इस पेज पर, एमएल के बुनियादी सिद्धांतों से जुड़े शब्दों की शब्दावली दी गई है. सभी शब्दावली के लिए, यहां क्लिक करें.
A
सटीक
सही क्लासिफ़िकेशन अनुमानों की संख्या को अनुमानों की कुल संख्या से भाग देने पर यह स्कोर मिलता है. यानी:
उदाहरण के लिए, अगर किसी मॉडल ने 40 अनुमान सही लगाए और 10 अनुमान गलत लगाए, तो उसकी सटीकता इस तरह से कैलकुलेट की जाएगी:
बाइनरी क्लासिफ़िकेशन में, सही अनुमानों और गलत अनुमानों की अलग-अलग कैटगरी के लिए खास नाम दिए गए हैं. इसलिए, बाइनरी क्लासिफ़िकेशन के लिए सटीक नतीजे का फ़ॉर्मूला यह है:
कहां:
- टीपी, ट्रू पॉज़िटिव (सही अनुमान) की संख्या है.
- TN, ट्रू नेगेटिव (सही अनुमान) की संख्या है.
- एफ़पी, फ़ॉल्स पॉज़िटिव (गलत अनुमान) की संख्या होती है.
- FN, फ़ॉल्स निगेटिव (गलत अनुमान) की संख्या है.
प्रिसिज़न और रीकॉल के साथ, सटीकता की तुलना करें और इनके बीच अंतर बताएं.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: सटीकता, रीकॉल, प्रेसिज़न, और इनसे जुड़ी मेट्रिक देखें.
ऐक्टिवेशन फ़ंक्शन
यह एक ऐसा फ़ंक्शन है जो न्यूरल नेटवर्क को सुविधाओं और लेबल के बीच नॉनलीनियर (जटिल) संबंधों को समझने में मदद करता है.
लोकप्रिय ऐक्टिवेशन फ़ंक्शन में ये शामिल हैं:
ऐक्टिवेशन फ़ंक्शन के प्लॉट कभी भी सीधी लाइनें नहीं होते. उदाहरण के लिए, ReLU ऐक्टिवेशन फ़ंक्शन के प्लॉट में दो सीधी लाइनें होती हैं:

सिगमॉइड ऐक्टिवेशन फ़ंक्शन का प्लॉट ऐसा दिखता है:

उदाहरण देखने के लिए, आइकॉन पर क्लिक करें.
न्यूरल नेटवर्क में, ऐक्टिवेशन फ़ंक्शन, न्यूरॉन के सभी इनपुट के वेटेड सम में बदलाव करते हैं. वेटेड सम का हिसाब लगाने के लिए, न्यूरॉन काम की वैल्यू और वेट के प्रॉडक्ट को जोड़ता है. उदाहरण के लिए, मान लें कि किसी न्यूरॉन के लिए ज़रूरी इनपुट में यह जानकारी शामिल है:
| इनपुट वैल्यू | इनपुट वज़न |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
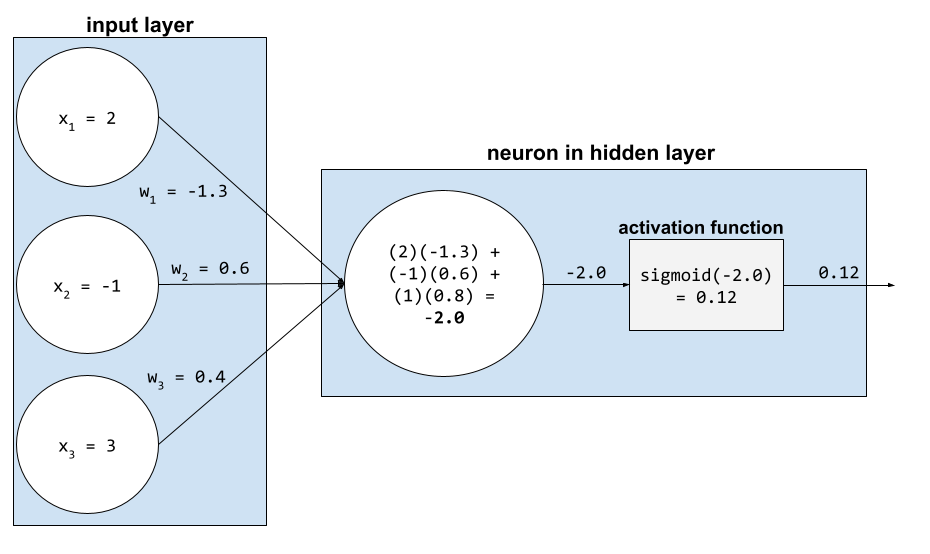
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: ऐक्टिवेशन फ़ंक्शन देखें.
आर्टिफ़िशियल इंटेलिजेंस
ऐसा प्रोग्राम या मॉडल जो इंसानों की तरह काम करता है और मुश्किल टास्क को हल कर सकता है. उदाहरण के लिए, टेक्स्ट का अनुवाद करने वाला प्रोग्राम या मॉडल या रेडियोलॉजिकल इमेज से बीमारियों का पता लगाने वाला प्रोग्राम या मॉडल, दोनों में आर्टिफ़िशियल इंटेलिजेंस का इस्तेमाल किया जाता है.
आधिकारिक तौर पर, मशीन लर्निंग, आर्टिफ़िशियल इंटेलिजेंस का एक उप-क्षेत्र है. हालांकि, हाल के वर्षों में कुछ संगठन, आर्टिफ़िशियल इंटेलिजेंस और मशीन लर्निंग शब्दों का इस्तेमाल एक-दूसरे की जगह कर रहे हैं.
AUC (आरओसी कर्व के नीचे का हिस्सा)
यह 0.0 से 1.0 के बीच की एक संख्या होती है. यह बाइनरी क्लासिफ़िकेशन मॉडल की, पॉज़िटिव क्लास को नेगेटिव क्लास से अलग करने की क्षमता को दिखाती है. एयूसी की वैल्यू 1.0 के जितनी ज़्यादा करीब होगी, मॉडल की परफ़ॉर्मेंस उतनी ही बेहतर होगी.
उदाहरण के लिए, इस इमेज में एक वर्गीकरण मॉडल दिखाया गया है. यह पॉज़िटिव क्लास (हरे रंग के ओवल) को नेगेटिव क्लास (बैंगनी रंग के आयत) से पूरी तरह अलग करता है. इस मॉडल का एयूसी 1.0 है, जो कि काफ़ी अच्छा है:

इसके उलट, यहां दिए गए उदाहरण में, क्लासिफ़िकेशन मॉडल के नतीजे दिखाए गए हैं. इस मॉडल ने रैंडम नतीजे जनरेट किए हैं. इस मॉडल का एयूसी 0.5 है:

हां, पिछले मॉडल का एयूसी 0.5 है, न कि 0.0.
ज़्यादातर मॉडल, इन दोनों के बीच में कहीं होते हैं. उदाहरण के लिए, यहां दिया गया मॉडल, पॉज़िटिव और नेगेटिव वैल्यू को कुछ हद तक अलग करता है. इसलिए, इसका एयूसी 0.5 और 1.0 के बीच है:

एयूसी, क्लासिफ़िकेशन थ्रेशोल्ड के लिए सेट की गई किसी भी वैल्यू को अनदेखा करता है. इसके बजाय, एयूसी, क्लासिफ़िकेशन के सभी संभावित थ्रेशोल्ड पर विचार करता है.
एयूसी और आरओसी कर्व के बीच के संबंध के बारे में जानने के लिए, आइकॉन पर क्लिक करें.
AUC, ROC कर्व के नीचे के क्षेत्र को दिखाता है. उदाहरण के लिए, किसी ऐसे मॉडल के लिए आरओसी कर्व यहां दिया गया है जो पॉज़िटिव और नेगेटिव को पूरी तरह से अलग करता है:
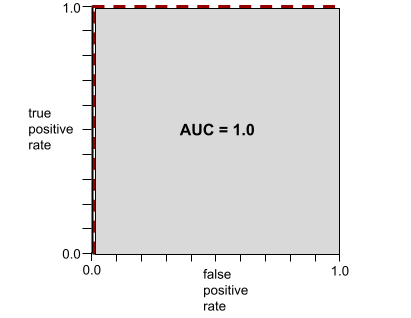
एयूसी, ऊपर दिए गए इलस्ट्रेशन में ग्रे रंग वाला हिस्सा है. इस खास मामले में, क्षेत्रफल निकालने के लिए ग्रे रंग वाले हिस्से की लंबाई (1.0) को ग्रे रंग वाले हिस्से की चौड़ाई (1.0) से गुणा किया जाता है. इसलिए, 1.0 और 1.0 के प्रॉडक्ट से, एयूसी का स्कोर ठीक 1.0 मिलता है. यह एयूसी का सबसे ज़्यादा स्कोर है.
इसके उलट, क्लासिफ़िकेशन मॉडल के लिए आरओसी कर्व, क्लास को अलग नहीं कर सकता. यह इस तरह दिखता है. इस ग्रे रंग के क्षेत्र का क्षेत्रफल 0.5 है.

आम तौर पर, आरओसी कर्व कुछ ऐसा दिखता है:
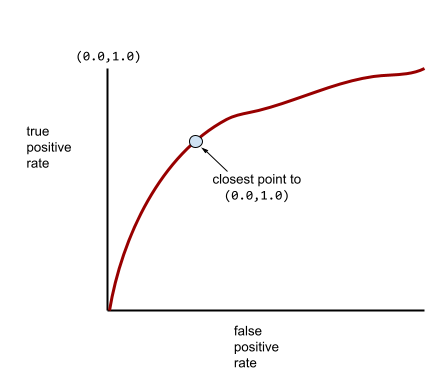
इस कर्व के नीचे के एरिया का हिसाब मैन्युअल तरीके से लगाना मुश्किल होता है. इसलिए, आम तौर पर कोई प्रोग्राम ज़्यादातर एयूसी वैल्यू का हिसाब लगाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: आरओसी और एयूसी देखें.
B
बैकप्रॉपैगेशन
यह एल्गोरिदम, न्यूरल नेटवर्क में ग्रेडिएंट डिसेंट को लागू करता है.
न्यूरल नेटवर्क को ट्रेन करने में, दो पास वाले साइकल के कई इटरेशन शामिल होते हैं. ये इटरेशन इस तरह से होते हैं:
- फ़ॉरवर्ड पास के दौरान, सिस्टम उदाहरणों के बैच को प्रोसेस करता है, ताकि अनुमान लगाया जा सके. सिस्टम, हर अनुमान की तुलना हर लेबल वैल्यू से करता है. अनुमानित वैल्यू और लेबल की वैल्यू के बीच के अंतर को उस उदाहरण के लिए लॉस कहा जाता है. सिस्टम, सभी उदाहरणों के लिए नुकसान को इकट्ठा करता है, ताकि मौजूदा बैच के लिए कुल नुकसान का हिसाब लगाया जा सके.
- बैकवर्ड पास (बैकप्रॉपैगेशन) के दौरान, सिस्टम सभी हिडन लेयर में मौजूद सभी न्यूरॉन के वेट को अडजस्ट करके, नुकसान को कम करता है.
न्यूरल नेटवर्क में, अक्सर कई हिडन लेयर में कई न्यूरॉन होते हैं. उनमें से हर न्यूरॉन, कुल नुकसान में अलग-अलग तरीके से योगदान देता है. बैकप्रॉपैगेशन से यह तय किया जाता है कि किसी न्यूरॉन पर लागू किए गए वेट को बढ़ाना है या घटाना है.
लर्निंग रेट एक मल्टीप्लायर होता है. यह कंट्रोल करता है कि हर बैकवर्ड पास, हर वेट को किस हद तक बढ़ाता या घटाता है. ज़्यादा लर्निंग रेट होने पर, हर वेट में बढ़ोतरी या गिरावट, कम लर्निंग रेट की तुलना में ज़्यादा होगी.
कैलकुलस के हिसाब से, बैकप्रॉपैगेशन में कैलकुलस का चेन रूल लागू होता है. इसका मतलब है कि बैकप्रॉपैगेशन, हर पैरामीटर के हिसाब से गड़बड़ी के आंशिक अवकलज का हिसाब लगाता है.
कुछ साल पहले, एमएल प्रैक्टिशनर को बैकप्रॉपैगेशन लागू करने के लिए कोड लिखना पड़ता था. Keras जैसे आधुनिक एमएल एपीआई, अब आपके लिए बैकप्रोपैगेशन लागू करते हैं. वाह!
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क देखें.
बैच
एक ट्रेनिंग इटरेशन में इस्तेमाल किए गए उदाहरणों का सेट. बैच साइज़ से यह तय होता है कि किसी बैच में कितने उदाहरण होंगे.
बैच का युग से क्या संबंध है, यह जानने के लिए युग देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
बैच का आकार
किसी बैच में उदाहरणों की संख्या. उदाहरण के लिए, अगर बैच का साइज़ 100 है, तो मॉडल हर इटरेशन में 100 उदाहरणों को प्रोसेस करता है.
बैच के साइज़ के लिए, यहां कुछ लोकप्रिय रणनीतियां दी गई हैं:
- स्टोकास्टिक ग्रेडिएंट डिसेंट (एसजीडी), जिसमें बैच का साइज़ 1 होता है.
- पूरा बैच, जिसमें बैच का साइज़ पूरे ट्रेनिंग सेट में मौजूद उदाहरणों की संख्या होती है. उदाहरण के लिए, अगर ट्रेनिंग सेट में 10 लाख उदाहरण शामिल हैं, तो बैच का साइज़ 10 लाख उदाहरणों का होगा. पूरे बैच को प्रोसेस करना, आम तौर पर एक असरदार रणनीति नहीं होती.
- मिनी-बैच, जिसमें बैच का साइज़ आम तौर पर 10 से 1,000 के बीच होता है. मिनी-बैच, आम तौर पर सबसे असरदार रणनीति होती है.
ज़्यादा जानकारी के लिए, यहां देखें:
- प्रोडक्शन एमएल सिस्टम: मशीन लर्निंग क्रैश कोर्स में स्टैटिक बनाम डाइनैमिक इन्फ़रेंस.
- डीप लर्निंग ट्यूनिंग प्लेबुक.
पूर्वाग्रह (नीतिशास्त्र/निष्पक्षता)
1. किसी चीज़, व्यक्ति या ग्रुप को दूसरों से बेहतर बताना या उनके बारे में पूर्वाग्रह रखना. इन पूर्वाग्रहों से, डेटा को इकट्ठा करने और उसकी व्याख्या करने, सिस्टम के डिज़ाइन, और उपयोगकर्ताओं के सिस्टम से इंटरैक्ट करने के तरीके पर असर पड़ सकता है. इस तरह के पूर्वाग्रह के उदाहरणों में ये शामिल हैं:
- ऑटोमेशन बायस
- कंफ़र्मेशन बायस
- एक्सपेरिमेंटर का पूर्वाग्रह
- ग्रुप एट्रिब्यूशन बायस
- अनजाने में भेदभाव करना
- इन-ग्रुप बायस
- आउट-ग्रुप होमोजेनिटी बायस
2. सैंपलिंग या रिपोर्टिंग की प्रोसेस की वजह से हुई सिस्टमैटिक गड़बड़ी. इस तरह के पूर्वाग्रह के उदाहरणों में ये शामिल हैं:
- कवरेज से जुड़ा पूर्वाग्रह
- नॉन-रिस्पॉन्स बायस
- सर्वे में हिस्सा लेने से जुड़ा पूर्वाग्रह
- रिपोर्टिंग बायस
- सैंपलिंग बायस
- सैंपल चुनने में होने वाला पक्षपात
इसे मशीन लर्निंग मॉडल में मौजूद बायस टर्म या पूर्वानुमान में पक्षपात से भ्रमित न करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: पूर्वाग्रह के टाइप देखें.
बायस (गणित) या बायस टर्म
किसी मूल बिंदु से इंटरसेप्ट या ऑफ़सेट. गड़बड़ी, मशीन लर्निंग मॉडल में एक पैरामीटर होता है. इसे इनमें से किसी भी तरीके से दिखाया जाता है:
- b
- w0
उदाहरण के लिए, इस फ़ॉर्मूले में b, बायस है:
आसान शब्दों में कहें, तो दो डाइमेंशन वाली लाइन में बायस का मतलब "y-इंटरसेप्ट" होता है. उदाहरण के लिए, इस इलस्ट्रेशन में लाइन का झुकाव 2 है.
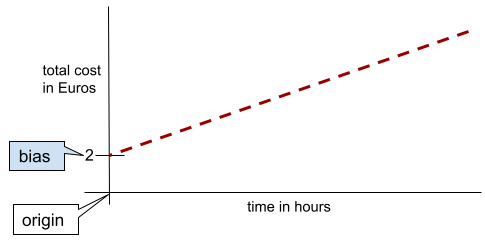
बायस इसलिए मौजूद है, क्योंकि सभी मॉडल ओरिजिन (0,0) से शुरू नहीं होते. उदाहरण के लिए, मान लें कि किसी अम्यूज़मेंट पार्क में जाने का शुल्क 200 रुपये है.इसके अलावा, हर घंटे के लिए 50 रुपये का अतिरिक्त शुल्क लगता है. इसलिए, कुल लागत को मैप करने वाले मॉडल में 2 का पूर्वाग्रह होता है, क्योंकि सबसे कम लागत 2 यूरो है.
पूर्वाग्रह को नैतिकता और निष्पक्षता में पूर्वाग्रह या अनुमान में पूर्वाग्रह से भ्रमित नहीं होना चाहिए.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन देखें.
बाइनरी क्लासिफ़िकेशन
यह क्लासिफ़िकेशन टास्क का एक टाइप है. इसमें, दो में से किसी एक क्लास के बारे में अनुमान लगाया जाता है:
उदाहरण के लिए, यहां दिए गए दोनों मशीन लर्निंग मॉडल, बाइनरी क्लासिफ़िकेशन करते हैं:
- यह मॉडल यह तय करता है कि ईमेल मैसेज स्पैम (पॉज़िटिव क्लास) हैं या स्पैम नहीं हैं (नेगेटिव क्लास).
- एक ऐसा मॉडल जो चिकित्सा से जुड़े लक्षणों का आकलन करता है. इससे यह पता चलता है कि किसी व्यक्ति को कोई खास बीमारी (पॉज़िटिव क्लास) है या नहीं (नेगेटिव क्लास).
इसकी तुलना मल्टी-क्लास क्लासिफ़िकेशन से करें.
लॉजिस्टिक रिग्रेशन और क्लासिफ़िकेशन थ्रेशोल्ड भी देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में वर्गीकरण देखें.
बकेटिंग
किसी एक फ़ीचर को कई बाइनरी फ़ीचर में बदलना. इन्हें आम तौर पर, वैल्यू रेंज के आधार पर बकेट या बिन कहा जाता है. आम तौर पर, काटी गई सुविधा एक लगातार चलने वाली सुविधा होती है.
