En esta página, se incluyen términos del glosario de ML Fundamentals. Para consultar todos los términos del glosario, haz clic aquí.
A
exactitud
Es la cantidad de predicciones de clasificación correctas dividida por la cantidad total de predicciones. Es decir:
Por ejemplo, un modelo que realizó 40 predicciones correctas y 10 incorrectas tendría una precisión de:
La clasificación binaria proporciona nombres específicos para las diferentes categorías de predicciones correctas y predicciones incorrectas. Por lo tanto, la fórmula de exactitud para la clasificación binaria es la siguiente:
Donde:
- TP es la cantidad de verdaderos positivos (predicciones correctas).
- TN es la cantidad de verdaderos negativos (predicciones correctas).
- FP es la cantidad de falsos positivos (predicciones incorrectas).
- FN es la cantidad de falsos negativos (predicciones incorrectas).
Compara y contrasta la exactitud con la precisión y la recuperación.
Consulta Clasificación: Precisión, recuperación, exactitud y métricas relacionadas en el Curso intensivo de aprendizaje automático para obtener más información.
función de activación
Es una función que permite que las redes neuronales aprendan relaciones no lineales (complejas) entre las características y la etiqueta.
Entre las funciones de activación populares, se incluyen las siguientes:
Los diagramas de las funciones de activación nunca son líneas rectas únicas. Por ejemplo, el gráfico de la función de activación ReLU consta de dos líneas rectas:

El gráfico de la función de activación sigmoidea se ve de la siguiente manera:

Haz clic en el ícono para ver un ejemplo.
En una red neuronal, las funciones de activación manipulan la suma ponderada de todas las entradas a una neurona. Para calcular una suma ponderada, la neurona suma los productos de los valores y los pesos relevantes. Por ejemplo, supongamos que la entrada pertinente para una neurona consta de lo siguiente:
| valor de entrada | Peso de entrada |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
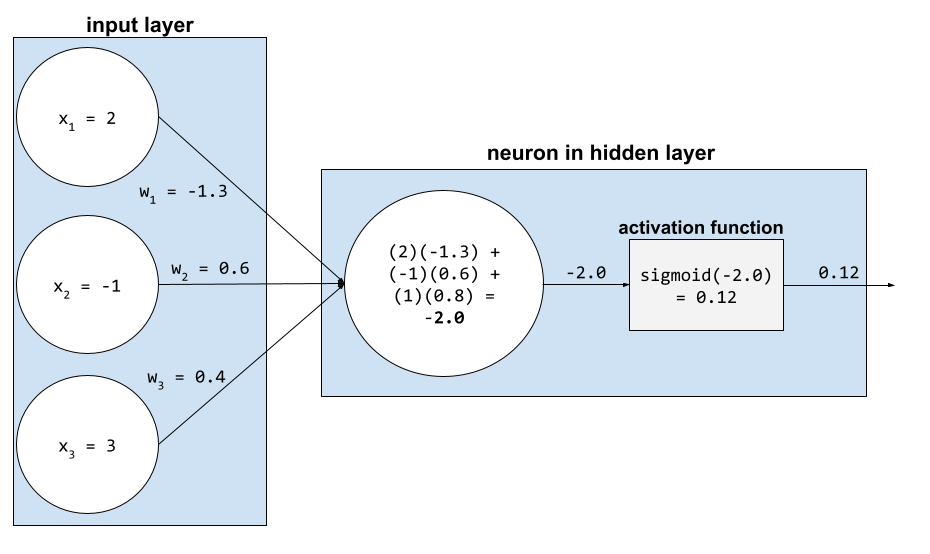
Consulta Redes neuronales: Funciones de activación en el Curso intensivo de aprendizaje automático para obtener más información.
inteligencia artificial
Es un programa o modelo no humano que puede resolver tareas sofisticadas. Por ejemplo, los programas o modelos que traducen textos o que identifican enfermedades a partir de imágenes radiológicas son muestras de inteligencia artificial.
Técnicamente, el aprendizaje automático es un subcampo de la inteligencia artificial. Sin embargo, en los últimos años, algunas organizaciones comenzaron a utilizar los términos inteligencia artificial y aprendizaje automático de manera indistinta.
AUC (área bajo la curva ROC)
Es un número entre 0.0 y 1.0 que representa la capacidad de un modelo de clasificación binaria para separar las clases positivas de las clases negativas. Cuanto más cerca esté el AUC de 1.0, mejor será la capacidad del modelo para separar las clases entre sí.
Por ejemplo, la siguiente ilustración muestra un modelo de clasificación que separa perfectamente las clases positivas (óvalos verdes) de las clases negativas (rectángulos morados). Este modelo irrealmente perfecto tiene un AUC de 1.0:

Por el contrario, la siguiente ilustración muestra los resultados de un modelo de clasificación que generó resultados aleatorios. Este modelo tiene un AUC de 0.5:

Sí, el modelo anterior tiene un AUC de 0.5, no de 0.0.
La mayoría de los modelos se encuentran en algún punto intermedio entre los dos extremos. Por ejemplo, el siguiente modelo separa los positivos de los negativos en cierta medida y, por lo tanto, tiene un AUC entre 0.5 y 1.0:

El AUC ignora cualquier valor que establezcas para el umbral de clasificación. En cambio, el AUC considera todos los umbrales de clasificación posibles.
Haz clic en el ícono para obtener información sobre la relación entre las curvas ROC y el AUC.
El AUC representa el área bajo una curva ROC. Por ejemplo, la curva ROC de un modelo que separa perfectamente los positivos de los negativos se ve de la siguiente manera:
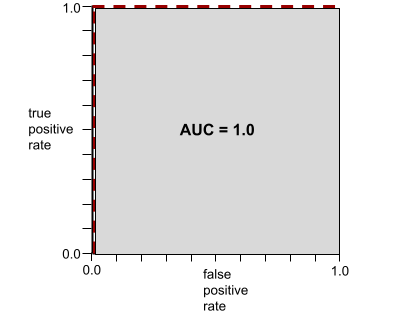
El AUC es el área de la región gris en la ilustración anterior. En este caso inusual, el área es simplemente la longitud de la región gris (1.0) multiplicada por el ancho de la región gris (1.0). Por lo tanto, el producto de 1.0 y 1.0 genera un AUC de exactamente 1.0, que es la puntuación de AUC más alta posible.
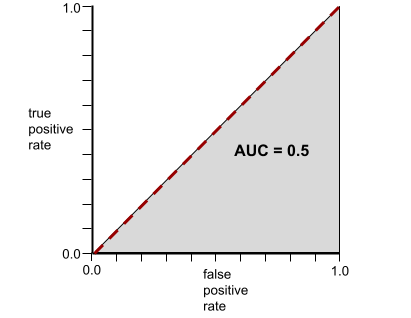
Por el contrario, la curva ROC para un modelo de clasificación que no puede separar las clases en absoluto es la siguiente. El área de esta región gris es 0.5.
Una curva ROC más típica se ve aproximadamente de la siguiente manera:
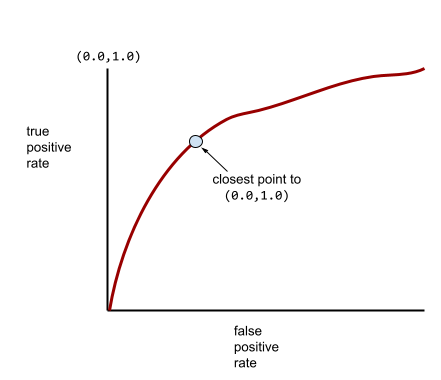
Calcular el área bajo esta curva de forma manual sería un trabajo arduo, por lo que, por lo general, un programa calcula la mayoría de los valores del AUC.
Para obtener más información, consulta Clasificación: ROC y AUC en el Curso intensivo de aprendizaje automático.
B
propagación inversa
Es el algoritmo que implementa el descenso de gradientes en las redes neuronales.
El entrenamiento de una red neuronal implica muchas iteraciones del siguiente ciclo de dos pasos:
- Durante el pase hacia adelante, el sistema procesa un lote de ejemplos para generar predicciones. El sistema compara cada predicción con cada valor de la etiqueta. La diferencia entre la predicción y el valor de la etiqueta es la pérdida para ese ejemplo. El sistema agrega las pérdidas de todos los ejemplos para calcular la pérdida total del lote actual.
- Durante el pase hacia atrás (retropropagación), el sistema reduce la pérdida ajustando los pesos de todas las neuronas en todas las capas ocultas.
Las redes neuronales suelen contener muchas neuronas en muchas capas ocultas. Cada una de esas neuronas contribuye a la pérdida general de diferentes maneras. La retropropagación determina si se deben aumentar o disminuir los pesos aplicados a neuronas específicas.
La tasa de aprendizaje es un multiplicador que controla el grado en que cada pase hacia atrás aumenta o disminuye cada peso. Una tasa de aprendizaje grande aumentará o disminuirá cada peso más que una tasa de aprendizaje pequeña.
En términos de cálculo, la retropropagación implementa la regla de la cadena del cálculo. Es decir, la retropropagación calcula la derivada parcial del error con respecto a cada parámetro.
Hace años, los profesionales del AA tenían que escribir código para implementar la retropropagación. Las APIs de AA modernas, como Keras, ahora implementan la retropropagación por ti. ¡Vaya!
Consulta Redes neuronales en el Curso intensivo de aprendizaje automático para obtener más información.
lote
Es el conjunto de ejemplos que se usan en una iteración de entrenamiento. El tamaño del lote determina la cantidad de ejemplos en un lote.
Consulta época para obtener una explicación de cómo se relaciona un lote con una época.
Consulta Regresión lineal: Hiperparámetros en el Curso intensivo de aprendizaje automático para obtener más información.
tamaño del lote
Cantidad de ejemplos en un lote. Por ejemplo, si el tamaño del lote es 100, el modelo procesa 100 ejemplos por iteración.
A continuación, se indican algunas estrategias populares para determinar el tamaño del lote:
- Descenso de gradientes estocástico (SGD), en el que el tamaño del lote es 1.
- Lote completo, en el que el tamaño del lote es la cantidad de ejemplos en todo el conjunto de entrenamiento. Por ejemplo, si el conjunto de entrenamiento contiene un millón de ejemplos, el tamaño del lote sería de un millón de ejemplos. Por lo general, el procesamiento por lotes completo es una estrategia ineficiente.
- Minilote, en el que el tamaño del lote suele ser entre 10 y 1,000. Por lo general, el minilote es la estrategia más eficiente.
Consulte los siguientes artículos para obtener más información:
- Sistemas de AA de producción: inferencia estática frente a inferencia dinámica en el Curso intensivo de aprendizaje automático.
- Guía de ajuste del aprendizaje profundo.
sesgo (ética/equidad)
1. Estereotipo, prejuicio o preferencia de cosas, personas o grupos por sobre otros. Estos sesgos pueden afectar la recopilación y la interpretación de datos, el diseño de un sistema y cómo los usuarios interactúan con él. Algunos tipos de este sesgo incluyen:
- sesgo de automatización
- sesgo de confirmación
- Sesgo del experimentador
- sesgo de correspondencia
- Sesgo implícito
- Sesgo endogrupal
- Sesgo de homogeneidad de los demás
2. Error sistemático debido a un procedimiento de muestreo o de realización de un informe. Algunos tipos de este sesgo incluyen:
- Sesgo de cobertura
- Sesgo de no respuesta
- Sesgo de participación
- Sesgo de reporte
- Sesgo de muestreo
- Sesgo de selección
No se debe confundir con el término de sesgo en los modelos de aprendizaje automático ni con el sesgo de predicción.
Consulta Equidad: Tipos de sesgo en el Curso intensivo de aprendizaje automático para obtener más información.
ordenada al origen (matemática) o término de sesgo
Una intersección o desplazamiento de un origen. El sesgo es un parámetro en los modelos de aprendizaje automático, que se simboliza con cualquiera de los siguientes elementos:
- b
- w0
Por ejemplo, la ordenada al origen es la b en la siguiente fórmula:
En una línea bidimensional simple, el sesgo solo significa "intersección con el eje Y". Por ejemplo, la ordenada al origen de la línea en la siguiente ilustración es 2.
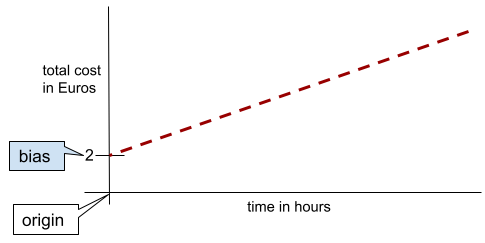
El sesgo existe porque no todos los modelos comienzan desde el origen (0,0). Por ejemplo, supongamos que la entrada a un parque de diversiones cuesta EUR 2 y se cobran EUR 0.5 adicionales por cada hora que se quede un cliente. Por lo tanto, un modelo que asigna el costo total tiene un sesgo de 2 porque el costo más bajo es de 2 euros.
El sesgo no se debe confundir con el sesgo en ética y equidad ni con el sesgo de predicción.
Consulta Regresión lineal en el Curso intensivo de aprendizaje automático para obtener más información.
