usados para treinar um modelo, incluindo:
- as camadas de composição do modelo
- o local dos dados
- Hiperparâmetros, como:
Em projetos de machine learning, a configuração pode ser feita usando um arquivo de configuração especial ou bibliotecas de configuração, como:
viés de confirmação
A tendência de procurar, interpretar, favorecer e recordar informações de uma maneira que confirme as crenças ou hipóteses preexistentes. Os desenvolvedores de machine learning podem coletar ou rotular dados sem querer de maneiras que influenciam um resultado que apoia as crenças atuais deles. O viés de confirmação é uma forma de viés implícito.
O viés do experimentador é uma forma de viés de confirmação em que um experimentador continua treinando modelos até que uma hipótese pré-existente seja confirmada.
matriz de confusão
Uma tabela NxN que resume o número de previsões corretas e incorretas feitas por um modelo de classificação. Por exemplo, considere a seguinte matriz de confusão para um modelo de classificação binária:
| Tumor (previsto) | Não tumor (previsto) | |
|---|---|---|
| Tumor (informações empíricas) | 18 (VP) | 1 (FN) |
| Não tumor (informações empíricas) | 6 (FP) | 452 (VN) |
A matriz de confusão acima mostra o seguinte:
- Das 19 previsões em que a informação empírica era "Tumor", o modelo classificou corretamente 18 e incorretamente 1.
- Das 458 previsões em que a verdade fundamental era "Não tumor", o modelo classificou corretamente 452 e incorretamente 6.
A matriz de confusão para um problema de classificação multiclasse pode ajudar a identificar padrões de erros. Por exemplo, considere a seguinte matriz de confusão para um modelo de classificação multiclasse de três classes que categoriza três tipos diferentes de íris (Virginica, Versicolor e Setosa). Quando a verdade fundamental era Virginica, a matriz de confusão mostra que o modelo tinha muito mais probabilidade de prever Versicolor do que Setosa por engano:
| Setosa (prevista) | Versicolor (previsto) | Virginica (prevista) | |
|---|---|---|---|
| Setosa (informações empíricas) | 88 | 12 | 0 |
| Versicolor (informações empíricas) | 6 | 141 | 7 |
| Virginica (informações empíricas) | 2 | 27 | 109 |
Como outro exemplo, uma matriz de confusão pode revelar que um modelo treinado para reconhecer dígitos manuscritos tende a prever erroneamente 9 em vez de 4 ou 1 em vez de 7.
As matrizes de confusão contêm informações suficientes para calcular várias métricas de performance, incluindo precisão e recall.
análise de constituintes
Dividir uma frase em estruturas gramaticais menores ("constituintes"). Uma parte posterior do sistema de ML, como um modelo de processamento de linguagem natural, pode analisar os constituintes com mais facilidade do que a frase original. Por exemplo, considere a seguinte frase:
Meu amigo adotou dois gatos.
Um analisador de constituintes pode dividir essa frase nos dois constituintes a seguir:
- Meu amigo é um sintagma nominal.
- adotou dois gatos é uma frase verbal.
Esses constituintes podem ser subdivididos em constituintes menores. Por exemplo, a frase verbal
adotou dois gatos
pode ser subdividido em:
- adotado é um verbo.
- dois gatos é outro sintagma nominal.
embedding de linguagem contextualizada
Uma embedding que se aproxima da "compreensão" de palavras e frases da mesma forma que falantes humanos fluentes. Os encodings de linguagem contextualizada podem entender sintaxe, semântica e contexto complexos.
Por exemplo, considere embeddings da palavra em inglês cow. Incorporações mais antigas, como o word2vec, podem representar palavras em inglês de modo que a distância no espaço de incorporação de cow (vaca) para bull (touro) seja semelhante à distância de ewe (ovelha fêmea) para ram (carneiro) ou de female (feminino) para male (masculino). As incorporações de linguagem contextualizada podem ir além, reconhecendo que os falantes de inglês às vezes usam casualmente a palavra cow para se referir a vaca ou touro.
janela de contexto
O número de tokens que um modelo pode processar em um determinado comando. Quanto maior a janela de contexto, mais informações o modelo pode usar para fornecer respostas coerentes e consistentes ao comando.
atributo contínuo
Um recurso de ponto flutuante com um intervalo infinito de valores possíveis, como temperatura ou peso.
Contraste com o atributo discreto.
amostragem por conveniência
Usar um conjunto de dados não coletado cientificamente para executar experimentos rápidos. Depois, é essencial mudar para um conjunto de dados coletado cientificamente.
convergência
Um estado alcançado quando os valores de perda mudam muito pouco ou nada a cada iteração. Por exemplo, a curva de perda a seguir sugere convergência em torno de 700 iterações:
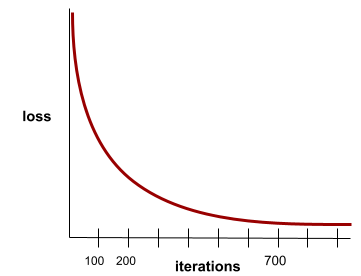
Um modelo converge quando um treinamento adicional não melhora o modelo.
No aprendizado profundo, os valores de perda às vezes permanecem constantes ou quase assim por muitas iterações antes de finalmente diminuírem. Durante um longo período de valores de perda constantes, você pode ter temporariamente uma falsa sensação de convergência.
Consulte também parada antecipada.
Consulte Convergência do modelo e curvas de perda no Curso intensivo de machine learning para mais informações.
programação conversacional
Um diálogo iterativo entre você e um modelo de IA generativa com o objetivo de criar software. Você emite um comando descrevendo um software. Em seguida, o modelo usa essa descrição para gerar código. Em seguida, você envia um novo comando para corrigir as falhas no comando anterior ou no código gerado, e o modelo gera um código atualizado. Vocês dois vão e voltam até que o software gerado seja bom o suficiente.
A programação de conversas é essencialmente o significado original de vibe coding.
Contraste com a programação especificacional.
função convexa
Uma função em que a região acima do gráfico é um conjunto convexo. A função convexa prototípica tem um formato semelhante à letra U. Por exemplo, as seguintes são todas funções convexas:
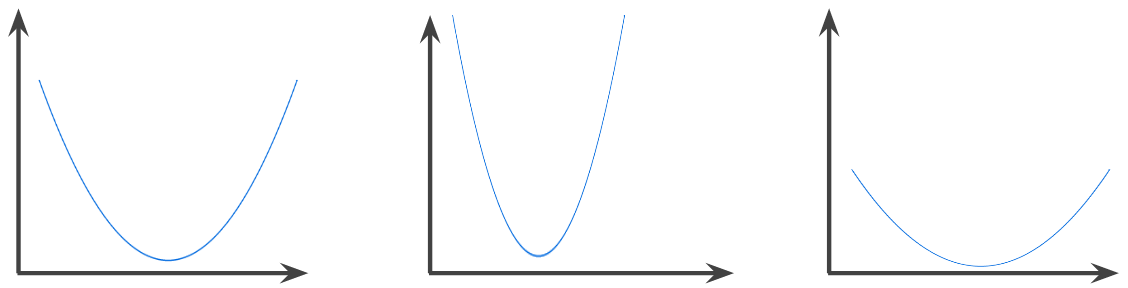
Por outro lado, a função a seguir não é convexa. Observe como a região acima do gráfico não é um conjunto convexo:

Uma função estritamente convexa tem exatamente um ponto de mínimo local, que também é o ponto de mínimo global. As funções clássicas em forma de U são estritamente convexas. No entanto, algumas funções convexas (por exemplo, linhas retas) não têm formato de U.
Consulte Convergência e funções convexas no Curso intensivo de machine learning para mais informações.
otimização convexa
O processo de usar técnicas matemáticas, como gradiente descendente, para encontrar o mínimo de uma função convexa. Grande parte da pesquisa em machine learning se concentrou em formular vários problemas como problemas de otimização convexa e em resolver esses problemas de maneira mais eficiente.
Para mais detalhes, consulte Boyd e Vandenberghe, Convex Optimization.
conjunto convexo
Um subconjunto do espaço euclidiano em que uma linha traçada entre dois pontos quaisquer do subconjunto permanece completamente dentro dele. Por exemplo, as duas formas a seguir são conjuntos convexos:

Em contraste, as duas formas a seguir não são conjuntos convexos:

convolução
Em matemática, falando de maneira informal, uma mistura de duas funções. No aprendizado de máquina, uma convolução mistura o filtro convolucional e a matriz de entrada para treinar pesos.
O termo "convolução" em machine learning é geralmente uma forma abreviada de se referir a uma operação convolucional ou a uma camada convolucional.
Sem convoluções, um algoritmo de aprendizado de máquina precisaria aprender um peso separado para cada célula em um grande tensor. Por exemplo, um algoritmo de aprendizado de máquina treinado em imagens de 2K x 2K seria forçado a encontrar 4 milhões de pesos separados. Graças às convoluções, um algoritmo de machine learning só precisa encontrar pesos para cada célula no filtro convolucional, reduzindo drasticamente a memória necessária para treinar o modelo. Quando o filtro convolucional é aplicado, ele é simplesmente replicado em todas as células, de modo que cada uma seja multiplicada pelo filtro.
filtro convolucional
Um dos dois atores em uma operação convolucional. O outro ator é uma fração de uma matriz de entrada. Um filtro convolucional é uma matriz com a mesma ordem da matriz de entrada, mas um formato menor. Por exemplo, considerando uma matriz de entrada de 28 x 28, o filtro pode ser qualquer matriz 2D menor que 28 x 28.
Na manipulação fotográfica, todas as células de um filtro convolucional são geralmente definidas como um padrão constante de uns e zeros. No aprendizado de máquina, os filtros convolucionais geralmente são inicializados com números aleatórios, e a rede treina os valores ideais.
camada convolucional
Uma camada de uma rede neural profunda em que um filtro convolucional passa por uma matriz de entrada. Por exemplo, considere o seguinte filtro convolucional 3x3:
![Uma matriz 3x3 com os seguintes valores: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=3&hl=pt)
A animação a seguir mostra uma camada convolucional com nove operações convolucionais envolvendo a matriz de entrada 5x5. Cada operação convolucional funciona em uma fatia 3x3 diferente da matriz de entrada. A matriz 3x3 resultante (à direita) consiste nos resultados das nove operações de convolução:
![Uma animação mostrando duas matrizes. A primeira matriz é a 5x5: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
A segunda matriz é a 3x3: [[181,303,618], [115,338,605], [169,351,560]].
A segunda matriz é calculada aplicando o filtro convolucional [[0, 1, 0], [1, 0, 1], [0, 1, 0]] em diferentes subconjuntos 3x3 da matriz 5x5.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=3&hl=pt)
rede neural convolucional
Uma rede neural em que pelo menos uma camada é uma camada convolucional. Uma rede neural convolucional típica consiste em alguma combinação das seguintes camadas:
As redes neurais convolucionais tiveram muito sucesso em alguns tipos de problemas, como reconhecimento de imagens.
operação de convolução
A seguinte operação matemática em duas etapas:
- Multiplicação elemento a elemento do filtro convolucional e uma fração de uma matriz de entrada. A fatia da matriz de entrada tem a mesma classificação e tamanho do filtro convolucional.
- Soma de todos os valores na matriz de produtos resultante.
Por exemplo, considere a seguinte matriz de entrada 5x5:
![A matriz 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=3&hl=pt)
Agora imagine o seguinte filtro convolucional 2x2:
![A matriz 2x2: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=3&hl=pt)
Cada operação convolucional envolve uma única fatia 2x2 da matriz de entrada. Por exemplo, suponha que usemos a fatia 2x2 no canto superior esquerdo da matriz de entrada. Assim, a operação de convolução nessa fatia fica assim:
![Aplicando o filtro convolucional [[1, 0], [0, 1]] à seção 2x2 superior esquerda da matriz de entrada, que é [[128,97], [35,22]].
O filtro convolucional deixa 128 e 22 intactos, mas zera 97 e 35. Consequentemente, a operação de convolução gera o valor 150 (128+22).](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=3&hl=pt)
Uma camada convolucional consiste em uma série de operações convolucionais, cada uma atuando em uma fatia diferente da matriz de entrada.
COPA
Abreviação de Escolha de alternativas plausíveis.
custo
Sinônimo de perda.
cotreinamento
Uma abordagem de aprendizagem semissupervisionada, especialmente útil quando todas as condições a seguir são verdadeiras:
- A proporção de exemplos sem rótulo para exemplos rotulados no conjunto de dados é alta.
- Esse é um problema de classificação (binária ou multiclasse).
- O conjunto de dados contém dois conjuntos diferentes de recursos preditivos que são independentes e complementares.
O treinamento conjunto amplifica indicadores independentes em um indicador mais forte. Por exemplo, considere um modelo de classificação que categoriza carros usados individuais como Bom ou Ruim. Um conjunto de recursos preditivos pode se concentrar em características agregadas, como ano, marca e modelo do carro. Outro conjunto pode se concentrar no histórico de direção do proprietário anterior e no histórico de manutenção do carro.
O artigo seminal sobre cotreinamento é Combining Labeled and Unlabeled Data with Co-Training (em inglês) de Blum e Mitchell.
Imparcialidade contrafactual
Uma métrica de justiça que verifica se um modelo de classificação produz o mesmo resultado para um indivíduo e para outro idêntico ao primeiro, exceto em relação a um ou mais atributos sensíveis. A avaliação de um modelo de classificação para imparcialidade contrafactual é um método para identificar possíveis fontes de viés em um modelo.
Para mais informações, consulte:
- Imparcialidade: imparcialidade contrafactual no curso intensivo de machine learning.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness (em inglês)
viés de cobertura
Consulte viés de seleção.
crash blossom
Uma frase ou expressão com um significado ambíguo. Os crash blossoms representam um problema significativo no entendimento de linguagem natural. Por exemplo, o título Burocracia atrasa arranha-céu é um crash blossom porque um modelo de NLU pode interpretar o título de forma literal ou figurativa.
crítico
Sinônimo de rede Q profunda.
entropia cruzada
Uma generalização da perda de registro para problemas de classificação multiclasse. A entropia cruzada quantifica a diferença entre duas distribuições de probabilidade. Consulte também perplexidade.
validação cruzada
Um mecanismo para estimar a capacidade de generalização de um modelo para novos dados. Para isso, o modelo é testado em um ou mais subconjuntos de dados não sobrepostos retidos do conjunto de treinamento.
função de distribuição cumulativa (CDF)
Uma função que define a frequência de amostras menores ou iguais a um valor de destino. Por exemplo, considere uma distribuição normal de valores contínuos. Uma CDF informa que aproximadamente 50% das amostras devem ser menores ou iguais à média e que aproximadamente 84% das amostras devem ser menores ou iguais a um desvio padrão acima da média.
D
análise de dados
Entender os dados considerando amostras, medições e visualizações. A análise de dados pode ser especialmente útil quando um conjunto de dados é recebido pela primeira vez, antes da criação do primeiro modelo. Também é essencial para entender experimentos e depurar problemas com o sistema.
ampliação de dados
Aumentar artificialmente o intervalo e o número de exemplos de treinamento transformando exemplos atuais para criar mais exemplos. Por exemplo, suponha que as imagens sejam um dos seus atributos, mas seu conjunto de dados não tenha exemplos suficientes para que o modelo aprenda associações úteis. O ideal é adicionar imagens rotuladas suficientes ao conjunto de dados para que o modelo seja treinado corretamente. Se isso não for possível, a ampliação de dados poderá girar, esticar e refletir cada imagem para produzir muitas variantes da foto original, gerando dados rotulados suficientes para permitir um treinamento excelente.
DataFrame
Um tipo de dados pandas popular para representar conjuntos de dados na memória.
Um DataFrame é análogo a uma tabela ou planilha. Cada coluna de um DataFrame tem um nome (um cabeçalho), e cada linha é identificada por um número exclusivo.
Cada coluna em um DataFrame é estruturada como uma matriz 2D, exceto que cada coluna pode receber um tipo de dados próprio.
Consulte também a página de referência oficial do pandas.DataFrame.
paralelismo de dados
Uma maneira de escalonar o treinamento ou a inferência que replica um modelo inteiro em vários dispositivos e transmite um subconjunto dos dados de entrada para cada dispositivo. O paralelismo de dados permite treinamento e inferência em tamanhos de lote muito grandes. No entanto, ele exige que o modelo seja pequeno o suficiente para caber em todos os dispositivos.
O paralelismo de dados geralmente acelera o treinamento e a inferência.
Consulte também paralelismo de modelos.
API Dataset (tf.data)
Uma API TensorFlow de alto nível para ler dados e
transformá-los em um formato exigido por um algoritmo de machine learning.
Um objeto tf.data.Dataset representa uma sequência de elementos, em que
cada elemento contém um ou mais tensores. Um objeto tf.data.Iterator fornece acesso aos elementos de um Dataset.
conjunto de dados
Uma coleção de dados brutos, geralmente (mas não exclusivamente) organizada em um dos seguintes formatos:
- uma planilha
- um arquivo no formato CSV (valores separados por vírgula)
fronteira de decisão
O separador entre classes aprendido por um modelo em um problema de classificação binária ou multiclasse. Por exemplo, na imagem a seguir, que representa um problema de classificação binária, a fronteira de decisão é a fronteira entre as classes laranja e azul:

floresta de decisão
Um modelo criado com várias árvores de decisão. Uma floresta de decisão faz uma previsão agregando as previsões das árvores de decisão dela. Os tipos mais usados de florestas de decisão incluem florestas aleatórias e árvores aprimoradas por gradiente.
Consulte a seção Florestas de decisão no curso sobre florestas de decisão para mais informações.
limiar de decisão
Sinônimo de limiar de classificação.
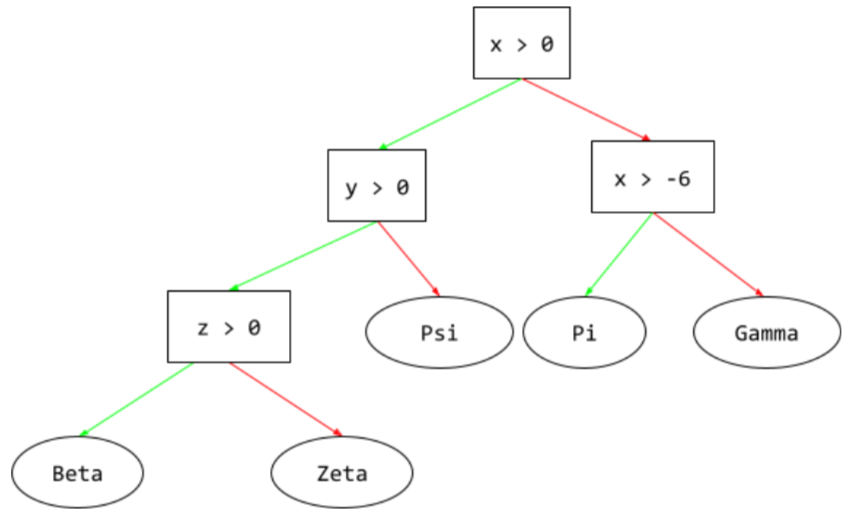
árvore de decisão
Um modelo de aprendizado supervisionado composto por um conjunto de condições e folhas organizadas hierarquicamente. Por exemplo, esta é uma árvore de decisão:
decodificador
Em geral, qualquer sistema de ML que converta de uma representação processada, densa ou interna para uma representação mais bruta, esparsa ou externa.
Os decodificadores geralmente são um componente de um modelo maior, em que são frequentemente pareados com um codificador.
Em tarefas de sequência para sequência, um decodificador começa com o estado interno gerado pelo codificador para prever a próxima sequência.
Consulte Transformer para ver a definição de um decodificador na arquitetura do Transformer.
Consulte Modelos de linguagem grandes no Curso intensivo de machine learning para mais informações.
modelo profundo
Uma rede neural que contém mais de uma camada oculta.
Um modelo profundo também é chamado de rede neural profunda.
Contraste com o modelo amplo.
de rede neural profunda, amplamente utilizado
Sinônimo de modelo profundo.
Rede Q profunda (DQN)
No aprendizado por Q, uma rede neural profunda prevê funções Q.
Crítico é um sinônimo de rede Q profunda.
paridade demográfica
Uma métrica de imparcialidade que é satisfeita se os resultados da classificação de um modelo não dependem de um determinado atributo sensível.
Por exemplo, se os liliputianos e os brobdingnagianos se inscreverem na Universidade de Glubbdubdrib, a paridade demográfica será alcançada se a porcentagem de liliputianos admitidos for a mesma que a de brobdingnagianos, independente de um grupo ser, em média, mais qualificado que o outro.
Contraste com odds equalizadas e igualdade de oportunidades, que permitem que os resultados da classificação dependam de atributos sensíveis no agregado, mas não permitem que os resultados da classificação para determinados rótulos de informações empíricas especificados dependam de atributos sensíveis. Consulte "Como combater a discriminação com um machine learning mais inteligente" para ver uma visualização que explora as compensações ao otimizar a paridade demográfica.
Consulte Imparcialidade: paridade demográfica no Curso intensivo de machine learning para mais informações.
remoção de ruído
Uma abordagem comum para aprendizado autossupervisionado em que:
A remoção de ruído permite o aprendizado com exemplos sem rótulo. O conjunto de dados original serve como destino ou rótulo, e os dados ruidosos como entrada.
Alguns modelos de linguagem mascarada usam a remoção de ruído da seguinte forma:
- O ruído é adicionado artificialmente a uma frase sem rótulo mascarando alguns dos tokens.
- O modelo tenta prever os tokens originais.
atributo denso
Uma característica em que a maioria ou todos os valores são diferentes de zero, geralmente um tensor de valores de ponto flutuante. Por exemplo, o tensor de 10 elementos a seguir é denso porque 9 dos valores são diferentes de zero:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Contraste com o atributo esparso.
camada densa
Sinônimo de camada totalmente conectada.
profundidade
A soma do seguinte em uma rede neural:
- o número de camadas ocultas
- o número de camadas de saída, que geralmente é 1
- o número de camadas de embedding
Por exemplo, uma rede neural com cinco camadas escondidas e uma de saída tem uma profundidade de 6.
A camada de entrada não influencia a profundidade.
rede neural convolucional separável por profundidade (sepCNN)
Uma arquitetura de rede neural convolucional baseada em Inception, mas em que os módulos do Inception são substituídos por convoluções separáveis em profundidade. Também conhecido como Xception.
Uma convolução separável por profundidade (também abreviada como convolução separável) transforma uma convolução 3D padrão em duas operações de convolução separadas que são mais eficientes em termos de computação: primeiro, uma convolução separável por profundidade, com uma profundidade de 1 (n ✕ n ✕ 1) e, em seguida, uma convolução pontual, com comprimento e largura de 1 (1 ✕ 1 ✕ n).
Para saber mais, consulte Xception: Deep Learning with Depthwise Separable Convolutions (em inglês).
rótulo derivado
Sinônimo de rótulo indireto.
dispositivo
Um termo sobrecarregado com as duas definições possíveis a seguir:
- Uma categoria de hardware que pode executar uma sessão do TensorFlow, incluindo CPUs, GPUs e TPUs.
- Ao treinar um modelo de ML em chips aceleradores (GPUs ou TPUs), a parte do sistema que manipula tensores e incorporações. O dispositivo funciona com chips aceleradores. Por outro lado, o host normalmente é executado em uma CPU.
privacidade diferencial
Em machine learning, uma abordagem de anonimização para proteger dados sensíveis (por exemplo, informações pessoais de um indivíduo) incluídos no conjunto de treinamento de um modelo contra exposição. Essa abordagem garante que o modelo não aprenda nem se lembre de muita coisa sobre um indivíduo específico. Isso é feito por amostragem e adição de ruído durante o treinamento do modelo para ocultar pontos de dados individuais, reduzindo o risco de exposição de dados de treinamento sensíveis.
A privacidade diferencial também é usada fora do machine learning. Por exemplo, os cientistas de dados às vezes usam a privacidade diferencial para proteger a privacidade individual ao calcular estatísticas de uso do produto para diferentes dados demográficos.
redução de dimensão
Diminuir o número de dimensões usadas para representar um recurso específico em um vetor de recurso, geralmente convertendo para um vetor de embedding.
dimensões
Termo sobrecarregado com qualquer uma das seguintes definições:
O número de níveis de coordenadas em um Tensor. Por exemplo:
- Um escalar tem zero dimensões, por exemplo,
["Hello"]. - Um vetor tem uma dimensão, por exemplo,
[3, 5, 7, 11]. - Uma matriz tem duas dimensões, por exemplo,
[[2, 4, 18], [5, 7, 14]]. É possível especificar uma célula em um vetor unidimensional com uma coordenada, mas são necessárias duas coordenadas para especificar uma célula em uma matriz bidimensional.
- Um escalar tem zero dimensões, por exemplo,
O número de entradas em um vetor de recursos.
O número de elementos em uma camada de incorporação.
comando direto
Sinônimo de comando zero-shot.
atributo discreto
Um recurso com um conjunto finito de valores possíveis. Por exemplo, um atributo cujos valores só podem ser animal, vegetal ou mineral é um atributo discreto (ou categórico).
Contraste com o atributo contínuo.
modelo discriminativo
Um modelo que prevê rótulos com base em um conjunto de um ou mais atributos. De maneira mais formal, os modelos discriminativos definem a probabilidade condicional de uma saída considerando os recursos e os pesos. Ou seja:
p(output | features, weights)
Por exemplo, um modelo que prevê se um e-mail é spam com base em recursos e pesos é um modelo discriminativo.
A grande maioria dos modelos de aprendizado supervisionado, incluindo modelos de classificação e regressão, são discriminativos.
Contraste com o modelo generativo.
discriminador
Um sistema que determina se exemplos são reais ou falsos.
Ou, o subsistema em uma rede generativa adversarial que determina se os exemplos criados pelo gerador são reais ou falsos.
Consulte O discriminador no curso de GAN para mais informações.
impacto desigual
Tomar decisões sobre pessoas que afetam desproporcionalmente diferentes subgrupos da população. Isso geralmente se refere a situações em que um processo algorítmico de tomada de decisões prejudica ou beneficia alguns subgrupos mais do que outros.
Por exemplo, suponha que um algoritmo que determina a qualificação de um liliputiano para um empréstimo de uma casa em miniatura tenha mais probabilidade de classificá-lo como "não qualificado" se o endereço de correspondência dele contiver um determinado CEP. Se os Big-Endian Lilliputians tiverem mais probabilidade de ter endereços postais com esse CEP do que os Little-Endian Lilliputians, esse algoritmo poderá resultar em impacto desigual.
Contraste com o tratamento desigual, que se concentra nas disparidades resultantes quando as características do subgrupo são entradas explícitas em um processo algorítmico de tomada de decisões.
tratamento desigual
Considerar os atributos sensíveis dos indivíduos em um processo algorítmico de tomada de decisões para que diferentes subgrupos de pessoas sejam tratados de maneira diferente.
Por exemplo, considere um algoritmo que determina a qualificação dos liliputianos para um empréstimo de uma casa em miniatura com base nos dados fornecidos na solicitação de empréstimo. Se o algoritmo usar a afiliação de um liliputiano como Big-Endian ou Little-Endian como entrada, ele estará realizando um tratamento desigual nessa dimensão.
Em contraste com o impacto desigual, que se concentra nas disparidades nos impactos sociais das decisões algorítmicas em subgrupos, independentemente de esses subgrupos serem entradas para o modelo.
destilação
O processo de reduzir o tamanho de um modelo (conhecido como professor) em um modelo menor (conhecido como estudante) que emula as previsões do modelo original da forma mais fiel possível. A destilação é útil porque o modelo menor tem dois benefícios principais em relação ao modelo maior (o professor):
- Tempo de inferência mais rápido
- Uso reduzido de memória e energia
No entanto, as previsões dos estudantes geralmente não são tão boas quanto as dos professores.
A destilação treina o modelo estudante para minimizar uma função de perda com base na diferença entre as saídas das previsões dos modelos estudante e professor.
Compare e contraste a destilação com os seguintes termos:
Consulte LLMs: ajuste fino, destilação e engenharia de comando no Curso intensivo de machine learning para mais informações.
Distribuição
A frequência e o intervalo de diferentes valores para um determinado recurso ou rótulo. Uma distribuição captura a probabilidade de um valor específico.
A imagem a seguir mostra histogramas de duas distribuições diferentes:
- À esquerda, uma distribuição de lei de potência de riqueza versus o número de pessoas que possuem essa riqueza.
- À direita, uma distribuição normal de altura versus o número de pessoas com essa altura.
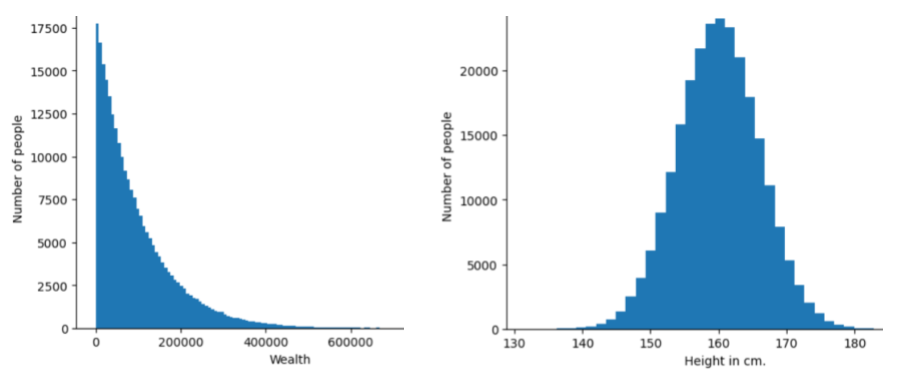
Entender a distribuição de cada recurso e rótulo ajuda a determinar como normalizar valores e detectar outliers.
A frase fora da distribuição se refere a um valor que não aparece no conjunto de dados ou é muito raro. Por exemplo, uma imagem do planeta Saturno seria considerada fora da distribuição para um conjunto de dados composto por imagens de gatos.
clustering divisivo
Consulte clustering hierárquico.
redução de amostragem
Termo sobrecarregado que pode significar uma das seguintes opções:
- Reduzir a quantidade de informações em um atributo para treinar um modelo com mais eficiência. Por exemplo, antes de treinar um modelo de reconhecimento de imagens, faça o downsampling de imagens de alta resolução para um formato de resolução mais baixa.
- Treinar com uma porcentagem desproporcionalmente baixa de exemplos de classe super-representada para melhorar o treinamento do modelo em classes sub-representadas. Por exemplo, em um conjunto de dados com desequilíbrio de classes, os modelos tendem a aprender muito sobre a classe majoritária e pouco sobre a classe minoritária. A subamostragem ajuda a equilibrar a quantidade de treinamento nas classes majoritária e minoritária.
Consulte Conjuntos de dados: conjuntos de dados desequilibrados no Curso intensivo de machine learning para mais informações.
DQN
Abreviação de Deep Q-Network.
regularização por dropout
Uma forma de regularização útil no treinamento de redes neurais. A regularização de dropout remove uma seleção aleatória de um número fixo de unidades em uma camada de rede para uma única etapa de gradiente. Quanto mais unidades forem descartadas, mais forte será a regularização. Isso é análogo ao treinamento da rede para emular um conjunto exponencialmente grande de redes menores. Para mais detalhes, consulte Dropout: uma maneira simples de evitar o overfitting de redes neurais.
dinâmico
Algo feito com frequência ou de forma contínua. Os termos dinâmico e on-line são sinônimos em machine learning. Confira a seguir usos comuns de dinâmico e on-line no aprendizado de máquina:
- Um modelo dinâmico (ou modelo on-line) é um modelo que é treinado novamente com frequência ou de forma contínua.
- O treinamento dinâmico (ou treinamento on-line) é o processo de treinamento frequente ou contínuo.
- A inferência dinâmica (ou on-line) é o processo de gerar previsões sob demanda.
modelo dinâmico
Um modelo que é treinado novamente com frequência (talvez até continuamente). Um modelo dinâmico é um "aprendiz permanente" que se adapta constantemente aos dados em evolução. Um modelo dinâmico também é conhecido como um modelo on-line.
Contraste com o modelo estático.
E
execução rápida
Um ambiente de programação do TensorFlow em que as operações são executadas imediatamente. Em contraste, as operações chamadas na execução de gráficos não são executadas até serem avaliadas explicitamente. A execução imediata é uma interface imperativa, muito parecida com o código na maioria das linguagens de programação. Em geral, é muito mais fácil depurar programas de execução rápida do que programas de execução de gráficos.
parada antecipada
Um método de regularização que envolve encerrar o treinamento antes que a perda de treinamento pare de diminuir. Na parada antecipada, você interrompe intencionalmente o treinamento do modelo quando a perda em um conjunto de dados de validação começa a aumentar, ou seja, quando o desempenho de generalização piora.
Contraste com o descarte antecipado.
Distância de movimentação de terra (EMD, na sigla em inglês)
Uma medida da similaridade relativa de duas distribuições. Quanto menor a distância do trabalho do operador de terra, mais semelhantes são as distribuições.
distância de edição
Uma medição de como duas strings de texto são semelhantes entre si. No aprendizado de máquina, a distância de edição é útil pelos seguintes motivos:
- A distância de edição é fácil de calcular.
- A distância de edição pode comparar duas strings que são semelhantes entre si.
- A distância de edição pode determinar o grau de semelhança entre diferentes strings e uma string específica.
Existem várias definições de distância de edição, cada uma usando diferentes operações de string. Consulte Distância de Levenshtein para conferir um exemplo.
Notação Einsum
Uma notação eficiente para descrever como dois tensores devem ser combinados. Para combinar os tensores, multiplique os elementos de um tensor pelos elementos do outro e some os produtos. A notação de Einsum usa símbolos para identificar os eixos de cada tensor, e esses mesmos símbolos são reorganizados para especificar a forma do novo tensor resultante.
O NumPy oferece uma implementação comum do Einsum.
camada de embedding
Uma camada oculta especial que treina em um recurso categórico de alta dimensão para aprender gradualmente um vetor de embedding de dimensão inferior. Uma camada de incorporação permite que uma rede neural seja treinada de maneira muito mais eficiente do que apenas com o recurso categórico de alta dimensão.
Por exemplo, o Earth atualmente é compatível com cerca de 73.000 espécies de árvores. Suponha que a espécie de árvore seja um recurso no seu modelo. Assim, a camada de entrada dele inclui um vetor one-hot com 73.000 elementos.
Por exemplo, talvez baobab seja representado assim:

Uma matriz de 73.000 elementos é muito longa. Se você não adicionar uma camada de incorporação ao modelo, o treinamento vai levar muito tempo devido à multiplicação de 72.999 zeros. Talvez você escolha que a camada de embedding tenha 12 dimensões. Como consequência, a camada de incorporação vai aprender gradualmente um novo vetor de incorporação para cada espécie de árvore.
Em algumas situações, o hashing é uma alternativa razoável a uma camada de incorporação.
Consulte Embeddings no Curso intensivo de machine learning para mais informações.
espaço de embedding
O espaço vetorial d-dimensional em que os recursos de um espaço vetorial de dimensão maior são mapeados. O espaço de embedding é treinado para capturar uma estrutura significativa para o aplicativo pretendido.
O produto escalar de dois embeddings é uma medida da semelhança entre eles.
vetor de embedding
De modo geral, uma matriz de números de ponto flutuante extraídos de qualquer camada oculta que descreve as entradas dessa camada. Muitas vezes, um vetor de embedding é a matriz de números de ponto flutuante treinada em uma camada de embedding. Por exemplo, suponha que uma camada de embedding precise aprender um vetor de embedding para cada uma das 73.000 espécies de árvores na Terra. Talvez a matriz a seguir seja o vetor de embedding de um baobá:

Um vetor de embedding não é um monte de números aleatórios. Uma camada de embedding determina esses valores por treinamento, de maneira semelhante a como uma rede neural aprende outros pesos durante o treinamento. Cada elemento da matriz é uma classificação de alguma característica de uma espécie de árvore. Qual elemento representa a característica de qual espécie de árvore? Isso é muito difícil para os humanos.
A parte matematicamente notável de um vetor de embedding é que itens semelhantes têm conjuntos semelhantes de números de ponto flutuante. Por exemplo, espécies de árvores semelhantes têm um conjunto mais parecido de números de ponto flutuante do que espécies diferentes. As sequoias e os cedros-da-califórnia são espécies de árvores relacionadas. Portanto, elas têm um conjunto mais parecido de números de ponto flutuante do que sequoias e coqueiros. Os números no vetor de incorporação mudam sempre que você treina o modelo de novo, mesmo que o faça com entradas idênticas.
função de distribuição cumulativa empírica (eCDF ou EDF)
Uma função de distribuição cumulativa com base em medições empíricas de um conjunto de dados real. O valor da função em qualquer ponto ao longo do eixo x é a fração de observações no conjunto de dados que são menores ou iguais ao valor especificado.
minimização do risco empírico (ERM, na sigla em inglês)
Escolher a função que minimiza a perda no conjunto de treinamento. Contraste com a minimização de risco estrutural.
codificador
Em geral, qualquer sistema de ML que converte uma representação bruta, esparsa ou externa em uma representação mais processada, densa ou interna.
Os codificadores geralmente são um componente de um modelo maior, em que são frequentemente pareados com um decodificador. Alguns Transformers combinam codificadores e decodificadores, mas outros usam apenas o codificador ou apenas o decodificador.
Alguns sistemas usam a saída do codificador como entrada para uma rede de classificação ou regressão.
Em tarefas de sequência para sequência, um codificador recebe uma sequência de entrada e retorna um estado interno (um vetor). Em seguida, o decodificador usa esse estado interno para prever a próxima sequência.
Consulte Transformer para ver a definição de um codificador na arquitetura do Transformer.
Consulte LLMs: o que é um modelo de linguagem grande? no Curso intensivo de machine learning para mais informações.
endpoints
Um local endereçável por rede (normalmente um URL) em que um serviço pode ser acessado.
automatizado
Uma coleção de modelos treinados de forma independente cujas previsões são calculadas ou agregadas. Em muitos casos, um conjunto produz previsões melhores do que um único modelo. Por exemplo, uma floresta aleatória é um conjunto criado com várias árvores de decisão. Nem todas as florestas de decisão são conjuntos.
Consulte Floresta aleatória no Curso intensivo de machine learning para mais informações.
entropia
Na teoria da informação, uma descrição de como uma distribuição de probabilidade é imprevisível. Outra definição de entropia é a quantidade de informações que cada exemplo contém. Uma distribuição tem a maior entropia possível quando todos os valores de uma variável aleatória têm a mesma probabilidade.
A entropia de um conjunto com dois valores possíveis "0" e "1" (por exemplo, os rótulos em um problema de classificação binária) tem a seguinte fórmula:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
em que:
- H é a entropia.
- p é a fração de exemplos "1".
- q é a fração de exemplos "0". q = (1 - p)
- log geralmente é log2. Nesse caso, a unidade de entropia é um bit.
Por exemplo, suponha que:
- 100 exemplos contêm o valor "1"
- 300 exemplos contêm o valor "0"
Portanto, o valor de entropia é:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) - (0,75)log2(0,75) = 0,81 bits por exemplo
Um conjunto perfeitamente equilibrado (por exemplo, 200 "0"s e 200 "1"s) teria uma entropia de 1,0 bit por exemplo. À medida que um conjunto se torna mais desequilibrado, a entropia dele se aproxima de 0,0.
Nas árvores de decisão, a entropia ajuda a formular o ganho de informações para que o divisor selecione as condições durante o crescimento de uma árvore de decisão de classificação.
Compare a entropia com:
- impureza de Gini
- Função de perda de entropia cruzada
A entropia é geralmente chamada de entropia de Shannon.
Consulte Divisor exato para classificação binária com recursos numéricos no curso "Florestas de decisão" para mais informações.
ambiente
No aprendizado por reforço, o mundo que contém o agente e permite que ele observe o estado desse mundo. Por exemplo, o mundo representado pode ser um jogo como xadrez ou um mundo físico como um labirinto. Quando o agente aplica uma ação ao ambiente, ele faz a transição entre estados.
episódio
Na aprendizagem por reforço, cada uma das tentativas repetidas do agente para aprender um ambiente.
época
Uma passagem completa de treinamento em todo o conjunto de treinamento, de modo que cada exemplo seja processado uma vez.
Uma época representa N/tamanho do lote
iterações de treinamento, em que N é o número total de exemplos.
Por exemplo, suponha que:
- O conjunto de dados consiste em 1.000 exemplos.
- O tamanho do lote é de 50 exemplos.
Portanto, uma única época requer 20 iterações:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
política epsilon-greedy
No aprendizado por reforço, uma política que segue uma política aleatória com probabilidade epsilon ou uma política gananciosa. Por exemplo, se epsilon for 0,9, a política seguirá uma política aleatória 90% das vezes e uma política greedy 10% das vezes.
Em episódios sucessivos, o algoritmo reduz o valor de epsilon para mudar de uma política aleatória para uma política gananciosa. Ao mudar a política, o agente primeiro explora o ambiente de forma aleatória e depois aproveita os resultados dessa exploração.
igualdade de oportunidades
Uma métrica de imparcialidade para avaliar se um modelo está prevendo o resultado desejado de forma igualmente boa para todos os valores de um atributo sensível. Em outras palavras, se o resultado desejado para um modelo for a classe positiva, o objetivo será ter a taxa de verdadeiro positivo igual para todos os grupos.
A igualdade de oportunidade está relacionada às chances equalizadas, que exigem que ambas as taxas de verdadeiro positivo e falso positivo sejam iguais para todos os grupos.
Suponha que a Universidade Glubbdubdrib admita liliputianos e brobdingnagianos em um programa rigoroso de matemática. As escolas de ensino médio de Lilliput oferecem um currículo robusto de aulas de matemática, e a grande maioria dos estudantes se qualifica para o programa universitário. As escolas secundárias de Brobdingnag não oferecem aulas de matemática, e, como resultado, muito menos estudantes se qualificam. A igualdade de oportunidades é satisfeita para o rótulo preferido "admitido" em relação à nacionalidade (Lilliputiana ou Brobdingnagiana) se os estudantes qualificados tiverem a mesma probabilidade de serem admitidos, independentemente de serem Lilliputianos ou Brobdingnagianos.
Por exemplo, suponha que 100 liliputianos e 100 brobdingnagianos se inscrevam na Universidade de Glubbdubdrib, e as decisões de admissão sejam tomadas da seguinte forma:
Tabela 1. Candidatos liliputianos (90% são qualificados)
| Qualificado | Não qualificado | |
|---|---|---|
| Permitido | 45 | 3 |
| Recusado | 45 | 7 |
| Total | 90 | 10 |
|
Porcentagem de estudantes qualificados admitidos: 45/90 = 50% Porcentagem de estudantes não qualificados rejeitados: 7/10 = 70% Porcentagem total de estudantes de Lilliput admitidos: (45+3)/100 = 48% |
||
Tabela 2. Candidatos brobdingnagianos (10% são qualificados):
| Qualificado | Não qualificado | |
|---|---|---|
| Permitido | 5 | 9 |
| Recusado | 5 | 81 |
| Total | 10 | 90 |
|
Porcentagem de estudantes qualificados admitidos: 5/10 = 50% Porcentagem de estudantes não qualificados rejeitados: 81/90 = 90% Porcentagem total de estudantes de Brobdingnag admitidos: (5+9)/100 = 14% |
||
Os exemplos anteriores atendem à igualdade de oportunidades para a aceitação de estudantes qualificados, porque tanto os liliputianos quanto os brobdingnagianos têm 50% de chance de serem aceitos.
Embora a igualdade de oportunidade seja atendida, as duas métricas de imparcialidade a seguir não são:
- Paridade demográfica: os lilliputianos e os brobdingnagianos são admitidos na universidade em taxas diferentes. 48% dos estudantes lilliputianos são admitidos, mas apenas 14% dos estudantes brobdingnagianos são admitidos.
- Probabilidades igualadas: embora os estudantes qualificados de Lilliput e Brobdingnag tenham a mesma chance de serem aceitos, a restrição adicional de que os estudantes não qualificados de Lilliput e Brobdingnag tenham a mesma chance de serem rejeitados não é atendida. Os lilliputianos não qualificados têm uma taxa de rejeição de 70%, enquanto os brobdingnagianos não qualificados têm uma taxa de rejeição de 90%.
Consulte Imparcialidade: igualdade de oportunidades no Curso intensivo de machine learning para mais informações.
probabilidades igualadas
Uma métrica de justiça para avaliar se um modelo está prevendo resultados igualmente bem para todos os valores de um atributo sensível em relação à classe positiva e à classe negativa, e não apenas uma classe ou outra exclusivamente. Em outras palavras, tanto a taxa de verdadeiros positivos quanto a taxa de falsos negativos precisam ser iguais para todos os grupos.
A igualdade de chances está relacionada à igualdade de oportunidades, que se concentra apenas nas taxas de erro de uma única classe (positiva ou negativa).
Por exemplo, suponha que a Universidade Glubbdubdrib admita liliputianos e brobdingnagianos em um programa rigoroso de matemática. As escolas de ensino médio de Lilliput oferecem um currículo robusto de aulas de matemática, e a grande maioria dos estudantes se qualifica para o programa universitário. As escolas secundárias de Brobdingnag não oferecem aulas de matemática, e, como resultado, muito menos estudantes se qualificam. A igualdade de chances é satisfeita desde que, não importa se um candidato é um liliputiano ou um brobdingnagiano, se ele for qualificado, terá a mesma probabilidade de ser aceito no programa, e se não for qualificado, terá a mesma probabilidade de ser rejeitado.
Suponha que 100 liliputianos e 100 brobdingnagianos se inscrevam na Universidade de Glubbdubdrib, e as decisões de admissão sejam tomadas da seguinte forma:
Tabela 3. Candidatos liliputianos (90% são qualificados)
| Qualificado | Não qualificado | |
|---|---|---|
| Permitido | 45 | 2 |
| Recusado | 45 | 8 |
| Total | 90 | 10 |
|
Porcentagem de estudantes qualificados admitidos: 45/90 = 50% Porcentagem de estudantes não qualificados rejeitados: 8/10 = 80% Porcentagem total de estudantes de Lilliput admitidos: (45+2)/100 = 47% |
||
Tabela 4. Candidatos brobdingnagianos (10% são qualificados):
| Qualificado | Não qualificado | |
|---|---|---|
| Permitido | 5 | 18 |
| Recusado | 5 | 72 |
| Total | 10 | 90 |
|
Porcentagem de estudantes qualificados admitidos: 5/10 = 50% Porcentagem de estudantes não qualificados rejeitados: 72/90 = 80% Porcentagem total de estudantes de Brobdingnag admitidos: (5+18)/100 = 23% |
||
A igualdade de chances é satisfeita porque os estudantes qualificados de Lilliput e Brobdingnag têm uma chance de 50% de serem aceitos, e os estudantes não qualificados de Lilliput e Brobdingnag têm uma chance de 80% de serem rejeitados.
A probabilidade igualada é formalmente definida em "Equality of Opportunity in Supervised Learning" (em inglês) da seguinte forma: "o preditor Ŷ satisfaz a probabilidade igualada em relação ao atributo protegido A e ao resultado Y se Ŷ e A forem independentes, condicionalmente a Y".
Estimator
Uma API TensorFlow descontinuada. Use tf.keras em vez de Estimators.
avaliações
Usado principalmente como uma abreviação de avaliações de LLM. De modo geral, avaliações é uma abreviação de qualquer forma de avaliação.
Avaliação
O processo de medir a qualidade de um modelo ou comparar diferentes modelos.
Para avaliar um modelo de aprendizado de máquina supervisionado, normalmente você o compara a um conjunto de validação e a um conjunto de teste. Avaliar um LLM normalmente envolve avaliações mais amplas de qualidade e segurança.
correspondência exata
Uma métrica tudo ou nada em que a saída do modelo corresponde exatamente às informações empíricas ou ao texto de referência, ou não corresponde. Por exemplo, se as informações empíricas forem laranja, a única saída do modelo que atende à correspondência exata é laranja.
A correspondência exata também pode avaliar modelos cuja saída é uma sequência (uma lista classificada de itens). Em geral, a correspondência exata exige que a lista classificada gerada corresponda exatamente à verdade fundamental. Ou seja, cada item nas duas listas precisa estar na mesma ordem. No entanto, se as informações empíricas consistirem em várias sequências corretas, a correspondência exata só vai exigir que a saída do modelo corresponda a uma das sequências corretas.
exemplo
Os valores de uma linha de atributos e possivelmente um rótulo. Os exemplos de aprendizado supervisionado se enquadram em duas categorias gerais:
- Um exemplo rotulado consiste em um ou mais atributos e um rótulo. Exemplos rotulados são usados durante o treinamento.
- Um exemplo sem rótulo consiste em um ou mais atributos, mas sem rótulo. Exemplos sem rótulo são usados durante a inferência.
Por exemplo, suponha que você esteja treinando um modelo para determinar a influência das condições climáticas nas notas dos estudantes. Confira três exemplos rotulados:
| Recursos | Rótulo | ||
|---|---|---|---|
| Temperatura | Umidade | Pressão | Pontuação do teste |
| 15 | 47 | 998 | Boa |
| 19 | 34 | 1020 | Excelente |
| 18 | 92 | 1012 | Ruim |
Confira três exemplos sem rótulo:
| Temperatura | Umidade | Pressão | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
A linha de um conjunto de dados geralmente é a origem bruta de um exemplo. Ou seja, um exemplo geralmente consiste em um subconjunto das colunas no conjunto de dados. Além disso, os recursos em um exemplo também podem incluir recursos sintéticos, como cruzamentos de recursos.
Consulte Aprendizado supervisionado no curso Introdução ao machine learning para mais informações.
replay de experiência
No aprendizado por reforço, uma técnica DQN usada para reduzir correlações temporais em dados de treinamento. O agente armazena transições de estado em um buffer de repetição e, em seguida, faz amostragem de transições do buffer de repetição para criar dados de treinamento.
viés do experimentador
Consulte viés de confirmação.
problema de gradiente explosivo
A tendência de gradientes em redes neurais profundas (especialmente redes neurais recorrentes) se tornarem surpreendentemente íngremes (altos). Gradientes acentuados geralmente causam atualizações muito grandes nos pesos de cada nó em uma rede neural profunda.
Modelos que sofrem com o problema de gradiente explosivo se tornam difíceis ou impossíveis de treinar. O corte de gradiente pode reduzir esse problema.
Compare com o problema do desaparecimento de gradiente.
Resumo extremo (xsum)
Um conjunto de dados para avaliar a capacidade de um LLM de resumir um único documento. Cada entrada no conjunto de dados consiste em:
- Um documento criado pela British Broadcasting Corporation (BBC).
- Um resumo de uma frase desse documento.
Para mais detalhes, consulte Não me dê os detalhes, apenas o resumo! Redes neurais convolucionais com reconhecimento de tema para sumarização extrema.
F
F1
Uma métrica de classificação binária "consolidada" que depende da precisão e do recall. Esta é a fórmula:
veracidade
No mundo do ML, uma propriedade que descreve um modelo cuja saída é baseada na realidade. A veracidade é um conceito, não uma métrica. Por exemplo, suponha que você envie o seguinte comando para um modelo de linguagem grande:
Qual é a fórmula química do sal de cozinha?
Um modelo que otimiza a veracidade responderia:
NaCl
É tentador presumir que todos os modelos devem ser baseados em fatos. No entanto, alguns comandos, como os seguintes, fazem com que um modelo de IA generativa otimize a criatividade em vez da veracidade.
Conte uma sátira sobre um astronauta e uma lagarta.
É improvável que o limerick resultante seja baseado na realidade.
Contraste com o fundamento.
restrição de imparcialidade
Aplicar uma restrição a um algoritmo para garantir que uma ou mais definições de imparcialidade sejam atendidas. Exemplos de restrições de imparcialidade:- Pós-processamento da saída do modelo.
- Alterar a função de perda para incorporar uma penalidade por violar uma métrica de justiça.
- Adicionar diretamente uma restrição matemática a um problema de otimização.
métrica de imparcialidade
Uma definição matemática de "justiça" que pode ser medida. Algumas métricas de imparcialidade usadas com frequência incluem:
Muitas métricas de imparcialidade são mutuamente exclusivas. Consulte incompatibilidade das métricas de imparcialidade.
falso negativo (FN)
Um exemplo em que o modelo prevê incorretamente a classe negativa. Por exemplo, o modelo prevê que uma determinada mensagem de e-mail não é spam (a classe negativa), mas na verdade é spam.
taxa de falso negativo
A proporção de exemplos positivos reais para os quais o modelo previu incorretamente a classe negativa. A fórmula a seguir calcula a taxa de falsos negativos:
Consulte Limiares e a matriz de confusão no Curso intensivo de machine learning para mais informações.
falso positivo (FP)
Um exemplo em que o modelo prevê incorretamente a classe positiva. Por exemplo, o modelo prevê que uma determinada mensagem de e-mail é spam (a classe positiva), mas que essa mensagem não é spam.
Consulte Limiares e a matriz de confusão no Curso intensivo de machine learning para mais informações.
taxa de falso positivo (FPR)
A proporção de exemplos negativos reais para os quais o modelo previu incorretamente a classe positiva. A fórmula a seguir calcula a taxa de falsos positivos:
A taxa de falso positivo é o eixo x em uma curva ROC.
Consulte Classificação: ROC e AUC no Curso intensivo de machine learning para mais informações.
decaimento rápido
Uma técnica de treinamento para melhorar a performance dos LLMs. O decaimento rápido envolve a diminuição rápida da taxa de aprendizado durante o treinamento. Essa estratégia ajuda a evitar que o modelo faça overfitting nos dados de treinamento e melhora a generalização.
recurso
Uma variável de entrada para um modelo de machine learning. Um exemplo consiste em um ou mais atributos. Por exemplo, suponha que você esteja treinando um modelo para determinar a influência das condições climáticas nas notas dos estudantes. A tabela a seguir mostra três exemplos, cada um com três recursos e um rótulo:
| Recursos | Rótulo | ||
|---|---|---|---|
| Temperatura | Umidade | Pressão | Pontuação do teste |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Contraste com o rótulo.
Consulte Aprendizado supervisionado no curso "Introdução ao machine learning" para mais informações.
cruzamento de atributos
Um atributo sintético formado pelo "cruzamento" de atributos categóricos ou agrupados por classes.
Por exemplo, considere um modelo de "previsão de humor" que representa a temperatura em um dos quatro intervalos a seguir:
freezingchillytemperatewarm
e representa a velocidade do vento em um dos três buckets a seguir:
stilllightwindy
Sem cruzamentos de atributos, o modelo linear é treinado de forma independente em cada um dos sete intervalos anteriores. Assim, o modelo é treinado em freezing de forma independente do treinamento em windy.
Como alternativa, você pode criar um cruzamento de atributos de temperatura e velocidade do vento. Esse recurso sintético teria os seguintes 12 valores possíveis:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Graças aos cruzamentos de atributos, o modelo pode aprender as diferenças de humor entre um dia freezing-windy e um dia freezing-still.
Se você criar um atributo sintético com base em dois atributos que têm muitos intervalos diferentes, o cruzamento de atributos resultante terá um grande número de combinações possíveis. Por exemplo, se um recurso tiver 1.000 buckets e o outro tiver 2.000, a combinação resultante terá 2.000.000 de buckets.
Formalmente, uma combinação é um produto cartesiano.
As combinações de atributos são usadas principalmente com modelos lineares e raramente com redes neurais.
Consulte Dados categóricos: combinações de recursos no Curso intensivo de machine learning para mais informações.
engenharia de atributos
Um processo que envolve as seguintes etapas:
- Determinar quais recursos podem ser úteis no treinamento de um modelo.
- Converter dados brutos do conjunto de dados em versões eficientes desses atributos.
Por exemplo, você pode determinar que temperature é um recurso útil. Depois, teste o agrupamento em intervalos para otimizar o que o modelo pode aprender com diferentes intervalos de temperature.
A engenharia de atributos às vezes é chamada de extração de atributos ou criação de atributos.
Consulte Dados numéricos: como um modelo ingere dados usando vetores de recursos no Curso intensivo de machine learning para mais informações.
extração de atributos
Termo sobrecarregado com uma das seguintes definições:
- Recuperar representações de recursos intermediários calculadas por um modelo não supervisionado ou pré-treinado (por exemplo, valores da camada oculta em uma rede neural) para uso em outro modelo como entrada.
- Sinônimo de engenharia de atributos.
importâncias de atributos
Sinônimo de importâncias de variáveis.
conjunto de atributos
O grupo de atributos em que seu modelo de machine learning é treinado. Por exemplo, um conjunto de recursos simples para um modelo que prevê preços de imóveis pode consistir em CEP, tamanho e condição da propriedade.
especificação de atributos
Descreve as informações necessárias para extrair dados de recursos do buffer de protocolo tf.Example. Como o buffer de protocolo tf.Example é apenas um contêiner de dados, é necessário especificar o seguinte:
- Os dados a serem extraídos (ou seja, as chaves dos recursos)
- O tipo de dados (por exemplo, ponto flutuante ou inteiro)
- A duração (fixa ou variável)
vetor de atributos
A matriz de valores de recurso que compõem um exemplo. O vetor de recursos é inserido durante o treinamento e a inferência. Por exemplo, o vetor de recursos de um modelo com dois recursos discretos pode ser:
[0.92, 0.56]
Cada exemplo fornece valores diferentes para o vetor de atributos. Portanto, o vetor de atributos do próximo exemplo pode ser algo como:
[0.73, 0.49]
A engenharia de atributos determina como representar atributos no vetor de atributos. Por exemplo, um atributo categórico binário com cinco valores possíveis pode ser representado com codificação one-hot. Nesse caso, a parte do vetor de recursos para um exemplo específico consistiria em quatro zeros e um único 1,0 na terceira posição, da seguinte forma:
[0.0, 0.0, 1.0, 0.0, 0.0]
Como outro exemplo, suponha que seu modelo consista em três recursos:
- um atributo categórico binário com cinco valores possíveis representados com codificação one-hot. Por exemplo:
[0.0, 1.0, 0.0, 0.0, 0.0] - outro atributo categórico binário com três valores possíveis representados
com codificação one-hot. Por exemplo:
[0.0, 0.0, 1.0] - um recurso de ponto flutuante, por exemplo:
8.3.
Nesse caso, o vetor de atributos de cada exemplo seria representado por nove valores. Considerando os valores de exemplo na lista anterior, o vetor de recursos seria:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Consulte Dados numéricos: como um modelo ingere dados usando vetores de recursos no Curso intensivo de machine learning para mais informações.
caracterização
O processo de extrair recursos de uma fonte de entrada, como um documento ou vídeo, e mapear esses recursos em um vetor de recursos.
Alguns especialistas em ML usam a featurização como sinônimo de engenharia de atributos ou extração de atributos.
federated learning
Uma abordagem de machine learning distribuído que treina modelos de machine learning usando exemplos descentralizados em dispositivos como smartphones. No aprendizado federado, um subconjunto de dispositivos faz o download do modelo atual de um servidor central de coordenação. Os dispositivos usam os exemplos armazenados para fazer melhorias no modelo. Em seguida, os dispositivos fazem upload das melhorias do modelo (mas não dos exemplos de treinamento) para o servidor de coordenação, onde são agregadas a outras atualizações para gerar um modelo global aprimorado. Depois da agregação, as atualizações do modelo calculadas pelos dispositivos não são mais necessárias e podem ser descartadas.
Como os exemplos de treinamento nunca são enviados, o aprendizado federado segue os princípios de privacidade da coleta de dados focada e da minimização de dados.
Consulte os quadrinhos sobre aprendizado federado (sim, um quadrinho) para mais detalhes.
ciclo de feedback
Em machine learning, uma situação em que as previsões de um modelo influenciam os dados de treinamento do mesmo modelo ou de outro. Por exemplo, um modelo que recomenda filmes influencia os filmes que as pessoas assistem, o que, por sua vez, influencia os modelos de recomendação de filmes subsequentes.
Consulte Sistemas de ML de produção: perguntas a fazer no Curso intensivo de machine learning para mais informações.
rede neural feedforward (FFN)
Uma rede neural sem conexões cíclicas ou recursivas. Por exemplo, as redes neurais profundas tradicionais são redes neurais feedforward. Em contraste com as redes neurais recorrentes, que são cíclicas.
aprendizado few-shot
Uma abordagem de aprendizado de máquina, geralmente usada para classificação de objetos, projetada para treinar modelos de classificação eficazes com apenas um pequeno número de exemplos de treinamento.
Consulte também aprendizado one-shot e aprendizado zero-shot.
comando de poucos disparos
Um comando que contém mais de um exemplo (alguns) demonstrando como o modelo de linguagem grande deve responder. Por exemplo, o comando longo a seguir contém dois exemplos que mostram a um modelo de linguagem grande como responder a uma consulta.
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Por exemplo, |
| Reino Unido: GBP | Outro exemplo. |
| Índia: | A consulta real. |
Em geral, os comandos de poucos disparos (few-shot) produzem resultados mais interessantes do que os comandos sem disparos (zero-shot) e de um disparo (one-shot). No entanto, os comandos de poucos disparos exigem um comando mais longo.
Os comandos few-shot são uma forma de aprendizado few-shot aplicada ao aprendizado baseado em comandos.
Consulte Engenharia de comando no Curso intensivo de machine learning para mais informações.
Violino
Uma biblioteca de configuração com Python em primeiro lugar que define os valores de funções e classes sem código ou infraestrutura invasivos. No caso do Pax e de outras bases de código de ML, essas funções e classes representam modelos e hiperparâmetros de treinamento.
O Fiddle pressupõe que os codebases de machine learning são normalmente divididos em:
- Código da biblioteca, que define as camadas e os otimizadores.
- Código "glue" do conjunto de dados, que chama as bibliotecas e conecta tudo.
O Fiddle captura a estrutura de chamada do código de ligação em uma forma não avaliada e mutável.
ajuste de detalhes
Uma segunda passagem de treinamento específica para tarefas realizada em um modelo pré-treinado para refinar os parâmetros dele em um caso de uso específico. Por exemplo, a sequência de treinamento completa para alguns modelos de linguagem grandes é a seguinte:
- Pré-treinamento:treine um modelo de linguagem grande em um vasto conjunto de dados geral, como todas as páginas da Wikipédia em inglês.
- Ajuste de detalhes:treine o modelo pré-treinado para realizar uma tarefa específica, como responder a consultas médicas. O ajuste geralmente envolve centenas ou milhares de exemplos focados na tarefa específica.
Como outro exemplo, a sequência de treinamento completa para um modelo de imagem grande é a seguinte:
- Pré-treinamento:treine um modelo de imagem grande em um vasto conjunto de dados de imagens gerais, como todas as imagens do Wikimedia Commons.
- Ajuste:treine o modelo pré-treinado para realizar uma tarefa específica, como gerar imagens de orcas.
O ajuste fino pode envolver qualquer combinação das seguintes estratégias:
- Modificar todos os parâmetros do modelo pré-treinado. Às vezes, isso é chamado de ajuste fino completo.
- Modificar apenas alguns dos parâmetros atuais do modelo pré-treinado (normalmente, as camadas mais próximas da camada de saída), mantendo outros parâmetros inalterados (normalmente, as camadas mais próximas da camada de entrada). Consulte ajuste da eficiência de parâmetros.
- Adicionar mais camadas, geralmente acima das camadas atuais mais próximas da camada de saída.
O ajuste detalhado é uma forma de aprendizado por transferência. Assim, o ajuste fino pode usar uma função de perda ou um tipo de modelo diferente daqueles usados para treinar o modelo pré-treinado. Por exemplo, é possível ajustar um modelo de imagem grande pré-treinado para produzir um modelo de regressão que retorne o número de pássaros em uma imagem de entrada.
Compare e contraste o ajuste fino com os seguintes termos:
Consulte Ajuste refinado no Curso intensivo de machine learning para mais informações.
Modelo do flash
Uma família de modelos Gemini relativamente pequenos otimizados para velocidade e baixa latência. Os modelos Flash são projetados para uma ampla variedade de aplicativos em que respostas rápidas e alta capacidade de processamento são cruciais.
Linho
Uma biblioteca de código aberto de alto desempenho para aprendizado profundo criada com base no JAX. O Flax oferece funções para treinar redes neurais, além de métodos para avaliar o desempenho delas.
Flaxformer
Uma biblioteca Transformer de código aberto, criada com base no Flax e projetada principalmente para processamento de linguagem natural e pesquisa multimodal.
forget gate
A parte de uma célula de memória de longo prazo e curto prazo que regula o fluxo de informações pela célula. Os portões de esquecimento mantêm o contexto decidindo quais informações descartar do estado da célula.
modelo de fundação
Um modelo pré-treinado muito grande treinado em um conjunto de treinamento enorme e diversificado. Um modelo de base pode fazer o seguinte:
- Responder bem a uma ampla variedade de solicitações.
- Servir como um modelo de base para outros ajustes ou personalizações.
Em outras palavras, um modelo de fundação já é muito capaz em um sentido geral, mas pode ser ainda mais personalizado para se tornar ainda mais útil para uma tarefa específica.
fração de sucessos
Uma métrica para avaliar o texto gerado de um modelo de ML. A fração de sucessos é o número de saídas de texto geradas "bem-sucedidas" dividido pelo número total de saídas de texto geradas. Por exemplo, se um modelo de linguagem grande gerar 10 blocos de código, cinco dos quais foram bem-sucedidos, a fração de sucessos será de 50%.
Embora a fração de sucessos seja útil em estatísticas, no aprendizado de máquina, essa métrica é usada principalmente para medir tarefas verificáveis, como geração de código ou problemas de matemática.
softmax completa
Sinônimo de softmax.
Contraste com a amostragem de candidatos.
Consulte Redes neurais: classificação multiclasse no Curso intensivo de machine learning para mais informações.
camada totalmente conectada
Uma camada oculta em que cada nó é conectado a todos os nós na camada oculta subsequente.
Uma camada totalmente conectada também é conhecida como camada densa.
transformação de função
Uma função que recebe outra função como entrada e retorna uma função transformada como saída. O JAX usa transformações de função.
G
GAN
Abreviação de rede adversária generativa.
Gemini
O ecossistema que inclui a IA mais avançada do Google. Os elementos desse ecossistema incluem:
- Vários modelos do Gemini.
- A interface de conversa interativa para um modelo do Gemini. Os usuários digitam comandos, e o Gemini responde a eles.
- Várias APIs Gemini.
- Vários produtos comerciais baseados em modelos do Gemini, por exemplo, o Gemini para Google Cloud.
Modelos do Gemini
Modelos multimodais de última geração do Google baseados em Transformer. Os modelos do Gemini foram criados especificamente para integração com agentes.
Os usuários podem interagir com os modelos do Gemini de várias maneiras, incluindo uma interface de diálogo interativa e SDKs.
Gemma
Uma família de modelos abertos leves criados com base na mesma pesquisa e tecnologia usadas para criar os modelos do Gemini. Vários modelos diferentes da Gemma estão disponíveis, cada um com recursos diferentes, como visão, código e instruções a seguir. Consulte Gemma para mais detalhes.
IA generativa ou IA generativa
Abreviação de IA generativa.
generalização
A capacidade de um modelo de fazer previsões corretas sobre dados novos e nunca vistos antes. Um modelo que pode generalizar é o oposto de um modelo que está overfitting.
Consulte Generalização no Curso intensivo de machine learning para mais informações.
curva de generalização
Um gráfico da perda de treinamento e da perda de validação como uma função do número de iterações.
Uma curva de generalização pode ajudar você a detectar possível overfitting. Por exemplo, a curva de generalização a seguir sugere overfitting porque a perda de validação acaba se tornando significativamente maior do que a perda de treinamento.
Consulte Generalização no Curso intensivo de machine learning para mais informações.
modelo linear generalizado
Uma generalização dos modelos de regressão de mínimos quadrados, que se baseiam em ruído gaussiano, para outros tipos de modelos baseados em outros tipos de ruído, como ruído de Poisson ou ruído categórico. Exemplos de modelos lineares generalizados:
- regressão logística
- regressão multiclasse
- regressão dos mínimos quadrados
Os parâmetros de um modelo linear generalizado podem ser encontrados por otimização convexa.
Os modelos lineares generalizados têm as seguintes propriedades:
- A previsão média do modelo de regressão de mínimos quadrados ideal é igual ao rótulo médio nos dados de treinamento.
- A probabilidade média prevista pelo modelo de regressão logística ideal é igual ao rótulo médio nos dados de treinamento.
O poder de um modelo linear generalizado é limitado pelos recursos dele. Ao contrário de um modelo profundo, um modelo linear generalizado não pode "aprender novos recursos".
texto gerado
Em geral, o texto gerado por um modelo de ML. Ao avaliar modelos de linguagem grandes, algumas métricas comparam o texto gerado com um texto de referência. Por exemplo, suponha que você esteja tentando determinar a eficácia de um modelo de ML na tradução do francês para o holandês. Neste caso:
- O texto gerado é a tradução em holandês que o modelo de ML gera.
- O texto de referência é a tradução em holandês criada por um tradutor humano (ou software).
Algumas estratégias de avaliação não envolvem texto de referência.
rede adversária generativa (GAN)
Um sistema para criar novos dados em que um gerador cria dados e um discriminador determina se os dados criados são válidos ou inválidos.
Para mais informações, consulte o curso sobre redes adversárias generativas.
IA generativa
Um campo transformador emergente sem uma definição formal. No entanto, a maioria dos especialistas concorda que os modelos de IA generativa podem criar ("gerar") conteúdo que seja:
- complexo
- coerente
- original
Exemplos de IA generativa:
- Modelos de linguagem grandes, que podem gerar textos originais sofisticados e responder a perguntas.
- Modelo de geração de imagens, que pode produzir imagens únicas.
- Modelos de geração de áudio e música, que podem compor músicas originais ou gerar fala realista.
- Modelos de geração de vídeo, que podem criar vídeos originais.
Algumas tecnologias anteriores, incluindo LSTMs e RNNs, também podem gerar conteúdo original e coerente. Alguns especialistas consideram essas tecnologias anteriores como IA generativa, enquanto outros acham que a IA generativa de verdade exige uma saída mais complexa do que essas tecnologias podem produzir.
Contraste com a ML preditiva.
modelo generativo
Na prática, um modelo que faz uma destas ações:
- Cria (gera) novos exemplos do conjunto de dados de treinamento. Por exemplo, um modelo generativo pode criar poesia depois de ser treinado com um conjunto de dados de poemas. A parte geradora de uma rede adversária generativa se enquadra nessa categoria.
- Determina a probabilidade de um novo exemplo vir do conjunto de treinamento ou ter sido criado pelo mesmo mecanismo que criou o conjunto de treinamento. Por exemplo, depois de treinar um conjunto de dados com frases em inglês, um modelo generativo pode determinar a probabilidade de uma nova entrada ser uma frase válida em inglês.
Um modelo generativo pode, em teoria, discernir a distribuição de exemplos ou recursos específicos em um conjunto de dados. Ou seja:
p(examples)
Os modelos de aprendizado não supervisionado são generativos.
Contraste com modelos discriminativos.
gerador
O subsistema em uma rede generativa adversarial que cria novos exemplos.
Contraste com o modelo discriminativo.
impureza de Gini
Uma métrica semelhante à entropia. Divisores usam valores derivados da impureza de Gini ou da entropia para compor condições para classificação árvores de decisão. O ganho de informação é derivado da entropia. Não existe um termo equivalente universalmente aceito para a métrica derivada da impureza de Gini. No entanto, essa métrica sem nome é tão importante quanto o ganho de informação.
A impureza de Gini também é chamada de índice de Gini ou simplesmente Gini.
conjunto de dados de ouro
Um conjunto de dados selecionados manualmente que capturam informações empíricas. As equipes podem usar um ou mais conjuntos de dados de referência para avaliar a qualidade de um modelo.
Alguns conjuntos de dados de referência capturam diferentes subdomínios de verdade fundamental. Por exemplo, um conjunto de dados de ouro para classificação de imagens pode capturar condições de iluminação e resolução de imagem.
resposta de ouro
Uma resposta conhecida por ser boa. Por exemplo, considerando o seguinte comando:
2 + 2
A resposta ideal é:
4
Google AI Studio
Uma ferramenta do Google que oferece uma interface fácil de usar para testar e criar aplicativos usando os modelos de linguagem grandes do Google. Confira mais detalhes na página inicial do Google AI Studio.
GPT (transformador generativo pré-treinado)
Uma família de modelos de linguagem grandes baseados em Transformer desenvolvida pela OpenAI.
As variantes do GPT podem ser aplicadas a várias modalidades, incluindo:
- geração de imagens (por exemplo, ImageGPT)
- geração de texto para imagem (por exemplo, DALL-E).
gradiente
O vetor de derivadas parciais em relação a todas as variáveis independentes. Em machine learning, o gradiente é o vetor de derivadas parciais da função do modelo. O gradiente aponta na direção da maior inclinação.
acumulação de gradiente
Uma técnica de backpropagation que atualiza os parâmetros apenas uma vez por época, em vez de uma vez por iteração. Depois de processar cada minilote, o acúmulo de gradientes simplesmente atualiza um total contínuo de gradientes. Depois de processar o último minilote na época, o sistema atualiza os parâmetros com base no total de todas as mudanças de gradiente.
O acúmulo de gradientes é útil quando o tamanho do lote é muito grande em comparação com a quantidade de memória disponível para treinamento. Quando a memória é um problema, a tendência natural é reduzir o tamanho do lote. No entanto, reduzir o tamanho do lote na retropropagação normal aumenta o número de atualizações de parâmetros. O acúmulo de gradientes permite que o modelo evite problemas de memória e ainda seja treinado de maneira eficiente.
árvores de decisão com aumento de gradiente (GBT)
Um tipo de floresta de decisão em que:
- O treinamento usa o boost de gradiente.
- O modelo fraco é uma árvore de decisão.
Consulte Árvores de decisão com aumento de gradiente no curso sobre florestas de decisão para mais informações.
aumento de gradiente
Um algoritmo de treinamento em que modelos fracos são treinados para melhorar iterativamente a qualidade (reduzir a perda) de um modelo forte. Por exemplo, um modelo fraco pode ser linear ou uma pequena árvore de decisões. O modelo forte se torna a soma de todos os modelos fracos treinados anteriormente.
Na forma mais simples de otimização de gradiente, a cada iteração, um modelo fraco é treinado para prever o gradiente de perda do modelo forte. Em seguida, a saída do modelo forte é atualizada subtraindo o gradiente previsto, semelhante ao descida do gradiente.
em que:
- $F_{0}$ é o modelo de início forte.
- $F_{i+1}$ é o próximo modelo forte.
- $F_{i}$ é o modelo forte atual.
- $\xi$ é um valor entre 0,0 e 1,0 chamado de contração, que é análogo à taxa de aprendizado no gradiente descendente.
- $f_{i}$ é o modelo fraco treinado para prever o gradiente de perda de $F_{i}$.
As variações modernas do gradient boosting também incluem a segunda derivada (Hessiana) da perda no cálculo.
As árvores de decisão são usadas com frequência como modelos fracos no aumento de gradiente. Consulte árvores de decisão aprimoradas por gradiente.
truncamento de gradiente
Um mecanismo usado com frequência para reduzir o problema de gradiente explosivo, limitando (cortando) artificialmente o valor máximo dos gradientes ao usar o gradiente descendente para treinar um modelo.
gradiente descendente
Uma técnica matemática para minimizar a perda. O gradiente descendente ajusta iterativamente pesos e tendências, encontrando gradualmente a melhor combinação para minimizar a perda.
A descida do gradiente é muito mais antiga que o machine learning.
Consulte Regressão linear: gradiente descendente no Curso intensivo de machine learning para mais informações.
gráfico
No TensorFlow, uma especificação de computação. Os nós no gráfico representam operações. As arestas são direcionadas e representam a transmissão do resultado de uma operação (um Tensor) como um operando para outra operação. Use o TensorBoard para visualizar um gráfico.
execução de grafo
Um ambiente de programação do TensorFlow em que o programa primeiro cria um gráfico e depois executa todo ou parte dele. A execução de grafo é o modo de execução padrão no TensorFlow 1.x.
Contraste com a execução imediata.
política gananciosa
No aprendizado por reforço, uma política que sempre escolhe a ação com o maior retorno esperado.
Embasamento
Uma propriedade de um modelo cuja saída é baseada (ou "fundamentada") em material de origem específico. Por exemplo, imagine que você forneça um livro didático inteiro de física como entrada ("contexto") para um modelo de linguagem grande. Em seguida, você envia uma pergunta de física para esse modelo de linguagem grande. Se a resposta do modelo refletir informações desse livro didático, ele será embasado nele.Um modelo embasado nem sempre é factual. Por exemplo, o livro didático de física pode conter erros.
informações empíricas
Realidade.
O que realmente aconteceu.
Por exemplo, considere um modelo de classificação binária que prevê se um estudante do primeiro ano da universidade vai se formar em até seis anos. A verdade fundamental para esse modelo é se o estudante se formou ou não em seis anos.
viés de atribuição a grupos
A suposição de que o que é verdade para um indivíduo também é verdade para todos no grupo. Os efeitos do viés de atribuição de grupo podem ser exacerbados se uma amostragem por conveniência for usada para a coleta de dados. Em uma amostra não representativa, as atribuições podem não refletir a realidade.
Consulte também viés de homogeneidade externa ao grupo e viés de grupo. Consulte também Imparcialidade: tipos de viés no Curso intensivo de machine learning para mais informações.
H
alucinação
A produção de resultados aparentemente plausíveis, mas factualmente incorretos, por um modelo de IA generativa que pretende fazer uma declaração sobre o mundo real. Por exemplo, um modelo de IA generativa que afirma que Barack Obama morreu em 1865 está alucinando.
hash
Em machine learning, um mecanismo para criar grupos de dados categóricos, principalmente quando o número de categorias é grande, mas o número de categorias que aparecem no conjunto de dados é comparativamente pequeno.
Por exemplo, a Terra tem cerca de 73 mil espécies de árvores. Você pode representar cada uma das 73.000 espécies de árvores em 73.000 intervalos categóricos separados. Como alternativa, se apenas 200 dessas espécies de árvores aparecerem em um conjunto de dados, use o hash para dividir as espécies em talvez 500 buckets.
Um único bucket pode conter várias espécies de árvores. Por exemplo, o hash pode colocar baobá e bordo-vermelho, duas espécies geneticamente diferentes, no mesmo bucket. De qualquer forma, o hash ainda é uma boa maneira de mapear grandes conjuntos categóricos no número selecionado de agrupamentos. O hash transforma um atributo categórico com um grande número de valores possíveis em um número muito menor de valores, agrupando-os de maneira determinista.
Consulte Dados categóricos: vocabulário e codificação one-hot no Curso intensivo de machine learning para mais informações.
heurística
Uma solução simples e rápida para um problema. Por exemplo, "Com uma heurística, alcançamos 86% de acurácia. Quando mudamos para uma rede neural profunda, a acurácia aumentou para 98%".
camada oculta
Uma camada em uma rede neural entre a camada de entrada (os recursos) e a camada de saída (a previsão). Cada camada oculta consiste em um ou mais neurônios. Por exemplo, a rede neural a seguir contém duas camadas ocultas, a primeira com três neurônios e a segunda com dois:
Uma rede neural profunda contém mais de uma camada oculta. Por exemplo, a ilustração anterior é uma rede neural profunda porque o modelo contém duas camadas ocultas.
Consulte Redes neurais: nós e camadas ocultas no Curso intensivo de machine learning para mais informações.
clustering hierárquico
Uma categoria de algoritmos de clustering que criam uma árvore de clusters. O clustering hierárquico é adequado para dados hierárquicos, como taxonomias botânicas. Há dois tipos de algoritmos de agrupamento hierárquico:
- O clustering aglomerativo primeiro atribui cada exemplo ao próprio cluster e mescla de forma iterativa os clusters mais próximos para criar uma árvore hierárquica.
- O clustering divisivo primeiro agrupa todos os exemplos em um cluster e depois divide iterativamente o cluster em uma árvore hierárquica.
Contraste com o agrupamento com base em centroide.
Consulte Algoritmos de clustering no curso de clustering para mais informações.
subida de colina
Um algoritmo para melhorar iterativamente ("subir uma colina") um modelo de ML até que ele pare de melhorar ("chegue ao topo de uma colina"). A forma geral do algoritmo é a seguinte:
- Crie um modelo inicial.
- Crie novos modelos candidatos fazendo pequenos ajustes na forma como você treina ou ajusta. Isso pode envolver trabalhar com um conjunto de treinamento ligeiramente diferente ou hiperparâmetros diferentes.
- Avalie os novos modelos candidatos e realize uma das seguintes ações:
- Se um modelo candidato tiver uma performance melhor que o modelo inicial, ele se tornará o novo modelo inicial. Nesse caso, repita as etapas 1, 2 e 3.
- Se nenhum modelo superar o inicial, você terá atingido o topo da colina e deverá parar de iterar.
Consulte o Playbook de ajuste de aprendizado profundo para orientações sobre o ajuste de hiperparâmetros. Consulte os módulos de dados do Curso intensivo de machine learning para orientações sobre engenharia de atributos.
perda de articulação
Uma família de funções de perda para classificação projetada para encontrar a fronteira de decisão o mais distante possível de cada exemplo de treinamento, maximizando assim a margem entre exemplos e a fronteira. KSVMs usam perda de dobradiça (ou uma função relacionada, como perda de dobradiça ao quadrado). Para classificação binária, a função de perda de dobradiça é definida da seguinte forma:
em que y é o rótulo verdadeiro, -1 ou +1, e y' é a saída bruta do modelo de classificação:
Consequentemente, um gráfico da perda de dobradiça versus (y * y') tem esta aparência:

viés histórico
Um tipo de viés que já existe no mundo e foi incorporado a um conjunto de dados. Esses vieses tendem a refletir estereótipos culturais, desigualdades demográficas e preconceitos contra determinados grupos sociais.
Por exemplo, considere um modelo de classificação que prevê se um solicitante de empréstimo vai deixar de pagar ou não. Esse modelo foi treinado com dados históricos de inadimplência de empréstimos dos anos 1980 de bancos locais em duas comunidades diferentes. Se os candidatos da Comunidade A tinham seis vezes mais chances de inadimplência do que os da Comunidade B, o modelo pode aprender um viés histórico que resulta em menos aprovações de empréstimos na Comunidade A, mesmo que as condições históricas que resultaram nas taxas de inadimplência mais altas dessa comunidade não sejam mais relevantes.
Consulte Imparcialidade: tipos de viés no Curso intensivo de machine learning para mais informações.
dados de validação
Exemplos intencionalmente não usados ("retidos") durante o treinamento. O conjunto de dados de validação e o conjunto de dados de teste são exemplos de dados de espera. Os dados de validação ajudam a avaliar a capacidade do modelo de generalizar para dados diferentes daqueles usados no treinamento. A perda no conjunto de validação fornece uma estimativa melhor da perda em um conjunto de dados não visto do que a perda no conjunto de treinamento.
host
Ao treinar um modelo de ML em chips aceleradores (GPUs ou TPUs), a parte do sistema que controla o seguinte:
- O fluxo geral do código.
- A extração e transformação do pipeline de entrada.
O host geralmente é executado em uma CPU, não em um chip acelerador. O dispositivo manipula tensores nos chips aceleradores.
avaliação humana
Um processo em que pessoas avaliam a qualidade da saída de um modelo de ML. Por exemplo, pessoas bilíngues avaliam a qualidade de um modelo de tradução de ML. A avaliação humana é especialmente útil para julgar modelos que não têm uma resposta certa.
Contraste com a avaliação automática e a avaliação do autorrater.
human in the loop (HITL)
Uma expressão mal definida que pode significar uma das seguintes opções:
- Uma política de analisar a saída da IA generativa de forma crítica ou cética.
- Uma estratégia ou um sistema para garantir que as pessoas ajudem a moldar, avaliar e refinar o comportamento de um modelo. Manter um humano no processo permite que uma IA se beneficie da inteligência humana e de máquina. Por exemplo, um sistema em que uma IA gera código que engenheiros de software revisam é um sistema humano no loop.
hiperparâmetro
As variáveis que você ou um serviço de ajuste de hiperparâmetros ajustam durante execuções sucessivas de treinamento de um modelo. Por exemplo, a taxa de aprendizado é um hiperparâmetro. Você pode definir a taxa de aprendizado como 0,01 antes de uma sessão de treinamento. Se você determinar que 0,01 é muito alto, talvez defina a taxa de aprendizado como 0,003 para a próxima sessão de treinamento.
Já os parâmetros são os vários pesos e vieses que o modelo aprende durante o treinamento.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
hiperplano
Um limite que separa um espaço em dois subespaços. Por exemplo, uma linha é um hiperplano em duas dimensões, e um plano é um hiperplano em três dimensões. Em machine learning, um hiperplano é o limite que separa um espaço de alta dimensão. Máquinas de vetores de suporte baseadas em kernels usam hiperplanos para separar classes positivas de negativas, geralmente em um espaço de alta dimensão.
I
i.i.d.
Abreviação de independente e identicamente distribuído.
Reconhecimento de imagem
Um processo que classifica objetos, padrões ou conceitos em uma imagem. O reconhecimento de imagem também é conhecido como classificação de imagem.
conjunto de dados desequilibrado
Sinônimo de conjunto de dados não balanceado.
viés implícito
Fazer uma associação ou suposição automaticamente com base nos modelos mentais e nas memórias. O viés implícito pode afetar o seguinte:
- Como os dados são coletados e classificados.
- Como os sistemas de machine learning são projetados e desenvolvidos.
Por exemplo, ao criar um modelo de classificação para identificar fotos de casamento, um engenheiro pode usar a presença de um vestido branco em uma foto como um recurso. No entanto, vestidos brancos foram usados apenas durante certas épocas e em algumas culturas.
Consulte também viés de confirmação.
imputação
Forma abreviada de imputação de valores.
incompatibilidade das métricas de imparcialidade
A ideia de que algumas noções de justiça são mutuamente incompatíveis e não podem ser atendidas simultaneamente. Por isso, não há uma única métrica universal para quantificar a imparcialidade que possa ser aplicada a todos os problemas de ML.
Embora isso possa parecer desencorajador, a incompatibilidade das métricas de imparcialidade não significa que os esforços de imparcialidade são inúteis. Em vez disso, ela sugere que a imparcialidade seja definida dentro do contexto de um determinado problema de ML, com o objetivo de evitar danos específicos aos casos de uso.
Consulte "On the (im)possibility of fairness" (em inglês) para uma discussão mais detalhada sobre a incompatibilidade das métricas de imparcialidade.
aprendizado contextual
Sinônimo de comando de poucos disparos (few-shot).
independente e identicamente distribuído (i.i.d)
Dados extraídos de uma distribuição que não muda e em que cada valor extraído não depende de valores extraídos anteriormente. Uma variável i.i.d. é o gás ideal do aprendizado de máquina: uma construção matemática útil, mas quase nunca encontrada exatamente no mundo real. Por exemplo, a distribuição de visitantes em uma página da Web pode ser i.i.d. em um breve período. Ou seja, a distribuição não muda durante esse período, e a visita de uma pessoa é geralmente independente da visita de outra. No entanto, se você aumentar esse período, poderão aparecer diferenças sazonais nos visitantes da página da Web.
Consulte também não estacionariedade.
justiça individual
Uma métrica de justiça que verifica se indivíduos semelhantes são classificados de maneira semelhante. Por exemplo, a Academia Brobdingnagian pode querer satisfazer a justiça individual garantindo que dois estudantes com notas idênticas e pontuações de testes padronizados tenham a mesma probabilidade de serem aceitos.
A imparcialidade individual depende totalmente de como você define "similaridade" (neste caso, notas e resultados de testes). Você pode correr o risco de introduzir novos problemas de imparcialidade se sua métrica de similaridade não considerar informações importantes, como o rigor do currículo de um estudante.
Consulte "Fairness Through Awareness" (em inglês) para uma discussão mais detalhada sobre a justiça individual.
inferência
No machine learning tradicional, o processo de fazer previsões aplicando um modelo treinado a exemplos sem rótulo. Consulte Aprendizado supervisionado no curso "Introdução ao aprendizado de máquina" para saber mais.
Em modelos de linguagem grande, a inferência é o processo de usar um modelo treinado para gerar uma resposta a um comando.
A inferência tem um significado um pouco diferente em estatística. Consulte o artigo da Wikipédia sobre inferência estatística para mais detalhes.
caminho de inferência
Em uma árvore de decisão, durante a inferência, o caminho que um exemplo específico faz da raiz até outras condições, terminando com uma folha. Por exemplo, na árvore de decisões a seguir, as setas mais grossas mostram o caminho de inferência para um exemplo com os seguintes valores de recursos:
- x = 7
- y = 12
- z = -3
O caminho de inferência na ilustração a seguir passa por três condições antes de chegar à folha (Zeta).

As três setas grossas mostram o caminho de inferência.
Consulte Árvores de decisão no curso "Florestas de decisão" para mais informações.
ganho de informação
Em florestas de decisão, a diferença entre a entropia de um nó e a soma ponderada (pelo número de exemplos) da entropia dos nós filhos. A entropia de um nó é a entropia dos exemplos nesse nó.
Por exemplo, considere os seguintes valores de entropia:
- entropia do nó pai = 0,6
- entropia de um nó filho com 16 exemplos relevantes = 0,2
- entropia de outro nó filho com 24 exemplos relevantes = 0,1
Portanto, 40% dos exemplos estão em um nó filho e 60% estão no outro. Assim:
- Soma ponderada da entropia dos nós filhos = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Portanto, o ganho de informação é:
- Ganho de informação = entropia do nó pai - soma ponderada da entropia dos nós filhos
- ganho de informação = 0,6 - 0,14 = 0,46
A maioria dos divisores tenta criar condições que maximizam o ganho de informações.
viés de grupo
Mostrar parcialidade em relação ao próprio grupo ou às próprias características. Se os testadores ou avaliadores forem amigos, familiares ou colegas do desenvolvedor de machine learning, o viés intragrupo poderá invalidar o teste do produto ou o conjunto de dados.
O viés de grupo é uma forma de viés de atribuição a grupos. Consulte também o viés de homogeneidade externa ao grupo.
Consulte Imparcialidade: tipos de viés no Curso intensivo de machine learning para mais informações.
gerador de entradas
Um mecanismo pelo qual os dados são carregados em uma rede neural.
Um gerador de entrada pode ser considerado um componente responsável por processar dados brutos em tensores, que são iterados para gerar lotes para treinamento, avaliação e inferência.
camada de entrada
A camada de uma rede neural que contém o vetor de atributos. Ou seja, a camada de entrada fornece exemplos para treinamento ou inferência. Por exemplo, a camada de entrada na rede neural a seguir consiste em dois recursos:
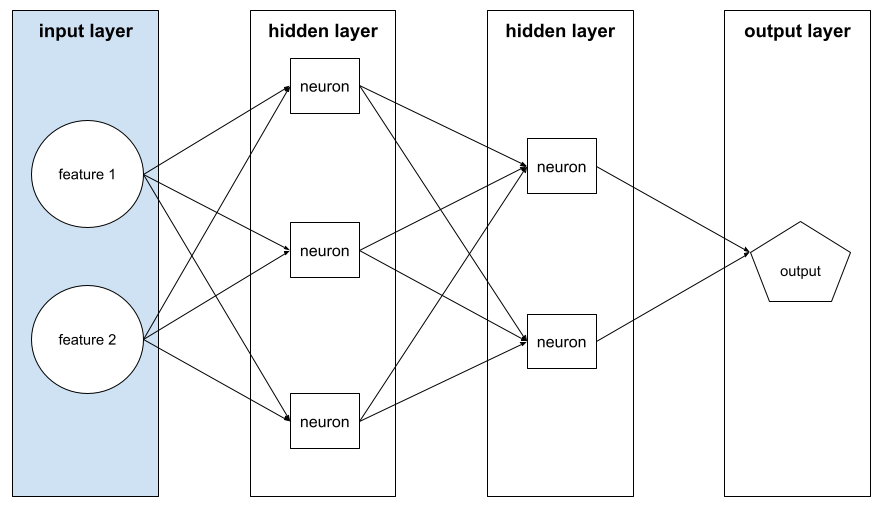
condição no conjunto
Em uma árvore de decisão, uma condição que testa a presença de um item em um conjunto de itens. Por exemplo, esta é uma condição de conjunto:
house-style in [tudor, colonial, cape]
Durante a inferência, se o valor do recurso de estilo de casa for tudor, colonial ou cape, essa condição será avaliada como "Sim". Se o valor do recurso de estilo da casa for algo diferente (por exemplo, ranch), essa condição será avaliada como "Não".
As condições no conjunto geralmente levam a árvores de decisão mais eficientes do que as condições que testam recursos codificados com one-hot.
instância
Sinônimo de example.
ajuste de instruções
Uma forma de ajuste refinado que melhora a capacidade de um modelo de IA generativa de seguir instruções. O ajuste de instruções envolve treinar um modelo em uma série de comandos de instrução, geralmente abrangendo uma ampla variedade de tarefas. O modelo ajustado com instruções resultante tende a gerar respostas úteis para comandos zero-shot em várias tarefas.
Comparar e contrastar com:
interpretabilidade
A capacidade de explicar ou apresentar o raciocínio de um modelo de ML em termos compreensíveis para as pessoas.
A maioria dos modelos de regressão linear, por exemplo, é altamente interpretável. Basta observar os pesos treinados para cada recurso. As florestas de decisão também são altamente interpretáveis. Porém, alguns modelos precisam de uma visualização sofisticada para se tornarem interpretáveis.
Você pode usar a Ferramenta de aprendizado de interpretabilidade (LIT) para interpretar modelos de ML.
concordância entre avaliadores
Uma medida da frequência com que os avaliadores humanos concordam ao realizar uma tarefa. Se os avaliadores discordarem, talvez seja necessário melhorar as instruções da tarefa. Também chamado de concordância entre rotuladores ou confiabilidade entre avaliadores. Consulte também Kappa de Cohen, uma das medidas de concordância entre avaliadores mais usadas.
Consulte Dados categóricos: problemas comuns no Curso intensivo de machine learning para mais informações.
intersecção sobre união (IoU)
A interseção de dois conjuntos dividida pela união deles. Em tarefas de detecção de imagens de machine learning, o IoU é usado para medir a precisão da caixa delimitadora prevista pelo modelo em relação à caixa delimitadora de informações empíricas. Nesse caso, a IoU das duas caixas é a proporção entre a área de sobreposição e a área total. O valor varia de 0 (nenhuma sobreposição entre a caixa delimitadora prevista e a caixa delimitadora de informações empíricas) a 1 (a caixa delimitadora prevista e a caixa delimitadora de informações empíricas têm exatamente as mesmas coordenadas).
Por exemplo, na imagem abaixo:
- A caixa delimitadora prevista (as coordenadas que delimitam onde o modelo prevê que a mesa de cabeceira está localizada na pintura) é destacada em roxo.
- A caixa delimitadora de evidência empírica (as coordenadas que delimitam onde a mesa de cabeceira na pintura está localizada) é destacada em verde.
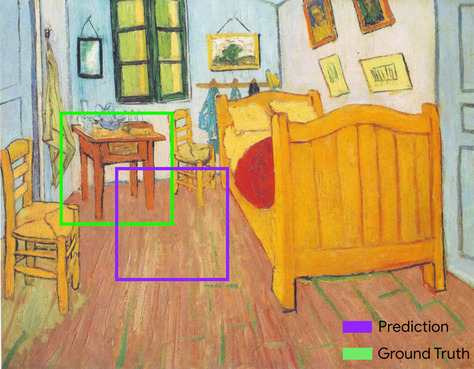
Aqui, a interseção das caixas delimitadoras para previsão e informações empíricas (abaixo à esquerda) é 1, e a união das caixas delimitadoras para previsão e informações empíricas (abaixo à direita) é 7. Portanto, o IoU é \(\frac{1}{7}\).
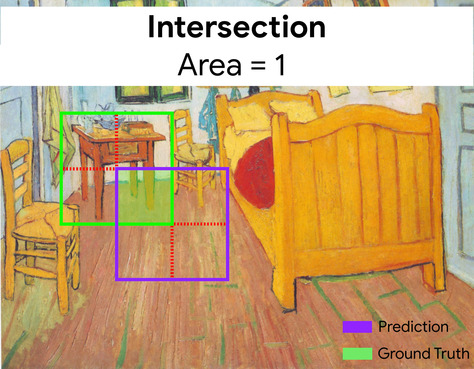
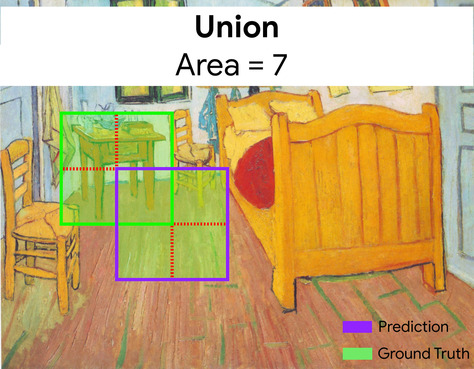
IoU
Abreviação de intersecção sobre união.
matriz de itens
Em sistemas de recomendação, uma matriz de vetores de incorporação gerada por fatoração de matrizes que contém sinais latentes sobre cada item. Cada linha da matriz de itens contém o valor de uma única característica latente para todos os itens. Por exemplo, considere um sistema de recomendação de filmes. Cada coluna na matriz de itens representa um único filme. Os indicadores latentes podem representar gêneros ou ser mais difíceis de interpretar, envolvendo interações complexas entre gênero, estrelas, idade do filme ou outros fatores.
A matriz de itens tem o mesmo número de colunas que a matriz de destino que está sendo fatorada. Por exemplo, em um sistema de recomendação de filmes que avalia 10.000 títulos, a matriz de itens terá 10.000 colunas.
itens
Em um sistema de recomendação, as entidades que um sistema recomenda. Por exemplo, vídeos são os itens que uma locadora recomenda, enquanto livros são os itens que uma livraria recomenda.
iteração
Uma única atualização dos parâmetros de um modelo (os pesos e vieses) durante o treinamento. O tamanho do lote determina quantos exemplos o modelo processa em uma única iteração. Por exemplo, se o tamanho do lote for 20, o modelo vai processar 20 exemplos antes de ajustar os parâmetros.
Ao treinar uma rede neural, uma única iteração envolve as duas transmissões a seguir:
- Uma transmissão direta para avaliar a perda em um único lote.
- Uma transmissão de volta (backpropagation) para ajustar os parâmetros do modelo com base na perda e na taxa de aprendizado.
Consulte Descida de gradiente no Curso intensivo de machine learning para mais informações.
J
JAX
Uma biblioteca de computação de matrizes que reúne XLA (álgebra linear acelerada) e diferenciação automática para computação numérica de alta performance. O JAX oferece uma API simples e eficiente para escrever código numérico acelerado com transformações combináveis. O JAX oferece recursos como:
grad(diferenciação automática)jit(compilação just-in-time)vmap(vetorização ou agrupamento em lote automático)pmap(paralelização)
O JAX é uma linguagem para expressar e compor transformações de código numérico, análoga, mas muito maior em escopo, à biblioteca NumPy do Python. Na verdade, a biblioteca .numpy no JAX é uma versão funcionalmente equivalente, mas totalmente reescrita da biblioteca NumPy do Python.
O JAX é especialmente adequado para acelerar muitas tarefas de machine learning transformando os modelos e dados em uma forma adequada para paralelismo em GPUs e TPUs (links em inglês).
Flax, Optax, Pax e muitas outras bibliotecas são criadas na infraestrutura JAX.
K
Keras
Uma API Python de machine learning muito usada. O Keras é executado em vários frameworks de aprendizado profundo, incluindo o TensorFlow, em que está disponível como tf.keras.
Máquinas de vetores de suporte baseadas em kernels (KSVMs)
Um algoritmo de classificação que busca maximizar a margem entre classes positivas e negativas mapeando vetores de dados de entrada para um espaço de maior dimensão. Por exemplo, considere um problema de classificação em que o conjunto de dados de entrada tem 100 recursos. Para maximizar a margem entre classes positivas e negativas, um KSVM pode mapear internamente esses recursos em um espaço de um milhão de dimensões. Os KSVMs usam uma função de perda chamada perda de dobradiça.
keypoints
As coordenadas de recursos específicos em uma imagem. Por exemplo, em um modelo de reconhecimento de imagens que distingue espécies de flores, os pontos principais podem ser o centro de cada pétala, o caule, o estame e assim por diante.
Validação cruzada k-fold
Um algoritmo para prever a capacidade de um modelo de generalizar para novos dados. O k em k-fold se refere ao número de grupos iguais em que você divide os exemplos de um conjunto de dados. Ou seja, você treina e testa seu modelo k vezes. Para cada rodada de treinamento e teste, um grupo diferente é o conjunto de teste, e todos os grupos restantes se tornam o conjunto de treinamento. Depois de k rodadas de treinamento e teste, calcule a média e o desvio padrão das métricas de teste escolhidas.
Por exemplo, suponha que seu conjunto de dados tenha 120 exemplos. Suponha que você decida definir k como 4. Portanto, depois de misturar os exemplos, divida o conjunto de dados em quatro grupos iguais de 30 exemplos e faça quatro rodadas de treinamento e teste:
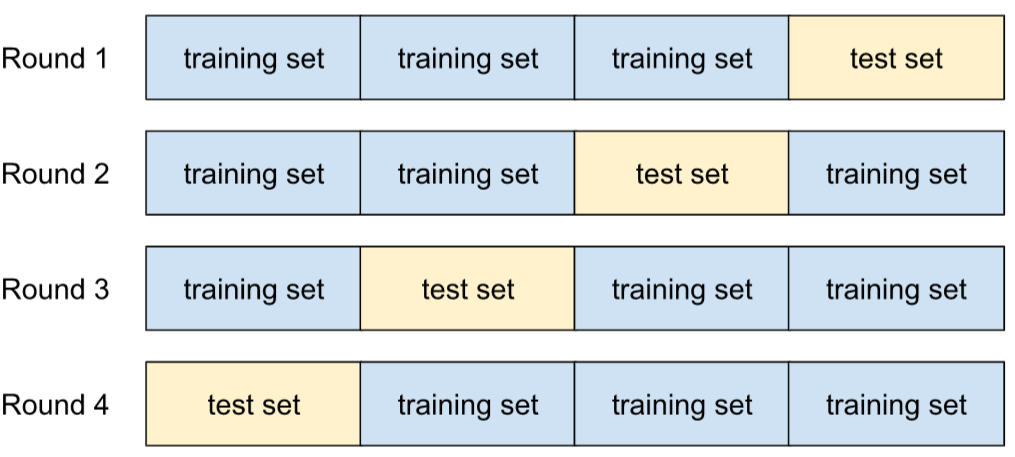
Por exemplo, o erro quadrático médio (EQM) pode ser a métrica mais significativa para um modelo de regressão linear. Portanto, você encontraria a média e o desvio padrão do EQM em todas as quatro rodadas.
k-means
Um algoritmo de clustering conhecido que agrupa exemplos no aprendizado não supervisionado. O algoritmo k-means faz o seguinte:
- Determina de forma iterativa os melhores pontos centrais k (conhecidos como centróides).
- Atribui cada exemplo ao centroide mais próximo. Os exemplos mais próximos do mesmo centroide pertencem ao mesmo grupo.
O algoritmo k-means escolhe locais de centroide para minimizar o quadrado cumulativo das distâncias de cada exemplo ao centroide mais próximo.
Por exemplo, considere o seguinte gráfico de altura x largura de cachorros:

Se k=3, o algoritmo k-means vai determinar três centroides. Cada exemplo é atribuído ao centroide mais próximo, resultando em três grupos:

Imagine que um fabricante quer determinar os tamanhos ideais para suéteres pequenos, médios e grandes para cachorros. Os três centroides identificam a altura e a largura médias de cada cachorro no cluster. Portanto, o fabricante provavelmente vai basear os tamanhos de suéter nesses três centroides. O centroide de um cluster geralmente não é um exemplo no cluster.
As ilustrações anteriores mostram o k-means para exemplos com apenas dois recursos (altura e largura). O k-means pode agrupar exemplos em vários recursos.
Consulte O que é cluster K-means? no curso de clustering para mais informações.
k-median
Um algoritmo de clustering intimamente relacionado ao k-means. A diferença prática entre os dois é a seguinte:
- No k-means, os centroides são determinados minimizando a soma dos quadrados da distância entre um candidato a centroide e cada um dos exemplos dele.
- No k-median, os centroides são determinados minimizando a soma da distância entre um candidato a centroide e cada um dos exemplos dele.
As definições de distância também são diferentes:
- O k-means depende da distância euclidiana do centróide a um exemplo. Em duas dimensões, a distância euclidiana significa usar o teorema de Pitágoras para calcular a hipotenusa. Por exemplo, a distância k-means entre (2,2) e (5,-2) seria:
- O k-mediana usa a distância de Manhattan do centróide até um exemplo. Essa distância é a soma dos deltas absolutos em cada dimensão. Por exemplo, a distância k-mediana entre (2,2) e (5,-2) seria:
L
Regularização L0
Um tipo de regularização que penaliza o número total de ponderações diferentes de zero em um modelo. Por exemplo, um modelo com 11 pesos diferentes de zero seria mais penalizado do que um modelo semelhante com 10 pesos diferentes de zero.
A regularização L0 às vezes é chamada de regularização da norma L0.
Perda L1
Uma função de perda que calcula o valor absoluto da diferença entre os valores reais de rótulo e os valores previstos por um modelo. Por exemplo, este é o cálculo da perda L1 para um lote de cinco exemplos:
| Valor real do exemplo | Valor previsto do modelo | Valor absoluto de delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = perda L1 | ||
A perda L1 é menos sensível a outliers do que a perda L2.
O erro médio absoluto é a perda média L1 por exemplo.
Consulte Regressão linear: perda no Curso intensivo de machine learning para mais informações.
Regularização L1
Um tipo de regularização que penaliza ponderações na proporção à soma do valor absoluto das ponderações. A regularização L1 ajuda a levar os pesos de atributos irrelevantes ou pouco relevantes a exatamente 0. Um atributo com um peso de 0 é removido do modelo.
Contraste com a regularização L2.
Perda L2
Uma função de perda que calcula o quadrado da diferença entre os valores reais de rótulo e os valores previstos por um modelo. Por exemplo, este é o cálculo da perda L2 para um lote de cinco exemplos:
| Valor real do exemplo | Valor previsto do modelo | Quadrado de delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = perda L2 | ||
Devido ao uso de quadrados, a perda L2 aumenta a influência de outliers. Ou seja, a perda L2 reage mais fortemente a previsões ruins do que a perda L1. Por exemplo, a perda L1 para o lote anterior seria 8 em vez de 16. Uma única conta atípica representa 9 das 16.
Modelos de regressão geralmente usam a perda L2 como função de perda.
O erro quadrático médio é a perda média de L2 por exemplo. Perda quadrática é outro nome para perda L2.
Consulte Regressão logística: perda e regularização no Curso intensivo de machine learning para mais informações.
Regularização L2
Um tipo de regularização que penaliza ponderações na proporção à soma dos quadrados das ponderações. A regularização L2 ajuda a aproximar de zero os pesos outliers (aqueles com valores positivos altos ou negativos baixos), mas não exatamente zero. Os recursos com valores muito próximos de 0 permanecem no modelo, mas não influenciam muito a previsão dele.
A regularização L2 sempre melhora a generalização em modelos lineares.
Contraste com a regularização L1.
Consulte Overfitting: regularização L2 no Curso intensivo de machine learning para mais informações.
o rótulo.
Em aprendizado supervisionado de máquina, a parte "resposta" ou "resultado" de um exemplo.
Cada exemplo rotulado consiste em um ou mais atributos e um rótulo. Por exemplo, em um conjunto de dados de detecção de spam, o rótulo provavelmente seria "spam" ou "não é spam". Em um conjunto de dados de precipitação, o rótulo pode ser a quantidade de chuva que caiu durante um determinado período.
Consulte Aprendizado supervisionado em "Introdução ao machine learning" para mais informações.
exemplo rotulado
Um exemplo que contém um ou mais atributos e um rótulo. Por exemplo, a tabela a seguir mostra três exemplos rotulados de um modelo de avaliação de imóveis, cada um com três recursos e um rótulo:
| Número de quartos | Número de banheiros | Idade da casa | Preço da casa (rótulo) |
|---|---|---|---|
| 3 | 2 | 15 | US$ 345.000 |
| 2 | 1 | 72 | US$ 179.000 |
| 4 | 2 | 34 | US$ 392.000 |
No machine learning supervisionado, os modelos são treinados com exemplos rotulados e fazem previsões com exemplos sem rótulo.
Contraste exemplos rotulados com exemplos não rotulados.
Consulte Aprendizado supervisionado em "Introdução ao machine learning" para mais informações.
vazamento de rótulos
Uma falha no design do modelo em que um recurso é um proxy do rótulo. Por exemplo, considere um modelo de classificação binária que prevê se um cliente em potencial vai comprar um produto específico.
Suponha que um dos atributos do modelo seja um booleano chamado SpokeToCustomerAgent. Suponha também que um agente de atendimento ao cliente só seja atribuído depois que o cliente em potencial compra o produto. Durante o treinamento, o modelo aprende rapidamente a associação entre SpokeToCustomerAgent e o rótulo.
Consulte Como monitorar pipelines no Curso intensivo de machine learning para mais informações.
lambda
Sinônimo de taxa de regularização.
Lambda é um termo sobrecarregado. Aqui, estamos nos concentrando na definição do termo em regularização.
LaMDA (Language Model for Dialogue Applications)
Um modelo de linguagem grande baseado em Transformer desenvolvido pelo Google e treinado em um grande conjunto de dados de diálogo que pode gerar respostas realistas de conversação.
LaMDA: nossa tecnologia de conversação inovadora oferece uma visão geral.
pontos de referência
Sinônimo de keypoints.
modelo de linguagem
Um modelo que estima a probabilidade de um token ou uma sequência de tokens ocorrer em uma sequência mais longa.
Consulte O que é um modelo de linguagem? no Curso intensivo de machine learning para mais informações.
modelo de linguagem grande
No mínimo, um modelo de linguagem com um número muito alto de parâmetros. De maneira mais informal, qualquer modelo de linguagem baseado em Transformer, como o Gemini ou o GPT.
Consulte Modelos de linguagem grandes (LLMs) no Curso intensivo de machine learning para mais informações.
latência
O tempo que um modelo leva para processar a entrada e gerar uma resposta. Uma resposta de alta latência leva mais tempo para ser gerada do que uma de baixa latência.
Os fatores que influenciam a latência dos modelos de linguagem grandes incluem:
- Comprimentos de tokens de entrada e saída
- Complexidade do modelo
- A infraestrutura em que o modelo é executado
A otimização para latência é essencial para criar aplicativos responsivos e fáceis de usar.
espaço latente
Sinônimo de espaço de embedding.
layer
Um conjunto de neurônios em uma rede neural. Confira três tipos comuns de camadas:
- A camada de entrada, que fornece valores para todos os recursos.
- Uma ou mais camadas ocultas, que encontram relações não lineares entre os atributos e o rótulo.
- A camada de saída, que fornece a previsão.
Por exemplo, a ilustração a seguir mostra uma rede neural com uma camada de entrada, duas camadas ocultas e uma camada de saída:
No TensorFlow, as camadas também são funções Python que recebem tensores e opções de configuração como entrada e produzem outros tensores como saída.
API Layers (tf.layers)
Uma API do TensorFlow para criar uma rede neural profunda como uma composição de camadas. Com a API Layers, é possível criar diferentes tipos de camadas, como:
tf.layers.Densepara uma camada totalmente conectada.tf.layers.Conv2Dpara uma camada convolucional.
A API Layers segue as convenções da API de camadas do Keras. Ou seja, além de um prefixo diferente, todas as funções na API Layers têm os mesmos nomes e assinaturas que as equivalentes na API Keras Layers.
folha
Qualquer endpoint em uma árvore de decisão. Ao contrário de uma condição, uma folha não realiza um teste. Em vez disso, uma folha é uma previsão possível. Uma folha também é o nó terminal de um caminho de inferência.
Por exemplo, a árvore de decisão a seguir contém três folhas:
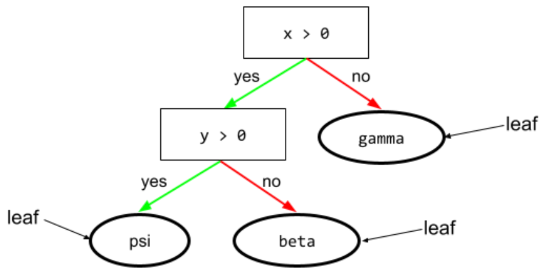
Consulte Árvores de decisão no curso "Florestas de decisão" para mais informações.
Ferramenta de aprendizado de interpretabilidade (LIT)
Uma ferramenta visual e interativa de compreensão de modelos e visualização de dados.
É possível usar o LIT de código aberto para interpretar modelos ou visualizar dados de texto, imagem e tabulares.
taxa de aprendizado
Um número de ponto flutuante que informa ao algoritmo de descida do gradiente a intensidade com que ajustar pesos e vieses em cada iteração. Por exemplo, uma taxa de aprendizado de 0,3 ajustaria os pesos e os vieses três vezes mais do que uma taxa de 0,1.
A taxa de aprendizado é um hiperparâmetro fundamental. Se você definir a taxa de aprendizado muito baixa, o treinamento vai levar muito tempo. Se você definir uma taxa de aprendizado muito alta, a descida do gradiente terá dificuldade em alcançar a convergência.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
regressão dos mínimos quadrados
Um modelo de regressão linear treinado minimizando a perda L2.
Distância de Levenshtein
Uma métrica de distância de edição que calcula o menor número de operações de exclusão, inserção e substituição necessárias para mudar uma palavra em outra. Por exemplo, a distância de Levenshtein entre as palavras "heart" e "darts" é três porque as três edições a seguir são as mudanças mínimas para transformar uma palavra na outra:
- heart → deart (substitua "h" por "d")
- deart → dart (exclua "e")
- dardo → dardos (inserir "s")
A sequência anterior não é o único caminho de três edições.
linear
Uma relação entre duas ou mais variáveis que pode ser representada apenas por adição e multiplicação.
O gráfico de uma relação linear é uma linha.
Contraste com não linear.
modelo linear
Um modelo que atribui um peso por atributo para fazer previsões. Os modelos lineares também incorporam um vies. Em contraste, a relação entre recursos e previsões em modelos profundos geralmente é não linear.
Os modelos lineares geralmente são mais fáceis de treinar e mais interpretáveis do que os modelos de aprendizado profundo. No entanto, os modelos profundos podem aprender relações complexas entre atributos.
A regressão linear e a regressão logística são dois tipos de modelos lineares.
regressão linear
Um tipo de modelo de machine learning em que as duas condições a seguir são verdadeiras:
- O modelo é linear.
- A previsão é um valor de ponto flutuante. Essa é a parte de regressão da regressão linear.
Compare a regressão linear com a regressão logística. Além disso, compare a regressão de contraste com a classificação.
Consulte Regressão linear no Curso intensivo de machine learning para mais informações.
LIT
Abreviação da Ferramenta de aprendizado de interpretabilidade (LIT), antes conhecida como Ferramenta de interpretação de linguagem.
LLM
Abreviação de modelo de linguagem grande.
Avaliações de LLM
Um conjunto de métricas e comparativos para avaliar a performance de modelos de linguagem grandes (LLMs). Em um nível alto, as avaliações de LLM:
- Ajudar os pesquisadores a identificar áreas em que os LLMs precisam melhorar.
- São úteis para comparar diferentes LLMs e identificar o melhor para uma tarefa específica.
- Ajudar a garantir que os LLMs sejam seguros e éticos para uso.
Consulte Modelos de linguagem grandes (LLMs) no Curso intensivo de machine learning para mais informações.
regressão logística
Um tipo de modelo de regressão que prevê uma probabilidade. Os modelos de regressão logística têm as seguintes características:
- O rótulo é categórico. O termo regressão logística geralmente se refere à regressão logística binária, ou seja, a um modelo que calcula probabilidades para rótulos com dois valores possíveis. Uma variante menos comum, a regressão logística multinomial, calcula probabilidades para rótulos com mais de dois valores possíveis.
- A função de perda durante o treinamento é a perda logarítmica. Várias unidades de perda de entropia podem ser colocadas em paralelo para rótulos com mais de dois valores possíveis.
- O modelo tem uma arquitetura linear, não uma rede neural profunda. No entanto, o restante dessa definição também se aplica a modelos profundos que preveem probabilidades para rótulos categóricos.
Por exemplo, considere um modelo de regressão logística que calcula a probabilidade de um e-mail de entrada ser spam ou não. Durante a inferência, suponha que o modelo preveja 0,72. Portanto, o modelo está estimando:
- Uma chance de 72% de o e-mail ser spam.
- Uma chance de 28% de o e-mail não ser spam.
Um modelo de regressão logística usa a seguinte arquitetura de duas etapas:
- O modelo gera uma previsão bruta (y') aplicando uma função linear de atributos de entrada.
- O modelo usa essa previsão bruta como entrada para uma função sigmoide, que converte a previsão bruta em um valor entre 0 e 1, exclusivo.
Como qualquer modelo de regressão, um modelo de regressão logística prevê um número. No entanto, esse número geralmente faz parte de um modelo de classificação binária da seguinte forma:
- Se o número previsto for maior que o limite de classificação, o modelo de classificação binária vai prever a classe positiva.
- Se o número previsto for menor que o limite de classificação, o modelo de classificação binária vai prever a classe negativa.
Consulte Regressão logística no Curso intensivo de machine learning para mais informações.
logits
O vetor de previsões brutas (não normalizadas) que um modelo de classificação gera, que geralmente é transmitido a uma função de normalização. Se o modelo estiver resolvendo um problema de classificação multiclasse, os logits geralmente se tornam uma entrada para a função softmax. A função softmax gera um vetor de probabilidades (normalizadas) com um valor para cada classe possível.
Log Perda
A função de perda usada na regressão logística binária.
Consulte Regressão logística: perda e regularização no Curso intensivo de machine learning para mais informações.
log-odds
O logaritmo de probabilidades de algum evento.
Memória de curto prazo longa (LSTM)
Um tipo de célula em uma rede neural recorrente (link em inglês) usada para processar sequências de dados em aplicativos como reconhecimento de escrita à mão, tradução automática e legenda de imagens. As LSTMs resolvem o problema do desaparecimento do gradiente que ocorre ao treinar RNNs devido a sequências longas de dados, mantendo o histórico em um estado de memória interna com base em novas entradas e no contexto de células anteriores na RNN.
LoRA
Abreviação de adaptabilidade de baixa classificação.
perda
Durante o treinamento de um modelo supervisionado, uma medida de quanto uma previsão do modelo se distancia do rótulo.
Uma função de perda calcula a perda.
Consulte Regressão linear: perda no Curso intensivo de machine learning para mais informações.
agregador de perda
Um tipo de algoritmo de machine learning que melhora a performance de um modelo combinando as previsões de vários modelos e usando essas previsões para fazer uma única previsão. Como resultado, um agregador de perda pode reduzir a variância das previsões e melhorar a acurácia delas.
curva de perda
Um gráfico da perda como uma função do número de iterações de treinamento. O gráfico a seguir mostra uma curva de perda típica:
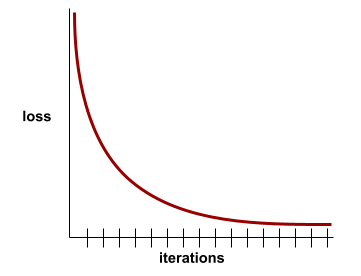
As curvas de perda ajudam a determinar quando o modelo está converging ou overfitting.
As curvas de perda podem representar todos os seguintes tipos de perda:
Consulte também a curva de generalização.
Consulte Overfitting: interpretando curvas de perda no Curso intensivo de machine learning para mais informações.
função de perda
Durante o treinamento ou teste, uma função matemática que calcula a perda em um lote de exemplos. Uma função de perda retorna uma perda menor para modelos que fazem boas previsões do que para modelos que fazem previsões ruins.
O objetivo do treinamento geralmente é minimizar a perda retornada por uma função de perda.
Existem muitos tipos diferentes de funções de perda. Escolha a função de perda adequada para o tipo de modelo que você está criando. Exemplo:
- A perda L2 (ou erro quadrático médio) é a função de perda da regressão linear.
- A perda de registro é a função de perda para regressão logística.
superfície de perda
Um gráfico de peso(s) x perda. O gradiente descendente(link em inglês) visa encontrar as ponderações para as quais a superfície de perda está em um mínimo local.
efeito de perda no meio
A tendência de um LLM de usar informações do início e do fim de uma janela de contexto longa de maneira mais eficaz do que informações do meio. Ou seja, dado um contexto longo, o efeito de perda no meio faz com que a acurácia seja:
- Relativamente alta quando as informações relevantes para formar uma resposta estão perto do início ou do fim do contexto.
- Relativamente baixo quando as informações relevantes para formar uma resposta estão no meio do contexto.
O termo vem de Lost in the Middle: How Language Models Use Long Contexts.
Adaptabilidade de classificação baixa (LoRA)
Uma técnica eficiente em parâmetros para ajuste fino que "congela" os pesos pré-treinados do modelo (para que não possam mais ser modificados) e insere um pequeno conjunto de pesos treináveis no modelo. Esse conjunto de pesos treináveis (também conhecido como "matrizes de atualização") é consideravelmente menor do que o modelo de base e, portanto, é muito mais rápido de treinar.
A LoRA oferece os seguintes benefícios:
- Melhora a qualidade das previsões de um modelo para o domínio em que o ajuste refinado é aplicado.
- Faz ajustes mais rápidos do que técnicas que exigem o ajuste de detalhes de todos os parâmetros de um modelo.
- Reduz o custo computacional da inferência ao permitir a exibição simultânea de vários modelos especializados que compartilham o mesmo modelo de base.
LSTM
Abreviação de Long Short-Term Memory (memória de curto prazo longa).
M
machine learning
Um programa ou sistema que treina um modelo usando dados de entrada. O modelo treinado pode fazer previsões úteis com dados novos (nunca acessados) coletados da mesma distribuição usada para treinamento dele.
O aprendizado de máquina também faz referência ao campo que estuda esses programas ou sistemas.
Consulte o curso Introdução ao machine learning para mais informações.
tradução automática
Usar um software (normalmente, um modelo de machine learning) para converter texto de um idioma humano para outro, por exemplo, do inglês para o japonês.
classe majoritária
O rótulo mais comum em um conjunto de dados não balanceado. Por exemplo, em um conjunto de dados com 99% de rótulos negativos e 1% de rótulos positivos, os rótulos negativos são a classe majoritária.
Contraste com a classe minoritária.
Consulte Conjuntos de dados: conjuntos de dados desequilibrados no Curso intensivo de machine learning para mais informações.
Processo de decisão de Markov (MDP)
Um gráfico que representa o modelo de tomada de decisões em que as decisões (ou ações) são tomadas para navegar por uma sequência de estados, supondo que a propriedade de Markov seja válida. No aprendizado por reforço, essas transições entre estados retornam uma recompensa numérica.
Propriedade de Markov
Uma propriedade de determinados ambientes, em que as transições de estado são totalmente determinadas por informações implícitas no estado atual e na ação do agente.
modelo de linguagem mascarado
Um modelo de linguagem que prevê a probabilidade de tokens candidatos preencherem espaços em branco em uma sequência. Por exemplo, um modelo de linguagem mascarado pode calcular probabilidades para palavras candidatas que substituem o sublinhado na seguinte frase:
O ____ no chapéu voltou.
A literatura geralmente usa a string "MASK" em vez de um sublinhado. Exemplo:
A "MÁSCARA" no chapéu voltou.
A maioria dos modelos de linguagem mascarada modernos são bidirecionais.
math-pass@k
Uma métrica para determinar a precisão de um LLM ao resolver um problema de matemática em K tentativas. Por exemplo, math-pass@2 mede a capacidade de um LLM de resolver problemas de matemática em duas tentativas. Uma acurácia de 0,85 em math-pass@2 indica que um LLM conseguiu resolver problemas matemáticos 85% das vezes em duas tentativas.
math-pass@k é idêntico à métrica pass@k, exceto que o termo math-pass@k é usado especificamente para avaliação de matemática.
matplotlib
Uma biblioteca de plotagem 2D do Python de código aberto. O matplotlib ajuda a visualizar diferentes aspectos do machine learning.
fatoração de matrizes
Na matemática, um mecanismo para encontrar as matrizes cujo produto escalar se aproxima de uma matriz de destino.
Em sistemas de recomendação, a matriz de destino geralmente contém as classificações dos usuários em itens. Por exemplo, a matriz de destino para um sistema de recomendação de filmes pode ser parecida com esta, em que os números inteiros positivos são as classificações dos usuários e 0 significa que o usuário não classificou o filme:
| Casablanca | Aconteceu naquela noite | Pantera Negra | Mulher-Maravilha | Pulp Fiction | |
|---|---|---|---|---|---|
| Usuário 1 | 5.0 | 3.0 | 0,0 | 2,0 | 0,0 |
| Usuário 2 | 4.0 | 0,0 | 0,0 | 1.0 | 5.0 |
| Usuário 3 | 3.0 | 1.0 | 4.0 | 5.0 | 0,0 |
O sistema de recomendação de filmes tem como objetivo prever as classificações dos usuários para filmes não classificados. Por exemplo, o usuário 1 vai gostar de Pantera Negra?
Uma abordagem para sistemas de recomendação é usar a fatoração de matrizes para gerar estas duas matrizes:
- Uma matriz de usuários, com o formato do número de usuários X o número de dimensões de incorporação.
- Uma matriz de itens, com o formato do número de dimensões de embedding X o número de itens.
Por exemplo, usar a fatoração de matrizes nos três usuários e cinco itens pode gerar as seguintes matrizes de usuário e item:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
O produto escalar da matriz de usuários e da matriz de itens gera uma matriz de recomendação que contém não apenas as classificações originais dos usuários, mas também previsões para os filmes que cada usuário não assistiu. Por exemplo, considere a avaliação do usuário 1 de Casablanca, que foi 5,0. O produto escalar correspondente a essa célula na matriz de recomendação deve ser de aproximadamente 5,0, e é:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9E mais importante: o usuário 1 vai gostar de Pantera Negra? O produto escalar correspondente à primeira linha e à terceira coluna gera uma classificação prevista de 4,3:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3A fatoração de matrizes geralmente gera uma matriz de usuários e uma matriz de itens que, juntas, são muito mais compactas do que a matriz de destino.
MBPP
Abreviação de Mostly Basic Python Problems.
Erro médio absoluto (MAE)
A perda média por exemplo quando a perda L1 é usada. Calcule o erro médio absoluto da seguinte forma:
- Calcula a perda L1 para um lote.
- Divida a perda L1 pelo número de exemplos no lote.
Por exemplo, considere o cálculo da perda L1 no seguinte lote de cinco exemplos:
| Valor real do exemplo | Valor previsto do modelo | Perda (diferença entre o valor real e o previsto) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = perda L1 | ||
Portanto, a perda L1 é 8 e o número de exemplos é 5. Portanto, o erro absoluto médio é:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Compare o erro médio absoluto com o erro quadrático médio e a raiz do erro quadrático médio.
Precisão média em k (mAP@k)
A média estatística de todas as pontuações de precisão média em k em um conjunto de dados de validação. Um uso da precisão média em k é julgar a qualidade das recomendações geradas por um sistema de recomendação.
Embora a frase "média média" pareça redundante, o nome da métrica é adequado. Afinal, essa métrica encontra a média de vários valores de precisão média em k.
Erro quadrático médio (EQM)
A perda média por exemplo quando a perda L2 é usada. Calcule o erro quadrático médio da seguinte forma:
- Calcula a perda L2 de um lote.
- Divida a perda L2 pelo número de exemplos no lote.
Por exemplo, considere a perda no seguinte lote de cinco exemplos:
| Valor real | Previsão do modelo | Perda | Perda quadrática |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = perda L2 | |||
Portanto, o erro quadrático médio é:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
O erro quadrático médio é um otimizador de treinamento popular, principalmente para regressão linear.
Contraste o erro quadrático médio com o erro médio absoluto e a raiz do erro quadrático médio.
O TensorFlow Playground usa o erro quadrático médio para calcular os valores de perda.
malha
Na programação paralela de ML, um termo associado à atribuição dos dados e do modelo aos chips de TPU e à definição de como esses valores serão fragmentados ou replicados.
Mesh é um termo sobrecarregado que pode significar qualquer uma das seguintes opções:
- Um layout físico dos chips de TPU.
- Uma construção lógica abstrata para mapear os dados e o modelo para os chips de TPU.
Em qualquer caso, uma malha é especificada como uma forma.
meta-aprendizagem
Um subconjunto do aprendizado de máquina que descobre ou melhora um algoritmo de aprendizado. Um sistema de meta-aprendizagem também pode treinar um modelo para aprender rapidamente uma nova tarefa com uma pequena quantidade de dados ou com a experiência adquirida em tarefas anteriores. Os algoritmos de meta-aprendizagem geralmente tentam alcançar o seguinte:
- Melhorar ou aprender recursos projetados manualmente, como um inicializador ou um otimizador.
- Ser mais eficiente em termos de dados e computação.
- Melhorar a generalização.
A meta-aprendizagem está relacionada ao aprendizado few-shot.
métrica
Uma estatística importante para você.
Um objetivo é uma métrica que um sistema de machine learning tenta otimizar.
API Metrics (tf.metrics)
Uma API do TensorFlow para avaliar modelos. Por exemplo, tf.metrics.accuracy determina a frequência com que as previsões de um modelo correspondem aos rótulos.
minilote
Um subconjunto pequeno e selecionado aleatoriamente de um lote processado em uma iteração. O tamanho do lote de um minilote geralmente fica entre 10 e 1.000 exemplos.
Por exemplo, suponha que o conjunto de treinamento inteiro (o lote completo) consista em 1.000 exemplos. Suponha também que você defina o tamanho do lote de cada minilote como 20. Portanto, cada iteração determina a perda em 20 exemplos aleatórios dos 1.000 e ajusta os pesos e vieses de acordo.
É muito mais eficiente calcular a perda em um minilote do que em todos os exemplos do lote completo.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
gradiente descendente estocástico com minilotes
Um algoritmo de gradiente descendente que usa minilotes. Em outras palavras, o gradiente descendente estocástico com minilotes estima o gradiente com base em um pequeno subconjunto dos dados de treinamento. O gradiente descendente estocástico regular usa um minilote de tamanho 1.
perda minimax
Uma função de perda para redes adversárias generativas (em inglês), com base na entropia cruzada entre a distribuição de dados gerados e dados reais.
A perda de minimax é usada no primeiro artigo para descrever redes generativas adversárias.
Consulte Funções de perda no curso de redes adversárias generativas para mais informações.
classe minoritária
O rótulo menos comum em um conjunto de dados com classes desequilibradas. Por exemplo, em um conjunto de dados com 99% de rótulos negativos e 1% de rótulos positivos, os rótulos positivos são a classe minoritária.
Contraste com a classe majoritária.
Consulte Conjuntos de dados: conjuntos de dados desequilibrados no Curso intensivo de machine learning para mais informações.
mistura de especialistas
Um esquema para aumentar a eficiência da rede neural usando apenas um subconjunto dos parâmetros dela (conhecido como especialista) para processar um determinado token ou exemplo de entrada. Uma rede de controle de acesso encaminha cada token ou exemplo de entrada para os especialistas adequados.
Para mais detalhes, consulte um dos seguintes artigos:
- Redes neurais extremamente grandes: a camada de mistura de especialistas com poucos portões
- Mixture-of-Experts com roteamento de escolha de especialistas
ML
Abreviação de aprendizado de máquina.
MMIT
Abreviação de multimodal instruction-tuned.
MNIST
Um conjunto de dados de domínio público compilado por LeCun, Cortes e Burges com 60.000 imagens, cada uma mostrando como um humano escreveu manualmente um dígito específico de 0 a 9. Cada imagem é armazenada como uma matriz de números inteiros de 28 x 28, em que cada número inteiro é um valor de escala de cinza entre 0 e 255, inclusive.
O MNIST é um conjunto de dados canônico para machine learning, geralmente usado para testar novas abordagens de machine learning. Para mais detalhes, consulte O banco de dados MNIST de dígitos manuscritos.
modality
Uma categoria de dados de alto nível. Por exemplo, números, texto, imagens, vídeo e áudio são cinco modalidades diferentes.
modelo
Em geral, qualquer construção matemática que processe dados de entrada e retorne uma saída. Em outras palavras, um modelo é o conjunto de parâmetros e a estrutura necessários para que um sistema faça previsões. No aprendizado de máquina supervisionado, um modelo usa um exemplo como entrada e infere uma previsão como saída. No aprendizado supervisionado, os modelos são um pouco diferentes. Exemplo:
- Um modelo de regressão linear consiste em um conjunto de pesos e um bias.
- Um modelo de rede neural consiste em:
- Um conjunto de camadas ocultas, cada uma contendo um ou mais neurônios.
- Os pesos e o viés associados a cada neurônio.
- Um modelo de árvore de decisão consiste em:
- O formato da árvore, ou seja, o padrão em que as condições e as folhas estão conectadas.
- As condições e as folhas.
É possível salvar, restaurar ou fazer cópias de um modelo.
O aprendizado de máquina não supervisionado também gera modelos, geralmente uma função que pode mapear um exemplo de entrada para o cluster mais adequado.
capacidade do modelo
A complexidade dos problemas que um modelo pode aprender. Quanto mais complexos forem os problemas que um modelo pode aprender, maior será a capacidade dele. A capacidade de um modelo geralmente aumenta com o número de parâmetros. Para uma definição formal da capacidade de um modelo de classificação, consulte Dimensão VC.
cascata de modelos
Um sistema que escolhe o modelo ideal para uma consulta de inferência específica.
Imagine um grupo de modelos, que variam de muito grandes (muitos parâmetros) a muito menores (muito menos parâmetros). Modelos muito grandes consomem mais recursos computacionais no momento da inferência do que modelos menores. No entanto, modelos muito grandes geralmente conseguem inferir solicitações mais complexas do que modelos menores. A cascata de modelos determina a complexidade da consulta de inferência e escolhe o modelo adequado para realizar a inferência. A principal motivação para o encadeamento de modelos é reduzir os custos de inferência selecionando modelos menores e só escolhendo um modelo maior para consultas mais complexas.
Imagine que um modelo pequeno é executado em um smartphone e uma versão maior dele é executada em um servidor remoto. Uma boa cascata de modelos reduz o custo e a latência, permitindo que o modelo menor processe solicitações simples e chame o modelo remoto apenas para solicitações complexas.
Consulte também roteador de modelo.
paralelismo de modelos
Uma maneira de dimensionar o treinamento ou a inferência que coloca diferentes partes de um modelo em diferentes dispositivos. O paralelismo de modelos permite usar modelos grandes demais para caber em um único dispositivo.
Para implementar o paralelismo de modelo, um sistema geralmente faz o seguinte:
- Fragmenta (divide) o modelo em partes menores.
- Distribui o treinamento dessas partes menores em vários processadores. Cada processador treina a própria parte do modelo.
- Combina os resultados para criar um único modelo.
O paralelismo de modelos deixa o treinamento mais lento.
Consulte também paralelismo de dados.
roteador de modelo
O algoritmo que determina o modelo ideal para inferência no encadeamento de modelos. Um roteador de modelo é normalmente um modelo de machine learning que aprende gradualmente a escolher o melhor modelo para uma determinada entrada. No entanto, um roteador de modelo às vezes pode ser um algoritmo mais simples, sem machine learning.
treinamento de modelo
O processo de determinar o melhor modelo.
MOE
Abreviação de mistura de especialistas.
Momentum
Um algoritmo sofisticado de gradiente descendente em que uma etapa de aprendizado depende não apenas da derivada na etapa atual, mas também das derivadas das etapas imediatamente anteriores. O momentum envolve o cálculo de uma média móvel exponencialmente ponderada dos gradientes ao longo do tempo, semelhante ao momentum na física. Às vezes, o momentum impede que o aprendizado fique preso em mínimos locais.
Mostly Basic Python Problems (MBPP)
Um conjunto de dados para avaliar a proficiência de um LLM na geração de código Python. O Mostly Basic Python Problems oferece cerca de 1.000 problemas de programação criados por colaboradores. Cada problema no conjunto de dados contém:
- Uma descrição da tarefa
- Código da solução
- Três casos de teste automatizados
MT
Abreviação de tradução automática.
classificação multiclasse
No aprendizado supervisionado, um problema de classificação em que o conjunto de dados contém mais de duas classes de rótulos. Por exemplo, os rótulos no conjunto de dados Iris precisam ser de uma das três classes a seguir:
- Iris setosa
- Iris virginica
- Iris versicolor
Um modelo treinado no conjunto de dados Iris que prevê o tipo de íris em novos exemplos está realizando uma classificação multiclasse.
Em contraste, os problemas de classificação que distinguem exatamente duas classes são modelos de classificação binária. Por exemplo, um modelo de e-mail que prevê spam ou não spam é um modelo de classificação binária.
Em problemas de clusterização, a classificação multiclasse se refere a mais de dois clusters.
Consulte Redes neurais: classificação multiclasse no Curso intensivo de machine learning para mais informações.
regressão logística multiclasse
Usando regressão logística em problemas de classificação multiclasse.
autoatenção multicabeça
Uma extensão da autoatenção que aplica o mecanismo de autoatenção várias vezes para cada posição na sequência de entrada.
Os Transformers introduziram a autoatenção de várias cabeças.
multimodal com ajuste de instrução
Um modelo ajustado para instruções que pode processar entradas além de texto, como imagens, vídeos e áudio.
modelo multimodal
Um modelo cujas entradas, saídas ou ambas incluem mais de uma modalidade. Por exemplo, considere um modelo que usa uma imagem e uma legenda de texto (duas modalidades) como recursos e gera uma pontuação indicando o quão adequada a legenda é para a imagem. Portanto, as entradas desse modelo são multimodais e a saída é unimodal.
classificação multinomial
Sinônimo de classificação multiclasse.
regressão multinomial
Sinônimo de regressão logística multiclasse.
Interpretação de texto com várias frases (MultiRC)
Um conjunto de dados para avaliar a capacidade de um LLM de responder a exercícios de múltipla escolha. Cada exemplo no conjunto de dados contém:
- Um parágrafo de contexto
- Uma pergunta sobre esse parágrafo
- Várias respostas para a pergunta. Cada resposta é marcada como "Verdadeiro" ou "Falso". Várias respostas podem ser verdadeiras.
Exemplo:
Parágrafo de contexto:
Susan queria fazer uma festa de aniversário. Ela ligou para todos os amigos. Ela tem cinco amigos. A mãe dela disse que Susan pode convidar todos para a festa. A primeira amiga dela não pôde ir à festa porque estava doente. A segunda amiga estava viajando. A terceira amiga não tinha certeza se os pais dela permitiriam. O quarto amigo disse que talvez. O quinto amigo com certeza poderia ir à festa. Susan ficou um pouco triste. No dia da festa, todos os cinco amigos apareceram. Cada amigo tinha um presente para Susan. Susan ficou feliz e enviou um cartão de agradecimento para cada amigo na semana seguinte.
Pergunta: o amigo doente de Susan se recuperou?
Várias respostas:
- Sim, ela se recuperou. (True)
- Não. (Falso)
- Sim. (True)
- Não, ela não se recuperou. (Falso)
- Sim, ela estava na festa da Susan. (True)
O MultiRC é um componente do conjunto SuperGLUE.
Para mais detalhes, consulte Looking Beyond the Surface: A Challenge Set for Reading Comprehension over Multiple Sentences (em inglês).
multitarefa
Uma técnica de machine learning em que um único modelo é treinado para realizar várias tarefas.
Os modelos multitarefa são criados com treinamento em dados adequados para cada uma das diferentes tarefas. Isso permite que o modelo aprenda a compartilhar informações entre as tarefas, o que ajuda o modelo a aprender de forma mais eficaz.
Um modelo treinado para várias tarefas geralmente tem recursos de generalização aprimorados e pode ser mais robusto no processamento de diferentes tipos de dados.
N
Nano
Um modelo do Gemini relativamente pequeno, projetado para uso no dispositivo. Consulte Gemini Nano para mais detalhes.
Armadilha de NaN
Quando um número no modelo se torna um NaN durante o treinamento, fazendo com que muitos ou todos os outros números no modelo se tornem um NaN.
NaN é uma abreviação de Not a Number.
processamento de linguagem natural
A área de ensino de computadores para processar o que um usuário disse ou digitou usando regras linguísticas. Quase todo o processamento de linguagem natural moderno depende do machine learning.processamento de linguagem natural
Um subconjunto do processamento de linguagem natural que determina as intenções de algo dito ou digitado. O entendimento de linguagem natural pode ir além do processamento de linguagem natural para considerar aspectos complexos da linguagem, como contexto, sarcasmo e sentimento.
classe negativa
Na classificação binária, uma classe é chamada de positiva e a outra de negativa. A classe positiva é o objeto ou evento que o modelo está testando, e a classe negativa é a outra possibilidade. Exemplo:
- A classe negativa em um teste médico pode ser "sem tumor".
- A classe negativa em um modelo de classificação de e-mail pode ser "não é spam".
Contraste com a classe positiva.
amostragem negativa
Sinônimo de amostragem de candidatos.
Pesquisa de arquitetura neural (NAS)
Uma técnica para projetar automaticamente a arquitetura de uma rede neural. Os algoritmos de NAS podem reduzir o tempo e os recursos necessários para treinar uma rede neural.
Normalmente, o NAS usa:
- Um espaço de pesquisa, que é um conjunto de arquiteturas possíveis.
- Uma função de aptidão, que é uma medida de como uma arquitetura específica se sai em uma determinada tarefa.
Os algoritmos de NAS geralmente começam com um pequeno conjunto de arquiteturas possíveis e expandem gradualmente o espaço de pesquisa à medida que o algoritmo aprende mais sobre quais arquiteturas são eficazes. A função de aptidão geralmente se baseia na performance da arquitetura em um conjunto de treinamento, e o algoritmo é treinado usando uma técnica de aprendizado por reforço.
Os algoritmos de NAS se mostraram eficazes na descoberta de arquiteturas de alta performance para várias tarefas, incluindo classificação de imagens, classificação de texto e tradução automática.
do feedforward
Um modelo que contenha pelo menos uma camada oculta. Uma rede neural profunda é um tipo de rede neural que contém mais de uma camada oculta. Por exemplo, o diagrama a seguir mostra uma rede neural profunda com duas camadas ocultas.
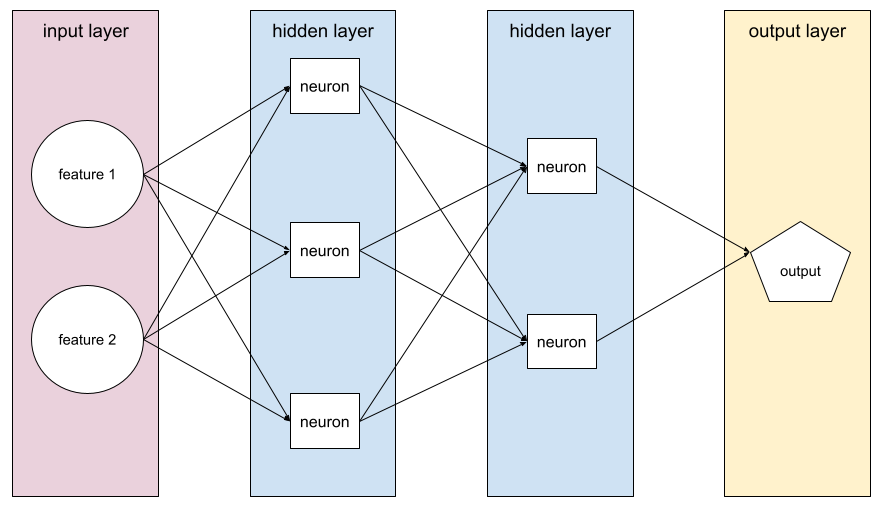
Cada neurônio em uma rede neural se conecta a todos os nós na próxima camada. Por exemplo, no diagrama anterior, observe que cada um dos três neurônios na primeira camada oculta se conecta separadamente aos dois neurônios na segunda camada oculta.
As redes neurais implementadas em computadores às vezes são chamadas de redes neurais artificiais para diferenciá-las das redes neurais encontradas em cérebros e outros sistemas nervosos.
Algumas redes neurais podem imitar relações não lineares extremamente complexas entre diferentes recursos e o rótulo.
Consulte também rede neural convolucional e rede neural recorrente.
Consulte Redes neurais no Curso intensivo de machine learning para mais informações.
neurônio
Em machine learning, uma unidade distinta em uma camada oculta de uma rede neural. Cada neurônio realiza as seguintes ações em duas etapas:
- Calcula a soma ponderada dos valores de entrada multiplicados pelos pesos correspondentes.
- Transmite a soma ponderada como entrada para uma função de ativação.
Um neurônio na primeira camada oculta aceita entradas dos valores de recursos na camada de entrada. Um neurônio em qualquer camada oculta além da primeira aceita entradas dos neurônios na camada oculta anterior. Por exemplo, um neurônio na segunda camada oculta aceita entradas dos neurônios na primeira camada oculta.
A ilustração a seguir destaca dois neurônios e as respectivas entradas.
Um neurônio em uma rede neural imita o comportamento dos neurônios no cérebro e em outras partes do sistema nervoso.
N-grama
Uma sequência ordenada de N palavras. Por exemplo, truly madly é um bigrama. Como a ordem é relevante, madly truly é um bigrama diferente de truly madly.
| N | Nome(s) para esse tipo de n-grama | Exemplos |
|---|---|---|
| 2 | bigrama ou 2-grama | ir, ir a, almoçar, jantar |
| 3 | trigrama ou 3-grama | ate too much, happily ever after, the bell tolls |
| 4 | 4-grama | walk in the park, dust in the wind, the boy ate lentils |
Muitos modelos de processamento de linguagem natural (PLN) usam N-gramas para prever a próxima palavra que o usuário vai digitar ou dizer. Por exemplo, suponha que um usuário tenha digitado felizes para sempre. Um modelo de PLN baseado em trigramas provavelmente vai prever que o usuário vai digitar a palavra depois.
Contraste n-gramas com conjunto de palavras, que são conjuntos de palavras não ordenados.
Consulte Modelos de linguagem grandes no Curso intensivo de machine learning para mais informações.
PLN
Abreviação de processamento de linguagem natural.
PLN
Abreviação de processamento de linguagem natural.
nó (árvore de decisão)
Em uma árvore de decisão, qualquer condição ou folha.
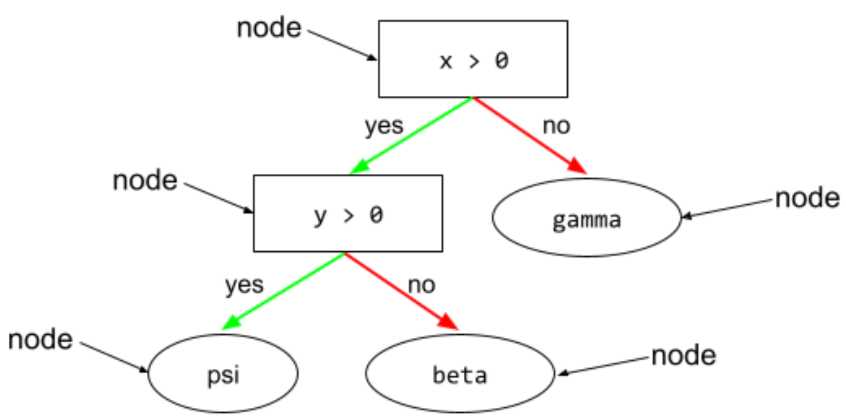
Consulte Árvores de decisão no curso "Florestas de decisão" para mais informações.
nó (rede neural)
Um neurônio em uma camada oculta.
Consulte Redes neurais no Curso intensivo de machine learning para mais informações.
nó (grafo do TensorFlow)
Uma operação em um grafo do TensorFlow.
ruído
De modo geral, qualquer coisa que obscureça o sinal em um conjunto de dados. O ruído pode ser introduzido nos dados de várias maneiras. Exemplo:
- Os rotuladores humanos cometem erros na rotulagem.
- Humanos e instrumentos registram ou omitem valores de atributos incorretamente.
condição não binária
Uma condição que contém mais de dois resultados possíveis. Por exemplo, a condição não binária a seguir tem três resultados possíveis:
Consulte Tipos de condições no curso "Florestas de decisão" para mais informações.
não linear
Uma relação entre duas ou mais variáveis que não pode ser representada apenas por adição e multiplicação. Uma relação linear pode ser representada como uma linha, mas uma relação não linear não. Por exemplo, considere dois modelos que relacionam um único atributo a um único rótulo. O modelo à esquerda é linear e o modelo à direita é não linear:

Consulte Redes neurais: nós e camadas ocultas no Curso intensivo de machine learning para testar diferentes tipos de funções não lineares.
viés de não resposta
Consulte viés de seleção.
não estacionariedade
Uma característica cujos valores mudam em uma ou mais dimensões, geralmente o tempo. Por exemplo, considere os seguintes exemplos de não estacionariedade:
- O número de maiôs vendidos em uma loja específica varia de acordo com a estação.
- A quantidade de uma determinada fruta colhida em uma região específica é zero durante grande parte do ano, mas grande por um breve período.
- Devido às mudanças climáticas, as temperaturas médias anuais estão mudando.
Contraste com a estacionariedade.
NORA (no one right answer, em inglês)
Um comando com várias respostas corretas. Por exemplo, o comando a seguir não tem uma resposta certa:
Conte uma piada engraçada sobre elefantes.
Avaliar as respostas a comandos sem uma resposta certa geralmente é muito mais subjetivo do que avaliar comandos com uma resposta certa. Por exemplo, avaliar uma piada de elefante requer uma maneira sistemática de determinar o quanto ela é engraçada.
NORA
Abreviação de não existe uma resposta certa.
normalização
Em termos gerais, o processo de conversão do intervalo real de valores de uma variável em um intervalo padrão, como:
- -1 a +1
- 0 a 1
- Valores Z (aproximadamente de -3 a +3)
Por exemplo, suponha que o intervalo real de valores de um determinado recurso seja de 800 a 2.400. Como parte da engenharia de recursos, é possível normalizar os valores reais para um intervalo padrão, como de -1 a +1.
A normalização é uma tarefa comum na engenharia de recursos. Normalmente, os modelos são treinados mais rápido (e produzem previsões melhores) quando cada atributo numérico no vetor de atributos tem aproximadamente o mesmo intervalo.
Consulte também Normalização de pontuação Z.
Consulte Dados numéricos: normalização no Curso intensivo de machine learning para mais informações.
NotebookLM
Uma ferramenta baseada no Gemini que permite aos usuários fazer upload de documentos e usar comandos para fazer perguntas, resumir ou organizar esses documentos. Por exemplo, um autor pode enviar vários contos e pedir ao NotebookLM para encontrar os temas em comum ou identificar qual deles seria o melhor filme.
detecção de novidades
O processo de determinar se um exemplo novo (inédito) vem da mesma distribuição que o conjunto de treinamento. Em outras palavras, depois do treinamento no conjunto de treinamento, a detecção de novidades determina se um exemplo novo (durante a inferência ou o treinamento adicional) é um outlier.
Contraste com a detecção de outliers.
dados numéricos
Atributos representados como números inteiros ou de valor real. Por exemplo, um modelo de avaliação de imóveis provavelmente representaria o tamanho de uma casa (em metros quadrados) como dados numéricos. Representar um atributo como dados numéricos indica que os valores do atributo têm uma relação matemática com o rótulo. Ou seja, o número de metros quadrados em uma casa provavelmente tem alguma relação matemática com o valor dela.
Nem todos os dados de números inteiros devem ser representados como dados numéricos. Por exemplo, os códigos postais em algumas partes do mundo são números inteiros. No entanto, eles não devem ser representados como dados numéricos em modelos. Isso porque um código postal de 20000 não é duas vezes (ou metade) tão potente quanto um código postal de 10000. Além disso, embora códigos postais diferentes sejam correlacionados a valores imobiliários diferentes, não podemos presumir que os valores imobiliários no código postal 20000 sejam duas vezes mais valiosos do que os valores imobiliários no código postal 10000.
Em vez disso, eles devem ser representados como dados categóricos.
Às vezes, os recursos numéricos são chamados de recursos contínuos.
Consulte Como trabalhar com dados numéricos no Curso intensivo de machine learning para mais informações.
NumPy
Uma biblioteca de matemática de código aberto que oferece operações eficientes de matrizes em Python. O pandas é criado com base no NumPy.
O
objetivo
Uma métrica que seu algoritmo está tentando otimizar.
função objetiva
A fórmula matemática ou métrica que um modelo visa otimizar. Por exemplo, a função objetiva da regressão linear geralmente é a perda quadrática média. Assim, ao treinar um modelo de regressão linear, o objetivo é minimizar a perda quadrática média.
Em alguns casos, a meta é maximizar a função objetiva. Por exemplo, se a função objetiva for a acurácia, a meta será maximizar a acurácia.
Consulte também perda.
condição oblíqua
Em uma árvore de decisão, uma condição que envolve mais de uma característica. Por exemplo, se altura e largura forem recursos, a condição a seguir será oblíqua:
height > width
Contraste com a condição alinhada ao eixo.
Consulte Tipos de condições no curso "Florestas de decisão" para mais informações.
off-line
Sinônimo de static.
inferência off-line
O processo de um modelo gerar um lote de previsões e depois armazenar em cache (salvar) essas previsões. Os apps podem acessar a previsão inferida do cache em vez de executar o modelo novamente.
Por exemplo, considere um modelo que gera previsões do tempo locais (previsões) a cada quatro horas. Depois de cada execução do modelo, o sistema armazena em cache todas as previsões do tempo locais. Os apps de clima recuperam as previsões do cache.
A inferência off-line também é chamada de inferência estática.
Contraste com a inferência on-line. Consulte Sistemas de ML de produção: inferência estática x dinâmica no Curso intensivo de machine learning para mais informações.
codificação one-hot
Representar dados categóricos como um vetor em que:
- Um elemento é definido como 1.
- Todos os outros elementos são definidos como 0.
A codificação simples é usada com frequência para representar strings ou identificadores que têm um conjunto finito de valores possíveis.
Por exemplo, suponha que um determinado recurso categórico chamado Scandinavia tenha cinco valores possíveis:
- "Dinamarca"
- "Suécia"
- "Noruega"
- "Finlândia"
- "Islândia"
A codificação one-hot pode representar cada um dos cinco valores da seguinte forma:
| País | Vetor | ||||
|---|---|---|---|---|---|
| "Dinamarca" | 1 | 0 | 0 | 0 | 0 |
| "Suécia" | 0 | 1 | 0 | 0 | 0 |
| "Noruega" | 0 | 0 | 1 | 0 | 0 |
| "Finlândia" | 0 | 0 | 0 | 1 | 0 |
| "Islândia" | 0 | 0 | 0 | 0 | 1 |
Graças à codificação one-hot, um modelo pode aprender diferentes conexões com base em cada um dos cinco países.
Representar um atributo como dados numéricos é uma alternativa à codificação one-hot. Infelizmente, representar os países escandinavos numericamente não é uma boa escolha. Por exemplo, considere a seguinte representação numérica:
- "Dinamarca" é 0
- "Suécia" é 1
- "Noruega" é 2
- "Finlândia" é 3
- "Islândia" é 4
Com a codificação numérica, um modelo interpretaria os números brutos matematicamente e tentaria treinar com eles. No entanto, a Islândia não é o dobro (ou a metade) de algo em comparação com a Noruega. Portanto, o modelo chegaria a conclusões estranhas.
Consulte Dados categóricos: vocabulário e codificação one-hot no Curso intensivo de machine learning para mais informações.
uma resposta correta (ORA)
Um comando com uma única resposta correta. Por exemplo, considere o seguinte comando:
Verdadeiro ou falso: Saturno é maior que Marte.
A única resposta correta é verdadeira.
Contraste com não existe uma resposta certa.
aprendizado one-shot
Uma abordagem de aprendizado de máquina, geralmente usada para classificação de objetos, projetada para aprender um modelo de classificação eficaz com base em um único exemplo de treinamento.
Consulte também aprendizado few-shot e aprendizado zero-shot.
comando one-shot
Um comando que contém um exemplo demonstrando como o modelo de linguagem grande deve responder. Por exemplo, o comando a seguir contém um exemplo que mostra a um modelo de linguagem grande como ele deve responder a uma consulta.
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Por exemplo, |
| Índia: | A consulta real. |
Compare e contraste o comando único com os seguintes termos:
um-contra-todos
Dado um problema de classificação com N classes, uma solução que consiste em N modelos separados de classificação binária, um para cada resultado possível. Por exemplo, considerando um modelo que classifica exemplos como animal, vegetal ou mineral, uma solução de um contra todos forneceria os três modelos de classificação binária separados a seguir:
- animal x não animal
- vegetal x não vegetal
- mineral x não mineral
on-line
Sinônimo de dynamic.
inferência on-line
Gerar previsões sob demanda. Por exemplo, suponha que um app transmita uma entrada para um modelo e emita uma solicitação de previsão. Um sistema que usa inferência on-line responde à solicitação executando o modelo e retornando a previsão ao app.
Contraste com a inferência off-line.
Consulte Sistemas de ML de produção: inferência estática x dinâmica no Curso intensivo de machine learning para mais informações.
operação (op)
No TensorFlow, qualquer procedimento que crie, manipule ou destrua um Tensor. Por exemplo, uma multiplicação de matrizes é uma operação que usa dois tensores como entrada e gera um tensor como saída.
Optax
Uma biblioteca de processamento e otimização de gradientes para JAX. O Optax facilita a pesquisa fornecendo blocos de construção que podem ser recombinados de maneiras personalizadas para otimizar modelos paramétricos, como redes neurais profundas. Outras metas incluem:
- Fornecer implementações legíveis, bem testadas e eficientes de componentes principais.
- Melhorar a produtividade ao permitir a combinação de ingredientes de baixo nível em otimizadores personalizados (ou outros componentes de processamento de gradiente).
- Acelerar a adoção de novas ideias facilitando a contribuição de qualquer pessoa.
optimizer
Uma implementação específica do algoritmo de gradiente descendente. Alguns otimizadores conhecidos são:
- AdaGrad, que significa gradiente descendente ADAptativo.
- Adam, que significa ADAptativo com Momentum.
ORA
Abreviação de uma resposta certa.
viés de homogeneidade externa ao grupo
A tendência de ver os membros de um grupo externo como mais parecidos do que os de um grupo interno ao comparar atitudes, valores, traços de personalidade e outras características. Intragrupo se refere a pessoas com quem você interage regularmente. Extragrupo se refere a pessoas com quem você não interage regularmente. Se você criar um conjunto de dados pedindo que as pessoas forneçam atributos sobre grupos externos, esses atributos podem ser menos sutis e mais estereotipados do que os que os participantes listam para pessoas do próprio grupo.
Por exemplo, os liliputianos podem descrever as casas de outros liliputianos com muitos detalhes, citando pequenas diferenças em estilos arquitetônicos, janelas, portas e tamanhos. No entanto, os mesmos liliputianos podem simplesmente declarar que todos os brobdingnagianos vivem em casas idênticas.
O viés de homogeneidade externa ao grupo é uma forma de viés de atribuição a grupos.
Consulte também viés de grupo.
detecção de outlier
O processo de identificar outliers em um conjunto de treinamento.
Contraste com a detecção de novidade.
as exceções
Valores distantes da maioria dos outros valores. Em machine learning, qualquer um dos seguintes é um outlier:
- Dados de entrada com valores que estão a mais de aproximadamente três desvios padrão da média.
- Ponderações com valores absolutos altos.
- Valores previstos relativamente distantes dos valores reais.
Por exemplo, suponha que widget-price seja um recurso de um determinado modelo.
Suponha que a média widget-price seja de 7 euros com um desvio padrão de 1 euro. Exemplos com um widget-price de 12 ou 2 euros seriam considerados outliers porque cada um desses preços está a cinco desvios padrão da média.
Geralmente, os outliers são causados por erros de digitação ou outros erros de entrada. Em outros casos, os outliers não são erros. Afinal, valores a cinco desvios padrão da média são raros, mas não impossíveis.
Os outliers geralmente causam problemas no treinamento do modelo. O corte é uma maneira de gerenciar outliers.
Consulte Como trabalhar com dados numéricos no Curso intensivo de machine learning para mais informações.
avaliação fora da amostra (OOB)
Um mecanismo para avaliar a qualidade de uma floresta de decisão testando cada árvore de decisão em relação aos exemplos não usados durante o treinamento dessa árvore de decisão. Por exemplo, no diagrama a seguir, observe que o sistema treina cada árvore de decisão em cerca de dois terços dos exemplos e depois avalia o restante.
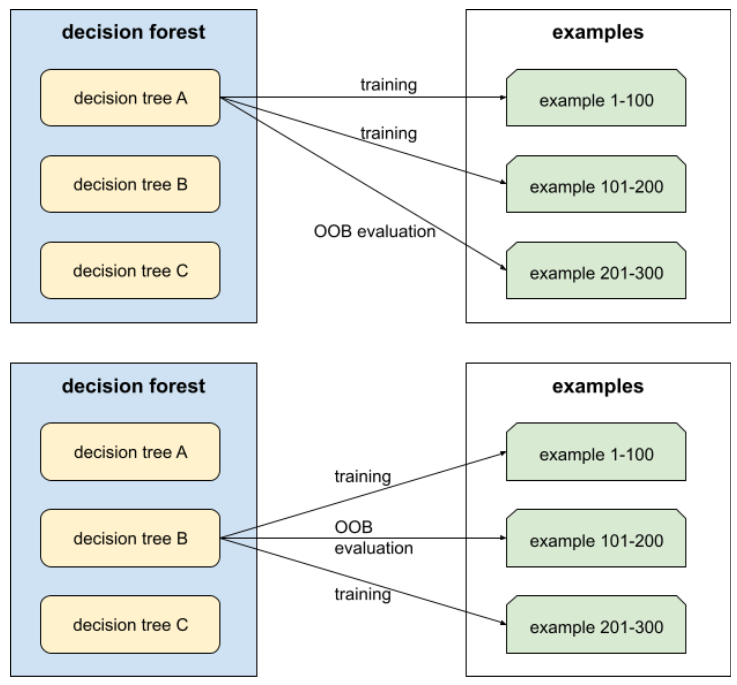
A avaliação fora da amostra é uma aproximação computacionalmente eficiente e conservadora do mecanismo de validação cruzada. Na validação cruzada, um modelo é treinado para cada rodada de validação cruzada (por exemplo, 10 modelos são treinados em uma validação cruzada de 10 dobras). Com a avaliação OOB, um único modelo é treinado. Como o bagging retém alguns dados de cada árvore durante o treinamento, a avaliação OOB pode usar esses dados para aproximar a validação cruzada.
Consulte Avaliação fora da amostra no curso "Florestas de decisão" para mais informações.
camada de saída
A camada "final" de uma rede neural. A camada de saída contém a previsão.
A ilustração a seguir mostra uma pequena rede neural profunda com uma camada de entrada, duas camadas ocultas e uma camada de saída:
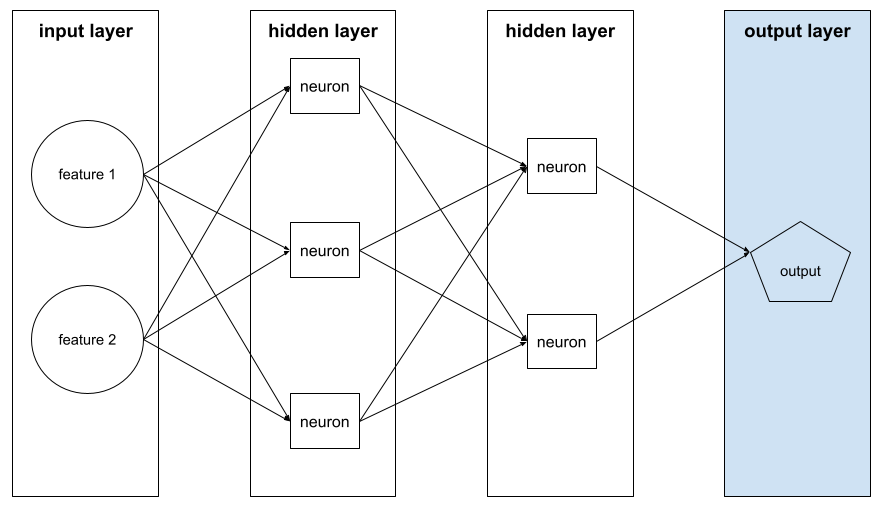
overfitting
Criar um modelo que corresponda aos dados de treinamento de forma tão próxima que não consiga fazer previsões corretas sobre novos dados.
A regularização pode reduzir o overfitting. O treinamento em um conjunto de dados grande e diversificado também pode reduzir o overfitting.
Consulte Overfitting no Curso intensivo de machine learning para mais informações.
superamostragem
Reutilizar os exemplos de uma classe minoritária em um conjunto de dados não balanceado para criar um conjunto de treinamento mais equilibrado.
Por exemplo, considere um problema de classificação binária em que a proporção da classe majoritária para a classe minoritária é de 5.000:1. Se o conjunto de dados tiver um milhão de exemplos, ele terá apenas cerca de 200 exemplos da classe minoritária, o que pode ser muito pouco para um treinamento eficaz. Para superar essa deficiência, você pode fazer uma superamostragem (reutilizar) desses 200 exemplos várias vezes, o que pode gerar exemplos suficientes para um treinamento útil.
É preciso ter cuidado com o overfitting ao fazer o oversampling.
Contraste com subamostragem.
P
dados compactados
Uma abordagem para armazenar dados com mais eficiência.
Os dados compactados são armazenados usando um formato compactado ou de alguma outra forma que permita o acesso mais eficiente. Os dados compactados minimizam a quantidade de memória e computação necessárias para acessá-los, o que leva a um treinamento mais rápido e uma inferência de modelo mais eficiente.
Os dados compactados são usados com frequência com outras técnicas, como aumento de dados e regularização, melhorando ainda mais a performance dos modelos.
PaLM
Abreviação de Pathways Language Model.
pandas
Uma API de análise de dados orientada por colunas criada com base no numpy. Muitos frameworks de aprendizado de máquina, incluindo o TensorFlow, aceitam estruturas de dados do pandas como entradas. Consulte a documentação do pandas para mais detalhes.
parâmetro
Os pesos e vieses que um modelo aprende durante o treinamento. Por exemplo, em um modelo de regressão linear, os parâmetros consistem na tendência (b) e em todos os pesos (w1, w2 etc.) na seguinte fórmula:
Já os hiperparâmetros são os valores que você (ou um serviço de ajuste de hiperparâmetros) fornece ao modelo. Por exemplo, a taxa de aprendizado é um hiperparâmetro.
ajuste da eficiência de parâmetros
Um conjunto de técnicas para ajustar um modelo de linguagem pré-treinado (PLM) grande de maneira mais eficiente do que o ajuste completo. O ajuste com eficiência de parâmetros geralmente ajusta muito menos parâmetros do que o ajuste fino completo, mas geralmente produz um modelo de linguagem grande que tem uma performance tão boa (ou quase tão boa) quanto um modelo de linguagem grande criado com ajuste fino completo.
Compare e contraste o ajuste da eficiência dos parâmetros com:
O ajuste com eficiência de parâmetros também é conhecido como ajuste fino com eficiência de parâmetros.
Servidor de parâmetros (PS)
Um job que acompanha os parâmetros de um modelo em um ambiente distribuído.
atualização de parâmetros
A operação de ajustar os parâmetros de um modelo durante o treinamento, geralmente em uma única iteração de gradiente descendente.
derivada parcial
Uma derivada em que todas as variáveis, exceto uma, são consideradas constantes. Por exemplo, a derivada parcial de f(x, y) em relação a x é a derivada de f considerada como uma função de x apenas (ou seja, mantendo y constante). A derivada parcial de f em relação a x se concentra apenas em como x está mudando e ignora todas as outras variáveis na equação.
viés de participação
Sinônimo de viés de não resposta. Consulte viés de seleção.
estratégia de particionamento
O algoritmo pelo qual as variáveis são divididas entre servidores de parâmetros.
pass at k (pass@k)
Uma métrica para determinar a qualidade do código (por exemplo, Python) que um modelo de linguagem grande gera. Mais especificamente, "pass at k" informa a probabilidade de que pelo menos um bloco de código gerado entre k blocos de código gerados passe em todos os testes de unidade.
Os modelos de linguagem grandes geralmente têm dificuldade para gerar um bom código para problemas de programação complexos. Os engenheiros de software se adaptam a esse problema pedindo ao modelo de linguagem grande para gerar várias (k) soluções para o mesmo problema. Em seguida, os engenheiros de software testam cada uma das soluções com testes de unidade. O cálculo da aprovação em k depende do resultado dos testes de unidade:
- Se uma ou mais dessas soluções passarem no teste de unidade, o LLM passará no desafio de geração de código.
- Se nenhuma das soluções passar no teste de unidade, o LLM falhará no desafio de geração de código.
A fórmula para aprovação em k é a seguinte:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
Em geral, valores mais altos de k produzem pontuações mais altas de aprovação em k. No entanto, valores mais altos de k exigem mais recursos de teste de unidade e modelo de linguagem grande.
Modelo de linguagem para programa de treinamentos (PaLM)
Um modelo mais antigo e predecessor dos modelos do Gemini.
Pax
Um framework de programação projetado para treinar modelos de rede neural em grande escala tão grandes que abrangem várias TPUs, chips aceleradores, frações ou pods.
O Pax é baseado no Flax, que é baseado no JAX.
perceptron
Um sistema (hardware ou software) que recebe um ou mais valores de entrada, executa uma função na soma ponderada das entradas e calcula um único valor de saída. No aprendizado de máquina, a função geralmente é não linear, como ReLU, sigmoide ou tanh. Por exemplo, o perceptron a seguir depende da função sigmoide para processar três valores de entrada:
Na ilustração a seguir, o perceptron recebe três entradas, cada uma delas modificada por um peso antes de entrar no perceptron:

Os perceptrons são os neurônios nas redes neurais.
desempenho
Termo sobrecarregado com os seguintes significados:
- O significado padrão na engenharia de software. Ou seja, qual a velocidade (ou eficiência) de execução desse software?
- O significado no machine learning. Aqui, a performance responde à seguinte pergunta: quão correto é este modelo? Ou seja, quão boas são as previsões do modelo?
Importâncias de variáveis de troca
Um tipo de importância da variável que avalia o aumento no erro de previsão de um modelo após a troca dos valores do atributo. A importância da variável de permutação é uma métrica independente do modelo.
perplexidade
Uma medida de como um modelo está realizando a tarefa. Por exemplo, suponha que sua tarefa seja ler as primeiras letras de uma palavra que um usuário está digitando em um teclado de smartphone e oferecer uma lista de possíveis palavras de conclusão. A perplexidade, P, para essa tarefa é aproximadamente o número de palpites que você precisa oferecer para que sua lista contenha a palavra real que o usuário está tentando digitar.
A perplexidade está relacionada à entropia cruzada da seguinte maneira:
pipeline
A infraestrutura que envolve um algoritmo de machine learning. Um pipeline inclui a coleta de dados, a colocação dos dados em arquivos de dados de treinamento, o treinamento de um ou mais modelos e a exportação dos modelos para produção.
Consulte Pipelines de ML no curso "Gerenciamento de projetos de ML" para mais informações.
pipelining
Uma forma de paralelismo de modelo em que o processamento de um modelo é dividido em etapas consecutivas, e cada etapa é executada em um dispositivo diferente. Enquanto um estágio processa um lote, o estágio anterior pode trabalhar no próximo lote.
Consulte também o treinamento em etapas.
pjit
Uma função JAX que divide o código para ser executado em vários chips aceleradores. O usuário transmite uma função para pjit, que retorna uma função com semântica equivalente, mas compilada em um cálculo XLA executado em vários dispositivos (como GPUs ou núcleos de TPU).
O pjit permite que os usuários fragmentem cálculos sem reescrevê-los usando o particionador SPMD.
Em março de 2023, o pjit foi incorporado ao jit. Consulte Matrizes distribuídas e paralelização automática para mais detalhes.
PLM
Abreviação de modelo de linguagem pré-treinado.
pmap
Uma função JAX que executa cópias de uma função de entrada em vários dispositivos de hardware subjacentes (CPUs, GPUs ou TPUs), com diferentes valores de entrada. O pmap depende do SPMD.
política
Na aprendizagem por reforço, um mapeamento probabilístico do agente de estados para ações.
pooling
Reduzir uma matriz (ou matrizes) criada por uma camada convolucional anterior para uma matriz menor. O pooling geralmente envolve usar o valor máximo ou médio em toda a área agrupada. Por exemplo, suponha que temos a seguinte matriz 3x3:
![A matriz 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=3&hl=pt)
Uma operação de pooling, assim como uma operação convolucional, divide essa matriz em fatias e desliza essa operação convolucional por strides. Por exemplo, suponha que a operação de pooling divida a matriz convolucional em fatias de 2x2 com uma passada de 1x1. Como ilustrado no diagrama a seguir, quatro operações de pooling são realizadas. Imagine que cada operação de pooling escolha o valor máximo dos quatro na fatia:
![A matriz de entrada é 3x3 com os valores: [[5,3,1], [8,2,5], [9,4,3]].
A submatriz 2x2 no canto superior esquerdo da matriz de entrada é [[5,3], [8,2]]. Portanto, a operação de pooling no canto superior esquerdo gera o valor 8, que é o máximo de 5, 3, 8 e 2. A submatriz 2x2 no canto superior direito da matriz de entrada é [[3,1], [2,5]], então a operação de pooling no canto superior direito gera o valor 5. A submatriz 2x2 da parte de baixo à esquerda da matriz de entrada é [[8,2], [9,4]], então a operação de pooling da parte de baixo à esquerda gera o valor 9. A submatriz 2x2 inferior direita da matriz de entrada é [[2,5], [4,3]], então a operação de pooling inferior direita gera o valor 5. Em resumo, a operação de pooling gera a matriz 2x2 [[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=3&hl=pt)
O agrupamento ajuda a aplicar a invariância de translação na matriz de entrada.
O pooling para aplicativos de visão é conhecido mais formalmente como pooling espacial. Os aplicativos de série temporal geralmente se referem ao pooling como pooling temporal. De maneira menos formal, o pooling é chamado de subamostragem ou redução da amostragem.
codificação posicional
Uma técnica para adicionar informações sobre a posição de um token em uma sequência à incorporação do token. Os modelos Transformer usam codificação posicional para entender melhor a relação entre diferentes partes da sequência.
Uma implementação comum da codificação posicional usa uma função senoidal. Especificamente, a frequência e a amplitude da função senoidal são determinadas pela posição do token na sequência. Essa técnica permite que um modelo Transformer aprenda a atender a diferentes partes da sequência com base na posição delas.
classe positiva
A classe que você está testando.
Por exemplo, a classe positiva em um modelo de câncer pode ser "tumor". A classe positiva em um modelo de classificação de e-mail pode ser "spam".
Contraste com a classe negativa.
pós-processamento
Ajustar a saída de um modelo depois que ele foi executado. O pós-processamento pode ser usado para aplicar restrições de justiça sem modificar os modelos.
Por exemplo, é possível aplicar pós-processamento a um modelo de classificação binária definindo um limite de classificação para que a igualdade de oportunidades seja mantida para algum atributo. Para isso, verifique se a taxa de verdadeiros positivos é a mesma para todos os valores desse atributo.
modelo com ajuste fino
Termo mal definido que normalmente se refere a um modelo pré-treinado que passou por algum pós-processamento, como um ou mais dos seguintes:
AUC PR (área sob a curva PR)
Área sob a curva de precisão-recall interpolada, obtida ao representar pontos (recall, precisão) para diferentes valores do limiar de classificação.
Praxis
Uma biblioteca de ML principal e de alto desempenho do Pax. Muitas vezes, a Praxis é chamada de "biblioteca de camadas".
O Praxis não contém apenas as definições da classe Layer, mas também a maioria dos componentes de suporte, incluindo:
- entradas de dados
- bibliotecas de configuração (HParam e Fiddle)
- optimizers
A Praxis fornece as definições para a classe Model.
precision
Uma métrica para modelos de classificação que responde à seguinte pergunta:
Quando o modelo previu a classe positiva, qual foi a porcentagem de previsões corretas?
Esta é a fórmula:
em que:
- verdadeiro positivo significa que o modelo previu corretamente a classe positiva.
- falso positivo significa que o modelo previu incorretamente a classe positiva.
Por exemplo, suponha que um modelo tenha feito 200 previsões positivas. Das 200 previsões positivas:
- 150 eram verdadeiros positivos.
- 50 eram falsos positivos.
Neste caso:
Contraste com acurácia e recall.
Consulte Classificação: acurácia, recall, precisão e métricas relacionadas no Curso intensivo de machine learning para mais informações.
precisão em k (precision@k)
Uma métrica para avaliar uma lista classificada (ordenada) de itens. A precisão em k identifica a fração dos primeiros k itens na lista que são "relevantes". Ou seja:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
O valor de k precisa ser menor ou igual ao tamanho da lista retornada. O comprimento da lista retornada não faz parte do cálculo.
A relevância costuma ser subjetiva. Até mesmo avaliadores humanos especializados discordam sobre quais itens são relevantes.
Comparar com:
curva de precisão/recall
Uma curva de precisão versus recall em diferentes limiares de classificação.
previsão
A saída de um modelo. Exemplo:
- A previsão de um modelo de classificação binária é a classe positiva ou a classe negativa.
- A previsão de um modelo de classificação multiclasse é uma classe.
- A previsão de um modelo de regressão linear é um número.
viés de previsão
Um valor que indica a distância entre a média das previsões e a média dos rótulos no conjunto de dados.
Não confundir com o termo de viés em modelos de machine learning ou com o viés em ética e imparcialidade.
ML preditiva
Qualquer sistema padrão ("clássico") de machine learning.
O termo ML preditiva não tem uma definição formal. Em vez disso, o termo distingue uma categoria de sistemas de ML não baseada em IA generativa.
paridade preditiva
Uma métrica de imparcialidade que verifica se, para um determinado modelo de classificação, as taxas de precisão são equivalentes para os subgrupos em consideração.
Por exemplo, um modelo que prevê a aceitação na faculdade satisfaria a paridade preditiva para nacionalidade se a taxa de precisão fosse a mesma para liliputianos e brobdingnagianos.
Às vezes, a paridade preditiva também é chamada de paridade de taxa preditiva.
Consulte "Explicação das definições de justiça" (seção 3.2.1) para uma discussão mais detalhada sobre a paridade preditiva.
paridade de taxa preditiva
Outro nome para paridade preditiva.
pré-processamento
Processar dados antes de usá-los para treinar um modelo. O pré-processamento pode ser tão simples quanto remover palavras de um corpus de texto em inglês que não aparecem no dicionário inglês ou tão complexo quanto reexpressar pontos de dados de uma forma que elimine o máximo possível de atributos correlacionados com atributos sensíveis. O pré-processamento pode ajudar a atender às restrições de imparcialidade.modelo pré-treinado
Embora esse termo possa se referir a qualquer modelo ou vetor de incorporação treinado, agora ele geralmente se refere a um modelo de linguagem grande treinado ou outra forma de modelo de IA generativa treinado.
Consulte também modelo de base e modelo de fundação.
autoguiado
O treinamento inicial de um modelo em um grande conjunto de dados. Alguns modelos pré-treinados são gigantes desajeitados e geralmente precisam ser refinados com mais treinamento. Por exemplo, especialistas em ML podem pré-treinar um modelo de linguagem grande em um vasto conjunto de dados de texto, como todas as páginas em inglês da Wikipédia. Após o pré-treinamento, o modelo resultante pode ser refinado ainda mais usando qualquer uma das seguintes técnicas:
- destilação
- ajuste de detalhes
- ajuste de instruções
- ajuste com eficiência de parâmetros
- prompt-tuning
crença a priori
O que você acredita sobre os dados antes de começar a treinar com eles. Por exemplo, a regularização L2 (link em inglês) se baseia na crença a priori de que os pesos devem ser pequenos e normalmente distribuídos em torno de zero.
Pro
Um modelo do Gemini com menos parâmetros que o Ultra, mas mais parâmetros que o Nano. Consulte Gemini Pro para mais detalhes.
modelo de regressão probabilística
Um modelo de regressão que usa não apenas os pesos de cada recurso, mas também a incerteza desses pesos. Um modelo de regressão probabilística gera uma previsão e a incerteza dela. Por exemplo, um modelo de regressão probabilística pode gerar uma previsão de 325 com um desvio padrão de 12. Para mais informações sobre modelos de regressão probabilística, consulte este Colab em tensorflow.org.
função da densidade de probabilidade
Uma função que identifica a frequência de amostras de dados com exatamente um valor específico. Quando os valores de um conjunto de dados são números de ponto flutuante contínuos, as correspondências exatas raramente ocorrem. No entanto, integrar uma função de densidade de probabilidade do valor x ao valor y gera a frequência esperada de amostras de dados entre x e y.
Por exemplo, considere uma distribuição normal com média de 200 e desvio padrão de 30. Para determinar a frequência esperada de amostras de dados que estão no intervalo de 211,4 a 218,7, é possível integrar a função de densidade de probabilidade de uma distribuição normal de 211,4 a 218,7.
comando
Qualquer texto inserido como entrada em um modelo de linguagem grande para condicionar o modelo a se comportar de uma determinada maneira. Os comandos podem ser tão curtos quanto uma frase ou arbitrariamente longos (por exemplo, o texto inteiro de um romance). Os comandos se enquadram em várias categorias, incluindo as mostradas na tabela a seguir:
| Categoria de comando | Exemplo | Observações |
|---|---|---|
| Pergunta | A que velocidade um pombo consegue voar? | |
| Instrução | Escreva um poema engraçado sobre arbitragem. | Um comando que pede ao modelo de linguagem grande para fazer algo. |
| Exemplo | Traduza o código Markdown para HTML. Por exemplo:
Markdown: * item da lista HTML: <ul> <li>item da lista</li> </ul> |
A primeira frase neste exemplo é uma instrução. O restante do comando é o exemplo. |
| Papel | Explique por que o gradiente descendente é usado no treinamento de machine learning para um PhD em física. | A primeira parte da frase é uma instrução, e a frase "para um PhD em Física" é a parte da função. |
| Entrada parcial para o modelo concluir | O primeiro-ministro do Reino Unido mora em | Um comando de entrada parcial pode terminar abruptamente (como neste exemplo) ou com um sublinhado. |
Um modelo de IA generativa pode responder a um comando com texto, código, imagens, embeddings, vídeos… quase tudo.
aprendizagem baseada em comandos
Uma capacidade de determinados modelos que permite adaptar o comportamento em resposta a entradas de texto arbitrárias (comandos). Em um paradigma típico de aprendizado baseado em comandos, um modelo de linguagem grande responde a um comando gerando texto. Por exemplo, suponha que um usuário insira o seguinte comando:
Resuma a terceira lei de Newton.
Um modelo capaz de aprendizado baseado em comandos não é treinado especificamente para responder ao comando anterior. Em vez disso, o modelo "conhece" muitos fatos sobre física, muitas regras gerais de linguagem e muito sobre o que constitui respostas geralmente úteis. Esse conhecimento é suficiente para fornecer uma resposta (esperamos) útil. Outros feedbacks humanos ("Essa resposta foi muito complicada" ou "O que é uma reação?") permitem que alguns sistemas de aprendizado baseados em comandos melhorem gradualmente a utilidade das respostas.
design de comandos
Sinônimo de engenharia de comando.
engenharia de comando
A arte de criar comandos que extraem as respostas desejadas de um modelo de linguagem grande. Os humanos fazem engenharia de comandos. Escrever comandos bem estruturados é essencial para garantir respostas úteis de um modelo de linguagem grande. A engenharia de prompts depende de muitos fatores, incluindo:
- O conjunto de dados usado para pré-treinar e possivelmente ajustar o modelo de linguagem grande.
- A temperatura e outros parâmetros de decodificação que o modelo usa para gerar respostas.
Design de comandos é sinônimo de engenharia de comandos.
Consulte Introdução à criação de comandos para mais detalhes sobre como escrever comandos úteis.
conjunto de comandos
Um grupo de comandos para avaliar um modelo de linguagem grande. Por exemplo, a ilustração a seguir mostra um conjunto de comandos com três opções:

Um bom conjunto de comandos consiste em uma coleção suficientemente "ampla" de comandos para avaliar completamente a segurança e a utilidade de um modelo de linguagem grande.
Consulte também conjunto de respostas.
ajuste de comandos
Um mecanismo de ajuste eficiente de parâmetros que aprende um "prefixo" que o sistema adiciona ao comando.
Uma variação do ajuste de comandos, às vezes chamado de ajuste de prefixo, é adicionar o prefixo a todas as camadas. Em contraste, a maioria dos ajustes de comandos apenas adiciona um prefixo à camada de entrada.
proxy (atributos sensíveis)
Um atributo usado como substituto de um atributo sensível. Por exemplo, o código postal de uma pessoa pode ser usado como um proxy para renda, raça ou etnia.rotulação indireta
Dados usados para aproximar rótulos não disponíveis diretamente em um conjunto de dados.
Por exemplo, suponha que você precise treinar um modelo para prever o nível de estresse dos funcionários. Seu conjunto de dados tem muitos recursos preditivos, mas não tem um rótulo chamado nível de estresse. Sem se intimidar, você escolhe "acidentes de trabalho" como um rótulo substituto para o nível de estresse. Afinal, funcionários sob alto estresse sofrem mais acidentes do que funcionários tranquilos. Ou não? Talvez os acidentes de trabalho aumentem e diminuam por vários motivos.
Como segundo exemplo, suponha que você queira que está chovendo? seja um rótulo booleano para seu conjunto de dados, mas ele não contém dados de chuva. Se houver fotos disponíveis, você poderá estabelecer imagens de pessoas carregando guarda-chuvas como um rótulo substituto para está chovendo? Esse é um bom marcador indireto? Talvez, mas pessoas de algumas culturas podem ter mais probabilidade de carregar guarda-chuvas para se proteger do sol do que da chuva.
Os rótulos de proxy geralmente são imperfeitos. Sempre que possível, escolha rótulos reais em vez de substitutos. No entanto, quando um rótulo real está ausente, escolha o rótulo substituto com muito cuidado, selecionando o candidato menos ruim.
Consulte Conjuntos de dados: rótulos no Curso intensivo de machine learning para mais informações.
função pura
Uma função cujas saídas são baseadas apenas nas entradas e que não tem efeitos colaterais. Especificamente, uma função pura não usa nem muda nenhum estado global, como o conteúdo de um arquivo ou o valor de uma variável fora da função.
As funções puras podem ser usadas para criar código thread-safe, o que é útil ao fragmentar o código do modelo em vários chips aceleradores.
Os métodos de transformação de função do JAX exigem que as funções de entrada sejam puras.
Q
Função Q
No aprendizado por reforço, a função que prevê o retorno esperado ao realizar uma ação em um estado e seguir uma determinada política.
A função Q também é conhecida como função de valor de estado-ação.
Q-learning
No aprendizado por reforço, um algoritmo permite que um agente aprenda a função Q ideal de um processo de decisão de Markov aplicando a equação de Bellman. O processo de decisão de Markov modela um ambiente.
quantil
Cada bucket em agrupamento por quantil.
agrupamento por classes de quantil
Distribuir os valores de um atributo em buckets para que cada bucket contenha o mesmo (ou quase o mesmo) número de exemplos. Por exemplo, a figura a seguir divide 44 pontos em quatro intervalos, cada um com 11 pontos. Para que cada bucket na figura contenha o mesmo número de pontos, alguns buckets abrangem uma largura diferente de valores de x.

Consulte Dados numéricos: agrupamento em intervalos no Curso intensivo de machine learning para mais informações.
quantização
Termo sobrecarregado que pode ser usado de qualquer uma das seguintes maneiras:
- Implementar agrupamento por quantil em um recurso específico.
- Transformar dados em zeros e uns para armazenamento, treinamento e inferência mais rápidos. Como os dados booleanos são mais robustos a ruídos e erros do que outros formatos, a quantização pode melhorar a correção do modelo. As técnicas de quantização incluem arredondamento, truncamento e agrupamento por classes.
Reduzir o número de bits usados para armazenar os parâmetros de um modelo. Por exemplo, suponha que os parâmetros de um modelo sejam armazenados como números de ponto flutuante de 32 bits. A quantização converte esses parâmetros de 32 bits para 4, 8 ou 16 bits. A quantização reduz o seguinte:
- Uso de computação, memória, disco e rede
- Tempo para inferir uma previsão
- Consumo de energia
No entanto, às vezes, a quantização diminui a correção das previsões de um modelo.
fila
Uma operação do TensorFlow que implementa uma estrutura de dados de fila. Normalmente usado em E/S.
R
RAG
Abreviação de geração aumentada de recuperação.
floresta aleatória
Um conjunto de árvores de decisão em que cada árvore é treinada com um ruído aleatório específico, como bagging.
As florestas aleatórias são um tipo de floresta de decisão.
Consulte Floresta aleatória no curso "Florestas de decisão" para mais informações.
política aleatória
No aprendizado por reforço, uma política que escolhe uma ação aleatória.
rank (ordinality)
A posição ordinal de uma classe em um problema de machine learning que categoriza classes do maior para o menor. Por exemplo, um sistema de classificação de comportamento pode classificar as recompensas de um cachorro do maior (um bife) ao menor (couve murcha).
rank (Tensor)
O número de dimensões em um Tensor. Por exemplo, um escalar tem classificação 0, um vetor tem classificação 1 e uma matriz tem classificação 2.
Não confunda com classificação (ordinalidade).
ranking
Um tipo de aprendizado supervisionado cujo objetivo é ordenar uma lista de itens.
rotulador
Uma pessoa que fornece rótulos para exemplos. "Anotador" é outro nome para avaliador.
Consulte Dados categóricos: problemas comuns no Curso intensivo de machine learning para mais informações.
Interpretação de texto com o conjunto de dados de raciocínio de senso comum (ReCoRD)
Um conjunto de dados para avaliar a capacidade de um LLM de realizar raciocínio de senso comum. Cada exemplo no conjunto de dados contém três componentes:
- Um ou dois parágrafos de uma matéria
- Uma consulta em que uma das entidades identificadas explícita ou implicitamente na passagem está mascarada.
- A resposta (o nome da entidade que pertence à máscara)
Consulte ReCoRD para ver uma lista extensa de exemplos.
O ReCoRD é um componente do conjunto SuperGLUE.
RealToxicityPrompts
Um conjunto de dados que contém um conjunto de inícios de frases que podem ter conteúdo tóxico. Use esse conjunto de dados para avaliar a capacidade de um LLM de gerar texto não tóxico para completar a frase. Normalmente, você usa a API Perspective para determinar o desempenho do LLM nessa tarefa.
Consulte RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models para mais detalhes.
recall
Uma métrica para modelos de classificação que responde à seguinte pergunta:
Quando a informação empírica era a classe positiva, qual porcentagem de previsões o modelo identificou corretamente como a classe positiva?
Esta é a fórmula:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
em que:
- verdadeiro positivo significa que o modelo previu corretamente a classe positiva.
- Um falso negativo significa que o modelo previu incorretamente a classe negativa.
Por exemplo, suponha que seu modelo tenha feito 200 previsões em exemplos para os quais a verdade fundamental era a classe positiva. Das 200 previsões:
- 180 eram verdadeiros positivos.
- 20 eram falsos negativos.
Neste caso:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Consulte Classificação: acurácia, recall, precisão e métricas relacionadas para mais informações.
recall em k (recall@k)
Uma métrica para avaliar sistemas que geram uma lista classificada (ordenada) de itens. O recall em k identifica a fração de itens relevantes nos primeiros k itens da lista em relação ao número total de itens relevantes retornados.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Contraste com precisão em k.
Reconhecimento de implicação textual (RTE, na sigla em inglês)
Um conjunto de dados para avaliar a capacidade de um LLM de determinar se uma hipótese pode ser deduzida (extraída logicamente) de uma passagem de texto. Cada exemplo em uma avaliação de RTE consiste em três partes:
- Um trecho, geralmente de notícias ou artigos da Wikipédia
- Uma hipótese
- A resposta correta, que é:
- Verdadeiro, ou seja, a hipótese pode ser deduzida da passagem
- Falso, ou seja, a hipótese não pode ser inferida da passagem
Exemplo:
- Trecho:o euro é a moeda da União Europeia.
- Hipótese:a França usa o euro como moeda.
- Entailment:verdadeiro, porque a França faz parte da União Europeia.
O RTE é um componente do conjunto SuperGLUE.
sistema de recomendação
Um sistema que seleciona para cada usuário um conjunto relativamente pequeno de itens desejáveis de um grande corpus. Por exemplo, um sistema de recomendação de vídeos pode recomendar dois vídeos de um corpus de 100.000 vídeos, selecionando Casablanca e Uma Cilada para Johnson para um usuário, e Mulher-Maravilha e Pantera Negra para outro. Um sistema de recomendação de vídeos pode basear as sugestões em fatores como:
- Filmes que usuários semelhantes classificaram ou assistiram.
- Gênero, diretores, atores, grupo demográfico desejado...
Consulte o curso sobre sistemas de recomendação para mais informações.
ReCoRD
Abreviação de Reading Comprehension with Commonsense Reasoning Dataset.
Unidade linear retificada (ReLU)
Uma função de ativação com o seguinte comportamento:
- Se a entrada for negativa ou zero, a saída será 0.
- Se a entrada for positiva, a saída será igual à entrada.
Exemplo:
- Se a entrada for -3, a saída será 0.
- Se a entrada for +3, a saída será 3,0.
Confira um gráfico da ReLU:
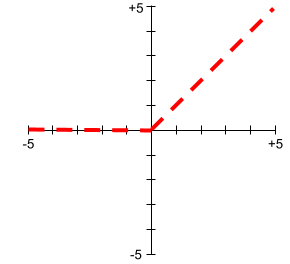
A ReLU é uma função de ativação muito conhecida. Apesar do comportamento simples, a ReLU ainda permite que uma rede neural aprenda relações não lineares entre atributos e o rótulo.
rede neural recorrente
Uma rede neural que é executada várias vezes de propósito, em que partes de cada execução alimentam a próxima. Especificamente, as camadas ocultas da execução anterior fornecem parte da entrada para a mesma camada oculta na próxima execução. As redes neurais recorrentes são especialmente úteis para avaliar sequências. Assim, as camadas ocultas podem aprender com execuções anteriores da rede neural em partes anteriores da sequência.
Por exemplo, a figura a seguir mostra uma rede neural recorrente que é executada quatro vezes. Os valores aprendidos nas camadas ocultas da primeira execução se tornam parte da entrada das mesmas camadas ocultas na segunda execução. Da mesma forma, os valores aprendidos na camada oculta na segunda execução se tornam parte da entrada para a mesma camada oculta na terceira execução. Dessa forma, a rede neural recorrente treina e prevê gradualmente o significado de toda a sequência, e não apenas o significado de palavras individuais.

texto de referência
A resposta de um especialista a um comando. Por exemplo, considerando o seguinte comando:
Traduza a pergunta "What is your name?" do inglês para o francês.
A resposta de um especialista pode ser:
Comment vous appelez-vous?
Várias métricas (como ROUGE) medem o grau em que o texto de referência corresponde ao texto gerado de um modelo de ML.
reflexão
Uma estratégia para melhorar a qualidade de um fluxo de trabalho de agente examinando (refletindo sobre) a saída de uma etapa antes de passar para a próxima.
O examinador geralmente é o mesmo LLM que gerou a resposta (embora possa ser um LLM diferente). Como o mesmo LLM que gerou uma resposta pode ser um juiz imparcial dela? O "truque" é colocar o LLM em uma mentalidade crítica (reflexiva). Esse processo é semelhante a um escritor que usa uma mentalidade criativa para escrever um primeiro rascunho e depois muda para uma mentalidade crítica para editá-lo.
Por exemplo, imagine um fluxo de trabalho com agentes em que a primeira etapa é criar texto para xícaras de café. O comando para esta etapa pode ser:
Você é um criativo. Gere um texto original e divertido de menos de 50 caracteres adequado para uma xícara de café.
Agora imagine o seguinte comando reflexivo:
Você gosta de café. Você acharia a resposta anterior engraçada?
O fluxo de trabalho pode passar apenas o texto que recebe uma pontuação alta de reflexão para a próxima etapa.
modelo de regressão
Informalmente, um modelo que gera uma previsão numérica. Em contraste, um modelo de classificação gera uma previsão de classe. Por exemplo, todos os modelos a seguir são de regressão:
- Um modelo que prevê o valor de uma determinada casa em euros, como 423.000.
- Um modelo que prevê a expectativa de vida de uma determinada árvore em anos, como 23,2.
- Um modelo que prevê a quantidade de chuva em polegadas que vai cair em uma determinada cidade nas próximas seis horas, como 0,18.
Dois tipos comuns de modelos de regressão são:
- Regressão linear, que encontra a linha que melhor se ajusta aos valores de rótulo e aos recursos.
- Regressão logística, que gera uma probabilidade entre 0,0 e 1,0 que um sistema normalmente mapeia para uma previsão de classe.
Nem todo modelo que gera previsões numéricas é um modelo de regressão. Em alguns casos, uma previsão numérica é apenas um modelo de classificação que tem nomes de classes numéricos. Por exemplo, um modelo que prevê um CEP numérico é um modelo de classificação, não de regressão.
regularização
Qualquer mecanismo que reduza o overfitting. Os tipos mais usados de regularização incluem:
- Regularização L1
- Regularização de L2
- regularização por dropout
- Interrupção antecipada: não é um método formal de regularização, mas pode limitar o overfitting de maneira eficaz.
A regularização também pode ser definida como a penalidade na complexidade de um modelo.
Consulte Overfitting: complexidade do modelo no Curso intensivo de machine learning para mais informações.
taxa de regularização
Um número que especifica a importância relativa da regularização durante o treinamento. Aumentar a taxa de regularização reduz o overfitting, mas pode diminuir o poder preditivo do modelo. Por outro lado, reduzir ou omitir a taxa de regularização aumenta o overfitting.
Consulte Overfitting: regularização L2 no Curso intensivo de machine learning para mais informações.
aprendizado por reforço (RL)
Uma família de algoritmos que aprendem uma política ideal, cujo objetivo é maximizar o retorno ao interagir com um ambiente. Por exemplo, a recompensa final da maioria dos jogos é a vitória. Os sistemas de aprendizado por reforço podem se tornar especialistas em jogos complexos avaliando sequências de movimentos anteriores que levaram a vitórias e derrotas.
Aprendizado por reforço com feedback humano (RLHF)
Usar o feedback de avaliadores humanos para melhorar a qualidade das respostas de um modelo. Por exemplo, um mecanismo de RLHF pode pedir aos usuários para avaliar a qualidade da resposta de um modelo com um emoji 👍 ou 👎. Assim, o sistema pode ajustar as respostas futuras com base nesse feedback.
ReLU
Abreviação de Unidade Linear Retificada.
buffer de repetição
Em algoritmos semelhantes ao DQN, a memória usada pelo agente para armazenar transições de estado e usar na repetição de experiência.
réplica
Uma cópia (ou parte) de um conjunto de treinamento ou modelo, geralmente armazenado em outra máquina. Por exemplo, um sistema pode usar a seguinte estratégia para implementar o paralelismo de dados:
- Colocar réplicas de um modelo em várias máquinas.
- Envie diferentes subconjuntos do conjunto de treinamento para cada réplica.
- Agregue as atualizações do parâmetro.
Uma réplica também pode se referir a outra cópia de um servidor de inferência. Aumentar o número de réplicas aumenta a quantidade de solicitações que o sistema pode atender simultaneamente, mas também aumenta os custos de veiculação.
viés de relatório
O fato de que a frequência com que as pessoas escrevem sobre ações, resultados ou propriedades não é um reflexo das frequências no mundo real ou do grau em que uma propriedade é característica de uma classe de indivíduos. O viés de relatório pode influenciar a composição dos dados que os sistemas de machine learning aprendem.
Por exemplo, em livros, a palavra riu é mais comum do que respirou. Um modelo de machine learning que estima a frequência relativa de risadas e respiração em um corpus de livros provavelmente determinaria que rir é mais comum do que respirar.
Consulte Imparcialidade: tipos de viés no Curso intensivo de machine learning para mais informações.
representação de vetor
O processo de mapear dados para recursos úteis.
reclassificação
A etapa final de um sistema de recomendação, em que os itens classificados podem ser reavaliados de acordo com outro algoritmo (normalmente, não de ML). O reordenamento avalia a lista de itens gerada pela fase de pontuação, realizando ações como:
- Eliminar itens que o usuário já comprou.
- Aumentar a pontuação de itens mais recentes.
Consulte Reclassificação no curso "Sistemas de recomendação" para mais informações.
resposta
O texto, as imagens, o áudio ou o vídeo que um modelo de IA generativa infere. Em outras palavras, um comando é a entrada para um modelo de IA generativa, e a resposta é a saída.
conjunto de respostas
O conjunto de respostas que um modelo de linguagem grande retorna para um conjunto de comandos de entrada.
geração aumentada por recuperação (RAG)
Uma técnica para melhorar a qualidade da saída de um modelo de linguagem grande (LLM), embasando o resultado com fontes de conhecimento recuperadas após o treinamento do modelo. A RAG melhora a acurácia das respostas do LLM ao fornecer ao LLM treinado acesso a informações recuperadas de bases de conhecimento ou documentos confiáveis.
Alguns motivos comuns para usar a geração aumentada de recuperação:
- Aumentar a acurácia factual das respostas geradas por um modelo.
- Dar ao modelo acesso a conhecimentos com os quais ele não foi treinado.
- Mudar o conhecimento usado pelo modelo.
- Permitir que o modelo cite fontes.
Por exemplo, suponha que um app de química use a API PaLM para gerar resumos relacionados a consultas do usuário. Quando o back-end do app recebe uma consulta, ele:
- Pesquisa ("recupera") dados relevantes para a consulta do usuário.
- Adiciona ("aumenta") os dados de química relevantes à consulta do usuário.
- Instrui o LLM a criar um resumo com base nos dados anexados.
return
No aprendizado por reforço, considerando uma determinada política e um determinado estado, o retorno é a soma de todas as recompensas que o agente espera receber ao seguir a política do estado até o final do episódio. O agente considera a natureza atrasada das recompensas esperadas descontando-as de acordo com as transições de estado necessárias para obtê-las.
Portanto, se o fator de desconto for \(\gamma\), e \(r_0, \ldots, r_{N}\) denotar as recompensas até o final do episódio, o cálculo do retorno será o seguinte:
prêmio
No aprendizado por reforço, o resultado numérico de uma ação em um estado, conforme definido pelo ambiente.
regularização Ridge
Sinônimo de regularização L2. O termo regularização de ridge é mais usado em contextos de estatística pura, enquanto regularização de L2 é mais comum em machine learning.
RNN
Abreviação de redes neurais recorrentes.
Curva ROC
Um gráfico da taxa de verdadeiro positivo em relação à taxa de falso positivo para diferentes limiares de classificação na classificação binária.
O formato de uma curva ROC sugere a capacidade de um modelo de classificação binária de separar classes positivas de negativas. Por exemplo, suponha que um modelo de classificação binária separe perfeitamente todas as classes negativas de todas as positivas:
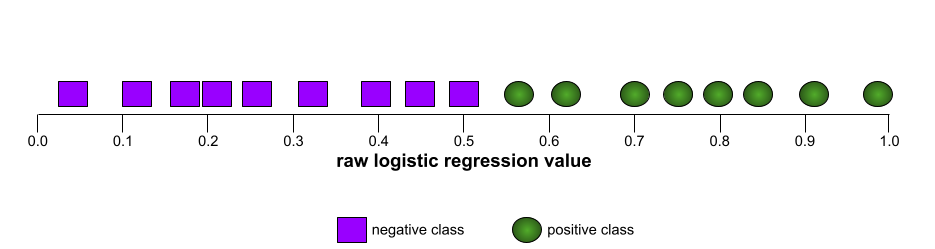
A curva ROC do modelo anterior é assim:
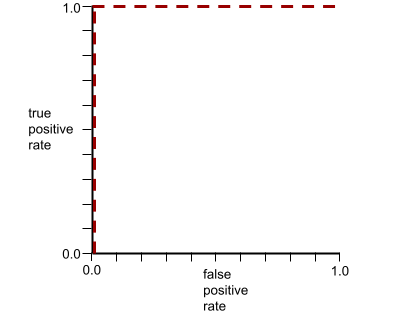
Em contraste, a ilustração a seguir mostra os valores brutos de regressão logística de um modelo ruim que não consegue separar classes negativas de positivas:
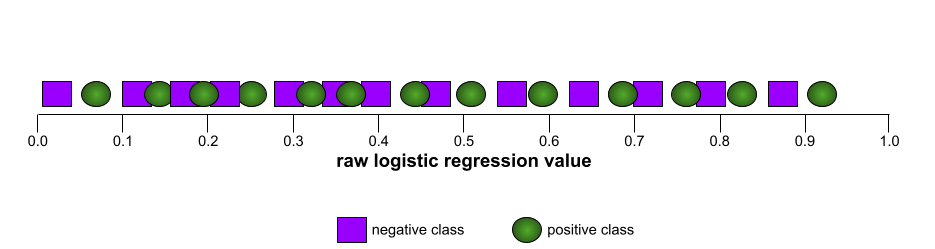
A curva ROC para esse modelo é assim:
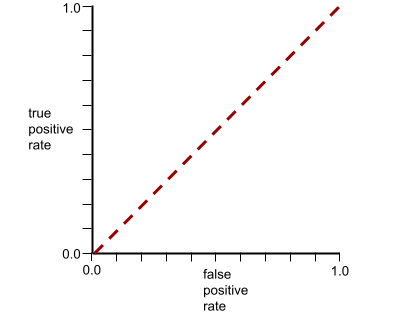
Enquanto isso, no mundo real, a maioria dos modelos de classificação binária separa classes positivas e negativas até certo ponto, mas geralmente não de forma perfeita. Assim, uma curva ROC típica fica entre os dois extremos:
O ponto em uma curva ROC mais próximo de (0,0, 1,0) identifica teoricamente o limite de classificação ideal. No entanto, vários outros problemas do mundo real influenciam a seleção do limite de classificação ideal. Por exemplo, talvez os falsos negativos causem muito mais problemas do que os falsos positivos.
Uma métrica numérica chamada AUC resume a curva ROC em um único valor de ponto flutuante.
criação de comandos de papel
Um comando, geralmente começando com o pronome você, que diz a um modelo de IA generativa para fingir ser uma determinada pessoa ou função ao gerar a resposta. Os comandos de função podem ajudar um modelo de IA generativa a entrar no "estado de espírito" certo para gerar uma resposta mais útil. Por exemplo, qualquer um dos seguintes comandos de função pode ser adequado, dependendo do tipo de resposta que você está procurando:
Você tem um PhD em ciência da computação.
Você é um engenheiro de software que gosta de dar explicações pacientes sobre Python para novos estudantes de programação.
Você é um herói de ação com um conjunto muito específico de habilidades de programação. Me garanta que você vai encontrar um item específico em uma lista do Python.
root
O nó inicial (a primeira condição) em uma árvore de decisão. Por convenção, os diagramas colocam a raiz na parte de cima da árvore de decisões. Exemplo:

diretório raiz
O diretório especificado para hospedar subdiretórios do ponto de verificação do TensorFlow e arquivos de eventos de vários modelos.
Raiz do erro quadrático médio (RMSE)
A raiz quadrada do erro quadrático médio.
invariância rotacional
Em um problema de classificação de imagens, é a capacidade de um algoritmo classificar imagens com sucesso mesmo quando a orientação delas muda. Por exemplo, o algoritmo ainda pode identificar uma raquete de tênis, mesmo que ela esteja apontando para cima, para baixo ou para os lados. A invariância de rotação nem sempre é desejável. Por exemplo, um 9 de cabeça para baixo não deve ser classificado como um 9.
Consulte também invariância de translação e invariância de tamanho.
Recall-Oriented Understudy for Gisting Evaluation (ROUGE, na sigla em inglês)
Uma família de métricas que avaliam modelos de resumo automático e tradução automática. As métricas ROUGE determinam o grau em que um texto de referência se sobrepõe ao texto gerado de um modelo de ML. Cada membro da família ROUGE mede a sobreposição de uma maneira diferente. Pontuações ROUGE mais altas indicam mais similaridade entre o texto de referência e o texto gerado do que pontuações ROUGE mais baixas.
Cada membro da família ROUGE geralmente gera as seguintes métricas:
- Precisão
- Recall
- F1
Para detalhes e exemplos, consulte:
ROUGE-L
Um membro da família ROUGE (em inglês) focado no comprimento da maior subsequência comum no texto de referência e no texto gerado. As fórmulas a seguir calculam o recall e a precisão para ROUGE-L:
Em seguida, use F1 para resumir o recall e a precisão do ROUGE-L em uma única métrica:
O ROUGE-L ignora todas as novas linhas no texto de referência e no texto gerado. Assim, a maior subsequência comum pode abranger várias frases. Quando o texto de referência e o texto gerado envolvem várias frases, uma variação do ROUGE-L chamada ROUGE-Lsum geralmente é uma métrica melhor. O ROUGE-Lsum determina a maior subsequência comum para cada frase em uma passagem e calcula a média dessas maiores subsequências comuns.
ROUGE-N
Um conjunto de métricas da família ROUGE que compara os N-gramas compartilhados de um determinado tamanho no texto de referência e no texto gerado. Exemplo:
- ROUGE-1 mede o número de tokens compartilhados no texto de referência e no texto gerado.
- ROUGE-2 mede o número de bigramas (2-gramas) compartilhados no texto de referência e no texto gerado.
- ROUGE-3 mede o número de trigramas (3-gramas) compartilhados no texto de referência e no texto gerado.
Você pode usar as seguintes fórmulas para calcular o recall e a precisão de ROUGE-N para qualquer membro da família ROUGE-N:
Em seguida, use F1 para agregar o recall e a precisão do ROUGE-N em uma única métrica:
ROUGE-S
Uma forma tolerante de ROUGE-N que permite a correspondência de skip-gram. Ou seja, o ROUGE-N conta apenas N-gramas que correspondem exatamente, mas o ROUGE-S também conta N-gramas separados por uma ou mais palavras. Por exemplo, considere o seguinte:
- texto de referência: Nuvens brancas
- Texto gerado: Nuvens brancas e onduladas
Ao calcular o ROUGE-N, o 2-grama Nuvens brancas não corresponde a Nuvens brancas e onduladas. No entanto, ao calcular o ROUGE-S, Nuvens brancas corresponde a Nuvens brancas e onduladas.
R ao quadrado
Uma métrica de regressão que indica o quanto da variação em um rótulo se deve a um atributo individual ou a um conjunto de atributos. O R ao quadrado é um valor entre 0 e 1, que pode ser interpretado da seguinte maneira:
- Um R ao quadrado de 0 significa que nada da variação de um rótulo se deve ao conjunto de atributos.
- Um R ao quadrado de 1 significa que toda a variação de um rótulo se deve ao conjunto de atributos.
- Um R ao quadrado entre 0 e 1 indica o quanto da variação de um rótulo pode ser previsto a partir de um atributo específico ou do conjunto de atributos. Por exemplo, um R ao quadrado de 0,10 significa que 10% da variância no rótulo se deve ao conjunto de atributos. Um R ao quadrado de 0,20 significa que 20% se deve ao conjunto de atributos, e assim por diante.
R ao quadrado é o quadrado do coeficiente de correlação de Pearson entre os valores previstos por um modelo e a verdade fundamental.
RTE
Abreviação de Recognizing Textual Entailment.
S
viés de amostragem
Consulte viés de seleção.
amostragem com substituição
Um método de escolha de itens de um conjunto de itens candidatos em que o mesmo item pode ser escolhido várias vezes. A frase "com substituição" significa que, após cada seleção, o item escolhido é retornado ao conjunto de itens candidatos. O método inverso, amostragem sem substituição, significa que um item candidato só pode ser escolhido uma vez.
Por exemplo, considere o seguinte conjunto de frutas:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}Suponha que o sistema escolha aleatoriamente fig como o primeiro item.
Se você estiver usando amostragem com substituição, o sistema vai escolher o segundo item do seguinte conjunto:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}Sim, é o mesmo conjunto de antes. Portanto, o sistema pode escolher fig novamente.
Se você usar amostragem sem substituição, uma amostra escolhida não poderá ser selecionada novamente. Por exemplo, se o sistema escolher aleatoriamente fig como a primeira amostra, fig não poderá ser escolhido novamente. Portanto, o sistema escolhe a segunda amostra do seguinte conjunto (reduzido):
fruit = {kiwi, apple, pear, cherry, lime, mango}SavedModel
O formato recomendado para salvar e recuperar modelos do TensorFlow. O SavedModel é um formato de serialização recuperável e independente de linguagem que permite que sistemas e ferramentas de nível superior produzam, consumam e transformem modelos do TensorFlow.
Consulte a seção Salvar e restaurar do Guia do programador do TensorFlow para mais detalhes.
Econômico
Um objeto do TensorFlow responsável por salvar pontos de verificação do modelo.
escalar
Um único número ou uma única string que pode ser representada como um tensor de rank 0. Por exemplo, as linhas de código a seguir criam um escalar no TensorFlow:
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)escalonamento
Qualquer transformação ou técnica matemática que mude o intervalo de um rótulo, um valor de atributo ou ambos. Algumas formas de escalonamento são muito úteis para transformações como a normalização.
Algumas formas comuns de escalonamento úteis em machine learning incluem:
- escalonamento linear, que geralmente usa uma combinação de subtração e divisão para substituir o valor original por um número entre -1 e +1 ou entre 0 e 1.
- Escalonamento logarítmico, que substitui o valor original pelo logaritmo dele.
- Normalização de pontuação Z, que substitui o valor original por um valor de ponto flutuante que representa o número de desvios padrão da média desse recurso.
scikit-learn
Uma plataforma de machine learning de código aberto muito usada. Consulte scikit-learn.org.
em lote
A parte de um sistema de recomendação que fornece um valor ou classificação para cada item produzido pela fase de geração de candidatos.
viés de seleção
Erros em conclusões extraídas de dados amostrados devido a um processo de seleção que gera diferenças sistemáticas entre amostras observadas nos dados e aquelas não observadas. Existem as seguintes formas de viés de seleção:
- Viés de cobertura: a população representada no conjunto de dados não corresponde à população sobre a qual o modelo de machine learning faz previsões.
- Viés de amostragem: os dados não são coletados aleatoriamente do grupo de destino.
- Viés de não resposta (também chamado de viés de participação): usuários de determinados grupos desativam as pesquisas em taxas diferentes de usuários de outros grupos.
Por exemplo, suponha que você esteja criando um modelo de machine learning que prevê se as pessoas vão gostar de um filme. Para coletar dados de treinamento, você distribui uma pesquisa para todos na primeira fila de um teatro que está exibindo o filme. À primeira vista, essa pode parecer uma maneira razoável de reunir um conjunto de dados. No entanto, essa forma de coleta pode introduzir as seguintes formas de viés de seleção:
- Viés de cobertura: ao fazer uma amostragem de uma população que escolheu assistir o filme, as previsões do seu modelo podem não ser generalizadas para pessoas que não expressaram esse nível de interesse no filme.
- viés de amostragem: em vez de fazer uma amostragem aleatória da população pretendida (todas as pessoas no cinema), você amostrou apenas as pessoas na primeira fila. É possível que as pessoas sentadas na primeira fila estivessem mais interessadas no filme do que as de outras filas.
- Viés de não resposta: em geral, pessoas com opiniões fortes tendem a responder a pesquisas opcionais com mais frequência do que pessoas com opiniões leves. Como a pesquisa sobre filmes é opcional, as respostas têm mais probabilidade de formar uma distribuição bimodal do que uma distribuição normal (em forma de sino).
autoatenção (também chamada de camada de autoatenção)
Uma camada de rede neural que transforma uma sequência de embeddings (por exemplo, embeddings de token) em outra sequência de embeddings. Cada incorporação na sequência de saída é construída integrando informações dos elementos da sequência de entrada por um mecanismo de atenção.
A parte self da autoatenção se refere à sequência que atende a si mesma, e não a algum outro contexto. A autoatenção é um dos principais blocos de construção para Transformadores e usa terminologia de pesquisa de dicionário, como "consulta", "chave" e "valor".
Uma camada de autoatenção começa com uma sequência de representações de entrada, uma para cada palavra. A representação de entrada de uma palavra pode ser um simples incorporação. Para cada palavra em uma sequência de entrada, a rede avalia a relevância da palavra para todos os elementos na sequência inteira de palavras. As pontuações de relevância determinam o quanto a representação final da palavra incorpora as representações de outras palavras.
Por exemplo, considere a seguinte frase:
O animal não atravessou a rua porque estava muito cansado.
A ilustração a seguir (de Transformer: A Novel Neural Network Architecture for Language Understanding) mostra o padrão de atenção de uma camada de autoatenção para o pronome it, com a intensidade de cada linha indicando o quanto cada palavra contribui para a representação:
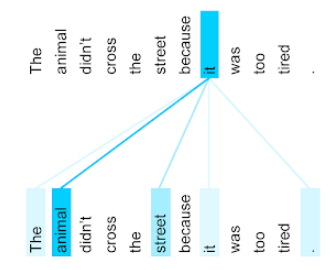
A camada de autoatenção destaca palavras relevantes para "it". Nesse caso, a camada de atenção aprendeu a destacar palavras a que ela pode se referir, atribuindo o peso mais alto a animal.
Para uma sequência de n tokens, a autoatenção transforma uma sequência de embeddings n vezes separadas, uma vez em cada posição na sequência.
Consulte também atenção e autoatenção multihead.
aprendizado autossupervisionado
Uma família de técnicas para converter um problema de aprendizado de máquina não supervisionado em um problema de aprendizado de máquina supervisionado criando rótulos substitutos de exemplos sem rótulo.
Alguns modelos baseados em transformadores, como o BERT, usam o aprendizado autossupervisionado.
O treinamento autossupervisionado é uma abordagem de aprendizado semi-supervisionado.
autotreinamento
Uma variante do aprendizado autossupervisionado que é particularmente útil quando todas as condições a seguir são verdadeiras:
- A proporção de exemplos sem rótulo para exemplos rotulados no conjunto de dados é alta.
- Este é um problema de classificação.
O autoaprendizado funciona iterando as duas etapas a seguir até que o modelo pare de melhorar:
- Use o aprendizado de máquina supervisionado para treinar um modelo com os exemplos rotulados.
- Use o modelo criado na etapa 1 para gerar previsões (rótulos) nos exemplos sem rótulo, movendo aqueles em que há alta confiança para os exemplos com rótulo e o rótulo previsto.
Cada iteração da etapa 2 adiciona mais exemplos rotulados para a etapa 1 treinar.
aprendizado semi-supervisionado
Treinar um modelo em dados em que alguns exemplos de treinamento têm rótulos, mas outros não. Uma técnica de aprendizado semi-supervisionado é inferir rótulos para os exemplos sem rótulo e treinar com base neles para criar um novo modelo. O aprendizado semi-supervisionado pode ser útil se os rótulos forem caros de obter, mas houver muitos exemplos sem rótulo.
O autotreinamento é uma técnica de aprendizado semi-supervisionado.
atributo sensível
Um atributo humano que pode receber atenção especial por motivos legais, éticos, sociais ou pessoais.análise de sentimento
Uso de algoritmos estatísticos ou de aprendizado de máquina para determinar a atitude geral de um grupo (positiva ou negativa) em relação a um serviço, produto, organização ou tema. Por exemplo, usando o processamento de linguagem natural, um algoritmo pode fazer uma análise de sentimento do feedback textual de um curso universitário para determinar o grau em que os estudantes gostaram ou não do curso.
Consulte o guia de classificação de texto para mais informações.
modelo sequencial
Um modelo cujas entradas têm uma dependência sequencial. Por exemplo, prever o próximo vídeo assistido com base em uma sequência de vídeos assistidos anteriormente.
tarefa de sequência para sequência
Uma tarefa que converte uma sequência de entrada de tokens em uma sequência de saída de tokens. Por exemplo, dois tipos comuns de tarefas de sequência para sequência são:
- Tradutores:
- Sequência de entrada de exemplo: "I love you."
- Exemplo de sequência de saída: "Je t'aime".
- Respostas a perguntas:
- Exemplo de sequência de entrada: "Preciso do meu carro em Nova York?"
- Exemplo de sequência de saída: "Não. Deixe o carro em casa".
do modelo
O processo de disponibilizar um modelo treinado para fornecer previsões por inferência on-line ou off-line.
shape (Tensor)
O número de elementos em cada dimensão de um tensor. A forma é representada como uma lista de números inteiros. Por exemplo, o tensor bidimensional a seguir tem uma forma de [3,4]:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
O TensorFlow usa o formato de linha principal (estilo C) para representar a ordem das dimensões. Por isso, o formato no TensorFlow é [3,4] em vez de [4,3]. Em outras palavras, em um tensor bidimensional do TensorFlow, a forma é [número de linhas, número de colunas].
Uma forma estática é uma forma de tensor que é conhecida no momento da compilação.
Uma forma dinâmica é desconhecida no momento da compilação e, portanto, depende de dados de tempo de execução. Esse tensor pode ser representado com uma dimensão de marcador de posição no TensorFlow, como em [3, ?].
fragmento
Uma divisão lógica do conjunto de treinamento ou do modelo. Normalmente, algum processo cria fragmentos dividindo os exemplos ou parâmetros em partes (geralmente) de tamanho igual. Em seguida, cada fragmento é atribuído a uma máquina diferente.
A fragmentação de um modelo é chamada de paralelismo de modelos. Já a fragmentação de dados é chamada de paralelismo de dados.
encolhimento
Um hiperparâmetro no gradient boosting que controla o overfitting. A redução em gradient boosting é análoga à taxa de aprendizado no gradiente descendente. A redução é um valor decimal entre 0,0 e 1,0. Um valor de redução menor reduz o overfitting mais do que um valor maior.
avaliação lado a lado
Comparar a qualidade de dois modelos julgando as respostas ao mesmo comando. Por exemplo, suponha que o seguinte comando seja dado a dois modelos diferentes:
Crie a imagem de um cachorro fofo malabarizando três bolas.
Em uma avaliação lado a lado, um avaliador escolhe qual imagem é "melhor" (mais precisa? Mais bonita? Mais fofo?).
função sigmoide
Uma função matemática que "comprime" um valor de entrada em um intervalo restrito, geralmente de 0 a 1 ou de -1 a +1. Ou seja, você pode transmitir qualquer número (dois, um milhão, um bilhão negativo, o que for) para uma sigmoide, e a saída ainda estará no intervalo restrito. Um gráfico da função de ativação sigmoide tem esta aparência:
A função sigmoide tem vários usos no aprendizado de máquina, incluindo:
- Converter a saída bruta de um modelo de regressão logística ou multinomial em uma probabilidade.
- Atuando como uma função de ativação em algumas redes neurais.
medida de similaridade
Em algoritmos de clustering, a métrica usada para determinar o grau de semelhança entre dois exemplos.
programa único / vários dados (SPMD)
Uma técnica de paralelismo em que a mesma computação é executada em diferentes dados de entrada em paralelo em dispositivos diferentes. O objetivo do SPMD é obter resultados mais rapidamente. É o estilo mais comum de programação paralela.
invariância de tamanho
Em um problema de classificação de imagens, é a capacidade de um algoritmo classificar imagens com sucesso mesmo quando o tamanho delas muda. Por exemplo, o algoritmo ainda pode identificar um gato, mesmo que ele consuma 2 milhões de pixels ou 200 mil pixels. Mesmo os melhores algoritmos de classificação de imagens ainda têm limites práticos na invariância de tamanho. Por exemplo, é improvável que um algoritmo (ou humano) classifique corretamente uma imagem de gato consumindo apenas 20 pixels.
Consulte também invariância translacional e invariância rotacional.
Consulte o curso sobre clustering para mais informações.
esboço
No aprendizado de máquina não supervisionado, uma categoria de algoritmos que realiza uma análise preliminar de similaridade em exemplos. Os algoritmos de esboço usam uma função de hash sensível à localidade para identificar pontos que provavelmente são semelhantes e os agrupam em intervalos.
O esboço diminui a computação necessária para cálculos de similaridade em grandes conjuntos de dados. Em vez de calcular a similaridade para cada par de exemplos no conjunto de dados, calculamos apenas para cada par de pontos em cada agrupamento.
skip-gram
Um n-grama que pode omitir (ou "pular") palavras do contexto original, ou seja, as N palavras podem não ter sido originalmente adjacentes. Mais precisamente, um "k-skip-n-gram" é um n-gram em que até k palavras podem ter sido ignoradas.
Por exemplo, "a raposa marrom ligeira" tem os seguintes 2-gramas possíveis:
- "os vivos"
- "rápido marrom"
- "raposa marrom"
Um "1-skip-2-gram" é um par de palavras que têm no máximo uma palavra entre elas. Portanto, "a raposa marrom ligeira" tem os seguintes 1-skip 2-gramas:
- "o marrom"
- "raposa rápida"
Além disso, todos os 2-gramas também são 1-skip-2-gramas, já que menos de uma palavra pode ser ignorada.
Os skip-grams são úteis para entender mais sobre o contexto de uma palavra. No exemplo, "fox" foi associado diretamente a "quick" no conjunto de 1-skip-2-grams, mas não no conjunto de 2-grams.
Os skip-grams ajudam a treinar modelos de embedding de palavras.
softmax
Uma função que determina probabilidades para cada classe possível em um modelo de classificação multiclasse. As probabilidades somam exatamente 1,0. Por exemplo, a tabela a seguir mostra como o softmax distribui várias probabilidades:
| A imagem é um(a)... | Probabilidade |
|---|---|
| cachorro | 0,85 |
| gato | .13 |
| cavalo | .02 |
A softmax também é chamada de softmax completa.
Contraste com a amostragem de candidatos.
Consulte Redes neurais: classificação multiclasse no Curso intensivo de machine learning para mais informações.
ajuste de comandos flexível
Uma técnica para ajustar um modelo de linguagem grande para uma tarefa específica, sem o ajuste fino, que exige muitos recursos. Em vez de treinar novamente todos os pesos no modelo, o ajuste de soft prompt ajusta automaticamente um comando para alcançar a mesma meta.
Dado um comando de texto, o ajuste de comandos leves geralmente anexa mais incorporações de token ao comando e usa backpropagation para otimizar a entrada.
Um comando "fixo" contém tokens reais em vez de embeddings de token.
atributo esparso
Um atributo cujos valores são predominantemente zero ou vazios. Por exemplo, um recurso que contém um único valor 1 e um milhão de valores 0 é esparso. Por outro lado, um atributo denso tem valores que predominantemente não são zero nem vazios.
Em machine learning, um número surpreendente de atributos são esparsos. Os atributos categóricos geralmente são esparsos. Por exemplo, das 300 espécies de árvores possíveis em uma floresta, um único exemplo pode identificar apenas um bordo. Ou, dos milhões de vídeos possíveis em uma biblioteca, um único exemplo pode identificar apenas "Casablanca".
Em um modelo, geralmente representamos atributos esparsos com codificação one-hot. Se a codificação one-hot for grande, coloque uma camada de incorporação em cima dela para aumentar a eficiência.
representação esparsa
Armazenar apenas as posições de elementos diferentes de zero em um recurso esparso.
Por exemplo, suponha que um recurso categórico chamado species identifique as 36 espécies de árvores em uma floresta específica. Além disso, suponha que cada exemplo identifique apenas uma espécie.
Você pode usar um vetor one-hot para representar as espécies de árvores em cada exemplo.
Um vetor one-hot teria um único 1 (para representar a espécie de árvore específica no exemplo) e 35 0s (para representar as 35 espécies de árvores não incluídas no exemplo). Assim, a representação one-hot de maple pode ser parecida com esta:

Como alternativa, a representação esparsa simplesmente identificaria a posição da espécie específica. Se maple estiver na posição 24, a representação esparsa de maple será simplesmente:
24
A representação esparsa é muito mais compacta do que a representação one-hot.
Clique no ícone para ver um exemplo um pouco mais complexo.
Suponha que cada exemplo no seu modelo precise representar as palavras, mas não a ordem delas, em uma frase em inglês. O inglês tem cerca de 170.000 palavras, então é um recurso categórico com aproximadamente 170.000 elementos. A maioria das frases em inglês usa uma fração extremamente pequena dessas 170.000 palavras. Portanto, o conjunto de palavras em um único exemplo quase certamente será de dados esparsos.
Considere a seguinte frase:
My dog is a great dog
Você pode usar uma variante de vetor one-hot para representar as palavras nesta frase. Nessa variante, várias células no vetor podem conter um valor diferente de zero. Além disso, nessa variante, uma célula pode conter um número inteiro diferente de um. Embora as palavras "meu", "é", "um" e "ótimo" apareçam apenas uma vez na frase, a palavra "cachorro" aparece duas vezes. Usar essa variante de vetores one-hot para representar as palavras nesta frase gera o seguinte vetor de 170.000 elementos:

Uma representação esparsa da mesma frase seria simplesmente:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Consulte Como trabalhar com dados categóricos no Curso intensivo de machine learning para mais informações.
vetor esparso
Um vetor com valores principalmente iguais a zero. Consulte também recurso esparso e esparsidade.
esparsidade
O número de elementos definidos como zero (ou nulo) em um vetor ou matriz dividido pelo número total de entradas nesse vetor ou matriz. Por exemplo, considere uma matriz de 100 elementos em que 98 células contêm zero. O cálculo da escassez é o seguinte:
A esparsidade de atributos se refere à esparsidade de um vetor de atributos, e a esparsidade de modelo se refere à esparsidade dos pesos do modelo.
pooling espacial
Consulte agrupamento.
codificação especificacional
O processo de escrever e manter um arquivo em uma linguagem humana (por exemplo, inglês) que descreve um software. Em seguida, peça a um modelo de IA generativa ou a outro engenheiro de software para criar o software que atenda a essa descrição.
O código gerado automaticamente geralmente requer iteração. Na programação especificacional, você itera no arquivo de descrição. Por outro lado, na programação por conversa, você itera na caixa de comando. Na prática, a geração automática de código às vezes envolve uma combinação de programação especificacional e conversacional.
dividir
Em uma árvore de decisão, outro nome para uma condição.
divisor
Ao treinar uma árvore de decisão, a rotina (e o algoritmo) responsável por encontrar a melhor condição em cada node.
SPMD
Abreviação de programa único / vários dados.
SQuAD
Acrônimo de Stanford Question Answering Dataset (em inglês), apresentado no artigo SQuAD: 100.000+ Questions for Machine Comprehension of Text (em inglês). As perguntas neste conjunto de dados são de pessoas que fazem perguntas sobre artigos da Wikipédia. Algumas perguntas no SQuAD têm respostas, mas outras não têm intencionalmente. Portanto, é possível usar o SQuAD para avaliar a capacidade de um LLM de fazer o seguinte:
- Responda às perguntas que podem ser respondidas.
- Identifique perguntas que não podem ser respondidas.
A correspondência exata em combinação com F1 são as métricas mais comuns para avaliar LLMs em relação ao SQuAD.
perda de articulação quadrática
O quadrado da perda de articulação. A perda de articulação quadrática penaliza os outliers com mais rigor do que a perda de articulação regular.
perda quadrática
Sinônimo de perda L2.
treinamento por etapas
Uma tática de treinamento de um modelo em uma sequência de etapas discretas. O objetivo pode ser acelerar o processo de treinamento ou alcançar uma melhor qualidade do modelo.
Confira abaixo uma ilustração da abordagem de empilhamento progressivo:
- A fase 1 tem 3 camadas ocultas, a fase 2 tem 6 camadas ocultas e a fase 3 tem 12 camadas ocultas.
- A etapa 2 começa o treinamento com os pesos aprendidos nas três camadas ocultas da etapa 1. A etapa 3 começa o treinamento com os pesos aprendidos nas seis camadas ocultas da etapa 2.
Consulte também encadeamento de comandos.
estado
No aprendizado por reforço, os valores de parâmetro que descrevem a configuração atual do ambiente, que o agente usa para escolher uma ação.
função de valor de estado-ação
Sinônimo de função Q.
static
Algo feito uma vez em vez de continuamente. Os termos estático e off-line são sinônimos. Confira a seguir usos comuns de estático e off-line no aprendizado de máquina:
- Um modelo estático (ou modelo off-line) é treinado uma vez e usado por um tempo.
- O treinamento estático (ou treinamento off-line) é o processo de treinamento de um modelo estático.
- A inferência estática (ou off-line) é um processo em que um modelo gera um lote de previsões por vez.
Contraste com dinâmico.
inferência estática
Sinônimo de inferência off-line.
estacionariedade
Um recurso cujos valores não mudam em uma ou mais dimensões, geralmente o tempo. Por exemplo, um recurso cujos valores parecem quase iguais em 2021 e 2023 apresenta estacionaridade.
No mundo real, pouquíssimos recursos apresentam estacionaridade. Até mesmo recursos sinônimos de estabilidade, como o nível do mar, mudam com o tempo.
Contraste com não estacionariedade.
etapa
Um encaminhamento e uma retropropagação de um lote.
Consulte backpropagation para mais informações sobre a transmissão direta e a transmissão reversa.
taxa de aprendizado
Sinônimo de taxa de aprendizado.
gradiente descendente estocástico (GDE)
Um algoritmo de gradiente descendente em que o tamanho do lote é um. Em outras palavras, o SGD treina em um único exemplo escolhido de maneira uniforme e aleatória de um conjunto de treinamento.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
stride
Em uma operação convolucional ou de pooling, o delta em cada dimensão da próxima série de intervalos de entrada. Por exemplo, a animação a seguir demonstra uma passada (1,1) durante uma operação convolucional. Portanto, a próxima fatia de entrada começa uma posição à direita da fatia anterior. Quando a operação atinge a borda direita, a próxima fatia fica totalmente à esquerda, mas uma posição abaixo.
O exemplo anterior demonstra uma passada bidimensional. Se a matriz de entrada for tridimensional, o stride também será tridimensional.
minimização de risco estrutural (SRM, na sigla em inglês)
Um algoritmo que equilibra duas metas:
- A necessidade de criar o modelo mais preditivo (por exemplo, com menor perda).
- A necessidade de manter o modelo o mais simples possível (por exemplo, regularização forte).
Por exemplo, uma função que minimiza a perda + regularização no conjunto de treinamento é um algoritmo de minimização de risco estrutural.
Contraste com a minimização do risco empírico.
subamostragem
Consulte agrupamento.
token de subpalavra
Em modelos de linguagem, um token é uma subcadeia de uma palavra, que pode ser a palavra inteira.
Por exemplo, uma palavra como "itemize" pode ser dividida em "item" (uma palavra raiz) e "ize" (um sufixo), cada uma representada por um token próprio. Dividir palavras incomuns em partes menores, chamadas de subpalavras, permite que os modelos de linguagem operem nas partes constituintes mais comuns da palavra, como prefixos e sufixos.
Por outro lado, palavras comuns como "indo" podem não ser divididas e podem ser representadas por um único token.
resumo
No TensorFlow, um valor ou conjunto de valores calculado em uma determinada etapa, geralmente usado para rastrear métricas do modelo durante o treinamento.
SuperGLUE
Um conjunto de dados para classificar a capacidade geral de um LLM de entender e gerar texto. O conjunto é composto pelos seguintes conjuntos de dados:
- Perguntas booleanas (BoolQ)
- CommitmentBank (CB)
- Escolha de alternativas plausíveis (COPA)
- Interpretação de texto com várias frases (MultiRC)
- Conjunto de dados de interpretação de texto com raciocínio de senso comum (ReCoRD)
- Reconhecimento de implicação textual (RTE)
- Palavras no contexto (WiC)
- Desafio do esquema de Winograd (WSC)
Para mais detalhes, consulte SuperGLUE: um comparativo de mercado mais consistente para sistemas de compreensão de linguagem de uso geral.
machine learning supervisionado
Treinar um modelo com base em atributos e os respectivos rótulos. O aprendizado supervisionado de máquina é análogo a aprender um assunto estudando um conjunto de perguntas e respostas correspondentes. Depois de dominar a relação entre perguntas e respostas, um estudante pode responder a novas perguntas (nunca vistas antes) sobre o mesmo tema.
Compare com o aprendizado de máquina sem supervisão.
Consulte Aprendizado supervisionado no curso "Introdução ao ML" para mais informações.
atributo sintético
Um atributo que não está presente entre os atributos de entrada, mas é montado com base em um ou mais deles. Os métodos para criar recursos sintéticos incluem:
- Agrupamento por classes de um atributo contínuo em classes de intervalo.
- Criar um cruzamento de atributos.
- Multiplicar (ou dividir) um valor de atributo por outro valor de atributo ou por si mesmo. Por exemplo, se
aebforem recursos de entrada, os seguintes serão exemplos de recursos sintéticos:- ab
- a2
- Aplicar uma função transcendental a um valor de recurso. Por exemplo, se
cfor um recurso de entrada, os seguintes serão exemplos de recursos sintéticos:- sin(c)
- ln(c)
Os atributos criados apenas por normalização ou escalonamento não são considerados sintéticos.
T
T5
Um modelo de aprendizagem por transferência de texto para texto introduzido pela IA do Google em 2020. O T5 é um modelo codificador-decodificador, baseado na arquitetura Transformer e treinado em um conjunto de dados extremamente grande. Ele é eficaz em várias tarefas de processamento de linguagem natural, como gerar texto, traduzir idiomas e responder a perguntas de maneira conversacional.
O nome T5 vem dos cinco Ts da frase "Text-to-Text Transfer Transformer" (Transformador de transferência de texto para texto).
T5X
Um framework de machine learning de código aberto projetado para criar e treinar modelos de processamento de linguagem natural (PLN) em grande escala. O T5 é implementado na base de código T5X, que é criada com base no JAX e no Flax.
Aprendizado por Q tabular
No aprendizado por reforço, implemente o aprendizado Q usando uma tabela para armazenar as funções Q para cada combinação de estado e ação.
target
Sinônimo de marcador.
rede de destino
No aprendizado por reforço profundo com Q, uma rede neural é uma aproximação estável da rede neural principal, que implementa uma função Q ou uma política. Em seguida, treine a rede principal nos valores Q previstos pela rede de destino. Assim, você evita o ciclo de feedback que ocorre quando a rede principal treina com valores Q previstos por ela mesma. Ao evitar esse feedback, a estabilidade do treinamento aumenta.
tarefa
Um problema que pode ser resolvido usando técnicas de machine learning, como:
temperatura
Um hiperparâmetro que controla o grau de aleatoriedade da saída de um modelo. Temperaturas mais altas resultam em saídas mais aleatórias, enquanto temperaturas mais baixas resultam em saídas menos aleatórias.
A escolha da temperatura ideal depende do aplicativo específico e/ou dos valores de string.
dados temporais
Dados registrados em diferentes momentos. Por exemplo, as vendas de casacos de inverno registradas para cada dia do ano seriam dados temporais.
Rank 4
A principal estrutura de dados em programas do TensorFlow. Os tensores são estruturas de dados N-dimensionais (em que N pode ser muito grande), mais comumente escalares, vetores ou matrizes. Os elementos de um tensor podem conter valores inteiros, de ponto flutuante ou de string.
TensorBoard
O painel que mostra os resumos salvos durante a execução de um ou mais programas do TensorFlow.
TensorFlow
Uma plataforma de machine learning distribuída e em grande escala. O termo também se refere à camada de API básica na pilha do TensorFlow, que oferece suporte à computação geral em gráficos de fluxo de dados.
Embora o TensorFlow seja usado principalmente para machine learning, também é possível usá-lo para tarefas que não são de ML e exigem computação numérica usando grafos de fluxo de dados.
TensorFlow Playground
Um programa que mostra como diferentes hiperparâmetros influenciam o treinamento do modelo (principalmente de rede neural). Acesse http://playground.tensorflow.org para testar o TensorFlow Playground.
TensorFlow Serving
Uma plataforma para implantar modelos treinados em produção.
Unidade de Processamento de Tensor (TPU)
Um circuito integrado de aplicação específica (ASIC) que otimiza o desempenho das cargas de trabalho de machine learning. Esses ASICs são implantados como vários chips de TPU em um dispositivo de TPU.
Cardinalidade do Tensor
Consulte rank (Tensor).
Formato do tensor
O número de elementos que um Tensor contém em várias dimensões.
Por exemplo, um tensor [5, 10] tem uma forma de 5 em uma dimensão e 10 em outra.
Tamanho do tensor
O número total de escalares que um Tensor contém. Por exemplo, um tensor [5, 10] tem um tamanho de 50.
TensorStore
Uma biblioteca para ler e gravar matrizes multidimensionais grandes com eficiência.
condição de encerramento
No aprendizado por reforço, as condições que determinam quando um episódio termina, como quando o agente atinge um determinado estado ou excede um número limite de transições de estado. Por exemplo, em jogo da velha, um episódio termina quando um jogador marca três espaços consecutivos ou quando todos os espaços são marcados.
teste
Em uma árvore de decisão, outro nome para uma condição.
perda de teste
Uma métrica que representa a perda de um modelo em relação ao conjunto de teste. Ao criar um modelo, geralmente você tenta minimizar a perda de teste. Isso porque uma perda de teste baixa é um indicador de qualidade mais forte do que uma perda de treinamento ou de validação baixa.
Uma grande diferença entre a perda de teste e a perda de treinamento ou validação às vezes sugere que você precisa aumentar a taxa de regularização.
conjunto de teste
Um subconjunto do conjunto de dados reservado para testar um modelo treinado.
Tradicionalmente, você divide os exemplos no conjunto de dados nos três subconjuntos distintos a seguir:
- um conjunto de treinamento
- um conjunto de validação
- um conjunto de teste
Cada exemplo em um conjunto de dados precisa pertencer a apenas um dos subconjuntos anteriores. Por exemplo, um único exemplo não pode pertencer ao conjunto de treinamento e ao conjunto de teste.
Os conjuntos de treinamento e validação estão intimamente ligados ao treinamento de um modelo. Como o conjunto de teste está associado ao treinamento apenas indiretamente, a perda de teste é uma métrica menos enviesada e de maior qualidade do que a perda de treinamento ou a perda de validação.
Consulte Conjuntos de dados: dividindo o conjunto de dados original no Curso intensivo de machine learning para mais informações.
extensão de texto
O intervalo de índice da matriz associado a uma subseção específica de uma string de texto.
Por exemplo, a palavra good na string Python s="Be good now" ocupa o intervalo de texto de 3 a 6.
tf.Example
Um buffer de protocolo padrão para descrever dados de entrada para treinamento ou inferência de modelos de machine learning.
tf.keras
Uma implementação do Keras integrada ao TensorFlow.
limiar (para árvores de decisão)
Em uma condição alinhada ao eixo, o valor com que um recurso está sendo comparado. Por exemplo, 75 é o valor de limite na seguinte condição:
grade >= 75
Consulte Divisor exato para classificação binária com recursos numéricos no curso "Florestas de decisão" para mais informações.
análise de séries temporais
Um subcampo do machine learning e da estatística que analisa dados temporais. Muitos tipos de problemas de machine learning exigem análise de série temporal, incluindo classificação, clustering, previsão e detecção de anomalias. Por exemplo, você pode usar a análise de série temporal para prever as vendas futuras de casacos de inverno por mês com base em dados históricos de vendas.
timestep
Uma célula "desenrolada" em uma rede neural recorrente. Por exemplo, a figura a seguir mostra três etapas de tempo (marcadas com os subscritos t-1, t e t+1):