उदाहरण के लिए, तापमान को एक फ़्लोटिंग-पॉइंट फ़ीचर के तौर पर दिखाने के बजाय, तापमान की रेंज को अलग-अलग बकेट में बांटा जा सकता है. जैसे:
- <= 10 डिग्री सेल्सियस को "ठंडा" बकेट में रखा जाएगा.
- 11 से 24 डिग्री सेल्सियस के बीच के तापमान को "सामान्य" बकेट में रखा जाएगा.
- >= 25 डिग्री सेल्सियस को "गर्म" बकेट में रखा जाएगा.
मॉडल, एक ही बकेट में मौजूद हर वैल्यू को एक जैसा मानेगा. उदाहरण के लिए, 13 और 22, दोनों वैल्यू को सामान्य बकेट में रखा गया है. इसलिए, मॉडल इन दोनों वैल्यू को एक जैसा मानता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: बिनिंग देखें.
C
कैटगोरिकल डेटा
सुविधाएं, जिनमें संभावित वैल्यू का कोई खास सेट होता है. उदाहरण के लिए, traffic-light-state नाम की कैटगरी वाली सुविधा पर विचार करें. इसकी सिर्फ़ तीन वैल्यू हो सकती हैं:
redyellowgreen
traffic-light-state को कैटगरी के हिसाब से तय की गई सुविधा के तौर पर दिखाने से, मॉडल यह जान सकता है कि ड्राइवर के व्यवहार पर red, green, और yellow का क्या असर पड़ता है.
कैटगोरिकल फ़ीचर को कभी-कभी डिसक्रीट फ़ीचर भी कहा जाता है.
संख्यात्मक डेटा से तुलना करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटगरी में बांटे गए डेटा का इस्तेमाल करना लेख पढ़ें.
क्लास
वह कैटगरी जिससे कोई लेबल जुड़ा हो सकता है. उदाहरण के लिए:
- स्पैम का पता लगाने वाले बाइनरी क्लासिफ़िकेशन मॉडल में, दो क्लास स्पैम और स्पैम नहीं है हो सकती हैं.
- मल्टी-क्लास क्लासिफ़िकेशन मॉडल में, कुत्ते की नस्लों की पहचान की जाती है. इसमें क्लास पूडल, बीगल, पग वगैरह हो सकती हैं.
क्लासिफ़िकेशन मॉडल किसी क्लास का अनुमान लगाता है. इसके उलट, रिग्रेशन मॉडल, क्लास के बजाय किसी संख्या का अनुमान लगाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में वर्गीकरण देखें.
क्लासिफ़िकेशन मॉडल
ऐसा मॉडल जिसका अनुमान, क्लास होता है. उदाहरण के लिए, यहां दिए गए सभी क्लासिफ़िकेशन मॉडल हैं:
- ऐसा मॉडल जो इनपुट किए गए वाक्य की भाषा का अनुमान लगाता है (क्या यह फ़्रेंच है? स्पैनिश? इटैलियन?).
- ऐसा मॉडल जो पेड़ की प्रजातियों का अनुमान लगाता है (मेपल? ओक? बेओबैब?).
- ऐसा मॉडल जो किसी खास बीमारी के लिए पॉज़िटिव या नेगेटिव क्लास का अनुमान लगाता है.
इसके उलट, रिग्रेशन मॉडल क्लास के बजाय संख्याओं का अनुमान लगाते हैं.
आम तौर पर, क्लासिफ़िकेशन मॉडल दो तरह के होते हैं:
श्रेणी में बाँटने की सीमा
बाइनरी क्लासिफ़िकेशन में, 0 से 1 के बीच की कोई संख्या होती है. यह लॉजिस्टिक रिग्रेशन मॉडल के रॉ आउटपुट को पॉज़िटिव क्लास या नेगेटिव क्लास के अनुमान में बदलती है. ध्यान दें कि क्लासिफ़िकेशन थ्रेशोल्ड एक ऐसी वैल्यू होती है जिसे कोई व्यक्ति चुनता है. यह मॉडल ट्रेनिंग के दौरान चुनी गई वैल्यू नहीं होती.
लॉजिस्टिक रिग्रेशन मॉडल, 0 और 1 के बीच की रॉ वैल्यू दिखाता है. इसके बाद:
- अगर यह रॉ वैल्यू, क्लासिफ़िकेशन थ्रेशोल्ड से ज़्यादा है, तो पॉज़िटिव क्लास का अनुमान लगाया जाता है.
- अगर यह रॉ वैल्यू, क्लासिफ़िकेशन थ्रेशोल्ड से कम है, तो नेगेटिव क्लास का अनुमान लगाया जाता है.
उदाहरण के लिए, मान लें कि क्लासिफ़िकेशन थ्रेशोल्ड 0.8 है. अगर रॉ वैल्यू 0.9 है, तो मॉडल पॉज़िटिव क्लास का अनुमान लगाता है. अगर रॉ वैल्यू 0.7 है, तो मॉडल नेगेटिव क्लास का अनुमान लगाता है.
क्लासिफ़िकेशन थ्रेशोल्ड चुनने से, फ़ॉल्स पॉज़िटिव और फ़ॉल्स नेगेटिव की संख्या पर काफ़ी असर पड़ता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में थ्रेशोल्ड और कन्फ़्यूज़न मैट्रिक्स देखें.
डेटा की कैटगरी तय करने वाला
क्लासिफ़िकेशन मॉडल के लिए इस्तेमाल किया जाने वाला सामान्य शब्द.
क्लास-इंबैलेंस वाला डेटासेट
क्लासिफ़िकेशन के लिए डेटासेट, जिसमें हर क्लास के लेबल की कुल संख्या में काफ़ी अंतर होता है. उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन वाले किसी डेटासेट पर विचार करें. इसके दो लेबल इस तरह बांटे गए हैं:
- 10,00,000 नेगेटिव लेबल
- 10 पॉज़िटिव लेबल
नेगेटिव और पॉज़िटिव लेबल का अनुपात 100,000 से 1 है. इसलिए, यह क्लास-इंबैलेंस वाला डेटासेट है.
इसके उलट, यहां दिया गया डेटासेट क्लास-बैलेंस है, क्योंकि नेगेटिव लेबल और पॉज़िटिव लेबल का अनुपात 1 के आस-पास है:
- 517 नेगेटिव लेबल
- 483 पॉज़िटिव लेबल
मल्टी-क्लास डेटासेट में क्लास का बैलेंस भी बिगड़ा हो सकता है. उदाहरण के लिए, यहां दिया गया मल्टी-क्लास क्लासिफ़िकेशन डेटासेट भी क्लास के असंतुलन वाला है. ऐसा इसलिए, क्योंकि एक लेबल के उदाहरण, अन्य दो लेबल के मुकाबले काफ़ी ज़्यादा हैं:
- "green" क्लास वाले 10,00,000 लेबल
- "purple" क्लास वाले 200 लेबल
- "ऑरेंज" क्लास वाले 350 लेबल
ट्रेनिंग के लिए, क्लास-इंबैलेंस वाले डेटासेट में खास चुनौतियां आ सकती हैं. ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट में क्लास का असंतुलित डिस्ट्रिब्यूशन देखें.
एंट्रॉपी, मेजर क्लास}, और माइनर क्लास के बारे में भी जानें.
क्लिपिंग
यह आउटलायर को मैनेज करने का एक तरीका है. इसके तहत, इनमें से कोई एक या दोनों काम किए जाते हैं:
- सुविधा की उन वैल्यू को कम करना जो ज़्यादा से ज़्यादा थ्रेशोल्ड से ज़्यादा हैं. इन वैल्यू को ज़्यादा से ज़्यादा थ्रेशोल्ड तक कम किया जाता है.
- सुविधा की उन वैल्यू को बढ़ाना जो कम से कम थ्रेशोल्ड से कम हैं, ताकि वे कम से कम थ्रेशोल्ड तक पहुंच सकें.
उदाहरण के लिए, मान लें कि किसी सुविधा के लिए, 0.5% से कम वैल्यू, 40 से 60 के बीच की सीमा से बाहर हैं. इस मामले में, ये काम किए जा सकते हैं:
- 60 से ज़्यादा की सभी वैल्यू को 60 पर सेट करें. यह ज़्यादा से ज़्यादा थ्रेशोल्ड है.
- 40 से कम (कम से कम थ्रेशोल्ड) वाली सभी वैल्यू को 40 पर सेट करें.
आउटलायर, मॉडल को नुकसान पहुंचा सकते हैं. कभी-कभी, ट्रेनिंग के दौरान वज़न ज़्यादा हो जाते हैं. कुछ आउटलायर, सटीकता जैसी मेट्रिक को भी काफ़ी हद तक खराब कर सकते हैं. क्लिपिंग, नुकसान को कम करने का एक सामान्य तरीका है.
ग्रेडिएंट क्लिपिंग, ट्रेनिंग के दौरान ग्रेडिएंट की वैल्यू को तय की गई रेंज में रखती है.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में संख्यात्मक डेटा: नॉर्मलाइज़ेशन देखें.
कन्फ़्यूज़न मैट्रिक्स
यह NxN टेबल होती है. इसमें क्लासिफ़िकेशन मॉडल के सही और गलत अनुमानों की संख्या के बारे में खास जानकारी दी जाती है. उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल के लिए, यहां दी गई कन्फ़्यूज़न मैट्रिक्स देखें:
| ट्यूमर (अनुमानित) | नॉन-ट्यूमर (अनुमानित) | |
|---|---|---|
| ट्यूमर (ग्राउंड ट्रुथ) | 18 (TP) | 1 (FN) |
| ट्यूमर नहीं है (असल डेटा) | 6 (FP) | 452 (TN) |
ऊपर दी गई कन्फ़्यूज़न मैट्रिक्स में यह जानकारी दिखती है:
- ट्यूमर के 19 अनुमानों में से, मॉडल ने 18 अनुमानों को सही तरीके से और 1 अनुमान को गलत तरीके से क्लासिफ़ाई किया.
- 458 अनुमानों में से, मॉडल ने 452 अनुमानों को सही तरीके से और 6 अनुमानों को गलत तरीके से क्लासिफ़ाई किया. इन अनुमानों में, ग्राउंड ट्रुथ के तौर पर नॉन-ट्यूमर की जानकारी दी गई थी.
मल्टी-क्लास क्लासिफ़िकेशन की समस्या के लिए कन्फ़्यूज़न मैट्रिक्स की मदद से, गलतियों के पैटर्न की पहचान की जा सकती है. उदाहरण के लिए, तीन क्लास वाले मल्टी-क्लास क्लासिफ़िकेशन मॉडल के लिए, यहां दी गई कन्फ़्यूज़न मैट्रिक्स देखें. यह मॉडल, आइरिस की तीन अलग-अलग प्रजातियों (वर्जिनिका, वर्सीकलर, और सेटोसा) को कैटगरी में बांटता है. जब ग्राउंड ट्रुथ वर्जिनिका था, तब कन्फ़्यूज़न मैट्रिक्स से पता चलता है कि मॉडल ने सेटोसा के मुकाबले वर्सिकलर का अनुमान ज़्यादा गलत तरीके से लगाया:
| सेटोज़ा (अनुमानित) | वर्सीकलर (अनुमानित) | वर्जिनिका (अनुमानित) | |
|---|---|---|---|
| सेटोज़ा (ग्राउंड ट्रूथ) | 88 | 12 | 0 |
| वर्सीकलर (ग्राउंड ट्रुथ) | 6 | 141 | 7 |
| वर्जिनिका (ग्राउंड ट्रुथ) | 2 | 27 | 109 |
एक और उदाहरण के तौर पर, कन्फ़्यूज़न मैट्रिक्स से पता चल सकता है कि हाथ से लिखे गए अंकों को पहचानने के लिए ट्रेन किए गए मॉडल में, 4 की जगह 9 या 7 की जगह 1 का अनुमान लगाने की गड़बड़ी होती है.
कन्फ़्यूज़न मैट्रिक्स में, परफ़ॉर्मेंस की अलग-अलग मेट्रिक का हिसाब लगाने के लिए ज़रूरी जानकारी होती है. इनमें सटीकता और रिकॉल शामिल हैं.
लगातार काम करने वाली सुविधा
फ़्लोटिंग-पॉइंट सुविधा, जिसमें वैल्यू की रेंज इनफ़िनिट होती है. जैसे, तापमान या वज़न.
इसकी तुलना डिस्क्रीट फ़ीचर से करें.
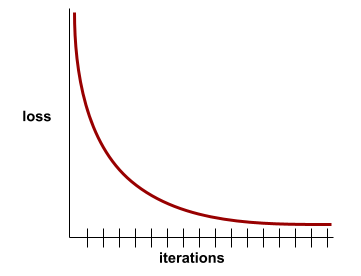
कन्वर्जेंस
यह ऐसी स्थिति होती है, जब हर इटरेशन के साथ नुकसान की वैल्यू में बहुत कम बदलाव होता है या कोई बदलाव नहीं होता. उदाहरण के लिए, यहां दिया गया लॉस कर्व, 700 इटरेशन के आस-पास कन्वर्जेंस का सुझाव देता है:
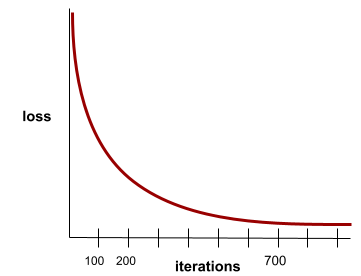
जब ज़्यादा ट्रेनिंग देने से मॉडल में सुधार नहीं होता, तो मॉडल कन्वर्ज हो जाता है.
डीप लर्निंग में, लॉस वैल्यू कभी-कभी कई इटरेशन के लिए स्थिर रहती हैं या आखिर में कम होने से पहले लगभग स्थिर रहती हैं. लंबे समय तक नुकसान की वैल्यू में लगातार बढ़ोतरी होने पर, आपको कुछ समय के लिए कन्वर्जेंस का गलत अनुमान मिल सकता है.
अर्ली स्टॉपिंग के बारे में भी जानें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में मॉडल कन्वर्जेंस और लॉस कर्व देखें.
D
DataFrame
यह pandas का एक लोकप्रिय डेटा टाइप है. इसका इस्तेमाल मेमोरी में डेटासेट को दिखाने के लिए किया जाता है.
डेटाफ़्रेम, टेबल या स्प्रेडशीट की तरह होता है. डेटाफ़्रेम के हर कॉलम का एक नाम (हेडर) होता है. साथ ही, हर लाइन की पहचान एक यूनीक नंबर से होती है.
डेटाफ़्रेम में मौजूद हर कॉलम को 2D ऐरे की तरह स्ट्रक्चर किया जाता है. हालांकि, हर कॉलम को उसका डेटा टाइप असाइन किया जा सकता है.
आधिकारिक pandas.DataFrame रेफ़रंस पेज भी देखें.
डेटा सेट या डेटासेट
रॉ डेटा का कलेक्शन. आम तौर पर (लेकिन सिर्फ़) इसे इनमें से किसी एक फ़ॉर्मैट में व्यवस्थित किया जाता है:
- स्प्रेडशीट
- CSV (कॉमा लगाकर अलग की गई वैल्यू) फ़ॉर्मैट वाली फ़ाइल
डीप मॉडल
एक न्यूरल नेटवर्क, जिसमें एक से ज़्यादा हिडन लेयर होती हैं.
डीप मॉडल को डीप न्यूरल नेटवर्क भी कहा जाता है.
वाइड मॉडल से तुलना करें.
डेंस फ़ीचर
यह एक सुविधा है, जिसमें ज़्यादातर या सभी वैल्यू शून्य नहीं होती हैं. आम तौर पर, यह फ़्लोटिंग-पॉइंट वैल्यू का टेंसर होता है. उदाहरण के लिए, नीचे दिया गया 10 एलिमेंट वाला टेंसर डेंस है, क्योंकि इसकी 9 वैल्यू शून्य नहीं हैं:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
इसकी तुलना विरल सुविधा से करें.
गहराई
न्यूरल नेटवर्क में, इन वैल्यू का योग:
- छिपी हुई लेयर की संख्या
- आउटपुट लेयर की संख्या, जो आम तौर पर 1 होती है
- किसी भी embedding layers की संख्या
उदाहरण के लिए, पांच छिपी हुई लेयर और एक आउटपुट लेयर वाले न्यूरल नेटवर्क की डेप्थ 6 होती है.
ध्यान दें कि इनपुट लेयर से डेप्थ पर कोई असर नहीं पड़ता.
डिस्क्रीट सुविधा
ऐसी सुविधा जिसमें संभावित वैल्यू का एक सीमित सेट होता है. उदाहरण के लिए, ऐसी सुविधा जिसकी वैल्यू सिर्फ़ animal, vegetable या mineral हो सकती है, वह डिसक्रीट (या कैटगरी वाली) सुविधा होती है.
लगातार चलने वाली सुविधा से तुलना करें.
डाइनैमिक
कोई काम जो अक्सर या लगातार किया जाता है. मशीन लर्निंग में, डाइनैमिक और ऑनलाइन शब्द एक-दूसरे के समानार्थी हैं. मशीन लर्निंग में, डाइनैमिक और ऑनलाइन का इस्तेमाल आम तौर पर इन कामों के लिए किया जाता है:
- डाइनैमिक मॉडल (या ऑनलाइन मॉडल) एक ऐसा मॉडल होता है जिसे बार-बार या लगातार फिर से ट्रेन किया जाता है.
- डाइनैमिक ट्रेनिंग (या ऑनलाइन ट्रेनिंग) का मतलब है कि ट्रेनिंग को बार-बार या लगातार दिया जाता है.
- डाइनैमिक इन्फ़रेंस (या ऑनलाइन इन्फ़रेंस) एक ऐसी प्रोसेस है जिसमें मांग के आधार पर अनुमान जनरेट किए जाते हैं.
डाइनैमिक मॉडल
ऐसा मॉडल जिसे बार-बार (ऐसा हो सकता है कि लगातार) फिर से ट्रेन किया जाता है. डाइनैमिक मॉडल एक "लाइफ़लॉन्ग लर्नर" होता है, जो लगातार बदलते डेटा के हिसाब से खुद को ढालता रहता है. डाइनैमिक मॉडल को ऑनलाइन मॉडल भी कहा जाता है.
इसकी तुलना स्टैटिक मॉडल से करें.
E
अर्ली स्टॉपिंग
यह रेगुलराइज़ेशन का एक तरीका है. इसमें ट्रेनिंग को पहले ही रोक दिया जाता है, ताकि ट्रेनिंग लॉस कम हो सके. अर्ली स्टॉपिंग में, मॉडल को ट्रेनिंग देना जान-बूझकर तब बंद कर दिया जाता है, जब मान्य डेटासेट पर नुकसान बढ़ने लगता है. इसका मतलब है कि जब सामान्यीकरण की परफ़ॉर्मेंस खराब होने लगती है.