Clasificación binaria
Es un tipo de tarea de clasificación que predice una de dos clases mutuamente exclusivas:
- la clase positiva
- la clase negativa
Por ejemplo, los siguientes dos modelos de aprendizaje automático realizan una clasificación binaria:
- Un modelo que determina si los mensajes de correo electrónico son spam (la clase positiva) o no son spam (la clase negativa).
- Un modelo que evalúa síntomas médicos para determinar si una persona tiene una enfermedad en particular (la clase positiva) o no la tiene (la clase negativa).
Compara esto con la clasificación de clases múltiples.
Consulta también regresión logística y umbral de clasificación.
Para obtener más información, consulta Clasificación en el Curso intensivo de aprendizaje automático.
Agrupamiento
Conversión de un solo atributo en varios atributos binarios denominados agrupamientos o discretizaciones, que en general se basan en un rango de valores. Por lo general, el atributo segmentado es un atributo continuo.
Por ejemplo, en lugar de representar la temperatura como un solo atributo de punto flotante continuo, podrías dividir los rangos de temperatura en discretos discretos, como los siguientes:
- Las temperaturas inferiores o iguales a 10 grados Celsius se incluirían en el intervalo “frío”.
- El intervalo de 11 a 24 grados Celsius sería el intervalo "templado".
- Los valores mayores o iguales a 25 grados Celsius se incluirían en el bucket "cálido".
El modelo tratará cada valor del mismo bucket de forma idéntica. Por ejemplo, los valores 13 y 22 se encuentran en el bucket de temperatura, por lo que el modelo trata ambos valores de forma idéntica.
Consulta Datos numéricos: discretización en el Curso intensivo de aprendizaje automático para obtener más información.
C
datos categóricos
Atributos que tienen un conjunto específico de valores posibles. Por ejemplo, considera un atributo categórico llamado traffic-light-state, que solo puede tener uno de los siguientes tres valores posibles:
redyellowgreen
Si se representa traffic-light-state como un atributo categórico, un modelo puede aprender los diferentes impactos de red, green y yellow en el comportamiento del conductor.
En ocasiones, los atributos categóricos se denominan atributos discretos.
Compara esto con los datos numéricos.
Consulta Cómo trabajar con datos categóricos en el Curso intensivo de aprendizaje automático para obtener más información.
clase
Es una categoría a la que puede pertenecer una etiqueta. Por ejemplo:
- En un modelo de clasificación binaria que detecta spam, las dos clases podrían ser spam y no es spam.
- En un modelo de clasificación de varias clases que identifica razas de perros, las clases podrían ser caniche, beagle, pug, etcétera.
Un modelo de clasificación predice una clase. Por el contrario, un modelo de regresión predice un número en lugar de una clase.
Para obtener más información, consulta Clasificación en el Curso intensivo de aprendizaje automático.
modelo de clasificación
Un modelo cuya predicción es una clase. Por ejemplo, todos los siguientes son modelos de clasificación:
- Un modelo que predice el idioma de una oración de entrada (¿francés? ¿Español? ¿Italiano?
- Un modelo que predice especies de árboles (¿arce? ¿Roble? ¿Baobab?).
- Un modelo que predice la clase positiva o negativa para una afección médica en particular.
Por el contrario, los modelos de regresión predicen números en lugar de clases.
Estos son dos tipos comunes de modelos de clasificación:
umbral de clasificación
En una clasificación binaria, es un número entre 0 y 1 que convierte el resultado sin procesar de un modelo de regresión logística en una predicción de la clase positiva o la clase negativa. Ten en cuenta que el umbral de clasificación es un valor que elige un humano, no un valor que se elige durante el entrenamiento del modelo.
Un modelo de regresión logística genera un valor sin procesar entre 0 y 1. Luego:
- Si este valor sin procesar es mayor que el umbral de clasificación, se predice la clase positiva.
- Si este valor sin procesar es menor que el umbral de clasificación, se predice la clase negativa.
Por ejemplo, supongamos que el umbral de clasificación es 0.8. Si el valor sin procesar es 0.9, el modelo predice la clase positiva. Si el valor sin procesar es 0.7, el modelo predice la clase negativa.
La elección del umbral de clasificación influye en gran medida en la cantidad de falsos positivos y falsos negativos.
Para obtener más información, consulta Umbrales y la matriz de confusión en el Curso intensivo de aprendizaje automático.
clasificador
Término informal para un modelo de clasificación.
conjunto de datos con desequilibrio de clases
Un conjunto de datos para una clasificación en la que la cantidad total de etiquetas de cada clase difiere significativamente. Por ejemplo, considera un conjunto de datos de clasificación binaria cuyas dos etiquetas se dividen de la siguiente manera:
- 1,000,000 de etiquetas negativas
- 10 etiquetas positivas
La proporción de etiquetas negativas y positivas es de 100,000 a 1, por lo que se trata de un conjunto de datos con desequilibrio de clases.
En cambio, el siguiente conjunto de datos está equilibrado en cuanto a las clases porque la proporción de etiquetas negativas y positivas es relativamente cercana a 1:
- 517 etiquetas negativas
- 483 etiquetas positivas
Los conjuntos de datos de varias clases también pueden tener un desequilibrio de clases. Por ejemplo, el siguiente conjunto de datos de clasificación de varias clases también está desequilibrado en cuanto a las clases, ya que una etiqueta tiene muchos más ejemplos que las otras dos:
- 1,000,000 de etiquetas con la clase "verde"
- 200 etiquetas con la clase "púrpura"
- 350 etiquetas con la clase "naranja"
El entrenamiento de conjuntos de datos con desequilibrio de clases puede presentar desafíos especiales. Consulta Conjuntos de datos desequilibrados en el Curso intensivo de aprendizaje automático para obtener más detalles.
Consulta también entropía, clase mayoritaria y clase minoritaria.
recorte
Técnica para manejar valores atípicos realizando una o ambas de las siguientes acciones:
- Se reducen los valores de características que superan un umbral máximo hasta ese umbral.
- Se incrementan hasta un umbral mínimo aquellos valores de atributo que sean menores.
Por ejemplo, supongamos que menos del 0.5% de los valores de un atributo en particular se encuentran fuera del rango de 40 a 60. En ese caso, puedes hacer lo siguiente:
- Recorta todos los valores superiores a 60 (el umbral máximo) para que sean exactamente 60.
- Hacer un recorte de todos los valores menores que 40 (el umbral mínimo) para que sean exactamente 40
Los valores atípicos pueden dañar los modelos y, a veces, provocar un desbordamiento de los pesos durante el entrenamiento. Algunos valores atípicos también pueden afectar significativamente las métricas, como la precisión. El recorte es una técnica común para limitar el daño.
El recorte de gradientes fuerza los valores del gradiente dentro de un rango designado durante el entrenamiento.
Consulta Datos numéricos: Normalización en el Curso intensivo de aprendizaje automático para obtener más información.
matriz de confusión
Es una tabla de NxN que resume la cantidad de predicciones correctas e incorrectas que realizó un modelo de clasificación. Por ejemplo, considera la siguiente matriz de confusión para un modelo de clasificación binaria:
| Tumor (previsto) | Sin tumor (predicción) | |
|---|---|---|
| Tumor (verdad fundamental) | 18 (TP) | 1 (FN) |
| No tumor (verdad fundamental) | 6 (FP) | 452 (TN) |
En la matriz de confusión anterior, se muestra lo siguiente:
- De las 19 predicciones en las que la verdad fundamental era Tumor, el modelo clasificó correctamente 18 y clasificó incorrectamente 1.
- De las 458 predicciones en las que la verdad fundamental era Non-Tumor, el modelo clasificó correctamente 452 y clasificó incorrectamente 6.
La matriz de confusión para un problema de clasificación de varias clases puede ayudarte a identificar patrones de errores. Por ejemplo, considera la siguiente matriz de confusión para un modelo de clasificación multiclase de 3 clases que categoriza tres tipos diferentes de iris (Virginica, Versicolor y Setosa). Cuando la verdad fundamental era Virginica, la matriz de confusión muestra que el modelo era mucho más propenso a predecir erróneamente Versicolor que Setosa:
| Setosa (previsto) | Versicolor (previsto) | Virginica (previsto) | |
|---|---|---|---|
| Setosa (verdad fundamental) | 88 | 12 | 0 |
| Versicolor (verdad fundamental) | 6 | 141 | 7 |
| Virginica (verdad fundamental) | 2 | 27 | 109 |
Como otro ejemplo, una matriz de confusión podría revelar que un modelo entrenado para reconocer dígitos escritos a mano tiende a predecir de manera incorrecta 9 en lugar de 4, o 1 en lugar de 7.
Las matrices de confusión contienen suficiente información para calcular una variedad de métricas de rendimiento, incluidas la precisión y la recuperación.
atributo continuo
Un atributo de punto flotante con un rango infinito de valores posibles, como la temperatura o el peso.
Compara esto con atributo discreto.
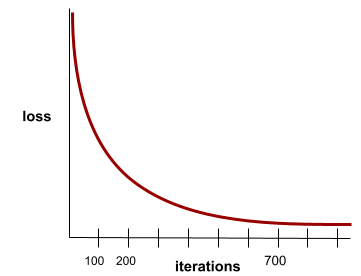
convergencia
Es un estado que se alcanza cuando los valores de la pérdida cambian muy poco o nada con cada iteración. Por ejemplo, la siguiente curva de pérdida sugiere convergencia alrededor de las 700 iteraciones:
Un modelo converge cuando el entrenamiento adicional no lo mejora.
En el aprendizaje profundo, los valores de pérdida a veces se mantienen constantes o casi constantes durante muchas iteraciones antes de descender finalmente. Durante un período prolongado de valores de pérdida constantes, es posible que, temporalmente, tengas una falsa sensación de convergencia.
Consulta también interrupción anticipada.
Consulta Curvas de pérdida y convergencia del modelo en el Curso intensivo de aprendizaje automático para obtener más información.
D
DataFrame
Un tipo de datos pandas popular para representar conjuntos de datos en la memoria.
Un DataFrame es similar a una tabla o una hoja de cálculo. Cada columna de un DataFrame tiene un nombre (un encabezado) y cada fila se identifica con un número único.
Cada columna de un DataFrame se estructura como un array 2D, excepto que a cada columna se le puede asignar su propio tipo de datos.
Consulta también la página de referencia oficial de pandas.DataFrame.
conjunto de datos (data set o dataset)
Es una colección de datos sin procesar, que se suelen organizar (aunque no exclusivamente) en uno de los siguientes formatos:
- una hoja de cálculo
- Un archivo en formato CSV (valores separados por comas)
modelo profundo
Una red neuronal que contiene más de una capa oculta.
Un modelo profundo también se denomina red neuronal profunda.
Compara esto con el modelo amplio.
atributo denso
Es una característica en la que la mayoría o todos los valores son distintos de cero, por lo general, un tensor de valores de punto flotante. Por ejemplo, el siguiente tensor de 10 elementos es denso porque 9 de sus valores no son cero:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Compara esto con el atributo disperso.
depth
La suma de los siguientes elementos en una red neuronal:
- La cantidad de capas ocultas
- La cantidad de capas de salida, que suele ser 1
- La cantidad de capas de incorporación
Por ejemplo, una red neuronal con cinco capas ocultas y una capa de salida tiene una profundidad de 6.
Ten en cuenta que la capa de entrada no influye en la profundidad.
atributo discreto
Un atributo con un conjunto finito de valores posibles. Por ejemplo, un atributo cuyos valores solo pueden ser animal, vegetal o mineral es un atributo discreto (o categórico).
Compara esto con el atributo continuo.
dinámico
Algo que se hace con frecuencia o de forma continua. En el aprendizaje automático, los términos dinámico y en línea son sinónimos. A continuación, se muestran algunos usos comunes de dinámico y en línea en el aprendizaje automático:
- Un modelo dinámico (o modelo en línea) es un modelo que se vuelve a entrenar con frecuencia o de forma continua.
- El entrenamiento dinámico (o entrenamiento en línea) es el proceso de entrenamiento frecuente o continuo.
- La inferencia dinámica (o inferencia en línea) es el proceso de generar predicciones a pedido.
modelo dinámico
Un modelo que se vuelve a entrenar con frecuencia (quizás incluso de forma continua). Un modelo dinámico es un "aprendiz permanente" que se adapta constantemente a los datos en evolución. Un modelo dinámico también se conoce como modelo en línea.
Compara esto con el modelo estático.
E
Interrupción anticipada
Es un método de regularización que implica finalizar el entrenamiento antes de que la pérdida de entrenamiento deje de disminuir. En la interrupción anticipada, detienes intencionalmente el entrenamiento del modelo cuando la pérdida en un conjunto de datos de validación comienza a aumentar, es decir, cuando empeora el rendimiento de la generalización.
Compara esto con la salida anticipada.
Capa de embedding
Es una capa oculta especial que se entrena en un atributo categórico de alta dimensión para aprender gradualmente un vector de incorporación de menor dimensión. Una capa de incorporación permite que una red neuronal se entrene de manera mucho más eficiente que si solo se entrenara con el atributo categórico de alta dimensión.