token
Em um modelo de linguagem, a unidade atômica que o modelo usa para treinar e fazer previsões. Um token geralmente é um dos seguintes:
- uma palavra. Por exemplo, a frase "cachorros gostam de gatos" consiste em três tokens de palavra: "cachorros", "gostam" e "gatos".
- um caractere. Por exemplo, a frase "peixe bicicleta" consiste em nove tokens de caractere. O espaço em branco conta como um dos tokens.
- subpalavras, em que uma única palavra pode ser um ou vários tokens. Uma subpalavra consiste em uma palavra raiz, um prefixo ou um sufixo. Por exemplo, um modelo de linguagem que usa subpalavras como tokens pode ver a palavra "cachorros" como dois tokens (a palavra raiz "cachorro" e o sufixo plural "s"). O mesmo modelo de linguagem pode considerar a palavra "taller" como duas subpalavras (a palavra raiz "tall" e o sufixo "er").
Em domínios fora dos modelos de linguagem, os tokens podem representar outros tipos de unidades atômicas. Por exemplo, em visão computacional, um token pode ser um subconjunto de uma imagem.
Consulte Modelos de linguagem grandes no Curso intensivo de machine learning para mais informações.
tokenizer
Um sistema ou algoritmo que traduz uma sequência de dados de entrada em tokens.
A maioria dos modelos de fundação modernos é multimodal. Um tokenizador para um sistema multimodal precisa traduzir cada tipo de entrada para o formato adequado. Por exemplo, considerando dados de entrada compostos de texto e gráficos, o tokenizador pode traduzir o texto de entrada em subpalavras e as imagens de entrada em pequenos patches. Em seguida, o tokenizador precisa converter todos os tokens em um único espaço de embedding unificado, o que permite que o modelo "entenda" um fluxo de entrada multimodal.
Precisão do Top-k
A porcentagem de vezes que um "rótulo de destino" aparece nas primeiras k posições das listas geradas. As listas podem ser recomendações personalizadas ou uma lista de itens ordenados por softmax.
A acurácia Top-k também é conhecida como acurácia em k.
torre
Um componente de uma rede neural profunda que também é uma rede neural profunda. Em alguns casos, cada torre lê de uma fonte de dados independente, e elas permanecem assim até que a saída seja combinada em uma camada final. Em outros casos, por exemplo, na torre encoder e decoder de muitos Transformers, as torres têm conexões cruzadas entre si.
conteúdo tóxico
O grau em que o conteúdo é abusivo, ameaçador ou ofensivo. Muitos modelos de aprendizado de máquina podem identificar, medir e classificar a toxicidade. A maioria desses modelos identifica toxicidade em vários parâmetros, como o nível de linguagem abusiva e ameaçadora.
TPU
Abreviação de Unidade de Processamento de Tensor.
Chip de TPU
Um acelerador de álgebra linear programável com memória de alta largura de banda no chip otimizado para cargas de trabalho de machine learning. Vários chips de TPU são implantados em um dispositivo de TPU.
Dispositivo de TPU
Uma placa de circuito impresso (PCB) com vários chips de TPU, interfaces de rede de alta largura de banda e hardware de resfriamento do sistema.
Nó da TPU
Um recurso de TPU no Google Cloud com um tipo de TPU específico. O nó de TPU se conecta à sua rede VPC de uma rede VPC de peering. Os nós da TPU são um recurso definido na API Cloud TPU.
Pod de TPU
Uma configuração específica de dispositivos de TPU em um data center do Google. Todos os dispositivos em um Pod de TPU são conectados entre si por uma rede dedicada de alta velocidade. Um Pod de TPU é a maior configuração de dispositivos de TPU disponível para uma versão específica de TPU.
Recurso da TPU
Uma entidade de TPU no Google Cloud que você cria, gerencia ou consome. Por exemplo, nós de TPU e tipos de TPU são recursos de TPU.
Fração de TPU
Uma fração da TPU é uma parte fracionária dos dispositivos de TPU em um pod de TPU. Todos os dispositivos em uma fração de TPU são conectados uns aos outros por uma rede dedicada de alta velocidade.
Tipo de TPU
Uma configuração de um ou mais dispositivos de TPU com uma versão específica de hardware de TPU. Você seleciona um tipo de TPU ao criar
um nó de TPU no Google Cloud. Por exemplo, um tipo de TPU v2-8 é um único dispositivo TPU v2 com 8 núcleos. Um tipo de TPU v3-2048 tem 256 dispositivos de TPU v3 em rede e um total de 2.048 núcleos. Os tipos de TPU são um recurso
definido na
API Cloud TPU.
worker da TPU
Um processo executado em uma máquina host e que executa programas de aprendizado de máquina em dispositivos TPU.
treinamento
O processo de determinar os parâmetros (pesos e vieses) ideais que compõem um modelo. Durante o treinamento, um sistema lê exemplos e ajusta gradualmente os parâmetros. O treinamento usa cada exemplo de algumas vezes a bilhões de vezes.
Consulte Aprendizado supervisionado no curso "Introdução ao ML" para mais informações.
perda de treinamento
Uma métrica que representa a perda de um modelo durante uma iteração de treinamento específica. Por exemplo, suponha que a função de perda seja erro quadrático médio. Talvez a perda de treinamento (o erro quadrático médio) da 10ª iteração seja 2,2, e a perda de treinamento da 100ª iteração seja 1,9.
Uma curva de perda representa a perda de treinamento em relação ao número de iterações. Uma curva de perda fornece as seguintes dicas sobre o treinamento:
- Uma inclinação para baixo implica que o modelo está melhorando.
- Uma inclinação para cima significa que o modelo está piorando.
- Uma inclinação plana significa que o modelo atingiu a convergência.
Por exemplo, a curva de perda um pouco idealizada a seguir mostra:
- Uma inclinação acentuada para baixo durante as iterações iniciais, o que implica uma melhoria rápida do modelo.
- Uma inclinação gradualmente mais plana (mas ainda descendente) até perto do fim do treinamento, o que implica uma melhoria contínua do modelo em um ritmo um pouco mais lento do que durante as iterações iniciais.
- Uma inclinação plana no final do treinamento, o que sugere convergência.
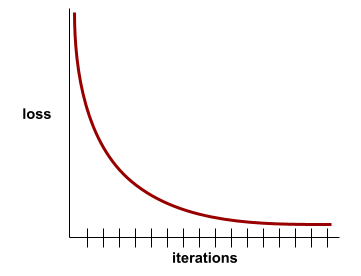
Embora a perda de treinamento seja importante, consulte também a generalização.
desvio entre treinamento e disponibilização
A diferença entre o desempenho de um modelo durante o treinamento e o desempenho do mesmo modelo durante a disponibilização.
conjunto de treinamento
O subconjunto do conjunto de dados usado para treinar um modelo.
Tradicionalmente, os exemplos no conjunto de dados são divididos nos três subconjuntos distintos a seguir:
- um conjunto de treinamento
- um conjunto de validação
- um conjunto de teste
O ideal é que cada exemplo no conjunto de dados pertença a apenas um dos subconjuntos anteriores. Por exemplo, um único exemplo não pode pertencer aos conjuntos de treinamento e validação.
Consulte Conjuntos de dados: dividindo o conjunto de dados original no Curso intensivo de machine learning para mais informações.
trajetória
No aprendizado por reforço, uma sequência de tuplas representa uma sequência de transições de estado do agente. Cada tupla corresponde ao estado, à ação, à recompensa e ao próximo estado de uma determinada transição de estado.
aprendizado por transferência
Transferir informações de uma tarefa de aprendizado de máquina para outra. Por exemplo, no aprendizado multitarefa, um único modelo resolve várias tarefas, como um modelo profundo que tem diferentes nós de saída para diferentes tarefas. O aprendizado por transferência pode envolver a transferência de conhecimento de uma tarefa mais simples para uma mais complexa ou de uma tarefa com mais dados para uma com menos dados.
A maioria dos sistemas de machine learning resolve uma única tarefa. O aprendizado por transferência é um pequeno passo em direção à inteligência artificial, em que um único programa pode resolver várias tarefas.
Transformer
Uma arquitetura de rede neural desenvolvida no Google que usa mecanismos de autoatenção para transformar uma sequência de incorporações de entrada em uma sequência de incorporações de saída sem depender de convoluções ou redes neurais recorrentes. Um Transformer pode ser visto como uma pilha de camadas de autoatenção.
Um Transformer pode incluir qualquer um dos seguintes elementos:
- um codificador
- um decodificador
- um codificador e um decodificador
Um codificador transforma uma sequência de embeddings em uma nova sequência do mesmo comprimento. Um codificador inclui N camadas idênticas, cada uma contendo duas subcamadas. Essas duas subcamadas são aplicadas em cada posição da sequência de incorporação de entrada, transformando cada elemento da sequência em uma nova incorporação. A primeira subcamada do codificador agrega informações de toda a sequência de entrada. A segunda subcamada do codificador transforma as informações agregadas em um embedding de saída.
Um decodificador transforma uma sequência de embeddings de entrada em uma sequência de embeddings de saída, possivelmente com um comprimento diferente. Um decodificador também inclui N camadas idênticas com três subcamadas, duas delas semelhantes às subcamadas do codificador. A terceira subcamada do decodificador usa a saída do codificador e aplica o mecanismo de autoatenção para coletar informações dele.
A postagem do blog Transformer: A Novel Neural Network Architecture for Language Understanding oferece uma boa introdução aos Transformers.
Consulte LLMs: o que é um modelo de linguagem grande? no Curso intensivo de machine learning para mais informações.
invariância translacional
Em um problema de classificação de imagens, a capacidade de um algoritmo de classificar imagens com sucesso mesmo quando a posição dos objetos dentro da imagem muda. Por exemplo, o algoritmo ainda pode identificar um cachorro, seja no centro ou na extremidade esquerda do frame.
Consulte também invariância de tamanho e invariância rotacional.
trigram
Um trigrama, em que N=3.
Respostas a perguntas de curiosidades
Conjuntos de dados para avaliar a capacidade de um LLM de responder a perguntas de curiosidades. Cada conjunto de dados contém pares de perguntas e respostas criados por entusiastas de curiosidades. Diferentes conjuntos de dados são fundamentados por diferentes fontes, incluindo:
- Pesquisa na Web (TriviaQA)
- Wikipedia (TriviaQA_wiki)
Para mais informações, consulte TriviaQA: um conjunto de dados de desafio supervisionado remotamente em grande escala para compreensão de leitura.
verdadeiro negativo (VN)
Um exemplo em que o modelo prevê corretamente a classe negativa. Por exemplo, o modelo deduz que uma determinada mensagem de e-mail não é spam, e essa mensagem realmente não é spam.
verdadeiro positivo (VP)
Um exemplo em que o modelo prevê corretamente a classe positiva. Por exemplo, o modelo infere que uma determinada mensagem de e-mail é spam, e ela realmente é.
taxa de verdadeiro positivo (TVP)
Sinônimo de recall. Ou seja:
A taxa de verdadeiro positivo é o eixo y em uma curva ROC.
TTL
Abreviação de time to live.
Respostas a perguntas tipologicamente diversas (TyDi QA)
Um grande conjunto de dados para avaliar a proficiência de um LLM em responder a perguntas. O conjunto de dados contém pares de perguntas e respostas em vários idiomas.
Para mais detalhes, consulte TyDi QA: um comparativo para resposta a perguntas de busca de informações em idiomas tipologicamente diversos (em inglês).
U
Ultra
O modelo do Gemini com o maior número de parâmetros. Consulte Gemini Ultra para mais detalhes.
desconhecimento (de um atributo sensível)
Uma situação em que atributos sensíveis estão presentes, mas não incluídos nos dados de treinamento. Como os atributos sensíveis geralmente são correlacionados com outros atributos dos dados de uma pessoa, um modelo treinado sem conhecimento de um atributo sensível ainda pode ter um impacto desigual em relação a esse atributo ou violar outras restrições de justiça.
underfitting
Produzir um modelo com capacidade preditiva ruim porque ele não capturou totalmente a complexidade dos dados de treinamento. Muitos problemas podem causar subajuste, incluindo:
- Treinamento com o conjunto errado de recursos.
- Treinar por poucas épocas ou com uma taxa de aprendizado muito baixa.
- Treinamento com uma taxa de regularização muito alta.
- Fornecer poucas camadas ocultas em uma rede neural profunda.
Consulte Overfitting no Curso intensivo de machine learning para mais informações.
subamostragem
Remover exemplos da classe majoritária em um conjunto de dados com desequilíbrio de classes para criar um conjunto de treinamento mais equilibrado.
Por exemplo, considere um conjunto de dados em que a proporção da classe majoritária para a classe minoritária é de 20:1. Para resolver esse problema, crie um conjunto de treinamento com todos os exemplos da classe minoritária, mas apenas um décimo dos exemplos da classe majoritária, o que criaria uma proporção de classe de conjunto de treinamento de 2:1. Graças à subamostragem, esse conjunto de treinamento mais equilibrado pode produzir um modelo melhor. Por outro lado, esse conjunto de treinamento mais equilibrado pode ter exemplos insuficientes para treinar um modelo eficaz.
Contraste com a superamostragem.
unidirecional
Um sistema que avalia apenas o texto que antecede uma seção de texto de destino. Já um sistema bidirecional avalia o texto que precede e segue uma seção de texto de destino. Consulte bidirecional para mais detalhes.
modelo de linguagem unidirecional
Um modelo de linguagem que baseia as probabilidades apenas nos tokens que aparecem antes, não depois, dos tokens de destino. Contraste com o modelo de linguagem bidirecional.
exemplo sem rótulo
Um exemplo que contém atributos, mas nenhum rótulo. Por exemplo, a tabela a seguir mostra três exemplos não rotulados de um modelo de avaliação de imóveis, cada um com três recursos, mas sem valor da casa:
| Número de quartos | Número de banheiros | Idade da casa |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
No machine learning supervisionado, os modelos são treinados com exemplos rotulados e fazem previsões com exemplos sem rótulo.
No aprendizado semi-supervisionado e não supervisionado, exemplos sem rótulo são usados durante o treinamento.
Contraste um exemplo sem rótulo com um exemplo rotulado.
aprendizado de máquina sem supervisão
Treinar um modelo para encontrar padrões em um conjunto de dados, geralmente um conjunto de dados sem rótulos.
O uso mais comum do aprendizado de máquina não supervisionado é agrupar dados em grupos de exemplos semelhantes. Por exemplo, um algoritmo de aprendizado de máquina não supervisionado pode agrupar músicas com base em várias propriedades da música. Os clusters resultantes podem se tornar uma entrada para outros algoritmos de aprendizado de máquina (por exemplo, um serviço de recomendação de músicas). O clustering pode ajudar quando os rótulos úteis são escassos ou ausentes. Por exemplo, em domínios como combate a abusos e fraudes, os clusters podem ajudar as pessoas a entender melhor os dados.
Contraste com o aprendizado de máquina supervisionado.
Consulte O que é machine learning? no curso de introdução ao ML para mais informações.
modelagem de uplift
Uma técnica de estimativa, comumente usada em marketing, que estima o "efeito causal" (também conhecido como "impacto incremental") de um "tratamento" em um "indivíduo". Veja dois exemplos:
- Os médicos podem usar a modelagem de uplift para prever a diminuição da mortalidade (efeito causal) de um procedimento médico (tratamento) dependendo da idade e do histórico médico de um paciente (indivíduo).
- Os profissionais de marketing podem usar a estimativa de Lift para prever o aumento na probabilidade de uma compra (efeito causal) devido a um anúncio (tratamento) para uma pessoa (indivíduo).
A modelagem de Lift difere da classificação ou da regressão porque alguns rótulos (por exemplo, metade dos rótulos em tratamentos binários) sempre estão ausentes na modelagem de Lift. Por exemplo, um paciente pode receber ou não um tratamento. Portanto, só podemos observar se ele vai se curar ou não em uma dessas duas situações (mas nunca em ambas). A principal vantagem de um modelo de Lift é que ele pode gerar previsões para a situação não observada (o contrafactual) e usá-las para calcular o efeito causal.
aumento da ponderação
Aplicar um peso à classe subamostrada igual ao fator de subamostragem.
matriz de usuários
Em sistemas de recomendação, um vetor de incorporação gerado por fatoração de matrizes que contém indicadores latentes sobre as preferências do usuário. Cada linha da matriz de usuários contém informações sobre a força relativa de vários indicadores latentes para um único usuário. Por exemplo, considere um sistema de recomendação de filmes. Nesse sistema, os sinais latentes na matriz do usuário podem representar o interesse de cada usuário em gêneros específicos ou podem ser sinais mais difíceis de interpretar que envolvem interações complexas em vários fatores.
A matriz de usuários tem uma coluna para cada recurso latente e uma linha para cada usuário. Ou seja, a matriz de usuários tem o mesmo número de linhas que a matriz de destino que está sendo fatorizada. Por exemplo, considerando um sistema de recomendação de filmes para 1 milhão de usuários, a matriz de usuários terá 1 milhão de linhas.
V
validação
A avaliação inicial da qualidade de um modelo. A validação verifica a qualidade das previsões de um modelo em relação ao conjunto de validação.
Como o conjunto de validação é diferente do conjunto de treinamento, a validação ajuda a evitar o overfitting.
Pense na avaliação do modelo em relação ao conjunto de validação como a primeira rodada de testes e na avaliação do modelo em relação ao conjunto de teste como a segunda rodada.
perda de validação
Uma métrica que representa a perda de um modelo no conjunto de validação durante uma iteração específica do treinamento.
Consulte também a curva de generalização.
conjunto de validação
O subconjunto do conjunto de dados que realiza a avaliação inicial em relação a um modelo treinado. Normalmente, você avalia o modelo treinado em relação ao conjunto de validação várias vezes antes de avaliar o modelo em relação ao conjunto de teste.
Tradicionalmente, você divide os exemplos no conjunto de dados nos três subconjuntos distintos a seguir:
- um conjunto de treinamento
- um conjunto de validação
- um conjunto de teste
O ideal é que cada exemplo no conjunto de dados pertença a apenas um dos subconjuntos anteriores. Por exemplo, um único exemplo não pode pertencer aos conjuntos de treinamento e validação.
Consulte Conjuntos de dados: dividindo o conjunto de dados original no Curso intensivo de machine learning para mais informações.
imputação de valor
O processo de substituir um valor ausente por um substituto aceitável. Quando um valor está faltando, você pode descartar o exemplo inteiro ou usar a imputação de valor para salvar o exemplo.
Por exemplo, considere um conjunto de dados que contém um atributo temperature que deve ser registrado a cada hora. No entanto, a leitura da temperatura ficou indisponível por uma hora específica. Confira uma seção do conjunto de dados:
| Carimbo de data/hora | Temperatura |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | ausente |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
Um sistema pode excluir o exemplo ausente ou imputar a temperatura ausente como 12, 16, 18 ou 20, dependendo do algoritmo de imputação.
problema de desaparecimento de gradiente
A tendência de os gradientes das primeiras camadas ocultas de algumas redes neurais profundas ficarem surpreendentemente planos (baixos). Gradientes cada vez menores resultam em mudanças cada vez menores nos pesos dos nós em uma rede neural profunda, levando a pouco ou nenhum aprendizado. Modelos que sofrem com o problema de desaparecimento de gradiente se tornam difíceis ou impossíveis de treinar. As células de memória de curto prazo longa resolvem esse problema.
Compare com o problema do gradiente explosivo.
importâncias de variáveis
Um conjunto de pontuações que indica a importância relativa de cada atributo para o modelo.
Por exemplo, considere uma árvore de decisão que estima os preços das casas. Suponha que essa árvore de decisão use três recursos: tamanho, idade e estilo. Se um conjunto de importâncias de variáveis para os três recursos for calculado como {size=5.8, age=2.5, style=4.7}, o tamanho será mais importante para a árvore de decisão do que a idade ou o estilo.
Existem diferentes métricas de importância da variável, que podem informar aos especialistas em ML sobre diferentes aspectos dos modelos.
codificador automático variacional (VAE, na sigla em inglês)
Um tipo de autoencoder que aproveita a discrepância entre entradas e saídas para gerar versões modificadas das entradas. Os codificadores automáticos variacionais são úteis para IA generativa.
Os VAEs se baseiam na inferência variacional, uma técnica para estimar os parâmetros de um modelo de probabilidade.
vetor
Termo muito sobrecarregado cujo significado varia em diferentes campos matemáticos e científicos. No machine learning, um vetor tem duas propriedades:
- Tipo de dados: vetores em machine learning geralmente contêm números de ponto flutuante.
- Número de elementos: é o comprimento do vetor ou a dimensão dele.
Por exemplo, considere um vetor de recursos que contém oito números de ponto flutuante. Esse vetor de recursos tem um comprimento ou dimensão de oito. Os vetores de machine learning costumam ter um grande número de dimensões.
É possível representar vários tipos de informações como um vetor. Exemplo:
- Qualquer posição na superfície da Terra pode ser representada como um vetor bidimensional, em que uma dimensão é a latitude e a outra é a longitude.
- Os preços atuais de cada uma das 500 ações podem ser representados como um vetor de 500 dimensões.
- Uma distribuição de probabilidade em um número finito de classes pode ser representada como um vetor. Por exemplo, um sistema de classificação multiclasse que prevê uma de três cores de saída (vermelho, verde ou amarelo) pode gerar o vetor
(0.3, 0.2, 0.5)para significarP[red]=0.3, P[green]=0.2, P[yellow]=0.5.
Os vetores podem ser concatenados. Portanto, uma variedade de mídias diferentes pode ser representada como um único vetor. Alguns modelos operam diretamente na concatenação de várias codificações one-hot.
Processadores especializados, como as TPUs, são otimizados para realizar operações matemáticas em vetores.
Um vetor é um tensor de cardinalidade 1.
Vertex
Plataforma do Google Cloud para IA e machine learning. A Vertex oferece ferramentas e infraestrutura para criar, implantar e gerenciar aplicativos de IA, incluindo acesso aos modelos do Gemini.vibe coding
Comandar um modelo de IA generativa para criar software. Ou seja, seus comandos descrevem a finalidade e os recursos do software, que um modelo de IA generativa traduz em código-fonte. O código gerado nem sempre corresponde às suas intenções, então a programação por vibe geralmente requer iteração.
Andrej Karpathy cunhou o termo vibe coding nesta postagem no X. Na postagem no X, Karpathy descreve isso como "um novo tipo de programação...em que você se entrega totalmente às vibes..." Portanto, o termo originalmente implicava uma abordagem intencionalmente flexível para criar software em que talvez você nem examine o código gerado. No entanto, o termo evoluiu rapidamente em muitos círculos para significar qualquer forma de programação gerada por IA.
Para uma descrição mais detalhada da codificação de vibe, consulte O que é vibe coding?.
Além disso, compare e contraste o vibe coding com:
W
Perda de Wasserstein
Uma das funções de perda usadas com frequência em redes adversárias generativas (GANs, na sigla em inglês), com base na distância do movimento de terra entre a distribuição de dados gerados e dados reais.
peso
Um valor que um modelo multiplica por outro valor. O treinamento é o processo de determinar os pesos ideais de um modelo. A inferência é o processo de usar esses pesos aprendidos para fazer previsões.
Consulte Regressão linear no Curso intensivo de machine learning para mais informações.
Mínimos quadrados ponderados alternados (WALS, na sigla em inglês)
Um algoritmo para minimizar a função objetiva durante a fatoração de matrizes em sistemas de recomendação, que permite uma redução dos exemplos ausentes. O WALS minimiza o erro quadrático ponderado entre a matriz original e a reconstrução alternando entre a fixação da fatoração de linhas e colunas. Cada uma dessas otimizações pode ser resolvida por otimização convexa de mínimos quadrados . Para mais detalhes, consulte o curso sobre sistemas de recomendação.
soma de pesos
A soma de todos os valores de entrada relevantes multiplicados pelos pesos correspondentes. Por exemplo, suponha que as entradas relevantes consistam no seguinte:
| valor de entrada | peso de entrada |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
Portanto, a soma ponderada é:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Uma soma ponderada é o argumento de entrada de uma função de ativação.
WiC
Abreviação de Palavras em contexto.
modelo amplo
Um modelo linear que normalmente tem muitos recursos de entrada esparsos. Chamamos de "amplo" porque esse modelo é um tipo especial de rede neural com um grande número de entradas que se conectam diretamente ao nó de saída. Em geral, é mais fácil depurar e inspecionar modelos amplos do que modelos profundos. Embora modelos amplos não possam expressar não linearidades por camadas ocultas, eles podem usar transformações como cruzamento de atributos e agrupamento em intervalos para modelar não linearidades de maneiras diferentes.
Contraste com o modelo profundo.
largura
O número de neurônios em uma determinada camada de uma rede neural.
WikiLingua (wiki_lingua)
Um conjunto de dados para avaliar a capacidade de um LLM de resumir artigos curtos. O WikiHow, uma enciclopédia de artigos que explicam como realizar várias tarefas, é a fonte criada por humanos para os artigos e os resumos. Cada entrada no conjunto de dados consiste em:
- Um artigo, que é criado anexando cada etapa da versão em prosa (parágrafo) da lista numerada, menos a frase inicial de cada etapa.
- Um resumo desse artigo, consistindo na frase inicial de cada etapa da lista numerada.
Para mais detalhes, consulte WikiLingua: um novo conjunto de dados de comparativo para resumo abstrativo multilíngue.
Desafio de esquema de Winograd (WSC)
Um formato (ou conjunto de dados em conformidade com esse formato) para avaliar a capacidade de um LLM de determinar a frase nominal a que um pronome se refere.
Cada entrada em um desafio de esquema de Winograd consiste em:
- Uma passagem curta que contém um pronome de destino
- Um pronome de destino
- Frases nominais candidatas, seguidas da resposta correta (um booleano). Se o pronome de destino se referir a esse candidato, a resposta será "True". Se o pronome de destino não se referir a esse candidato, a resposta será "False".
Exemplo:
- Trecho: Mark contou muitas mentiras sobre si mesmo para Pete, que as incluiu no livro. Ele deveria ter sido mais sincero.
- Pronome de destino: ele
- Frases nominais candidatas:
- Mark: True, porque o pronome de destino se refere a Mark
- Pete: falso, porque o pronome de destino não se refere a Peter.
O Winograd Schema Challenge é um componente do conjunto SuperGLUE.
sabedoria da multidão
A ideia de que a média das opiniões ou estimativas de um grande grupo de pessoas ("a multidão") geralmente produz resultados surpreendentemente bons. Por exemplo, considere um jogo em que as pessoas adivinham o número de jujubas em um pote grande. Embora a maioria dos palpites individuais seja imprecisa, a média de todos os palpites se mostrou empiricamente surpreendentemente próxima do número real de jujubas no pote.
Os ensembles são um análogo de software da sabedoria da multidão. Mesmo que modelos individuais façam previsões muito imprecisas, a média das previsões de muitos modelos geralmente gera previsões surpreendentemente boas. Por exemplo, embora uma árvore de decisão individual possa fazer previsões ruins, uma floresta de decisão geralmente faz previsões muito boas.
WMT
Estranhamente, uma abreviação de Conference on Machine Translation. A abreviação é WMT porque o nome original era Workshop on Machine Translation. A conferência se concentra em desenvolvimentos nos sistemas de tradução automática.
embedding de palavra
Representar cada palavra em um conjunto de palavras dentro de um vetor de incorporação, ou seja, representar cada palavra como um vetor de valores de ponto flutuante entre 0,0 e 1,0. Palavras com significados semelhantes têm representações mais parecidas do que palavras com significados diferentes. Por exemplo, cenouras, aipo e pepinos teriam representações relativamente semelhantes, que seriam muito diferentes das representações de avião, óculos de sol e pasta de dente.
Palavras no contexto (WiC)
Um conjunto de dados para avaliar o desempenho de um LLM ao usar o contexto para entender palavras que têm vários significados. Cada entrada no conjunto de dados contém:
- Duas frases, cada uma contendo a palavra de destino
- A palavra de destino
- A resposta correta (um booleano), em que:
- "True" significa que a palavra de destino tem o mesmo significado nas duas frases.
- "False" significa que a palavra de destino tem um significado diferente nas duas frases.
Exemplo:
- Duas frases:
- Há muito lixo no leito do rio.
- Eu deixo um copo de água ao lado da minha cama quando durmo.
- A palavra-alvo:cama
- Resposta correta: falso, porque a palavra-alvo tem um significado diferente nas duas frases.
Para mais detalhes, consulte WiC: o conjunto de dados Word-in-Context para avaliar representações de significado sensíveis ao contexto.
O recurso "Palavras no contexto" é um componente do conjunto SuperGLUE.
WSC
Abreviação de Winograd Schema Challenge.
X
XLA (álgebra linear acelerada)
Um compilador de machine learning de código aberto para GPUs, CPUs e aceleradores de ML.
O compilador XLA usa modelos de frameworks de ML conhecidos, como PyTorch, TensorFlow e JAX, e os otimiza para execução de alta performance em diferentes plataformas de hardware, incluindo GPUs, CPUs e aceleradores de ML.
XL-Sum (xlsum)
Um conjunto de dados para avaliar a capacidade de um LLM de resumir texto. O XL-Sum fornece entradas em vários idiomas. Cada entrada no conjunto de dados contém:
- Um artigo da British Broadcasting Company (BBC).
- Um resumo do artigo, escrito pelo autor dele. O resumo pode conter palavras ou frases que não estão no artigo.
Para mais detalhes, consulte XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages (em inglês).
xsum
Abreviação de Resumo extremo.
Z
aprendizado zero-shot
Um tipo de treinamento de machine learning em que o modelo infere uma previsão para uma tarefa em que ele não foi treinado especificamente. Em outras palavras, o modelo recebe zero exemplos de treinamento específicos da tarefa, mas é solicitado a fazer inferência para essa tarefa.
comando zero-shot
Um comando que não fornece um exemplo de como você quer que o modelo de linguagem grande responda. Exemplo:
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| Índia: | A consulta real. |
O modelo de linguagem grande pode responder com qualquer uma das opções a seguir:
- Rúpia
- INR
- ₹
- Rúpias indianas
- A rupia
- A rupia indiana
Todas as respostas estão corretas, mas talvez você prefira um formato específico.
Compare e contraste o comando zero-shot com os seguintes termos:
Normalização de valor Z
Uma técnica de escalonamento que substitui um valor bruto de recurso por um valor de ponto flutuante que representa o número de desvios padrão da média desse recurso. Por exemplo, considere um recurso cuja média é 800 e o desvio padrão é 100. A tabela a seguir mostra como a normalização por pontuação Z mapearia o valor bruto para a pontuação Z:
| Valor bruto | Valor Z |
|---|---|
| 800 | 0 |
| 950 | +1,5 |
| 575 | -2,25 |
O modelo de machine learning é treinado nos escores Z desse recurso, em vez dos valores brutos.
Consulte Dados numéricos: normalização no Curso intensivo de machine learning para mais informações.