जल्दी बाहर निकलना से तुलना करें.
एंबेडिंग लेयर
यह एक खास हिडन लेयर होती है. यह ज़्यादा डाइमेंशन वाली कैटेगरी सुविधा पर ट्रेनिंग देती है, ताकि कम डाइमेंशन वाले एंबेड किए जा रहे वेक्टर को धीरे-धीरे सीखा जा सके. एम्बेडिंग लेयर की मदद से, न्यूरल नेटवर्क को ट्रेनिंग देने में कम समय लगता है. ऐसा सिर्फ़ हाई-डाइमेंशनल कैटगरी वाली सुविधा के आधार पर ट्रेनिंग देने की तुलना में होता है.
उदाहरण के लिए, Earth में फ़िलहाल करीब 73,000 तरह के पेड़ों की प्रजातियों की जानकारी उपलब्ध है. मान लें कि आपके मॉडल में पेड़ की प्रजाति एक फ़ीचर है. इसलिए, आपके मॉडल की इनपुट लेयर में 73,000 एलिमेंट वाला वन-हॉट वेक्टर शामिल है.
उदाहरण के लिए, शायद baobab को इस तरह दिखाया जाएगा:

73,000 एलिमेंट वाला ऐरे बहुत लंबा होता है. अगर मॉडल में एम्बेडिंग लेयर नहीं जोड़ी जाती है, तो ट्रेनिंग में बहुत ज़्यादा समय लगेगा. ऐसा इसलिए होगा, क्योंकि 72,999 शून्य को गुणा करना होगा. ऐसा हो सकता है कि आपने एम्बेडिंग लेयर को 12 डाइमेंशन से मिलकर बनाने का विकल्प चुना हो. इसलिए, एम्बेडिंग लेयर धीरे-धीरे हर पेड़ की प्रजाति के लिए एक नया एम्बेडिंग वेक्टर सीखेगी.
कुछ स्थितियों में, हैशिंग, एम्बेडिंग लेयर का एक बेहतर विकल्प है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में एम्बेडिंग देखें.
epoch
पूरे ट्रेनिंग सेट पर ट्रेनिंग पास की जाती है, ताकि हर उदाहरण को एक बार प्रोसेस किया जा सके.
एक इपॉक, N/बैच साइज़
ट्रेनिंग इटरेशन को दिखाता है. इसमें N, उदाहरणों की कुल संख्या है.
उदाहरण के लिए, मान लें कि:
- इस डेटासेट में 1,000 उदाहरण शामिल हैं.
- बैच का साइज़ 50 उदाहरणों का है.
इसलिए, एक इपॉक के लिए 20 बार दोहराना ज़रूरी है:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
उदाहरण
features की एक लाइन की वैल्यू और शायद label की वैल्यू. सुपरवाइज़्ड लर्निंग के उदाहरणों को दो सामान्य कैटगरी में बाँटा जा सकता है:
- लेबल किए गए उदाहरण में एक या उससे ज़्यादा सुविधाएं और एक लेबल होता है. ट्रेनिंग के दौरान, लेबल किए गए उदाहरणों का इस्तेमाल किया जाता है.
- बिना लेबल वाले उदाहरण में एक या उससे ज़्यादा सुविधाएं होती हैं, लेकिन कोई लेबल नहीं होता. अनुमान लगाने के दौरान, बिना लेबल वाले उदाहरणों का इस्तेमाल किया जाता है.
उदाहरण के लिए, मान लें कि आपको एक ऐसे मॉडल को ट्रेन करना है जो यह पता लगा सके कि मौसम की स्थितियों का छात्र-छात्राओं के टेस्ट स्कोर पर क्या असर पड़ता है. यहां लेबल किए गए तीन उदाहरण दिए गए हैं:
| सुविधाएं | लेबल | ||
|---|---|---|---|
| तापमान | नमी | दबाव | टेस्ट का स्कोर |
| 15 | 47 | 998 | अच्छा |
| 19 | 34 | 1020 | बहुत बढ़िया |
| 18 | 92 | 1012 | खराब |
यहां बिना लेबल वाले तीन उदाहरण दिए गए हैं:
| तापमान | नमी | दबाव | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
किसी उदाहरण के लिए, डेटासेट की लाइन आम तौर पर रॉ सोर्स होती है. इसका मतलब है कि उदाहरण में आम तौर पर, डेटासेट में मौजूद कॉलम का सबसेट शामिल होता है. इसके अलावा, उदाहरण में दी गई सुविधाओं में सिंथेटिक सुविधाएं भी शामिल हो सकती हैं. जैसे, फ़ీचर क्रॉस.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी देने वाले कोर्स में सुपरवाइज़्ड लर्निंग देखें.
F
फ़ॉल्स नेगेटिव (FN)
इस उदाहरण में, मॉडल ने गलती से नेगेटिव क्लास का अनुमान लगाया है. उदाहरण के लिए, मॉडल का अनुमान है कि कोई ईमेल मैसेज स्पैम नहीं है (नेगेटिव क्लास), लेकिन वह ईमेल मैसेज असल में स्पैम है.
फ़ॉल्स पॉज़िटिव (FP)
ऐसा उदाहरण जिसमें मॉडल, पॉज़िटिव क्लास के बारे में गलत अनुमान लगाता है. उदाहरण के लिए, मॉडल का अनुमान है कि कोई ईमेल मैसेज स्पैम (पॉज़िटिव क्लास) है, लेकिन वह ईमेल मैसेज असल में स्पैम नहीं है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में थ्रेशोल्ड और कन्फ़्यूज़न मैट्रिक्स देखें.
फ़ॉल्स पॉज़िटिव रेट (एफ़पीआर)
यह असल नेगेटिव उदाहरणों का अनुपात है जिनके लिए मॉडल ने गलती से पॉज़िटिव क्लास का अनुमान लगाया. यहां दिए गए फ़ॉर्मूले से, फ़ॉल्स पॉज़िटिव रेट का पता लगाया जाता है:
फ़ॉल्स पॉज़िटिव रेट, आरओसी कर्व में x-ऐक्सिस होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: आरओसी और एयूसी देखें.
सुविधा
मशीन लर्निंग मॉडल के लिए इनपुट वैरिएबल. उदाहरण में एक या उससे ज़्यादा सुविधाएं होती हैं. उदाहरण के लिए, मान लें कि आपको किसी मॉडल को इस तरह से ट्रेन करना है कि वह मौसम की स्थितियों का छात्र-छात्राओं के टेस्ट स्कोर पर पड़ने वाले असर का पता लगा सके. यहां दी गई टेबल में तीन उदाहरण दिए गए हैं. इनमें से हर उदाहरण में तीन सुविधाएं और एक लेबल शामिल है:
| सुविधाएं | लेबल | ||
|---|---|---|---|
| तापमान | नमी | दबाव | टेस्ट का स्कोर |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
लेबल से कंट्रास्ट.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी देने वाले कोर्स में सुपरवाइज़्ड लर्निंग देखें.
सुविधा क्रॉस
सिंथेटिक फ़ीचर, कैटगोरिकल या बकेटेड फ़ीचर को "क्रॉस" करके बनाई जाती है.
उदाहरण के लिए, "मूड का अनुमान लगाने वाले" मॉडल पर विचार करें. यह मॉडल, तापमान को इन चार बकेट में से किसी एक में दिखाता है:
freezingchillytemperatewarm
साथ ही, हवा की रफ़्तार को इन तीन बकेट में से किसी एक में दिखाता है:
stilllightwindy
फ़्रीक्वेंसी कैपिंग की सुविधा के बिना, लीनियर मॉडल पिछले सात अलग-अलग बकेट में से हर एक पर अलग से ट्रेन होता है. इसलिए, मॉडल को freezing के उदाहरणों से ट्रेनिंग मिलती है. यह ट्रेनिंग, windy के उदाहरणों से मिलने वाली ट्रेनिंग से अलग होती है.
इसके अलावा, तापमान और हवा की रफ़्तार को मिलाकर भी कोई नई सुविधा बनाई जा सकती है. इस सिंथेटिक फ़ीचर की ये 12 संभावित वैल्यू होंगी:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
फ़ीचर क्रॉस की वजह से, मॉडल को freezing-windy दिन और freezing-still दिन के मूड में अंतर का पता चल सकता है.
अगर आपने दो ऐसी सुविधाओं से कोई सिंथेटिक सुविधा बनाई है जिनमें अलग-अलग बकेट की संख्या बहुत ज़्यादा है, तो सुविधा क्रॉस में संभावित कॉम्बिनेशन की संख्या बहुत ज़्यादा होगी. उदाहरण के लिए, अगर किसी सुविधा में 1,000 बकेट हैं और दूसरी सुविधा में 2,000 बकेट हैं, तो दोनों सुविधाओं को मिलाकर बनने वाली सुविधा में 20,00,000 बकेट होंगी.
आसान शब्दों में कहें, तो क्रॉस एक कार्टीज़ियन प्रॉडक्ट है.
फ़्रीक्वेंसी क्रॉस का इस्तेमाल ज़्यादातर लीनियर मॉडल के साथ किया जाता है. इनका इस्तेमाल न्यूरल नेटवर्क के साथ बहुत कम किया जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटेगरी के हिसाब से डेटा: फ़ीचर क्रॉस देखें.
फ़ीचर इंजीनियरिंग
यह एक ऐसी प्रोसेस है जिसमें ये चरण शामिल होते हैं:
- यह तय करना कि मॉडल को ट्रेन करने के लिए, कौनसी सुविधाएं काम की हो सकती हैं.
- डेटासेट से मिले रॉ डेटा को उन सुविधाओं के असरदार वर्शन में बदलना.
उदाहरण के लिए, आपको लग सकता है कि temperature एक काम की सुविधा है. इसके बाद, बकेटिंग का इस्तेमाल करके यह ऑप्टिमाइज़ किया जा सकता है कि मॉडल, अलग-अलग temperature रेंज से क्या सीख सकता है.
फ़ीचर इंजीनियरिंग को कभी-कभी फ़ीचर एक्सट्रैक्शन या फ़ीचरराइज़ेशन भी कहा जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: कोई मॉडल, फ़ीचर वेक्टर का इस्तेमाल करके डेटा को कैसे प्रोसेस करता है लेख पढ़ें.
सुविधाओं का सेट
सुविधाओं का वह ग्रुप जिस पर आपका मशीन लर्निंग मॉडल ट्रेन होता है. उदाहरण के लिए, घर की कीमतों का अनुमान लगाने वाले मॉडल के लिए, सामान्य फ़ीचर सेट में पिन कोड, प्रॉपर्टी का साइज़, और प्रॉपर्टी की स्थिति शामिल हो सकती है.
फ़ीचर वेक्टर
feature वैल्यू की वह सरणी जिसमें example शामिल है. फ़ेचर वेक्टर को ट्रेनिंग और इनफ़रेंस के दौरान इनपुट किया जाता है. उदाहरण के लिए, दो डिस्क्रीट फ़ीचर वाले मॉडल के लिए फ़ीचर वेक्टर ऐसा हो सकता है:
[0.92, 0.56]
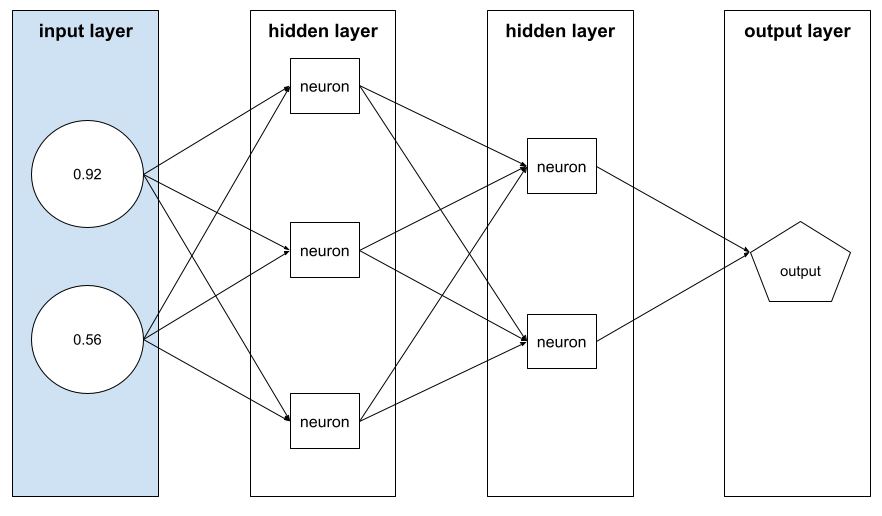
हर उदाहरण में, फ़ीचर वेक्टर के लिए अलग-अलग वैल्यू दी गई हैं. इसलिए, अगले उदाहरण के लिए फ़ीचर वेक्टर कुछ इस तरह का हो सकता है:
[0.73, 0.49]
फ़ीचर इंजीनियरिंग से यह तय होता है कि फ़ीचर वेक्टर में फ़ीचर को कैसे दिखाया जाए. उदाहरण के लिए, पांच संभावित वैल्यू वाली बाइनरी कैटगोरिकल सुविधा को वन-हॉट एन्कोडिंग की मदद से दिखाया जा सकता है. इस मामले में, किसी उदाहरण के लिए फ़ीचर वेक्टर में चार शून्य और तीसरी पोज़िशन पर एक 1.0 होगा. यह इस तरह दिखेगा:
[0.0, 0.0, 1.0, 0.0, 0.0]
एक और उदाहरण के तौर पर, मान लें कि आपके मॉडल में तीन सुविधाएं शामिल हैं:
- पांच संभावित वैल्यू वाली बाइनरी कैटगरी की सुविधा, जिसे वन-हॉट एन्कोडिंग के साथ दिखाया गया है. उदाहरण के लिए:
[0.0, 1.0, 0.0, 0.0, 0.0] - एक और बाइनरी कैटगरी वाली सुविधा, जिसकी तीन संभावित वैल्यू हैं. इन्हें वन-हॉट एन्कोडिंग की मदद से दिखाया गया है. उदाहरण के लिए:
[0.0, 0.0, 1.0] - फ़्लोटिंग-पॉइंट फ़ीचर; उदाहरण के लिए:
8.3.
इस मामले में, हर उदाहरण के लिए फ़ीचर वेक्टर को नौ वैल्यू से दिखाया जाएगा. ऊपर दी गई सूची में मौजूद उदाहरण वैल्यू के हिसाब से, फ़ीचर वेक्टर यह होगा:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: कोई मॉडल, फ़ीचर वेक्टर का इस्तेमाल करके डेटा को कैसे प्रोसेस करता है लेख पढ़ें.
फ़ीडबैक लूप
मशीन लर्निंग में, ऐसी स्थिति जिसमें किसी मॉडल के अनुमान, उसी मॉडल या किसी दूसरे मॉडल के ट्रेनिंग डेटा पर असर डालते हैं. उदाहरण के लिए, फ़िल्मों का सुझाव देने वाला मॉडल, लोगों को दिखने वाली फ़िल्मों पर असर डालेगा. इसके बाद, यह फ़िल्मों का सुझाव देने वाले अन्य मॉडल पर असर डालेगा.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में प्रोडक्शन एमएल सिस्टम: पूछने लायक सवाल देखें.
G
सामान्यीकरण
मॉडल की ऐसी क्षमता जिससे वह नए और पहले कभी न देखे गए डेटा के आधार पर सही अनुमान लगा सके. सामान्यीकरण करने वाला मॉडल, ओवरफ़िटिंग करने वाले मॉडल से अलग होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में सामान्यीकरण देखें.
सामान्यीकरण कर्व
इटरेशन की संख्या के आधार पर, ट्रेनिंग लॉस और वैलडेशन लॉस, दोनों का प्लॉट.
सामान्यीकरण कर्व से, ओवरफ़िटिंग का पता लगाया जा सकता है. उदाहरण के लिए, यहां दिया गया सामान्यीकरण कर्व, ओवरफ़िटिंग के बारे में बताता है. ऐसा इसलिए, क्योंकि आखिर में पुष्टि करने के दौरान होने वाला नुकसान, ट्रेनिंग के दौरान होने वाले नुकसान से काफ़ी ज़्यादा हो जाता है.
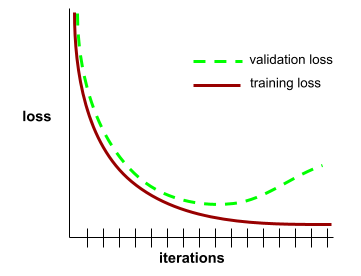
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में सामान्यीकरण देखें.
ग्रेडिएंट डिसेंट
यह नुकसान को कम करने की एक गणितीय तकनीक है. ग्रेडिएंट डिसेंट, वज़न और बायस को बार-बार अडजस्ट करता है. इससे, नुकसान को कम करने के लिए सबसे सही कॉम्बिनेशन धीरे-धीरे मिल जाता है.
ग्रेडिएंट डिसेंट, मशीन लर्निंग से बहुत पुराना है.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में लीनियर रिग्रेशन: ग्रेडिएंट डिसेंट देखें.
ग्राउंड ट्रूथ
रियलिटी.
असल में क्या हुआ.
उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल पर विचार करें. यह मॉडल अनुमान लगाता है कि यूनिवर्सिटी के पहले साल में पढ़ने वाला छात्र/छात्रा, छह साल के अंदर ग्रेजुएट हो पाएगा या नहीं. इस मॉडल के लिए, ग्राउंड ट्रुथ यह है कि छात्र-छात्रा ने छह साल के अंदर वाकई में ग्रेजुएशन की है या नहीं.