Por ejemplo, actualmente, la Tierra admite alrededor de 73,000 especies de árboles. Supongamos que la especie de árbol es un atributo en tu modelo, por lo que la capa de entrada del modelo incluye un vector de un solo 1 de 73,000 elementos de longitud.
Por ejemplo, tal vez baobab se representaría de la siguiente manera:

Un array de 73,000 elementos es muy largo. Si no agregas una capa de incorporación al modelo, el entrenamiento consumirá mucho tiempo debido a la multiplicación de 72,999 ceros. Quizás elijas que la capa de embedding conste de 12 dimensiones. En consecuencia, la capa de incorporación aprenderá gradualmente un nuevo vector de incorporación para cada especie de árbol.
En ciertas situaciones, el hashing es una alternativa razonable a una capa de incorporación.
Consulta Incorporaciones en el Curso intensivo de aprendizaje automático para obtener más información.
época
Un recorrido de entrenamiento completo por todo el conjunto de entrenamiento, de manera que cada ejemplo se haya procesado una vez.
Un ciclo representa N/tamaño del lote iteraciones de entrenamiento, donde N es la cantidad total de ejemplos.
Por ejemplo, supongamos lo siguiente:
- El conjunto de datos consta de 1,000 ejemplos.
- El tamaño del lote es de 50 ejemplos.
Por lo tanto, una sola época requiere 20 iteraciones:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Consulta Regresión lineal: Hiperparámetros en el Curso intensivo de aprendizaje automático para obtener más información.
ejemplo
Son los valores de una fila de atributos y, posiblemente, una etiqueta. Los ejemplos de aprendizaje supervisado se dividen en dos categorías generales:
- Un ejemplo etiquetado consta de uno o más atributos y una etiqueta. Durante el entrenamiento, se usan ejemplos etiquetados.
- Un ejemplo sin etiquetar consta de uno o más atributos, pero no tiene etiqueta. Los ejemplos sin etiqueta se usan durante la inferencia.
Por ejemplo, supongamos que estás entrenando un modelo para determinar la influencia de las condiciones climáticas en las calificaciones de los estudiantes. Estos son tres ejemplos etiquetados:
| Funciones | Etiqueta | ||
|---|---|---|---|
| Temperatura | Humedad | Presionar | Puntuación de la prueba |
| 15 | 47 | 998 | Bueno |
| 19 | 34 | 1020 | Excelente |
| 18 | 92 | 1012 | Deficiente |
Estos son tres ejemplos sin etiquetas:
| Temperatura | Humedad | Presionar | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Por lo general, la fila de un conjunto de datos es la fuente sin procesar de un ejemplo. Es decir, un ejemplo suele consistir en un subconjunto de las columnas del conjunto de datos. Además, los atributos de un ejemplo también pueden incluir atributos sintéticos, como combinaciones de atributos.
Consulta Aprendizaje supervisado en el curso Introducción al aprendizaje automático para obtener más información.
F
falso negativo (FN)
Ejemplo en el que el modelo predice de manera incorrecta la clase negativa. Por ejemplo, el modelo predice que un mensaje de correo electrónico en particular no es spam (la clase negativa), pero ese mensaje de correo electrónico en realidad sí es spam.
Falso positivo (FP)
Ejemplo en el que el modelo predice de manera incorrecta la clase positiva. Por ejemplo, el modelo predice que un mensaje de correo electrónico en particular es spam (la clase positiva), pero ese mensaje de correo electrónico en realidad no es spam.
Para obtener más información, consulta Umbrales y la matriz de confusión en el Curso intensivo de aprendizaje automático.
tasa de falsos positivos (FPR)
Proporción de ejemplos negativos reales para los que el modelo predijo erróneamente la clase positiva. La siguiente fórmula calcula la tasa de falsos positivos:
La tasa de falsos positivos es el eje X en una curva ROC.
Para obtener más información, consulta Clasificación: ROC y AUC en el Curso intensivo de aprendizaje automático.
función
Es una variable de entrada para un modelo de aprendizaje automático. Un ejemplo consta de una o más características. Por ejemplo, supongamos que estás entrenando un modelo para determinar la influencia de las condiciones climáticas en las calificaciones de los estudiantes. En la siguiente tabla, se muestran tres ejemplos, cada uno de los cuales contiene tres características y una etiqueta:
| Funciones | Etiqueta | ||
|---|---|---|---|
| Temperatura | Humedad | Presionar | Puntuación de la prueba |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Compara esto con la etiqueta.
Consulta Aprendizaje supervisado en el curso Introducción al aprendizaje automático para obtener más información.
combinación de atributos
Un atributo sintético que se forma al "combinar" atributos categóricos o agrupados en buckets
Por ejemplo, considera un modelo de "previsión del estado de ánimo" que representa la temperatura en uno de los siguientes cuatro intervalos:
freezingchillytemperatewarm
Y representa la velocidad del viento en uno de los siguientes tres buckets:
stilllightwindy
Sin combinaciones de atributos, el modelo lineal se entrena de forma independiente en cada uno de los siete segmentos anteriores. Por lo tanto, el modelo se entrena en, por ejemplo, freezing de forma independiente del entrenamiento en, por ejemplo, windy.
Como alternativa, podrías crear una combinación de atributos de temperatura y velocidad del viento. Esta variable sintética tendría los siguientes 12 valores posibles:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Gracias a las combinaciones de atributos, el modelo puede aprender las diferencias de humor entre un día freezing-windy y un día freezing-still.
Si creas un atributo sintético a partir de dos atributos que tienen muchos discretizaciones diferentes, la combinación de atributos resultante tendrá una gran cantidad de combinaciones posibles. Por ejemplo, si un atributo tiene 1,000 discretizaciones y el otro tiene 2,000, la discretización resultante tendrá 2,000,000 de discretizaciones.
Formalmente, un cruce es un producto cartesiano.
Las combinaciones de atributos se usan principalmente con modelos lineales y rara vez con redes neuronales.
Consulta Datos categóricos: combinaciones de atributos en el Curso intensivo de aprendizaje automático para obtener más información.
ingeniería de atributos.
Un proceso que incluye los siguientes pasos:
- Determinar qué atributos podrían ser útiles para entrenar un modelo
- Convertir los datos sin procesar del conjunto de datos en versiones eficientes de esos atributos
Por ejemplo, podrías determinar que temperature podría ser una función útil. Luego, puedes experimentar con el agrupamiento para optimizar lo que el modelo puede aprender de diferentes rangos de temperature.
En algunas ocasiones, la ingeniería de atributos se denomina extracción de características o featurización.
Para obtener más información, consulta Datos numéricos: Cómo un modelo ingiere datos con vectores de características en el Curso intensivo de aprendizaje automático.
conjunto de atributos
Es el grupo de atributos con el que se entrena el modelo de aprendizaje automático. Por ejemplo, un conjunto de atributos simple para un modelo que predice los precios de las viviendas podría constar del código postal, el tamaño de la propiedad y el estado de la propiedad.
vector de atributos
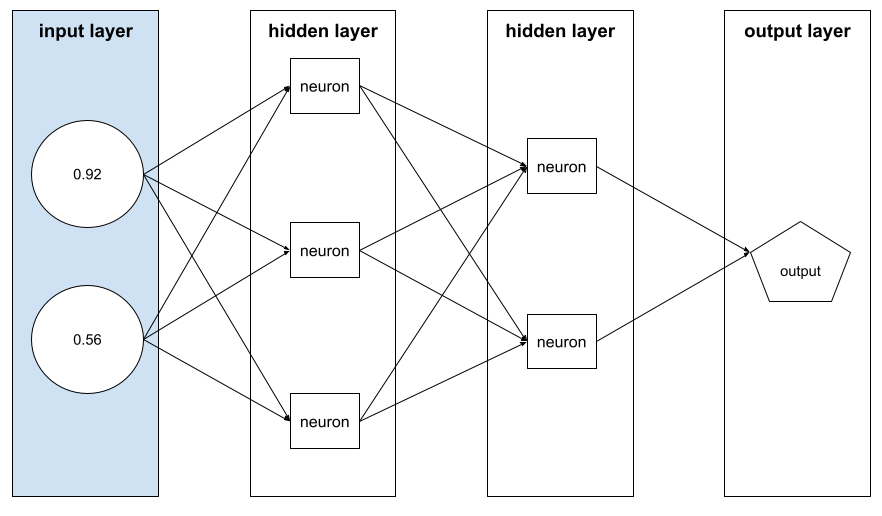
Es el array de valores de atributo que componen un ejemplo. El vector de atributos se ingresa durante el entrenamiento y la inferencia. Por ejemplo, el vector de atributos para un modelo con dos atributos discretos podría ser el siguiente:
[0.92, 0.56]
Cada ejemplo proporciona valores diferentes para el vector de atributos, por lo que el vector de atributos para el siguiente ejemplo podría ser similar al siguiente:
[0.73, 0.49]
La ingeniería de atributos determina cómo representar los atributos en el vector de atributos. Por ejemplo, un atributo categórico binario con cinco valores posibles se podría representar con codificación one-hot. En este caso, la porción del vector de características para un ejemplo en particular constaría de cuatro ceros y un solo 1.0 en la tercera posición, como se muestra a continuación:
[0.0, 0.0, 1.0, 0.0, 0.0]
Como otro ejemplo, supongamos que tu modelo consta de tres atributos:
- Un atributo categórico binario con cinco valores posibles representados con codificación one-hot; por ejemplo:
[0.0, 1.0, 0.0, 0.0, 0.0] - Otro atributo categórico binario con tres valores posibles representados con codificación one-hot; por ejemplo:
[0.0, 0.0, 1.0] - Es una característica de punto flotante, por ejemplo,
8.3.
En este caso, el vector de atributos para cada ejemplo se representaría con nueve valores. Con los valores de ejemplo de la lista anterior, el vector de atributos sería el siguiente:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Para obtener más información, consulta Datos numéricos: Cómo un modelo ingiere datos con vectores de características en el Curso intensivo de aprendizaje automático.
ciclo de retroalimentación
En el aprendizaje automático, situación en la que las predicciones de un modelo influyen en los datos de entrenamiento del mismo modelo o de otro. Por ejemplo, un modelo que recomienda películas influirá en las películas que miran las personas, lo que, a su vez, influirá en los modelos posteriores de recomendación de películas.
Para obtener más información, consulta Sistemas de AA en producción: Preguntas que debes hacer en el Curso intensivo de aprendizaje automático.
G
generalización
Es la capacidad de un modelo para realizar predicciones correctas sobre datos nuevos nunca antes vistos. Un modelo que puede generalizar es lo contrario de un modelo que tiene sobreajuste.
Consulta Generalización en el Curso intensivo de aprendizaje automático para obtener más información.
Curva de generalización
Un gráfico de la pérdida de entrenamiento y la pérdida de validación como una función de la cantidad de iteraciones.
Una curva de generalización puede ayudarte a detectar un posible sobreajuste. Por ejemplo, la siguiente curva de generalización sugiere sobreajuste porque la pérdida de validación se vuelve, en última instancia, significativamente mayor que la pérdida de entrenamiento.
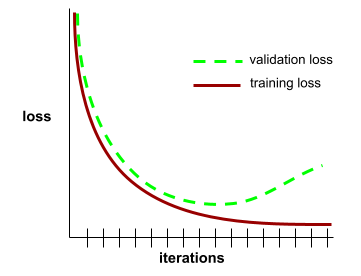
Consulta Generalización en el Curso intensivo de aprendizaje automático para obtener más información.
descenso de gradientes
Técnica matemática para minimizar la pérdida. El descenso de gradientes ajusta de forma iterativa los pesos y los sesgos, y encuentra gradualmente la mejor combinación para minimizar la pérdida.
El descenso del gradiente es más antiguo (mucho más antiguo) que el aprendizaje automático.
Para obtener más información, consulta Regresión lineal: Descenso del gradiente en el Curso intensivo de aprendizaje automático.
Verdad fundamental
Realidad.
Lo que realmente sucedió
Por ejemplo, considera un modelo de clasificación binaria que predice si un estudiante de primer año de universidad se graduará en un plazo de seis años. La verdad fundamental para este modelo es si el estudiante se graduó o no en un plazo de seis años.