H
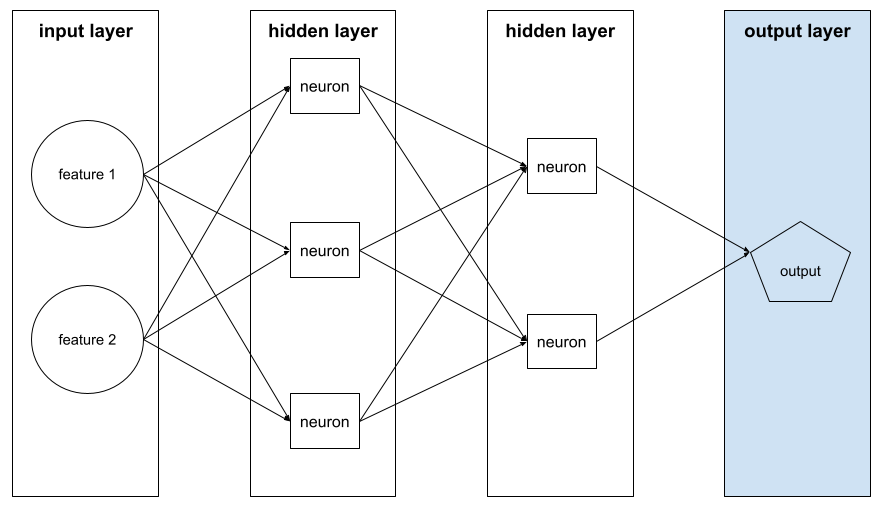
छिपी हुई लेयर
यह न्यूरल नेटवर्क में एक लेयर होती है. यह इनपुट लेयर (सुविधाएं) और आउटपुट लेयर (अनुमान) के बीच होती है. हर छिपी हुई लेयर में एक या उससे ज़्यादा न्यूरॉन होते हैं. उदाहरण के लिए, यहां दिए गए न्यूरल नेटवर्क में दो हिडन लेयर हैं. पहली लेयर में तीन न्यूरॉन और दूसरी लेयर में दो न्यूरॉन हैं:
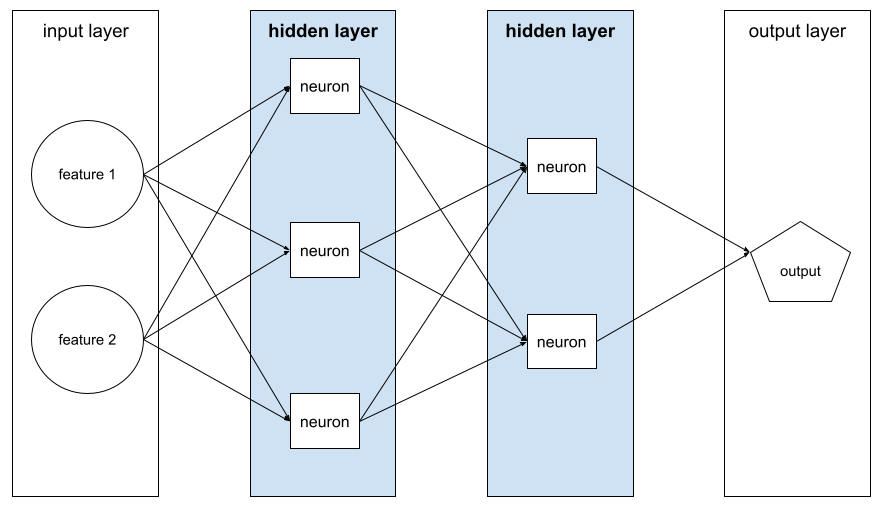
डीप न्यूरल नेटवर्क में एक से ज़्यादा हिडन लेयर होती हैं. उदाहरण के लिए, ऊपर दी गई इमेज एक डीप न्यूरल नेटवर्क है, क्योंकि मॉडल में दो हिडन लेयर शामिल हैं.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: नोड और हिडन लेयर देखें.
हाइपर पैरामीटर
ये ऐसे वैरिएबल होते हैं जिन्हें मॉडल को ट्रेन करने के दौरान, आपने या हाइपरपैरामीटर ट्यूनिंग सेवाने अडजस्ट किया है. उदाहरण के लिए, लर्निंग रेट एक हाइपरपैरामीटर है. ट्रेनिंग सेशन से पहले, लर्निंग रेट को 0.01 पर सेट किया जा सकता है. अगर आपको लगता है कि 0.01 बहुत ज़्यादा है, तो अगले ट्रेनिंग सेशन के लिए लर्निंग रेट को 0.003 पर सेट किया जा सकता है.
इसके उलट, पैरामीटर अलग-अलग वज़न और बायस होते हैं. मॉडल, ट्रेनिंग के दौरान इन्हें सीखता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
I
स्वतंत्र और समान रूप से डिस्ट्रिब्यूट किया गया (आई.आई.डी.)
यह ऐसे डिस्ट्रिब्यूशन से लिया गया डेटा होता है जिसमें कोई बदलाव नहीं होता. साथ ही, इसमें ली गई हर वैल्यू, पहले ली गई वैल्यू पर निर्भर नहीं करती. आई.आई.डी., मशीन लर्निंग का आदर्श गैस है. यह एक उपयोगी गणितीय कॉन्सेप्ट है, लेकिन असल दुनिया में यह कभी भी पूरी तरह से नहीं मिलता. उदाहरण के लिए, किसी वेब पेज पर आने वाले लोगों का डिस्ट्रिब्यूशन, कुछ समय के लिए i.i.d. हो सकता है. इसका मतलब है कि उस अवधि के दौरान डिस्ट्रिब्यूशन में कोई बदलाव नहीं होता. साथ ही, आम तौर पर एक व्यक्ति की विज़िट, दूसरे व्यक्ति की विज़िट से अलग होती है. हालांकि, अगर इस समय अवधि को बढ़ाया जाता है, तो वेब पेज पर आने वाले लोगों की संख्या में सीज़न के हिसाब से अंतर दिख सकता है.
नॉनस्टेशनैरिटी के बारे में भी जानें.
अनुमान
ट्रेडिशनल मशीन लर्निंग में, बिना लेबल वाले उदाहरणों पर ट्रेन किए गए मॉडल को लागू करके अनुमान लगाने की प्रोसेस. ज़्यादा जानने के लिए, एमएल के बारे में जानकारी देने वाले कोर्स में निगरानी में की जाने वाली लर्निंग सेक्शन देखें.
लार्ज लैंग्वेज मॉडल में, अनुमान लगाने की प्रोसेस का इस्तेमाल, ट्रेनिंग दिए गए मॉडल का इस्तेमाल करके, इनपुट प्रॉम्प्ट के लिए जवाब जनरेट करने के लिए किया जाता है.
आंकड़ों में अनुमान का मतलब कुछ अलग होता है. ज़्यादा जानकारी के लिए, सांख्यिकीय अनुमान के बारे में Wikipedia लेख पढ़ें.
इनपुट लेयर
न्यूरल नेटवर्क की वह लेयर जिसमें फ़ीचर वेक्टर होता है. इसका मतलब है कि इनपुट लेयर, ट्रेनिंग या अनुमान के लिए उदाहरण देती है. उदाहरण के लिए, यहां दिए गए न्यूरल नेटवर्क की इनपुट लेयर में दो सुविधाएं शामिल हैं:
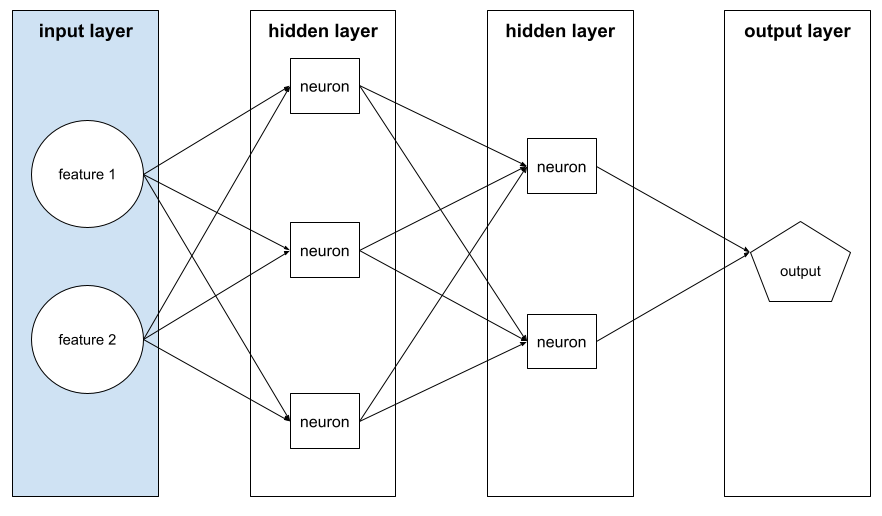
व्याख्या करने की क्षमता
मशीन लर्निंग मॉडल के फ़ैसले के पीछे की वजह को आसान शब्दों में किसी इंसान को समझाना.
उदाहरण के लिए, ज़्यादातर लीनियर रिग्रेशन मॉडल को आसानी से समझा जा सकता है. (आपको सिर्फ़ हर सुविधा के लिए, ट्रेनिंग के दौरान तय किए गए वेट देखने हैं.) डिसिज़न फ़ॉरेस्ट को आसानी से समझा जा सकता है. हालांकि, कुछ मॉडल को समझने के लिए, बेहतर विज़ुअलाइज़ेशन की ज़रूरत होती है.
एमएल मॉडल को समझने के लिए, Learning Interpretability Tool (LIT) का इस्तेमाल किया जा सकता है.
फिर से करें
ट्रेनिंग के दौरान, मॉडल के पैरामीटर—मॉडल के वज़न और बायस—को एक बार अपडेट करना. बैच साइज़ से यह तय होता है कि मॉडल एक बार में कितने उदाहरणों को प्रोसेस करेगा. उदाहरण के लिए, अगर बैच का साइज़ 20 है, तो मॉडल पैरामीटर को अडजस्ट करने से पहले, 20 उदाहरणों को प्रोसेस करता है.
न्यूरल नेटवर्क को ट्रेन करते समय, एक बार में ये दो पास शामिल होते हैं:
- किसी एक बैच पर नुकसान का आकलन करने के लिए फ़ॉरवर्ड पास.
- मॉडल के पैरामीटर को नुकसान और लर्निंग रेट के आधार पर अडजस्ट करने के लिए, बैकवर्ड पास (बैकप्रॉपैगेशन) का इस्तेमाल किया जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ग्रेडिएंट डिसेंट देखें.
L
L0 रेगुलराइज़ेशन
यह रेगुलराइज़ेशन का एक टाइप है. यह मॉडल में, शून्य से अलग वज़न की कुल संख्या को कम करता है. उदाहरण के लिए, 11 नॉन-ज़ीरो वेट वाले मॉडल पर, 10 नॉन-ज़ीरो वेट वाले मॉडल की तुलना में ज़्यादा जुर्माना लगाया जाएगा.
L0 रेगुलराइज़ेशन को कभी-कभी L0-नॉर्म रेगुलराइज़ेशन भी कहा जाता है.
L1 नुकसान
यह एक लॉस फ़ंक्शन है. यह लेबल की असल वैल्यू और मॉडल की अनुमानित वैल्यू के बीच के अंतर की ऐब्सलूट वैल्यू का हिसाब लगाता है. उदाहरण के लिए, यहां पांच उदाहरणों के बैच के लिए, L1 लॉस की गणना दी गई है:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | डेल्टा की ऐब्सलूट वैल्यू |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 नुकसान | ||
L1 लॉस, L2 लॉस की तुलना में आउटलायर के लिए कम संवेदनशील होता है.
कुल गड़बड़ी का मध्यमान, हर उदाहरण के लिए औसत L1 लॉस होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: लॉस देखें.
L1 रेगुलराइज़ेशन
यह एक तरह का रेगुलराइज़ेशन है. इसमें वेट को, वेट की ऐब्सलूट वैल्यू के योग के अनुपात में दंडित किया जाता है. L1 रेगुलराइज़ेशन से, काम की नहीं या बहुत कम काम की सुविधाओं के वेट को शून्य पर सेट करने में मदद मिलती है. वज़न के तौर पर 0 वैल्यू वाली सुविधा को मॉडल से हटा दिया जाता है.
इसकी तुलना L2 रेगुलराइज़ेशन से करें.
L2 नुकसान
यह एक लॉस फ़ंक्शन है. यह लेबल की असल वैल्यू और मॉडल की अनुमानित वैल्यू के बीच के अंतर का स्क्वेयर कैलकुलेट करता है. उदाहरण के लिए, यहां पांच उदाहरणों के बैच के लिए, L2 लॉस की गणना दी गई है:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | डेल्टा का स्क्वेयर |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 लॉस | ||
स्क्वेयर करने की वजह से, L2 लॉस, आउटलायर के असर को बढ़ा देता है. इसका मतलब है कि L1 लॉस की तुलना में, L2 लॉस, खराब अनुमानों पर ज़्यादा असर डालता है. उदाहरण के लिए, पिछले बैच के लिए L1 लॉस, 16 के बजाय 8 होगा. ध्यान दें कि एक आउटलायर, 16 में से 9 के लिए ज़िम्मेदार है.
रिग्रेशन मॉडल, आम तौर पर लॉस फ़ंक्शन के तौर पर L2 लॉस का इस्तेमाल करते हैं.
मीन स्क्वेयर्ड एरर, हर उदाहरण के लिए औसत L2 लॉस होता है. स्क्वेयर्ड लॉस को L2 लॉस भी कहा जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लॉजिस्टिक रिग्रेशन: लॉस और रेगुलराइज़ेशन देखें.
L2 रेगुलराइज़ेशन
यह रेगुलराइज़ेशन का एक टाइप है. इसमें वज़न को, वज़न के स्क्वेयर के योग के अनुपात में दंडित किया जाता है. L2 रेगुलराइज़ेशन, आउटलायर वेट (ज़्यादा पॉज़िटिव या कम नेगेटिव वैल्यू वाले) को 0 के करीब लाने में मदद करता है, लेकिन पूरी तरह से 0 नहीं करता है. जिन सुविधाओं की वैल्यू 0 के बहुत करीब होती है वे मॉडल में बनी रहती हैं, लेकिन मॉडल के अनुमान पर इनका ज़्यादा असर नहीं पड़ता.
L2 रेगुलराइज़ेशन, लीनियर मॉडल में हमेशा सामान्यीकरण को बेहतर बनाता है.
L1 रेगुलराइज़ेशन से तुलना करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग: L2 रेगुलराइज़ेशन देखें.
लेबल
सुपरवाइज़्ड मशीन लर्निंग में, उदाहरण का "जवाब" या "नतीजा" वाला हिस्सा.
हर लेबल किए गए उदाहरण में एक या उससे ज़्यादा विशेषताएं और एक लेबल होता है. उदाहरण के लिए, स्पैम का पता लगाने वाले डेटासेट में, लेबल शायद "स्पैम" या "स्पैम नहीं" होगा. बारिश के डेटासेट में, लेबल यह हो सकता है कि किसी समयावधि के दौरान कितनी बारिश हुई.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी में सुपरवाइज़्ड लर्निंग देखें.
लेबल किया गया उदाहरण
ऐसा उदाहरण जिसमें एक या उससे ज़्यादा सुविधाएं और एक लेबल शामिल हो. उदाहरण के लिए, यहां दी गई टेबल में घर की कीमत का अनुमान लगाने वाले मॉडल के तीन लेबल किए गए उदाहरण दिखाए गए हैं. इनमें से हर उदाहरण में तीन सुविधाएं और एक लेबल है:
| कमरों की संख्या | बाथरूम की संख्या | घर की उम्र | घर की कीमत (लेबल) |
|---|---|---|---|
| 3 | 2 | 15 | $345,000 |
| 2 | 1 | 72 | $179,000 |
| 4 | 2 | 34 | $3,92,000 |
सुपरवाइज़्ड मशीन लर्निंग में, मॉडल को लेबल किए गए उदाहरणों के आधार पर ट्रेन किया जाता है. साथ ही, वे बिना लेबल वाले उदाहरणों के आधार पर अनुमान लगाते हैं.
लेबल किए गए उदाहरण की तुलना, लेबल नहीं किए गए उदाहरणों से करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी में सुपरवाइज़्ड लर्निंग देखें.
lambda
रेगुलराइज़ेशन रेट के लिए समानार्थी शब्द.
Lambda एक ओवरलोडेड शब्द है. यहां हम रेगुलराइज़ेशन के तहत, शब्द की परिभाषा पर फ़ोकस कर रहे हैं.
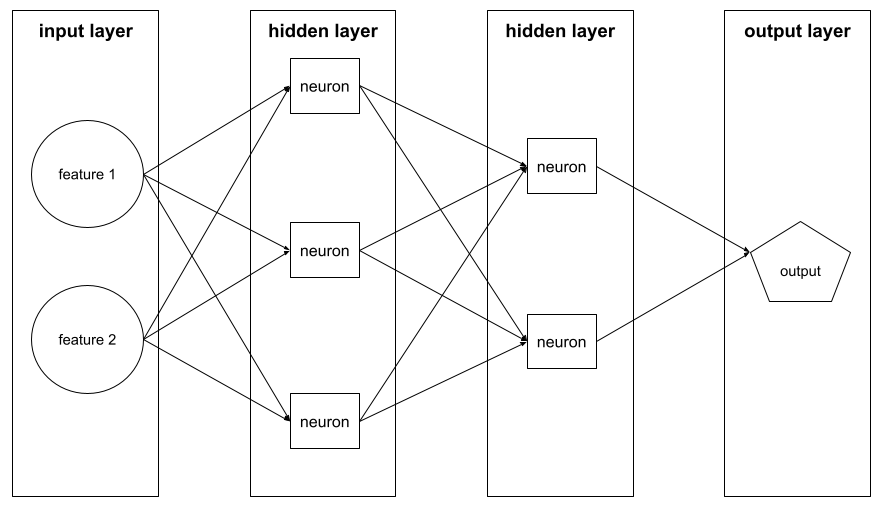
लेयर
न्यूरल नेटवर्क में न्यूरॉन का एक सेट. आम तौर पर, तीन तरह की लेयर इस्तेमाल की जाती हैं. इनके बारे में यहां बताया गया है:
- इनपुट लेयर, जो सभी सुविधाओं के लिए वैल्यू देती है.
- एक या उससे ज़्यादा छिपी हुई लेयर, जो सुविधाओं और लेबल के बीच नॉनलीनियर संबंध ढूंढती हैं.
- आउटपुट लेयर, जो अनुमान देती है.
उदाहरण के लिए, इस इमेज में एक इनपुट लेयर, दो छिपी हुई लेयर, और एक आउटपुट लेयर वाला न्यूरल नेटवर्क दिखाया गया है:
TensorFlow में, लेयर भी Python फ़ंक्शन होती हैं. ये टेंसर और कॉन्फ़िगरेशन के विकल्पों को इनपुट के तौर पर लेती हैं और आउटपुट के तौर पर अन्य टेंसर जनरेट करती हैं.
सीखने की दर
यह एक फ़्लोटिंग-पॉइंट नंबर होता है. इससे ग्रेडिएंट डिसेंट एल्गोरिदम को यह पता चलता है कि हर इटरेशन पर, वज़न और बायस को कितना अडजस्ट करना है. उदाहरण के लिए, 0.3 का लर्निंग रेट, 0.1 के लर्निंग रेट की तुलना में वज़न और पूर्वाग्रहों को तीन गुना ज़्यादा असरदार तरीके से अडजस्ट करेगा.
लर्निंग रेट, एक मुख्य हाइपरपैरामीटर है. अगर लर्निंग रेट बहुत कम सेट किया जाता है, तो ट्रेनिंग में बहुत ज़्यादा समय लगेगा. अगर लर्निंग रेट को बहुत ज़्यादा पर सेट किया जाता है, तो ग्रेडिएंट डिसेंट को अक्सर कन्वर्जेंस तक पहुंचने में समस्या होती है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
रेखीय
दो या उससे ज़्यादा वैरिएबल के बीच का ऐसा संबंध जिसे सिर्फ़ जोड़ और गुणा करके दिखाया जा सकता है.
लीनियर रिलेशनशिप का प्लॉट एक लाइन होती है.
नॉनलीनियर विज्ञापन से तुलना करें.
लीनियर मॉडल
यह एक ऐसा मॉडल है जो पूर्वानुमान लगाने के लिए, हर फ़ीचर को एक वज़न असाइन करता है. (लीनियर मॉडल में भी बायस शामिल होता है.) इसके उलट, डीप मॉडल में, सुविधाओं और अनुमानों के बीच का संबंध आम तौर पर नॉनलीनियर होता है.
लीनियर मॉडल को आम तौर पर ट्रेन करना आसान होता है. साथ ही, डीप मॉडल की तुलना में इन्हें समझना ज़्यादा आसान होता है. हालांकि, डीप मॉडल, सुविधाओं के बीच जटिल संबंधों को समझ सकते हैं.
लीनियर रिग्रेशन और लॉजिस्टिक रिग्रेशन, दो तरह के लीनियर मॉडल होते हैं.
लीनियर रिग्रेशन
यह एक तरह का मशीन लर्निंग मॉडल है. इसमें ये दोनों बातें सही होती हैं:
- यह मॉडल, लीनियर मॉडल है.
- अनुमान, फ़्लोटिंग-पॉइंट वैल्यू होती है. (यह लीनियर रिग्रेशन का रिग्रेशन हिस्सा है.)
लॉजिस्टिक रिग्रेशन की तुलना में लीनियर रिग्रेशन के बारे में जानकारी. साथ ही, रिग्रेशन की तुलना क्लासिफ़िकेशन से करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन देखें.
लॉजिस्टिक रिग्रेशन
यह एक तरह का रिग्रेशन मॉडल है, जो संभावना का अनुमान लगाता है. लॉजिस्टिक रिग्रेशन मॉडल में ये विशेषताएं होती हैं:
- लेबल कैटगरिकल है. लॉजिस्टिक रिग्रेशन शब्द का इस्तेमाल आम तौर पर बाइनरी लॉजिस्टिक रिग्रेशन के लिए किया जाता है. इसका मतलब है कि यह एक ऐसा मॉडल है जो दो संभावित वैल्यू वाले लेबल के लिए संभावनाओं का हिसाब लगाता है. मल्टीनोमियल लॉजिस्टिक रिग्रेशन, एक कम इस्तेमाल किया जाने वाला वैरिएंट है. यह दो से ज़्यादा संभावित वैल्यू वाले लेबल के लिए, संभावनाओं का हिसाब लगाता है.
- ट्रेनिंग के दौरान लॉस फ़ंक्शन लॉग लॉस होता है. (दो से ज़्यादा संभावित वैल्यू वाले लेबल के लिए, एक साथ कई लॉग लॉस यूनिट रखी जा सकती हैं.)
- मॉडल में लीनियर आर्किटेक्चर है, न कि डीप न्यूरल नेटवर्क. हालांकि, इस परिभाषा का बाकी हिस्सा डीप मॉडल पर भी लागू होता है. ये मॉडल, कैटगरी के हिसाब से लेबल की संभावनाओं का अनुमान लगाते हैं.
उदाहरण के लिए, लॉजिस्टिक रिग्रेशन मॉडल पर विचार करें. यह मॉडल, किसी इनपुट ईमेल के स्पैम होने या न होने की संभावना का हिसाब लगाता है. मान लें कि अनुमान लगाने के दौरान, मॉडल 0.72 का अनुमान लगाता है. इसलिए, मॉडल अनुमान लगा रहा है कि:
- ईमेल के स्पैम होने की 72% संभावना है.
- ईमेल के स्पैम न होने की संभावना 28% है.
लॉजिस्टिक रिग्रेशन मॉडल, दो चरणों वाले इस आर्किटेक्चर का इस्तेमाल करता है:
- यह मॉडल, इनपुट सुविधाओं पर लीनियर फ़ंक्शन लागू करके, अनुमान (y') जनरेट करता है.
- मॉडल, उस रॉ अनुमान का इस्तेमाल सिग्मॉइड फ़ंक्शन के इनपुट के तौर पर करता है. यह फ़ंक्शन, रॉ अनुमान को 0 से 1 के बीच की वैल्यू में बदलता है. इसमें 0 और 1 शामिल नहीं होते.
किसी भी रिग्रेशन मॉडल की तरह, लॉजिस्टिक रिग्रेशन मॉडल भी किसी संख्या का अनुमान लगाता है. हालांकि, आम तौर पर इस संख्या को बाइनरी क्लासिफ़िकेशन मॉडल का हिस्सा बनाया जाता है. ऐसा इस तरह किया जाता है:
- अगर अनुमानित संख्या, वर्गीकरण थ्रेशोल्ड से ज़्यादा है, तो बाइनरी क्लासिफ़िकेशन मॉडल, पॉज़िटिव क्लास का अनुमान लगाता है.
- अगर अनुमानित संख्या, क्लासिफ़िकेशन थ्रेशोल्ड से कम है, तो बाइनरी क्लासिफ़िकेशन मॉडल, नेगेटिव क्लास का अनुमान लगाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लॉजिस्टिक रिग्रेशन देखें.
लॉग लॉस
बाइनरी लॉजिस्टिक रिग्रेशन में इस्तेमाल किया गया लॉस फ़ंक्शन.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लॉजिस्टिक रिग्रेशन: लॉस और रेगुलराइज़ेशन देखें.
लॉग-ऑड्स
यह किसी इवेंट के होने की संभावना का लॉगरिद्म होता है.
हार की वजह से
निगरानी वाले मॉडल की ट्रेनिंग के दौरान, यह मेज़रमेंट किया जाता है कि मॉडल का अनुमान, उसके लेबल से कितना अलग है.
लॉस फ़ंक्शन, लॉस का हिसाब लगाता है.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में लीनियर रिग्रेशन: लॉस देखें.
ऐप्लिकेशन हटाने का कर्व
ट्रेनिंग के इटरेशन की संख्या के फ़ंक्शन के तौर पर, नुकसान का प्लॉट. नीचे दिए गए प्लॉट में, सामान्य लॉस कर्व दिखाया गया है:
लॉस कर्व से यह पता लगाया जा सकता है कि आपका मॉडल कब कन्वर्ज हो रहा है या ओवरफ़िट हो रहा है.
लॉस कर्व में, यहां दिए गए सभी तरह के लॉस को प्लॉट किया जा सकता है:
जनरलाइज़ेशन कर्व भी देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग: लॉस कर्व की व्याख्या करना देखें.
लॉस फ़ंक्शन
ट्रेनिंग या टेस्टिंग के दौरान, यह एक गणितीय फ़ंक्शन होता है. यह उदाहरणों के बैच के नुकसान की गणना करता है. लॉस फ़ंक्शन, अच्छी परफ़ॉर्मेंस वाले मॉडल के लिए कम लॉस दिखाता है. वहीं, खराब परफ़ॉर्मेंस वाले मॉडल के लिए ज़्यादा लॉस दिखाता है.
ट्रेनिंग का मकसद आम तौर पर, लॉस फ़ंक्शन से मिलने वाले नुकसान को कम करना होता है.
कई तरह के लॉस फ़ंक्शन मौजूद होते हैं. बनाए जा रहे मॉडल के हिसाब से, सही लॉस फ़ंक्शन चुनें. उदाहरण के लिए:
- L2 लॉस या मीन स्क्वेयर्ड एरर, लीनियर रिग्रेशन के लिए लॉस फ़ंक्शन होता है.
- लॉग लॉस, लॉजिस्टिक्स रिग्रेशन के लिए लॉस फ़ंक्शन है.
M
मशीन लर्निंग
यह एक प्रोग्राम या सिस्टम है, जो इनपुट डेटा की मदद से मॉडल को ट्रेन करता है. ट्रेन किया गया मॉडल, नए (पहले कभी न देखे गए) डेटा से काम के अनुमान लगा सकता है. यह डेटा, मॉडल को ट्रेन करने के लिए इस्तेमाल किए गए डेटा के डिस्ट्रिब्यूशन से लिया जाता है.
मशीन लर्निंग, पढ़ाई के उस फ़ील्ड को भी कहा जाता है जो इन प्रोग्राम या सिस्टम से जुड़ा है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी कोर्स देखें.
मेजर क्लास
क्लास-इंबैलेंस वाले डेटासेट में सबसे ज़्यादा बार दिखने वाला लेबल. उदाहरण के लिए, अगर किसी डेटासेट में 99% नेगेटिव लेबल और 1% पॉज़िटिव लेबल हैं, तो नेगेटिव लेबल मेजॉरिटी क्लास हैं.
माइनॉरिटी क्लास से तुलना करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: असंतुलित डेटासेट देखें.
मिनी-बैच
यह बैच का एक छोटा सबसेट होता है. इसे रैंडम तरीके से चुना जाता है और एक इटरेशन में प्रोसेस किया जाता है. मिनी-बैच का बैच साइज़ आम तौर पर 10 से 1,000 उदाहरणों के बीच होता है.
उदाहरण के लिए, मान लें कि पूरे ट्रेनिंग सेट (पूरे बैच) में 1,000 उदाहरण शामिल हैं. मान लें कि आपने हर मिनी-बैच का बैच साइज़ 20 पर सेट किया है. इसलिए, हर इटरेशन में 1,000 उदाहरणों में से 20 उदाहरणों के नुकसान का पता लगाया जाता है. इसके बाद, वेट और बायस में बदलाव किया जाता है.
पूरे बैच के सभी उदाहरणों के नुकसान की तुलना में, मिनी-बैच के नुकसान का हिसाब लगाना ज़्यादा आसान होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
माइनॉरिटी क्लास
क्लास-इम्बैलेंस वाले डेटासेट में सबसे कम बार दिखने वाला लेबल. उदाहरण के लिए, अगर किसी डेटासेट में 99% नेगेटिव लेबल और 1% पॉज़िटिव लेबल हैं, तो पॉज़िटिव लेबल माइनॉरिटी क्लास में आते हैं.
ज़्यादातर क्लास के साथ कंट्रास्ट.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: असंतुलित डेटासेट देखें.
मॉडल
आम तौर पर, कोई भी ऐसा गणितीय फ़ंक्शन जो इनपुट डेटा को प्रोसेस करता है और आउटपुट देता है. दूसरे शब्दों में कहें, तो मॉडल, पैरामीटर और स्ट्रक्चर का ऐसा सेट होता है जिसकी मदद से कोई सिस्टम अनुमान लगाता है. सुपरवाइज़्ड मशीन लर्निंग में, मॉडल उदाहरण को इनपुट के तौर पर लेता है और अनुमान को आउटपुट के तौर पर दिखाता है. सुपरवाइज़्ड मशीन लर्निंग में, मॉडल कुछ हद तक अलग-अलग होते हैं. उदाहरण के लिए:
- लीनियर रिग्रेशन मॉडल में वज़न और बायस का सेट होता है.
- न्यूरल नेटवर्क मॉडल में ये शामिल होते हैं:
- छिपी हुई लेयर का एक सेट. हर लेयर में एक या उससे ज़्यादा न्यूरॉन होते हैं.
- हर न्यूरॉन से जुड़े वेट और बायस.
- डिसिज़न ट्री मॉडल में ये शामिल होते हैं:
- ट्री का आकार. इसका मतलब है कि शर्तें और पत्तियां किस पैटर्न में जुड़ी हैं.
- के आने और जाने की सूचना.
आपके पास किसी मॉडल को सेव करने, वापस लाने या उसकी कॉपी बनाने का विकल्प होता है.
बिना निगरानी वाली मशीन लर्निंग भी मॉडल जनरेट करती है. आम तौर पर, यह एक ऐसा फ़ंक्शन होता है जो इनपुट उदाहरण को सबसे सही क्लस्टर से मैप कर सकता है.
मल्टी-क्लास क्लासिफ़िकेशन
यह सुपरवाइज़्ड लर्निंग में क्लासिफ़िकेशन की समस्या है. इसमें डेटासेट में लेबल की दो से ज़्यादा क्लास होती हैं. उदाहरण के लिए, आइरिस डेटासेट में मौजूद लेबल, इन तीन क्लास में से कोई एक होना चाहिए:
- आइरिस सेटोसा
- आइरिस वर्जिनिका
- आइरिस वर्सिकलर
आइरिस डेटासेट पर ट्रेन किया गया मॉडल, नए उदाहरणों के आधार पर आइरिस टाइप का अनुमान लगाता है. यह मल्टी-क्लास क्लासिफ़िकेशन करता है.
इसके उलट, क्लासिफ़िकेशन की ऐसी समस्याएं जिनमें सिर्फ़ दो क्लास के बीच अंतर किया जाता है उन्हें बाइनरी क्लासिफ़िकेशन मॉडल कहा जाता है. उदाहरण के लिए, ईमेल मॉडल यह अनुमान लगाता है कि ईमेल स्पैम है या स्पैम नहीं है. यह एक बाइनरी क्लासिफ़िकेशन मॉडल है.
क्लस्टरिंग की समस्याओं में, मल्टी-क्लास क्लासिफ़िकेशन का मतलब दो से ज़्यादा क्लस्टर से होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: मल्टी-क्लास क्लासिफ़िकेशन देखें.
नहीं
नेगेटिव क्लास
बाइनरी क्लासिफ़िकेशन में, एक क्लास को पॉज़िटिव और दूसरी क्लास को नेगेटिव कहा जाता है. पॉज़िटिव क्लास, वह चीज़ या इवेंट होता है जिसके लिए मॉडल की टेस्टिंग की जा रही है. वहीं, नेगेटिव क्लास, दूसरी संभावना होती है. उदाहरण के लिए:
- मेडिकल टेस्ट में नेगेटिव क्लास "ट्यूमर नहीं है" हो सकती है.
- ईमेल के क्लासिफ़िकेशन मॉडल में नेगेटिव क्लास "स्पैम नहीं है" हो सकती है.
पॉज़िटिव क्लास से तुलना करें.
न्यूरल नेटवर्क
एक मॉडल, जिसमें कम से कम एक हिडन लेयर हो. डीप न्यूरल नेटवर्क, न्यूरल नेटवर्क का एक टाइप है. इसमें एक से ज़्यादा हिडन लेयर होती हैं. उदाहरण के लिए, इस डायग्राम में दो हिडन लेयर वाला डीप न्यूरल नेटवर्क दिखाया गया है.
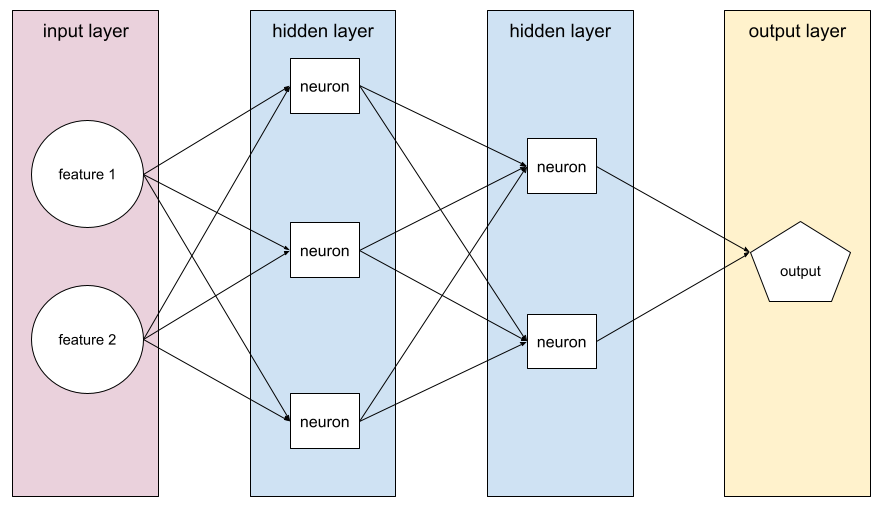
न्यूरल नेटवर्क में मौजूद हर न्यूरॉन, अगली लेयर के सभी नोड से कनेक्ट होता है. उदाहरण के लिए, ऊपर दिए गए डायग्राम में देखें कि पहली हिडन लेयर में मौजूद तीनों न्यूरॉन, दूसरी हिडन लेयर में मौजूद दोनों न्यूरॉन से अलग-अलग तरीके से कनेक्ट होते हैं.
कंप्यूटर पर लागू किए गए न्यूरल नेटवर्क को कभी-कभी आर्टिफ़िशियल न्यूरल नेटवर्क कहा जाता है. ऐसा इसलिए, ताकि इन्हें दिमाग़ और अन्य नर्वस सिस्टम में मौजूद न्यूरल नेटवर्क से अलग किया जा सके.
कुछ न्यूरल नेटवर्क, अलग-अलग सुविधाओं और लेबल के बीच बेहद जटिल नॉनलीनियर रिलेशनशिप की नकल कर सकते हैं.
कन्वलूशनल न्यूरल नेटवर्क और रीकरंट न्यूरल नेटवर्क के बारे में भी जानें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क देखें.
न्यूरॉन
मशीन लर्निंग में, न्यूरल नेटवर्क की हिडन लेयर में मौजूद एक अलग यूनिट. हर न्यूरॉन, दो चरणों में यह कार्रवाई करता है:
- यह नोड, इनपुट वैल्यू को उनके वेट से गुणा करके, वेटेड सम की कैलकुलेशन करता है.
- वेटेड सम को ऐक्टिवेशन फ़ंक्शन के इनपुट के तौर पर पास करता है.
पहली हिडन लेयर में मौजूद न्यूरॉन, इनपुट लेयर में मौजूद फ़ीचर वैल्यू से इनपुट स्वीकार करता है. पहली हिडन लेयर के बाद की किसी भी हिडन लेयर में मौजूद न्यूरॉन, पिछली हिडन लेयर में मौजूद न्यूरॉन से इनपुट स्वीकार करता है. उदाहरण के लिए, दूसरी हिडन लेयर में मौजूद न्यूरॉन, पहली हिडन लेयर में मौजूद न्यूरॉन से इनपुट स्वीकार करता है.
नीचे दिए गए इलस्ट्रेशन में, दो न्यूरॉन और उनके इनपुट को हाइलाइट किया गया है.