H
Capa oculta
Capa en una red neuronal entre la capa de entrada (las características) y la capa de salida (la predicción). Cada capa oculta consta de una o más neuronas. Por ejemplo, la siguiente red neuronal contiene dos capas ocultas, la primera con tres neuronas y la segunda con dos:
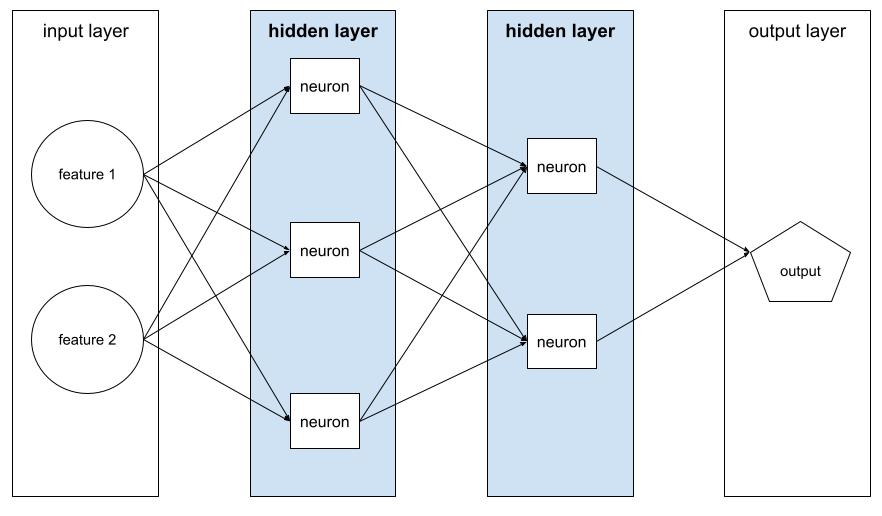
Una red neuronal profunda contiene más de una capa oculta. Por ejemplo, la ilustración anterior es una red neuronal profunda porque el modelo contiene dos capas ocultas.
Consulta Redes neuronales: Nodos y capas ocultas en el Curso intensivo de aprendizaje automático para obtener más información.
hiperparámetro
Son las variables que tú o un servicio de ajuste de hiperparámetros ajustan durante las ejecuciones sucesivas del entrenamiento de un modelo. Por ejemplo, la tasa de aprendizaje es un hiperparámetro. Podrías establecer la tasa de aprendizaje en 0.01 antes de una sesión de entrenamiento. Si determinas que 0.01 es demasiado alto, podrías establecer la tasa de aprendizaje en 0.003 para la próxima sesión de entrenamiento.
En cambio, los parámetros son los diversos pesos y el sesgo que el modelo aprende durante el entrenamiento.
Consulta Regresión lineal: Hiperparámetros en el Curso intensivo de aprendizaje automático para obtener más información.
I
independiente e idénticamente distribuido (i.i.d.)
Son datos extraídos de una distribución que no cambia y en la que cada valor extraído no depende de los valores que se extrajeron anteriormente. Un i.i.d. es el gas ideal del aprendizaje automático; es una construcción matemática útil, pero casi nunca se encuentra exactamente en el mundo real. Por ejemplo, la distribución de los visitantes de una página web pueden ser datos i.i.d. en una ventana de tiempo breve, es decir, la distribución no cambia durante esa ventana breve y la visita de una persona por lo general es independiente de la visita de otra. Sin embargo, si amplías ese período, es posible que aparezcan diferencias estacionales en los visitantes de la página web.
Consulta también no estacionariedad.
Inferencia
En el aprendizaje automático tradicional, el proceso de realizar predicciones aplicando un modelo entrenado a ejemplos sin etiqueta. Consulta Aprendizaje supervisado en el curso Introducción al AA para obtener más información.
En los modelos de lenguaje grandes, la inferencia es el proceso de usar un modelo entrenado para generar una respuesta a una instrucción de entrada.
En estadística, la inferencia tiene un significado algo diferente. Consulta el artículo de Wikipedia sobre inferencia estadística para obtener más detalles.
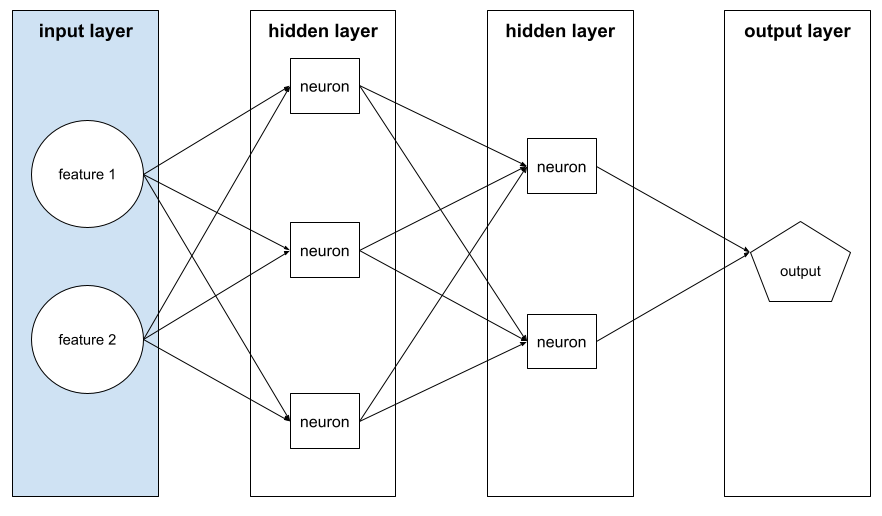
Capa de entrada
La capa de una red neuronal que contiene el vector de atributos. Es decir, la capa de entrada proporciona ejemplos para el entrenamiento o la inferencia. Por ejemplo, la capa de entrada de la siguiente red neuronal consta de dos atributos:
interpretabilidad
Es la capacidad de explicar o presentar el razonamiento de un modelo de AA en términos comprensibles para los humanos.
Por ejemplo, la mayoría de los modelos de regresión lineal son altamente interpretables. (solo necesitas ver los pesos entrenados para cada función). Los bosques de decisión también son altamente interpretables. Sin embargo, algunos modelos requieren una visualización sofisticada para convertirse en interpretables.
Puedes usar la Herramienta de interpretabilidad del aprendizaje (LIT) para interpretar modelos de AA.
iteración
Es una sola actualización de los parámetros de un modelo (los pesos y los sesgos del modelo) durante el entrenamiento. El tamaño del lote determina cuántos ejemplos procesa el modelo en una sola iteración. Por ejemplo, si el tamaño del lote es 20, el modelo procesa 20 ejemplos antes de ajustar los parámetros.
Cuando se entrena una red neuronal, una sola iteración implica los siguientes dos pases:
- Pase hacia adelante para evaluar la pérdida en un solo lote.
- Un pase hacia atrás (propagación hacia atrás) para ajustar los parámetros del modelo según la pérdida y la tasa de aprendizaje
Consulta Descenso del gradiente en el Curso intensivo de aprendizaje automático para obtener más información.
L
Regularización L0
Es un tipo de regularización que penaliza la cantidad total de pesos distintos de cero en un modelo. Por ejemplo, un modelo con 11 pesos distintos de cero se penalizaría más que un modelo similar con 10 pesos distintos de cero.
A veces, la regularización L0 se denomina regularización de norma L0.
Pérdida L1
Una función de pérdida que calcula el valor absoluto de la diferencia entre los valores de la etiqueta real y los valores que predice un modelo. Por ejemplo, aquí se muestra el cálculo de la pérdida L1 para un lote de cinco ejemplos:
| Valor real del ejemplo | Valor predicho del modelo | Valor absoluto del delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = pérdida L1 | ||
La pérdida L1 es menos sensible a los valores atípicos que la pérdida L2.
El error absoluto medio es la pérdida promedio de L1 por ejemplo.
Consulta Regresión lineal: Pérdida en el Curso intensivo de aprendizaje automático para obtener más información.
Regularización L1
Tipo de regularización que penaliza los pesos en proporción a la suma del valor absoluto de los pesos. La regularización L1 ayuda a llevar los pesos de los atributos irrelevantes o poco relevantes a exactamente 0. Una característica con un peso de 0 se quita del modelo de manera efectiva.
Compara esto con la regularización L2.
Pérdida L2
Es una función de pérdida que calcula el cuadrado de la diferencia entre los valores de la etiqueta real y los valores que predice un modelo. Por ejemplo, aquí se muestra el cálculo de la pérdida de L2 para un lote de cinco ejemplos:
| Valor real del ejemplo | Valor predicho del modelo | Cuadrado de delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = pérdida L2 | ||
Debido al componente cuadrático, la pérdida L2 amplifica la influencia de los valores atípicos. Es decir, la pérdida L2 reacciona de manera más severa a las predicciones incorrectas que la pérdida L1. Por ejemplo, la pérdida de L1 para el lote anterior sería de 8 en lugar de 16. Ten en cuenta que un solo valor atípico representa 9 de los 16.
Los modelos de regresión suelen usar la pérdida L2 como función de pérdida.
El error cuadrático medio es la pérdida promedio de L2 por ejemplo. La pérdida al cuadrado es otro nombre para la pérdida L2.
Para obtener más información, consulta Regresión logística: Pérdida y regularización en el Curso intensivo de aprendizaje automático.
Regularización L2
Tipo de regularización que penaliza los pesos en proporción a la suma de los cuadrados de los pesos. La regularización L2 ayuda a llevar los pesos de valores atípicos (aquellos con valores negativos bajos o positivos altos) más cerca del 0, pero no exactamente a ese número. Los atributos con valores muy cercanos a 0 permanecen en el modelo, pero no influyen mucho en su predicción.
La regularización L2 siempre mejora la generalización en los modelos lineales.
Compara esto con la regularización L1.
Consulta Sobreajuste: Regularización L2 en el Curso intensivo de aprendizaje automático para obtener más información.
etiqueta
En el aprendizaje automático supervisado, la parte de "respuesta" o "resultado" de un ejemplo.
Cada ejemplo etiquetado consta de uno o más atributos y una etiqueta. Por ejemplo, en un conjunto de datos de detección de spam, la etiqueta probablemente sería "es spam" o "no es spam". En un conjunto de datos de lluvia, la etiqueta podría ser la cantidad de lluvia que cayó durante un período determinado.
Consulta Aprendizaje supervisado en Introducción al aprendizaje automático para obtener más información.
ejemplo etiquetado
Es un ejemplo que contiene uno o más atributos y una etiqueta. Por ejemplo, en la siguiente tabla, se muestran tres ejemplos etiquetados de un modelo de valuación de casas, cada uno con tres atributos y una etiqueta:
| Cantidad de dormitorios | Cantidad de baños | Antigüedad de la casa | Precio de la casa (etiqueta) |
|---|---|---|---|
| 3 | 2 | 15 | USD 345,000 |
| 2 | 1 | 72 | USD 179,000 |
| 4 | 2 | 34 | USD 392,000 |
En el aprendizaje automático supervisado, los modelos se entrenan con ejemplos etiquetados y realizan predicciones sobre ejemplos sin etiqueta.
Compara el ejemplo etiquetado con los ejemplos sin etiquetar.
Consulta Aprendizaje supervisado en Introducción al aprendizaje automático para obtener más información.
lambda
Sinónimo de tasa de regularización.
Lambda es un término sobrecargado. Aquí nos referimos a la definición del término dentro de la regularización.
oculta
Es un conjunto de neuronas en una red neuronal. A continuación, se describen tres tipos comunes de capas:
- La capa de entrada, que proporciona valores para todos los atributos.
- Una o más capas ocultas, que encuentran relaciones no lineales entre los atributos y la etiqueta
- La capa de salida, que proporciona la predicción.
Por ejemplo, en la siguiente ilustración, se muestra una red neuronal con una capa de entrada, dos capas ocultas y una capa de salida:
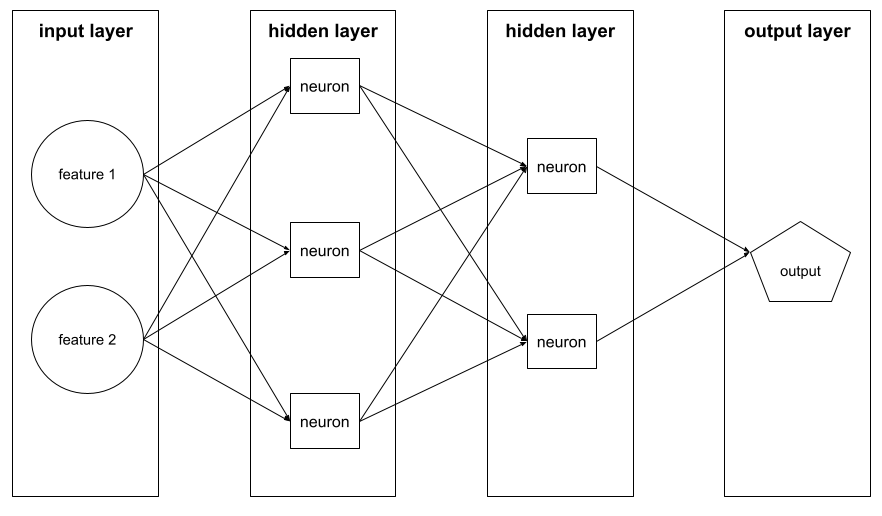
En TensorFlow, las capas también son funciones de Python que toman tensores y opciones de configuración como entrada y producen otros tensores como resultado.
tasa de aprendizaje
Es un número de punto flotante que le indica al algoritmo de descenso de gradientes con qué intensidad debe ajustar los pesos y las tendencias en cada iteración. Por ejemplo, una tasa de aprendizaje de 0.3 ajustaría los pesos y las tendencias tres veces más que una tasa de aprendizaje de 0.1.
La tasa de aprendizaje es un hiperparámetro fundamental. Si estableces la tasa de aprendizaje demasiado baja, el entrenamiento demorará demasiado. Si estableces la tasa de aprendizaje demasiado alta, el descenso de gradientes suele tener problemas para alcanzar la convergencia.