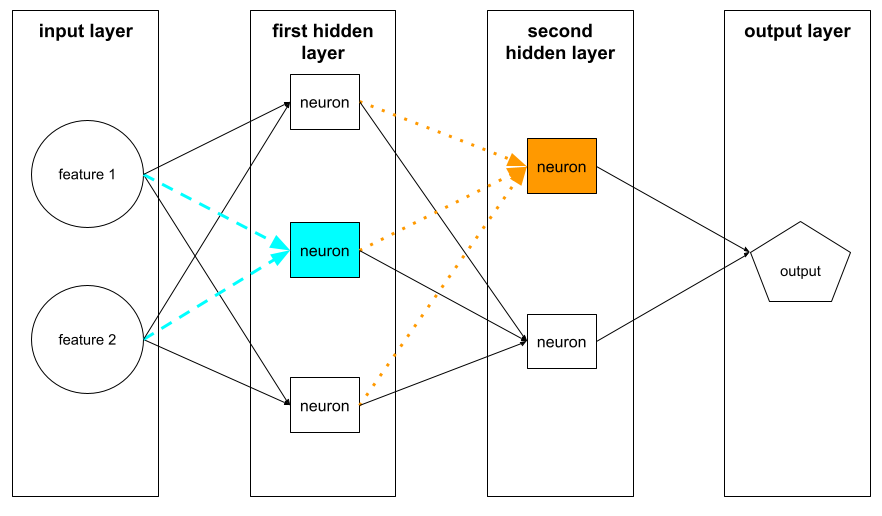
न्यूरल नेटवर्क में मौजूद न्यूरॉन, दिमाग और नर्वस सिस्टम के अन्य हिस्सों में मौजूद न्यूरॉन की तरह काम करता है.
नोड (न्यूरल नेटवर्क)
छिपी हुई लेयर में मौजूद न्यूरॉन.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क देखें.
नॉनलीनियर
दो या उससे ज़्यादा वैरिएबल के बीच ऐसा संबंध जिसे सिर्फ़ जोड़ और गुणा करके नहीं दिखाया जा सकता. लीनियर संबंध को लाइन के तौर पर दिखाया जा सकता है. वहीं, नॉनलीनियर संबंध को लाइन के तौर पर नहीं दिखाया जा सकता. उदाहरण के लिए, ऐसे दो मॉडल पर विचार करें जिनमें से हर मॉडल, एक सुविधा को एक लेबल से जोड़ता है. बाईं ओर मौजूद मॉडल लीनियर है और दाईं ओर मौजूद मॉडल नॉनलीनियर है:

अलग-अलग तरह के नॉनलीनियर फ़ंक्शन आज़माने के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: नोड और हिडन लेयर देखें.
नॉनस्टेशनैरिटी
ऐसी सुविधा जिसकी वैल्यू एक या उससे ज़्यादा डाइमेंशन के हिसाब से बदलती हैं. आम तौर पर, यह समय के हिसाब से बदलती है. उदाहरण के लिए, नॉनस्टेशनैरिटी के ये उदाहरण देखें:
- किसी स्टोर पर बेचे गए स्विमसूट की संख्या, सीज़न के हिसाब से अलग-अलग होती है.
- किसी खास इलाके में, किसी खास फल की फ़सल साल के ज़्यादातर समय में शून्य होती है, लेकिन कुछ समय के लिए यह बहुत ज़्यादा होती है.
- क्लाइमेट चेंज की वजह से, सालाना औसत तापमान में बदलाव हो रहा है.
स्टेशनैरिटी से तुलना करें.
नॉर्मलाइज़ेशन
सामान्य तौर पर, किसी वैरिएबल की वैल्यू की असल रेंज को वैल्यू की स्टैंडर्ड रेंज में बदलने की प्रोसेस को नॉर्मलाइज़ेशन कहते हैं. जैसे:
- -1 से +1
- 0 से 1
- ज़ेड-स्कोर (लगभग -3 से +3)
उदाहरण के लिए, मान लें कि किसी सुविधा की वैल्यू की असल रेंज 800 से 2,400 है. फ़ीचर इंजीनियरिंग के तहत, असल वैल्यू को स्टैंडर्ड रेंज में नॉर्मलाइज़ किया जा सकता है. जैसे, -1 से +1.
नॉर्मलाइज़ेशन, फ़ीचर इंजीनियरिंग में एक सामान्य टास्क है. जब फ़ीचर वेक्टर में मौजूद हर संख्यात्मक फ़ीचर की रेंज लगभग एक जैसी होती है, तो मॉडल आम तौर पर तेज़ी से ट्रेन होते हैं और बेहतर अनुमान लगाते हैं.
ज़ेड-स्कोर नॉर्मलाइज़ेशन भी देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: सामान्य बनाना देखें.
न्यूमेरिकल डेटा
विशेषताएं, जिन्हें पूर्णांक या असल वैल्यू वाली संख्याओं के तौर पर दिखाया जाता है. उदाहरण के लिए, घर की कीमत का अनुमान लगाने वाला मॉडल, घर के साइज़ (स्क्वेयर फ़ीट या स्क्वेयर मीटर में) को संख्या के तौर पर दिखाएगा. किसी सुविधा को संख्यात्मक डेटा के तौर पर दिखाने का मतलब है कि सुविधा की वैल्यू का लेबल से गणितीय संबंध है. इसका मतलब है कि घर के स्क्वेयर मीटर की संख्या का, घर की कीमत से कुछ गणितीय संबंध हो सकता है.
सभी पूर्णांक डेटा को संख्या के तौर पर नहीं दिखाया जाना चाहिए. उदाहरण के लिए, दुनिया के कुछ हिस्सों में पिन कोड पूर्णांक होते हैं. हालांकि, पूर्णांक वाले पिन कोड को मॉडल में संख्यात्मक डेटा के तौर पर नहीं दिखाया जाना चाहिए. ऐसा इसलिए है, क्योंकि 20000 का पिन कोड, 10000 के पिन कोड से दोगुना (या आधा) नहीं है. इसके अलावा, अलग-अलग पिन कोड के हिसाब से प्रॉपर्टी की वैल्यू अलग-अलग होती है. हालांकि, हम यह नहीं मान सकते कि पिन कोड 20000 के हिसाब से प्रॉपर्टी की वैल्यू, पिन कोड 10000 के हिसाब से प्रॉपर्टी की वैल्यू से दोगुनी है.
पिन कोड को कैटेगरी के हिसाब से बंटे डेटा के तौर पर दिखाया जाना चाहिए.
संख्यात्मक सुविधाओं को कभी-कभी कंटीन्यूअस फ़ीचर कहा जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा के साथ काम करना लेख पढ़ें.
O
अॉफ़लाइन
static का समानार्थी शब्द.
ऑफ़लाइन इन्फ़रेंस
किसी मॉडल के अनुमानों का एक बैच जनरेट करने और फिर उन अनुमानों को कैश मेमोरी में सेव करने की प्रोसेस. इसके बाद, ऐप्लिकेशन मॉडल को फिर से चलाने के बजाय, कैश मेमोरी से अनुमानित पूर्वानुमान को ऐक्सेस कर सकते हैं.
उदाहरण के लिए, एक ऐसे मॉडल पर विचार करें जो हर चार घंटे में एक बार, स्थानीय मौसम के पूर्वानुमान (अनुमान) जनरेट करता है. हर मॉडल रन के बाद, सिस्टम स्थानीय मौसम के सभी अनुमानों को कैश मेमोरी में सेव करता है. मौसम की जानकारी देने वाले ऐप्लिकेशन, कैश मेमोरी से पूर्वानुमान की जानकारी पाते हैं.
ऑफ़लाइन अनुमान को स्टैटिक अनुमान भी कहा जाता है.
इसकी तुलना ऑनलाइन इन्फ़रेंस से करें. ज़्यादा जानकारी के लिए, Machine Learning Crash Course में Production ML systems: Static versus dynamic inference देखें.
वन-हॉट एन्कोडिंग
कैटगरी वाले डेटा को ऐसे वेक्टर के तौर पर दिखाया जाता है जिसमें:
- एक एलिमेंट को 1 पर सेट किया गया है.
- अन्य सभी एलिमेंट को 0 पर सेट किया जाता है.
आम तौर पर, वन-हॉट एन्कोडिंग का इस्तेमाल उन स्ट्रिंग या आइडेंटिफ़ायर को दिखाने के लिए किया जाता है जिनकी वैल्यू सीमित होती हैं.
उदाहरण के लिए, मान लें कि कैटगरी के हिसाब से तय की गई किसी सुविधा का नाम Scandinavia है और इसकी पांच संभावित वैल्यू हैं:
- "डेनमार्क"
- "स्वीडन"
- "नॉर्वे"
- "फ़िनलैंड"
- "आइसलैंड"
वन-हॉट एन्कोडिंग, पांचों वैल्यू को इस तरह दिखा सकती है:
| देश | वेक्टर | ||||
|---|---|---|---|---|---|
| "डेनमार्क" | 1 | 0 | 0 | 0 | 0 |
| "स्वीडन" | 0 | 1 | 0 | 0 | 0 |
| "नॉर्वे" | 0 | 0 | 1 | 0 | 0 |
| "फ़िनलैंड" | 0 | 0 | 0 | 1 | 0 |
| "आइसलैंड" | 0 | 0 | 0 | 0 | 1 |
वन-हॉट एन्कोडिंग की मदद से, मॉडल पांचों देशों के आधार पर अलग-अलग कनेक्शन के बारे में जान सकता है.
किसी फ़ीचर को न्यूमेरिकल डेटा के तौर पर दिखाना, वन-हॉट एन्कोडिंग का एक विकल्प है. माफ़ करें, स्कैंडिनेवियन देशों को संख्या के हिसाब से दिखाना सही नहीं है. उदाहरण के लिए, यहां दिए गए संख्यात्मक फ़ॉर्मैट पर ध्यान दें:
- "डेनमार्क" के लिए 0
- "स्वीडन" 1 है
- "नॉर्वे" की वैल्यू 2 है
- "फ़िनलैंड" की वैल्यू 3 है
- "आइसलैंड" 4 है
न्यूमेरिक एन्कोडिंग की मदद से, मॉडल रॉ नंबर को गणित के हिसाब से समझता है और उन नंबरों के आधार पर ट्रेनिंग लेता है. हालांकि, आइसलैंड में नॉर्वे की तुलना में किसी चीज़ की कीमत दोगुनी (या आधी) नहीं है. इसलिए, मॉडल कुछ अजीब नतीजे देगा.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटेगरी के हिसाब से डेटा: शब्दावली और वन-हॉट एन्कोडिंग देखें.
वन-वर्सेज़-ऑल
अगर क्लासिफ़िकेशन की समस्या में N क्लास हैं, तो N अलग-अलग बाइनरी क्लासिफ़िकेशन मॉडल का इस्तेमाल किया जाता है. हर संभावित नतीजे के लिए एक बाइनरी क्लासिफ़िकेशन मॉडल होता है. उदाहरण के लिए, अगर कोई मॉडल उदाहरणों को जानवर, सब्ज़ी या खनिज के तौर पर कैटगरी में बांटता है, तो वन-वर्सेज़-ऑल (एक बनाम सभी) समाधान, बाइनरी क्लासिफ़िकेशन (दो कैटगरी में बांटने वाला) के ये तीन अलग-अलग मॉडल उपलब्ध कराएगा:
- जानवर बनाम जानवर नहीं
- सब्ज़ी है या नहीं
- मिनरल है या नहीं
online
डाइनैमिक के लिए समानार्थी शब्द.
ऑनलाइन अनुमान
मांग के आधार पर अनुमान जनरेट करना. उदाहरण के लिए, मान लें कि कोई ऐप्लिकेशन, मॉडल को इनपुट देता है और अनुमान लगाने का अनुरोध करता है. ऑनलाइन इन्फ़्रेंस का इस्तेमाल करने वाला सिस्टम, मॉडल को चलाकर अनुरोध का जवाब देता है. साथ ही, ऐप्लिकेशन को अनुमानित नतीजे दिखाता है.
इसकी तुलना ऑफ़लाइन इन्फ़रेंस से करें.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में Production ML systems: Static versus dynamic inference देखें.
आउटपुट लेयर
न्यूरल नेटवर्क की "आखिरी" लेयर. आउटपुट लेयर में अनुमान शामिल होता है.
इस इलस्ट्रेशन में, इनपुट लेयर, दो छिपी हुई लेयर, और आउटपुट लेयर वाला एक छोटा डीप न्यूरल नेटवर्क दिखाया गया है:
ओवरफ़िटिंग
ऐसा मॉडल बनाना जो ट्रेनिंग डेटा से इतना मिलता-जुलता हो कि मॉडल नए डेटा के आधार पर सही अनुमान न लगा पाए.
रेगुलराइज़ेशन से ओवरफ़िटिंग कम हो सकती है. बड़े और अलग-अलग तरह के ट्रेनिंग सेट पर ट्रेनिंग देने से भी ओवरफ़िटिंग की समस्या कम हो सकती है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग देखें.
P
पांडा
यह कॉलम के हिसाब से डेटा का विश्लेषण करने वाला एपीआई है. इसे numpy के आधार पर बनाया गया है. TensorFlow जैसे कई मशीन लर्निंग फ़्रेमवर्क, pandas डेटा स्ट्रक्चर को इनपुट के तौर पर इस्तेमाल करते हैं. ज़्यादा जानकारी के लिए, pandas का दस्तावेज़ देखें.
पैरामीटर
वज़न और बायस, जो मॉडल ट्रेनिंग के दौरान सीखता है. उदाहरण के लिए, लीनियर रिग्रेशन मॉडल में, पैरामीटर में बायस (b) और इस फ़ॉर्मूले में मौजूद सभी वेट (w1, w2 वगैरह) शामिल होते हैं:
इसके उलट, हाइपरपैरामीटर वे वैल्यू होती हैं जिन्हें आप (या हाइपरपैरामीटर ट्यूनिंग सेवा) मॉडल को उपलब्ध कराती हैं. उदाहरण के लिए, लर्निंग रेट एक हाइपरपैरामीटर है.
पॉज़िटिव क्लास
वह क्लास जिसके लिए आपको टेस्ट करना है.
उदाहरण के लिए, कैंसर के मॉडल में पॉज़िटिव क्लास "ट्यूमर" हो सकती है. ईमेल क्लासिफ़िकेशन मॉडल में पॉज़िटिव क्लास "स्पैम" हो सकती है.
नेगेटिव क्लास से तुलना करें.
प्रोसेस होने के बाद
मॉडल के चलने के बाद, उसके आउटपुट में बदलाव करना. पोस्ट-प्रोसेसिंग का इस्तेमाल, मॉडल में बदलाव किए बिना निष्पक्षता से जुड़ी शर्तों को लागू करने के लिए किया जा सकता है.
उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल पर पोस्ट-प्रोसेसिंग लागू की जा सकती है. इसके लिए, क्लासिफ़िकेशन थ्रेशोल्ड को इस तरह से सेट किया जाता है कि किसी एट्रिब्यूट के लिए अवसर की समानता बनी रहे. इसके लिए, यह जांच की जाती है कि उस एट्रिब्यूट की सभी वैल्यू के लिए ट्रू पॉज़िटिव रेट एक जैसा है.
प्रीसिज़न
यह वर्गीकरण मॉडल के लिए एक मेट्रिक है. इससे इस सवाल का जवाब मिलता है:
जब मॉडल ने पॉज़िटिव क्लास का अनुमान लगाया, तो कितने प्रतिशत अनुमान सही थे?
यहां फ़ॉर्मूला दिया गया है:
कहां:
- ट्रू पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का सही अनुमान लगाया है.
- फ़ॉल्स पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का गलत अनुमान लगाया है.
उदाहरण के लिए, मान लें कि किसी मॉडल ने 200 पॉज़िटिव अनुमान लगाए. इन 200 पॉज़िटिव अनुमानों में से:
- इनमें से 150 सही पॉज़िटिव थे.
- इनमें से 50 फ़ॉल्स पॉज़िटिव थे.
इस मामले में:
इसकी तुलना सटीकता और रीकॉल से करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: सटीकता, रीकॉल, प्रेसिज़न, और इनसे जुड़ी मेट्रिक देखें.
अनुमान
मॉडल का आउटपुट. उदाहरण के लिए:
- बाइनरी क्लासिफ़िकेशन मॉडल का अनुमान, पॉज़िटिव क्लास या नेगेटिव क्लास होता है.
- मल्टी-क्लास क्लासिफ़िकेशन मॉडल का अनुमान, एक क्लास होता है.
- लीनियर रिग्रेशन मॉडल का अनुमान एक संख्या होती है.
प्रॉक्सी लेबल
लेबल का अनुमान लगाने के लिए इस्तेमाल किया गया डेटा, डेटासेट में सीधे तौर पर उपलब्ध नहीं है.
उदाहरण के लिए, मान लें कि आपको किसी मॉडल को कर्मचारी के तनाव के स्तर का अनुमान लगाने के लिए ट्रेन करना है. आपके डेटासेट में अनुमान लगाने वाली कई सुविधाएं हैं, लेकिन इसमें तनाव का स्तर नाम का कोई लेबल नहीं है. आपने "काम की जगह पर होने वाली दुर्घटनाएं" को तनाव के लेवल के लिए प्रॉक्सी लेबल के तौर पर चुना. आखिरकार, ज़्यादा तनाव में रहने वाले कर्मचारियों के साथ, शांत रहने वाले कर्मचारियों की तुलना में ज़्यादा दुर्घटनाएं होती हैं. या फिर ऐसा होता है? ऐसा हो सकता है कि काम की जगह पर होने वाली दुर्घटनाओं की संख्या में कई वजहों से उतार-चढ़ाव होता हो.
दूसरे उदाहरण के तौर पर, मान लें कि आपको अपने डेटासेट के लिए, क्या बारिश हो रही है? को बूलियन लेबल के तौर पर इस्तेमाल करना है, लेकिन आपके डेटासेट में बारिश का डेटा मौजूद नहीं है. अगर फ़ोटोग्राफ़ उपलब्ध हैं, तो क्या बारिश हो रही है? के लिए, छाता लिए हुए लोगों की तस्वीरों को प्रॉक्सी लेबल के तौर पर इस्तेमाल किया जा सकता है क्या यह एक अच्छा प्रॉक्सी लेबल है? ऐसा हो सकता है. हालांकि, कुछ संस्कृतियों में लोग बारिश से बचने के बजाय, धूप से बचने के लिए छतरी का इस्तेमाल ज़्यादा करते हैं.
प्रॉक्सी लेबल अक्सर सही नहीं होते. जब भी संभव हो, प्रॉक्सी लेबल के बजाय असली लेबल चुनें. हालांकि, अगर कोई असल लेबल मौजूद नहीं है, तो प्रॉक्सी लेबल को बहुत सोच-समझकर चुनें. साथ ही, सबसे कम खराब प्रॉक्सी लेबल कैंडिडेट को चुनें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: लेबल देखें.
R
RAG
रिट्रीवल-ऑगमेंटेड जनरेशन का संक्षिप्त नाम.
रेटिंग देने वाला
एक ऐसा व्यक्ति जो उदाहरणों के लिए लेबल देता है. "एनोटेटर", रेटर का दूसरा नाम है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटेगरी के हिसाब से बंटा हुआ डेटा: सामान्य समस्याएं देखें.
रीकॉल
यह वर्गीकरण मॉडल के लिए एक मेट्रिक है. इससे इस सवाल का जवाब मिलता है:
जब ग्राउंड ट्रुथ, पॉज़िटिव क्लास थी, तब मॉडल ने कितने प्रतिशत अनुमानों को सही तरीके से पॉज़िटिव क्लास के तौर पर पहचाना?
यहां फ़ॉर्मूला दिया गया है:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
कहां:
- ट्रू पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का सही अनुमान लगाया है.
- फ़ॉल्स नेगेटिव का मतलब है कि मॉडल ने गलती से नेगेटिव क्लास का अनुमान लगाया है.
उदाहरण के लिए, मान लें कि आपके मॉडल ने उन उदाहरणों के लिए 200 अनुमान लगाए जिनके लिए ग्राउंड ट्रुथ पॉज़िटिव क्लास था. इन 200 अनुमानों में से:
- इनमें से 180 ट्रू पॉज़िटिव थे.
- इनमें से 20 फ़ॉल्स नेगेटिव थे.
इस मामले में:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
ज़्यादा जानकारी के लिए, क्लासिफ़िकेशन: सटीकता, रिकॉल, सटीक और इससे जुड़ी मेट्रिक देखें.
रेक्टिफ़ाइड लीनियर यूनिट (आरईएलयू)
ऐक्टिवेशन फ़ंक्शन, जो इस तरह काम करता है:
- अगर इनपुट नेगेटिव या शून्य है, तो आउटपुट 0 होता है.
- अगर इनपुट पॉज़िटिव है, तो आउटपुट इनपुट के बराबर होता है.
उदाहरण के लिए:
- अगर इनपुट -3 है, तो आउटपुट 0 होगा.
- अगर इनपुट +3 है, तो आउटपुट 3.0 होगा.
यहां ReLU का प्लॉट दिया गया है:
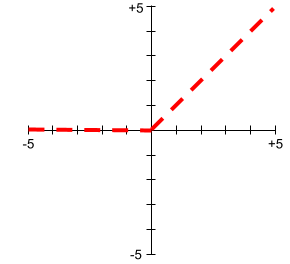
ReLU, एक बहुत लोकप्रिय ऐक्टिवेशन फ़ंक्शन है. आसान तरीके से काम करने के बावजूद, ReLU की मदद से न्यूरल नेटवर्क, विशेषताओं और लेबल के बीच नॉनलीनियर संबंधों को सीख पाता है.
रिग्रेशन मॉडल
आसान शब्दों में कहें, तो यह एक ऐसा मॉडल है जो संख्या के तौर पर अनुमान जनरेट करता है. (इसके उलट, क्लासिफ़िकेशन मॉडल, क्लास के बारे में अनुमान लगाता है.) उदाहरण के लिए, ये सभी रिग्रेशन मॉडल हैं:
- ऐसा मॉडल जो किसी घर की कीमत का अनुमान यूरो में लगाता है. जैसे, 4,23,000.
- ऐसा मॉडल जो किसी पेड़ की उम्र का अनुमान लगाता है. जैसे, 23.2 साल.
- यह मॉडल, अगले छह घंटों में किसी शहर में होने वाली बारिश का अनुमान लगाता है. यह अनुमान इंच में होता है. जैसे, 0.18.
आम तौर पर, दो तरह के रिग्रेशन मॉडल इस्तेमाल किए जाते हैं:
- लीनियर रिग्रेशन, जो ऐसी लाइन ढूंढता है जो लेबल वैल्यू को सुविधाओं के हिसाब से सबसे सही तरीके से फ़िट करती है.
- लॉजिस्टिक रिग्रेशन, जो 0.0 और 1.0 के बीच की संभावना जनरेट करता है. आम तौर पर, सिस्टम इस संभावना को क्लास के अनुमान पर मैप करता है.
संख्यात्मक अनुमान देने वाला हर मॉडल, रिग्रेशन मॉडल नहीं होता. कुछ मामलों में, संख्यात्मक अनुमान लगाने वाला मॉडल सिर्फ़ एक क्लासिफ़िकेशन मॉडल होता है. हालांकि, इसमें क्लास के नाम संख्यात्मक होते हैं. उदाहरण के लिए, पिन कोड का अनुमान लगाने वाला मॉडल, क्लासिफ़िकेशन मॉडल होता है, न कि रिग्रेशन मॉडल.
रेगुलराइज़ेशन
ऐसा कोई भी मेकैनिज़्म जो ओवरफ़िटिंग को कम करता है. रेगुलराइज़ेशन के लोकप्रिय टाइप में ये शामिल हैं:
- L1 रेगुलराइज़ेशन
- L2 रेगुलराइज़ेशन
- ड्रॉपआउट रेगुलराइज़ेशन
- अर्ली स्टॉपिंग (यह सामान्य तौर पर इस्तेमाल होने वाला तरीका नहीं है, लेकिन इससे ओवरफ़िटिंग को कम किया जा सकता है)
रेगुलराइज़ेशन को मॉडल की जटिलता पर लगने वाले जुर्माने के तौर पर भी तय किया जा सकता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग: मॉडल की जटिलता देखें.
रेगुलराइज़ेशन रेट
यह एक ऐसा नंबर होता है जो ट्रेनिंग के दौरान, रेगुलराइज़ेशन के महत्व को दिखाता है. रेगुलराइज़ेशन रेट बढ़ाने से ओवरफ़िटिंग कम हो जाती है. हालांकि, इससे मॉडल की अनुमान लगाने की क्षमता कम हो सकती है. इसके उलट, रेगुलराइज़ेशन रेट को कम करने या हटाने से ओवरफ़िटिंग बढ़ जाती है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग: L2 रेगुलराइज़ेशन देखें.
ReLU
Rectified Linear Unit के लिए इस्तेमाल किया जाने वाला छोटा नाम.
जानकारी खोजकर जवाब देने की सुविधा (आरएजी)
यह लार्ज लैंग्वेज मॉडल (एलएलएम) के आउटपुट की क्वालिटी को बेहतर बनाने की एक तकनीक है. इसके लिए, मॉडल को ट्रेनिंग देने के बाद, जानकारी के स्रोतों से मिली जानकारी का इस्तेमाल किया जाता है. आरएजी, एलएलएम के जवाबों को ज़्यादा सटीक बनाता है. इसके लिए, यह ट्रेनिंग वाले एलएलएम को भरोसेमंद नॉलेज बेस या दस्तावेज़ों से मिली जानकारी का ऐक्सेस देता है.
जानकारी खोजकर जवाब जनरेट करने की तकनीक का इस्तेमाल करने की सामान्य वजहें ये हैं:
- मॉडल के जनरेट किए गए जवाबों में तथ्यों की सटीकता को बढ़ाना.
- मॉडल को ऐसी जानकारी का ऐक्सेस देना जिसके बारे में उसे ट्रेनिंग नहीं दी गई है.
- मॉडल के इस्तेमाल किए गए ज्ञान को बदलना.
- मॉडल को सोर्स के उद्धरण देने की सुविधा चालू करना.
उदाहरण के लिए, मान लें कि कोई केमिस्ट्री ऐप्लिकेशन, उपयोगकर्ता की क्वेरी से जुड़ी खास जानकारी जनरेट करने के लिए PaLM API का इस्तेमाल करता है. जब ऐप्लिकेशन के बैकएंड को कोई क्वेरी मिलती है, तो बैकएंड:
- यह कुकी, उपयोगकर्ता की क्वेरी से जुड़ा डेटा खोजती है ("फिर से पाती है").
- यह उपयोगकर्ता की क्वेरी में, केमिस्ट्री से जुड़ा काम का डेटा जोड़ता है ("बढ़ाता है").
- यह एलएलएम को, जोड़े गए डेटा के आधार पर खास जानकारी बनाने का निर्देश देता है.
आरओसी (रिसीवर ऑपरेटिंग कैरेक्टरिस्टिक) कर्व
यह बाइनरी क्लासिफ़िकेशन में, अलग-अलग क्लासिफ़िकेशन थ्रेशोल्ड के लिए, ट्रू पॉज़िटिव रेट बनाम फ़ॉल्स पॉज़िटिव रेट का ग्राफ़ है.
आरओसी कर्व का आकार, बाइनरी क्लासिफ़िकेशन मॉडल की पॉज़िटिव क्लास को नेगेटिव क्लास से अलग करने की क्षमता के बारे में बताता है. उदाहरण के लिए, मान लें कि बाइनरी क्लासिफ़िकेशन मॉडल, सभी नेगेटिव क्लास को सभी पॉज़िटिव क्लास से पूरी तरह अलग करता है:
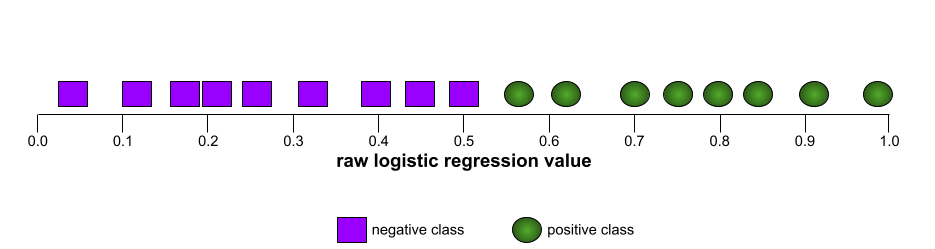
ऊपर दिए गए मॉडल के लिए आरओसी कर्व ऐसा दिखता है:
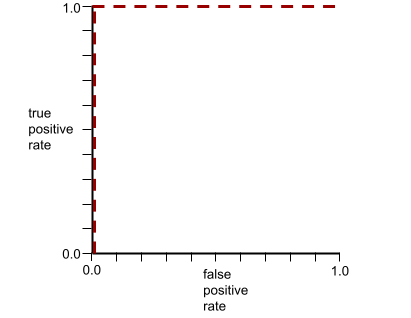
इसके उलट, इस इमेज में एक खराब मॉडल के लिए लॉजिस्टिक रिग्रेशन की रॉ वैल्यू दिखाई गई हैं. यह मॉडल, नेगेटिव क्लास को पॉज़िटिव क्लास से अलग नहीं कर सकता:
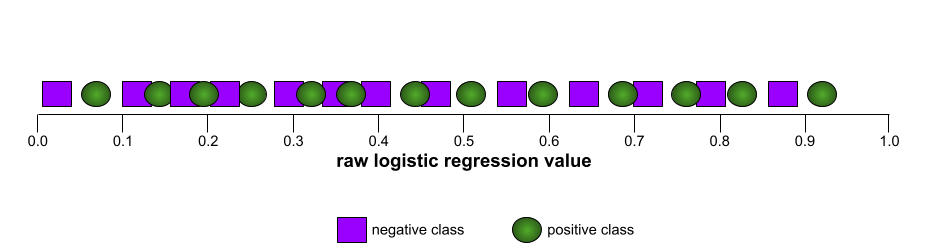
इस मॉडल के लिए आरओसी कर्व ऐसा दिखता है:
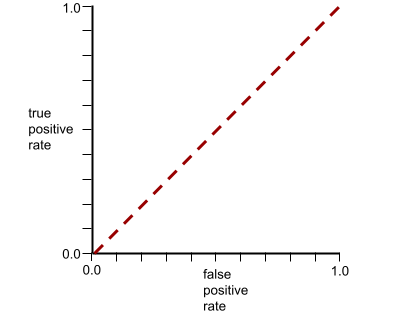
वहीं, असल दुनिया में ज़्यादातर बाइनरी क्लासिफ़िकेशन मॉडल, पॉज़िटिव और नेगेटिव क्लास को कुछ हद तक अलग करते हैं. हालांकि, वे आम तौर पर ऐसा पूरी तरह से नहीं कर पाते. इसलिए, एक सामान्य आरओसी कर्व, इन दोनों एक्सट्रीम के बीच कहीं होता है:
आरओसी कर्व पर (0.0,1.0) के सबसे करीब वाला पॉइंट, सैद्धांतिक तौर पर सबसे सही क्लासिफ़िकेशन थ्रेशोल्ड की पहचान करता है. हालांकि, असल दुनिया की कई अन्य समस्याएं, क्लासिफ़िकेशन के सही थ्रेशोल्ड को चुनने पर असर डालती हैं. उदाहरण के लिए, ऐसा हो सकता है कि गलत पहचान किए जाने से ज़्यादा नुकसान, पहचान न किए जाने से होता हो.
AUC नाम की संख्यात्मक मेट्रिक, आरओसी कर्व को एक फ़्लोटिंग-पॉइंट वैल्यू में बदल देती है.
रूट मीन स्क्वेयर्ड एरर (आरएमएसई)
यह मीन स्क्वेयर्ड एरर का वर्गमूल होता है.
S
सिगमॉइड फ़ंक्शन
यह एक गणितीय फ़ंक्शन है, जो इनपुट वैल्यू को सीमित रेंज में "स्क्वीज़" करता है. आम तौर पर, यह रेंज 0 से 1 या -1 से +1 होती है. इसका मतलब है कि सिग्मॉइड फ़ंक्शन में कोई भी संख्या (दो, दस लाख, नेगेटिव अरब वगैरह) डाली जा सकती है. हालांकि, आउटपुट हमेशा तय सीमा के अंदर ही होगा. सिगमॉइड ऐक्टिवेशन फ़ंक्शन का प्लॉट ऐसा दिखता है:
मशीन लर्निंग में सिगमॉइड फ़ंक्शन का इस्तेमाल कई कामों के लिए किया जाता है. जैसे:
- लॉजिस्टिक रिग्रेशन या मल्टीनोमियल रिग्रेशन मॉडल के रॉ आउटपुट को संभावना में बदलना.
- कुछ न्यूरल नेटवर्क में ऐक्टिवेशन फ़ंक्शन के तौर पर काम करता है.
सॉफ़्टमैक्स
यह फ़ंक्शन, मल्टी-क्लास क्लासिफ़िकेशन मॉडल में हर संभावित क्लास के लिए संभावनाएं तय करता है. सभी संभावनाओं का जोड़ 1.0 होता है. उदाहरण के लिए, यहां दी गई टेबल से पता चलता है कि सॉफ़्टमैक्स, अलग-अलग संभावनाओं को कैसे डिस्ट्रिब्यूट करता है:
| इमेज एक... | प्रॉबेबिलिटी |
|---|---|
| कुत्ता | .85 |
| cat | .13 |
| घोड़ा | .02 |
सॉफ़्टमैक्स को फ़ुल सॉफ़्टमैक्स भी कहा जाता है.
उम्मीदवार के सैंपल से तुलना करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: मल्टी-क्लास क्लासिफ़िकेशन देखें.
स्पार्स फ़ीचर
ऐसी सुविधा जिसकी वैल्यू ज़्यादातर शून्य या खाली होती हैं. उदाहरण के लिए, अगर किसी सुविधा में एक वैल्यू 1 है और 10 लाख वैल्यू 0 हैं, तो उसे स्पार्स कहा जाता है. इसके उलट, डेंस फ़ीचर में ऐसी वैल्यू होती हैं जो ज़्यादातर शून्य या खाली नहीं होती हैं.
मशीन लर्निंग में, ज़्यादातर फ़ीचर स्पार्स फ़ीचर होते हैं. कैटगोरिकल फ़ीचर आम तौर पर स्पार्स फ़ीचर होती हैं. उदाहरण के लिए, किसी जंगल में पेड़ की 300 संभावित प्रजातियों में से, एक उदाहरण सिर्फ़ मेपल के पेड़ की पहचान कर सकता है. इसके अलावा, वीडियो लाइब्रेरी में मौजूद लाखों वीडियो में से किसी एक उदाहरण में सिर्फ़ "कैसाब्लांका" की पहचान की जा सकती है.
किसी मॉडल में, आम तौर पर स्पार्स फ़ीचर को वन-हॉट एन्कोडिंग की मदद से दिखाया जाता है. अगर वन-हॉट एन्कोडिंग बड़ी है, तो बेहतर परफ़ॉर्मेंस के लिए, वन-हॉट एन्कोडिंग के ऊपर एम्बेडिंग लेयर लगाई जा सकती है.
स्पार्स वेक्टर के तौर पर डेटा को दिखाना
स्पार्स फ़ीचर में, सिर्फ़ गैर-शून्य एलिमेंट की जगह(जगहों) को सेव करना.
उदाहरण के लिए, मान लें कि कैटगरी वाली कोई सुविधा है, जिसका नाम species है. यह किसी जंगल में मौजूद 36 तरह के पेड़ों की पहचान करती है. यह भी मान लें कि हर उदाहरण में सिर्फ़ एक प्रजाति की पहचान की गई है.
हर उदाहरण में पेड़ की प्रजातियों को दिखाने के लिए, वन-हॉट वेक्टर का इस्तेमाल किया जा सकता है.
वन-हॉट वेक्टर में एक 1 (उदाहरण में पेड़ की किसी खास प्रजाति को दिखाने के लिए) और 35 0 (उदाहरण में पेड़ की 35 प्रजातियों को नहीं दिखाने के लिए) शामिल होंगे. इसलिए, maple का वन-हॉट रिप्रेजेंटेशन कुछ ऐसा दिख सकता है:

इसके अलावा, स्पार्स रिप्रेजेंटेशन से सिर्फ़ किसी खास प्रजाति की जगह की पहचान की जा सकती है. अगर maple 24वें स्थान पर है, तो maple का स्पार्स प्रज़ेंटेशन यह होगा:
24
ध्यान दें कि स्पार्स प्रज़ेंटेशन, वन-हॉट प्रज़ेंटेशन की तुलना में ज़्यादा कॉम्पैक्ट होता है.
थोड़े ज़्यादा जटिल उदाहरण के लिए, आइकॉन पर क्लिक करें.
मान लें कि आपके मॉडल में मौजूद हर उदाहरण में, अंग्रेज़ी के वाक्य में मौजूद शब्दों को शामिल करना ज़रूरी है. हालांकि, उन शब्दों का क्रम अलग-अलग हो सकता है. अंग्रेज़ी में करीब 1,70,000 शब्द होते हैं. इसलिए, अंग्रेज़ी एक कैटगरिकल फ़ीचर है, जिसमें करीब 1,70,000 एलिमेंट होते हैं. अंग्रेज़ी के ज़्यादातर वाक्यों में, उन 1,70,000 शब्दों का बहुत छोटा हिस्सा इस्तेमाल किया जाता है. इसलिए, किसी एक उदाहरण में शब्दों का सेट, लगभग निश्चित रूप से स्पार्स डेटा होगा.