Consulta Regresión lineal: Hiperparámetros en el Curso intensivo de aprendizaje automático para obtener más información.
linear
Es una relación entre dos o más variables que se puede representar únicamente a través de la suma y la multiplicación.
La gráfica de una relación lineal es una línea.
Compara esto con no lineal.
modelo lineal
Un modelo que asigna un peso por atributo para realizar predicciones. (Los modelos lineales también incorporan un sesgo). Por el contrario, la relación de las características con las predicciones en los modelos profundos suele ser no lineal.
Los modelos lineales suelen ser más fáciles de entrenar y más interpretables que los modelos profundos. Sin embargo, los modelos profundos pueden aprender relaciones complejas entre los atributos.
La regresión lineal y la regresión logística son dos tipos de modelos lineales.
regresión lineal
Es un tipo de modelo de aprendizaje automático en el que se cumplen las siguientes condiciones:
- El modelo es un modelo lineal.
- La predicción es un valor de punto flotante. (Esta es la parte de la regresión de la regresión lineal).
Compara la regresión lineal con la regresión logística. Además, compara la regresión con la clasificación.
Consulta Regresión lineal en el Curso intensivo de aprendizaje automático para obtener más información.
regresión logística
Es un tipo de modelo de regresión que predice una probabilidad. Los modelos de regresión logística tienen las siguientes características:
- La etiqueta es categórica. El término regresión logística suele referirse a la regresión logística binaria, es decir, a un modelo que calcula probabilidades para etiquetas con dos valores posibles. Una variante menos común, la regresión logística multinomial, calcula las probabilidades de las etiquetas con más de dos valores posibles.
- La función de pérdida durante el entrenamiento es la pérdida logística. (Se pueden colocar varias unidades de pérdida logarítmica en paralelo para las etiquetas con más de dos valores posibles).
- El modelo tiene una arquitectura lineal, no una red neuronal profunda. Sin embargo, el resto de esta definición también se aplica a los modelos profundos que predicen probabilidades para las etiquetas categóricas.
Por ejemplo, considera un modelo de regresión logística que calcula la probabilidad de que un correo electrónico de entrada sea spam o no spam. Durante la inferencia, supongamos que el modelo predice 0.72. Por lo tanto, el modelo estima lo siguiente:
- Hay un 72% de probabilidades de que el correo electrónico sea spam.
- Hay un 28% de probabilidades de que el correo electrónico no sea spam.
Un modelo de regresión logística usa la siguiente arquitectura de dos pasos:
- El modelo genera una predicción sin procesar (y') aplicando una función lineal de los atributos de entrada.
- El modelo usa esa predicción sin procesar como entrada para una función sigmoidea, que convierte la predicción sin procesar en un valor entre 0 y 1, sin incluir estos valores.
Al igual que cualquier modelo de regresión, un modelo de regresión logística predice un número. Sin embargo, este número suele formar parte de un modelo de clasificación binaria de la siguiente manera:
- Si el número predicho es mayor que el umbral de clasificación, el modelo de clasificación binaria predice la clase positiva.
- Si el número predicho es menor que el umbral de clasificación, el modelo de clasificación binaria predice la clase negativa.
Consulta Regresión logística en el Curso intensivo de aprendizaje automático para obtener más información.
Pérdida logística
La función de pérdida que se usa en la regresión logística binaria.
Para obtener más información, consulta Regresión logística: Pérdida y regularización en el Curso intensivo de aprendizaje automático.
Logaritmo de probabilidad
Es el logaritmo de las probabilidades de algún evento.
pérdida
Durante el entrenamiento de un modelo supervisado, se calcula una medida de qué tan lejos está la predicción de un modelo de su etiqueta.
Una función de pérdida calcula la pérdida.
Consulta Regresión lineal: Pérdida en el Curso intensivo de aprendizaje automático para obtener más información.
Curva de pérdida
Es un gráfico de la pérdida como una función de la cantidad de iteraciones de entrenamiento. En el siguiente gráfico, se muestra una curva de pérdida típica:
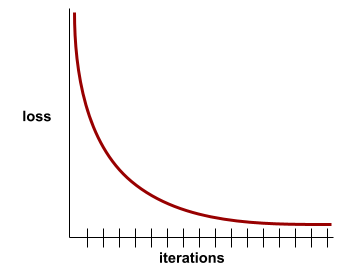
Las curvas de pérdida pueden ayudarte a determinar cuándo tu modelo está convergiendo o sobreajustándose.
Las curvas de pérdida pueden trazar todos los siguientes tipos de pérdida:
Consulta también curva de generalización.
Para obtener más información, consulta Sobreajuste: Interpretación de las curvas de pérdida en el Curso intensivo de aprendizaje automático.
función de pérdida
Durante el entrenamiento o las pruebas, una función matemática que calcula la pérdida en un lote de ejemplos. Una función de pérdida devuelve una pérdida menor para los modelos que realizan buenas predicciones que para los modelos que realizan predicciones deficientes.
Por lo general, el objetivo del entrenamiento es minimizar la pérdida que devuelve una función de pérdida.
Existen muchos tipos diferentes de funciones de pérdida. Elige la función de pérdida adecuada para el tipo de modelo que estás creando. Por ejemplo:
- La pérdida L2 (o error cuadrático medio) es la función de pérdida para la regresión lineal.
- La pérdida logística es la función de pérdida para la regresión logística.
M
aprendizaje automático
Es un programa o sistema que entrena un modelo a partir de datos de entrada. El modelo entrenado puede hacer predicciones útiles a partir de datos nuevos (nunca vistos) extraídos de la misma distribución que la utilizada para entrenar el modelo.
El aprendizaje automático también se conoce como el campo de estudio relacionado con estos programas o sistemas.
Para obtener más información, consulta el curso Introducción al aprendizaje automático.
clase mayoritaria
Es la etiqueta más común en un conjunto de datos con desequilibrio de clases. Por ejemplo, dado un conjunto de datos con un 99% de etiquetas negativas y un 1% de etiquetas positivas, la clase mayoritaria son las etiquetas negativas.
Compara esto con la clase minoritaria.
Consulta Conjuntos de datos: Conjuntos de datos desequilibrados en el Curso intensivo de aprendizaje automático para obtener más información.
minilote
Es un subconjunto pequeño seleccionado al azar de un lote que se procesa en una iteración. El tamaño del lote de un minilote generalmente es entre 10 y 1,000 ejemplos.
Por ejemplo, supongamos que el conjunto de entrenamiento completo (el lote completo) consta de 1,000 ejemplos. Supongamos que estableces el tamaño del lote de cada minilote en 20. Por lo tanto, cada iteración determina la pérdida en 20 ejemplos aleatorios de los 1,000 y, luego, ajusta los pesos y los sesgos según corresponda.
Es mucho más eficiente calcular la pérdida en un minilote que en todos los ejemplos del lote completo.
Consulta Regresión lineal: Hiperparámetros en el Curso intensivo de aprendizaje automático para obtener más información.
clase minoritaria
Es la etiqueta menos común en un conjunto de datos con desequilibrio de clases. Por ejemplo, dado un conjunto de datos con un 99% de etiquetas negativas y un 1% de etiquetas positivas, la clase minoritaria son las etiquetas positivas.
Compara esto con la clase mayoritaria.
Consulta Conjuntos de datos: Conjuntos de datos desequilibrados en el Curso intensivo de aprendizaje automático para obtener más información.
modelo
En general, cualquier construcción matemática que procese datos de entrada y devuelva resultados. Dicho de otra manera, un modelo es el conjunto de parámetros y la estructura necesarios para que un sistema realice predicciones. En el aprendizaje automático supervisado, un modelo toma un ejemplo como entrada y deduce una predicción como salida. Dentro del aprendizaje automático supervisado, los modelos difieren un poco. Por ejemplo:
- Un modelo de regresión lineal consta de un conjunto de pesos y un sesgo.
- Un modelo de red neuronal consta de lo siguiente:
- Un conjunto de capas ocultas, cada una de las cuales contiene una o más neuronas.
- Los pesos y el sesgo asociados a cada neurona.
- Un modelo de árbol de decisión consta de lo siguiente:
- Es la forma del árbol, es decir, el patrón en el que se conectan las condiciones y las hojas.
- Son las condiciones y las hojas.
Puedes guardar, restablecer o hacer copias de un modelo.
El aprendizaje automático no supervisado también genera modelos, por lo general, una función que puede asignar un ejemplo de entrada al clúster más adecuado.
clasificación de clases múltiples
En el aprendizaje supervisado, un problema de clasificación en el que el conjunto de datos contiene más de dos clases de etiquetas. Por ejemplo, las etiquetas del conjunto de datos Iris deben ser una de las siguientes tres clases:
- Iris setosa
- Iris virginica
- Iris versicolor
Un modelo entrenado en el conjunto de datos Iris que predice el tipo de iris en ejemplos nuevos realiza una clasificación de varias clases.
En cambio, los problemas de clasificación que distinguen entre exactamente dos clases son modelos de clasificación binaria. Por ejemplo, un modelo de correo electrónico que predice si un mensaje es spam o no es spam es un modelo de clasificación binaria.
En los problemas de agrupamiento, la clasificación de clases múltiples hace referencia a más de dos clústeres.
Consulta Redes neuronales: clasificación de clases múltiples en el Curso intensivo de aprendizaje automático para obtener más información.
N
clase negativa
En la clasificación binaria, una clase se denomina positiva y la otra, negativa. La clase positiva es el elemento o evento que el modelo está probando, y la clase negativa es la otra posibilidad. Por ejemplo:
- La clase negativa en una prueba médica puede ser "no es un tumor".
- La clase negativa en un modelo de clasificación de correos electrónicos podría ser "no es spam".
Compara esto con la clase positiva.
neuronal prealimentada
Un modelo que contiene al menos una capa oculta. Una red neuronal profunda es un tipo de red neuronal que contiene más de una capa oculta. Por ejemplo, en el siguiente diagrama, se muestra una red neuronal profunda que contiene dos capas ocultas.
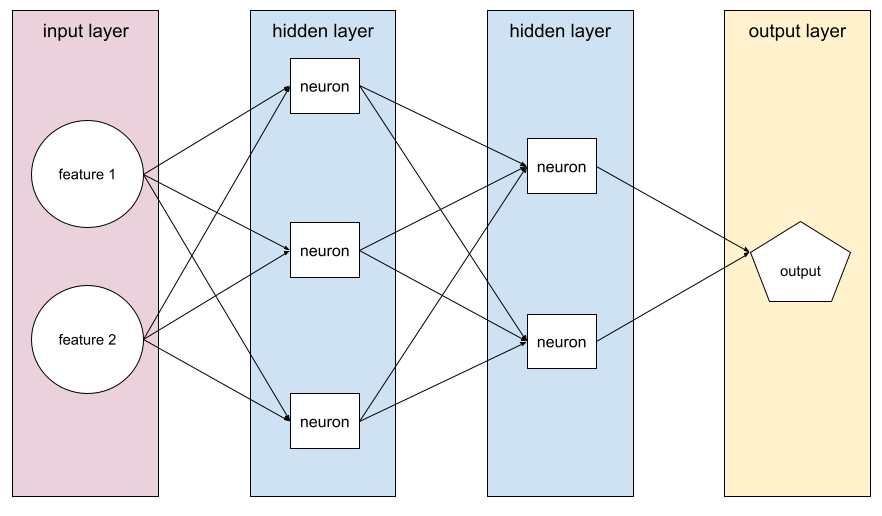
Cada neurona de una red neuronal se conecta a todos los nodos de la siguiente capa. Por ejemplo, en el diagrama anterior, observa que cada una de las tres neuronas de la primera capa oculta se conecta por separado con las dos neuronas de la segunda capa oculta.
Las redes neuronales implementadas en computadoras a veces se denominan redes neuronales artificiales para diferenciarlas de las redes neuronales que se encuentran en el cerebro y otros sistemas nerviosos.
Algunas redes neuronales pueden imitar relaciones no lineales extremadamente complejas entre diferentes atributos y la etiqueta.
Consulta también red neuronal convolucional y red neuronal recurrente.
Consulta Redes neuronales en el Curso intensivo de aprendizaje automático para obtener más información.