इस वाक्य पर ध्यान दें:
My dog is a great dog
इस वाक्य में मौजूद शब्दों को दिखाने के लिए, वन-हॉट वेक्टर के किसी वैरिएंट का इस्तेमाल किया जा सकता है. इस वैरिएंट में, वेक्टर की एक से ज़्यादा सेल में शून्य से अलग वैल्यू हो सकती है. इसके अलावा, इस वैरिएंट में किसी सेल में एक के अलावा कोई और पूर्णांक हो सकता है. हालांकि, वाक्य में "my", "is", "a", और "great" शब्द सिर्फ़ एक बार आए हैं, लेकिन "dog" शब्द दो बार आया है. इस वाक्य में मौजूद शब्दों को दिखाने के लिए, वन-हॉट वेक्टर के इस वैरिएंट का इस्तेमाल करने पर, 1,70,000 एलिमेंट वाला यह वेक्टर मिलता है:

इसी वाक्य को कम शब्दों में इस तरह लिखा जा सकता है:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटगरी में बांटे गए डेटा का इस्तेमाल करना लेख पढ़ें.
स्पार्स वेक्टर
ऐसा वेक्टर जिसकी वैल्यू ज़्यादातर शून्य होती हैं. विरल फ़ीचर और विरलता के बारे में भी जानें.
स्क्वेयर्ड लॉस
L2 नुकसान के लिए समानार्थी शब्द.
स्टैटिक
कोई काम जो लगातार न किया जाए, बल्कि एक बार किया जाए. स्टैटिक और ऑफ़लाइन शब्द एक-दूसरे के समानार्थी हैं. मशीन लर्निंग में static और offline का इस्तेमाल आम तौर पर इन कामों के लिए किया जाता है:
- स्टैटिक मॉडल (या ऑफ़लाइन मॉडल) एक ऐसा मॉडल होता है जिसे एक बार ट्रेन किया जाता है. इसके बाद, इसका इस्तेमाल कुछ समय तक किया जाता है.
- स्टैटिक ट्रेनिंग (या ऑफ़लाइन ट्रेनिंग) का मतलब, स्टैटिक मॉडल को ट्रेनिंग देने की प्रोसेस से है.
- स्टैटिक इन्फ़रेंस (या ऑफ़लाइन इन्फ़रेंस) एक ऐसी प्रोसेस है जिसमें मॉडल, एक बार में अनुमानों का एक बैच जनरेट करता है.
डाइनैमिक के साथ कंट्रास्ट करें.
स्टैटिक इन्फ़रेंस
ऑफ़लाइन इन्फ़रेंस के लिए समानार्थी शब्द.
स्टेशनैरिटी
ऐसी सुविधा जिसकी वैल्यू एक या उससे ज़्यादा डाइमेंशन (आम तौर पर, समय) के हिसाब से नहीं बदलती. उदाहरण के लिए, अगर किसी सुविधा की वैल्यू 2021 और 2023 में लगभग एक जैसी दिखती हैं, तो इसका मतलब है कि वह सुविधा स्टेशनरी है.
असल दुनिया में, बहुत कम सुविधाओं में स्टेशनरी की सुविधा होती है. स्थिरता से जुड़ी सुविधाओं (जैसे, समुद्र का स्तर) में भी समय के साथ बदलाव होता है.
इसकी तुलना नॉनस्टेशनैरिटी से करें.
स्टोकेस्टिक ग्रेडिएंट डिसेंट (एसजीडी)
यह ग्रैडिएंट डिसेंट एल्गोरिदम है, जिसमें बैच साइज़ एक होता है. दूसरे शब्दों में कहें, तो SGD, ट्रेनिंग सेट से एक उदाहरण को रैंडम तरीके से चुनकर ट्रेनिंग देता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
सुपरवाइज़्ड मशीन लर्निंग
सुविधाओं और उनके लेबल से मॉडल को ट्रेनिंग देना. सुपरवाइज़्ड मशीन लर्निंग, किसी विषय को सीखने के लिए सवालों के सेट और उनके जवाबों का अध्ययन करने जैसा है. जब छात्र-छात्रा को सवालों और जवाबों के बीच मैपिंग करने में महारत हासिल हो जाती है, तब वह उसी विषय पर नए (पहले कभी नहीं देखे गए) सवालों के जवाब दे सकता है.
इसकी तुलना अनसुपरवाइज़्ड मशीन लर्निंग से करें.
ज़्यादा जानकारी के लिए, एमएल कोर्स की बुनियादी जानकारी में पर्यवेक्षित लर्निंग देखें.
सिंथेटिक फ़ीचर
ऐसी सुविधा जो इनपुट सुविधाओं में मौजूद नहीं है, लेकिन उनमें से एक या उससे ज़्यादा सुविधाओं से मिलकर बनी है. अप्राकृतिक सुविधाओं को बनाने के तरीकों में ये शामिल हैं:
- किसी कंटीन्यूअस फ़ीचर को रेंज बिन में बकेटिंग करना.
- क्रॉस-फ़िचर बनाना.
- किसी सुविधा की वैल्यू को दूसरी सुविधा की वैल्यू या खुद से गुणा (या भाग) करना. उदाहरण के लिए, अगर
aऔरbइनपुट फ़ीचर हैं, तो यहां सिंथेटिक फ़ीचर के उदाहरण दिए गए हैं:- ab
- a2
- किसी फ़ीचर वैल्यू पर ट्रांसेंडेंटल फ़ंक्शन लागू करना. उदाहरण के लिए, अगर
cएक इनपुट सुविधा है, तो यहां सिंथेटिक सुविधाओं के उदाहरण दिए गए हैं:- sin(c)
- ln(c)
सिर्फ़ नॉर्मलाइज़ेशन या स्केलिंग करके बनाई गई सुविधाओं को सिंथेटिक सुविधाएं नहीं माना जाता.
T
टेस्ट लॉस
यह मेट्रिक, टेस्ट सेट के हिसाब से मॉडल के लॉस को दिखाती है. मॉडल बनाते समय, आम तौर पर टेस्ट लॉस को कम करने की कोशिश की जाती है. ऐसा इसलिए है, क्योंकि कम टेस्ट लॉस, कम ट्रेनिंग लॉस या कम पुष्टि करने वाले लॉस की तुलना में ज़्यादा भरोसेमंद क्वालिटी सिग्नल होता है.
कभी-कभी, टेस्ट लॉस और ट्रेनिंग लॉस या पुष्टि करने के लॉस के बीच का बड़ा अंतर यह बताता है कि आपको रेगुलराइज़ेशन रेट को बढ़ाना होगा.
ट्रेनिंग
मॉडल में शामिल पैरामीटर (वज़न और बायस) तय करने की प्रोसेस. ट्रेनिंग के दौरान, सिस्टम उदाहरण पढ़ता है और धीरे-धीरे पैरामीटर में बदलाव करता है. ट्रेनिंग के दौरान, हर उदाहरण का इस्तेमाल कुछ बार से लेकर अरबों बार तक किया जाता है.
ज़्यादा जानकारी के लिए, एमएल कोर्स की बुनियादी जानकारी में पर्यवेक्षित लर्निंग देखें.
ट्रेनिंग लॉस
यह मेट्रिक, ट्रेनिंग के किसी खास इटरेशन के दौरान मॉडल के लॉस को दिखाती है. उदाहरण के लिए, मान लें कि लॉस फ़ंक्शन Mean Squared Error है. ऐसा हो सकता है कि 10वें इटरेशन के लिए ट्रेनिंग लॉस (मीन स्क्वेयर्ड एरर) 2.2 हो और 100वें इटरेशन के लिए ट्रेनिंग लॉस 1.9 हो.
लॉस कर्व, ट्रेनिंग लॉस की तुलना में इटरेशन की संख्या को प्लॉट करता है. लॉस कर्व से, ट्रेनिंग के बारे में ये संकेत मिलते हैं:
- नीचे की ओर झुकी हुई लाइन का मतलब है कि मॉडल बेहतर हो रहा है.
- ऊपर की ओर बढ़ती हुई ढलान का मतलब है कि मॉडल की परफ़ॉर्मेंस खराब हो रही है.
- स्लोप के फ़्लैट होने का मतलब है कि मॉडल कन्वर्जेंस पर पहुंच गया है.
उदाहरण के लिए, यहां दिए गए लॉस कर्व से पता चलता है कि:
- शुरुआती इटरेशन के दौरान, नीचे की ओर तेज़ी से गिरता हुआ स्लोप. इससे पता चलता है कि मॉडल में तेज़ी से सुधार हो रहा है.
- ट्रेनिंग के आखिर तक, धीरे-धीरे कम होने वाला (लेकिन अब भी नीचे की ओर) स्लोप. इसका मतलब है कि मॉडल में सुधार जारी है, लेकिन शुरुआती इटरेशन की तुलना में कुछ हद तक धीमी गति से.
- ट्रेनिंग के आखिर में, लॉस में धीरे-धीरे कमी होना. इससे पता चलता है कि मॉडल कन्वर्ज हो रहा है.
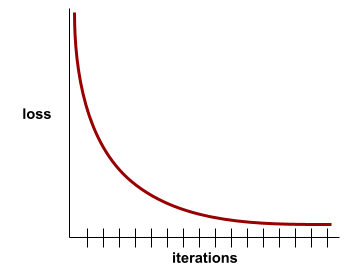
ट्रेनिंग लॉस अहम होता है. हालांकि, सामान्यीकरण के बारे में भी जानें.
ट्रेनिंग और ब्राउज़र में वेब पेज खोलने के दौरान परफ़ॉर्मेंस में अंतर
ट्रेनिंग के दौरान मॉडल की परफ़ॉर्मेंस और सर्विस देने के दौरान उसी मॉडल की परफ़ॉर्मेंस के बीच का अंतर.
ट्रेनिंग सेट
डेटासेट का वह सबसेट जिसका इस्तेमाल मॉडल को ट्रेन करने के लिए किया जाता है.
आम तौर पर, डेटासेट में मौजूद उदाहरणों को तीन अलग-अलग सबसेट में बांटा जाता है:
- ट्रेनिंग सेट
- वैलिडेशन सेट
- टेस्ट सेट
आदर्श रूप से, डेटासेट में मौजूद हर उदाहरण, ऊपर दिए गए सबसेट में से सिर्फ़ एक से जुड़ा होना चाहिए. उदाहरण के लिए, एक ही उदाहरण को ट्रेनिंग सेट और पुष्टि करने वाले सेट, दोनों में शामिल नहीं किया जाना चाहिए.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: ओरिजनल डेटासेट को बांटना लेख पढ़ें.
ट्रू नेगेटिव (टीएन)
इस उदाहरण में, मॉडल ने नेगेटिव क्लास का सही अनुमान लगाया है. उदाहरण के लिए, मॉडल यह अनुमान लगाता है कि कोई ईमेल मैसेज स्पैम नहीं है और वह ईमेल मैसेज वाकई स्पैम नहीं है.
ट्रू पॉज़िटिव (टीपी)
ऐसा उदाहरण जिसमें मॉडल, पॉज़िटिव क्लास का सही अनुमान लगाता है. उदाहरण के लिए, मॉडल यह अनुमान लगाता है कि कोई ईमेल मैसेज स्पैम है और वह ईमेल मैसेज वाकई स्पैम है.
ट्रू पॉज़िटिव रेट (टीपीआर)
recall का समानार्थी शब्द. यानी:
ट्रू पॉज़िटिव रेट, आरओसी कर्व में y-ऐक्सिस होता है.
U
अंडरफ़िटिंग
मॉडल का अनुमान लगाने की क्षमता कम होना, क्योंकि मॉडल ने ट्रेनिंग डेटा की जटिलता को पूरी तरह से कैप्चर नहीं किया है. कई समस्याओं की वजह से अंडरफ़िटिंग हो सकती है. इनमें ये समस्याएं शामिल हैं:
- सुविधाओं के गलत सेट पर ट्रेनिंग दी गई हो.
- बहुत कम इपॉक के लिए ट्रेनिंग दी गई है या लर्निंग रेट बहुत कम है.
- रेगुलराइज़ेशन रेट बहुत ज़्यादा होने पर ट्रेनिंग.
- डीप न्यूरल नेटवर्क में बहुत कम हिडन लेयर उपलब्ध कराना.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग देखें.
बिना लेबल वाला उदाहरण
ऐसा उदाहरण जिसमें सुविधाएं शामिल हैं, लेकिन लेबल नहीं है. उदाहरण के लिए, यहां दी गई टेबल में, घर की वैल्यू का अनुमान लगाने वाले मॉडल के तीन ऐसे उदाहरण दिखाए गए हैं जिन्हें लेबल नहीं किया गया है. इनमें से हर उदाहरण में तीन सुविधाएं हैं, लेकिन घर की वैल्यू नहीं है:
| कमरों की संख्या | बाथरूम की संख्या | घर की उम्र |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
सुपरवाइज़्ड मशीन लर्निंग में, मॉडल को लेबल किए गए उदाहरणों के आधार पर ट्रेन किया जाता है. साथ ही, वे बिना लेबल वाले उदाहरणों के आधार पर अनुमान लगाते हैं.
सेमी-सुपरवाइज़्ड और अनसुपरवाइज़्ड लर्निंग में, ट्रेनिंग के दौरान बिना लेबल वाले उदाहरणों का इस्तेमाल किया जाता है.
लेबल किए गए उदाहरण के साथ, बिना लेबल वाले उदाहरण की तुलना करें.
अनसुपरवाइज़्ड मशीन लर्निंग
किसी डेटासेट में पैटर्न ढूंढने के लिए, मॉडल को ट्रेन करना. आम तौर पर, यह लेबल नहीं किया गया डेटासेट होता है.
बिना निगरानी वाली मशीन लर्निंग का सबसे ज़्यादा इस्तेमाल, डेटा को मिलते-जुलते उदाहरणों के ग्रुप में क्लस्टर करने के लिए किया जाता है. उदाहरण के लिए, बिना निगरानी वाले मशीन लर्निंग एल्गोरिदम, संगीत की अलग-अलग प्रॉपर्टी के आधार पर गानों को क्लस्टर कर सकता है. इन क्लस्टर का इस्तेमाल, मशीन लर्निंग के अन्य एल्गोरिदम के लिए इनपुट के तौर पर किया जा सकता है. उदाहरण के लिए, संगीत के सुझाव देने वाली सेवा के लिए. अगर काम के लेबल कम हैं या मौजूद नहीं हैं, तो क्लस्टरिंग से मदद मिल सकती है. उदाहरण के लिए, धोखाधड़ी और गलत इस्तेमाल रोकने जैसे डोमेन में क्लस्टर, लोगों को डेटा को बेहतर तरीके से समझने में मदद कर सकते हैं.
इसकी तुलना सुपरवाइज़्ड मशीन लर्निंग से करें.
ज़्यादा जानकारी के लिए, एमएल के बारे में जानकारी देने वाले कोर्स में मशीन लर्निंग क्या है? देखें.
V
वैलिडेशन
किसी मॉडल की क्वालिटी का शुरुआती आकलन. पुष्टि करने की प्रोसेस में, मॉडल के अनुमानों की क्वालिटी की जांच की जाती है. इसके लिए, पुष्टि करने के लिए इस्तेमाल किए जाने वाले डेटा सेट का इस्तेमाल किया जाता है.
पुष्टि करने के लिए इस्तेमाल किया गया डेटा, ट्रेनिंग के लिए इस्तेमाल किए गए डेटा से अलग होता है. इसलिए, पुष्टि करने से ओवरफ़िटिंग से बचने में मदद मिलती है.
मॉडल का आकलन करने के लिए, पुष्टि करने वाले सेट का इस्तेमाल करना, टेस्टिंग का पहला राउंड माना जा सकता है. वहीं, मॉडल का आकलन करने के लिए, टेस्ट सेट का इस्तेमाल करना, टेस्टिंग का दूसरा राउंड माना जा सकता है.
पुष्टि करने के दौरान होने वाला नुकसान
यह एक मेट्रिक है. यह ट्रेनिंग के किसी इटरेशन के दौरान, पुष्टि करने वाले सेट पर मॉडल के लॉस को दिखाती है.
जनरलाइज़ेशन कर्व भी देखें.
वैलिडेशन सेट
डेटासेट का वह सबसेट जो ट्रेन किए गए मॉडल के ख़िलाफ़ शुरुआती आकलन करता है. आम तौर पर, ट्रेन किए गए मॉडल का आकलन टेस्ट सेट के आधार पर करने से पहले, कई बार मान्य किए गए सेट के आधार पर किया जाता है.
आम तौर पर, डेटासेट में मौजूद उदाहरणों को इन तीन अलग-अलग सबसेट में बांटा जाता है:
- ट्रेनिंग सेट
- वैलिडेशन सेट
- टेस्ट सेट
आदर्श रूप से, डेटासेट में मौजूद हर उदाहरण, ऊपर दिए गए सबसेट में से सिर्फ़ एक से जुड़ा होना चाहिए. उदाहरण के लिए, एक ही उदाहरण को ट्रेनिंग सेट और पुष्टि करने वाले सेट, दोनों में शामिल नहीं किया जाना चाहिए.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: ओरिजनल डेटासेट को बांटना लेख पढ़ें.
W
वज़न का डेटा
यह एक ऐसी वैल्यू होती है जिसे मॉडल, दूसरी वैल्यू से गुणा करता है. ट्रेनिंग, मॉडल के सबसे सही वेट तय करने की प्रोसेस है; अनुमान, अनुमान लगाने के लिए सीखे गए वेट का इस्तेमाल करने की प्रोसेस है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन देखें.
वेटेड सम
सभी काम की इनपुट वैल्यू का योग, जिसे उनके संबंधित वेट से गुणा किया जाता है. उदाहरण के लिए, मान लें कि काम के इनपुट में यह जानकारी शामिल है:
| इनपुट वैल्यू | इनपुट वज़न |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
इसलिए, वज़न के हिसाब से कुल स्कोर यह होगा:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
वेटेड सम, ऐक्टिवेशन फ़ंक्शन का इनपुट आर्ग्युमेंट होता है.
Z
ज़ेड-स्कोर नॉर्मलाइज़ेशन
यह स्केलिंग की एक ऐसी तकनीक है जो रॉ फ़ीचर वैल्यू को फ़्लोटिंग-पॉइंट वैल्यू से बदल देती है. यह वैल्यू, उस फ़ीचर के औसत से मानक विचलनों की संख्या को दिखाती है. उदाहरण के लिए, मान लें कि किसी सुविधा का औसत 800 है और उसका स्टैंडर्ड डेविएशन 100 है. यहां दी गई टेबल में दिखाया गया है कि Z-स्कोर नॉर्मलाइज़ेशन, रॉ वैल्यू को उसके Z-स्कोर पर कैसे मैप करेगा:
| असल वैल्यू | ज़ेड-स्कोर |
|---|---|
| 800 | 0 |
| 950 | +1.5 |
| 575 | -2.25 |
इसके बाद, मशीन लर्निंग मॉडल, रॉ वैल्यू के बजाय उस सुविधा के लिए Z-स्कोर पर ट्रेन करता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: सामान्यीकरण देखें.