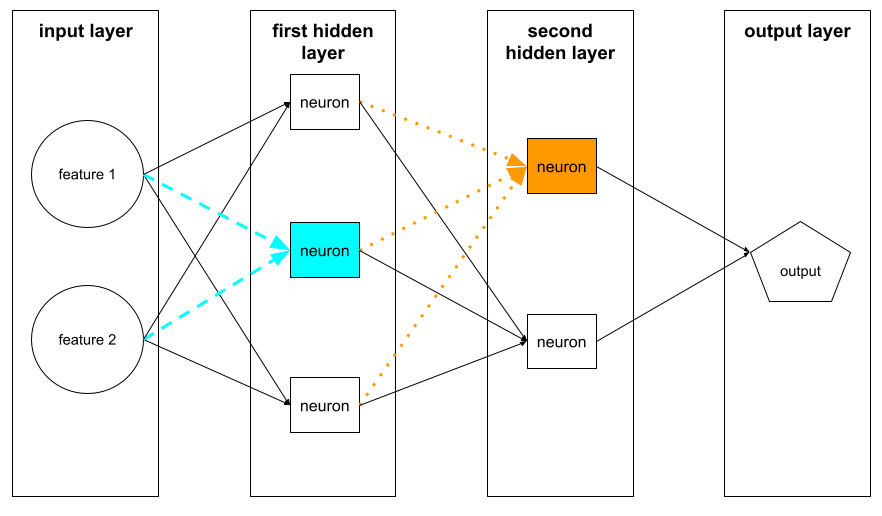
neurona
En el aprendizaje automático, es una unidad distinta dentro de una capa oculta de una red neuronal. Cada neurona realiza la siguiente acción de dos pasos:
- Calcula la suma ponderada de los valores de entrada multiplicados por sus pesos correspondientes.
- Pasa la suma ponderada como entrada a una función de activación.
Una neurona en la primera capa oculta acepta entradas de los valores de atributos en la capa de entrada. Una neurona en cualquier capa oculta más allá de la primera acepta entradas de las neuronas en la capa oculta precedente. Por ejemplo, una neurona en la segunda capa oculta acepta entradas de las neuronas en la primera capa oculta.
En la siguiente ilustración, se destacan dos neuronas y sus entradas.
Una neurona en una red neuronal imita el comportamiento de las neuronas en el cerebro y otras partes del sistema nervioso.
nodo (red neuronal)
Una neurona en una capa oculta.
Consulta Redes neuronales en el Curso intensivo de aprendizaje automático para obtener más información.
no lineal
Es una relación entre dos o más variables que no se puede representar solo a través de la suma y la multiplicación. Una relación lineal se puede representar como una línea, mientras que una relación no lineal no. Por ejemplo, considera dos modelos que relacionan un solo atributo con una sola etiqueta. El modelo de la izquierda es lineal y el de la derecha es no lineal:

Consulta Redes neuronales: nodos y capas ocultas en el Curso intensivo de aprendizaje automático para experimentar con diferentes tipos de funciones no lineales.
no estacionariedad
Es un atributo cuyos valores cambian en una o más dimensiones, por lo general, el tiempo. Por ejemplo, considera los siguientes ejemplos de no estacionariedad:
- La cantidad de trajes de baño que se venden en una tienda en particular varía según la temporada.
- La cantidad de una fruta en particular que se cosecha en una región específica es cero durante gran parte del año, pero es grande durante un breve período.
- Debido al cambio climático, las temperaturas medias anuales están cambiando.
Compara esto con la estacionariedad.
Normalización
En términos generales, es el proceso de convertir el rango real de valores de una variable en un rango estándar de valores, como los siguientes:
- De -1 a +1
- De 0 a 1
- Puntuaciones Z (aproximadamente, de -3 a +3)
Por ejemplo, supongamos que el rango real de valores de un atributo determinado es de 800 a 2,400. Como parte de la ingeniería de atributos, podrías normalizar los valores reales en un rango estándar, como de -1 a +1.
La normalización es una tarea común en la ingeniería de funciones. Por lo general, los modelos se entrenan más rápido (y producen mejores predicciones) cuando cada atributo numérico del vector de atributos tiene aproximadamente el mismo rango.
Consulta también la normalización de la puntuación Z.
Consulta Datos numéricos: Normalización en el Curso intensivo de aprendizaje automático para obtener más información.
datos numéricos
Atributos representados como números enteros o de valores reales. Por ejemplo, un modelo de valuación de casas probablemente representaría el tamaño de una casa (en pies cuadrados o metros cuadrados) como datos numéricos. Representar una característica como datos numéricos indica que los valores de la característica tienen una relación matemática con la etiqueta. Es decir, la cantidad de metros cuadrados de una casa probablemente tenga alguna relación matemática con su valor.
No todos los datos de números enteros deben representarse como datos numéricos. Por ejemplo, los códigos postales de algunas partes del mundo son números enteros. Sin embargo, los códigos postales enteros no deben representarse como datos numéricos en los modelos. Esto se debe a que un código postal de 20000 no es el doble (o la mitad) de potente que un código postal de 10000. Además, si bien los diferentes códigos postales sí se correlacionan con diferentes valores de bienes raíces, no podemos suponer que los valores de bienes raíces en el código postal 20000 son el doble de valiosos que los valores de bienes raíces en el código postal 10000.
Por lo tanto, los códigos postales deben representarse como datos categóricos.
En ocasiones, las funciones numéricas se denominan atributos continuos.
Para obtener más información, consulta Trabaja con datos numéricos en el Curso intensivo de aprendizaje automático.
O
Sin conexión
Sinónimo de estático.
inferencia sin conexión
Proceso por el que un modelo genera un lote de predicciones y, luego, las almacena en caché (las guarda). Luego, las apps pueden acceder a la predicción inferida desde la caché en lugar de volver a ejecutar el modelo.
Por ejemplo, considera un modelo que genera pronósticos del clima locales (predicciones) cada cuatro horas. Después de cada ejecución del modelo, el sistema almacena en caché todos los pronósticos del clima locales. Las apps del clima recuperan los pronósticos de la caché.
La inferencia sin conexión también se denomina inferencia estática.
Compara esto con la inferencia en línea. Para obtener más información, consulta Sistemas de AA en producción: inferencia estática versus dinámica en el Curso intensivo de aprendizaje automático.
codificación one-hot
Representa los datos categóricos como un vector en el que se cumple lo siguiente:
- Un elemento se establece en 1.
- Todos los demás elementos se establecen en 0.
La codificación one-hot se usa comúnmente para representar cadenas o identificadores que tienen un conjunto finito de valores posibles.
Por ejemplo, supongamos que un atributo categórico determinado llamado Scandinavia tiene cinco valores posibles:
- "Dinamarca"
- "Suecia"
- "Noruega"
- "Finlandia"
- "Islandia"
La codificación one-hot podría representar cada uno de los cinco valores de la siguiente manera:
| País | Vector | ||||
|---|---|---|---|---|---|
| "Dinamarca" | 1 | 0 | 0 | 0 | 0 |
| "Suecia" | 0 | 1 | 0 | 0 | 0 |
| "Noruega" | 0 | 0 | 1 | 0 | 0 |
| "Finlandia" | 0 | 0 | 0 | 1 | 0 |
| "Islandia" | 0 | 0 | 0 | 0 | 1 |
Gracias a la codificación one-hot, un modelo puede aprender diferentes conexiones en función de cada uno de los cinco países.
Representar un atributo como datos numéricos es una alternativa a la codificación one-hot. Lamentablemente, representar los países escandinavos de forma numérica no es una buena opción. Por ejemplo, considera la siguiente representación numérica:
- "Denmark" es 0.
- "Suecia" es 1.
- "Noruega" es 2.
- "Finland" es 3.
- "Islandia" es 4.
Con la codificación numérica, un modelo interpretaría los números sin procesar de forma matemática y trataría de entrenarse con esos números. Sin embargo, Islandia no tiene el doble (o la mitad) de algo que Noruega, por lo que el modelo llegaría a conclusiones extrañas.
Consulta Datos categóricos: Vocabulario y codificación one-hot en el Curso intensivo de aprendizaje automático para obtener más información.
uno frente a todos
Dado un problema de clasificación con N clases, una solución que consta de N modelos de clasificación binaria independientes, es decir, un modelo de clasificación binaria para cada resultado posible. Por ejemplo, dado un modelo que clasifica ejemplos como animal, vegetal o mineral, una solución de uno frente a todos proporcionaría los siguientes tres modelos de clasificación binaria independientes:
- animal versus no animal
- vegetal o no vegetal
- mineral versus no mineral
online
Sinónimo de dinámico.
inferencia en línea
Generación de predicciones a pedido. Por ejemplo, supongamos que una app pasa una entrada a un modelo y emite una solicitud de predicción. Un sistema que usa la inferencia en línea responde a la solicitud ejecutando el modelo (y devolviendo la predicción a la app).
Compara esto con la inferencia sin conexión.
Para obtener más información, consulta Sistemas de AA en producción: inferencia estática versus dinámica en el Curso intensivo de aprendizaje automático.
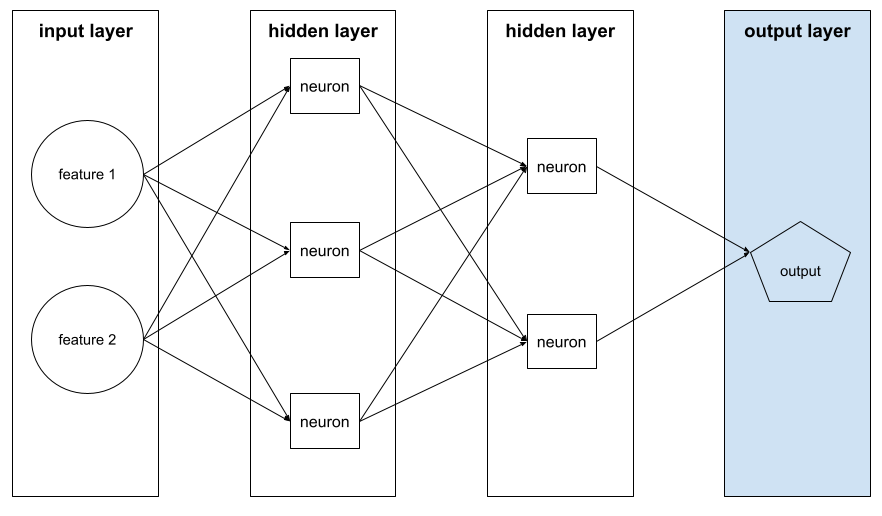
capa de salida
Es la capa "final" de una red neuronal. La capa de salida contiene la predicción.
En la siguiente ilustración, se muestra una pequeña red neuronal profunda con una capa de entrada, dos capas ocultas y una capa de salida:
sobreajuste
Creación de un modelo que coincide de tal manera con los datos de entrenamiento que no puede realizar predicciones correctas con datos nuevos.
La regularización puede reducir el sobreajuste. Entrenar el modelo con un conjunto de datos de entrenamiento grande y diverso también puede reducir el sobreajuste.
Consulta Sobreajuste en el Curso intensivo de aprendizaje automático para obtener más información.
P
pandas
Es una API de análisis de datos orientada a columnas compilada sobre numpy. Muchos frameworks de aprendizaje automático, incluido TensorFlow, admiten estructuras de datos de Pandas como entradas. Para obtener más información, consulta la documentación de Pandas.
parámetro
Los pesos y los sesgos que aprende un modelo durante el entrenamiento. Por ejemplo, en un modelo de regresión lineal, los parámetros constan de la ordenada al origen (b) y todos los pesos (w1, w2, etcétera) en la siguiente fórmula:
En cambio, los hiperparámetros son los valores que tú (o un servicio de ajuste de hiperparámetros) proporcionas al modelo. Por ejemplo, la tasa de aprendizaje es un hiperparámetro.
clase positiva
Es la clase para la que realizas la prueba.
Por ejemplo, la clase positiva en un modelo de cáncer podría ser "tumor". La clase positiva en un modelo de clasificación de correos electrónicos puede ser "spam".
Compara esto con la clase negativa.
posprocesamiento
Ajustar el resultado de un modelo después de que se haya ejecutado. El procesamiento posterior se puede usar para aplicar restricciones de equidad sin modificar los modelos.
Por ejemplo, se podría aplicar un posprocesamiento a un modelo de clasificación binaria estableciendo un umbral de clasificación de modo que se mantenga la igualdad de oportunidades para algún atributo verificando que la tasa de verdaderos positivos sea la misma para todos los valores de ese atributo.
precision
Es una métrica para los modelos de clasificación que responde la siguiente pregunta:
Cuando el modelo predijo la clase positiva, ¿qué porcentaje de las predicciones fueron correctas?
Esta es la fórmula:
Donde:
- Un verdadero positivo significa que el modelo predijo correctamente la clase positiva.
- Un falso positivo significa que el modelo predijo erróneamente la clase positiva.
Por ejemplo, supongamos que un modelo realizó 200 predicciones positivas. De estas 200 predicciones positivas, se obtuvieron los siguientes resultados:
- 150 fueron verdaderos positivos.
- 50 fueron falsos positivos.
En este caso, ocurre lo siguiente:
Compara esto con la exactitud y la recuperación.
Consulta Clasificación: Precisión, recuperación, exactitud y métricas relacionadas en el Curso intensivo de aprendizaje automático para obtener más información.
predicción
Es el resultado de un modelo. Por ejemplo:
- La predicción de un modelo de clasificación binaria es la clase positiva o la clase negativa.
- La predicción de un modelo de clasificación de varias clases es una clase.
- La predicción de un modelo de regresión lineal es un número.
etiquetas de proxy
Son los datos que se usan para aproximar etiquetas que no están disponibles en el conjunto de datos de forma directa.
Por ejemplo, supongamos que debes entrenar un modelo para predecir el nivel de estrés de los empleados. Tu conjunto de datos contiene muchas variables predictivas, pero no una etiqueta llamada nivel de estrés. Sin desanimarte, eliges "accidentes laborales" como etiqueta sustituta para el nivel de estrés. Después de todo, los empleados con mucho estrés tienen más accidentes que los empleados tranquilos. ¿O sí? Quizás los accidentes laborales aumenten y disminuyan por varios motivos.
Como segundo ejemplo, supongamos que deseas que ¿Está lloviendo? sea una etiqueta booleana para tu conjunto de datos, pero este no contiene datos sobre lluvia. Si hay fotografías disponibles, podrías establecer imágenes de personas con paraguas como una etiqueta de proxy para ¿está lloviendo? ¿Es esa una buena etiqueta de proxy? Es posible, pero las personas de algunas culturas pueden ser más propensas a llevar paraguas para protegerse del sol que de la lluvia.
Las etiquetas de proxy suelen ser imperfectas. Cuando sea posible, elige etiquetas reales en lugar de etiquetas proxy. Dicho esto, cuando no haya una etiqueta real, elige la etiqueta proxy con mucho cuidado y selecciona la opción menos horrible.
Consulta Conjuntos de datos: Etiquetas en el Curso intensivo de aprendizaje automático para obtener más información.
R
RAG
Abreviatura de generación aumentada por recuperación.
evaluador
Es una persona que proporciona etiquetas para ejemplos. "Anotador" es otro nombre para calificador.
Para obtener más información, consulta Datos categóricos: Problemas comunes en el Curso intensivo de aprendizaje automático.
recall
Es una métrica para los modelos de clasificación que responde la siguiente pregunta:
Cuando la verdad fundamental era la clase positiva, ¿qué porcentaje de predicciones identificó correctamente el modelo como la clase positiva?
Esta es la fórmula:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
Donde:
- Un verdadero positivo significa que el modelo predijo correctamente la clase positiva.
- Un falso negativo significa que el modelo predijo erróneamente la clase negativa.
Por ejemplo, supongamos que tu modelo realizó 200 predicciones sobre ejemplos para los que la verdad fundamental era la clase positiva. De estas 200 predicciones, se cumplen las siguientes:
- 180 fueron verdaderos positivos.
- 20 fueron falsos negativos.
En este caso, ocurre lo siguiente:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Consulta Clasificación: Métricas de precisión, recuperación, exactitud y relacionadas para obtener más información.
Unidad lineal rectificada (ReLU)
Una función de activación con el siguiente comportamiento:
- Si la entrada es negativa o cero, la salida es 0.
- Si la entrada es positiva, el resultado es igual a la entrada.
Por ejemplo:
- Si la entrada es -3, la salida es 0.
- Si la entrada es +3, el resultado es 3.0.
A continuación, se muestra un gráfico de la ReLU:
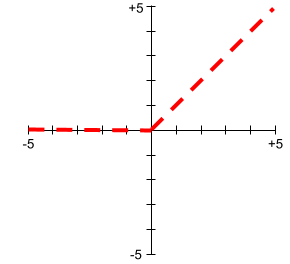
La ReLU es una función de activación muy popular. A pesar de su comportamiento simple, ReLU permite que una red neuronal aprenda relaciones no lineales entre los atributos y la etiqueta.
modelo de regresión
De manera informal, un modelo que genera una predicción numérica. (En cambio, un modelo de clasificación genera una predicción de clase). Por ejemplo, todos los siguientes son modelos de regresión:
- Un modelo que predice el valor de una casa determinada en euros, por ejemplo, 423,000.
- Un modelo que predice la esperanza de vida de un árbol determinado en años, por ejemplo, 23.2.
- Un modelo que predice la cantidad de lluvia en pulgadas que caerá en una ciudad determinada durante las próximas seis horas, por ejemplo, 0.18.
Estos son dos tipos comunes de modelos de regresión:
- Regresión lineal, que encuentra la línea que mejor se ajusta a los valores de la etiqueta para los atributos.
- La regresión logística, que genera una probabilidad entre 0.0 y 1.0 que un sistema suele asignar a una predicción de clase.
No todos los modelos que generan predicciones numéricas son modelos de regresión. En algunos casos, una predicción numérica es en realidad un modelo de clasificación que tiene nombres de clase numéricos. Por ejemplo, un modelo que predice un código postal numérico es un modelo de clasificación, no un modelo de regresión.
regularización
Cualquier mecanismo que reduzca el sobreajuste Entre los tipos populares de regularización, se incluyen los siguientes:
- Regularización L1
- Regularización de L2
- Regularización de retirados
- Interrupción anticipada (este no es un método de regularización formal, pero puede limitar el sobreajuste de manera eficaz)
La regularización también se puede definir como la penalización de la complejidad de un modelo.
Consulta Sobreajuste: complejidad del modelo en el Curso intensivo de aprendizaje automático para obtener más información.
tasa de regularización
Es un número que especifica la importancia relativa de la regularización durante el entrenamiento. Aumentar la tasa de regularización reduce el sobreajuste, pero puede disminuir la capacidad predictiva del modelo. Por el contrario, reducir u omitir la tasa de regularización aumenta el sobreajuste.
Consulta Sobreajuste: Regularización L2 en el Curso intensivo de aprendizaje automático para obtener más información.
ReLU
Abreviatura de unidad lineal rectificada.
Generación mejorada por recuperación (RAG)
Técnica para mejorar la calidad del resultado del modelo de lenguaje grande (LLM) fundamentándolo con fuentes de conocimiento recuperadas después del entrenamiento del modelo. La RAG mejora la precisión de las respuestas de los LLM, ya que les proporciona acceso a información recuperada de bases de conocimiento o documentos confiables.
Entre las motivaciones comunes para usar la generación mejorada por recuperación, se incluyen las siguientes:
- Aumentar la exactitud fáctica de las respuestas generadas por un modelo
- Darle acceso al modelo a conocimientos con los que no se entrenó
- Cambiar el conocimiento que usa el modelo
- Permite que el modelo cite fuentes.
Por ejemplo, supongamos que una app de química usa la API de PaLM para generar resúmenes relacionados con las búsquedas de los usuarios. Cuando el backend de la app recibe una búsqueda, hace lo siguiente:
- Busca (o "recupera") datos relevantes para la búsqueda del usuario.
- Agrega ("aumenta") los datos químicos pertinentes a la búsqueda del usuario.
- Indica al LLM que cree un resumen basado en los datos adjuntos.
Curva ROC (característica operativa del receptor)
Es un gráfico de la tasa de verdaderos positivos en comparación con la tasa de falsos positivos para diferentes umbrales de clasificación en la clasificación binaria.
La forma de una curva ROC sugiere la capacidad de un modelo de clasificación binaria para separar las clases positivas de las negativas. Supongamos, por ejemplo, que un modelo de clasificación binaria separa perfectamente todas las clases negativas de todas las clases positivas:
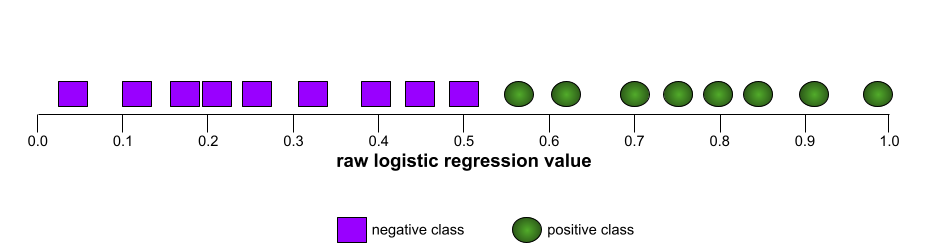
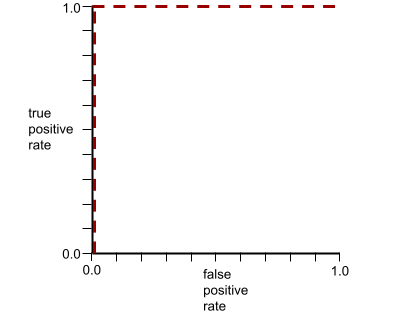
La curva ROC del modelo anterior se ve de la siguiente manera:
En cambio, en la siguiente ilustración, se grafican los valores de regresión logística sin procesar para un modelo deficiente que no puede separar las clases negativas de las positivas:
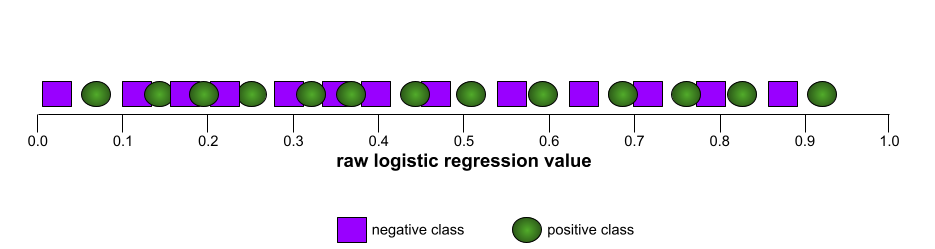
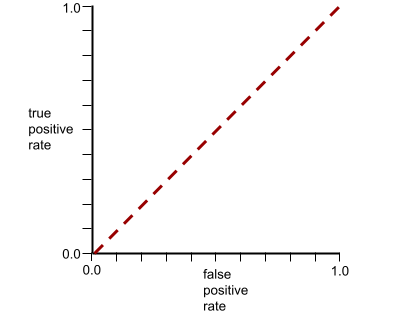
La curva ROC para este modelo se ve de la siguiente manera:
Mientras tanto, en el mundo real, la mayoría de los modelos de clasificación binaria separan las clases positivas y negativas en cierto grado, pero no de forma perfecta. Por lo tanto, una curva ROC típica se encuentra en algún punto entre los dos extremos:
En teoría, el punto de una curva ROC más cercano a (0.0, 1.0) identifica el umbral de clasificación ideal. Sin embargo, varios otros problemas del mundo real influyen en la selección del umbral de clasificación ideal. Por ejemplo, tal vez los falsos negativos causen mucho más dolor que los falsos positivos.
Una métrica numérica llamada AUC resume la curva ROC en un solo valor de punto flotante.
Raíz cuadrada del error cuadrático medio (RMSE)
Raíz cuadrada del error cuadrático medio.
S
función sigmoidea
Función matemática que "comprime" un valor de entrada en un rango restringido, generalmente de 0 a 1 o de -1 a +1. Es decir, puedes pasar cualquier número (dos, un millón, mil millones negativos, lo que sea) a una sigmoide y el resultado seguirá estando en el rango restringido. El gráfico de la función de activación sigmoidea se ve de la siguiente manera:
La función sigmoidea tiene varios usos en el aprendizaje automático, incluidos los siguientes:
- Convierte el resultado sin procesar de un modelo de regresión logística o de regresión multinomial en una probabilidad.
- Actúa como una función de activación en algunas redes neuronales.
softmax
Función que determina las probabilidades para cada clase posible en un modelo de clasificación de clases múltiples. Las probabilidades suman exactamente 1.0. Por ejemplo, en la siguiente tabla, se muestra cómo la función softmax distribuye varias probabilidades:
| La imagen es… | Probabilidad |
|---|---|
| perro | .85 |
| cat | .13 |
| caballo | 0.02 |
Softmax también se denomina softmax completo.
Compara esto con el muestreo de candidatos.
Consulta Redes neuronales: clasificación de clases múltiples en el Curso intensivo de aprendizaje automático para obtener más información.
atributo disperso
Es un atributo cuyos valores son predominantemente cero o están vacíos. Por ejemplo, una característica que contiene un solo valor 1 y un millón de valores 0 es dispersa. En cambio, un atributo denso tiene valores que no son predominantemente cero ni están vacíos.
En el aprendizaje automático, una cantidad sorprendente de atributos son atributos dispersos. Los atributos categóricos suelen ser atributos dispersos. Por ejemplo, de las 300 especies de árboles posibles en un bosque, un solo ejemplo podría identificar solo un arce. O bien, de los millones de videos posibles en una biblioteca de videos, un solo ejemplo podría identificar solo "Casablanca".
En un modelo, por lo general, representas los atributos dispersos con la codificación one-hot. Si la codificación one-hot es grande, puedes colocar una capa de embedding sobre la codificación one-hot para obtener una mayor eficiencia.
representación dispersa
Almacena solo las posiciones de los elementos distintos de cero en una característica dispersa.
Por ejemplo, supongamos que un atributo categórico llamado species identifica las 36 especies de árboles en un bosque en particular. Además, supongamos que cada ejemplo identifica solo una especie.
Podrías usar un vector one-hot para representar las especies de árboles en cada ejemplo.
Un vector one-hot contendría un solo 1 (para representar la especie de árbol en particular en ese ejemplo) y 35 0 (para representar las 35 especies de árboles que no se incluyen en ese ejemplo). Por lo tanto, la representación one-hot de maple podría verse de la siguiente manera:

Como alternativa, la representación dispersa simplemente identificaría la posición de la especie en particular. Si maple está en la posición 24, su representación dispersa sería la siguiente:maple
24
Observa que la representación dispersa es mucho más compacta que la representación one-hot.
Haz clic en el ícono para ver un ejemplo un poco más complejo.
Supongamos que cada ejemplo de tu modelo debe representar las palabras (pero no el orden de esas palabras) en una oración en inglés. El inglés consta de aproximadamente 170,000 palabras, por lo que es una característica categórica con alrededor de 170,000 elementos. La mayoría de las oraciones en inglés usan una fracción extremadamente pequeña de esas 170,000 palabras, por lo que el conjunto de palabras en un solo ejemplo casi con certeza serán datos dispersos.
Considera la siguiente oración:
My dog is a great dog
Podrías usar una variante del vector one-hot para representar las palabras de esta oración. En esta variante, varias celdas del vector pueden contener un valor distinto de cero. Además, en esta variante, una celda puede contener un número entero distinto de uno. Si bien las palabras "mi", "es", "un" y "gran" aparecen solo una vez en la oración, la palabra "perro" aparece dos veces. Si se usa esta variante de vectores one-hot para representar las palabras de esta oración, se obtiene el siguiente vector de 170,000 elementos:

Una representación dispersa de la misma oración sería simplemente la siguiente:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Consulta Cómo trabajar con datos categóricos en el Curso intensivo de aprendizaje automático para obtener más información.
vector disperso
Vector cuyos valores son predominantemente cero. Consulta también atributo disperso y dispersión.
pérdida al cuadrado
Sinónimo de pérdida L2.
static
Es algo que se hace una vez en lugar de continuamente. Los términos estático y sin conexión son sinónimos. A continuación, se indican los usos comunes de estático y sin conexión en el aprendizaje automático:
- Un modelo estático (o modelo sin conexión) es un modelo que se entrena una sola vez y, luego, se usa durante un tiempo.
- El entrenamiento estático (o entrenamiento sin conexión) es el proceso de entrenar un modelo estático.
- La inferencia estática (o inferencia sin conexión) es un proceso en el que un modelo genera un lote de predicciones a la vez.
Compara esto con dinámico.
Inferencia estática
Sinónimo de inferencia sin conexión.
Estacionariedad
Es una característica cuyos valores no cambian en una o más dimensiones, por lo general, el tiempo. Por ejemplo, un atributo cuyos valores se ven casi iguales en 2021 y 2023 presenta estacionariedad.
En el mundo real, muy pocas variables presentan estacionariedad. Incluso las características sinónimas de estabilidad (como el nivel del mar) cambian con el tiempo.
Compara esto con la no estacionariedad.
descenso de gradientes estocástico (SGD)
Algoritmo de descenso de gradientes en el que el tamaño del lote es uno. En otras palabras, el SGD se entrena con un solo ejemplo elegido al azar de manera uniforme de un conjunto de entrenamiento.
Consulta Regresión lineal: Hiperparámetros en el Curso intensivo de aprendizaje automático para obtener más información.
aprendizaje automático supervisado
Entrenar un modelo a partir de atributos y sus etiquetas correspondientes El aprendizaje automático supervisado es análogo a aprender una materia estudiando un conjunto de preguntas y sus respuestas correspondientes. Después de dominar la correlación entre preguntas y respuestas, el estudiante puede proporcionar respuestas a preguntas nuevas (nunca antes vistas) sobre el mismo tema.
Compara esto con el aprendizaje automático no supervisado.
Consulta Aprendizaje supervisado en el curso Introducción al AA para obtener más información.
atributo sintético
Un atributo que no está presente entre los atributos de entrada, pero que se ensambla a partir de uno o más de ellos. Entre los métodos para crear atributos sintéticos, se incluyen los siguientes:
- Agrupamiento de un atributo continuo en discretizaciones de rango
- Creación de una combinación de atributos
- Multiplicación (o división) de un valor de atributo por otros valores de atributos o por sí mismo Por ejemplo, si
aybson atributos de entrada, los siguientes son ejemplos de atributos sintéticos:- ab
- a2
- Aplicar una función trascendental a un valor de atributo Por ejemplo, si
ces un atributo de entrada, los siguientes son ejemplos de atributos sintéticos:- sin(c)
- ln(c)
Los atributos creados solo por normalización o escalamiento no se consideran atributos sintéticos.
T
Pérdida de prueba
Es una métrica que representa la pérdida de un modelo en relación con el conjunto de prueba. Cuando compilas un modelo, por lo general, intentas minimizar la pérdida de la prueba. Esto se debe a que una pérdida de prueba baja es un indicador de calidad más sólido que una pérdida de entrenamiento baja o una pérdida de validación baja.
A veces, una gran brecha entre la pérdida de prueba y la pérdida de entrenamiento o la pérdida de validación sugiere que debes aumentar la tasa de regularización.
entrenamiento
Proceso de determinar los parámetros ideales (pesos y sesgos) que conforman un modelo. Durante el entrenamiento, un sistema lee ejemplos y ajusta los parámetros de forma gradual. El entrenamiento usa cada ejemplo desde algunas veces hasta miles de millones de veces.
Consulta Aprendizaje supervisado en el curso Introducción al AA para obtener más información.
Pérdida de entrenamiento
Es una métrica que representa la pérdida de un modelo durante una iteración de entrenamiento en particular. Por ejemplo, supongamos que la función de pérdida es el error cuadrático medio. Quizás la pérdida de entrenamiento (el error cuadrático medio) para la décima iteración sea de 2.2, y la pérdida de entrenamiento para la iteración número 100 sea de 1.9.
Una curva de pérdida representa la pérdida de entrenamiento en función de la cantidad de iteraciones. Una curva de pérdida proporciona las siguientes sugerencias sobre el entrenamiento:
- Una pendiente descendente implica que el modelo está mejorando.
- Una pendiente ascendente implica que el modelo está empeorando.
- Una pendiente plana implica que el modelo alcanzó la convergencia.
Por ejemplo, la siguiente curva de pérdida algo idealizada muestra lo siguiente:
- Una pendiente descendente pronunciada durante las iteraciones iniciales, lo que implica una mejora rápida del modelo
- Una pendiente que se aplana gradualmente (pero que sigue siendo descendente) hasta cerca del final del entrenamiento, lo que implica una mejora continua del modelo a un ritmo algo más lento que durante las iteraciones iniciales.
- Una pendiente plana hacia el final del entrenamiento, lo que sugiere convergencia.
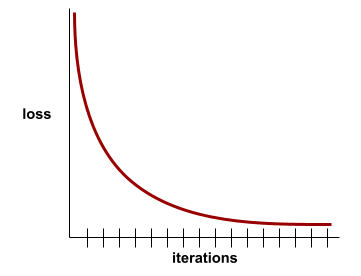
Si bien la pérdida de entrenamiento es importante, también debes consultar la generalización.
Sesgo entre el entrenamiento y la entrega
La diferencia entre el rendimiento de un modelo durante el entrenamiento y el rendimiento del mismo modelo durante la deriva.
conjunto de entrenamiento
Es el subconjunto del conjunto de datos que se usa para entrenar un modelo.
Tradicionalmente, los ejemplos del conjunto de datos se dividen en los siguientes tres subconjuntos distintos:
- un conjunto de entrenamiento
- un conjunto de validación
- un conjunto de prueba
Lo ideal es que cada ejemplo del conjunto de datos pertenezca a solo uno de los subconjuntos anteriores. Por ejemplo, un solo ejemplo no debe pertenecer al conjunto de entrenamiento y al conjunto de validación.
Consulta Conjuntos de datos: Cómo dividir el conjunto de datos original en el Curso intensivo de aprendizaje automático para obtener más información.
verdadero negativo (VN)
Ejemplo en el que el modelo predice correctamente la clase negativa. Por ejemplo, el modelo infiere que un mensaje de correo electrónico en particular no es spam y, en efecto, ese mensaje no es spam.
verdadero positivo (VP)
Ejemplo en el que el modelo predice correctamente la clase positiva. Por ejemplo, el modelo infiere que un mensaje de correo electrónico en particular es spam y realmente lo es.
tasa de verdaderos positivos (TVP)
Sinónimo de recuperación. Es decir:
La tasa de verdaderos positivos es el eje Y en una curva ROC.
U
Subajuste
Producir un modelo con poca capacidad predictiva porque el modelo no ha capturado por completo la complejidad de los datos de entrenamiento. El subajuste puede estar causado por varios problemas, como los siguientes:
- Entrenamiento con el conjunto incorrecto de atributos
- Entrenamiento con pocos ciclos o con una tasa de aprendizaje demasiado baja
- Entrenamiento con una tasa de regularización demasiado alta
- Establecer muy pocas capas ocultas en una red neuronal profunda
Consulta Sobreajuste en el Curso intensivo de aprendizaje automático para obtener más información.
ejemplo sin etiqueta
Es un ejemplo que contiene atributos, pero no una etiqueta. Por ejemplo, la siguiente tabla muestra tres ejemplos sin etiquetar de un modelo de valuación de viviendas, cada uno con tres atributos, pero sin valor de la vivienda:
| Cantidad de dormitorios | Cantidad de baños | Antigüedad de la casa |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
En el aprendizaje automático supervisado, los modelos se entrenan con ejemplos etiquetados y realizan predicciones sobre ejemplos sin etiqueta.
En el aprendizaje semisupervisado y no supervisado, los ejemplos sin etiqueta se usan durante el entrenamiento.
Compara el ejemplo sin etiqueta con el ejemplo etiquetado.
aprendizaje automático no supervisado
Entrenamiento de un modelo para encontrar patrones en un conjunto de datos, generalmente sin etiqueta.
El uso más común del aprendizaje automático no supervisado es la agrupación en clústeres de datos en grupos de ejemplos similares. Por ejemplo, un algoritmo de aprendizaje automático no supervisado puede agrupar canciones según varias propiedades de la música. Los clústeres resultantes pueden convertirse en una entrada para otros algoritmos de aprendizaje automático (por ejemplo, para un servicio de recomendación de música). El agrupamiento en clústeres puede ser útil cuando las etiquetas útiles son escasas o no están disponibles. Por ejemplo, en dominios como la protección contra el abuso y el fraude, los clústeres pueden ayudar a los humanos a comprender mejor los datos.
Compara esto con el aprendizaje automático supervisado.
Consulta ¿Qué es el aprendizaje automático? en el curso Introducción al AA para obtener más información.
V
validación
Es la evaluación inicial de la calidad de un modelo. La validación verifica la calidad de las predicciones de un modelo en comparación con el conjunto de validación.
Dado que el conjunto de validación difiere del conjunto de entrenamiento, la validación ayuda a evitar el sobreajuste.
Podrías pensar que evaluar el modelo con el conjunto de validación es la primera ronda de pruebas y que evaluar el modelo con el conjunto de prueba es la segunda ronda de pruebas.
Pérdida de validación
Es una métrica que representa la pérdida de un modelo en el conjunto de validación durante una iteración particular del entrenamiento.
Consulta también curva de generalización.
conjunto de validación
Es el subconjunto del conjunto de datos que realiza la evaluación inicial con un modelo entrenado. Por lo general, evalúas el modelo entrenado con el conjunto de validación varias veces antes de evaluarlo con el conjunto de prueba.
Tradicionalmente, los ejemplos del conjunto de datos se dividen en los siguientes tres subconjuntos distintos:
- un conjunto de entrenamiento
- un conjunto de validación
- un conjunto de prueba
Lo ideal es que cada ejemplo del conjunto de datos pertenezca a solo uno de los subconjuntos anteriores. Por ejemplo, un solo ejemplo no debe pertenecer al conjunto de entrenamiento y al conjunto de validación.
Consulta Conjuntos de datos: Cómo dividir el conjunto de datos original en el Curso intensivo de aprendizaje automático para obtener más información.
W
peso
Es un valor por el que un modelo multiplica otro valor. El entrenamiento es el proceso de determinar los pesos ideales de un modelo; la inferencia es el proceso de usar esos pesos aprendidos para hacer predicciones.
Consulta Regresión lineal en el Curso intensivo de aprendizaje automático para obtener más información.
suma ponderada
Es la suma de todos los valores de entrada relevantes multiplicados por sus pesos correspondientes. Por ejemplo, supongamos que las entradas pertinentes son las siguientes:
| valor de entrada | Peso de entrada |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
Por lo tanto, la suma ponderada es la siguiente:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Una suma ponderada es el argumento de entrada para una función de activación.
Z
Normalización de la puntuación Z
Técnica de ajuste que reemplaza un valor de atributo sin procesar por un valor de punto flotante que representa la cantidad de desviaciones estándares desde la media de ese atributo. Por ejemplo, considera un atributo cuya media es 800 y cuya desviación estándar es 100. En la siguiente tabla, se muestra cómo la normalización de la puntuación Z mapearía el valor sin procesar a su puntuación Z:
| Valor sin procesar | Puntuación Z |
|---|---|
| 800 | 0 |
| 950 | +1.5 |
| 575 | -2.25 |
Luego, el modelo de aprendizaje automático se entrena con las puntuaciones Z de ese atributo en lugar de con los valores sin procesar.
Consulta Datos numéricos: Normalización en el Curso intensivo de aprendizaje automático para obtener más información.